Машинное обучение для прогнозирования тенниса: часть 2
Вторая часть посвящена собственно машинному обучению: алгоритмам, проблемам и кейсам.

Содержание
Часть 2
Машинное обучение в теннисе
Модели машинного обучения
- Логистическая регрессия
- Нейронные сети
- Метод опорных векторов
- Другие алгоритмы МО
Проблемы с машинным обучением
- Переобучение
- Оптимизация гиперпараметров
- Live-прогнозирование
- Женский теннис
Кейсы МО для прогнозирования тенниса
- IBM
- Microsoft
- OhMyBet!
Машинное обучение в теннисе
Машинным обучением называется раздел искусственного интеллекта, изучающий алгоритмы, способные обучаться или адаптировать свою структуру на основании обработанной выборки данных. Машинное обучение с учителем решает задачу построения функции из набора помеченных обучающих примеров, где помеченный пример это пара, состоящая из вектора на входе и желаемого значения на выходе.
В контексте тенниса историческая статистика матчей может использоваться для формирования выборки обучающих примеров. Для отдельного матча входной вектор может содержать различные признаки матча и игроков, а выходным значением будет исход матча. Отбор релевантных признаков — это одна из основных проблем построения эффективного алгоритма машинного обучения.
С точки зрения существующих алгоритмов, прогнозирование тенниса можно рассмотреть с двух сторон:
- Как задачу регрессии, в которой выходное значение является вещественной величиной. Выход может представлять вероятность выигрыша матча напрямую, однако истинные вероятности выигрыша прошлых матчей неизвестны, что вынуждает нас использовать дискретные значения для меток обучающих примеров (например, 1 для победы, 0 для поражения). Иначе, можно прогнозировать вероятности выигрыша очка при подаче и вставлять их в иерархические выражения Барнета и О«Майли для нахождения вероятности выигрыша матча, но это возвращает нас к марковским цепям.
- Как задачу бинарной классификации, в которой можно попытаться классифицировать матчи по категориям «победа» или «поражение». Некоторые алгоритмы классификации также дают некоторую степень точности события, принадлежащего к классу, что можно использовать как вероятность победы в матче.
Модели машинного обучения
Логистическая регрессия
Несмотря на свое название, логистическая регрессия это по сути алгоритм классификации. Главными в алгоритме являются свойства логистической функции. Логистическая функция σ (t) определяется как:
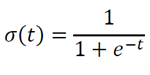
Как видно на рисунке ниже, логистическая функция отображает вещественные входные значения в диапазоне от –∞ до +∞ и от 0 до 1, позволяя интерпретировать выходы как вероятности.
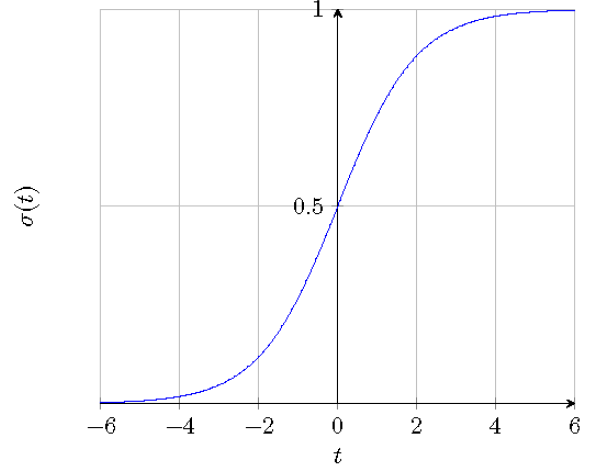
Логистическая функция σ (t)
Модель логистической регрессии для прогнозирования матчей состоит из вектора n признаков матча x = (x1, x2, …, xn) и вектора n+1 вещественных параметров модели β = (β0, β1, …, βn). Для прогнозирования с помощью модели сначала проецируем точку в нашем n-размерном пространстве признаков на вещественное число: 
Теперь можно преобразовать z в значение в приемлемом диапазоне вероятностей (от 0 до 1) с помощью логистической функции, определенной выше: 
Обучение модели состоит из оптимизации параметров β, так чтобы модель давала наилучшее воспроизведение исходов матчей для обучающей выборки. Это осуществляется путем минимизации функции логистических потерь (уравнение ниже), которая дает меру погрешности модели при прогнозировании исходов матчей, использовавшихся для обучения.
где N — количество матчей в выборке
pi — вероятность прогноза победы для матча i
yi— реальный исход матча i (0 — поражение, 1 — победа)
Рисунок ниже показывает логистические потери, возникающие из-за одного матча для различных прогнозируемых вероятностей, при условии, что матч завершился победой предсказанного игрока. Любое отклонение от самого точного предсказания p = 1,0 штрафуется.
Логистические потери при верном прогнозе матча
В зависимости от величины выборки выбирается один из двух методов обучения (т.е. минимизации логистических потерь):
1. стохастическое градиентное убывание — медленные итеративный метод, подходит для больших выборок;
2. максимальное правдоподобие — более быстрая численная аппроксимация, не подходит для больших выборок.
Большинство опубликованных моделей машинного обучения используют логистическую регрессию. Clarke and Dyte [8] применяют модель логистической регрессии к разнице по очкам двух игроков в рейтинге ATP для прогнозирования исхода сета. Иными словами они используют одноразмерное пространство признаков x = (rankdiff) и оптимизируют β1, так чтобы функция σ (β1 * rankdiff) давала наилучшее предсказание для обучающей выборки. Параметр β0 опущен в модели, так как rankdiff 0 даст вероятность победы в матче 0,5. Вместо непосредственного прогнозирования исхода матча Кларк и Дайт предсказывают вероятность победы в сете и моделируют вероятность победы в матче, таким образом увеличивая размер выборки. Модель использовалась для прогнозирования результатов нескольких мужских турниров в 1998 и 1999 гг., однако авторы не приводят данных о точности предсказания, упоминая только, что результаты удовлетворительные.
Ma, Liu and Tan [9] использовали большее пространство признаков из 16 переменных, принадлежащих к трем категориям: навыки и результативность игрока, физические параметры игрока, параметры матча. Модель обучалась на матчах с 1991 по 2008 гг. и использовалась для выдачи рекомендаций игрокам: например, «больше тренировать прием подачи».
Логистическая регрессия является привлекательным алгоритмом для прогнозирования тенниса из-за скорости обучения, устойчивости к переобучению и выдачи на выходе вероятности победы в матче. Однако без дополнительных модификаций этот алгоритм не может моделировать сложные взаимоотношения между входными признаками.
Нейронные сети
Искусственная нейронная сеть — это система взаимосвязанных нейронов, созданная по модели биологических нейронов. Каждый нейрон вычисляет значение из сигналов на входе, которое затем может быть передано на вход другим нейронам.
Нейронная сеть прямого распространения (то есть сеть с механизмом прогнозирования событий, feed-forward network) — это ориентированный ациклический граф. Как правило, нейросети имеют несколько слоев, при этом каждый нейрон в невходном слое связан со всеми нейронами в предыдущем слое. На рисунке ниже показана трехслойная нейронная сеть.

Трехслойная нейронная сеть прямого распространения
Каждой связи в сети присваиваются веса. Нейрон использует входной сигнал и его вес для вычисления значения на выходе. Типичным методом компоновки сети является нелинейная взвешенная сумма: 
где wi — вес входных данных xi.
Нелинейная функция активации К позволяет сети вычислять нетривиальные задачи, используя малое количество нейронов. Обычно для этой цели используются сигмоидальные функции, например, логистическая функция, определенная выше.
Теннисные матчи можно прогнозировать, отдавая на входной слой нейронов признаки игрока и матча и проводя значения через сеть. Если использовать логистическую функцию активации, значение на выходе сети может представлять собой вероятность победы в матче. Существует много различных алгоритмов обучения, целью которых является оптимизация весов сети для получения наилучших значений на выходе для обучающей выборки. Например, алгоритм обратного распространения использует градиентный спуск для снижения среднеквадратичной ошибки между целевыми значениями и значениями на выходе нейронной сети.
Нейронные сети могут находить связи между различными признаками матча, однако по своей природе они все равно остаются «черным ящиком», то есть обученная сеть не дает дополнительного понимания системы, так как ее слишком сложно интерпретировать. Нейронные сети склонны к переобучению и поэтому для их обучения нужно очень много данных. Кроме того, разработка модели нейронной сети требует эмпирического подхода, и отбор гиперпараметров модели часто осуществляется методом проб и ошибок. Однако, учитывая успешность моделей нейронных сетей для прогнозирования тенниса, этот подход нужно признать перспективным.
Somboonphokkaphan [10] обучил трехслойную нейросеть для прогнозирования теннисных матчей с использованием алгоритма обратного распространения. Автор исследовал и сравнил несколько разных сетей с разными наборами входных параметров. Лучшая нейронная сеть состоит из 27 входных узлов, представляющих такие признаки матча и игрока как поверхность корта, процент выигрыша на первой подаче, второй подаче, ответной подаче, брейк-пойнтах и т.д. Автор утверждает о точности около 75% при прогнозировании исходов матчей турниров Большого шлема в 2007 и 2008 годов.
Sipko [11] использует логистическую регрессию и нейронные сети, проверяя модели на выборке из 6135 матчей турниров ATP 2013–2014 гг., ROI наиболее точной модели составил 4,35%, что по заявлению автора на 75% лучше современных стохастических моделей.
После публикации первой части статьи SpanishBoy нашел на GitHub реализацию моделей Сипко: их результат — 65%, однако ROI получился отрицательным.
Метод опорных векторов
Машины опорных векторов (support vector machines, SVM), как и другие описанные здесь алгоритмы машинного обучения, это алгоритм обучения с учителем. Он был предложен Владимиром Вапником и Алексеем Червоненкисом в 1963 г. и является одним из наиболее популярных современных методов обучения по прецедентам.
Задача, решаемая SVM, заключается в нахождении оптимальной гиперплоскости, корректно классифицирующей точки (примеры) путем максимально возможного разделения точек двух классов на категории, являющиеся их метками (как и в других алгоритмах, этими категориями могут быть «победа» и «поражение»). Новый пример, например, предстоящий матч, можно затем проецировать в то же пространство точек и классифицировать на основании того, с какой стороны гиперплоскости он оказывается.
SVM имеют ряд преимуществ перед нейронными сетями: во-первых, обучение никогда не приводит к локальному минимуму, что часто случается с нейронными сетями. Во-вторых, SVM часто опережают нейронные сети по точности прогнозирования, особенно при высоком отношении признаков к обучающим примерам. Однако на обучение SVM тратится намного больше времени, а модели тяжело настраивать.
Выпускники MIT Wagner and Narayanan [12] опубликовали курсовую работу, где они использовали SVM для прогнозирования победителей в интерактивной игре ATP World Tour Draw Challenge, проводившейся ассоциацией теннисистов-профессионалов до 2014 г. Суть игры — перед началом мирового турнира ATP любой желающий на сайте ATP пытался по турнирной таблице предсказать победителей во всех предстоящих матчах вплоть до победителя турнира. Авторы использовали 15 признаков, в основном посетовую статистику игроков. Обучающая выборка составила 40000 примеров, для тестирования модели использовали перекрестную проверку на 6000 примерах. Максимальная точность модели составила 65%.
Работа Panjan et al. [13] не касается напрямую прогнозирования исходов матчей. Они применяли SVM, наряду с другими алгоритмами классификации, для прогнозирования успешности карьеры молодых теннисистов из Словении в сравнении с их сверстниками и старшими теннисистами.
Другие алгоритмы МО
Машины опорных векторов несомненно заслуживают более пристального внимания как модели для прогнозирования тенниса. Важно отметить, что для выдачи хороших вероятностей SVM требуют ступенчатой калибровки, в то время как для логистической регрессии и нейронных сетей такой шаг не обязателен. Кроме того, для прогнозирования теннисных матчей могут быть использованы и байесовские сети, моделирующие взаимозависимость между разными переменными.
Каждая модель имеет разную эффективность в различных условиях. Машинное обучение можно использовать и для построения гибридной модели, сочетающей в себе выходные данные с других моделей. Так, прогнозы разных моделей могут стать отдельными признаками, и модель можно обучить для анализа сильных и слабых сторон каждой из них. Например, прогноз нейронной сети можно объединить с моделью общего соперника, используя параметры матча для взвешенной оценки относительного влияния двух прогнозов.
Проблемы с машинным обучением
Переобучение
Как уже говорилось, для обучения описанных моделей доступно очень много исторических данных. Однако, важно отметить, что игру теннисистов в предстоящем матче нужно оценивать на основании их прошедших матчей: только недавние матчи на таком же покрытии корта со схожими соперниками могут точно отражать ожидаемый результат игрока. Ясно, что таких данных крайне мало для моделирования, а это может привести к переобучению модели. Это значит, что модель будет описывать случайную ошибку или шум в данных вместо релевантной закономерности. Переобучению особенно подвержены нейронные сети, в первую очередь, когда количество скрытых слоев/нейронов слишком велико по сравнению с количеством примеров.
Чтобы избежать переобучения, нужно отбирать только наиболее релевантные признаки матча. Для самого процесса отбора признаков также существуют отдельные алгоритмы. Устранение нерелевантных признаков также позволит снизить время на обучение.
Оптимизация гиперпараметров
Обучение модели оптимизирует параметры модели, например, веса в нейронной сети. Однако в модели как правило есть и гиперпараметры, которым не обучают и которые нужно настраивать вручную. Например, для нейронных сетей одними из конфигурируемых гиперпараметров являются количество скрытых слоев и количество нейронов в каждом слое. Получение оптимальных гиперпараметров для каждой модели — процесс эмпирический. Традиционный алгоритмический подход — поиск по сетке — подразумевает исчерпывающий поиск по заранее определенному пространству признаков. По этим причинам успешная модель для прогнозирования тенниса требует тщательного отбора гиперпараметров.
Live-прогнозирование
Эксперт по ставкам на теннис Питер Уэбб утверждает, что более 80% всех ставок на теннис размещаются непосредственно во время матча. Стохастические модели могут прогнозировать вероятность исхода матча с любого начального счета, а значит, их можно использовать для live-ставок. Модели машинного обучения как правило не перестраиваются по ходу текущего матча. И хотя текущий счет можно было бы использовать в качестве признака матча, ресурсоемкость такой модели выросла бы в разы, а влияние на точность или ROI могло быть минимальным.
Женский теннис
Часто в исследованиях рассматриваются только мужские матчи ATP, а игры Женской теннисной ассоциации (WTA) не учитываются. Отчасти это обусловлено лучшей доступностью исторических данных и коэффициентов по игрокам ATP, отчасти тем, что для женщин могут оказаться релевантными дополнительные признаки, что потребует перепроверки и перекалибровки модели. В любом случае, прогнозирование женского тенниса со всеми его особенностями является прямым полем деятельности для машинного обучения, и возможно мы увидим такие исследования в будущем.
Кейсы МО для прогнозирования тенниса
Исследовательский интерес к прогностическим моделям для тенниса привел к появлению сервисов, предлагающих пользователям результаты такого прогнозирования. Важно отметить, что в силу специфики рынка ставок на спорт, в интернете активны множество людей-прогнозистов (капперов, типстеров и т. д.) разной степени порядочности, утверждающих, что они дают прогнозы на основании собственных алгоритмов. По понятным причинам в большинстве случаев они оказываются мошенниками, что легко отследить по количеству деталей и корректности технической информации, которую они раскрывают (или не раскрывают).
После отсева людей-прогнозистов остается лишь несколько ресурсов, использующих по всей видимости, реальные математические модели. Несмотря на то, что они, как правило, не раскрывают используемые алгоритмы и методы, их можно отследить по косвенным признакам.
Одна группа сервисов предоставляет вероятности победы обоих игроков в матче, оставляя статистику матча и историю игрока для самостоятельного анализа пользователя. Таким образом, они используют результаты прогнозирования на основе стохастических иерархических методов. Таких ресурсов большинство: toptennistips.com, robobet.info и т. д.
Сервисы на основе машинного обучения анализируют не только вероятности выигрыша, но и применяют самообучающиеся алгоритмы к исторической статистике по игрокам и параметрам матча. Такие системы создали IBM, Microsoft и российский сервис OhMyBet!
IBM

Система от IBM Keys to the Match для прогнозирования тенниса продвигается компанией с 2013 года как предиктивный аналитический инструмент для четырех турниров Большого шлема: Уимблдона и Открытых чемпионатов Австралии, Франции и США. Для каждого игрока система анализирует его уникальный стиль игры и дает рекомендации по трем ключевым показателям (keys), которых должен достигнуть теннисист, чтобы увеличить свои шансы на выигрыш в текущем матче. «Ключи» публикуюся на официальных сайтах турниров.
Система берет статистику турниров Большого шлема с 2005 г., это почти 12 000 матчей. IBM уже много лет является официальным партнером турниров Большого шлема: компания собирает и обрабатывает всю статистику этих матчей. IBM утверждает, что для каждого матча Keys to the Match анализирует до 41 миллиона точек данных, в том числе очки, счет, длительность, скорость подачи, процент подач, количество ударов, типы ударов и т. д.
На основании анализа система определяет 45 ключевых динамических показателей игры и выделяет из них три, которые наиболее важны для каждого игрока в данном матче: 19 ключей для атаки, 9 для защиты, 9 для выносливости и 8 ключей, описывающих общий стиль игры. За турнир система создает в общей сложности 5500 предиктивных моделей.
Для выбора трех ключевых признаков система также анализирует разницу в статистике игрока по каждому из четырех турниров Большого шлема, историю личных встреч соперников и историю игр со схожими соперниками. На каждого игрока создается профиль со всей релевантной статистикой, после чего алгоритм кластеризации разделяет игроков по степени схожести профилей и стиля игры.
IBM не раскрывает, какие именно прогностические алгоритмы используются в системе. Более того, несмотря на фразу «предиктивная аналитика», постоянно встречающуюся в маркетинговых материалах о Keys to the Match, представитель IBM Кеннет Дженсен подчеркивает: «Система не создана для прогнозирования победителя в матче или сете. Цель Keys to the Match — определить три показателя результативности игрока и отследить текущую игру теннисиста в сравнении с его предыдущими результатами и показателями сопоставимых игроков».
Microsoft
Система искусственного интеллекта Cortana Intelligence Suite от Microsoft пока не использовалась для прогнозирования тенниса, однако ее активно тестируют на прогнозировании футбольных матчей, поэтому рассказ о ней включен в этот обзор (более подробно можно почитать здесь).
Кортану впервые опробовали для прогнозирования спорта в 2014 г, когда она предсказывала результаты матчей Чемпионата мира по футболу. Тогда правильными оказались 15 из 16 прогнозов исходов игр. После этого Microsoft составляла прогнозы для чемпионата мира по футболу среди женщин, английской Премьер-лиги, Лиги чемпионов УЕФА, чемпионата Бразилии, чемпионата Франции, чемпионата Испании, чемпионата Германии, чемпионата Италии.
Для прогнозирования результатов система использует комплексный анализ двух факторов: статистические данные (соотношение побед и поражений команды, количество забитых голов, место проведения матча, погодные условия) и данные веб-поиска и социальных сетей (феномен «коллективного разума»). Шанс выигрыша каждой команды определяется в процентном соотношении, рассчитывается вероятность ничьей в матчах для каждой игры отборочного тура.
В целом феномен «коллективного знания» недооценен, считают в Microsoft. Результаты мероприятий, на которые, казалось бы, общественное мнение повлиять не может (футбольные чемпионаты как раз этот случай), на самом деле можно предсказать, анализируя поведение людей в интернете. Так Cortana Intelligence Suite прогнозирует результаты ТВ-шоу, выборов, церемоний награждения и самых разных конкурсов, основанных на голосовании. Система выявляет, какие именно публичные действия пользователей коррелируют с распределением голосов. На этих корреляциях и составляются предиктивные алгоритмы. Доказано, что в случаях, когда отдельно взятые эксперты могут ошибаться, анализ общественного мнения добавляет 5% к точности прогноза.
Однако, футбольный матч — это не голосование, а по своей структуре он сложнее тенниса, и результаты прогнозов Кортаны пока все еще далеки от идеала. Так, для Евро 2016 система прогнозировала, что с вероятностью 66% чемпионом станет Германия, а в матче с Англией 11 июня Россия не забьет ни одного гола, проведет менее четырех атак, а число результативных пасов не превысит 221.
Результат нам известен.
OhMyBet!
Сервис OhMyBet! создан выпускниками Физтеха и ВМиК МГУ. В начале июля заметка о сервисе появилась на vc.ru, где создатели кратко рассказали о системе. Изучение предиктивных алгоритмов в выпускных и диссертационных проектах привело авторов к мысли отработать свои модели на теннисных матчах.
Из данных о 825 000 сыгранных матчей в турнирах ITF и ATF с 2000 по 2014 выделили такие признаки как результат матча, покрытие, турнир, количество эйсов, количество двойных ошибок, процент выигрыша на первой и второй подаче, средняя скорость подачи каждого игрока, возраст игроков, оценочная мотивация выигрыша, предыдущие встречи игроков, травмы, время отдыха между матчами и т. д. К этим данным применили алгоритмы машинного обучения.
Валидация модели проводилась на матчах 2015 года. Результат: 12% ROI за 2015 год, при этом точность системы составила 75–77%. Максимальная точность в 2015 году — 85%, однако ROI при этом снижается.
Высокий ROI обеспечивается за счет того, что алгоритм сам отсекает прогнозы с низкими коэффициентами. Средний выигрышный коэффициент — 1,74. Всего с начала 2015 г по настоящий момент алгоритм дал 452 прогноза, 350 за 2015.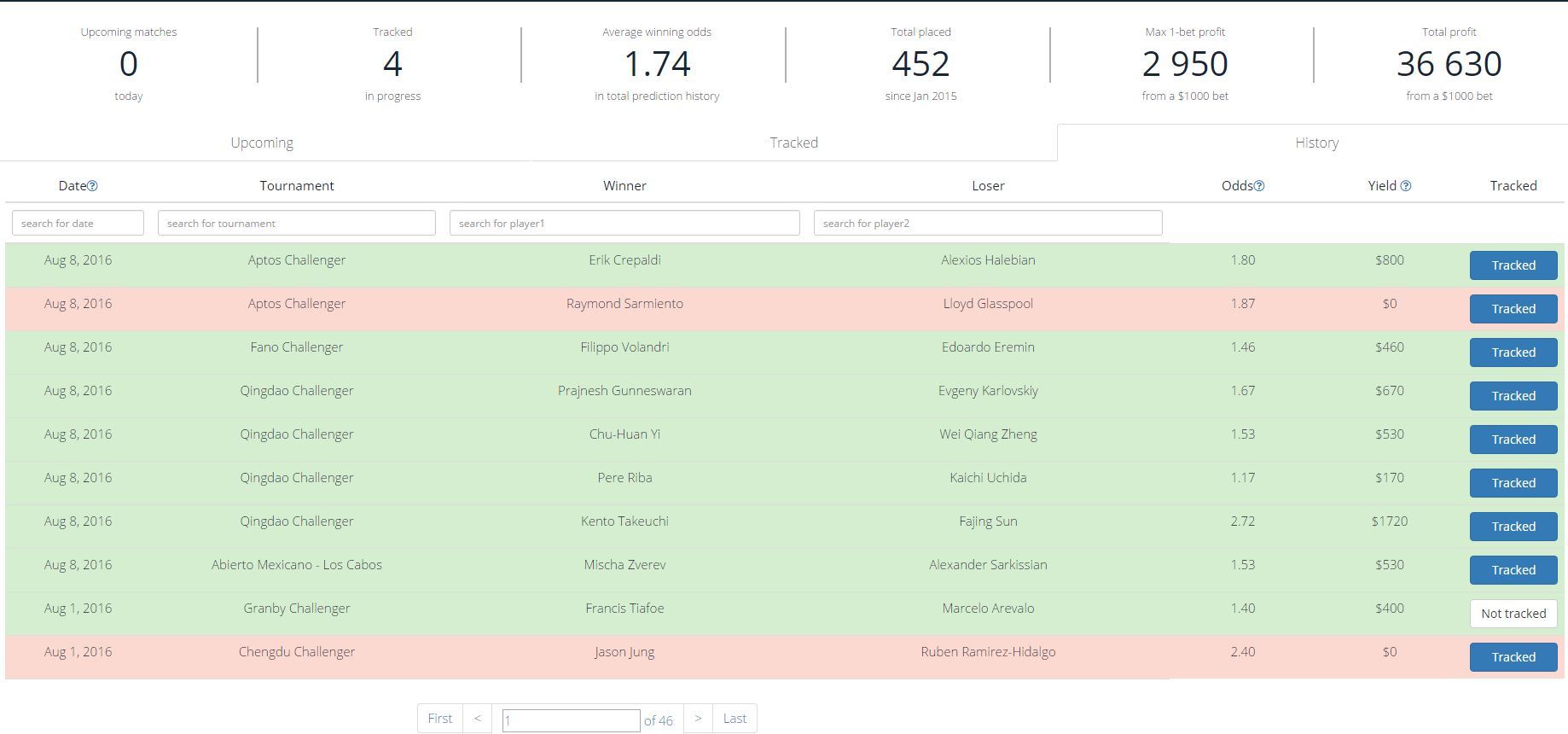
Алгоритм, используемый в системе, создатели не раскрывают, однако из анализа опубликованных работ и наблюдением за поведением самой системы можно предположить, что это нейронная сеть. Например, создатели рассказали, что при настройке модели столкнулись с переобучением и были вынуждены корректировать обучающие признаки.
Последнее крупное обновление алгоритма было проведено в начале июля 2016 г., после этого был открыт полный доступ к сайту для пользователей. Статистика прогнозов с начала 2015 до текущего матча доступна на сайте в разделе История. С момента запуска авторы ведут открытый мониторинг прогнозов на платформе Blogabet, чтобы избежать обвинений в подтасовке статистики.
Библиография8. S.R. Clarke and D. Dyte. Using official ratings to simulate major tennis tournaments. International Transactions in Operational Research, 7(6):585–594, 2000.
9. S. Ma, C. Liu, and Y. Tan. Winning matches in Grand Slam men«s singles: an analysis of player performance-related variables from 1991 to 2008. Journal of sports sciences, 31(11):1147–55, 2013.
10. A. Somboonphokkaphan, S. Phimoltares, and C. Lursinsap. Tennis Winner Prediction based on Time-Series History with Neural Modeling. IMECS 2009: International Multi-Conference of Engineers and Computer Scientists, Vols I and II, I:127–132, 2009.
11. M. Sipko. Machine Learning for the Prediction of Professional Tennis Matches. Technical report, Imperial College London, London, 2015.
12. A. Wagner, D. Narayanan. Using Machine Learning to predict tennis match outcomes. MIT 6.867 Final Project.
13. A. Panjan et al.: Prediction of the successfulness of tennis players with machine learning methods. Kinesiology 42(2010) 1:98–106
