Миграция с Mongo на Postgres: опыт газеты The Guardian

The Guardian — одна из крупнейших британских газет, она основана в 1821 году. За без малого 200 лет существования архив накопился изрядный. По счастью, далеко не весь он хранится на сайте — всего за какие-то последние пару десятков лет. В базе данных, которую сами англичане назвали «источником истины» для всего онлайн-контента, около 2,3 млн элементов. И в один прекрасный момент они осознали необходимость миграции с Mongo на Postgres SQL — после того, как одним жарким июльским днём в 2015 году процедуры аварийного переключения были подвергнуты суровому испытанию. Миграция заняла без малого 3 года!…
Мы перевели статью, в которой рассказывается, как проходил процесс миграции и с какими сложностями столкнулись администраторы. Процесс долгий, но резюме простое: приступая к большой задаче, смиритесь, что ошибки будут обязательно. Но в конечном итоге, 3 года спустя, британским коллегам удалось отпраздновать окончание миграции. И поспать.
Часть первая: начало
В Guardian большая часть контента, включая статьи, блоги, фотогалереи и видео, производится внутри нашей собственной CMS — Composer. До недавнего времени Composer взаимодействовал с Mongo DB, работающей на платформе AWS. Эта БД по существу была «источником истины» для всего онлайн контента Guardian — около 2,3 млн элементов. И мы только что завершили миграцию с Mongo на Postgres SQL.
Composer и его БД первоначально размещались в Guardian Cloud — ЦОД в подвале нашего офиса недалеко от Кингс-Кросс, с аварийным переключением в другом месте в Лондоне. Одним жарким июльским днем в 2015 году наши процедуры аварийного переключения были подвергнуты довольно суровому испытанию.

Жара: хороша для танцев у фонтана, губительна для ЦОД. Фотография: Сара Ли / Guardian
После этого миграция Guardian на AWS стала вопросом жизни и смерти. Для миграции в облако мы решили приобрести OpsManager, программное обеспечение для управления Mongo DB, и подписали контракт на техподдержку Mongo. Мы использовали OpsManager для управления резервными копиями, оркестрации и мониторинга нашего кластера БД.
Из-за редакционных требований нам нужно было запустить кластер БД и OpsManager на нашей собственной инфраструктуре в AWS, а не использовать managed-решение Mongo. Нам пришлось попотеть, так как Mongo не предоставлял никаких инструментов для легкой настройки на AWS: мы вручную оформляли всю инфраструктуру и написали сотни скрпитов Ruby для установки агентов мониторинга/автоматизации и оркестрации новых экземпляров БД. В итоге нам пришлось организовать в команде сеансы ликбеза об управлении БД — то, что мы надеялись, OpsManager возьмёт на себя.
С момента перехода на AWS у нас было два существенных сбоя из-за проблем с БД, каждый из которых не давал сделать публикацию на сайте theguardian.com по крайней мере в течение часа. В обоих случаях ни OpsManager, ни сотрудники техподдержки Mongo не смогли оказать нам достаточную помощь, и мы решили проблему сами — в одном случае благодаря члену нашей команды, который сумел разобраться с ситуацией по телефону из пустыни на окраине Абу-Даби.
Каждый из проблемных вопросов заслуживает отдельного поста, но вот общие моменты:
- Обращайте пристальное внимание на время — не блокируйте доступ к своему VPC до такой степени, чтобы NTP перестал работать.
- Автоматическое создание индексов БД при запуске приложения — плохая идея.
- Управление БД крайне важно и трудно — и мы не хотели бы делать это сами.
OpsManager не сдержал свои обещания о простом управлении БД. Например, фактическое управление самим OpsManager — в частности, обновление с OpsManager версии 1 до версии 2 — потребовало много времени и специальных знаний о нашей настройке OpsManager. Он также не выполнил свое обещание «обновления одним щелчком мыши» из-за изменений в схеме аутентификации между различными версиями Mongo DB. Мы теряли по крайней мере два месяца времени инженеров в год на управление БД.
Все эти проблемы, в сочетании со значительной годовой платой, которую мы платили за контракт на поддержку и OpsManager, заставили нас искать альтернативный вариант БД со следующими характеристиками:
- Минимальные усилия на управление БД.
- Шифрование в состоянии покоя.
- Приемлемый путь миграции с Mongo.
Поскольку все остальные наши сервисы работают в AWS, очевидным выбором стал Dynamo — база данных NoSQL от Amazon. К сожалению, в то время Dynamo не поддерживала шифрование данных в состоянии покоя (encryption at rest). Прождав около девяти месяцев, пока эта функция будет добавлена, мы в конечном итоге бросили эту идею, решив использовать Postgres на AWS RDS.
«Но Postgres — это не хранилище документов!» — возмутитесь вы… Ну да, это не хранилище доков, но у него есть таблицы, сходные столбцам JSONB, с поддержкой индексов в полях инструмента JSON Blob. Мы надеялись, что, используя JSONB, мы сможем мигрировать с Mongo на Postgres с минимальными изменениями в нашей модели данных. Кроме того, если бы мы хотели перейти к более реляционной модели в будущем, у нас была бы такая возможность. Еще одна замечательная вещь в Postgres — это то, насколько он отработан: на каждый вопрос, который у нас возникал, в большинстве случаев уже был дан ответ в Stack Overflow.
С точки зрения производительности мы были уверены, что Postgres справится: Composer — это инструмент исключительно для записи контента (запись в БД он делает каждый раз, когда журналист перестает печатать), и обычно количество одновременных пользователей не превышает несколько сотен — что не требует от системы сверхвысоких мощностей!
Часть вторая: миграция контента двух десятилетий прошла без простоев
План
Большинство миграций БД подразумевает одни и те же действия, и наша не стала исключением. Вот что мы сделали:
- Создали новую базу данных.
- Создали способ записи в новую БД (новый API).
- Создали прокси-сервер, который отправляет трафик как в старую, так и в новую БД, используя старую в качестве основной.
- Перенесли записи из старой БД в новую.
- Сделали новую БД основной.
- Удалили старую БД.
Учитывая, что БД, на которую мы мигрировали, обеспечивала функционирование нашей CMS, было критически важно, чтобы миграция вызвала как можно меньше неполадок в работе для наших журналистов. В конце концов, новости никогда не заканчиваются.
Новый API
Работа над новым API на основе Postgres началась в конце июля 2017 года. Это стало началом нашего путешествия. Но чтобы понять, каким оно было, надо сначала разъяснить, откуда мы стартовали.
Наша упрощенная архитектура CMS была примерно такой: база данных, API и несколько приложений, связанных с ней (например, пользовательский интерфейс). Стек был построен и вот уже 4 года функционирует на основе Scala, Scalatra Framework и Angular.js.
После некоторого анализа мы пришли к выводу, что, прежде чем мы сможем перенести существующий контент, нам нужен способ связываться с новой БД PostgreSQL, поддерживая старый API в рабочем состоянии. В конце концов, Mongo DB это наш «источник истины». Она служила нам спасательным кругом, пока мы экспериментировали с новым API.
Это одна из причин, почему построение поверх старого API не входило в наши планы. Разделение функций в исходном API было минимальным, а специфичные методы, необходимые для работы именно с Mongo DB, можно было найти даже на уровне контроллеров. В результате задача по добавлению БД другого типа в существующий API была слишком рискованной.
Мы пошли по другому пути и продублировали старый API. Так родился APIV2. Это была более или менее точная копия старого API, связанного с Mongo, и включала те же конечные точки и функциональность. Мы использовали doobie, чистый функциональный слой JDBC для Scala, добавили Docker для локального запуска и тестирования, а также улучшили ведение журнала операций и разделение ответственностей. APIV2 должен был стать быстрой и современной версией API.
К концу августа 2017 года у нас был развернут новый API, который использовал PostgreSQL в качестве своей базы данных. Но это было только начало. Есть статьи в Mongo DB, которые были впервые созданы более двух десятилетий назад, и все они должны были мигрировать в БД Postgres.
Миграция
Мы должны иметь возможность редактировать любую статью на сайте, независимо от того, когда она была опубликована, поэтому все статьи существуют в нашей БД как единый «источник истины».
Хотя все статьи живут в Guardian«s Content API (CAPI), который обслуживает приложения и сайт, для нас было крайне важно осуществить миграцию без каких-либо сбоев, так как наша БД — наш «источник истины». Если бы что-то случилось с кластером Elasticsearch CAPI, мы бы переиндексировали его из базы данных Composer.
Поэтому, прежде чем отключить Mongo, мы должны были убедиться, что один и тот же запрос на API, работающем на Postgres, и на API, работающем на Mongo, вернет идентичные ответы.
Для этого нам нужно было скопировать весь контент в новую БД Postgres. Это было сделано с помощью скрипта, который напрямую взаимодействовал со старым и новым API. Преимущество этого способа состояло в том, что оба API уже предоставляли собой хорошо протестированный интерфейс для чтения и записи статей в базах данных и из них, в отличие от написания чего-то, что напрямую обращалось к соответствующим базам данных.
Основной порядок миграции был следующим:
- Получить контент из Mongo.
- Опубликовать контент в Postgres.
- Получить контент из Postgres.
- Убедиться, что ответы из них идентичны.
Миграцию БД можно считать успешной, только если конечные пользователи не заметили, что это произошло, и хороший скрипт миграции всегда будет залогом такого успеха. Нам нужен был скрипт, который мог бы:
- Выполнить HTTP-запросы.
- Гарантировать, что после миграции части контента ответ обоих API совпадает.
- Остановиться при возникновении ошибки.
- Создать подробный журнал операций для диагностики проблем.
- Перезапуститься после ошибки с правильной точки.
Мы начали с использования Ammonite. Он позволяет писать скрипты на языке Scala, который является основным в нашей команде. Это была хорошая возможность поэкспериментировать с тем, что мы раньше не использовали, чтобы увидеть, будет ли это полезно для нас. Хотя Ammonite позволил использовать знакомый нам язык, в работе на нем мы обнаружили несколько недостатков. Сейчас Intellij поддерживает Ammonite, но во время нашей миграции он этого не делал — и мы потеряли автодополнение и автоимпортирование. Кроме того, в течение длительного периода времени не удавалось запустить скрипт Ammonite.
В конечном счете, Ammonite не был подходящим инструментом для этой работы, и вместо него мы использовали проект на sbt для выполнения миграции. Это позволило нам работать на языке, в котором мы были уверены, а также выполнить несколько 'тестовых миграций' до запуска в основном рабочем окружении.
Неожиданным было то, насколько полезным он оказался при проверке версии API, работающей на Postgres. Мы нашли несколько труднонаходимых ошибок и предельных случаев, которые мы не обнаружили ранее.
Перенесемся в январь 2018 года, когда пришло время протестировать полномасштабную миграцию в нашей пре-прод среде CODE.
Подобно большинству наших систем, единственное сходство между CODE и PROD — это версия запускаемого приложения. Инфраструктура AWS, поддерживающая среду CODE, была гораздо менее мощной, чем PROD, просто потому, что она получает гораздо меньше нагрузки.
Мы надеялись, что тестовая миграция в среде CODE поможет нам:
- Оценить, сколько времени займет миграция в среде PROD.
- Оценить, как (если вообще) отразится миграция на производительности.
Для того чтобы получить точные измерения этих показателей, мы должны были привести две среды в полное взаимное соответствие. Это включало восстановление резервной копии Mongo DB из PROD в CODE и обновление инфраструктуры, поддерживаемой AWS.
Миграция чуть более 2 млн элементов данных должна была занять гораздо больше времени, чем позволял стандартный рабочий день. Поэтому мы запустили скрипт в screen на ночь.
Чтобы замерять ход миграции, мы отправляли структурированные запросы (используя маркеры) в наш стек ELK (Elasticsearch, Logstash и Kibana). Оттуда мы могли создавать подробные панели мониторинга, отслеживая количество успешно перенесенных статей, количество сбоев и общий прогресс. Кроме того, все показатели выводились на большой экран, чтобы вся команда видела детали.
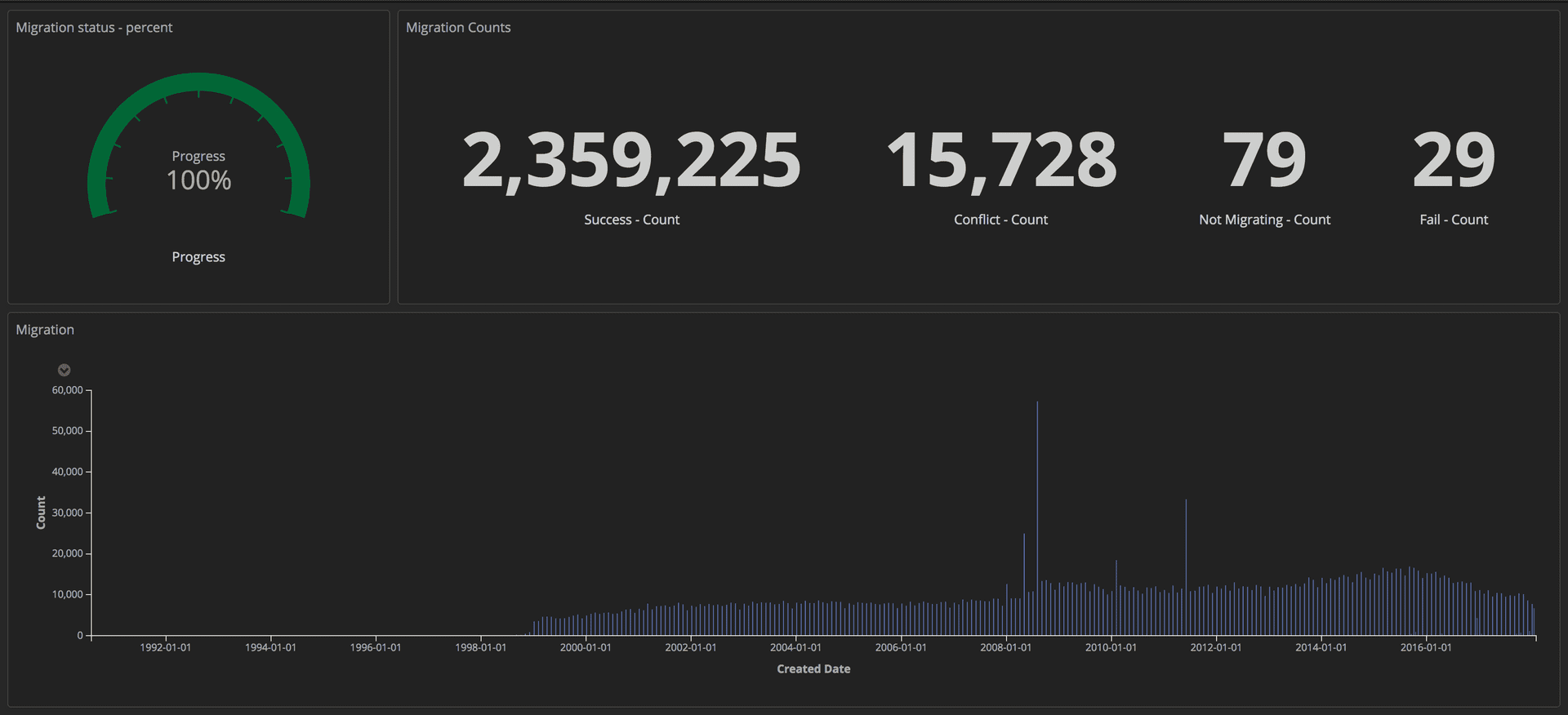
Панель мониторинга, показывающая ход выполнения миграции: Редакционные Инструменты / Guardian
Как только миграция была завершена, мы проверили совпадение каждого документа в Postgres и в Mongo.
Часть третья: Прокси и запуск на проде
Прокси
Теперь, когда новый API, работающий на Postgres, был запущен, нам нужно было протестировать его реальным трафиком и шаблонами доступа к данным, чтобы убедиться в его надежности и стабильности. Было два возможных способа это сделать: обновить каждого клиента, который обращается к API Mongo, чтобы тот обращался к обоим API; или запустить прокси, который сделает это за нас. Мы написали прокси на Scala, используя Akka Streams.
Работа прокси была достаточно проста:
- Принимать трафик от подсистемы балансировки нагрузки.
- Перенаправлять трафик в основной API и обратно.
- Асинхронно пересылать тот же трафик на дополнительный API.
- Вычислять расхождения между двумя ответами и фиксировать их в журнал.
Вначале прокси регистрировал много расхождений, включая некоторые труднонаходимые, но важные поведенческие различия в двух API, которые необходимо было исправить.
Структурированное ведение журнала
В Guardian мы ведем журнал, используя стек ELK (Elasticsearch, Logstash и Kibana). Использование Kibana дало нам возможность визуализировать журнал самым удобным для нас способом. Kibana использует синтаксис запросов Lucene, который довольно просто освоить. Но вскоре мы поняли, что отфильтровать или сгруппировать журнальные записи в текущей настройке было невозможно. Например, мы не смогли отфильтровать те, что были отправлены в результате GET запросов.
Мы решили отправлять в Kibana более структурированные данные, а не просто сообщения. Одна запись журнала содержит несколько полей, например, метку времени и имя стека или приложения, отправившего запрос. Добавлять новые поля очень легко. Эти структурированные поля называются маркерами и могут быть реализованы с помощью библиотеки logstash-logback-encoder. Для каждого запроса мы извлекали полезную информацию (например, маршрут, метод, код состояния) и создавали карту с дополнительной информацией, необходимой для журнала. Вот пример:
import akka.http.scaladsl.model.HttpRequest
import ch.qos.logback.classic.{Logger => LogbackLogger}
import net.logstash.logback.marker.Markers
import org.slf4j.{LoggerFactory, Logger => SLFLogger}
import scala.collection.JavaConverters._
object Logging {
val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger]
private def setMarkers (request: HttpRequest) = {
val markers = Map (
«path» → request.uri.path.toString (),
«method» → request.method.value
)
Markers.appendEntries (markers.asJava)
}
def infoWithMarkers (message: String, akkaRequest: HttpRequest) =
rootLogger.info (setMarkers (akkaRequest), message)
}
Дополнительные поля в наших журналах позволили нам создать информативные панели мониторинга и добавлять больше контекста касательно расхождений, что помогло нам выявить некоторые незначительные несоответствия между двумя API.
Репликация трафика и рефакторинг прокси
После переноса содержимого в БД CODE мы получили почти точную копию БД PROD. Главное отличие состояло в том, что CODE не имел трафика. Для репликации реального трафика в среду CODE мы использовали инструмент с открытым исходным кодом GoReplay (дальше — gor). Он очень легок в установке и гибок в настройке под ваши требования.
Поскольку весь трафик, поступавший в наши API, сначала попадал на прокси, имело смысл установить gor на прокси-контейнеры. Смотрите ниже, как загрузить gor в свой контейнер и как начать отслеживать трафик на 80-м порту и отправлять его на другой сервер.
с wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz
tar -xzf gor_0.16.0_x64.tar.gz gor
sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
Некоторое время все работало нормально, но очень скоро произошел сбой в работе, когда прокси стал недоступен в течение нескольких минут. При анализе мы обнаружили что все три прокси-контейнера периодически зависали в одно и то же время. Сначала мы думали, что прокси-сервер падал из-за того, что gor использовал слишком много ресурсов. При дальнейшем анализе консоли AWS мы обнаружили, что прокси-контейнеры зависали регулярно, но не одновременно.
Прежде чем углубляться в проблему дальше, мы попытались найти способ запустить gor, но на этот раз без дополнительной нагрузки на прокси. Решение пришло из нашего вторичного стека для Composer. Этот стек используется только в случае аварийной ситуации, а наш инструмент рабочего мониторинга постоянно его тестирует. На этот раз воспроизведение трафика из этого стека в CODE с удвоенной скоростью сработало без каких-либо проблем.
Новые выводы вызвали много вопросов. Прокси был построен как временный инструмент, поэтому он, возможно, не был так тщательно разработан, как другие приложения. Кроме того, он был построен с использованием Akka Http, с которым никто из нашей команды не был знаком. Код был сумбурным и полным быстрофиксов. Мы решили начать большую работу по рефакторингу, чтобы улучшить читаемость. На этот раз мы использовали for-генераторы вместо растущей вложенной логики, которую мы применяли прежде. И добавили еще больше маркеров ведения журнала.
Мы надеялись, что сможем предотвратить зависание прокси-контейнеров, если детально вникнем в происходящее внутри системы и упростим логику её работы. Но это не сработало. После двух недель попыток сделать прокси более надежным мы почувствовали себя в ловушке. Нужно было принять решение. Мы решили пойти на риск и оставить прокси как есть, так как лучше потратить время на саму миграцию, чем пытаться исправить часть программного обеспечения, которая станет ненужной через месяц. Мы заплатили за это решение еще двумя сбоями — почти по две минуты каждый, —, но это нужно было сделать.
Перенесемся в март 2018 года, когда мы уже закончили миграцию в CODE без ущерба для производительности API или клиентского опыта в CMS. Теперь мы могли начать думать о списании прокси из CODE.
Первый этап состоял в том, чтобы изменить приоритеты API, так чтобы прокси сначала взаимодействовала с Postgres. Как мы говорили выше, это решалось изменением в настройках. Однако была одна сложность.
Composer отправляет сообщения в поток Kinesis после обновления документа. Только один API должен был отправлять сообщения, чтобы предотвратить дублирование. Для этого API имеют флаг в конфигурации: true для API, поддерживаемого Mongo, и false — для поддерживаемого Postgres. Просто изменить прокси, чтобы он сначала взаимодействовал с Postgres, было недостаточно, так как сообщение не было бы отправлено в поток Kinesis, пока запрос не достиг Mongo. Это было слишком долго.
Чтобы решить эту проблему, мы создали конечные точки HTTP для мгновенного изменения конфигурации всех экземпляров подсистемы балансировки нагрузки на лету. Это позволило нам очень быстро подключать основной API без необходимости редактирования файла конфигурации и повторного развертывания. Кроме того, это можно автоматизировать, тем самым сократив человеческое взаимодействие и вероятность ошибок.
Теперь все запросы сначала отправлялись в Postgres, а API2 взаимодействовал с Kinesis. Замену можно было сделать постоянной с путем изменения конфигурации и перевыкладки.
Следующий этап состоял в том, чтобы полностью удалить прокси и заставить клиентов обращаться исключительно к API Postgres. Поскольку клиентов у нас много, обновление каждого из них по отдельности не было возможным. Поэтому мы подняли эту задачу до уровня DNS. То есть, мы создали CNAME в DNS, который сначала указывал на ELB прокси и изменялся бы, чтобы указывать на ELB API. Это позволило внести всего одно изменение вместо внесения обновлений каждого отдельного клиента API.
Пришло время перенести PROD. Хотя было и немного страшно, ну потому что это основная рабочая среда. Процесс был относительно прост, так как все решалось изменением настроек. К тому же, по мере добавления маркера этапа в журналы стало возможным перепрофилировать ранее построенные панели мониторинга, просто обновив фильтр Kibana.
Отключение прокси и Mongo DB
Спустя 10 месяцев и 2.4 млн перенесенных статей, мы были, наконец, в состоянии отключить всю инфраструктуру, связанную с Mongo. Но сначала нужно было сделать то, чего мы все ждали: убить прокси.
Логи, показывающие отключение Flexible API Proxy. Фотография: Редакционные Инструменты / Guardian
Эта небольшая часть программного обеспечения вызвала у нас так много проблем, что мы жаждали поскорее ее отключить! Все, что нам нужно было сделать, — это обновить запись CNAME, чтобы она указывала непосредственно на подсистему балансировки нагрузки APIV2.
Вся команда собралась вокруг одного компьютера. Нужно было совершить лишь одно нажатие клавиши. Дыхание затаили все! Полная тишина… Клик! Дело сделано. И ничего не слетело! Мы все радостно выдохнули.
Однако удаление старого API Mongo DB таило еще одно испытание. Отчаянно удаляя старый код, мы обнаружили, что наши интеграционные тесты никогда не корректировались для использования нового API. Все быстро стало красным. К счастью, большинство проблем были связаны с конфигурацией и мы легко их исправили. Было несколько проблем с запросами PostgreSQL, которые были пойманы тестами. Задумываясь о том, что можно было бы сделать, чтобы избежать этой ошибки, мы вынесли один урок: приступая к большой задаче, смиритесь, что ошибки будут обязательно.
После этого всё работало гладко. Мы отсоединили все экземпляры Mongo от OpsManager, а затем и отключили их. Единственное, что оставалось сделать — это отпраздновать. И поспать.
