Микросервисная архитектура, Spring Cloud и Docker
Привет, Хабр. В этой статье я кратко расскажу о деталях реализации микросервисной архитектуры с использованием инструментов, которые предоставляет Spring Cloud на примере простого концепт-пруф приложения.

Код доступен для ознакомления на гитхабе. Образы опубликованы на докерхабе, весь зоопарк стартует одной командой.
За основу я взял старый забытый проект, бэкенд которого представлял из себя монолит. Приложение позволяет организовать личные финансы: вносить регулярные доходы и расходы, следить за накоплениями, считать статистику и прогнозы.

Попробуем декомпозировать монолит на несколько основных микросервисов, каждый из которых будет отвечать за определенную бизнес-задачу.
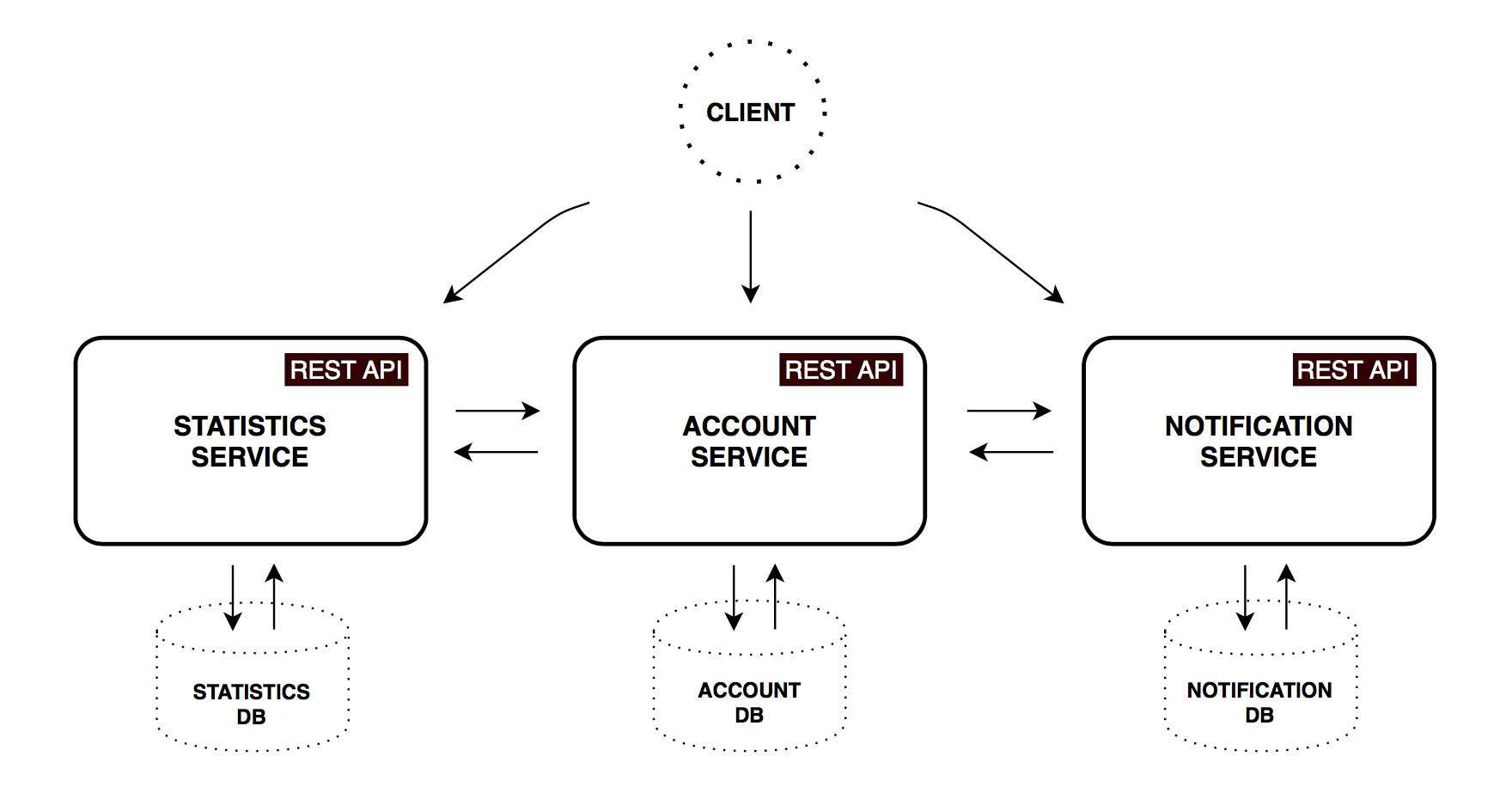
Account service
Реализует логику и валидацию по сохранению доходов, расходов, накоплений и настроек аккаунта.
| Метод | Путь | Описание | Пользователь авторизован | Доступно из UI |
|---|---|---|---|---|
| GET | /accounts/{account} | Получить данные указанного аккаунта | ||
| GET | /accounts/current | Получить данные текущего аккаунта | × | × |
| GET | /accounts/demo | Получить данные демо аккаунта | × | |
| PUT | /accounts/current | Сохранить данные текущего аккаунта | × | × |
| POST | /accounts/ | Зарегистрировать новый аккаунт | × |
Statistics service
Производит расчет основных статистических параметров аккаунта, приводит их значения к базовой валюте и периоду, сохраняет данные в виде, удобном для последующего анализа. Полученный временной ряд будет использован для отображения пользователю статистики и показателей за прошедшее время и экстраполяции для простейших прогнозов на будущее.
| Метод | Путь | Описание | Пользователь авторизован | Доступно из UI |
|---|---|---|---|---|
| GET | /statistics/{account} | Получить статистику указанного аккаунта | ||
| GET | /statistics/current | Получить статистику текущего аккаунта | × | × |
| GET | /statistics/demo | Получить статистику демо аккаунта | × | |
| PUT | /statistics/{account} | Создать/обновить дата-поинт для указанного аккаунта |
Notification service
Хранит настройки уведомлений (частоты напоминаний, периодичность бекапов). По расписанию производит рассылку e-mail сообщений, предварительно собирая и агрегируя нужные данные у первых двух сервисов, если требуется.
| Метод | Путь | Описание | Пользователь авторизован | Доступно из UI |
|---|---|---|---|---|
| GET | /notifications/settings/current | Получить настройки нотификаций для текущего аккаунта |
× | × |
| PUT | /notifications/settings/current | Сохранить настройки нотификаций для текущего аккаунта |
× | × |
Примечания
- Все микросервисы имеют свою собственную БД, соответственно любой доступ к данным можно получить только через API приложения.
- В этом проекте для простоты я использовал только MongoDB как основную БД для каждого из сервисов. На практике может оказаться полезным подход, называемый Polyglot persistence — выбор хранилища, наиболее подходящего для задач конкретного сервиса.
- Коммуникация между сервисами также существенно упрощена: используются только синхронные rest-запросы. Общепринятой практикой является комбинирование различных способов взаимодействия. Например, синхронные GET-запросы для получения информации и асинхронные запросы с использованием сервера очередей — для create/update операций. Что, кстати, переносит нас в мир eventual consistency — один из важных аспектов распределенных систем, с которым приходится жить.
Для обеспечения совместной работы описанных выше сервисов будем использовать набор основных паттернов и практик Микросервисной архитектуры. Многие из них реализованы в Spring Cloud (в частности, посредством интеграции с продуктами Netflix OSS) — на деле это зависимости, расширяющие возможности Spring Boot в ту или иную сторону. Ниже кратко рассмотрен каждый из компонентов.
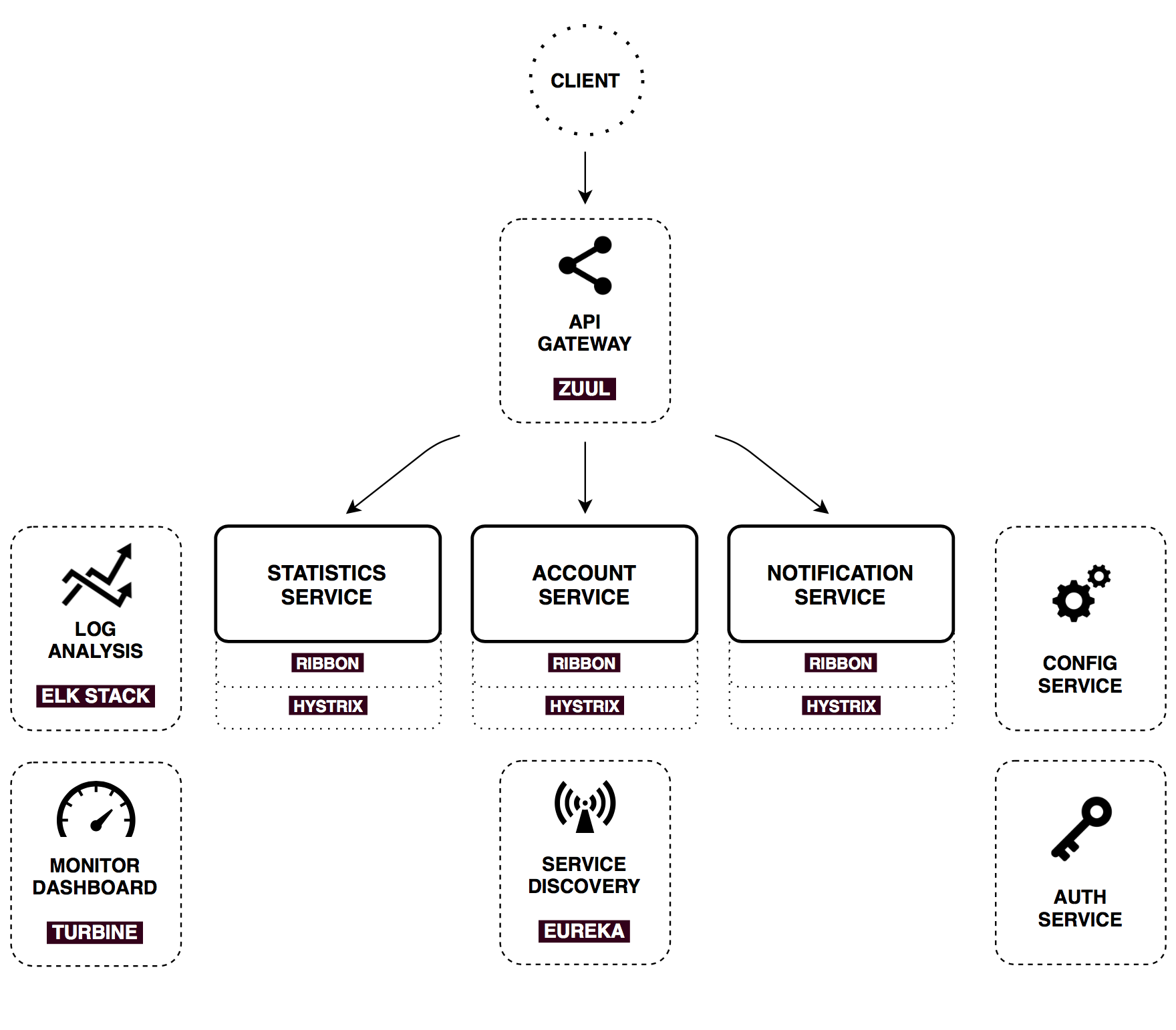
Config Server
Spring Cloud Config — это горизонтально масштабируемое хранилище конфигураций для распределенной системы. В качестве источника данных на данный момент поддерживаются Git, Subversion и простые файлы, хранящиеся локально. По умолчанию Spring Cloud Config отдает файлы, соответствующие имени запрашивающего Spring приложения (но можно забирать проперти под конкретный Spring profile и из определенной ветки системы контроля версий).
На практике наибольший интерес представляет загрузка конфигураций из систем котроля версий, но здесь для простоты будем использовать локальные файлы. Поместим дирректорию shared в класспасе приложения, в которой будут хранится конфигурационные файлы для всех приложений в кластере. Например, если Notification service запросит конфигурацию, Config server ответит ему содержимым файла shared/notification-service.yml, смердженным с shared/application.yml (который является общим для всех).
На стороне клиентского приложения теперь не требуются никаких конфигурационных файлов, кроме bootstrap.yml с именем приложения и адресом Config server:
spring:
application:
name: notification-service
cloud:
config:
uri: http://config:8888
fail-fast: true
Spring Cloud Config позволяет изменять конфигурацию динамически. Например, бин EmailService, помеченный аннотацией @RefreshScope, может начать рассылать измененный текст e-mail сообщения без пересборки.
Для этого следует внести правки в конфигурационный файл Config server, а затем выполнить следующий запрос к Notification service:
`curl -H "Authorization: Bearer #token#" -XPOST http://127.0.0.1:8000/notifications/refresh`
Этот процесс можно автоматизировать, если использовать загрузку конфигураций из систем контроля версий, настроив вебхук из Github, Gitlub или Bitbucket.
Примечания
- К сожалению, есть существенные ограничения на динамическое обновление конфигурации.
@RefreshScopeне работает для@Configurationклассов и методов, отмеченных аннотацией@Scheduled - Свойство
fail-fast, упомянутое вbootstrap.ymlозначает, что приложение остановит загрузку сразу же, если нет соединения с Config Server. Это пригодится нам при одновременном старте всей инфраструктуры. - Продвинутые настройки безопасности выходят за рамки этого концепт-пруф приложения. Spring Security предоставляет широкие возможности для реализации механизмов обеспечения безопасности. Использование JCE keystore для шифрования паролей микросервисов и информации в конфигурационных файлах подробно описаны в документации.
Auth Server
Обязанности по авторизации полностью вынесены в отдельное приложение, которое выдает OAuth2 токены для доступа к ресурсам бэкенда. Auth server используется как для авторизации пользователей, так и для защищенного общения сервис-сервис внутри периметра.
На самом деле, здесь описан только один из возможных подходов. Spring Cloud и Spring Security позволяют достаточно гибко настраивать конфигурацию под ваши нужды (например, имеет смысл проводить авторизацию на стороне API Gateway, а внутрь инфраструктуры передавать запрос с уже заполненными данными пользователя).
В этом проекте я использую Password credential grant type для авторизации пользователей и Client credentials grant type — для авторизации между сервисами.
Spring Cloud Security предоставляет удобные аннотации и автоконфигурацию, что позволяет достаточно просто реализовать описанный функционал как со стороны клиента, так и со стороны авторизационного сервера.
Со стороны клиента это ничем не отличается от традиционной авторизации с помощью сессий. Из запроса можно получить объект Principal, проверить роли и другие параметры с использованием аннотации @PreAuthorize.
Кроме того, каждое OAuth2-приложение имеет scope: для бэкенд-сервисов — server, для браузера — ui. Так мы можем ограничить доступ к некоторым эндпоинтам извне:
@PreAuthorize("#oauth2.hasScope('server')")
@RequestMapping(value = "accounts/{name}", method = RequestMethod.GET)
public List getStatisticsByAccountName(@PathVariable String name) {
return statisticsService.findByAccountName(name);
}
API Gateway
Все три основных сервиса, которые мы обсудили выше, предоставляют для внешнего пользователя некоторый API. В промышленных системах, построенных на Микросервисной архитектуре, число компонентов растет быстро — поговаривают, что в Амазоне в рендеринг страницы вовлечены порядка 150 сервисов.
Гипотетически, клиентское приложение могло бы запрашивать каждый из сервисов самостоятельно. Но такой подход сразу натыкается на массу ограничений — необходимость знать адрес каждого эндпоинта, делать запрос за каждым куском информации отдельно и самостоятельно мерджить результат. Кроме того, не все приложения не бэкенде могут поддерживать дружественные вебу протоколы, и прочее прочее.
Для решения такого рода проблем применяют API Gateway — единую точку входа. Ее используют для приема внешних запросов и маршрутизации в нужные сервисы внутренней инфраструктуры, отдачи статического контента, аутентификации, стресс тестирования, канареечного развертывания, миграции сервисов, динамического управления трафиком. У Netflix если блог-пост об оптимизации своего API за счет асинхронной аггрегации контента из разных микросервисов.
Netflix заопенсорсила свою имплементацию API Gateway — Zuul. Spring Cloud нативно интегрирован с ним и включается добавлением одной зависимости и аннотациии @EnableZuulProxy в Spring Boot приложение. В этом проекте Zuul используется для самых элементарных задач — отдачи статики (веб-приложение) и роутинга запросов.
Пример префиксной маршрутизации для Notification service:
zuul:
routes:
notification-service:
path: /notifications/**
serviceId: notification-service
stripPrefix: false
Теперь каждый запрос, uri которого начинается на /notifications, будет направлен в соответствующий сервис.
Service discovery
Еще один широко известный паттерн для распределенных систем. Service discovery позволяет автоматически определять сетевые адреса для доступных инстансов приложений, которые могут динамически изменяться по причинам масштабирования, падений и обновлений.
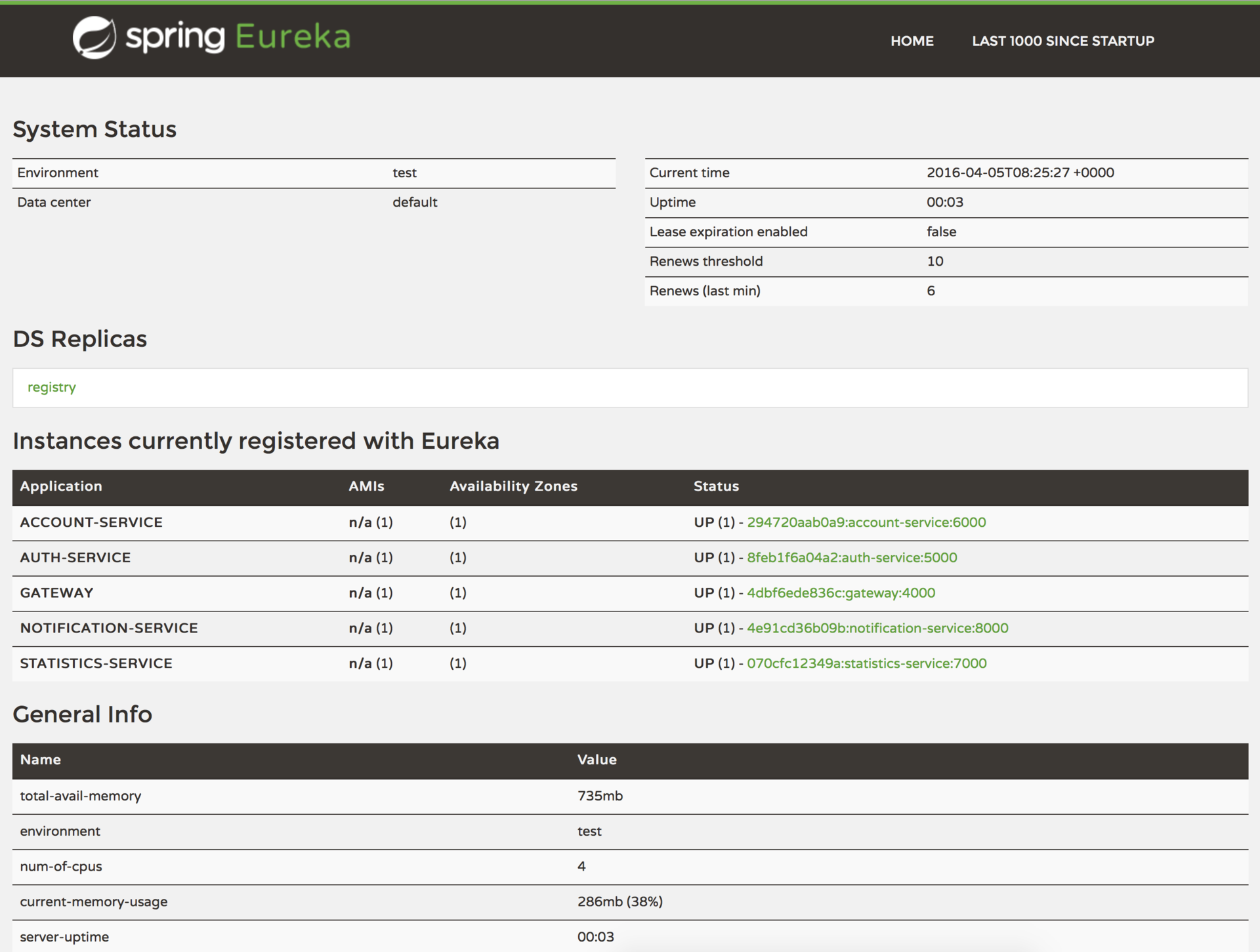
Ключевым звеном здесь является Registry service. В этом проекте я использую Netflix Eureka (но есть еще Consul, Zuukeeper, Etcd и другие). Eureka — пример client-side discovery паттерна, что означает клиент должен запросить адреса доступных инстансов и осуществлять балансировку между ними самостоятельно.
Чтобы превратить Spring Boot приложение в Registry server, достаточно добавить зависимость на spring-cloud-starter-eureka-server и аннотацию @EnableEurekaServer. На стороне клиентов — зависимость spring-cloud-starter-eureka, аннотацию @EnableDiscoveryClient и имя приложения (serviceId) в bootstrap.yml:
spring:
application:
name: notification-service
Теперь инстанс приложения при старте будет регистрироваться в Eureka, предоставляя мета-данные (такие как хост, порт и прочее). Eureka будет принимать хартбит-сообщения, и если их нет в течении сконфигурированного времени — инстанс будет удален из реестра. Кроме того, Eureka предоставляет дашборд, на котором видны зарегистрированные приложения с количеством инстансов и другая техническая информация: http://localhost:8761
Клиентский балансировщик, Предохранитель и Http-клиент
Следующий набор инструментов тоже разработан в Netflix и нативно интегрирован в Spring Cloud. Все они работают совместно и используются в микросервисах, которым нужно общаться с внешним миром или внутренней инфраструктурой.
Ribbon
Ribbon — это client-side балансировщик. По сравнению с традиционным, здесь запросы проходят напрямую по нужному адресу, что исключает лишний узел при вызове. Из коробки он интегрирован с механизмом Service Discovery, который предоставляет динамический список доступных инстансов для балансировки между ними.
Hystrix
Hystrix — это имплементация паттерна Circuit Breaker — предохранителя, который дает контроль над задержками и ошибками при вызовах по сети. Основная идея состоит в том, чтобы остановить каскадный отказ в распределенной системе, состоящей из большого числа компонентов. Это позволяет отдавать ошибку как можно быстрее, не задерживаясь при запросе к зависшему сервису (давая ему восстановится).
Помимо контроля за размыканием цепи, Hystrix позволяет определить fallback-метод, который будет вызван при неуспешном вызове. Тем самым можно отдавать дефолтный ответ, сообщение об ошибке, и др.
На каждый запрос Hystrix генерирует набор метрик (таких как скорость выполнения, результат), что позволяет анализировать общее состоянее системы. Ниже будет рассмотрен мониторинг на основе данных метрик.
Feign
Feign — простой и гибкий http-клиент, который нативно интегрирован с Ribbon и Hystrix. Проще говоря, имея в класспасе зависимость spring-cloud-starter-feign и активировав клиент аннотацией @EnableFeignClients, вы получаете полный набор из балансировщика, предохранителя и клиента, готовый к бою с разумной дефолтной конфигурацией.
Вот пример из Account Service:
@FeignClient(name = "statistics-service")
public interface StatisticsServiceClient {
@RequestMapping(method = RequestMethod.PUT, value = "/statistics/{accountName}", consumes = MediaType.APPLICATION_JSON_UTF8_VALUE)
void updateStatistics(@PathVariable("accountName") String accountName, Account account);
}
- Все что нужно — объявить интерфейс
- Как обычно, мы просто указываем имя сервиса (благодаря механизму Service Discovery), но конечно можно обращаться и к произвольному url
@RequestMappingвместе с содержимым можно оставлять единой для@FeignClientи@Controllerв Spring MVC
Панель мониторинга
Метрики, которые генерит Hystrix, можно отдавать наружу, включив в класспас зависимость spring-boot-starter-actuator. Помимо прочих интересных вещей, будет выставлен специальный эндпоинт — /hystrix.stream. Этот стрим можно визуализировать с помощью Hystrix dashboard, о котором мы подробно поговорим ниже. Для включения Hystrix Dashboard понадобится зависимость spring-cloud-starter-hystrix-dashboard и аннотация @EnableHystrixDashboard. Hystrix Dashboard можно натравить на стрим любого микросервиса для наблюдения живой картины происходящего в этом конкретном сервисе.
Однако в нашем случае сервисов несколько, и было бы здорово видеть все их метрики в одном месте. Для этого существует специальное решение. Каждый из наших сервисов будет пушить свои стримы в AMQP брокер (RabbitMQ), откуда аггрегатор стримов, Turbine, будет преобразовывать их, выставляя единый эндпоинт для Hystrix Dashboard.
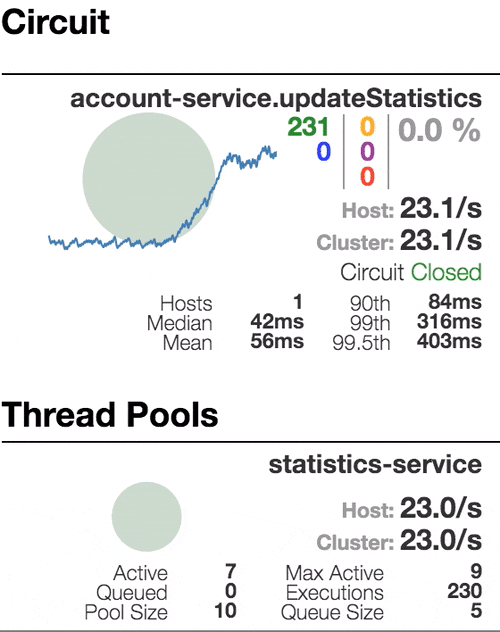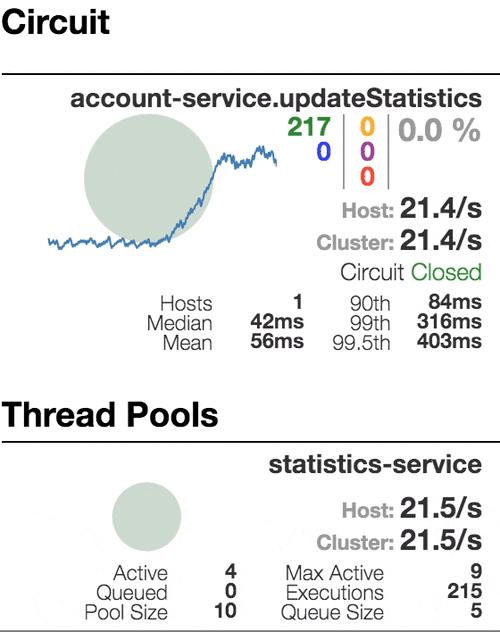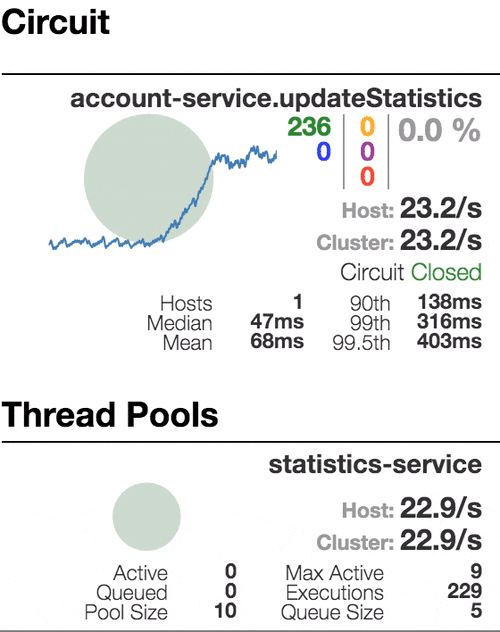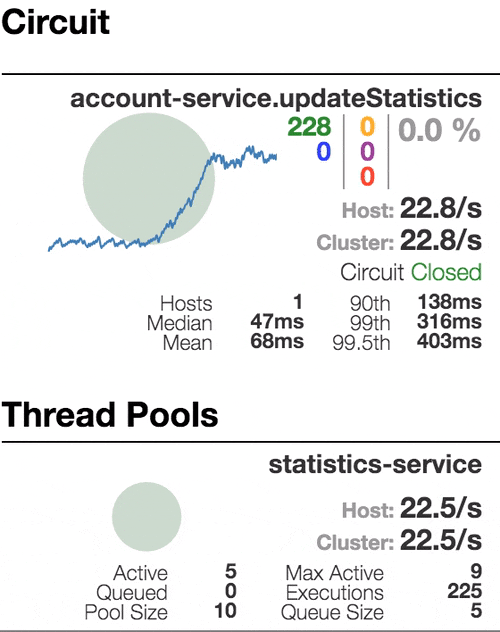
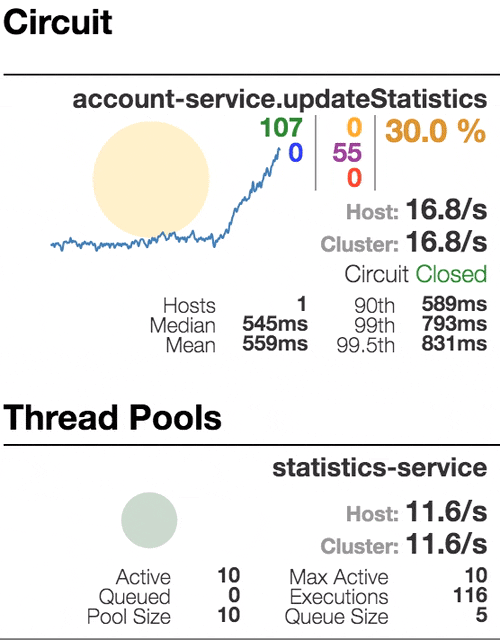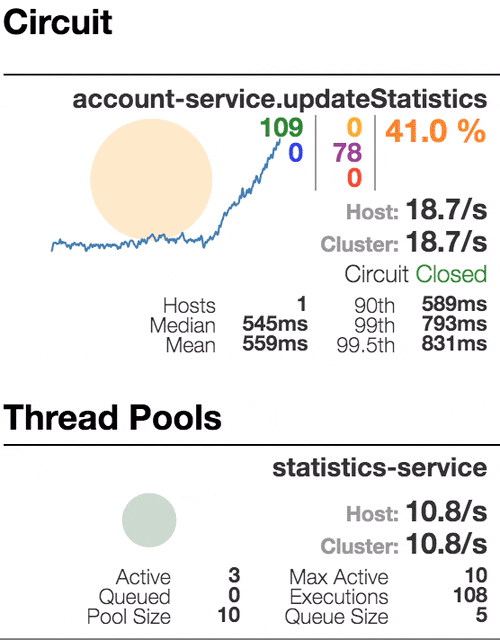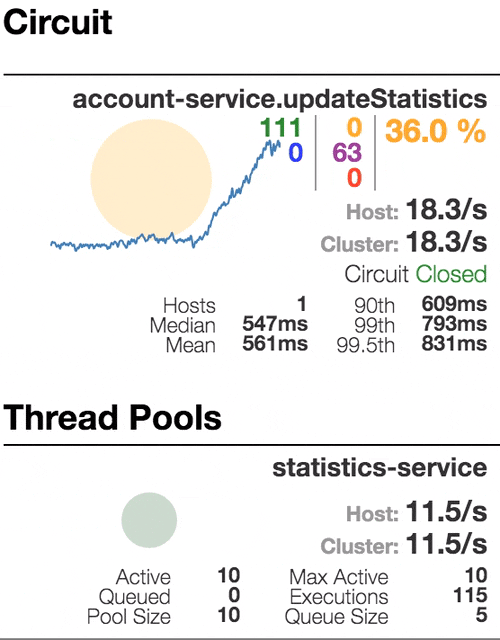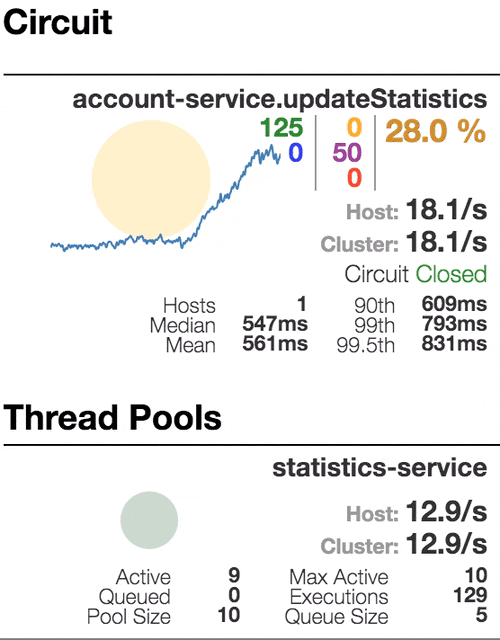
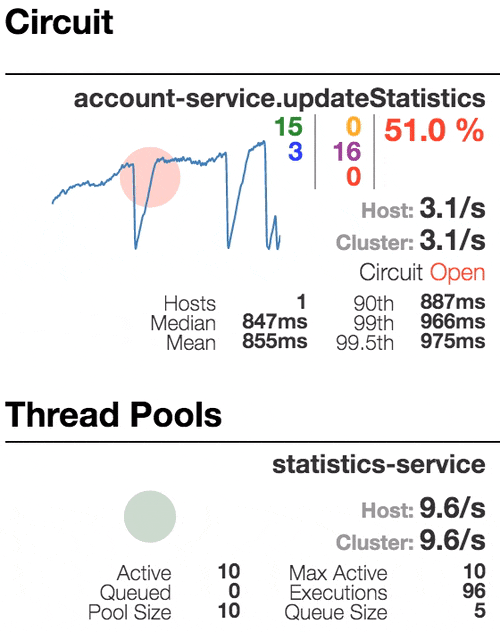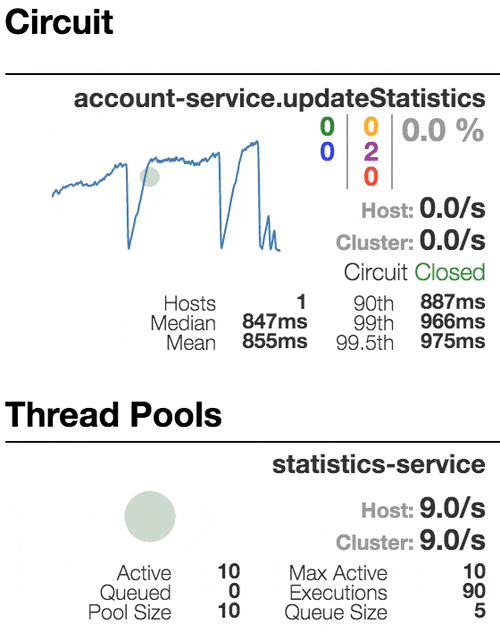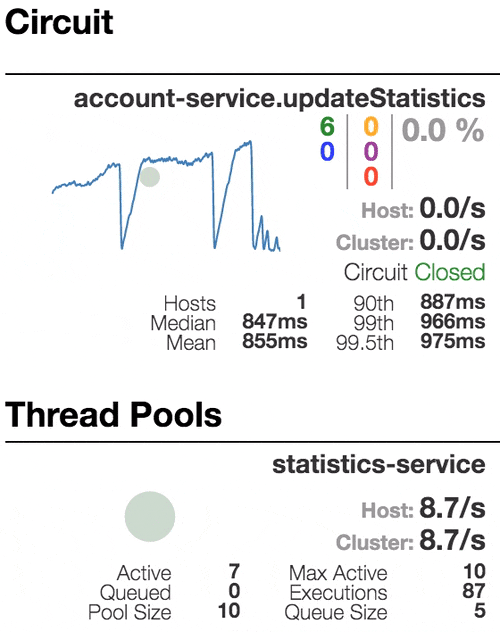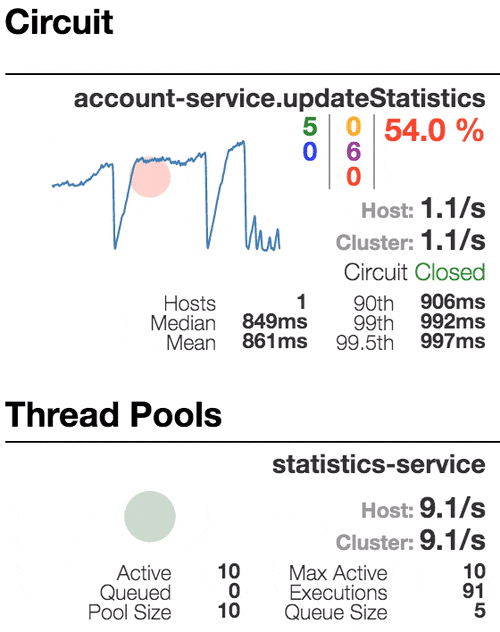
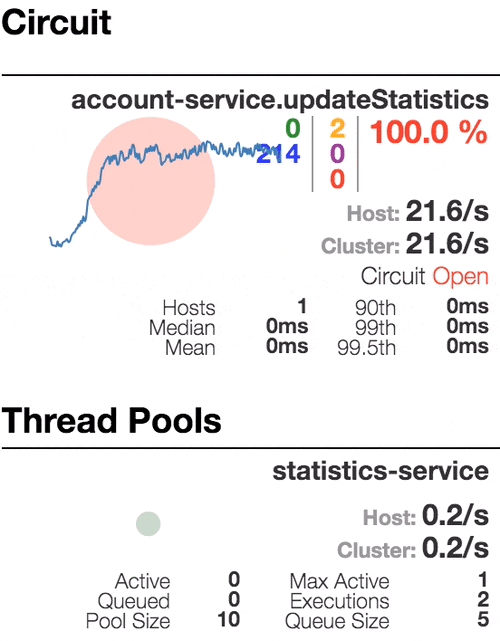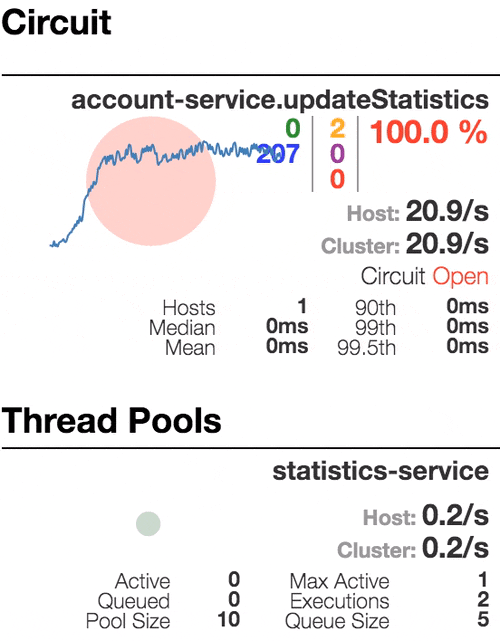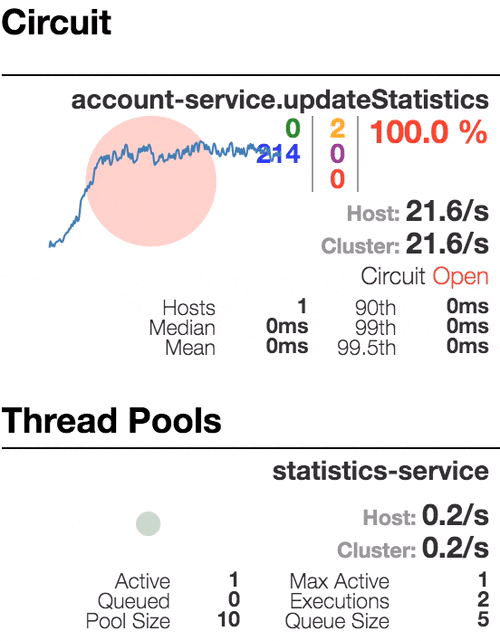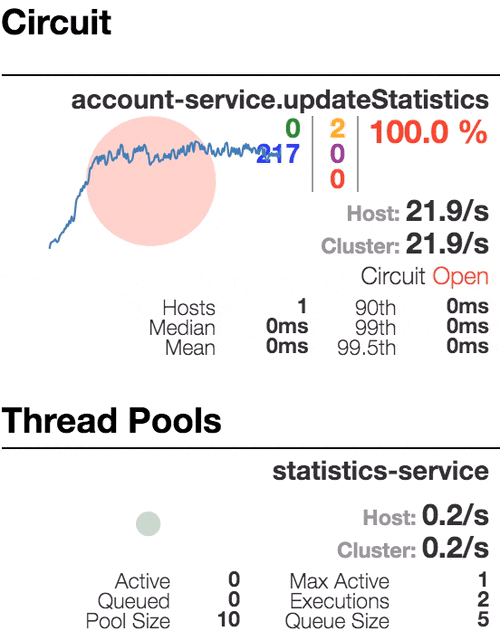
Рассмотрим поведение системы под нагрузкой: Account service вызывает Statistics Service, и тот отвечает с варьируемой имитационной задержкой. Пороговое значение времени запроса установлено в 1 секунду.

 |
 |
 |
 |
|---|---|---|---|
задержка 0 мс |
задержка 500 мс |
задержка 800 мс |
задержка 1100 мс |
| Система работает без ошибок. Пропускная способность порядка 22 з/с. Небольшое число активных потоков в Statistics service. Среднее время получения ответа — 50 мс. |
Число активных потоков увеличивается. Фиолетовая цифра показывает число отклоненных запросов, соответственно порядка 30–40% ошибок, но цепь все еще замкнута. | Полуоткрытое состояние: процент ошибок более 50%, предохранитель размыкает цепь. После определенного таймаута, цепь замыкается, но снова ненадолго. | 100% запросов с ошибками. Цепь разомкнута постоянно, попытки пропустить запрос спустя таймаут ничего не меняют — каждый отдельный запрос слишком медленный. |
В инфраструктуре, состоящей из большого количества движущихся частей (каждая из которых может иметь по нескольку экземпляров), очень важно использовать систему централизированного сбора, обработки и анализа логов. Elasticsearch, Logstash и Kibana составляют стeк, с помощью которого можно эффективно решать такую задачу.
Готовая к запуску Docker-конфигурация ELK с Куратором и шаблонами для шипперов доступна на гитхабе. Именно такая конфигурация, с небольшой кастомизацией и масштабированием, успешно работает в продакшене на моем текущем проекте для анализа логов, сетевой активности и мониторинга производительности серверов.
Картинка с официального сайта Elastic, просто для примера
Развертывание микросервисной системы с большим количеством движущихся частей и взаимосвязанностью — задача очевидно более комплексная, нежели деплой монолитного приложения. Без автоматизированной инфраструктуры вся история превратится в бесконечную боль и трату времени. Это тема для совершенно отдельного разговора, я лишь покажу простейший Сontinuous delivery воркфлоу, реализованный в этом проекте на бесплатных версиях сервисов:
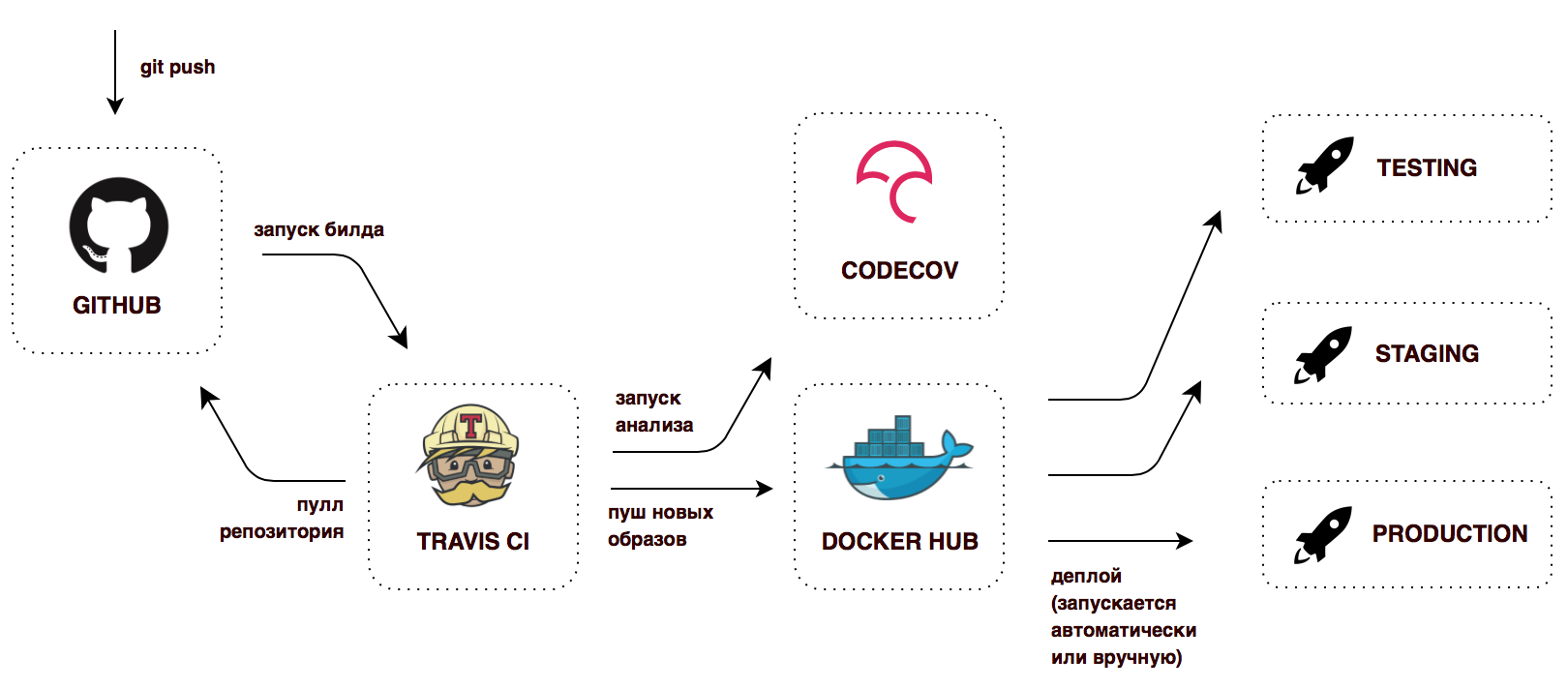
Последний этап — это образно, продакшена для проекта не предполагается.
К корне репозитория находится .travis.yml файл с указаниями для CI сервера — что делать после удачной сборки. В данной конфигурации на каждый успешный пуш в Github, Travis CI соберет докер-образы, пометит их тегом и запушит в Docker Hub. Теперь получается, что у нас всегда есть готовые к деплою контейнеры, помеченные тегом latest, а также контейнеры со старыми версиями, версиями из любых веток.
Запуск
Если вы дочитали до этого места, возможно вам будет интересно запустить все это своими руками. Хочу отметить, что инфраструктура состоит из 8 Spring Boot приложений, 4 инстансов MongoDB и одного RabbitMQ. Убедитесь, что в системе доступны 8 Гб памяти. В ином случае можно запустить систему с ограниченным функционалом (отказаться от Statistics service, Notification Service и Monitoring).
Прежде чем начать
- Установите Docker и Docker Compose
- Экспортируйте переменные окружения:
CONFIG_SERVICE_PASSWORD,NOTIFICATION_SERVICE_PASSWORD,STATISTICS_SERVICE_PASSWORD,ACCOUNT_SERVICE_PASSWORD,MONGODB_PASSWORD
Production mode
В этом режиме все предварительно собранные образы загружаются из центрального репозитория (в данном случае Docker Hub), порты проброшены наружу докера только для API Gateway, Service Discovery, Monitoring и RabbitMQ management. Все что вам понадобится — это docker-compose файл и команда docker-compose up -d.
version: '2'
services:
rabbitmq:
image: rabbitmq:3-management
restart: always
ports:
- 15672:15672
logging:
options:
max-size: "10m"
max-file: "10"
config:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
image: sqshq/piggymetrics-config
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
registry:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
image: sqshq/piggymetrics-registry
restart: always
ports:
- 8761:8761
logging:
options:
max-size: "10m"
max-file: "10"
gateway:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
image: sqshq/piggymetrics-gateway
restart: always
ports:
- 80:4000
logging:
options:
max-size: "10m"
max-file: "10"
auth-service:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
NOTIFICATION_SERVICE_PASSWORD: $NOTIFICATION_SERVICE_PASSWORD
STATISTICS_SERVICE_PASSWORD: $STATISTICS_SERVICE_PASSWORD
ACCOUNT_SERVICE_PASSWORD: $ACCOUNT_SERVICE_PASSWORD
MONGODB_PASSWORD: $MONGODB_PASSWORD
image: sqshq/piggymetrics-auth-service
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
auth-mongodb:
environment:
MONGODB_PASSWORD: $MONGODB_PASSWORD
image: sqshq/piggymetrics-mongodb
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
account-service:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
ACCOUNT_SERVICE_PASSWORD: $ACCOUNT_SERVICE_PASSWORD
MONGODB_PASSWORD: $MONGODB_PASSWORD
image: sqshq/piggymetrics-account-service
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
account-mongodb:
environment:
INIT_DUMP: account-service-dump.js
MONGODB_PASSWORD: $MONGODB_PASSWORD
image: sqshq/piggymetrics-mongodb
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
statistics-service:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
MONGODB_PASSWORD: $MONGODB_PASSWORD
STATISTICS_SERVICE_PASSWORD: $STATISTICS_SERVICE_PASSWORD
image: sqshq/piggymetrics-statistics-service
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
statistics-mongodb:
environment:
MONGODB_PASSWORD: $MONGODB_PASSWORD
image: sqshq/piggymetrics-mongodb
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
notification-service:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
MONGODB_PASSWORD: $MONGODB_PASSWORD
NOTIFICATION_SERVICE_PASSWORD: $NOTIFICATION_SERVICE_PASSWORD
image: sqshq/piggymetrics-notification-service
restart: always
logging:
options:
max-size: "10m"
max-file: "10"
notification-mongodb:
image: sqshq/piggymetrics-mongodb
restart: always
environment:
MONGODB_PASSWORD: $MONGODB_PASSWORD
logging:
options:
max-size: "10m"
max-file: "10"
monitoring:
environment:
CONFIG_SERVICE_PASSWORD: $CONFIG_SERVICE_PASSWORD
image: sqshq/piggymetrics-monitoring
restart: always
ports:
- 9000:8080
- 8989:8989
logging:
options:
max-size: "10m"
max-file: "10"
Development mode
В режиме разработки предполагается строить образы, а не забирать их из репозитория. Все контейнеры выставлены наружу для удобного дебага. Эта конфигурация наследуется от приведенной выше, перезаписывая и расширяя указанные моменты. Запускается командой docker-compose -f docker-compose.yml -f docker-compose.dev.yml up -d
version: '2'
services:
rabbitmq:
ports:
- 5672:5672
config:
build: config
ports:
- 8888:8888
registry:
build: registry
gateway:
build: gateway
auth-service:
build: auth-service
ports:
- 5000:5000
auth-mongodb:
build: mongodb
ports:
- 25000:27017
account-service:
build: account-service
ports:
- 6000:6000
account-mongodb:
build: mongodb
ports:
- 26000:27017
statistics-service:
build: statistics-service
ports:
- 7000:7000
statistics-mongodb:
build: mongodb
ports:
- 27000:27017
notification-service:
build: notification-service
ports:
- 8000:8000
notification-mongodb:
build: mongodb
ports:
- 28000:27017
monitoring:
build: monitoring
Примечания
Всем Spring Boot приложениям в этом проекте для старта необходим доступный Config Server. Благодаря опции fail-fast в bootstrap.yml каждого приложения и опции restart: always в докере, контейнеры можно запускать одновременно (они будут автоматически продолжать попытки старта, пока не поднимется Config Server).
Механизм Service Discovery так же требует некоторого времени для начала полноценной работы. Сервис не доступен для вызова, пока он сам, Eureka и клиент не имеют одну и ту же мета-информацию у себя локально — на это требуется 3 хартбита. По умолчанию период времени между хартбитами составляет 30 секунд.
Ссылки по теме
- Статьи о микросервисах Мартина Фаулера
- Building Microservices Сэма Ньюмана — книга, в деталях охватывающая все основные понятия Микросервисной архитектуры
- Целая брошюра с описанием отличий Микросервисов и SOA
- Серия статей о Микросервисах в блоге NGINX от Криса Ричардсона, основателя CloudFoundry
- Очень крутой и подробный доклад Кирилла Толкачёва tolkkv и Александра Тарасова aatarasoff из Альфа-Лаборатории, в двух частях. О микросервисах, Spring Boot, Spring Cloud, инструментах Netflix OSS, Apache Thrift и многом другом.
