Машинное обучение, предсказание будущего и анализ причин успеха в электронной коммерции

Мы продолжаем публиковать материалы с летней конференции Bitrix Summer Fest. На этот раз хотим поделиться выступлением Александра Сербула, посвящённым текущим трендам в сфере машинного обучения, доступным методикам, а также практическим способам использования математики для увеличения конверсии и удержания клиентов.
Материал ни в коем случае не претендует быть формальным и научно строгим. Воспринимайте его как лёгкое, весёлое, полезное и ознакомительное «чтиво».
В мире big-data, высшей математики и машинного обучения сейчас творится что-то невообразимое. Когда мы входим в эту область и начинаем считать деньги, которые она может дать, то оказывается, что нам необходимы знания, материалы и опыт из различных других областей. Мы с вами, как правило, разработчики. Кто-то из нас может быть с неким математическим бэкграундом, кто-то пишет хороший код, кто-то, например, дока в математической статистике. И машинное обучение как раз требует знания и навыков в этих сферах.

Причём оно не прощает нам какое-то дилетантство. А ведь очень мало кто может с достаточно высокой компетентностью разбираться во всех этих областях. И это большая проблема. Это понимают современные исследователи машинного обучения, учёные и сотрудники всевозможных компаний. Получается, что все хотят использовать машинное обучение, но нет людей, которые хорошо разбираются во всех необходимых областях и могут эклетически соединять компоненты воедино.
Если обратиться к Wikipedia или Google в надежде понять, что такое логистическая регрессия, то можно сойти с ума. Нормальный человек не поймёт, что там написано. Ведь математика — это отдельная культура, которая живёт по своим законам. Это относится и к нам, разработчикам. Если я буду рассказывать какому-нибудь математику про TSP-IP стек, про диаграммы состояния, датаграммы, ссылаться на авторов Unix, то он меня тоже не поймёт. И если разработчик не имеет «достаточного» математического образования, то ему будет довольно трудно освоить теорию множеств, теорию вероятности, математическую статистику, высшую математику, ряды и многое другое. А забив по привычке в поисковик запрос, вы мало что поймёте из полученных результатов.

Вы скажете, что хороший разработчик должен знать математику и вообще уметь учиться, и обратитесь к «правильной» литературе. Например, перечитаете «Справочник по высшей математике» Выгодского. И вообще надо будет вспомнить, чему нас учили в ВУЗах, влезть в теорию вероятности, потому что матожидание, корреляционная матрица, дисперсия, среднее квадратическое отклонение, медиана, мода — всё это мы должны вроде знать и помнить. Но жизнь накладывает свою «профессинальную деформацию»: современный мир IT требует узкой специализации, поскольку быть универсалом, глубоко разбираясь в целом ряде научных и прикладных дисциплин, практически невозможно. И очень ярко это проявляется в ситуации, сложившейся вокруг больших данных и машинного обучения.
Что же делать?
На самом деле, сейчас никто не знает, что с этим делать. Но я всё-таки хочу попытаться дать рецепт. Приведу аналогию с карате. Это боевое искусство зародилось в среде японских крестьян, которые хотели противостоять вооружённым и прекрасно подготовленным самураям. Благодаря карате вооружённые палками и мотыгами крестьяне умудрялись сопротивляться воинам в доспехах с мечами и копьями.
В Big Data я хочу предложить вам использовать подход, при котором нужно знать небольшое количество вещей, но знать их хорошо. Кто-то, возможно, станет со временем сэнсэем, если будет интенсивно развиваться и читать нужную литературу.
Для начала давайте рассмотрим, какие виды машинного обучения бывают, каковы принципы их действия, как оценивать их качество и как их можно применять.
Что такое машинное обучение?
Для чего нужно машинное обучение, зачем его придумали?
Обычно разработчик решает поставленную задачу следующим образом: сел, налил кофе, придумал (взял готовый — это чаще) алгоритм, закодил его — он работает. Проблема в том, что бывают ситуации, когда логически решить задачу по причине объема данных и сложных взаимосвязей крайне сложно. Также зачастую мало времени на решение задачи. В таких случаях лучше всего, чтобы компьютер сам сделал за вас всю работу, научился принимать решения самостоятельно. Т.е. нужно сделать из него дрона и заставить его не только работать, но и думать за вас.
Основные положения теории вероятности гласят, что сесть и продумать все связи между сущностями можно, но это очень долго и дорого. Например, надо рассчитать дальность полёта снарядов, при этом есть флуктуации по массе, температуре, количеству и химическому составу пороха, по углу наклона орудия и т.д. Всё это можно учесть, но модель вы будете создавать долго и подойдёт она для конкретного случая — это дорого. Поэтому в своё время была создана теория вероятности, занимающаяся изучением случайных явлений и осуществлением операций с ними — в общем придумали «как экономить» и «сокращать путь». А с помощью машинного обучения как раз можно «научить» компьютер использовать инструменты теории вероятности, и делать он это будет априори быстрее человека.
Чему можно научить компьютер?
Во-первых, классифицировать вещи: можно определять пол (мужской/женский), классифицировать почту (спам или не спам), осуществлять мультиклассовую классификацию (камень, ножницы, бумага). Пример мультиклассовой классификации из жизни: определение дохода клиента (низкий, средний или высокий — три категории).
Компьютер также может учиться сам — это задача кластеризации — он берёт данные и понимает, как их сгруппировать — но это если вам повезёт. Есть задачи, где компьютер нужно учить. То есть существует грубо два вида обучения: с учителем и без.
Можно научить компьютер прогнозировать те или иные данные, используя регрессию. Допустим, у нас есть база данных по квартирам с их стоимостью и некими атрибутами (район, площадь, наличие детского садика рядом и т.д.). Мы обучаем модель и потом вводим новые данные, новые атрибуты, на основании которых она предсказывает цену. Это регрессия.

Каким образом компьютер учится?
Перцептрон
Люди всегда пытались узнать, как работает человеческий мозг. Но лишь сравнительно недавно удалось выяснить, что модель нейронных связей довольно проста и может быть реализована алгоритмически.
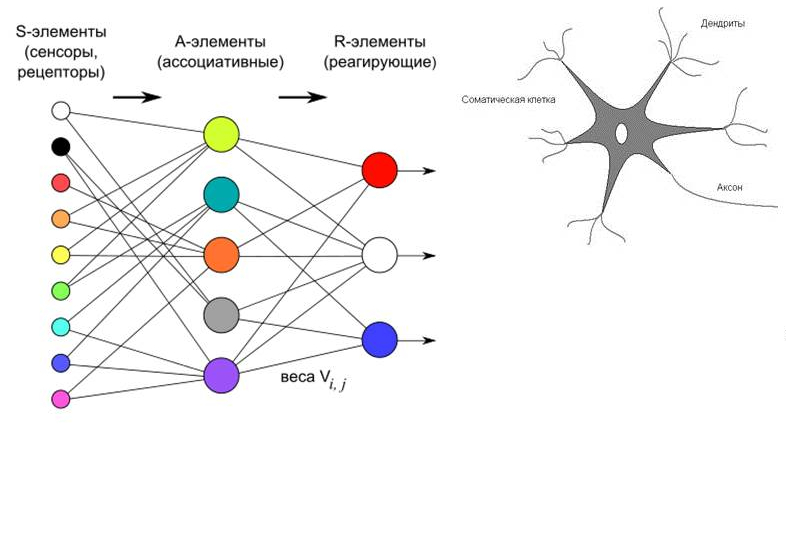
На вход подаются данные (S-элементы), затем А-элементы (нейроны) принимают какие-то значения. Мы можем назначать веса, то есть количество доходящих до каждого нейрона сигналов можно варьировать с помощью математических методов. И на выходе получаются R-элементы, то есть некий прогноз, выдаваемый нейронами.
Недостаток этого подхода, реализуемого «в лоб», в том, что нейроны могут прогнозировать, только линейно разделяя элементы в пространстве.
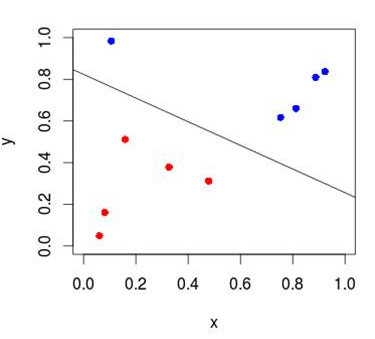
Если у нас двумерное пространство — то границей будет линия, если многомерное — то гиперплоскость. С помощью этого подхода можно решать задачи, связанные с бинарной классификацией, то есть с разделением данных на две группы.
Также можно добавить промежуточный слой. Как правило, не рекомендуется добавлять больше одного промежуточного (скрытого) слоя (иначе сильно вырастет время обучения).
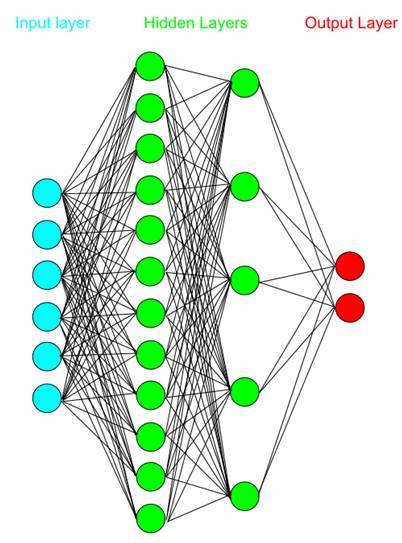
Получившаяся система представляет собой многослойный перцептрон — нейронную сеть. Благодаря дополнительному слою нейронов перцептрон может группировать данные по гораздо более сложным схемам. То есть в качестве границы будет выступать уже не прямая линия или плоскость, а гораздо более сложные линии и поверхности. Иными словами, перцептрон может аппроксимировать любую поверхность. Развивая идею, можно научиться даже распознавать лица.

На сегодняшний день перцептроны — как обычные, так и многослойные (MLP, multilayer perceptron), хорошо изучены и широко используются, в особенности, в deep learning
Байесовский идентификатор
Англичанин Томас Байес был математиком и священником. В промежутках между богослужениями он создал теорему Байеса. В ней идёт речь о вероятности одного события при условии происхождения другого взаимосвязанного события. То есть вся эта теорема визуально представляется в виде двух пересекающихся кругов.

Данная теорема и байесовский классификатор используются почти везде. Например, фильтрация почты — спам/не спам — это байесовский классификатор. Его гораздо проще закодить, чем многослойный перцептрон. Он и обучается быстрее, чем нейронная сеть. К тому же он куда доступнее для понимания. Поэтому, когда перед вами встанет задача быстро что-то классифицировать, то это самый простой вариант.
Ещё один популярный вариант для бинарной классификации — логистическая регрессия.
Дерево решений
Допустим, перед вами стоит задача быстро определить, является ли некое животное летающим или ползающим. Вы можете спрашивать, есть ли у него лапы, хвост, глаза, пищевод, нос, — это всё не приблизит к решению задачи. Достаточно спросить, есть ли у него крылья. Если да — это летающее животное.
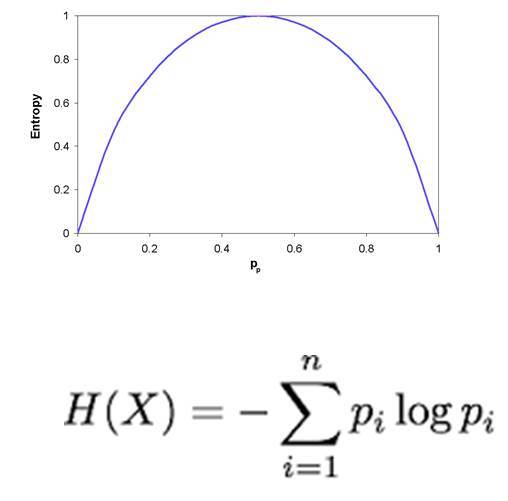
Если на входе есть атрибуты, то с помощью дерева ищутся атрибуты, которые позволяют однозначно отсечь часть входных данных, как не удовлетворяющие какому-то условию. С помощью наводящих вопросов можно очень быстро разделять множество возможных решений, пошагово уменьшая количество входных данных. То, насколько эффективно каждый атрибут делит данные, называется энтропией.
Можно натренировать классификатор и он построит дерево решений внутри себя. Вот пример дерева, с помощью которого можно определить вероятность выживания при крушении «Титаника».

Дерево решений строится быстро и прозрачно, можно разложить построенную модель и посмотреть, как она работает.
Random forests

Random forests — это набор деревьев решений. Как это работает? Можно построить много маленьких деревьев, которые «недостаточно хорошо» работают, но если соединить результаты их работы, то эффективность этой совокупности деревьев получается гораздо выше, чем у одного большого и сложного дерева. Слово random используется потому, что для работы этого леса добавляется элемент случайности.
Этот алгоритм сейчас очень популярен, потому что он очень хорошо распараллеливается — можно на куче дешёвого железа развернуть тысячи, миллионы деревьев и провести машинное обучение, которое будет работать на уровне лучших аналогов, существующих в мире. Этот алгоритм очень эффективен.
Boosting
Этот алгоритм работает следующим образом: он строит, например, деревья одно за другим, и каждое следующее дерево учится на результатах предыдущего, при этом данные модифицируются. Алгоритм может таким образом разделить вложенные кольца на классы, что является довольно сложной задачей классификации.
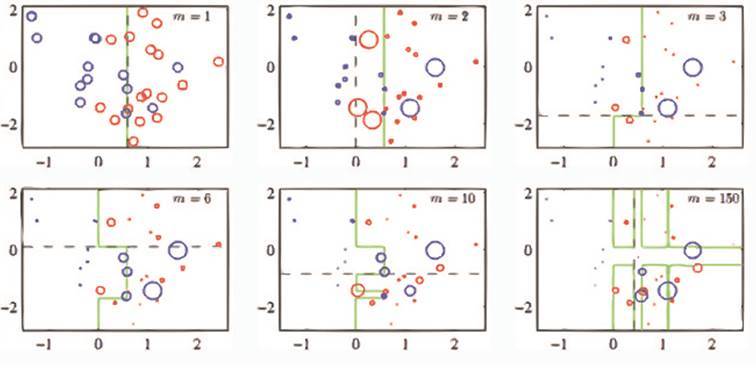
Для полноценной работы Boosting требуется гораздо больше времени, чем Random forests. Это связано с тем, что в данном алгоритме необходимо последовательно обучать каждое дерево. Это большая проблема.
Скрытая марковская модель
Эта модель разработана на базе марковского процесса, созданного известным российским математиком Андреем Андреевичем Марковым. Модели Маркова популярны в мире, их активно используют многие компании, в том числе Google. Суть модели Маркова очень проста.
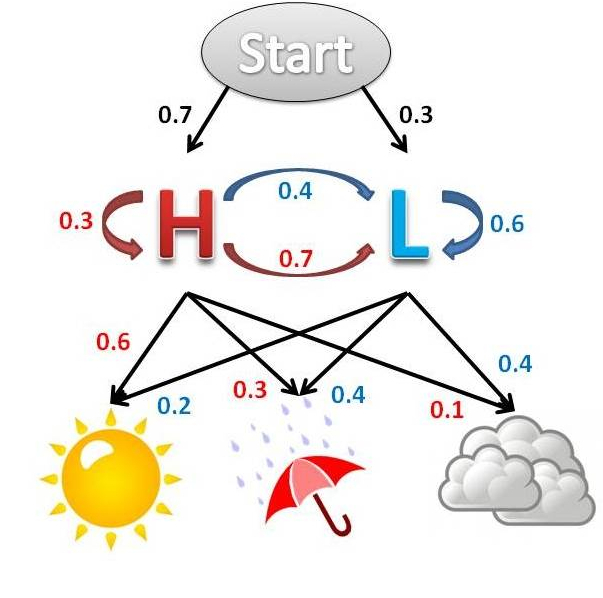
Есть некое состояние — допустим, высокая или низкая температура воздуха. Но какое именно состояние — вы не знаете. Зато вам известны признаки: светило солнце, шел дождь, были тучи. У вас имеется некий набор значений, собранных за статистический период: солнышко — дождь, солнышко — дождь — тучи. Цифры над стрелками — это вероятности, т.е. если солнышко, то с вероятность 60% тепло и с вероятностью 20% это холодно. Если тучи, то тепло с вероятностью 10%, а холодно с вероятностью 40%.
Когда вы получаете список состояний, то можете просчитать, в каком внутреннем, скрытом состоянии находилась система. Для чего это может быть полезно? Скажем, когда вы анализируете действие клиента — оплатил карточкой, обратился в техподдержку, совершил заказ, посмотрел элемент каталога — вы можете привязывать эти действия к скрытым действиям.
Например, действия, показывающие уровень лояльности клиента к вам — низкий, средний, высокий. И на основании этого вы предсказываете, в каком состоянии находится клиент. Если он вчера находился в «высоком» состоянии лояльности, завтра в среднем, послезавтра в низком, то тренд даст вам понять, что нужно что-то делать, иначе клиента можно «случайно» потерять. Как раз для решения подобных задач широко используются скрытые марковские модели.
Как оценивать качество модели?
Существует одна достаточно хорошая, понятная всем мера эффективности математических моделей-предсказателей — Confusion matrix.

Допустим, вы натренировали некую модель и она разложила исходные данные по группам. По горизонтали откладываются реальные группы, а по вертикали — предсказанные моделью. В примере выше у нас по факту 209 уток (общее количество в группе Duck по горизонтали), 242 птицы (Bird), 209 лягушек (Frog), 198 чаек (Seagull) и 198 голубей (Dove). Количественное распределение результатов по группам представлено в колонках. Чем точнее работает ваша модель, чем она качественнее, тем ярче выражена диагональ данных на матрице, тем меньше значения в ячейках вне диагоналей.
Где и что применять?
Churn-rate: классификатор, регрессор. Применяется для вычисления вероятности того, что конкретный человек может перестать быть вашим клиентом. Это полезно при проведении маркетинговых акций для удержания клиентов. Вы делаете классификатор: вводите данные клиента и на их основании определяете, уйдет он или нет. Это позволяет экономить маркетинговый бюджет.
CLV (customer lifetime value): классификатор, регрессор. По активности клиента позволяет оценить, какое количество денег он может принести вашей компании. Вводите в систему всю статистику, делаете перцептрон, или строите дерево решений, или Байесовский классификатор, или логистическую регрессию и определяете, сколько денег клиент принес — малое количество, среднее, большое. Затем вводите данные клиента и модель предсказывает, что этот клиент может принести вам большую сумму (до этого вы уже научились считать вероятность). И когда клиент готов уйти, а он стоит дорого и может принести много денег, вы начинаете работать только с ним, а не со всеми. В итоге ваши маркетинговые компании сужаются и становятся эффективнее. Или если такой клиент звонит вам, то CRM перенаправляет звонок не менеджеру, а руководителю. Этот подход очень широко используется на Западе банками, страховыми компаниями, крупными ритейлерами. У нас это пока только начинает развиваться.
Эффективность маркетинговой кампании для конкретного клиента: классификатор. Собрав данные по нескольким прошлым маркетинговым кампаниям, можно оценить, отреагирует ли новый клиент на очередную кампанию.
Например, вы разработали пять рекламных компаний. И когда вам нужно простимулировать клиента, который готов уйти и ценен для вас, вы математически тестируете, на какую рекламную кампанию он отзовётся. Таким образом можно сгруппировать клиентскую базу и таргетировать рекламные и маркетинговые кампании ради повышения их эффективности.
Тренд лояльности клиента: скрытая марковская модель. Вы отслеживаете внутреннее состояние клиента в системе по его действиям. Если тренд внутреннего состояния падает, вы что-то предпринимаете.
Цена/объём закупок: регрессор. Классическая задача прогнозирования объёма закупок товаров на основании интенсивности продаж.
Похожие товары: KNN (k nearest neighborhoods). Вы кластеризуете товары, ищете ближайшие кластеры и возвращаете товары, которые больше всего похожи. Это вариант алгоритма поисковика в математической KNN.
Аксессуары: item2item коллаборативная фильтрация. У вас есть основные товары и вам надо осуществить привязку сопутствующих аксессуаров, например, чехлов к смартфонам. Клиенты, ходя по сайту и выбирая, дают вам данные, из которых можно построить матрицу для осуществления привязки. Тем самым мы предлагаем клиенту релевантные товары, увеличивая оборот и удовлетворённость клиентов.
Рекомендации: item2item коллаборативная фильтрация. Подход аналогичен предыдущему. Например, вы посмотрели два фильма из серии «Звездные войны», а мы вам рекомендуем остальные. То есть мы рекомендуем вам товары, которые уже купили ваши друзья или люди, похожим на вас по каким-то критериями или поведенческим паттернам.
Софт
Вы можете поиграться с разными алгоритмами с помощью RapidMiner, IBM SPSS, SAS, Spark MLlib. Например, в нашем проекте нам необходимо всё считать в параллельном облаке, а для этого нужен Spark, MapReduce и много-много банок с пивом.
Коллеги, желаем вам удачи в увлекательном процессе прикладного машинного обучения. Тут главное не сдаваться, постоянно идти вперед и полезные модели для бизнеса раскроются во всей своей красе. Только усердно экспериментируя с алгоритмами, наборами данных, и замеряя качество на выходе можно добиться устойчивого успеха и обогнать конкурентов. Удачи вам!
