Микросервисы: размер имеет значение, даже если у вас Kubernetes
19 сентября в Москве состоялся первый тематический митап HUG (Highload++ User Group), который был посвящён микросервисам. На нём прозвучал доклад «Эксплуатация микросервисов: размер имеет значение, даже если у вас Kubernetes», в котором мы поделились обширным опытом компании «Флант» в области эксплуатации проектов с микросервисной архитектурой. В первую очередь он будет полезен всем разработчикам, задумывающимся о применении этого подхода в своём настоящем или будущем проекте.

Представляем видео с докладом (50 минут, гораздо информативнее статьи), а также основную выжимку из него в текстовом виде.
NB: Видео и презентация доступны также в конце этой публикации.
Введение
Обычно хорошая история имеет завязку, основной сюжет и развязку. Этот доклад больше похож на завязку, причём трагическую. Также важно отметить, что в нём представлен взгляд на микросервисы со стороны эксплуатации.
Начну с такого графика, автором которого (в 2015 году) стал Martin Fowler:
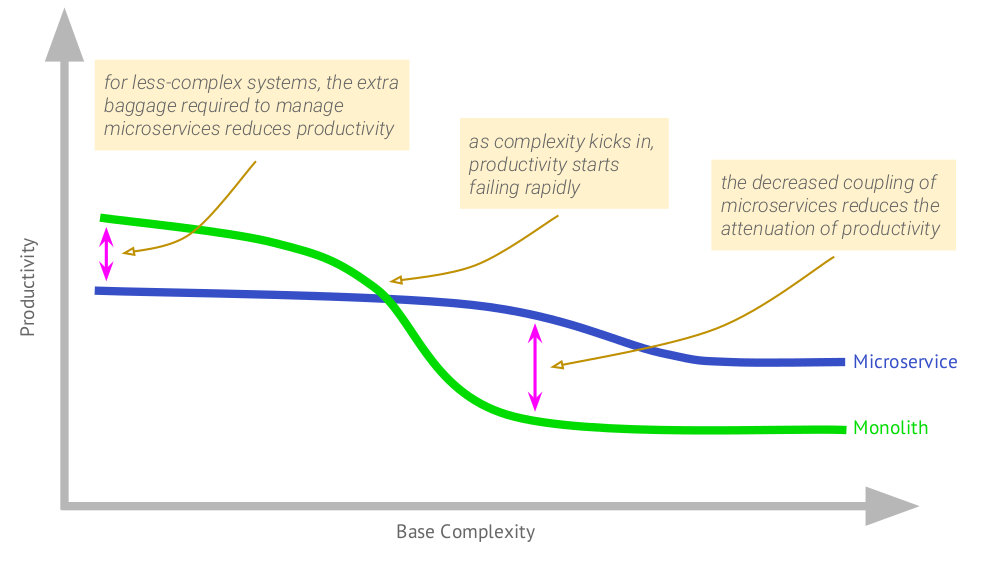
На нём видно, как в случае монолитного приложения, достигнувшего определённой величины, начинает падать продуктивность работы. Микросервисы отличаются тем, что изначальная продуктивность с ними ниже, однако по мере роста сложности деградация эффективности для них не так заметна.
Дополню этот график для случая использования Kubernetes:
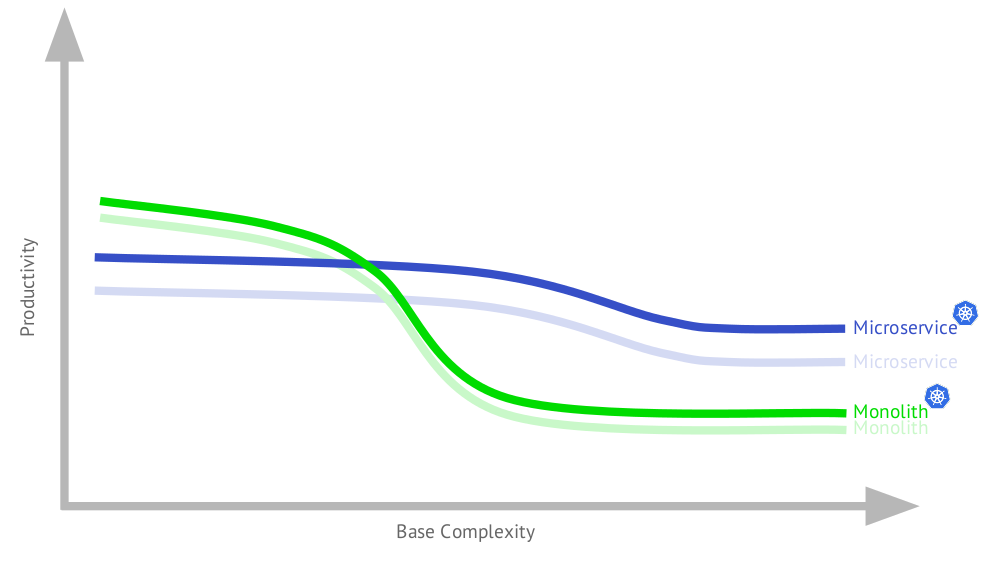
Почему приложению с микросервисами стало лучше? Потому что такая архитектура выдвигает серьёзные требования к архитектуре, которые в свою очередь отлично закрываются возможностями Kubernetes. С другой стороны, часть этой функциональности будет полезна и для монолита, особенно по той причине, что типичный на сегодняшний день монолит — это не совсем монолит (подробности будут далее в докладе).
Как видно, итоговый график (когда и монолитное, и микросервисное приложения в инфраструктуре с Kubernetes) не очень-то отличается от изначального. Далее речь будет идти о приложениях, эксплуатируемых с использованием Kubernetes.
Полезная и вредная микросервисность
И тут главная мысль:

Что же такое нормальная микросервисная архитектура? Она должна приносить вам реальную пользу, увеличивая эффективность работы. Если вернуться к графику, то вот она:
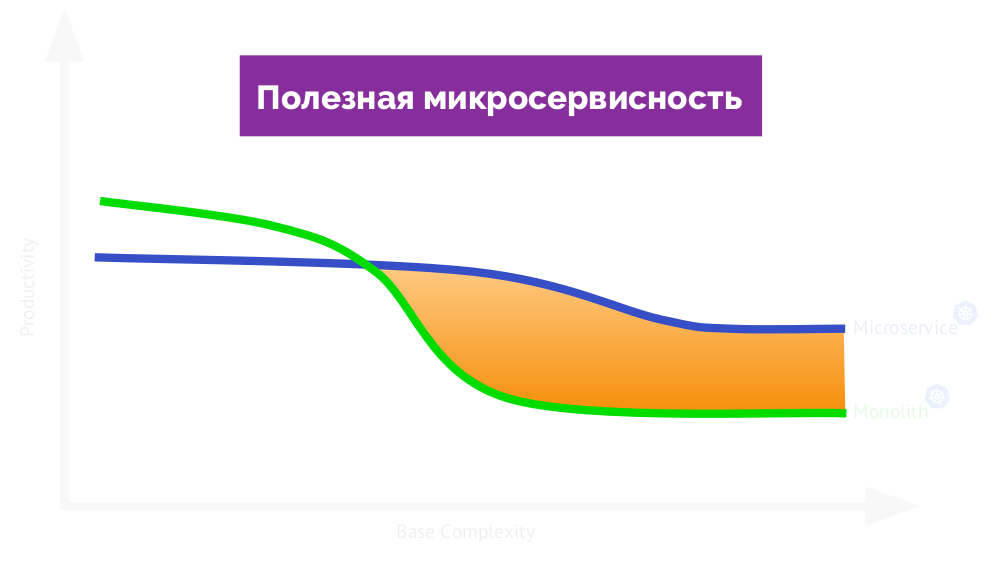
Если называть её полезной, то на другой стороне графика будет вредная микросервисность (мешает работе):
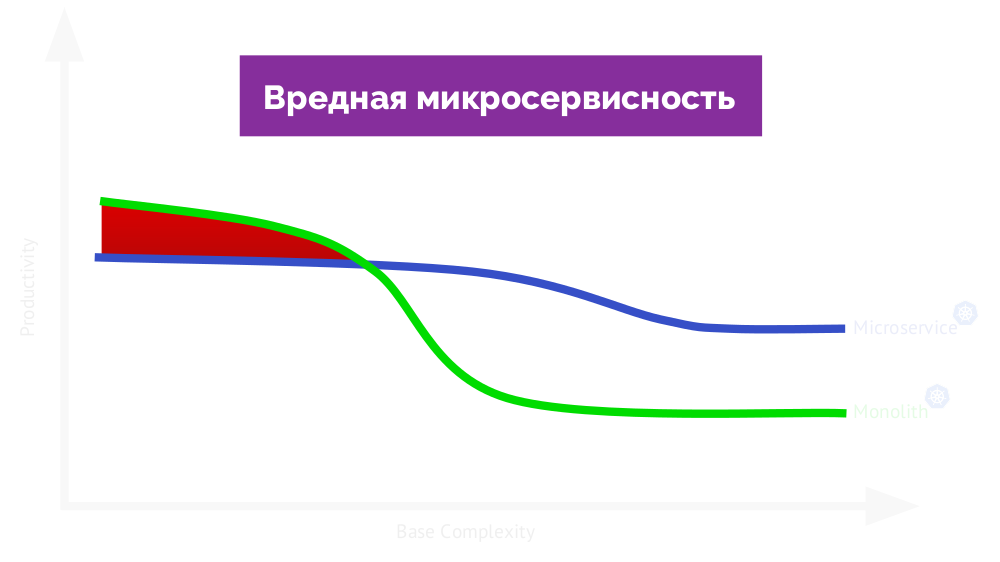
Возвращаясь к «главной мысли»: стоит ли вообще доверять моему опыту? С начала этого года я посмотрел 85 проектов. Не все они были микросервисными (такой архитектурой обладали примерно от трети до половины из них), но это всё равно большое число. Нам (компании «Флант») как аутсорсерам удаётся видеть широкое разнообразие приложений, разрабатываемых как в маленьких компаниях (с 5 разработчиками), так и в крупных (~500 разработчиков). Дополнительным плюсом является то, что мы видим, как эти приложения живут и развиваются на протяжении многих лет.
Зачем микросервисы?
На вопрос о пользе микросервисов есть весьма конкретный ответ у уже упомянутого Martin Fowler:
- чёткие границы модульности;
- независимый деплой;
- свобода выбора технологий.
Я много разговаривал с архитекторами и разработчиками программного обеспечения и спрашивал, зачем им микросервисы. И составил свой список их ожиданий. Вот что получилось:
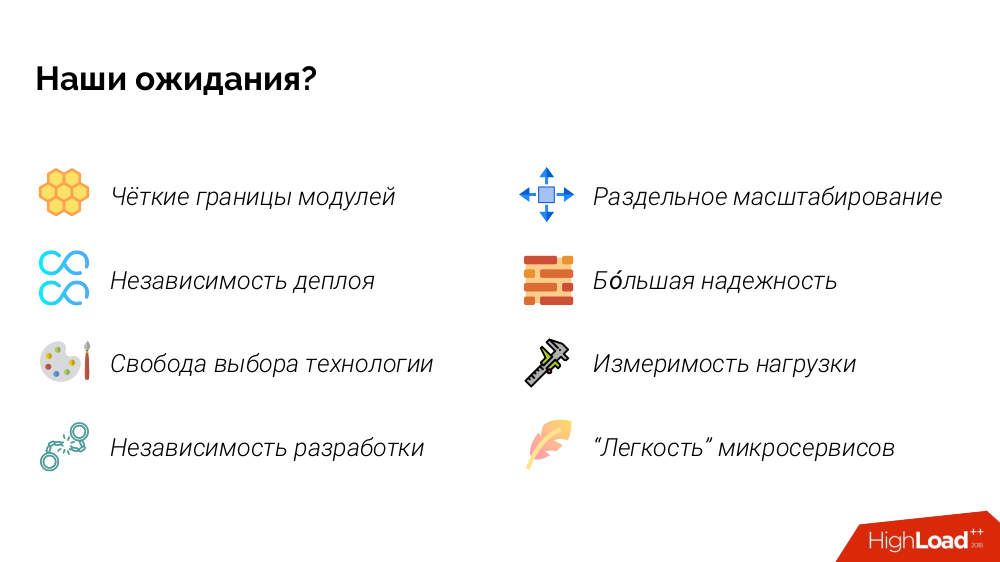
Если описать «в ощущениях» некоторые из пунктов, то:
- чёткие границы модулей: вот у нас есть страшный монолит, а теперь всё будет аккуратно разложено по Git-репозиториям, в которых всё «по полочкам», не перемешано тёплое с мягким;
- независимость деплоя: мы сможем выкатывать сервисы независимо, чтобы разработка шла быстрее (параллельно публиковать новые фичи);
- независимость разработки: мы можем отдать этот микросервис той команде/разработчику, а тот — другой, благодаря чему сможем быстрее разрабатывать;
- большая надёжность: если случится частичная деградация (упадёт один микросервис из 20), то перестанет работать лишь одна кнопка, а система в целом продолжит функционировать.
Типовая (вредная) микросервисная архитектура
Чтобы объяснить, почему в реальности всё не так, как мы ожидаем, я представлю собирательный образ микросервисной архитектуры, основанный на опыте из множества различных проектов.
Примером будет служить абстрактный интернет-магазин, собирающийся конкурировать с Amazon или хотя бы OZON. Его микросервисная архитектура выглядит так:
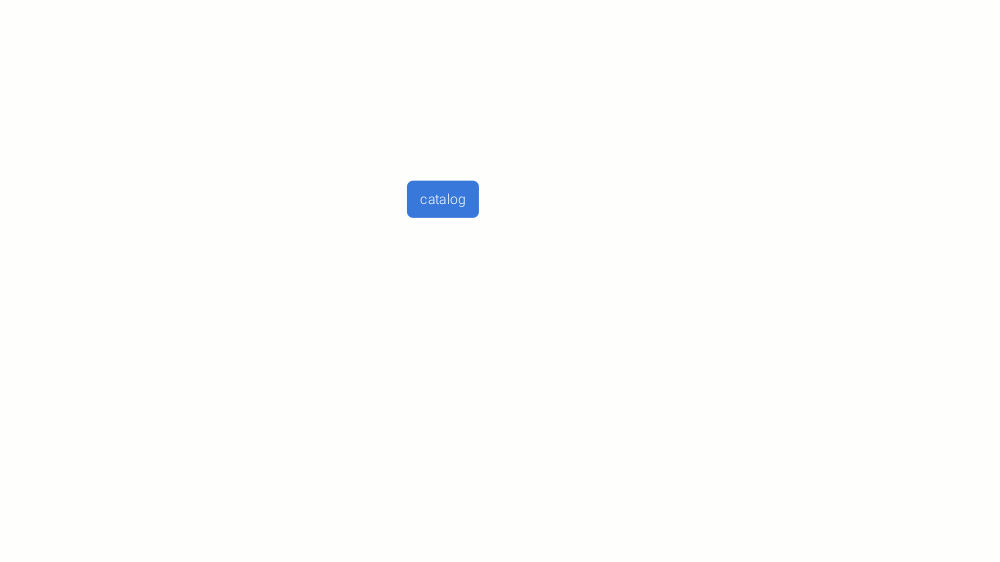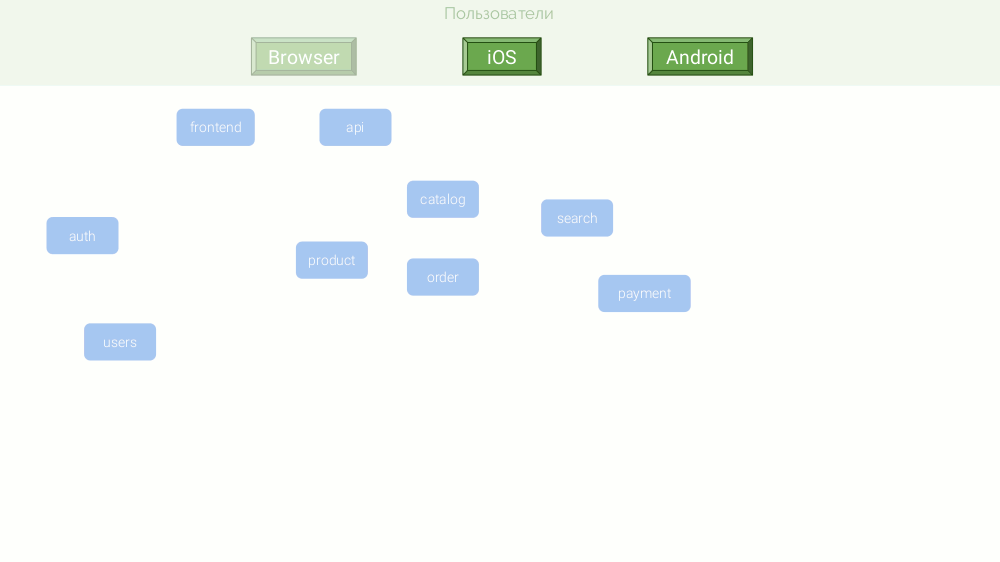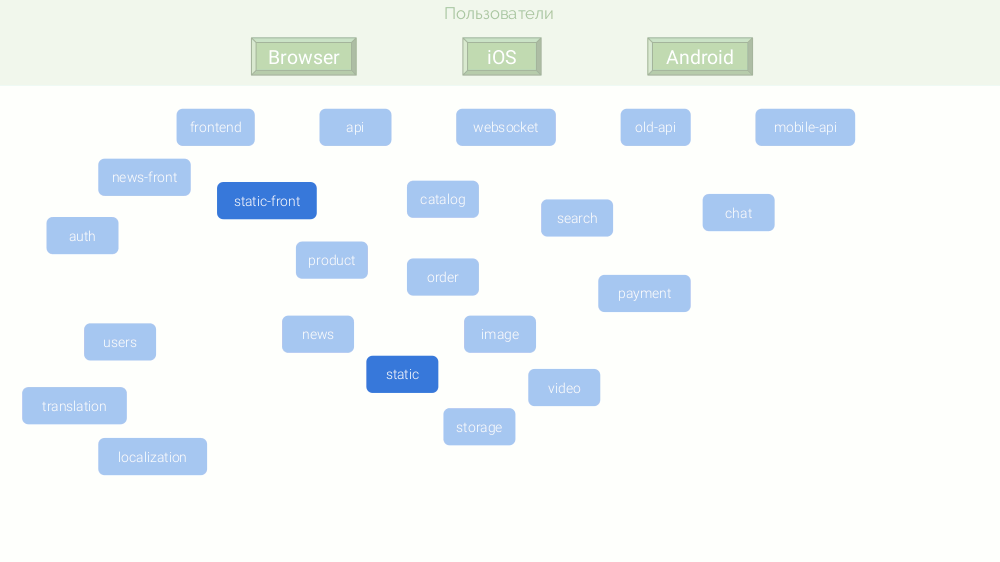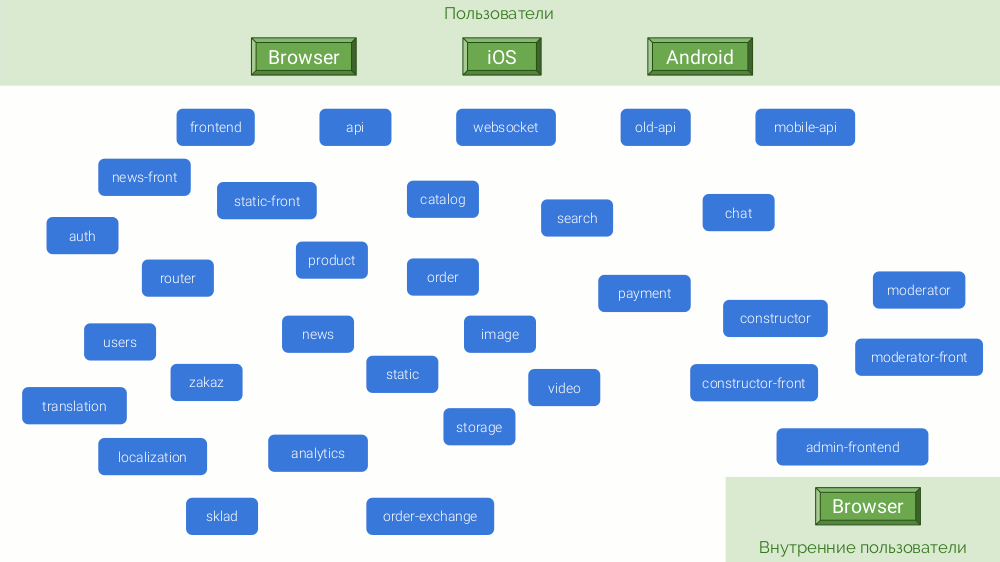
По совокупности причин, эти микросервисы написаны на разных платформах:

Поскольку у каждого микросервиса должна быть автономность, многие из них нуждаются в своей базе данных и кэше. Финальная архитектура получается следующей:
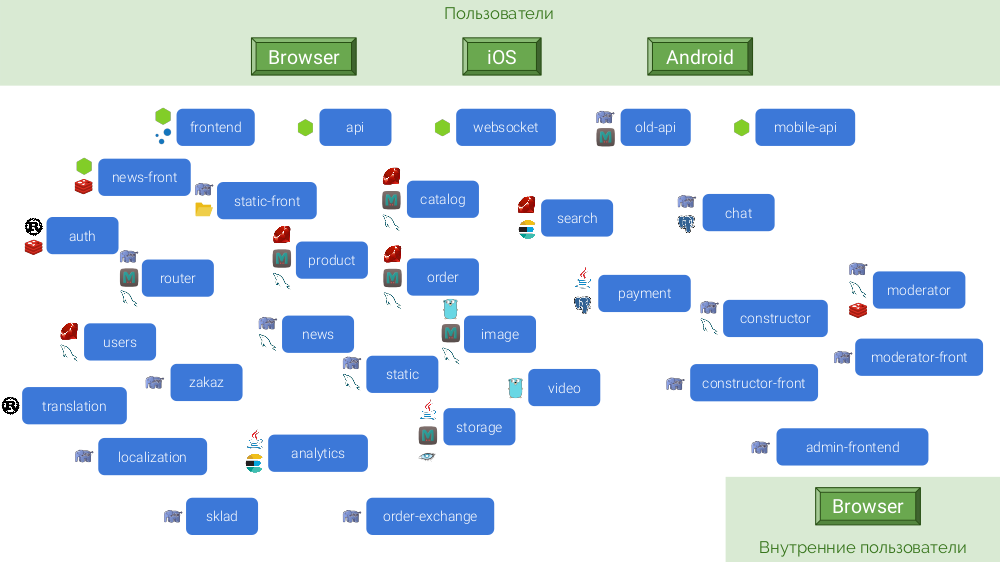
Каковы её последствия?
У Fowler’а и на этот счёт есть статья — о «расплате» за использование микросервисов:

А мы посмотрим, оправдались ли наши ожидания.
Чёткие границы модулей…
Но сколько микросервисов нам в действительности нужно поправить, чтобы выкатить изменение? Можем ли мы вообще разобраться, как всё работает, без распределённого трассировщика (ведь любой запрос обрабатывается половиной микросервисов)?
Существует паттерн «большой комок грязи», а здесь и вовсе получился распределённый комок грязи. В подтверждение тому — вот примерная иллюстрация того, как ходят запросы:
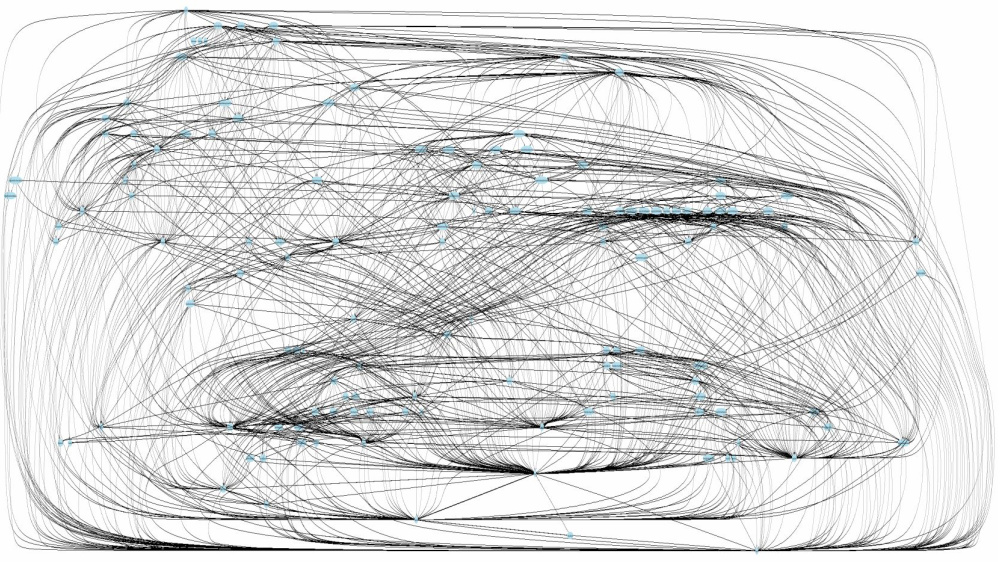
Независимость деплоя…
Технически она достигнута: мы можем перекатить каждый микросервис отдельно. Но на практике нужно учитывать, что всегда выкатывается множество микросервисов, причём нам нужно учитывать порядок их выката. По-хорошему нам вообще нужно в отдельном контуре тестировать, в правильном ли порядке мы выкатываем релиз.
Свобода выбора технологии…
Она есть. Только стоит помнить, что зачастую свобода граничит с беспределом. Очень важно здесь не выбирать технологии только для того, чтобы «поиграть» с ними.
Независимость разработки…
Как сделать тестовый контур для всего приложения (из такого множества компонентов)? А ведь ещё надо его поддерживать в актуальном виде. Всё это приводит к тому, что реальное количество тестовых контуров, которое мы в принципе можем содержать, оказывается минимальным.
А развернуть всё это локально?… Получается, что зачастую разработчик делает свою работу независимо, но «наугад», потому что вынужден ждать, когда освободится контур для тестирования.
Раздельное масштабирование…
Да, но оно ограничено в области используемых СУБД. В приведённом примере архитектуры не будет проблем у Cassandra, но будут у MySQL и PostgreSQL.
Большая надёжность…
Мало того, что в действительности вывод из строя одного микросервиса зачастую ломает корректное функционирование всей системы, так есть ещё и новая проблема: сделать отказоустойчивым каждый микросервис очень сложно. Потому что в микросервисах используются разные технологии (memcache, Redis и т.п.), для каждого нужно всё продумать и реализовать, что, конечно, возможно, но требует огромных ресурсов.
Измеримость нагрузки…
С этим действительно всё хорошо.
«Лёгкость» микросервисов…
У нас не только появились огромные сетевые накладные расходы (приумножаются запросы на DNS и т.п.), но и из-за множества подзапросов мы начали реплицировать данные (хранить кэши), что привело к значительному объёму хранилищ.
И вот каков итог соответствия нашим ожиданиям:
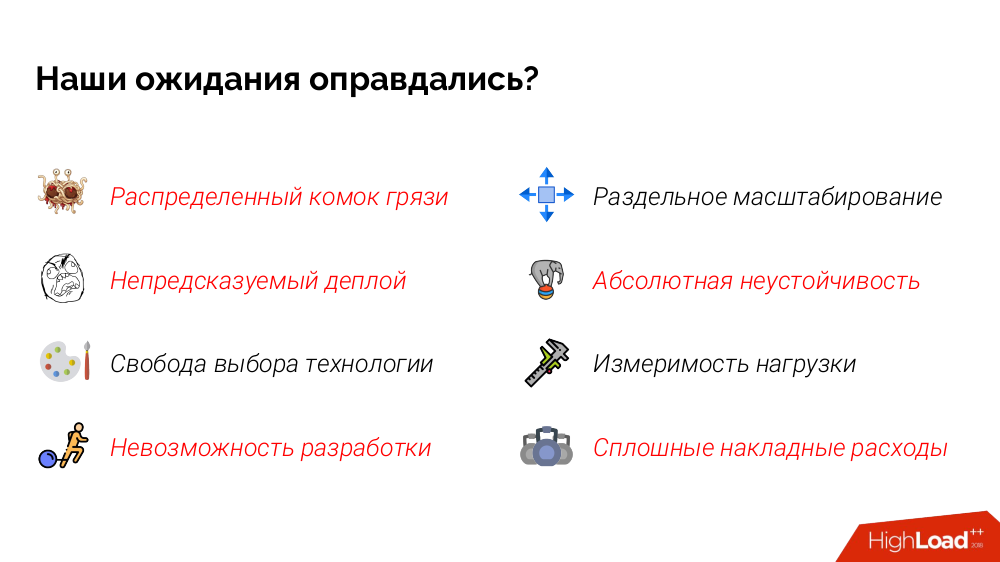
Но и это ещё не всё!
Потому что:
- Скорее всего нам потребуется шина сообщений.
- Как сделать консистентный бэкап на нужный момент времени? Единственный реальный вариант — выключить трафик для этого. Но как это сделать на production?
- Если идёт речь о поддержке нескольких регионов, то организовать устойчивость в каждом из них — очень трудоёмкая задача.
- Появляется проблема внесения централизованных изменений. Например, если нам нужно обновить версию PHP, то потребуется сделать коммит в каждый репозиторий (а их — десятки).
- Рост операционной сложности навскидку получается экспоненциальным.
Что со всем этим делать?
Начинайте с монолитного приложения. Опыт Fowler’а говорит о том, что практически все успешные микросервисные приложения начинались с монолита, который стал слишком большим, после чего и был разбит. В то же самое время практически все системы, построенные как микросервисные с самого начала, рано или поздно испытывали серьёзные проблемы.
Ещё одна ценная мысль — чтобы проект с микросервисной архитектурой был успешным, вы должны очень хорошо знать и предметную область, и как делать микросервисы. А лучший способ узнать предметную область — сделать монолит.
Но что делать, если мы уже оказались в такой ситуации?
Первый шаг к решению любой проблемы — согласиться с ней и понять, что это проблема, что мы больше не хотим страдать.
Если в случае разросшегося монолита (когда у нас закончилась возможность докупать для него ресурсы), мы его разрезаем, то в данном случае получается обратная история: когда чрезмерная микросервисность уже не помогает, а мешает — отрезайте лишнее и укрупняйте!
Например, для рассмотренного выше собирательного образа…
Избавьтесь от самых сомнительных микросервисов:

Объедините все микросервисы, отвечающие за генерацию фронтенда:

… в один микросервис, написанный на одном (современном и нормальном, как вы сами считаете) языке/фреймворке:

У него будет один ORM (одна СУБД) и сначала пара приложений:
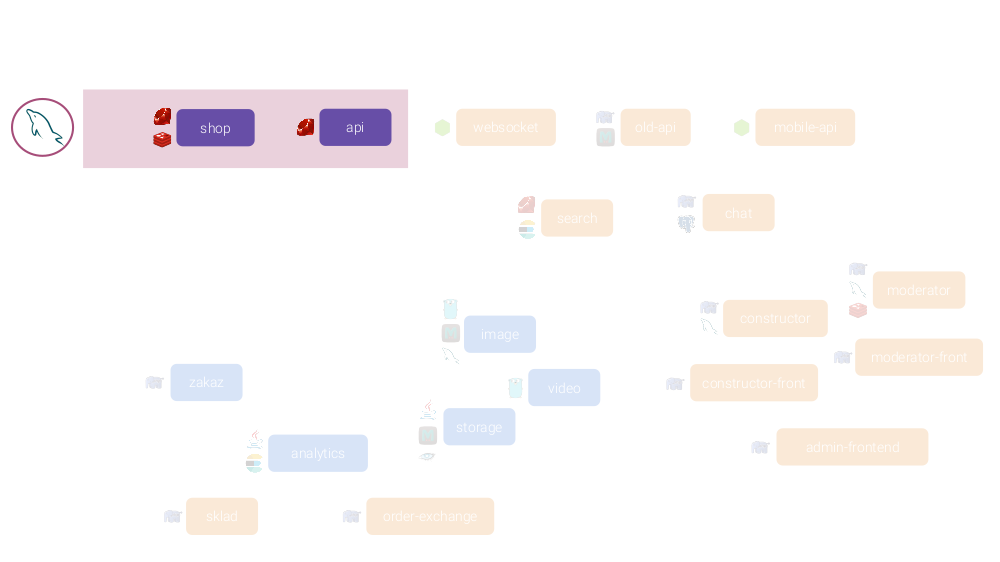
…, а вообще туда можно перенести гораздо больше, получив такой результат:

Причём в Kubernetes мы всё это запускаем отдельными экземплярами, а значит, что мы всё ещё можем измерять нагрузку и отдельно масштабировать их.
Резюмируя
Посмотрите на картину шире. Очень часто все эти проблемы с микросервисами возникают из-за того, что кто-то взял свою задачу, но хотел «поиграть в микросервисы».
В слове «микросервисы» часть «микро» является лишней. Они «микро» лишь по той причине, что меньше огромного монолита. Но не надо думать о них как о чём-то маленьком.
И для финальной мысли вернёмся к изначальному графику:

Написанное к нему примечание (справа наверху) сводится к тому, что навыки команды, которая делает ваш проект, всегда первичны — именно они сыграют ключевую роль в вашем выборе между микросервисами и монолитом. Если у команды не хватает умений, но она начинает делать микросервисы, история точно будет фатальной.
Видео и слайды
Видео с выступления (~50 минут; к сожалению, оно не передаёт многочисленные эмоции посетителей, что во многом определяло настроение доклада, но уж как есть):
Презентация доклада:
P.S.
Другие доклады в нашем блоге:
Вероятно, вас также заинтересуют следующие публикации:
