Метод Binoculars обещает высокую точность обнаружения текста от больших языковых моделей

ChatGPT пишет не хуже человека, но можно ли обнаружить «машинность» в тексте? Хотя некоторым компаниям было бы выгоднее представить всё так, будто результат работы языковых моделей неотличим от человеческого, исследования в этом направлении активно ведутся. Авторы научной статьи «Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text» (arXiv:2401.12070) утверждают, что их метод имеет низкий уровень ложноположительных срабатываний (0,01%), правильно обнаруживает текст от языковых моделей в 90% случаев и работает для нескольких семейств современных продуктов.
Люди и черви
Диапазон поведения больших языковых моделей широк. Это значительно осложняет создание инструмента для обнаружения текста, сгенерированного БЯМ. Считается даже, будто это невозможно.
Практическую ценность такого инструмента сложно недооценить — он чрезвычайно необходим для направления снижения вреда от искусственного интеллекта. Прикладные цели разнообразны, но в связи с распространением БЯМ на трансформерах все они затруднены.
К примеру, затруднена борьба с фальшивыми новостями, спамом и другим сгенерированным контентом. Толпа ботов в комментариях — это не что-то из отдалённой научной фантастики: на такое уже жалуются. Под твитом с новостью про закрытие всех границ Финляндии внезапно появляется кучка одобрительных, но явно написанных БЯМ комментариев.
Поделать с этим ничего нельзя. В одной из научных статей (arXiv:1905.12616) было показано, что опознать фальшивую новость от машины и настоящую новостную статью от человека получалось с точностью в лишь 73%. Статья датируется 2019 годом, и с тех пор языковые модели лишь продолжали улучшаться.
Также очевидно, что детектор БЯМ крайне необходим для поиска плагиата и мошенничества в академической среде. Под этим понимают также выяснение изначального источника текста. Но и здесь обнаружить следы даже не самых технически совершенных языковых моделей тяжело, если вообще возможно.
Как было показано в 2022 году (arXiv:2201.07406), учащийся, вооружённый открытой GPT-J (6 млрд параметров), без проблем может обмануть систему антиплагиата MOSS. Хотя GPT-J не обучен для таких задач, он пишет такой код для начального курса по программированию, который не вызывает подозрений у MOSS. Программный код, который пишет GPT-J, разнообразен в структуре и не имеет характерных признаков, по которым легко указать на использование БЯМ.
Если детектор работает с излишним «энтузиазмом», это тоже плохо. В одном из экспериментов (arXiv:2304.02819) было показано, что коммерческие детекторы GPT ошибочно помечают сочинения экзаменующихся по тесту на знание английского языка TOEFL как продукт БЯМ. Виной тому выступают данные, на которых эти инструменты обучались и оценивались: о не носителях языка никто не задумывался.
Кажется, детектировать текст от ИИ не может никто. Даже OpenAI, лидер направления текстовых ботов на трансфомерах, закрыла свой инструмент обнаружения текстов от БЯМ. Компания сделала это в июле 2023 года без объявления, никак не комментируя свою неудачу.
В сентябре СМИ обнаружили, что OpenAI расписалась в собственной беспомощности в этом вопросе. В разделе вопросов и ответов для образовательных нужд в одной из статей компания прямо признаёт: детекторы ИИ не работают. Как пишет OpenAI, собственные исследования организации показали ненадёжность подобных инструментов. В этом же абзаце компания предупреждает, что никак не ручается за точность сторонних детекторов ИИ.
Впрочем, OpenAI сейчас получает основной доход и инвестиции за счёт ChatGPT и DALL-E, а не от раздумий об опасности от искусственного интеллекта. Зачем пугать венчурный капитал разговорами про вред языковых моделей для мировой экономики и общества? Недавние перестановки в компании и общее раскачивание броненосца намекают, что теоретики были задвинуты глубоко на второй план, освободив место для менеджеров и предпринимателей.
Остальное научное сообщество не останавливало работу. Насколько точной может быть оценка, написал ли текст человек или БЯМ? Несколько научных работ (arXiv:2309.08913, arXiv:2002.03438, arXiv:2303.11156) пытаются оценить пределы точности, но обычно соглашаются, что творения моделей полностью общей направленности будут неотличимы от человеческих. Впрочем, другие (arXiv:2304.04736) утверждают, что даже близкие к совершенным БЯМ можно обнаружить с достаточным числом сэмплов.
Самые примитивные методы обнаружения предлагают: снабдите сгенерированный текст водяным знаком (arXiv:2301.10226) или сохраните его на стороне сервиса где-нибудь в базе данных для последующего поиска по семантической схожести (arXiv:2303.13408). Конечно, постепенное развитие открытых БЯМ, которые запускаются локально на оборудовании пользователя и могут быть как угодно дообучены, ставят крест на таких рекомендациях.
Методы анализа уже сгенерированного текста можно подразделить на две группы:
- Модели-детекторы: предобученные модели дообучены для задачи обнаружения текста от БЯМ (arXiv:1908.09203, arXiv:1905.12616, arXiv:2305.12519), в том числе с использованием техник adversial training (arXiv:2307.03838) и abstention (arXiv:2305.18149). В решении Ghostbuster (arXiv:2305.15047) применяется линейный классификатор. (На английский язык термин «литературный негр» переводится как «ghostwriter», «литетатурный призрак».)
- Выявление статистических отпечатков, которые характерны для лексикона БЯМ. Текстов для обучения здесь либо не нужно вовсе, либо мало, а также возможна быстрая адаптация для новых семейств моделей (2022.lrec-1.744). Подходов много: вычисление перплексии (new year, new features, new model, arXiv:2305.1822, arXiv:2305.14902) и её кривизны (arXiv:2301.11305), log rank (arXiv:2306.05540), n-граммный анализ (arXiv:2305.17359) и так далее. Для этого направления есть несколько обзорных научных статей: arXiv:2310.15264, arXiv:2303.07205, arXiv:2309.07689, раздел 5 статьи arXiv:2301.07597.
Binoculars
В научной работе «Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text» (arXiv:2401.12070) предлагается способ обнаружить тексты от БЯМ с высокой точностью. «Бинокль» превосходит как другие опубликованные методы, так и коммерческие решения, обещают исследователи.
Как следует из названия, бинокль — это оптический прибор из двух зрительных труб. Похожим образом инструмент для оценки «машинности» текста Binoculars рассматривает текст с позиции двух языковых моделей.
Перплексия — одна из самых распространённых метрик при работе с БЯМ. Если говорить упрощённо, перплексия показывает, насколько необычно и удивительно данные выглядят для модели. Казалось бы, дело в шляпе: по перплексии легко обнаружить тексты от ИИ, поскольку тексты от людей свободнее и оригинальней, у них показатель перплексии выше.
Однако, как показывают авторы метода Binoculars, просто перплексии недостаточно. Для иллюстрации приводится текст про капибару-астрофизика, который в научной статье называется проблемой капибары:
Dr. Capy Cosmos, a capybara unlike any other, astounded the scientific community with his groundbreaking research in astrophysics. With his keen sense of observation and unparalleled ability to interpret cosmic data, he uncovered new insights into the mysteries of black holes and the origins of the universe. As he peered through telescopes with his large, round eyes, fellow researchers often remarked that it seemed as if the stars themselves whispered their secrets directly to him. Dr. Cosmos not only became a beacon of inspiration to aspiring scientists but also proved that intellect and innovation can be found in the most unexpected of creatures.
Текст рассказывает про доктора Капи Космос, который поразил научное сообщество своей глубокой наблюдательностью и беспримерным чутьём в вопросах толкования космических данных. Будто сами звёзды нашёптывали секрет формирования Вселенной д-ру Космос, когда он смотрел на них через телескоп своими большими круглыми глазами. Астрофизик-капибара показал, что даже самые неожиданные существа могут обнаружить в себе интеллект и тягу к инновациям.
При всей выразительной флегматичности своей мордочки южноамериканская водосвинка вести научную деятельность не может. Также вряд ли даже GPT-4 смогла бы написать такой текст самостоятельно, без помощи извне.
Действительно, этот текст — результат запроса в чате ChatGPT с промптом «Can you write a few sentences about a capybara that is an astrophysicist?» [«Можешь написать несколько предложений про капибару-астрофизика?»].
Тем не менее при анализе с БЯМ Falcon перплексия высока — 2.20. Это куда выше среднего показателя как для машинного текста, так и человеческого. Инструмент DetectGPT назначает тексту рейтинг 0,14, что ниже границы в 0,17, и текст считается написанным человеком. Также ошибается GPTZero: вероятность авторства ИИ оценивается в 49,71%.
Дело в том, что в реальном мире анализу подвергается не промпт с ответом, а только ответ. В одном предложении будут встречаться слова «астрофизик» и «капибара», что приведёт к высокой неожиданности результата.
Чтобы решить проблему капибары, авторы Binoculars в дополнение к перплексии вводят перекрёстную перплексию [cross-perplexity], то есть показатель того, насколько необычно предсказание следующего токена выглядит для другой модели.
В формуле перекрёстной перплексии измеряется средняя перекрёстная энтропия для токена между результатом работы моделей M1 и M2. Знак · обозначает скалярное произведение. (Конечно, токенизатор моделей должен быть одинаков.)

Здесь  и
и  — сокращённая запись
— сокращённая запись  и
и  , где
, где  — последовательность символов текста для токенизации, а
— последовательность символов текста для токенизации, а  — токенизатор.
— токенизатор.  — число токенов в .
— число токенов в .
Метод Binoculars основан на механизме из двух моделей. Вместо анализа «сырой» перплексии предлагается измерять, насколько неожиданно токены из строки выглядят по отношению к базовой перплексии языковой модели, которой показали эту же строку.
Характер текста может быть таков, что у него будет высокая перплексия вне зависимости от того, кто её дописывает — человек или машина. Но если дописывает человек, то перплексия следующего токена будет ещё выше.
Если нормализовать наблюдаемую перплексию относительно перплексии машины, которая работает с этим текстом, получится метрика, почти не зависящая от промпта. Для этого вычисляется показатель  — отношение логарифмов перплексии и перекрёстной перплексии.
— отношение логарифмов перплексии и перекрёстной перплексии.

В числителе — показатель того, насколько строка неожиданно выглядит для модели  . Знаменатель измеряет, насколько неожиданны предсказания токенов модели
. Знаменатель измеряет, насколько неожиданны предсказания токенов модели  для модели . Если текст писал человек, то его текст будет уходить от ожиданий модели больше, чем модель уходит от ожиданий .
для модели . Если текст писал человек, то его текст будет уходить от ожиданий модели больше, чем модель уходит от ожиданий .
Для текста про астрофизика-капибару индекс составил 0,73, что ниже отсечки 0,901. По методу Binoculars текст уверенно идентифицируется как машинный.
Исследователи рекомендуют использовать для и схожие БЯМ. Для своих экспериментов и бенчмарков они задействовали Falcon-7B () и Falcon-7B-instruct ().
Бенчмарки
В своей работе авторы метода Binoculars заявляют, что наиболее важны ложноположительные срабатывания детектора, то есть те случаи, когда человеческий текст расценивается как машинный. Поэтому они обращают наибольшее внимание на показатели истинноположительных случаев (true-positive rates, TPR) при низких показателях ложноположительных случаев (false-positive rates, FPR). Для FPR был задан порог в 0,01%.
Для подборки бенчмарков исследователи нашли три источника. Заметный вклад внесли готовые датасеты OpenOrca и M4 (arXiv:2305.14902).
Другой источник — то, что придумали авторы работы про Ghostbuster (arXiv:2305.15047):
- Подреддит /r/WritingPrompts. Сообщество буквально создано для подобных исследований: одни участники предлагают идею для истории, а другие пишут в комментариях небольшой рассказ. Тем не менее подреддиту уже больше 13 лет, он зародился задолго до бума БЯМ на трансформерах. Чтобы избежать заражения данных (присутствия данных бенчмарка в датасете обучения), выделили данные от октября 2022 года, уже после релиза ChatGPT. По этим промптам gpt-3.5-turbo писал свои рассказы.
- Новостные статьи из датасета Reuters 50–50 (DOI:10.24432/C5DS42) из научной статьи 2006 года (DOI:10.1007/11861461_10). В этом датасете собраны 5 тыс. статей от 50 журналистов. Заголовки для статей попросили составить ChatGPT, затем он же (отдельно, без оригинала в контекстном окне) писал по этим заголовкам новые статьи.
- Сочинения уровня старших классов и вуза по разнообразным дисциплинам, взятые с сервиса помощи с домашней работой IvyPanda. По тексту сочинений ChatGPT составлял промпт, по которому он написал сочинения.
Авторы Ghostbuster выложили свои датасеты в репозитории GitHub, поэтому для тестирования Binoculars просто взяли эти же данные.

Зависимость размера документа от результата для датасетов (слева направо) новостей, данных подреддита /r/WritingPrompts и сочинений с IvyPanda. С ростом объёма информации детекторы отвечают точнее. Binoculars показывает превосходство над Ghostbuster на малом числе токенов
Кроме того, для Binoculars были составлены собственные датасеты. Для этого взяли написанные людьми тексты с CCNews (DOI:10.18452/1447), PubMed (doi:10.1609/aimag.v29i3.2157) и CNN (arXiv:1506.03340), а затем дали LLaMA-2–7B и Falcon-7B дописать альтернативные версии статей. Из сэмплов выделяли 50 первых токенов и скармливали их БЯМ в виде промпта, чтобы получить 512 токенов ответа. Человеческий промпт после этого из текста удалялся.
Сравнение на трёх датасетах проводилось против GPTZero, Ghostbuster и DetectGPT. Датасеты на основе ChatGPT «привычней» GPTZero и Ghostbuster, поскольку эти детекторы заточены для обнаружения ChatGPT. Аналогичным образом DetectGPT из-за своей натуры предрасположен лучше себя показывать на LLaMA.

Сравнение Binoculars с конкурентами на текстах, сгенерированных LLaMA-13B. Как видно, Ghostbuster способен обнаружить только ChatGPT
Действительно, Binoculars превосходит Ghostbuster вне «привычных» областей последнего. Авторы Binoculars замечают, что этот сценарий наиболее реалистичен и включает данные, не входящие в датасеты обучения Ghostbuster.
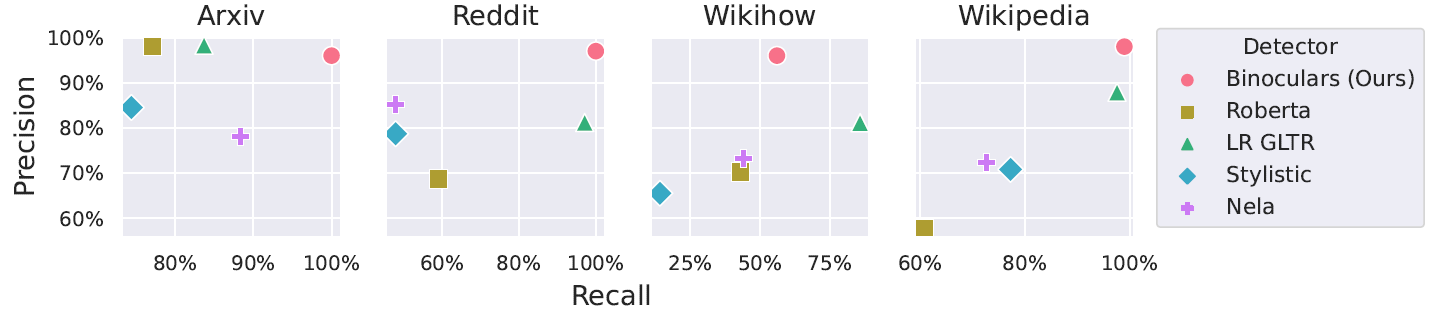
Обнаружение сгенерированного ChatGPT текста в различных областях из датасета M4. По горизонтали: полнота, то есть доля положительных случаев, которые были обнаружены. По вертикали: точность, то есть сколько положительных ответов были правильными
Проверили и тексты людей, для которых английский не является родным. Датасет сочинений с сайта EssayForum уже собран и опубликован. В этом датасете собраны оригинальные сочинения и тексты со скорректированной грамматикой. В отличие от некоторых детекторов, Binoculars сохраняет высокую точность как для эссе с ошибками, так и для скорректированных версий.
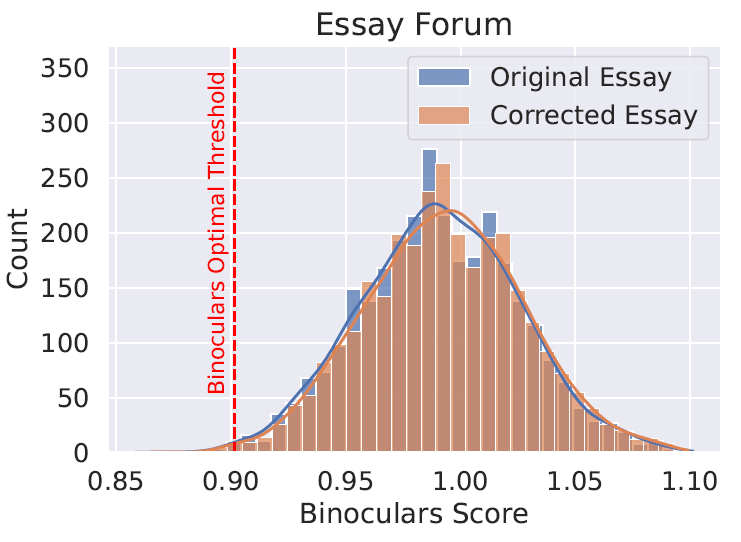
Binoculars расценивает обе версии сочинений как человеческий текст
Доля ложноположительных срабатываний Binoculars остаётся низкой даже для языков, слабо представленных в Common Crawl, на датасетах которого часто предобучают БЯМ. Но Binoculars часто распознаёт машинный текст в этих языках как человеческий. Вероятно, если бы текущая версия Binoculars была построена не на двух моделях семейства Falcon, а на чём-то помощнее, то и производительность в этих языках возросла бы.
Однако, как признаются исследователи, запустить более крупные (30 млрд параметров и выше) модели помешали ограничения памяти их видеоускорителей.

Binoculars работает с высокой точностью для болгарского и урду, но с низкой полнотой для всех четырёх языков, включая русский
Также остаётся вопросом, что делать с воспоминаниями в языковых моделях. Любая подобная система распознает текст конституции США как написанный БЯМ, хотя на деле его писали делегаты филадельфийского конвента, а не какая-нибудь языковая модель в 2024 году. С другой стороны, это желаемое поведение для систем антиплагиата и вообще, в первую очередь вопрос в терминологии интерфейса инструмента.

Напротив, последовательность из полностью случайных токенов будет распознана как человеческий текст — хотя писала её машина. Очевидно, что БЯМ не будет генерировать случайные токены.
Ни один из экспериментов не включал программный код. Авторы Binoculars также предупреждают, что не брались за вопросы обхода таких детекторов.
Препринт научной статьи «Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text» опубликован на сайте препринтов arXiv.org (arXiv:2401.12070). В репозитории GitHub github.com/ahans30/Binoculars представлен код проекта под 3-пунктовой лицензий BSD. На странице huggingface.co/spaces/tomg-group-umd/Binoculars на Hugging Face запущен инстанс с веб-демонстрацией работы детектора.
