Масштабирование ClickHouse, управление миграциями и отправка запросов из PHP в кластер
В предыдущей статье мы поделились своим опытом внедрения и использования СУБД ClickHouse в компании СМИ2. В текущей статье мы затронем вопросы масштабирования, которые возникают с увеличением объема анализируемых данных и ростом нагрузки, когда данные уже не могут храниться и обрабатываться в рамках одного физического сервера. Также мы расскажем о разработанном нами инструменте для миграции DDL-запросов в ClickHouse-кластер.
ClickHouse специально проектировался для работы в кластерах, расположенных в разных дата-центрах. Масштабируется СУБД линейно до сотен узлов. Так, например, Яндекс.Метрика на момент написания статьи — это кластер из более чем 400 узлов.
ClickHouse предоставляет шардирование и репликацию «из коробки», они могут гибко настраиваться отдельно для каждой таблицы. Для обеспечения реплицирования требуется Apache ZooKeeper (рекомендуется использовать версию 3.4.5+). Для более высокой надежности мы используем ZK-кластер (ансамбль) из 5 узлов. Следует выбирать нечетное число ZK-узлов (например, 3 или 5), чтобы обеспечить кворум. Также отметим, что ZK не используется в операциях SELECT, а применяется, например, в ALTER-запросах для изменений столбцов, сохраняя инструкции для каждой из реплик.
Шардирование
Шардирование в ClickHouse позволяет записывать и хранить порции данных в кластере распределенно и обрабатывать (читать) данные параллельно на всех узлах кластера, увеличивая throughput и уменьшая latency. Например, в запросах с GROUP BY ClickHouse выполнит агрегирование на удаленных узлах и передаст узлу-инициатору запроса промежуточные состояния агрегатных функций, где они будут доагрегированы.
Для шардирования используется специальный движок Distributed, который не хранит данные, а делегирует SELECT-запросы на шардированные таблицы (таблицы, содержащие порции данных) с последующей обработкой полученных данных. Запись данных в шарды может выполняться в двух режимах: 1) через Distributed-таблицу и необязательный ключ шардирования или 2) непосредственно в шардированные таблицы, из которых далее данные будут читаться через Distributed-таблицу. Рассмотрим эти режимы более подробно.
В первом режиме данные записываются в Distributed-таблицу по ключу шардирования. В простейшем случае ключом шардирования может быть случайное число, т. е. результат вызова функции rand (). Однако в качестве ключа шардирования рекомендуется брать значение хеш-функции от поля в таблице, которое позволит, с одной стороны, локализовать небольшие наборы данных на одном шарде, а с другой — обеспечит достаточно ровное распределение таких наборов по разным шардам в кластере. Например, идентификатор сессии (sess_id) пользователя позволит локализовать показы страниц одному пользователю на одном шарде, при этом сессии разных пользователей будут распределены равномерно по всем шардам в кластере (при условии, что значения поля sess_id будут иметь хорошее распределение). Ключ шардирования может быть также нечисловым или составным. В этом случае можно использовать встроенную хеширующую функцию cityHash64. В рассматриваемом режиме данные, записываемые на один из узлов кластера, по ключу шардирования будут перенаправляться на нужные шарды автоматически, увеличивая, однако, при этом трафик.
Более сложный способ заключается в том, чтобы вне ClickHouse вычислять нужный шард и выполнять запись напрямую в шардированную таблицу. Сложность здесь обусловлена тем, что нужно знать набор доступных узлов-шардов. Однако в этом случае запись становится более эффективной, и механизм шардирования (определения нужного шарда) может быть более гибким.
Репликация
ClickHouse поддерживает репликацию данных, обеспечивая целостность данных на репликах. Для репликации данных используются специальные движки MergeTree-семейства:
- ReplicatedMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedSummingMergeTree
Репликация часто применяется вместе с шардированием. Например, кластер из 6 узлов может содержать 3 шарда по 2 реплики. Следует отметить, что репликация не зависит от механизмов шардирования и работает на уровне отдельных таблиц.
Запись данных может выполняться в любую из таблиц-реплик, ClickHouse выполняет автоматическую синхронизацию данных между всеми репликами.
Примеры конфигурации ClickHouse-кластера
В качестве примеров будем рассматривать различные конфигурации для четырех узлов: ch63.smi2, ch64.smi2, ch65.smi2, ch66.smi2. Настройки содержатся в конфигурационном файле /etc/clickhouse-server/config.xml.
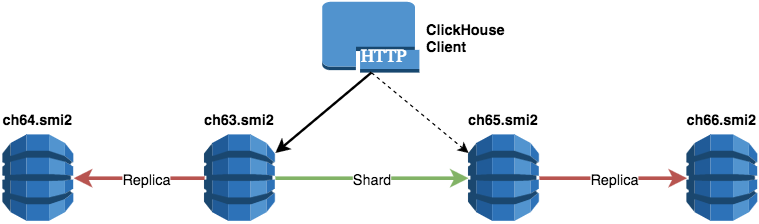
Один шард и четыре реплики
ch63.smi2
ch64.smi2
ch65.smi2
ch66.smi2
Пример схемы создания таблицы:

Пример SQL-запроса создания таблицы для указанной конфигурации:
CREATE DATABASE IF NOT EXISTS dbrepikator
;
CREATE TABLE IF NOT EXISTS dbrepikator.anysumming_repl_sharded (
event_date Date DEFAULT toDate(event_time),
event_time DateTime DEFAULT now(),
body_id Int32,
views Int32
) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{repikator_replica}/dbrepikator/anysumming_repl_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192)
;
CREATE TABLE IF NOT EXISTS dbrepikator.anysumming_repl AS dbrepikator.anysumming_repl_sharded
ENGINE = Distributed( repikator, dbrepikator, anysumming_repl_sharded , rand() )Преимущество данной конфигурации:
- Наиболее надежный способ хранения данных.
Недостатки:
- Для большинства задач будет храниться избыточное количество копий данных.
- Поскольку в данной конфигурации только 1 шард, SELECT-запрос не может выполняться параллельно на разных узлах.
- Требуются дополнительные ресурсы на многократное реплицирование данных между всеми узлами.
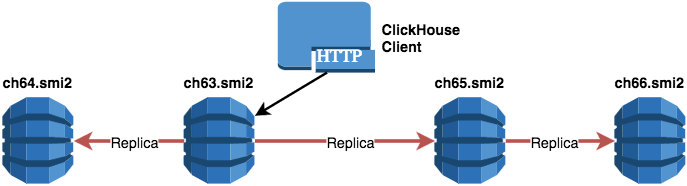
Четыре шарда по одной реплике
ch63.smi2
ch64.smi2
ch65.smi2
ch66.smi2
Пример SQL-запроса создания таблицы для указанной конфигурации:
CREATE DATABASE IF NOT EXISTS testshara
;
CREATE TABLE IF NOT EXISTS testshara.anysumming_sharded (
event_date Date DEFAULT toDate(event_time),
event_time DateTime DEFAULT now(),
body_id Int32,
views Int32
) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{sharovara_replica}/sharovara/anysumming_sharded_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192)
;
CREATE TABLE IF NOT EXISTS testshara.anysumming AS testshara.anysumming_sharded
ENGINE = Distributed( sharovara, testshara, anysumming_sharded , rand() )Преимущество данной конфигурации:
- Поскольку в данной конфигурации 4 шарда, SELECT-запрос может выполняться параллельно сразу на всех узлах кластера.
Недостаток:
- Наименее надежный способ хранения данных (потеря узла приводит к потере порции данных).
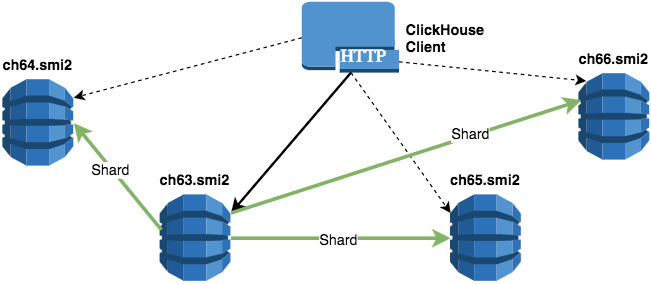
Два шарда по две реплики
ch63.smi2
ch64.smi2
ch65.smi2
ch66.smi2
Пример SQL-запроса создания таблицы для указанной конфигурации:
CREATE DATABASE IF NOT EXISTS dbpulse
;
CREATE TABLE IF NOT EXISTS dbpulse.normal_summing_sharded (
event_date Date DEFAULT toDate(event_time),
event_time DateTime DEFAULT now(),
body_id Int32,
views Int32
) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{pulse_replica}/pulse/normal_summing_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192)
;
CREATE TABLE IF NOT EXISTS dbpulse.normal_summing AS dbpulse.normal_summing_sharded
ENGINE = Distributed( pulse, dbpulse, normal_summing_sharded , rand() )Данная конфигурация воплощает лучшие качества из первого и второго примеров:
- Поскольку в данной конфигурации 2 шарда, SELECT-запрос может выполняться параллельно на каждом из шардов в кластере.
- Относительно надежный способ хранения данных (потеря одного узла кластера не приводит к потере порции данных).
Пример конфигурации кластеров в ansible
Конфигурация кластеров в ansible может выглядеть следующим образом:
- name: "pulse"
shards:
- { name: "01", replicas: ["ch63.smi2", "ch64.smi2"]}
- { name: "02", replicas: ["ch65.smi2", "ch66.smi2"]}
- name: "sharovara"
shards:
- { name: "01", replicas: ["ch63.smi2"]}
- { name: "02", replicas: ["ch64.smi2"]}
- { name: "03", replicas: ["ch65.smi2"]}
- { name: "04", replicas: ["ch66.smi2"]}
- name: "repikator"
shards:
- { name: "01", replicas: ["ch63.smi2", "ch64.smi2","ch65.smi2", "ch66.smi2"]}PHP-драйвер для работы с ClickHouse-кластером
В предыдущей статье мы уже рассказывали о нашем open-source PHP-драйвере для ClickHouse.
Когда количество узлов становится большим, управление кластером становится неудобным. Поэтому мы разработали простой и достаточно функциональный инструмент для миграции DDL-запросов в ClickHouse-кластер. Далее мы кратко опишем на примерах его возможности.
Для подключения к кластеру используется класс ClickHouseDB\Cluster:
$cl = new ClickHouseDB\Cluster(
['host'=>'allclickhouse.smi2','port'=>'8123','username'=>'x','password'=>'x']
);
В DNS-записи allclickhouse.smi2 перечислены IP-адреса всех узлов: ch63.smi2, ch64.smi2, ch65.smi2, ch66.smi2, что позволяет использовать механизм Round-robin DNS.
Драйвер выполняет подключение к кластеру и отправляет ping-запросы на каждый узел, перечисленный в DNS-записи.
Установка максимального времени подключения ко всем узлам кластера настраивается следующим образом:
$cl->setScanTimeOut(2.5); // 2500 ms
Проверка состояния реплик кластера выполняется так:
if (!$cl->isReplicasIsOk())
{
throw new Exception('Replica state is bad , error='.$cl->getError());
}
Состояние ClickHouse-кластера проверяется следующим образом:
- Проверяются соединения со всеми узлами кластера, перечисленными в DNS-записи.
- На каждый узел отправляется SQL-запрос, который позволяет определить состояние всех реплик ClickHouse-кластера.
Скорость выполнения запроса может быть увеличена, если не вычитывать значения столбцов log_max_index, log_pointer, total_replicas, active_replicas, при получении данных из которых выполняются запросы на ZK-кластер.
Для облегченной проверки в драйвере необходимо установить специальный флаг:
$cl->setSoftCheck(true);
Получение списка всех доступных кластеров делается следующим образом:
print_r($cl->getClusterList());
// result
// [0] => pulse
// [1] => repikator
// [2] => sharovaraНапример, получить конфигурацию кластеров, которые были описаны выше, можно так:
foreach (['pulse','repikator','sharovara'] as $name)
{
print_r($cl->getClusterNodes($name));
echo "> $name , count shard = ".$cl->getClusterCountShard($name)." ; count replica = ".$cl->getClusterCountReplica($name)."\n";
}
//Результат:
//> pulse , count shard = 2 ; count replica = 2
//> repikator , count shard = 1 ; count replica = 4
//> sharovara , count shard = 4 ; count replica = 1
Получение списка узлов по названию кластера или из шардированных таблиц:
$nodes=$cl->getNodesByTable('sharovara.body_views_sharded');
$nodes=$cl->getClusterNodes('sharovara');
Получение размера таблицы или размеров всех таблиц через отправку запроса на каждый узел кластера:
foreach ($nodes as $node)
{
echo "$node > \n";
print_r($cl->client($node)->tableSize('test_sharded'));
print_r($cl->client($node)->tablesSize());
}
// Упрощенный вариант использования
$cl->getSizeTable('dbName.tableName');
Получение списка таблиц кластера:
$cl->getTables()Определение лидера в кластере:
$cl->getMasterNodeForTable('dbName.tableName') // Лидер имеет установленный флаг is_leader=1
Запросы, связанные, например, с удалением или изменением структуры, отправляются на узел с установленным флагом is_leader.
Очистка данных в таблице в кластере:
$cl->truncateTable('dbName.tableName')`Инструмент миграции DDL-запросов
Для миграции DDL-запросов для реляционных СУБД в нашей компании используется MyBatis Migrations.
Об инструментах миграции на Хабре уже писали:
- Версионная миграция структуры базы данных: основные подходы
- Простые миграции с PHPixie Migrate
- Управление скриптами миграции или MyBatis Scheme Migration Extended
Для работы с ClickHouse-кластером нам требовался аналогичный инструмент.
На момент написания статьи ClickHouse имеет ряд особенностей (ограничений) связанных с DDL-запросами. Цитата:
Реплицируются INSERT, ALTER (см. подробности в описании запроса ALTER). Реплицируются сжатые данные, а не тексты запросов. Запросы CREATE, DROP, ATTACH, DETACH, RENAME не реплицируются — то есть, относятся к одному серверу. Запрос CREATE TABLE создаёт новую реплицируемую таблицу на том сервере, где выполняется запрос;, а если на других серверах такая таблица уже есть — добавляет новую реплику. Запрос DROP TABLE удаляет реплику, расположенную на том сервере, где выполняется запрос. Запрос RENAME переименовывает таблицу на одной из реплик — то есть, реплицируемые таблицы на разных репликах могут называться по разному.
Команда разработчиков ClickHouse уже анонсировала работу в этом направлении, но в настоящее время приходится решать эту задачу внешним инструментарием. Мы создали простой прототип инструмента phpMigrationsClickhouse для миграции DDL-запросов в ClickHouse-кластер. И в наших планах — абстрагировать phpMigrationsClickhouse от языка PHP.
Опишем алгоритм, использующийся в настоящий момент в phpMigrationsClickhouse, который может быть реализован на любом другом языке программирования.
На текущий момент инструкция по миграции в phpMigrationsClickhouse состоит из:
- SQL-запросов, которые нужно накатить и откатить в случае ошибки;
- имени кластера, в котором нужно выполнить SQL-запросы.
Создадим PHP-файл, содержащий следующий код:
$cluster_name = 'pulse';
$mclq = new \ClickHouseDB\Cluster\Migration($cluster_name);
$mclq->setTimeout(100);Добавим SQL-запросы, которые нужно накатить:
$mclq->addSqlUpdate(" CREATE DATABASE IF NOT EXISTS dbpulse ");
$mclq->addSqlUpdate("
CREATE TABLE IF NOT EXISTS dbpulse.normal_summing_sharded (
event_date Date DEFAULT toDate(event_time),
event_time DateTime DEFAULT now(),
body_id Int32,
views Int32
) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{pulse_replica}/pulse/normal_summing_sharded', '{replica}', event_date, (event_date, event_time, body_id), 8192)
"); Добавим SQL-запросы для выполнения отката в случае ошибки:
$mclq->addSqlDowngrade(' DROP TABLE IF EXISTS dbpulse.normal_summing_sharded ');
$mclq->addSqlDowngrade(' DROP DATABASE IF EXISTS dbpulse '); Существует 2 стратегии накатывания миграций:
- отправка каждого отдельного SQL-запроса на один сервер с переходом к следующему SQL-запросу;
- отправка всех SQL-запросов на один сервер с переходом к следующему серверу.
При возникновении ошибки возможны следующие варианты:
- выполнение downgrade-запроса на все узлы, на которых уже были произведены upgrade-запросы;
- ожидание перед отправкой upgrade-запросов на другие сервера;
- выполнение downgrade-запроса на всех серверах в случае возникновения ошибки.
Отдельное место занимают ошибки, когда не известно состояние кластера:
- ошибка timeout соединения;
- ошибка связи с сервером.
Принцип работы PHP-кода при выполнении миграции следующий:
// Получение списка IP-адресов узлов кластера
$node_hosts=$this->getClusterNodes($migration->getClusterName());
// Получение downgrade-запроса
$sql_down=$migration->getSqlDowngrade();
// Получение upgrade-запроса
$sql_up=$migration->getSqlUpdate();
// Выполнение upgrade-запроса на каждый узел и, в случае ошибки, выполнение downgrade-запроса
$need_undo=false;
$undo_ip=[];
foreach ($sql_up as $s_u) {
foreach ($node_hosts as $node) {
// Выполнение upgrade-запроса
$state=$this->client($node)->write($s_u);
if ($state->isError()) {
$need_undo = true;
} else {
// OK
}
if ($need_undo) {
// Фиксация узлов кластера, где произошла ошибка
$undo_ip[$node]=1;
break;
}
}
}
// Проверка успешности выполнения upgrade-запросов на всех узлах кластера
if (!$need_undo)
{
return true; // OK
}В случае ошибки выполняется отправка на все узлы кластера downgrade-запроса:
foreach ($node_hosts as $node) {
foreach ($sql_down as $s_u) {
try{
$st=$this->client($node)->write($s_u);
} catch (Exception $E) {
// Оповещение пользователя об ошибке при выполнении downgrade-запроса
}
}
}Мы продолжим цикл материалов, посвященных нашему опыту работы с ClickHouse.
В завершение статьи мы хотели бы провести небольшой опрос.
