Машинное зрение для ритейла. Как прочитать ценники в магазине
Машинное зрение — очень актуальная тема в наши дни. Для решения задачи по распознаванию магазинных ценников с использованием нейронных сетей мы выбрали фреймворк TensorFlow.
В статье пойдет речь именно о том, как с его помощью локализовать и идентифицировать несколько объектов на одном магазинном ценнике, а также распознать его содержимое. Похожая задача распознавания ценников IKEA уже решалась на Хабре с применением классических инструментов обработки изображений, доступных в библиотеке OpenCV.
Отдельно хотелось бы отметить, что решение может работать как на платформе SAP HANA в связке с Tensorflow Serving, так и на SAP Cloud Platform.
Задача распознавания цены товара актуальна и для покупателей, которые хотят «шарить» цены друг с другом и выбирать магазин для покупок, и для ритейлеров — они хотят узнавать про цены конкурентов в режиме реального времени.
Хватит лирики — гоу в технику!
Инструментарий
Для детекции и классификации изображений мы использовали сверточные нейронные сети, реализованные в библиотеке TensorFlow и доступные для управления через Object Detection API.
TensorFlow Object Detection API — это метафреймворк с открытым исходным кодом на основе TensorFlow, который упрощает создание, обучение и развертывание моделей для обнаружения объектов.
После детекции нужного объекта распознавание текста на нём проходило с помощью Tesseract-а — библиотеки для распознавания символов. Еще с 2006 года Tesseract считается одной из наиболее точных библиотек OCR, доступной в open source.
Возможно, что вы зададите вопрос — почему же не вся обработка сделана на TF? Ответ очень прост — это потребовало бы значительно больше времени на реализацию, а его и так было не много. Проще было пожертвовать скоростью обработки и собрать готовый прототип, чем заморачиваться с самодельным OCR.
Создание и подготовка датасета
Для начала было необходимо собрать материалы для работы. Мы посетили 3 магазина и сделали около 400 фотографий разных ценников на камеру мобильного телефона в автоматическом режиме
Примеры фотографий:

Рис. 1. Пример изображения ценника

Рис. 2. Пример изображения ценника
После необходимо все фотографии ценников обработать и разметить. В процессе сбора изображений мы старались собирать качественные изображения (без артефактов): ценники примерно одинакового формата, без размытия, значительных поворотов и т.д. Это делалось для облегчения дальнейшего сопоставления содержимого на реальном ценнике и его цифрового образа. Однако, если обучить нейронную сеть только на имеющихся качественных изображениях, это весьма закономерно приведет к тому, что уверенность модели при идентификации искаженных примеров будет значительно падать. Чтобы обучить нейронную сеть быть устойчивой к подобным ситуациям, мы воспользовались известной процедурой расширения обучающего множества искаженными вариантами изображений (аугментацией). Для дополнения обучающей выборки мы применили алгоритмы из библиотеки Imgaug: сдвиги, небольшие повороты, гауссово размытие, шум. Искаженные изображения были добавлены в выборку, что увеличило ее примерно в 5 раз (с 300 до 1500 изображений).
Для разметки изображения и выделения объектов использовалась программа LabelImg, которая доступна в свободном доступе. Она позволяет выделять необходимые объекты на изображении прямоугольником и присваивать каждой ограничивающей рамке нужный класс. Все координаты и метки созданных рамок для каждой фотографии сохраняются в отдельном XML файле.
На каждой фотографии выделялись следующие объекты: ценник товара, цена товара, наименование товара и штрих-код товара на ценнике. На некоторых примерах изображений, где это было логически обоснованно, области размечались с перекрытием.

Рис. 3. Пример фотографии пары ценников, размеченных в LabelImg. Выделены области с описанием товара, ценой и штрих-кодом.

Рис. 4. Пример фотографии ценника, размеченной в LabelImg. Выделены области с описанием товара, ценой и штрих-кодом.
После того, как все фотографии обработаны и размечены, подготавливаем датасет с разделением всех фотографий и файлов меток на обучающую и тестовую выборку. Обычно берут 80% обучающей выборки к 20% тестовой и перемешивают случайным образом.
Далее на машину, где будет происходить обучение модели, необходимо установить все необходимые библиотеки. В первую очередь устанавливаем библиотеку машинного обучения TensorFlow. В зависимости от типа вашей системы и необходимо установить дополнительную библиотеку для вычисления на GPU. Далее устанавливаем библиотеку Tensorflow Object Detection API и дополнительные библиотеки работы с изображениями и графиками. Ниже указан список библиотек, которые мы использовали в нашей работе:
TensorFlow-GPU v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Pillow 1.0, lxml, tf Slim, Jupyter notebook, Matplotlib
Tensorflow, Cython, Cocoapi; Opencv-python; Pandas
Когда все этапы установки завершены, можно переходить к подготовке данных и настройке параметров обучения.
Обучение модели
Для решения нашей задачи мы воспользовались двумя вариантами предобученной нейронной сети MobileNet V2 и Faster-RCNN V2 на датасете coco в качестве экстракторов свойств изображений. Модели были дообучены на 4 новых класса: ценник, описание товара, цена, штрих-код. В качестве основной мы выбрали MobileNet V2, которая представляет собой относительно простую модель, позволяющую обеспечить приемлемое качество при приятной скорости работы. MobileNet V2 позволяет реализовать распознавание изображений даже на мобильном устройстве.
Для начала необходимо указать библиотеке Tensorflow Object Detection API количество меток, а также наименования этих меток.
Последнее, что нужно сделать перед обучением — создать карту ярлыков и отредактировать файл конфигурации. Карта ярлыков сообщает модели и сопоставляет имена классов с номерами идентификаторов классов для каждого объекта.

Наконец, необходимо сконфигурировать источники обучения для Object Detection чтобы определить, какая модель и какие параметры будут использоваться для обучения. Это последний шаг перед началом обучения.

Процедура обучения запускается командой:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/mobilenet.config
Если все настроено правильно, TensorFlow инициализирует дообучение нейросети. Инициализация может занять до 30 секунд до старта фактического обучения. По мере дообучения нейронной сети на каждом шаге будет отображаться значение функции ошибки алгоритма (loss). Для MobileNet V2 начальное значение функции потерь — около 20. Модель следует обучать, пока функция потерь не снизится до значения, примерно равного 2. Для визуализации процесса обучения нейросети можно воспользоваться удобной утилитой TensorBoard.
Команда: tensorboard --logdir=training
Команда инициализирует веб-интерфейс на локальной машине, который будет доступен по адресу localhost:6006. После остановки процедуру обучения можно возобновить позднее, используя для этого чекпоинты, которые сохраняются каждые 5 минут.
Распознавание ценников и его элементов
Когда обучение завершено, последним шагом является создание графа нейронной сети. Это осуществляется консольной командой, где под звездочками необходимо указать наибольший номер cpkt-файла, существующий в директории обучения.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2.config --trained_checkpoint_prefix training/model.ckpt-**** --output_directory inference_graph
После этой процедуры классификатор обнаружения объектов готов к работе. Для проверки распознавания изображения достаточно запустить скрипт, который идет вместе с библиотекой Tensorflow Object Detection с указанием модели, которую предварительно обучали, и фотографии для распознавания. Стандартный пример скрипта на Python приведен по ссылке.
В нашем примере на распознавание одной фотографии моделью ssd mobilenet на простом ноутбуке уходит примерно 1,5 секунды.

Рис. 5. Результат распознавания изображения с ценниками в тестовой выборке

Рис. 6. Результат распознавания изображения с ценниками в тестовой выборке
Когда мы убедились, что ценники нормально детектируются, необходимо научить модель считывать информацию с отдельных элементов: цена товара, имя товара, штрих-код. Для этого есть доступные на Python библиотеки для распознавания символов и штрих-кодов на фотографиях — Pyzbar и Tesseract.
Перед тем, как начинать распознавать символы и штрих-коды на фотографии, необходимо эту фотографию порезать на необходимые нам элементы — чтобы увеличить скорость и не распознавать лишнюю информацию, которая не входит в ценник. Также необходимо «вытащить» координаты объектов, которые модель распознала вместе с их классами.

Затем мы используем эти координаты, чтобы разрезать нашу фотографию на части для распознавания только необходимой области.



Рис. 7. Пример выделенных частей ценника
Далее все вырезанные области передаем библиотекам: имя товара и цену товара передаем в tesseract, а штрих-код — в pyzbar, и получаем результат распознавания.


Рис. 8. Пример распознанного содержания область ценника.
На этом этапе с распознаванием текста и штрих-кода могут возникнуть проблемы, если исходное изображение было в низком разрешении или размытое. Если цена может быть распознана нормально из-за больших цифр на ценнике, то наименование товара и штрих-код будет определен плохо или не определен вовсе. Для этого рекомендуется не использовать маленькие фотографии для распознавания, а также загружать изображения без шумов и сильных искажений — например, без отсутствия правильной фокусировки.
Пример распознавания плохих изображений:



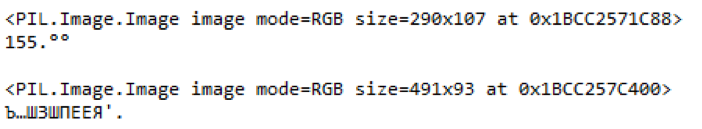
Рис. 9. Пример выделенных частей размытого ценника и распознанного содержания
В этом примере можно увидеть, что, если цена товара была распознана более менее правильно на изображении плохого качества, то с наименованием товара библиотека справиться не смогла. А штрих-код не подлежит распознаванию вовсе.
Тот же текст в хорошем качестве.

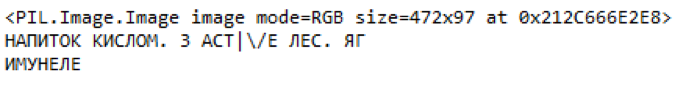
Рис. 10. Пример выделенных частей ценника и распознанного содержания
Выводы
В конечном итоге нам удалось получить модель приемлемого качества с низким процентом ошибок и высоким процентом обнаружения релевантных объектов. Faster-RCNN Inception V2 имеет лучшее качество распознавания, чем MobileNet SSD V2, но примерно на порядок уступает в скорости, что является существенным ограничением.
Полученная точность распознавания ценника на отложенной выборке из 50 изображений составляет 100%, то есть все ценники были успешно идентифицированы на всех фотографиях. Точность распознавания областей со штрих-кодом и ценой составила 90%. Точность распознавания области текста — 85%. Точность чтения цены при этом была около 95%, а текста — 80–85%. Дополнительно в качестве эксперимента приводим результат распознавания ценника, который совершенно отличается от ценников в обучающей выборке.

Рис. 11. Пример распознавания нетипичных ценников, отсутствующих в обучающей выборке.
Как можно увидеть, даже с ценниками, которые существенно отличается от ценников в обучении, модели не без ошибок, но удается распознать значимые объекты на ценнике.
Что еще можно было бы сделать?
1) Недавно вышла крутая статья про автоматическую аугментацию, подход которой можно использовать
2) Готовую обученную модель можно и нужно существенно ужимать
3) Примеры публикации готовых сервисов в SCP и TFS
При подготовке прототипа и данной статьи были использованы следующие материалы:
1. Bringing Machine Learning (TensorFlow) to the enterprise with SAP HANA
2. SAP Leonardo ML Foundation — Bring Your Own Model (BYOM)
3. GitHub-репозиторий TensorFlow Object Detection
4. Статья о распознавании чеков IKEA
5. Статья о преимуществах MobileNet
6. Статья о TensorFlow Object Detection
Статью подготовили:
Сергей Абдуракипов, Дмитрий Буслов, Алексей Христенко
