ML boot camp 2016 новичок в ТОП 10

И так, немного о моем опыте:
1) Вообще я PHP программист, и с питоном знаком очень мало, только по участию в Russian AI Cup 2015, там я впервые написал на питоне, и выиграл футболку;
2) По работе решил одну задачу по определению тональности текста, с использованием scikit-learn;
3) Начал проходить курс на coursera.org от яндекса, по машинному обучению.
На этом мой опыт с питоном и машинным обучением заканчивается.
Начало конкурса
Поставил себе python3 и notebook, и начал разбираться с pandas из обучающей статьи. Загрузил данные, скормил рандомному лесу, и получил на выходе ~0,133
Все, на этом мысли о решении задачи закончились.
Изучение предмета и сбор дополнительной информации
Возвращаюсь к задаче, цепляюсь за строчку »Идею задачи мы почерпнули из работы А.А. Сиднева, В.П. Гергеля». Собственно в книге описано как решать такую задачу. Правда я не понял как мне эту идею реализовать, но я увидел интересный график:
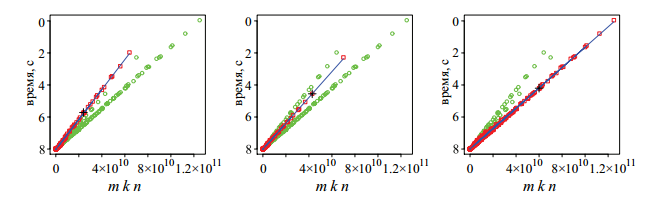
Хм, а действительно, зависимость времени от размера матриц то должна быть линейной, подумал я, и решил посмотреть как с этим обстоят дела с нашими данными. Сгруппировав все примеры по характеристикам я обнаружил что есть всего 92 группы. Собственно построив графики для каждого из вариантов я увидел, что у половины линейная зависимость с небольшими выбросами. А другая половина тоже показывала линейную зависимость, но с сильной дисперсией. Графиков много, поэтому приведу всего три примера
С дисперсией:
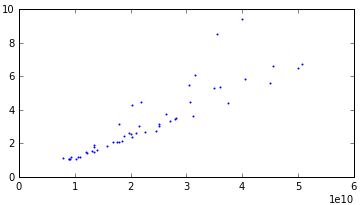
Линейная:
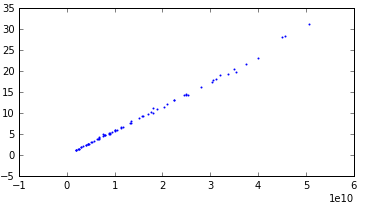
С очень сильной дисперсией:
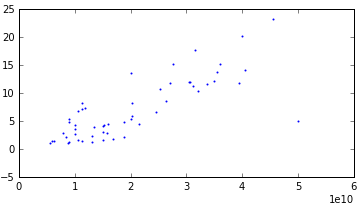
Последний график выделил в отдельную группу, потому что на кросс-валидации он показывал плохие результаты. Решил для этого случая что-нибудь особое сделать (но в итоге ничего особого не сделал).
Работа с данными
Собственно я построил линейные регрессии для каждой группы, и получил ~0,076. Здесь я подумал, что нашел ключ к решению задачи, и начал подстраиваться под графики. Испробовал практически все модели регрессии которые были в scikit-learn (да, знаний нет, поэтому решал задачу методом научного тыка) результат особо не улучшался.
Внедрил даже полином. Пробегался по всем группам, и с помощью GridSearchCV искал лучшие параметры для каждой группы. Заметил что в некоторых группах загибается совсем не так как мне бы хотелось. Начал работать с данными. Во первых заметил что есть строки с отсутствующими данными о памяти (memtRFC, memFreq, memType). C помощью просто логических умозаключений восстановил эти данные. Для примера, были данные с memtRFC равным 'DDR-SDRAM PC3200' и 'DDR-SDRAM PC-3200'. Очевидно что это одно и тоже.
Надеялся что это уменьшит количество групп, но так не вышло. Дальше, начал работать с выбросами. По хорошему нужно было бы написать метод автоматически определяющий выбросы, но я все делал руками. Нарисовал графики для всех групп, и визуально определял выбросы, и исключал эти точки.
Кросс-валидация
После всего этого столкнулся с проблемой, что у меня тесты показывают результат 0.064, а по факту 0,073. Переобучил видимо. Написал класс обертку с методами fit и predict внутри которого разбивал данные на группы, обучал модельки для каждой группы, и предсказывал так же для каждой группы. Это позволило мне использовать кросс-валидацию. Собственно после этого результат моих тестов и загруженных данных всегда был очень близок.
Выглядело это примерно так:
class MyModel:
def __init__(self):
pass
def fit(self, X, Y):
# здесь я пробегаюсь по x, понимаю в какой группе он находится, и обучаю нужную модель для этой группы
def predict(self, X):
# здесь я пробегаюсь по x, понимаю в какой группе он находится, беру нужную модель и делаю предсказание
def get_params(self, deep=False):
return {}Теперь с помощью cross_validation.cross_val_score я мог качественно тестировать свой подход.
Еще мелкий прирост мне дала работа с данными выходящими за условия задачи. По условию Y не может быть меньше единицы. Посмотрев статистику, увидел что минимальный Y = 1.000085, а мои предсказания давали результат меньше 1. Не много, но были такие. Решил я эту проблему опять же методом тыка. Получилась такая формула:
time_new = 1 + pow(time_predict/2,2)/10В какой то момент я осознал, что нужно не просто решать абстрактную задачу, а решать конкретную, то есть нужно стремиться не к точности предсказывания времени, а к минимизации ошибки. Это означает, что если реальное время работы скрипта 10 секунд, и я ошибся на 2 то моя ошибка |10–8|/10 = 0,2. А, если реально время 2 секунды, а я ошибся на 0,1, то |2–0,1|/2 = 0,95.
Разница очевидна. Когда я это осознал, а это почему то произошло далеко не сразу, решил увеличить точность на маленьком времени. Добавил к своей линейной регрессии веса. Методом подбора получилась такая формула 1/pow (Y,3.1). То есть, чем больше время, тем меньше ее значимость. Добавив к этому устойчивую к выбросам модель, получил в итоге связку из 4 моделей
LinearRegression() # у этой модели есть веса
TheilSenRegressor()
Pipeline([('poly', PolynomialFeatures()), ('linear', TheilSenRegressor())]) # параметры для каждой группы подбирались GreadSearchCV автоматическиСобственно среднее от этих моделей давало мне результат 0,057. Тогда я скаканул на 14 место, после чего плавно скатывался на 20.
Попытки как то улучшить результат подбором лучших параметров, изменение моделек, их комбинаций, и даже добавлением фейковых точек успехом не увенчались.
Финишная прямая
На четко линейных группах результат был отличный, значит нужно было работать с данными у которых сильная дисперсия. Решил и своим предсказанием добавить дисперсии, для этого обучил ExtraTreesRegressor на всех не четко линейных группах, взял 36 самых важных параметров по мнению модели. Написал скрипт, который в цикле делал кросс-валидацию по данным, только из этих 36 параметров, каждый раз исключая один параметр. Таким образом я увидел без какого параметра получается лучший результат. Эту итерацию повторял пока качество не перестало улучшаться. Да, это не совсем правильный подход, потому что параметр исключенный в первой итерации мог давать прирост в пятой. По хорошему нужно было проверить все варианты, но это через чур долго, так что улучшив на пару процентов качество, я был доволен результатом.
Далее, для нелинейных групп добавилась еще одна модель, но с особым условием. Если время предсказанное ExtraTreesRegressor было меньше чем, среднее время предсказанное линейными моделями, то брал среднее между ними, если же больше, то брал только время предсказанное линейными моделями. (Лучше ошибиться в меньшую сторону, потому что, если реальное время выше, то ошибка меньше).
Это выкинуло меня на 8 место, откуда я опять же скатился до 10 го. Остальные мои попытки как то улучшить результат, тоже не принесли плодов. При пересчете всех тестовых результатов, я оказался на 9 месте. Между последними из ТОП 10 и не вошедшими туда, разница в очках около 0.0002. Это очень мало, что говорит о большом значении везения на этом рубеже.
Итоги
И так, выводы которые я сделал для себя:
- Всегда использовать кросс-валидацию;
- Стараться минимизировать ошибку;
- Необходимо работать с данными (выбросами, или отсутствием данных);
Призы
Хорошо что призы были небольшие и аж за 10 мест, что позволило мне втиснуться в призовые места. За своим, жестким диском заехал в офис мэйла, где меня встретил Илья, вручил приз, напоил соком и показал смотровую площадку. Так же меня заверили что планируются новые конкурсы с большими призами, так что будем ждать.
У меня все, всем спасибо, всем удачи!
