Мечтают ли компьютеры строить дома? или Как заставить нейросети определять ремонт в квартирах и улучшать объявления
Как для большинства выглядит процесс постройки дома? Котлован, песок, цемент, какие-то блоки, снующие люди и техника, шум, пыль на пару лет и вот, дом готов. На самом деле всё давно не так. Точнее, так, но это, как говорится, frontend. Но строительство уже давно процесс не физический, а киберфизический. Поэтому есть у него и backend. Это работа с данными на всех этапах, от планирования до оценки ремонта, использование нейросетей для анализа объявлений о продаже, построение экономических моделей и множество всего. В общем, создание дома — это IT-проект, который начинается задолго до возведения здания и не заканчивается после сдачи жителям, т.к. во время эксплуатации продолжается сбор и обработка данных. Меня зовут Алексей, я техлид в команде Data Science по направлению Computer Vision в Самолете, и сейчас вам всё расскажу.

Наверняка вы слышали про Самолет, но скорее как про девелопера, ну или застройщика. На самом деле компания состоит из множества бизнес-юнитов, из которых лишь часть отвечает непосредственно за стройку. А вот остальные, в том числе и мой, готовит «почву» для этого, анализирует данные в процессе или помогает в оценке после постройки, и даже при продаже на вторичном рынке. Расскажу сегодня вкратце, что интересного может быть в стройке c точки зрения IT.
Содержание
Не девелопмент, а development
Почему-то исторически сложилось, что компании, которые строят дома, называются застройщиками, а те, кто с нуля разрабатывает проект, планирует, создаёт дом, инфраструктуру и т.п. — девелоперами. Хотя в нашей среде, конечно, developer — это разработчик. Но вот в Самолете всё сложилось так, что в компании много разработчиков, которые помогают строить дома. Мы уже давно встали на путь цифровизации и планомерно превращаемся из компании-застройщика в IT-компанию, развивая продукты, которые не очень связаны с квадратными метрами. Смотрите сами: у нас работает более 1500 разработчиков, которые ежедневно трудятся в 8 бизнес-юнитах.
Сейчас никакая стройка не начинается без предварительно подготовленных проектов, в рамках которых изучаются вводные, рассчитываются необходимые материалы, прорабатываются риски и т.п. Да, Data driven (основанный на данных) подход используется на всех этапах в компании. И хотя этого не видно, но технологическая часть процесса едва ли не больше, чем физическая. И для этого нам нужно очень много данных. Их сбором и анализом занимается отдельная дирекция по данным в бизнес-юните «Центр стратегической поддержки», которая построила единое хранилище данных и обрабатывает ценнейшие кусочки информации со всех направлений — от приобретения участка под стройку до повседневной работы УК по эксплуатации дома. В этом подразделении я и работаю.
Данные — это не только про отчётность, но и о предиктивной аналитике.
70% успеха — процесс автоматизации принятия решений.
Одно из самых интересных, на мой взгляд, чем мы занимаемся и что делает моя команда — это проекты, связанные с Computer Vision. Мы плотно работаем и с системами распознавания и классификации, и даже с генеративными сетями. Тут, поверьте, есть, где развернуться. Тем более, что за последние несколько лет количество удобных библиотек и инструментов и их точность выросли кратно, что позволяет нам довольно оперативно тестировать гипотезы и реализовывать сложные проекты, которые пару лет назад были лишь фантазиями.

Не буду говорить о достаточно скучной классификации изображений для объявлений о продажах, где мы определяем, является ли комната на фото кухней, ванной или жилым помещением. Но расскажу об интересных кейсах, где мы применяем компьютерное зрение. В своей работе мы используем довольно большой стек, про который как-нибудь расскажем отдельно. Отмечу лишь, что на текущий момент основными являются Python, Spark, SQL, Hive, Airflow. Ну, а для компьютерного зрения, конечно же, библиотеки Pytorch — 90% и TensorFlow — 10%. Впрочем, в зависимости от задачи инструменты могут меняться, расширяться и дополняться, так что список является актуальным только на сегодня.
Распознаём документы и контролируем стройку
Контроль стройки
Раньше за состоянием стройки следили специальные люди (нет, они и сейчас следят, конечно), но теперь мы можем поручить алгоритмам компьютерного зрения вспомогательные функции. Например, они позволяют контролировать соблюдение техпроцесса: что корректно производится кладка, правильно устанавливается остекление. С помощью установленных камер, фотоловушек и моделей машинного обучения мы можем контролировать более 30 параметров (из них 16 классов относятся к внутренней отделке).

И что немаловажно, мы также следим и за безопасностью. Когда монолит возведен, а кладки и окон еще нет, на этаже должны быть оградительные сетки. Модель по снапшотам из видеопотока может определять, есть сетка или нет. Может определять она и что строители носят каски на объектах, и что соблюдаются прочие требования к технике безопасности. И если вдруг где-то есть нарушения, то модель оперативно уведомит об этом команду, чтобы они могли всё исправить
Распознавание документов
В работе, разумеется, у нас есть огромное количество проектной документации. К сожалению, ещё не до всех поставщиков, подрядчиков и партнёров добрался электронный документооборот и часть документов существует в бумажном виде. А часть хоть и в электронном, но далеко не всегда классифицирована.

Поэтому, мы разработали внутреннюю систему, которая умеет распознавать по внешнему виду и семантике тип документа, чтобы дальше уже правильно его классифицировать и передать на обработку в нужный отдел. Внутри, разумеется, тоже нейросеть, которая работает не только с файлами документов, но и со сканами, и даже с фотографиями. Мы получаем эмбеддинги (вектора) формы документа (тут можно почитать подробнее, что это такое) и эмбеддинги текста документа (используются методы OCR + текстовые модели), и на их основе можем предсказать, какой у документа тип. Это не самая простая задача и внимательный читатель заметит, что на диаграмме выше документы с типом TTH распознаются лишь на 47%. И проблема тут в том, что этот тип документа очень похож на УПД, причём и по форме, и по содержанию. Но таких документов в данный момент не слишком много, так что проблема не критичная, однако, мы думаем, как её решить.
Кое-что посложнее: мониторинг ремонта и улучшение фотографий
Мониторинг ремонта
Помимо контроля стройки, мы умеем контролировать и работы по отделке. Механизм тут похожий, только, в отличие от стационарных камер и фотоловушек, здесь камеры используют сотрудники технадзора. Для них всё выглядит так же, как и всегда, они заходят в каждую квартиру и проверяют, стоят ли розетки, постелен ли ламинат и так далее, но мы усовершенствовали этот процесс. Итак, как это работает:
Сотрудник технадзора проводит съемку с помощью разработанного мобильного приложения;
Видео поступают на сервер с мобильных устройств по протоколу bittorrent для обеспечения докачки в случае нестабильной связи;
Видео автоматически нарезается на кадры, кадры обрабатываются на видеокартах;
По итогам обработки формируется отчет на основе количества кадров;
Процент готовности отделки вычисляется исходя из доли кадров с необходимым объектом на долю к кадрам, где класс должен быть.

Для того, чтобы это работало, мы создали алгоритм (читать код), который с помощью модели (использовали convnext_large_in22k (ConvNeXt Large)) по фото или видео определяет состояние отделки и выводит это на экран после обработки. А также сделали удобную панель управления администратора системы для контроля работы.

Затем получили данные и провели предобработку (смотреть тетрадку Jupiter) по всем объектам, обучили модель, классифицировали все объекты внутри квартир и получили вот такую картину.

Понятно, что в каждой квартире есть комнаты и ванные, много где есть коридоры. Ну, а классификация отделки уже зависела от обучающей выборки. Мы взяли основные параметры, но можно их, разумеется, и расширить, если бизнесу потребуется. Для разметки сняли 5 часов видео на двух объектах, этого оказалось достаточно. Видео имеет FPS 30 кадров в секунду. 5 часов = 5 × 60 минут = 300 минут = 300 × 60 секунд = 18 000 секунд × 30 FPS = 540 000 изображений из которых можно отобрать нужное количество примеров в датасет. В пилот отобрали 10 000 изображений.

После первоначальной разметки и обучения модели мы уже были готовы получать результат на новых данных. Дальше уже нужно оценивать статистику по классам, смотреть пересечения (где два взаимоисключающих класса возникают), произвести доразметку и дообучить модель на новых данных, а также, возможно скорректировать классы (добавить/убрать). Первые запуски нейросети на новых данных показали очень неплохие результаты.
Архитектура | Число параметров | FPS | F1 score |
convnext_tiny | 28 миллионов | 69 | 0.762 |
vit_giant_patch14_224_clip_laion2b | 18 миллионов | 18 | 0.830 |
Как видите, метрика F1 (в данном случае можно считать, что это общее значение для полноты и точности) на двух подходящих моделях показывает значение близкое к 0.8. Это значит, что в 80% случаев модель верно определяет, что находится на изображении. 100% добиться невозможно, а потери в 20% считаются хорошим результатом. Тем более, что данный инструмент лишь создаёт предупреждения, а далее всё равно проверяет человек.
В итоге мы получаем сводную таблицу данных об объекте, информация сохраняется в корпоративное хранилище в Hadoop для передачи в другие системы Самолета для дальнейшей работы остальных команд. В первую очередь данные нужны инженерам ПТО и заместителям директора по строительству для контроля динамики, а также руководству компании для выявления отстающих объектов, чтобы мониторить процесс внутреннейвнетренней отделки здания, в случае отставания от плана применять управленческие решения. Ниже показан пример отчёта, а полный отчёт в виде PDF можно посмотреть по ссылке.

Подобный процесс позволил снизить время на осмотр, ускорить работы, снизить штрафы и время на работу с подрядчиками, а также уменьшить затраты на инциденты. На основе проведенных расчетов, был получен эффект экономии в размере 10–20 млн. рублей на объект. Взгляните, как сейчас выглядит процесс, на который раньше уходили десятки человеко-часов.

Улучшение фотографий в объявлениях
Сервис Самолет Плюс обратился к нашему подразделению с задачей создать решение, которое могло бы автоматически исправлять изображения, например, при создании пользователями объявлений о продаже квартир. Нужно исправлять изображения так, чтобы там не было дубликатов, размытых фото и т.п. В этой работы мы решаем сразу несколько задач. В них мы использовали решения «из коробки», если они давали необходимое и достаточное качество или проводили исследования и брали наиболее подходящий метод:
Удаление дубликатов (брали векторы фото с помощью архитектуры трансформеров clip-ViT-B-32 и оценивали косинусную меру между ними)
Поворот фото в верную ориентацию (с помощью классификатора EfficientNet_V2_S)
Удаление вотермарки (пробовали разные решения, идеал пока не нашли)
Увеличение разрешения фото (с помощью модели EDSR на Python, подробнее про решение можно почитать тут)
Общее улучшение фото: яркость, контраст, резкость и пр. (использовали основу из DPED — Deep Convolutional Networks, но доработали и сделали интерфейс для удобства)
Мы заметили, что при публикации объявлений о продаже или аренде квартиры, пользователи часто загружают не очень качественные фото или большое число одинаковых или почти одинаковых изображений. Чтобы избежать этой проблемы, мы научили наши модели определять дубли, а также похожие фотографии, снятые даже со слегка измененного ракурса.


Таким образом, определяя косинусную меру («схожесть» двух векторов, которые нейронная сеть получает из изображений), мы можем удалить абсолютные (полные) или визуальные дубли, а также повёрнутые и отражённые дубли существующих изображений. Из дублей остаются наиболее информативные фото — где лучше ракурс, больше деталей, выше качество/разрешение и прочие факторы. В итоге получаем на выходе адекватный набор фото по каждой квартире, который не будет содержать лишней для покупателя или арендатора информации.
from sentence_transformers import SentenceTransformer, util
from PIL import Image
import os
from pathlib import Path
import pandas as pd
from tqdm import tqdm
import shutil
import numpy as np
def duplicates(
img_arrays,
similarity_threshold: float = 0.9,
batch_size: int = 64,
device: str = 'cuda:0'
) -> list:
if len(img_arrays) == 0:
return None
elif len(img_arrays) == 1:
return [0]
model = SentenceTransformer('clip-ViT-B-32')
img_embs = model.encode(
[Image.fromarray(img) for img in img_arrays],
batch_size=batch_size,
convert_to_tensor=True,
device=device
# show_progress_bar=True
)
img_data = {i: emb for i, emb in zip(range(len(img_arrays)), img_embs)}
img_unique = [list(img_data.keys())[0]]
for img_to_compare in list(img_data.keys())[1:]:
threshold_overcomed = False
for img_compared in img_unique:
metric = util.cos_sim(img_data[img_to_compare], img_data[img_compared])
if metric >= similarity_threshold:
threshold_overcomed = True
break
if not threshold_overcomed:
img_unique.append(img_to_compare)
# img_not_duplicated = [img_arrays[i] for i in img_unique]
is_duplicate = np.ones(len(img_arrays), dtype=int)
is_duplicate[img_unique] = 0
return is_duplicate.tolist(
После чего мы можем с помощью моделей (использовали проект DPED, который с помощью deep learning подхода переводит фотографии со смартфона в изображения качества DSLR) исправить плохое освещение на фотографиях, увеличить контрастность и даже резкость изображений.
В завершении процесса обработки фото с помощью решения EDSR (Enhanced Deep Super-Resolution) увеличить исходное изображение, т.к. пользователи не всегда делают фотографии подходящего качества. Как видите, по сравнению с бикубической интерполяцией х4 (наивный подход), реализация через нейросеть даёт более качественный результат, который можно использовать. Причем реализация максимально простая, просто взгляните на код, который, по сути, делает всё, что нам нужно, используя одну лишь библиотеку cv2.
import cv2
from cv2 import dnn_superres
img_orig = cv2.imread('path/to/img.jpg')
sr = dnn_superres.DnnSuperResImpl_create()
https://github.com/Saafke/EDSR_Tensorflow/tree/master/models/
sr.readModel(f'path/to/EDSR_x{scale_coef}.pb')
sr.setModel("edsr", scale_coef)
sr.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
sr.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
img_upscaled_edsr = sr.upsample(img_orig)
Одной из задач, которую нам предстоит решить, является удаление водяных знаков с фотографий. Нет, мы ни в коем случае не хотим использовать нелегально полученные фото, но ситуации бывают разные. Например, смартфон пользователя делает надпись с названием гаджета на фото, или же своё лого накладывает приложение для обработки фотографий или сервис для облачного хранения. Модели для обучения это только мешает. Решения без нейросетей (cv2 инструменты) не работают или работают плохо — основной упор, чтобы «отыскать» водяной знак по разнице контраста, цветовой гаммы и прочие спекуляции на разнице цвета пикселей. Получается сильно искаженное изображение, см. пример ниже.

Оригинал

Вариант 1 (искажение контраста)

Вариант 2 (искажение геометрии)
Открытые решения на машинном обучении зачастую требуют маску водяного знака (его форма и как он выглядит), что не всегда получается достать. Хочется удалять произвольный водяной знак, предварительно не имея информации о нем. Другая часть решений, часто только находит окрестность вотермарка, но никак его не убирает. Нужны дополнительные модели/ресурсы, чтобы дальше его обрабатывать. Остальная часть решений просто не работает или работает плохо.
На текущий момент мы протестировали различные варианты с Unet, Watermark-Removal-PyTorch, deep-image-prior и другие решения, но не нашли подходящее готовое или полуготовое решение. Своими силами попытались сделать решение на основе архитектур U-Net, GAn«ов, но это получалось похоже. Можно было дополнительно уделить время на доработку решений, причем скорее всего успех был бы, но обратились к другим источникам и получили качественные фото без водяных знаков для дальнейшей разработки. Таким образом, потребность в решении отпала. И такое тоже бывает, когда проблема решается не «в лоб», а другими способами. Благо, что мы готовы к экспериментам и поиску решений в различных источниках.
Что дальше? Генеративные модели!
Не буду сильно забегать вперёд, но вкратце скажу про одну из ключевых тем, над которыми мы работаем. Да, как и весь мир, увлеклись генеративными моделями. Мы уже умеем генерировать дизайн по проекту квартиры, менять его, даже переносить стиль и пр., но разумеется, есть определенные сложности.

Например, есть нюансы в обучении модели, в случае GAN есть проблема «моды коллапса» (mode collapse), когда модель начинает генерировать очень ограниченный набор изображений и не может воспроизвести все многообразие данных обучающей выборки. Есть пока и проблемы с качеством, даже при правильной настройке и обучении, генерируемые изображения могут быть менее реалистичными, чем мы бы хотели. Иногда они могут содержать неестественные артефакты или искажения. Плюс, мы не можем контролировать процесс генерации, точнее, можем, но ограниченно, а также пока это довольно сложно и долго.

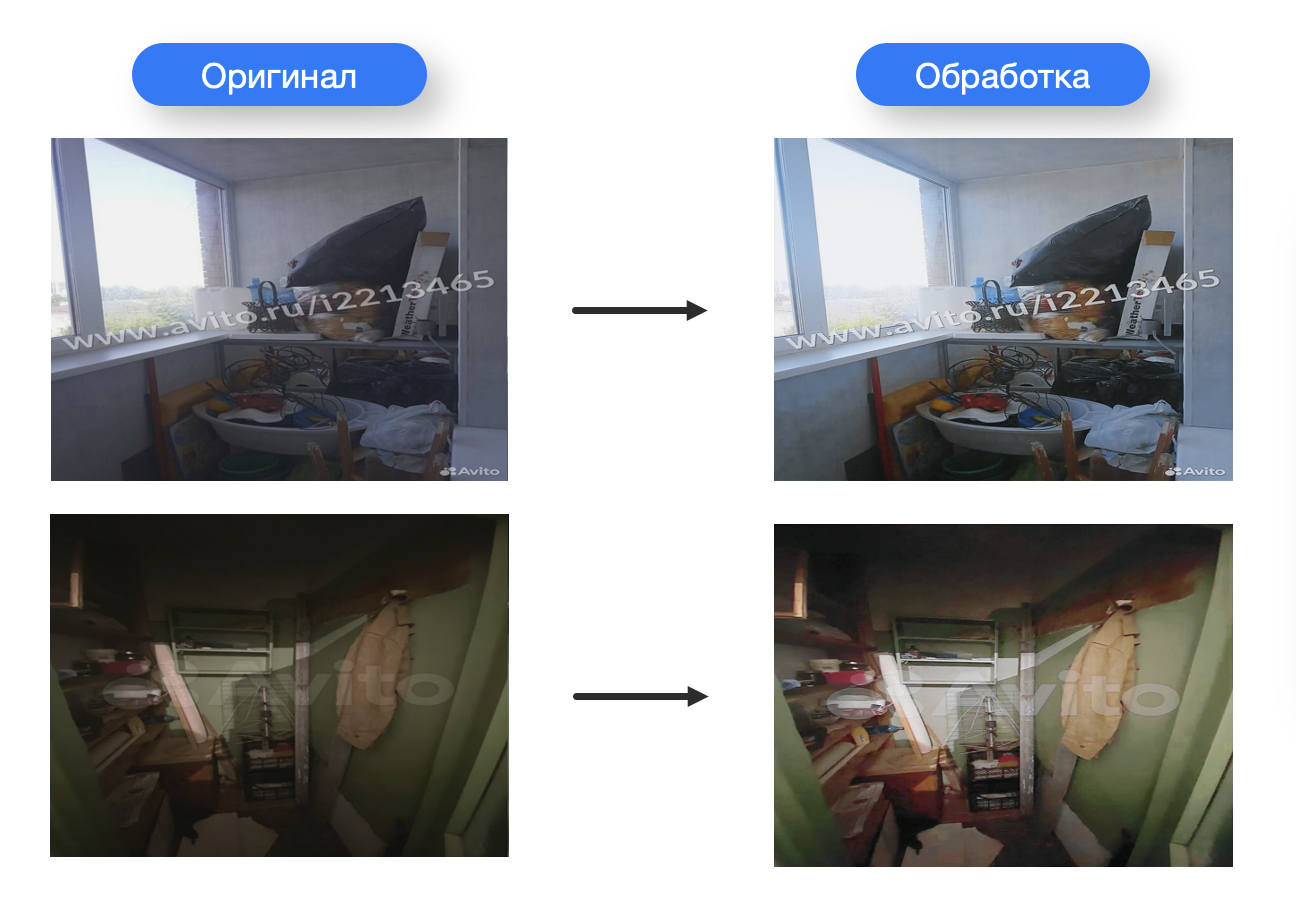
Однако мы активно работаем в направлении GAN, т.к. эти модели могут помочь создавать нам необходимый контент гораздо дешевле и проще, чем это делают люди. Кроме того, мы можем использовать такой контент для расширения существующих наборов данных или улучшения качества данных. И совсем в мечтах пока использование генеративных моделей для создания интерактивных систем, которые реагируют на ввод пользователя и могут генерировать соответствующий контент в реальном времени. На примерах ниже мы, например, используем Stable Diffusion + ControlNet. Как видите, готовые решения тут не помогли и нам удалось с помощью доработок базовых библиотек получить весьма неплохой результат. Как будто наша «мечта» уже перешла в реальность, но есть ещё куда расти.


Замахиваемся мы и на NeRF-модели, чтобы генерировать полноценное 3D. Как вы понимаете, для стройки и дизайна квартир это просто киллер-фича. Neural Raiance Fields (NeRF) — это полносвязная нейронная сеть, которая может генерировать новые ракурсы сложных 3D-сцен, основываясь на частичном наборе 2D изображений. Можно сказать, что это фотограмметрия, подкрепленная искусственным интеллектом.Однако, разумеется, NeRF — это алгоритм, требующий больших вычислительных ресурсов, и обработка сложных сцен может занять часы или дни. Тем не менее, мы испытываем сейчас разные варианты и стремимся оптимизировать производительность.

Вместо итогов
Мы всеми силами сейчас приближаем это будущее и надеемся, что скоро сможем вам кое-что показать. Как видите, наша работа почти не связана со стройкой. Точнее, для нас создание дома — это фундамент, источник данных и, одновременно, финальный результат. Но чтобы его достичь, мы используем множество различных механизмов и инструментов, чтобы изучить данные, корректно их обработать и передать тем, кто сможет их правильно применить. Как видите, стройка дома в Самолете — это уже не только и не столько сама стройка, сколько изучение, анализ, огромная подготовительная и постобработка, да так, что большую часть этого можно назвать IT-проектом, где само строительство — это лишь один из спринтов. Расскажите в комментариях, о каких этапах, которые я упомянул в посте, вам было бы интересно почитать подробнее?
