Медленное выполнение команды TRUNCATE: анализ проблемы блокировок спинлока в SQL Server
Приветствую всех читателей Хабра! Меня зовут Михаил, я администратор DBA в компании «Автомакон». На данный момент работаю на проекте для «ВкусВилл».
Решил затронуть одну из насущных проблем, связанную с работой SQL Server, а именно со спинлоками в нем. Да, даже такой зрелый и стабильный продукт как Microsoft SQL Server иногда подкидывает неожиданные задачи. Этот кейс хорошо демонстрирует, насколько увлекательные и интересные задачи решают администраторы баз данных.

Нет времени ждать: описание проблемы выполнения команды TRUNCATE
Проблема заключается в неожиданно долгом выполнении команд TRUNCATE в SQL Server 2019 и более новых версиях (хотя я не проверял, существует ли аналогичная проблема и в более старых версиях). Обычно операция TRUNCATE выполняется почти мгновенно. Но в рассматриваемых случаях время выполнения команд значительно увеличивалось — от 5 до 20 секунд и даже более.
Помимо моей статьи рекомендую ознакомиться с еще одним качественным анализом этой же проблемы: «Записки оптимизатора 1С (часть 1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE / Хабр (habr.com)».
Обобщая полезные выводы из публикации коллег, выделяю несколько ключевых наблюдений:
Высокое потребление CPU. Одним из ключевых аспектов этой проблемы было значительное потребление ресурсов CPU операциями TRUNCATE.
Специфика SQL Server 2019. Это необычное поведение. Предполагаю, что оно характерно только для SQL Server 2019 и более новых версий. Предыдущие версии SQL Server не демонстрировали этой аномалии, что указывает на специфику версии или изменения в новом выпуске.
Обходное решение. Временным решением стал перезапуск SQL Server, который смягчал проблему, но только на время. Через несколько дней все повторялось.
Независимость от размеров очищаемой таблицы. Количество строк во временной таблице не влияло на длительность команды TRUNCATE, что предполагает, что проблема не связана с объемом обрабатываемых данных.
Трудности воспроизведения. В статье также описаны трудности в воспроизведении проблемы в условиях тестирования, когда изменения интенсивности и количества строк во временных таблицах не позволяли последовательно воссоздать проблему, усложняя диагностику. К слову, мне тоже не удалось воспроизвести проблему в чистом виде.
Исследование проблемы
Подтверждение проблемы
При столкновении с проблемой аномальной производительности в SQL Server важно принять систематический подход к устранению неполадок. Первый шаг в процессе устранения неполадок — подтверждение существования проблемы. Для этого следует использовать Extended Events (XE) — гибкую систему логирования, которая позволяет наблюдать и собирать данные о работе SQL Server на разных уровнях.
Код используемой сессии XE:
CREATE EVENT SESSION [truncate] ON SERVER ADD EVENT sqlserver.sql_statement_completed (SET collect_statement=(1) ACTION (package0.callstack, sqlos.cpu_id, sqlos.scheduler_id, sqlos.task_time, sqlserver.session_id, sqlserver.username) WHERE ([sqlserver].[like_i_sql_unicode_string]([statement], N’TRUNCATE TABLE%') AND [cpu_time]>=(100000))) ADD TARGET package0.event_file (SET filename=N’truncate.xel', max_rollover_files=(0)) WITH (MAX_MEMORY=4096 KB, EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS, MAX_DISPATCH_LATENCY=30 SECONDS, MAX_EVENT_SIZE=0 KB, MEMORY_PARTITION_MODE=NONE, TRACK_CAUSALITY=OFF, STARTUP_STATE=OFF) GO
Сессия может длиться от нескольких минут до нескольких часов, в зависимости от целей. При этом важно помнить, что сбор данных 'sql_statement_completed' может повлиять на производительность, особенно когда сбор данных происходит на протяжении длительного времени в высоконагруженных системах. Более подробно о работе с XE можно ознакомиться в официальной документации Quickstart: Extended Events — SQL Server | Microsoft Learn.
Результаты сбора событий ниже:

Спинлоки или откуда у нас высокая утилизация CPU
Следующим шагом в устранении проблемы с производительностью операции TRUNCATE TABLE является исследование возможного влияния спинлоков. Спинлоки — это примитивы низкоуровневой синхронизации, используемые SQL Server для управления доступом к его внутренним структурам. Конкуренция за эти спинлоки может привести к увеличению нагрузки процессора.
Ниже прилагаю код XE для захвата событий spinlock_backoff, которые возникают, когда поток отступает после неудачной попытки получения спинлока. При сборе этих данных можно определить, происходит ли конкуренция за спинлоки во время выполнения операций TRUNCATE TABLE и является ли это фактором высокой утилизации CPU.
CREATE EVENT SESSION [spin_lock_backoff] ON SERVER ADD EVENT sqlos.spinlock_backoff (ACTION (package0.callstack, sqlserver.sql_text) WHERE ([sqlserver].[like_i_sql_unicode_string]([sqlserver].[sql_text], N’truncate table%'))) ADD TARGET package0.event_file (SET filename=N’spin_lock_backoff.xel', max_rollover_files=(0)), ADD TARGET package0.histogram (SET filtering_event_name=N’sqlos.spinlock_backoff', source=N’package0.callstack', source_type=(1)) WITH (MAX_MEMORY=51200 KB, EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS, MAX_DISPATCH_LATENCY=30 SECONDS, MAX_EVENT_SIZE=0 KB, MEMORY_PARTITION_MODE=PER_NODE, TRACK_CAUSALITY=OFF, STARTUP_STATE=OFF) GO
Результат ниже:
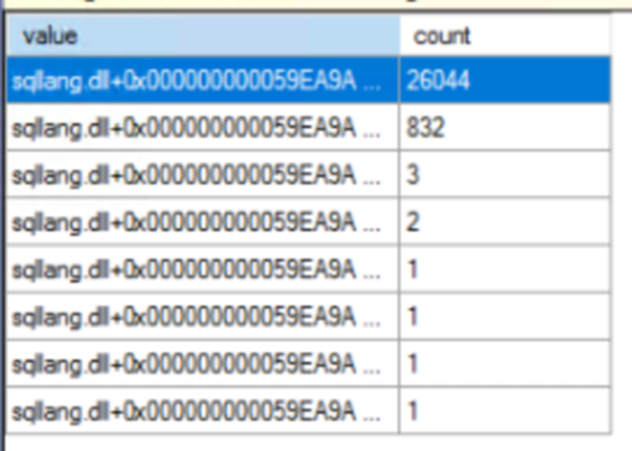
Рассмотрим результат из гистограммы XE для spinlock_backoff. Скриншот показывает список значений, каждое из которых представляет уникальный стек вызовов в процессе SQL Server, вместе с количеством случаев отказа от попытки захвата спинлок блокировки.
В полученных данных видно доминирование одного стека вызова над всеми остальными. Для точной идентификации спинлока, ответственного за эту конкуренцию, можно сопоставить стек вызовов с соответствующим названием спинлока. В данном случае, изучив собранный файл событий, идентифицировал блокировку спинлока как «OPT_IDX_STATS».

Расшифровка стека вызовов, полученного в XE, была выполнена с помощью SQLCallstackResolver, что позволило выявить последовательность операций внутри SQL Server, приведших к конкуренции за спинлок. Трассировка стека включает в себя несколько функций. Обратите внимание на «CQSIndexStatsMgr: DropIndexStatsWithWildcards.'
Расшифрованный стек вызовов:
sqllang! XeSqlPkg: CollectSqlText
sqllang! XeSqlPkg: CollectSqlTextActionInvoke
sqldk! XeSosPkg: spinlock_backoff: Publish
sqldk! SpinlockBase: Sleep
sqldk! SpinlockBase: Backoff
sqllang! Spinlock<287,1,257>:: SpinToAcquireWithExponentialBackoff
sqllang! CQSIndexStatsMgr: PqsisAdvanceInBucket
sqllang! CQSIndexStatsMgr: DropIndexStatsWithWildcards
sqllang! CQSIndexRecMgr: InvalidateMissingIndexes
sqllang! QPEvent: ModifyObject
sqllang! CStmtTruncateTable: XretExecute
sqllang! CMsqlExecContext: ExecuteStmts<1,0>
sqllang! CMsqlExecContext: FExecute
sqllang! CSQLSource: Execute
sqllang! process_request
sqllang! process_commands_internal
sqllang! process_messages
sqldk! SOS_Task: Param: Execute
sqldk! SOS_Scheduler: RunTask
sqldk! SOS_Scheduler: ProcessTasks
sqldk! SchedulerManager: WorkerEntryPoint
sqldk! SystemThreadDispatcher: ProcessWorker
sqldk! SchedulerManager: ThreadEntryPoint
KERNEL32+0×17974
Из стека вызова видно, что после операции TRUNCATE TABLE SQL Server приступает к инвалидации записей в кэше для предложений по отсутствующим индексам (MissingIndexes). Этот процесс требует доступа к спинлоку OPT_IDX_STATS для обновления кэша. Когда несколько операций TRUNCATE TABLE выполняются одновременно, это может привести к конкуренции за этот спинлок, потому что каждая транзакция пытается одновременно обновить один и тот же кэш.
Решение проблемы
Решение проблемы заключается в использовании флага трассировки (Trace Flag — TF) 2392, который отключает сбор данных об отсутствующих индексах.
Этот флаг трассировки упоминается в KB4042232 — FIX: Access violation when you cancel a pending query if the missing indexes feature is enabled in SQL Server — Microsoft Support.
После применения флага 2392 возобновил мониторинг при помощи XE для TRUNCATE TABLE. Теперь ни одно событие TRUNCATE TABLE не превышает 100 мс по времени CPU. Кроме того, как положительный побочный эффект на высоконагруженной системе, отметил снижение использования CPU в рабочее время, со среднего значения ~40% до ~30%.
Личный взгляд на проблему
Поведение, наблюдаемое в SQL Server, похоже на поведение by Design. Лично у меня вызывает сомнение необходимость вызова 'InvalidateMissingIndexes' при очистке временной таблицы. Рассматривая потенциальные решения, разработчики Microsoft SQL Server могли бы исследовать следующие варианты:
Подтверждение необходимости. Определить реальную необходимость в инвалидации кэша отсутствующих индексов во время очистки временных таблиц. Если это окажется необязательным, то этот шаг может быть пропущен для избежания проблемы.
Использование трассировочного флага 2392. В настоящее время этот флаг отключает сбор данных об отсутствующих индексах для всего экземпляра SQL Server. Более гибким подходом могло бы быть применением подобного поведения на конкретной базе данных.
Секционирование спинлока. Если избежать вызова 'InvalidateMissingIndexes' невозможно и контроль на уровне базы данных не является допустимым вариантом, другой возможностью может быть секционирование спинлока OPT_IDX_STATS. Это может снизить конкуренцию и улучшить производительность.
Данная статья была впервые опубликована мной на английском языке по ссылке Slow TRUNCATE: Diagnosing SQL Server Spinlock Contention — SQL Peak Performance
В комментариях предлагаю задать вопросы, готов ответить на них, обсудить проблему и решение.
