Механизмы обеспечения повышенной безопасности контейнеров в Linux
1. Введение. Что мы называем контейнером
Наше с вами современное время во всех учебниках истории уже названо периодом очередной смены производственного уклада или четвертой промышленной революцией (Индустрией 4.0). Основную роль при этом отводят информации, в том числе ИТ-системам. В попытках удешевления ИТ-инфраструктуры, унификации и ускорения процессов разработки ИТ-решений человечество сначала придумало «облака» на замену традиционным ЦОДам, а затем и контейнеры на замену виртуальным машинам.
Вероятнее всего, сейчас словами «контейнер», «контейнеризованное приложение», «docker», «Kubernetes» и пр. уже никого не удивить. Однако что это такое, и чем, собственно, контейнер отличается от виртуальной машины, все же было бы нелишним кратко напомнить (Рис. 1).
 Рис. 1. Виртуализация и контейнеризация.
Рис. 1. Виртуализация и контейнеризация.
Как следует из этой иллюстрации, контейнером буквально можно считать процесс (дерево процессов), исполняемый на некотором физическом компьютере c определенной операционной системой с помощью специальной оболочки (контейнер runtime). В чем же состоит суть контейнеризации?
Если рассмотреть случай с виртуальными машинами, их изоляция друг от друга, а также их доступ к аппаратным ресурсам обеспечивается специальными аппаратными средствами (расширения виртуализации), и их поддержкой на уровне гипервизора. Возможности воздействия из виртуальной машины на гипервизор и физическое железо сведены к очень ограниченному набору интерфейсов, которые, опять же, в рамках, предусмотренных дизайном, могут влиять лишь на данную виртуальную машину. Иными словами, все вышеупомянутое служит для строгой изоляции виртуальных машин и всего, что в них может происходить, как друг от друга, так и от внешнего окружения, включая систему, на которой они функционируют.
Главной и практически единственной значимой целью контейнеризации является также достижение максимально возможной изоляции процессов как друг от друга, так и от возможного негативного воздействия на операционную систему, в которой они исполняются. Иногда в литературе для описания этой изоляции используются термины «sandbox» — «песочница» и «jail» — «тюрьма».
При этом, поскольку для изоляции процессов, исполняемых в едином пространстве ОС и на одном физическом компьютере, может быть использован гораздо более ограниченный набор инструментов и возможностей, то, очевидно, что с точки зрения безопасности контейнеры выглядят более уязвимыми. В чем, собственно, тогда преимущества контейнеризации перед виртуализацией? На самом деле, их довольно много:
возможность более гибкого использования имеющихся ресурсов (нет необходимости их резервирования как в случае с виртуальными машинами);
возможность экономии ресурсов (нет необходимости их тратить на множество копий ОС для каждой виртуальной машины);
нет задержек при старте (запуск процесса происходит практически мгновенно по сравнению с временем, затрачиваемым на загрузку виртуальной машины);
взаимодействие между процессами, пусть даже и изолированными, в случае необходимости гораздо проще реализовать, чем между виртуальными машинами. Так появилась, кстати, соответствующая концепция микросервисов, в последнее время ставшая очень популярной.
Все вышеперечисленное привело к весьма бурному развитию контейнерных технологий, несмотря на периодически возникающие проблемы с безопасностью уже развернутых контейнерных облачных систем, их взломами и утечками данных. Соответственно, работа по усилению безопасности контейнеров также не прекращается ни на секунду. Как раз об этом и пойдет речь далее в этой статье.
2. Чем опасны контейнеры
Как уже мог догадаться внимательный читатель, если контейнер — это только процесс в окружении операционной системы, то обеспечить его качественную изоляцию не так легко. Здесь присутствует еще одна неприятная особенность, которая усложняет жизнь «охране нашей тюрьмы», поскольку очень часто для нормальной работы или запуска приложений требуется наличие каких-либо привилегий, то обычная практика — запуск контейнерных процессов от суперпользователя root. И это одна из самых главных опасностей.
Что еще может происходить опасного внутри и вокруг контейнера? Вот список (очевидно, неполный) основных рисков и угроз (Рис. 2), которые в литературе еще называют векторами атаки:
Уязвимости ПО (1 место) — программы пишутся людьми, которые всегда делают ошибки. Иногда это позволяет осуществлять злоумышленные действия: получать доступ к коду, данным и т.п. Ошибки со временем обнаруживаются, исправляются, появляются новые версии программ, которые, однако, не всегда вовремя заменяются в образах контейнеров. Единственный более-менее действенный метод борьбы — постоянное сканирование контейнерных образов. Сканеры уязвимостей — практически всегда коммерческий продукт и один из основных источников дохода компаний, работающий в сфере компьютерной безопасности. Не только уязвимости ПО внутри контейнера могут приводить к печальным результатам: иногда для взлома бывает достаточно и просто прикладного ПО, никак не связанного с контейнерами, но работающего рядом на той же физической машине;
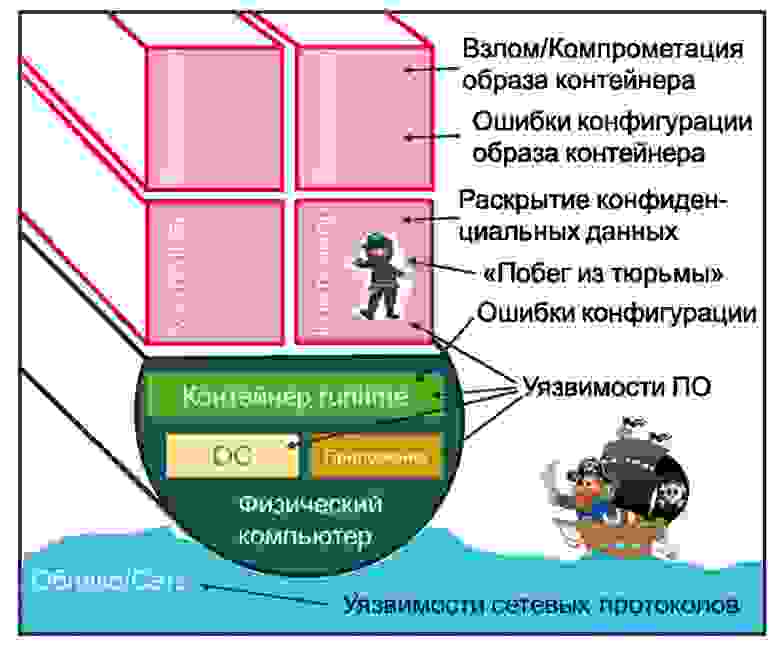 Рис. 2. Опасности «контейнерного мира»
Рис. 2. Опасности «контейнерного мира»
Ошибки конфигурации (2 место) — параметры конфигурации, которые, собственно, и задают то, как работают программы в контейнере, очень легко могут приводить к весьма нежелательным дырам в контейнерной изоляции, если они настроены неправильно;
Взлом/компрометация образа — если злоумышленнику на любом этапе разворачивания удалось как-то изменить/скомпрометировать образ контейнера, то он гарантированно получит все, что только можно пожелать. Для защиты от таких взломов используется масса различных методов с применением криптографии:
защищенные хранилища образов;
криптографические подписи образов;
различные контрольные суммы и т.п.
Раскрытие конфиденциальных данных — очень часто в результате небрежности необходимые для нормальной работы программ в контейнере конфиденциальные данные (логины, пароли, и т.п.) оказываются зашитыми прямо в коде образа контейнера. Далее он попадает с этими данными в общее хранилище, и то, что должно быть секретным, таковым уже более не является. Конечно же, есть правильные способы передачи этих данных уже после запуска контейнера, но «грабли» эти всегда почему-то наготове и, что самое печальное, никаких способов борьбы, за исключением организационных, до сих пор так и не появилось;
Уязвимости сетевых протоколов — сетевой трафик по-прежнему остается самым легкодоступным местом, если нужно чего-нибудь где-нибудь взломать, или куда-нибудь проникнуть. Единственная защита — шифровка всего и вся, применение TLS (Transport Layer Security, в девичестве SSL), а также драконовские меры по фильтрации трафика. Однако, и эти «грабли» тоже всегда наготове, и действенных способов борьбы с людской небрежностью тоже до сих пор нет;
«Побег из тюрьмы» — «jailbreak» или «root escape» — ситуация, когда в результате неудачного сочетания звезд и всех вышеприведенных факторов, враждебный код, который внутри контейнера оказался и исполнялся с привилегиями суперпользователя root (что довольно часто имеет место), получил доступ к ресурсам операционной системы и физической машины, на которой этот контейнер запущен, с теми же привилегиями. Самый опасный из всех возможных сценариев, т.к. весь сервер и все, что на нем в данный момент находится, а то и вообще все облако, поступает в полное распоряжение злоумышленника. Последствия могут быть очень печальными и непредсказуемыми, а убытки многомиллиардными.
3. Как изолируют контейнеры в ОС Linux. Штатные инструменты ОС
Опасности мы рассмотрели, страху нагнали… Теперь давайте поговорим о средствах и способах защиты. По сути, штатных средств изоляции процессов и, соответственно, контейнеров в ОС Linux всего (или аж целых) пять: DAC (discretionary access control), chroot / pivot_root, namespaces, cgroups и capabilities. Это первый эшелон обороны. Но перед его обсуждением, будет нелишним напомнить о том, как устроено и происходит взаимодействие ядра ОС и процессов в пользовательском пространстве.
Любые действия пользовательского процесса, связанные с доступом к каким-либо ресурсам, в ОС Linux (или в любой из Unix-подобной ОС) выполняются ядром и осуществляются посредством системных вызовов (system calls или syscalls) от процесса к ядру. Таких syscalls в процессе развития Linux становилось все больше и больше, и к настоящему времени их стало крайне много (их число уже перевалило за три сотни). Как правило, все обращения к ним обернуты в стандартной библиотеке, которая присутствует в данном дистрибутиве ОС, так что для типичного прикладного программирования они просто незаметны.
Вторым краеугольным камнем философии ОС Linux (или опять же всего семейства Unix ОС) является парадигма о том, что любой ресурс или объект в системе — это файл. А с файлами связана система контроля доступа к ним — DAC (discretionary access control — избирательный контроль доступа), т.е. к любому файлу приписаны некие обязательные атрибуты (та самая строчка вида rwxr-xr-x), которые определяют разрешения на чтение, запись и исполнение этого файла для его хозяина, группы, в которой он состоит, и всех остальных пользователей. Эта система контроля доступа всегда была и остается главной составляющей обеспечения безопасности и, соответственно, изоляции в ОС Linux, однако, как нетрудно догадаться, подход с выделением только трех групп контроля и трех действий не всегда является достаточным (особенно с точки зрения контейнеризации).
И, как всегда, есть еще осложняющие и запутывающие жизнь дополнительные атрибуты — setuid и setgid, которые влияют на то, как и от какого пользователя запускается процесс при исполнении данного файла. Намерения-то у создателей были хорошие — облегчить жизнь простым пользователям, позволив им таким образом расширить свои полномочия, не злоупотребляя использованием привилегий root. Однако как обычно — палка оказалась о двух концах, и, при неумелом использовании, результатом такой манипуляции может быть, как раз-таки пресловутый и страш-шный root escape.
Вторым краеугольным камнем обеспечения изоляции является использование функций (команд) chroot / pivot_root, которые меняют для текущего процесса и всех его наследников самый верхний видимый уровень иерархии (корень) файловой системы. При этом все, что находится выше по иерархии, чем текущий установленный корень, становится невидимым и, соответственно, недоступным для этого процесса. Разница между этими двумя функциями заключается в том, что chroot меняет корневую директорию, а pivot_root — корневую точку монтирования файловой системы, но при этом не меняя текущей директории. Это более безопасно, т.к. после chroot старый корень файловой системы можно перемонтировать и по-прежнему иметь к нему доступ, но здесь требуется выполнение команды «cd /» сразу после осуществления вызова pivot_root.
Здесь мы плавно переходим к третьему столпу изоляции процессов в ОС Linux — парадигме namespaces. Суть здесьв том, что, поместив процесс в как бы отдельную закрытую «комнату» (namespace) для какого-либо ресурса, мы ограничиваем стенами этой «комнаты» то, что видимо и доступно для этого процесса. Так вот, как раз наш pivot_root и делает свою работу по изменению корневой точки монтирования в текущем mount namespace процесса.
Лишь некоторые ключевые ресурсы на данный момент имеют свои namespace. Точки монтирования файловой системы исторически были первым ресурсом, получившим свои «комнаты». Список поддерживаемых ресурсов сейчас включает такие, как:
UTS (Unix Timesharing System) — здесь находятся в частности имена хоста и домена;
Идентификаторы процессов (Process IDs);
Точки монтирования файловой системы;
Сетевые интерфейсы;
Идентификаторы пользователей и групп;
Объекты межпроцессного обмена (IPC);
Управление физическими ресурсами — Control groups (cgroups).
И этот список несомненно будет расширяться в будущем. Например, Linux-сообщество довольно давно активно обсуждает внедрение новых namespace для модулей LSM (Linux security modules), и об этом речь пойдет чуть дальше.
Все рассмотренное выше пока относилось к файловой системе и виртуально-логическим объектам вроде идентификаторов, имен, флагов, очередей IPC и т.п., но никак не затрагивало физических ресурсов — использования процессоров, памяти и т.п. Контроль доступа к этим физическим ресурсам осуществляется посредством control groups или cgroups. Это четвертый ключевой компонент систем контроля доступа в ОС Linux.
Использование ограничений на доступ к физическим ресурсам позволяет избежать ситуаций с злонамеренным захватом всех физических ресурсов сервера каким-либо процессом, например, посредством бесконечного клонирования себя (пресловутая fork bomb). В системах с контейнеризацией этот аспект исключительно важен, т.к. никто априори не знает, что в контейнере лежит, и что оно может начать делать.
Последняя, пятая колонна обеспечения безопасности и изоляции процессов в ОС Linux — это capabilities, т.е. возможности или привилегии, которые можно присваивать конкретному процессу. Идея изначально заключалась в том, что, поскольку для выполнения даже элементарных операций в системе часто требовались привилегии, которыми изначально обладал только суперпользователь root, и практически никакие полезные действия в системе обычному пользователю было сделать невозможно, то для того, чтобы избавить как можно большее число операций от root-привилегий, эти самые root-привилегии и были разбиты на много мелких частей, или capabilities.
Список их сейчас уже весьма длинный, а также постоянно меняется и расширяется. Все время возникает потребность во все более новых… Но свою задачу избавления от root-зависимости этот механизм, тем не менее, исполняет все более и более качественно. Повышает ли это безопасность, или в итоге является с учетом текущей неразберихи с дизайном «пятой колонной», приводя к противоположному результату на фоне всеобщего успокоения отсутствием root-а — это вопрос провокационно-философский, и даже саму постановку вопроса в таком ключе будем считать сугубо личным мнением автора.
4. Дополнительные средства. LSM и overlayfs
Все, о чем шел разговор выше, относится к DAC (discretionary access control — избирательному контролю доступа). Однако, как практика показывает, избирательного контроля очень часто недостаточно для полноценной защиты от всех возможных угроз. Это привело к появлению в ядре ОС Linux механизма дополнительных модулей безопасности LSM (Linux security modules). Этот механизм, хоть и является опциональным, но будучи во включенном состоянии, осуществляет другой принцип контроля доступа — MAC (Mandatory Access Control — мандатный контроль доступа). Разница в подходах весьма проста, но очень существенна: DAC — разрешено все, что не запрещено; MAC — запрещено все, что не разрешено.
Модулей LSM уже имеется немалое количество, они постоянно развиваются и появляются новые, мы же далее рассмотрим только четыре из них, наиболее важные с точки зрения работы с контейнерами. Это: SELinux, AppArmor, Integrity/IMA (Integrity Measurement Architecture) и SecComp. Все они имеют во многом общий подход к осуществлению своих функций (Рис. 3.). Есть объекты (ресурсы), доступ к которым субъектов (процессов) осуществляется в соответствии с определенным настраиваемым набором правил. Доступ предоставляется, только если он по этим правилам явно разрешен. По умолчанию — все запрещено.
SELinux контролирует доступ к файлам на основании меток в расширенных атрибутах, которые приписываются к каждому файлу в системе. AppArmor для осуществления такого же контроля вместо меток использует абсолютный путь к файлу. Задача у модуля Integrity немного другая, этот модуль контролирует целостность кода системы, подсчитывая и сравнивая контрольные суммы файлов с записанными также в расширенных атрибутах в зашифрованном виде эталонными значениями. При несовпадении доступ к файлу блокируется.
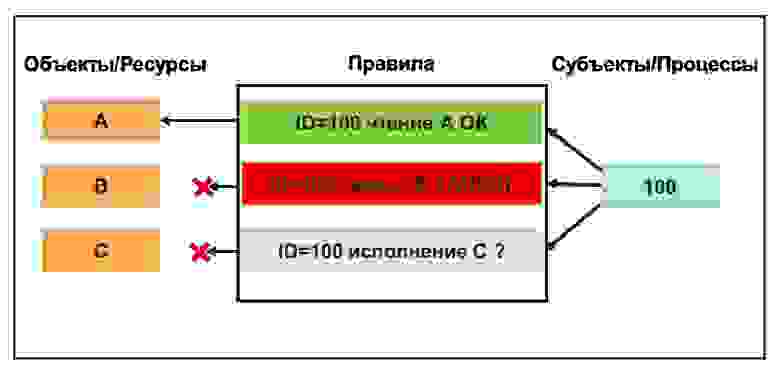 Рис. 3. Общий принцип работы LSM.
Рис. 3. Общий принцип работы LSM.
Модуль SecComp имеет совсем другую область применения. Он осуществляет фильтрацию системных вызовов (syscalls) на основании заданного набора правил и блокирует процессы, которые пытаются эти правила нарушать.
Еще одна крайне рекомендованная мера по обеспечению контейнерной безопасности — файловая система, смонтированная только на чтение. Это позволяет избежать множества неприятностей, если что-то вдруг выйдет из-под контроля. Однако на практике части приложений требуется не только читать, но и писать, например, для вывода информации в логи для последующего анализа. И есть вариант, который позволяет, не трогая основную файловую систему, обеспечить возможность записи логов и прочего — использование двухуровневых файловых систем с оверлеем типа overlayfs, fuse-overlayfs, и др.
Общий принцип построения таких файловых систем (Рис. 4.) в том, что есть как бы два уровня, две файловых системы — верхняя и нижняя. Файл виден для пользователя из верхнего уровня (если он существует на верхнем или обоих уровнях) и из нижнего (если он существует только на нижнем, который при этом является неизменным и открыт только на чтение). Верхний уровень открыт на запись, но все сделанные изменения остаются только в его пределах и не распространяются далее. При этом, собственно, вновь записываемые файлы могут вообще сохраняться только в ОЗУ и до дисковой памяти не доходить вовсе. Нижних уровней может быть несколько, в любом случае будет виден файл из самого верхнего уровня.
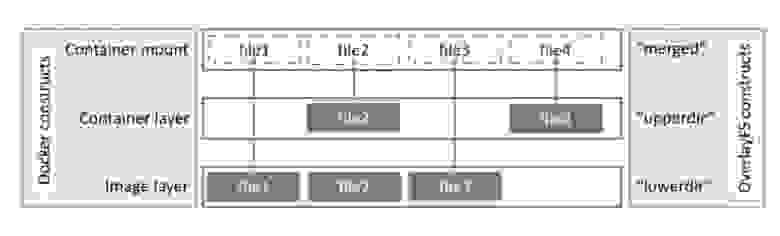 Рис. 4. Принцип overlayfs (из docker documentation).
Рис. 4. Принцип overlayfs (из docker documentation).
5. Нерешенные на данный момент проблемы
Все вышеизложенное более или менее работает уже довольно давно, но, тем не менее, имеет массу нерешенных или полурешенных проблем, над решением части которых работаем и мы в лаборатории ASTL (Advanced Software Technology Laboratory) Московского Исследовательского Центра Huawei. Несомненно, главная из них представляет собой по-прежнему необходимость root-привилегий для работы контейнеров. Декларированные как «rootless» (непривилегированные) контейнеры — это как раз половинчатое решение, т.к. root-привилегии все равно в том или ином виде присутствуют. Работа же по настоящему избавлению от root«а, а также и усилению безопасности контейнерных систем, требует решения довольно большого числа мелких и достаточно крупных проблем, из которых можно выделить следующие (список неполный):
виртуальные сетевые подключения требуют root-привилегии для открытия соединения; используемые обходные решения вроде эмуляции последовательного порта (slirp4netns) работают неудовлетворительно медленно;
модули LSM (integrity, AppArmor, SELinux) не имеют поддержки раздельных политик безопасности индивидуально для выделенных процессов, контейнеров (необходимо внедрение namespaces). В текущей реализации любые политики безопасности оказываются общими для всех процессов на данной ОС;
функционал контрольных точек/точек восстановления системы при отсутствии root-привилегий еще до конца не реализован. Хотя в ядре уже появилась необходимая capability (CAP_CHECKPOINT_RESTORE), необходимые механизмы для поддержки в контейнер runtime пока отсутствуют.
6. Вместо заключения
Текущее истинное положение дел, говоря словами одного из гуру от «контейнерных дел секьюрити» Дэна Уолша, можно охарактеризовать так: «Docker is about running random crap from the Internet as root on your host» («Докер — это про исполнение с правами суперпользователя случайного мусора из Интернета на вашей машине»). Это, конечно, несколько утрированное преувеличение, но доля правды, и довольно приличная, в этом есть. Проблемы, перечисленные выше, к сожалению, в силу своей сложности пока не находят должного окончательного решения среди Linux коммьюнити.
Так, например, предложения по решению поддержки раздельных политик безопасности для модулей LSM уже достаточно давно готовы и ждут одобрения для включения в Linux upstream, но при этом дело движется весьма медленно, гораздо медленнее, чем хотелось бы. И такая ситуация не может не вызывать определенных опасений.
При этом существует совершенно определенная необходимость в усилении безопасности контейнеризации. Пока что этот вакуум заполняется различными коммерческими поделками, призванными снизить остроту проблемы, при этом не давая ее окончательного решения. От сообщества требуется ускорение в наведении порядка в этом вопросе, поэтому с надеждой, что это вскоре произойдет, и позвольте закончить эту статью…
Источники и составные части вдохновения (aka список литературы):
Документация ядра и пользователя Linux, URL: https://www.kernel.org/doc/
Liz Rice, «Container security», O«Reilly Media, 2020
Документация проекта SELinux, URL: http://www.selinuxproject.org
Документация проекта AppArmor, URL: https://apparmor.net
Документация проекта Integrity/IMA, URL: http://linux-ima.sourceforge.net
Документация проекта docker, URL: https://www.docker.com
Wayne Jansen, Timothy Grance, «NIST Special Publication 800–144. Guidelines on Security and Privacy in Public Cloud Computing», NIST, 2011.
Ramaswamy Chandramouli, «Security Assurance Requirements for Linux Application Container Deployments», NISTIR 8176, NIST, 2017.
Murugiah Souppaya, John Morello, Karen Scarfone, «NIST Special Publication 800–190. Application Container Security Guide.», NIST, 2017.
