ML в реальном мире: Складская система распознавания деталей

Одним из проектов над которыми мне пришлось недавно поработать в качестве тим лида команды быстрого прототипирования ИИ решений компании ICL Services [1], стало создание складской системы для распознавания складируемых деталей. Проблема достаточно простая для понимания: на промышленном складе кладовщики, особенно новые, при поступлении новой партии, зачастую не могут с ходу понять что за детали поступили, и куда их нужно отнести. Когда имеются десятки тысяч позиций, задача перестает быть тривиальной, а незнание деталей «в лицо» зачастую превращается в получасовое листание каталогов и блуждание по просторам склада в поисках заветного контейнера, что является пустой тратой времени.
Решение, которое сразу напрашивается — создание системы, которая при помощи компьютерного зрения распознает попавшую в поле зрения видеокамеры деталь и показывает место на складе, где эта деталь хранится.
Решение в лоб — сделать с десяток фотографий каждой детали (из около 10-ти тысяч) и обучить на этом классификатор, а потом по мере появления добавлять фото новых деталей и дообучать систему в процессе эксплуатации. Решение вполне рабочее, но… создание обучающей выборки такого размера вживую займет несколько месяцев работы и впоследствии потребует постоянного контроля добавляемых примеров. Заказчик же обычно хочет получить результаты быстрее, дешевле и без ввязывания в дорогостоящее постоянное дообучение системы в ручном режиме.
Можно ли что-то сделать?
Нам повезло и ответ в нашем случае был утвердительным. Нюанс, который позволил нам в разы снизить стоимость и продолжительность проекта — это то, что в нашем случае мы имеем дело со складом завода по производству деталей, а сами детали плоские, хотя и производятся из стальных листов разной толщины. А главное — для всех деталей имеются CAD-модели.
![Рис. 1. Пример CAD-модели в Blender [2]](https://habrastorage.org/getpro/habr/upload_files/811/6e4/36a/8116e436a88bbe2fd6846fd86921c477.png) Рис. 1. Пример CAD-модели в Blender [2]
Рис. 1. Пример CAD-модели в Blender [2]Соответственно, оптимальное решение к которому мы пришли — обучить систему на изображениях на основе CAD-моделей, а использовать уже на реальных. Тогда не надо создавать огромный датасет из фотографий реальных объектов. В нашем случае это становится возможным, учитывая, что все детали плоские.
Делаем 2 модели:
Модель сегментации, которая по фото объекта дает его маску (маска плоского объекта однозначно определяет деталь; примеры масок можно посмотреть ниже на Рис. 5);
Модель классификации, которая по полученной маске объекта на входе говорит что это за деталь.
Модель классификации — классическая ResNet-50 [3], предобученная на ImageNet [4]. Датасет создается достаточно прямолинейно. По имеющимся CAD-моделям при помощи скриптов для Blender [2] рендерим маски наших деталей с разбросом смещений детали от центра и под разными углами камеры относительно вертикали (это необходимо, т.к. несмотря на плоскость деталей снимает их камера, которая может это делать под различными ракурсами; мы допускали отклонение до 30 градусов). Количество классов равно количеству наименований деталей в каталоге. При добавлении новых деталей в каталог (на сетевом диске появляются новые CAD-модели) модель автоматически обновляется путем повторного обучения, что занимает несколько часов на том же самом GPU, который параллельно используется для распознавания деталей.
С моделью сегментации немного сложнее. Необходимо научить модель сегментировать детали на синтетических данных так, чтобы потом сегментация происходила с высокой точностью уже на реальных фотографиях при различной освещенности, была устойчива к изменениям материала деталей, к изменениям фона, к теням.
Сама модель сегментации — это классическая U-Net [5] (бинарный сегментатор, где для каждого пиксела изображения определяем принадлежит он детали или нет, обученный при помощи Dice Loss [6]) на основе той же ResNet-50 [3], предобученной на ImageNet [4]. Несмотря на нетривиальность, такой синтетический датасет для обучения сегментации удалось построить, симулируя разнообразие возможного внешнего вида деталей, которые мы строим из случайной комбинации следующих элементов:
масок деталей (строго говоря, не обязательно деталей; подойдет все, что выглядит как маска);
 Рис. 2. Примеры масок для генерации синтетических изображений деталей
Рис. 2. Примеры масок для генерации синтетических изображений деталейтекстур фона (из любых свободно распространяемых подборок);
 Рис. 3. Примеры текстур фона для генерации синтетических изображений деталей
Рис. 3. Примеры текстур фона для генерации синтетических изображений деталейтекстур материала деталей (из любых свободно распространяемых подборок);
 Рис. 4. Примеры текстур материала деталей для генерации изображений
Рис. 4. Примеры текстур материала деталей для генерации изображенийтого, как могут выглядеть блики на краях (см. примеры генерации ниже на Рис. 6);
того, как деталь на краях может отбрасывать тени (см. примеры генерации ниже на Рис. 6);
того, как тени могут налагаться на сцену (см. примеры генерации ниже на Рис. 6).
Тема достаточно сложная, но толковый специалист по машинной графике за разумное время решит проблему генерации синтетических примеров для сегментации. Здесь я не буду приводить формул. Приведу лишь примеры масок (Рис. 5), которые относительно легко получаются из CAD-моделей, и процедурно сгенерированные по ним псевдо-фотографии (Рис. 6).
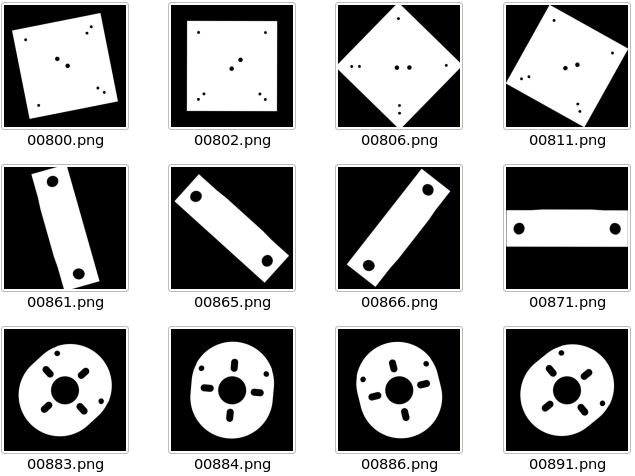 Рис. 5. Примеры масок деталей для генерации синтетических изображений деталей
Рис. 5. Примеры масок деталей для генерации синтетических изображений деталей Рис. 6. Примеры сгенерированных по маскам синтетических изображений деталей
Рис. 6. Примеры сгенерированных по маскам синтетических изображений деталейДобавим аугментацию (augmentation [7]). Теперь примеры для обучения сегментатора выглядят так.
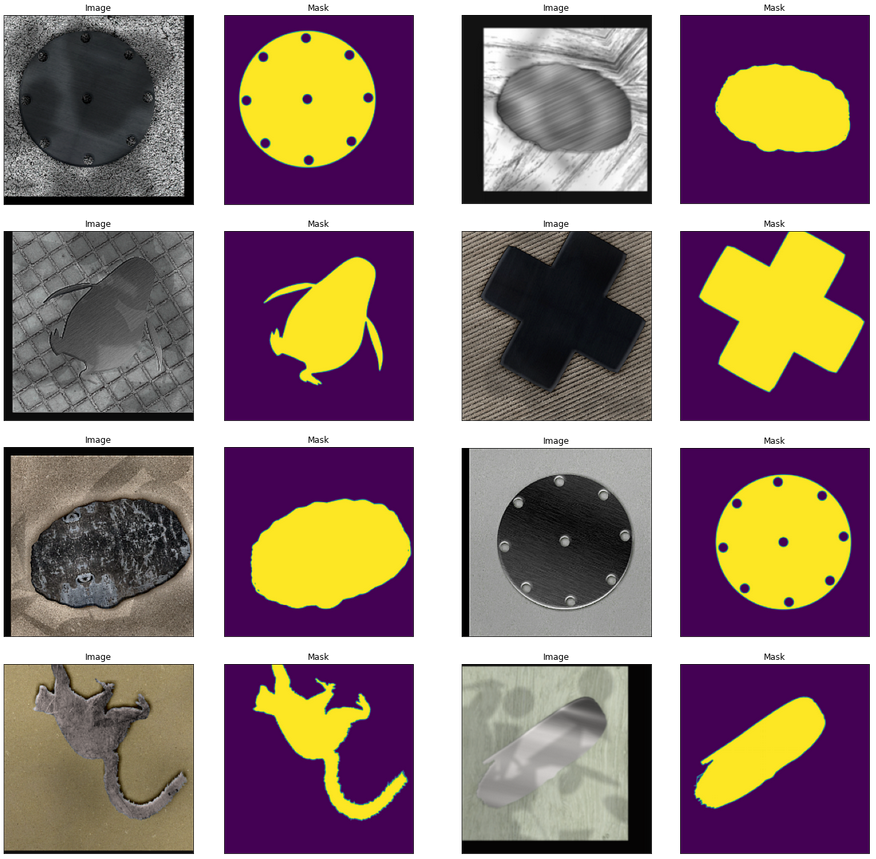 Рис. 7. Аугментированные (augmented) примеры для обучения модели сегментации
Рис. 7. Аугментированные (augmented) примеры для обучения модели сегментацииДальше все просто. Учим модель-сегментатор сегментировать изображения, а модель классификатор классифицировать маски деталей. И проверяем точность классификации на тестовой выборке (в нашем случае у нас было 177 реальных фотографий деталей).
 Рис. 8. Результаты классификации на нескольких примерах тестовой выборки
Рис. 8. Результаты классификации на нескольких примерах тестовой выборкиИтого имеем: Correct predictions: 100.00% (177 out of 177)
Ну здесь нам просто повезло, и вся тестовая выборка определилась правильно на 100%, хотя от запуска к запуску результаты могут немного отличаться. Такое происходит, т.к. мы используем технику Test Time Augmentation (TTA) [8] как для сегментации, так и для классификации, т.к. TTA позволяет снизить ошибку примерно на 10%. Поэтому процесс классификации недетерминированный и зависит от random seed (на который завязана TTA). Если же смотреть усредненную точность по 10 запускам, то она получается около 99% (более объективные цифры мы получим позже, когда у нас появится доступ к большому количеству реальных изображений и мы сформируем полноценный test set).
Остается завернуть все это в простой пользовательский интерфейс, который в первой версии выглядел так.
 Рис. 9. Пользовательский интерфейс первой версии системы
Рис. 9. Пользовательский интерфейс первой версии системыЗдесь мы видим изображение с камеры (в данном случае камеры тестового стенда, под которую мы подкладываем черно-белую распечатку фото детали), результат обработки детали моделью сегментации и топ 16 предсказаний модели (если вдруг модель ошибется с топ 1 предсказанием, то все-равно с вероятностью более 99.9% ее можно отыскать в топ 16). Для найденной детали мы видим ее наименование и позицию на карте склада с указанием номера полки.
Таким образом, кладовщик теперь всегда может быстро понять что за деталь ему попалась, и где такие детали хранятся. Для этого ему нужно просто поместить деталь в поле зрения видеокамеры на входе в склад.
PS:
Эта статья является первой в цикле статей «ML в реальном мире» где я планирую поделиться историями создания продуктов, которые мы уже создали и еще только будем создавать нашими командами дата-саентистов компании ICL Services [1].
Также я веду микроблог, в котором разбираю ключевые моменты и идеи в периодически появляющихся передовых работах в сфере машинного обучения.
Не стесняйтесь оставлять обратную связь в комментариях. Всем удачи!
Ссылки
[1] ICL Services
[2] Blender
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, et al. Deep Residual Learning for Image Recognition. Ссылка.
[4] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, Li Fei-Fei, et al. ImageNet Large Scale Visual Recognition Challenge. Ссылка.
[5] Olaf Ronneberger, Philipp Fischer, Thomas Brox, et al. U-Net: Convolutional Networks for Biomedical Image Segmentation. Ссылка.
[6] Fausto Milletari, Nassir Navab, Seyed-Ahmad Ahmadi, et al. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. Ссылка.
[7] Data Augmentation
[8] Test Time Augmentation
