Малоизвестные библиотеки Python для анализа данных, которые сделают вашу жизнь проще
 Автор статьи: Виктория Ляликова
Автор статьи: Виктория Ляликова
Привет Хабр! В этой статье мы рассмотрим некоторые полезные библиотеки Python для задач обработки данных, с которыми, возможно, вы еще не знакомы. Хотя для задач машинного обучения на ум приходят такие библиотеки, как pandas, numpy, scikit-learn, keras, tensorflow, matplotlib и т.д., но всегда полезно знать о других предложениях Python, особенно если это поможет улучшить ваши проекты.
1. Sketch
Для тех, кто использует библиотеку pandas модуль Sketch может стать хорошим помощником в написании кода с использованием искусственного интеллекта. Sketch использует алгоритмы машинного обучения для понимания контекста пользовательских данных и предоставляет соответствующие предложения по коду. Также Sketch может автоматизировать повторяющиеся задачи, находить ошибки и предлагать исправления, анализировать кодовую базу и предлагать предложения по оптимизации. Это все может значительно сократить время и усилия, необходимые для выполнения задач, связанных с данными.
Библиотека имеет следующие методы:
.
sketch.askAsk — это простая функция вопросов и ответов в sketch, представляет собой текстовый ответ на основе сводной статистики и описания данных
С помощью
Askможно узнать больше о данных, разработать лучшие названия столбцов, задать гипотетические вопросы, например: «Как бы я выполнил X с этими данными?» и более..sketch.howtohowto— дает рекомендации по написанию кода. Например, можно спросить, как нормализовать данные, заполнить пропуски, создать новые признаки, построить графики и т.д..sketch.applyapply— более продвинутая система ввода вопросов, которая больше подходит для генерации данных. Может использоваться для парсинга полей, создания новых признаков и многого другого. Для её использования необходимо иметь бесплатный OpenAI аккаунт, поскольку она работает только с личным API ключом.
Установка
pip install sketchили
conda install -c conda-forge sketch Теперь импортируем Sketch и Pandas, поработаем с библиотекой:
import sketch
import pandas as pdВозьмем набор данных, который содержит сводную статистику с 2015 по 2020 год по мировому счастью и восприятию коррупции. В наборе 792 записи, которые имеют такие характеристики как: страна, индекс счастья (оценка от 0 до 10), ВВП на душу населения, семья, здоровье, щедрость, доверие правительству, остаточная дистопия, континент, год, социальная поддержка, индекс коррупции.
Загружаем набор данных
data = pd.read_csv("WorldHappiness_Corruption.csv")
data.head()
.sketch.ask
Начнем с простых вопросов. Можно попросить описать датасет:
data.sketch.ask('Опиши датасет')Результат:
Датасет содержит информацию о счастье в различных странах мира. Он содержит 792 строки и 13 столбцов, включая индекс, страну, оценку счастья, ВВП на душу населения, семью, здоровье, свободу, щедрость, доверие к правительству, резидуальный дистопийный индекс, континент, год, социальную поддержку и CPI-оценкуУзнаем какие столбцы имеют категориальный тип данных:
data.sketch.ask('какие столбцы имеют категориальный тип данных')Результат:
Country, continent, and Year are categorical columns in the dataframe.Узнаем основные характеристики набора данных:
data.sketch.ask('Какие минимальные, максимальные, средние значения у числовых столбцов')Результат:
happiness_score: min = 2.566900015, max = 7.808700085, mean = 5.37072857 gdp_per_capita: min = 0.0, max = 2.096, mean = 0.90873788 family: min = 0.0, max = 1.610574007, mean = 1.09485084 health: min = 0.0, max = 1.141, mean = 0.63730409 freedom: min = 0.0, max = 0.724, mean = 0.42862031 generosity: min = 0.0, max = 0.838075161, mean = 0.17953856 government_trust: min = 0.0, max = 0.55191, mean = 0.09566011 dystopia_residual: min = 0.0, max = 3.60214, mean = 1.85023834 cpi_score: min = 11.0, max = 91.0, mean = 40.552795031Или, например, узнаем какие столбцы наиболее значимы в датафрейме:
data.sketch.ask('Какие столбцы наиболее значимы в датафрейме')Результат:
The most significant columns in the dataframe are happiness_score, gdp_per_capita, family, health, freedom, generosity, government_trust, and dystopia_residual. These columns provide important information about the overall happiness of a country and its citizens.Узнаем какие алгоритмы можно применить для предсказания уровня счастья:
data.sketch.ask('Какие алгоритмы можно применить для предсказания уровня счастья')Результат:
Для предсказания уровня счастья можно использовать алгоритмы машинного обучения, такие как решающие деревья, логистическая регрессия, метод опорных векторов, наивный байесовский классификатор, случайный лес, K-means и т.д.А теперь попробуем сравнить вопросы на английском и русском языке. Например узнаем о том, какая страна имеет хорошую социальную поддержку. Спросим на английском языке.
data.sketch.ask('Which country has good social support')Результат:
The countries with the highest social support scores are Denmark, Finland, Norway, Iceland, and Switzerland.А теперь на русском
data.sketch.ask('В какой стране хорошая социальная поддержка')Результат
The country with the highest social support score is Finland, with a score of 1.644.Видим, что задавая один и тот же вопрос на разных языках, мы получаем разные ответы. Посмотрим теперь на данные по Финляндии:
data.loc[data.Country == 'Finland']
Видим расхождения в полученных значениях. Пока не совсем понятно откуда у Норвегии уровень социальной поддержки 1.644. Видимо sketch вычисляет уровень social_support каким-то своим способом.
Иногда модель вместо ответа может просто дать рекомендации:
data.sketch.ask('Как восстановить пропущенные значения')Результат:
Missing values can be recovered by using various methods such as imputation, interpolation, and extrapolation. Imputation is the process of replacing missing values with estimates based on the available data. Interpolation is the process of estimating values between two known values. Extrapolation is the process of estimating values beyond the range of known values. Other methods such as clustering and machine learning can also be used to recover missing values.Или узнаем как можно визуализировать данные:
data.sketch.ask('Как можно визуализировать данные?')Результат:
The data can be visualized using various types of charts and graphs, such as bar charts, line graphs, scatter plots, and histograms. These visualizations can help to identify patterns and trends in the data, as well as compare different variables. Additionally, heatmaps and boxplots can be used to further explore the data.Наверное все-таки функцию ask лучше использовать для получения советов, а не для получения численных значений.
.sketch.howto
howto наверно более интересная и полезная функция у библиотеки, так как она дает уже подсказки по написанию кода. Попробуем проверить, что функция howto нам предложит.
Узнаем как получить статистическую сводку по нашим данным:
data.sketch.howto('Как получить статистическую сводку каждого числового столбца')Результат:
# Get summary statistics for each numerical column
data.describe()Попробуем узнать как нормализовать данные:
data.sketch.howto('Normalize data')Результат:
# Normalize data
from sklearn.preprocessing import MinMaxScaler
# Create a scaler object
scaler = MinMaxScaler()
# Fit the scaler to the dataframe
data_scaled = scaler.fit_transform(data)
# View the normalized dataframe
data_scaledТолько прежде, чем пользоваться советом по нормализации данных, необходимо убедиться, что все столбцы имеют численный формат, иначе будут ошибки. Поэтому сначала лучше узнать, какие столбцы можно нормализовать без предварительной обработки.
Можно узнать как построить гистограмму уровня счастья
data.sketch.howto('Как построить гистограмму уровня счастья?')Результат:
# import matplotlib library
import matplotlib.pyplot as plt
# filter dataframe for year 2015
data_2015 = data[data['Year'] == 2015]
# plot histogram of happiness score for 2015
plt.hist(data_2015['happiness_score'], bins=20)
plt.title('Happiness Score in 2015')
plt.xlabel('Happiness Score')
plt.ylabel('Frequency')
plt.show()Что интересно, Sketch даже сам указывает какие библиотеки необходимо подключить, чтобы получить желаемый результат

Узнаем как построить диаграмму рассеяния:
data.sketch.howto('Как можно визуализировать данные с помощью scatter plot')Результат:
import matplotlib.pyplot as plt
# Scatter plot of happiness score vs gdp per capita
plt.scatter(data['happiness_score'], data['gdp_per_capita'])
plt.xlabel('Happiness Score')
plt.ylabel('GDP per Capita')
plt.title('Happiness Score vs GDP per Capita')
plt.show()Sketch предлагает построить диаграмму рассеяния зависимости уровня счастья от ввп на душу населения

Попросим построить модель линейной регрессии для предсказания уровня счастья:
data.sketch.howto('Как применить алгоритм линейной регрессии для предсказания показателя счастья')Результат:
#import necessary libraries
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
#load data into a dataframe
df = pd.DataFrame(data)
#define the features and target variables
X = df.drop(['happiness_score'], axis=1)
y = df['happiness_score']
#split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#fit the linear regression model to the training data
model = LinearRegression()
model.fit(X_train, y_train)
#predict the happiness score using the test data
y_pred = model.predict(X_test)Да, алгоритм построения модели предложен, даже удален целевой столбец из датафрейма. Не хватает только импортирования модуля для разделения данных на выборку для обучения и тестовую. И так же не учитывается, что не все данные имеют числовые признаки. Но с другой стороны, мы спросили, модуль предложил, а дальше это наша проблема как мы будем применять этот алгоритм. Можно, наверное, более аккуратно и четко формулировать вопросы, чтобы получать правильные ответы.
В целом ощущения от работы с библиотекой положительные. Да, есть нюансы, но… Просто, чтобы можно было извлечь пользу от использования библиотеки надо понимать принципы работы и предназначение различных методов, то есть необходимы знания по работе с данными и алгоритмами.
Sketch может помочь неопытным разработчика, которые только начинают свой путь в анализе данных или машинном обучении и придет на помощь в изучении новых методов и практик. При этом для опытных разработчиков библиотека тоже может стать полезным инструментом, который поможет сэкономить драгоценное время и сосредоточиться на более сложных проблемах.
Наверное самое главное помнить, что ты работаешь с искусственным интеллектом и полагаться надо на себя, тщательно обдумывая предложенные варианты решений. И главное, чтобы получить желаемый ответ, надо формулировать запрос на языке машины. И не забывать, что язык библиотеки — английский.
2. MLxtend
БиблиотекуMLxtend можно использовать как основной инструмент для задач машинного обучения или в качестве дополнения и вспомогательного инструмента к другим более известным библиотекам по анализу данных.
MLxtend включает такие модули как классификатор, кластеризатор, методы оценки, извлечение признаков, предварительная обработка, методы визуализации и т.д
Модуль классификации MLxtend предоставляет различные алгоритмы классификации и регрессии, включая многослойные персептроны, классификаторы, стекирования, логистическую регрессию и др.
Модуль рисования mlxtend предоставляет различные инструменты рисования на основе машинного обучения, такие как диаграммы разброса классификации, тепловые карты, диаграммы границ решений, диаграммы матрицы путаницы с несколькими классами и так далее.
Модуль предварительной обработки mlxtend предоставляет различные методы стандартизации и нормализации данных.
Установка:
pip install mlxtendили
conda install -c conda-forge mlxtendВозьмем набор данных о вине, который содержит 13 атрибутов алкоголя для трех видов вина. Здесь имеем дело с набором данных многоклассовой классификации.
import pandas as pd
data_path = 'D:/wine.csv'
df = pd.read_csv(data_path, header=0)
df.head()
Начнем с более интересного примера, такого как, построение границы решения классификатора с помощью метода plot_decision_regions() библиотеки MLxtend
# Создадим целевой вектор y
# Преобразуем классы 1, 2, 3 к классам 0, 1, 2 соответственно
y_s = df["Wine"].map({1: 0, 2: 1, 3: 2})
y = y_s.values
# Получим столбец признаков
X_df = df.drop(columns=["Wine"])
X = X_df.values
attribute_names = X_df.columnsВизуализация работает только с двумя признаками одновременно, поэтому создадим массив со свойствами «Flavanoids» и «Color»
X_2d= X_df[["Flavanoids", "Color.int"]].valuesСоздаем классификатор Байеса, подгоняем данные и получаем визуализацию границ решений:
from sklearn.naive_bayes import GaussianNB
# создаем классификатор
model_nb = GaussianNB()
# подгоняем модель
model_nb.fit(X_2d, y)
# импортируем библиотеку для визуализации
from mlxtend.plotting import plot_decision_regions
# строим границы решений
plot_decision_regions(
X=X_2d,
y=y,
clf=model_nb)
Еще одна интересная функция — это круг корреляции анализа главных компонент (PCA). Анализ главных компонент или PCA — обычно используют для уменьшения размерности путем использования каждой точки данных только для первых нескольких основных компонентов (в большинстве случаев первого и второго измерений) для получения данных меньшей размерности с сохранением как можно большего разнообразия данных. Как раз круг корреляции PCA покажет насколько исходные переменные коррелируют с первыми двумя главными компонентами.
Помним, что в PCA нормализация очень важна, потому что PCA проецирует исходные данные в направлениях, которые максимизируют дисперсию
Используем метод plot_pca_correlation_graph()
# импортируем библиотеки
from mlxtend.plotting import plot_pca_correlation_graph
from sklearn.preprocessing import StandardScaler
# нормализуем данные (X - mean) / std
X_norm = StandardScaler().fit_transform(X)
# строим круг корреляции
fig, correlation_matrix = plot_pca_correlation_graph(
X_norm,
attribute_names,
dimensions=(1, 2),
figure_axis_size=6)
correlation_matrix

Можно рассмотреть еще такую функцию как разложение дисперсии смещения. Компромисс смещения и дисперсии поможет показать производительность модели. В обучении с учителем цель часто состоит в том, чтобы минимизировать как ошибку смещения (чтобы предотвратить недостаточную подгонку), так и дисперсию (чтобы предотвратить переобучение), чтобы модель могла обобщать за пределами обучающей выборки. Этот процесс известен как компромисс между смещением и дисперсией. В разложении на самом деле есть и третья компонента — случайный шум в данных. Поэтому мы можем использовать разложение смещения-дисперсии, чтобы разложить ошибку обобщения на сумму 1) смещения, 2) дисперсии и 3) неснижаемой ошибки .
Декомпозиция смещения-дисперсии может быть реализована с помощью метода bias_variance_decomp()
from mlxtend.evaluate import bias_variance_decomp
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X_df.values,y,test_size=0.3,shuffle=True,stratify=y)
model_nb1 = GaussianNB()
avg_expected_loss, avg_bias, avg_var = bias_variance_decomp(
model_nb1, X_train, y_train, X_test, y_test,
loss='mse',
num_rounds=50)
print(f"Average expected loss: {avg_expected_loss.round(3)}")
print(f"Average bias: {avg_bias.round(3)}")
print(f"Average variance: {avg_var.round(3)}")Результат:
Average expected loss: 0.024
Average bias: 0.017
Average variance: 0.006Мне кажется, что в библиотеке MLxtend можно найти достаточно много полезных функций и методов по работе с данными.
3. SciencePlots
SciencePlots — это библиотека, которая предоставляет стили для библиотеки Matplotlib, чтобы получить профессиональные графики для презентаций, исследовательских работ и т.д.
Установка:
pip install SciencePlotsили
conda install -c conda-forge scienceplotsСо списком доступных стилей можно ознакомиться следующим образом:
import matplotlib.pyplot as plt
import scienceplots as sp
plt.style.avaibleРезультат
['Solarize_Light2',
'_classic_test_patch',
'_mpl-gallery',
'_mpl-gallery-nogrid',
'bmh',
'classic',
'dark_background',
'fast',
'fivethirtyeight',
'ggplot',
'grayscale',
……
и т.д.]Попробуем построить несколько графиков, используя комбинацию стилей «fivethirtyeight» и «dark_background».
import matplotlib.pyplot as plt
import scienceplots as sp
plt.style.use(['fivethirtyeight','dark_background])
x = np.linspace(0, 10, 100)
y1 = np.sin(x)/np.exp(x/3)
y2 = np.cos(x)/np.exp(x/5)
with plt.style.context('seaborn-paper'):
plt.figure()
plt.plot(x, y1, color = 'green', linewidth = 2)
plt.plot(x, y2, color = 'orange', linewidth = 2)
plt.show()
Или построим гистограмму индекса массы тела человека, предварительно взяв данные из датафрейма.
import pandas as pd
import seaborn as sns
data_healthcares= pd.read_csv('healthcare-dataset-stroke-data.csv')
with plt.style.context(['science','ieee','no-latex']):
fig = plt.figure
fig, ax = plt.subplots(figsize=(2,2))
sns.distplot(new_data.bmi, color = 'green', label='bmi', ax=ax)
Если необходимы профессиональные графики с использованием Matplotlib и не хочется тратить слишком много энергии, чтобы настроить стили рисования, SciencePlots, как мне кажется, является очень хорошим выбором.
4. Ftfy
Библиотека ftfy исправляет Unicode, который был поврежден различными способами. Функции, выполняемые библиотекой:
Исправление строк с кривым юникодом
Удаление разрыва строк
Преобразование html в обычный текст
Установка:
pip install ftfyили
conda install -c conda-forge ftfyСамая интересная поломка, которую сможет исправить ftfy — это когда кто-то закодировал Unicode одним стандартом, а декодировал его другим. Это часто проявляется в виде символов, которые превращаются в бессмысленные последовательности (так называемые «моджибаке»). Попробуем это исправить:
import ftfy
print(ftfy.fix_text('The Mona Lisa doesnà ¢Ã¢â€š ¬Ã¢â€ž ¢t have eyebrows.'))
print(ftfy.fix_text('à perturber la réflexion'))
print(ftfy.fix_text(' '))
print(ftfy.fix_text('ЧÑÐ¾Ð±Ñ Ð½Ð¸ ÑлÑÑилоÑÑ,верь в себя, верь в жизнь, в завтрашний день....'+
'ÐеÑÑ Ð²Ð¾ вÑÑ, ÑÑо ÑÑ Ð´ÐµÐ»Ð°ÐµÑÑ, вÑегда!'))
Результат:
"The Mona Lisa doesn't have eyebrows."
à perturber la réflexion
LOUD NOISES
Чтобы ни случилось,верь в себя, верь в жизнь, в завтрашний день....Верь во всё, что ты делаешь, всегда!5. Pgeocode
Модуль геокодирования pgeocode Python создан для обработки географических данных и помогает объединять и сопоставлять различные данные. С помощью модуля pgeocode можно получать и предоставлять информацию, связанную с регионом или областью, используя информацию о почтовом индексе. Также поддерживаются расстояния между двумя почтовыми индексами. База данных включает почтовые индексы 83 стран, но к сожалению, поддерживаются запросы только внутри одной страны.
Установка:
pip install pgeocodeили
conda install -c conda-forge pgeocodeИмпортируем модуль:
import pgeocodeПосмотрим какие данные выдаст нам модуль при запросе страны случайного почтового кода:
data = pgeocode.Nominatim('RU')
data.query_postal_code("123242")Результат:
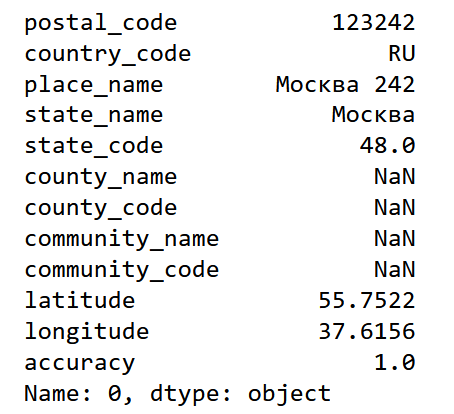
Или можно получить геоинформацию сразу для нескольких почтовых индексов:
data = pgeocode.Nominatim('Ru')
data.query_postal_code(["123242", "190000", "394000"])
Рассмотрим еще одну интересную функцию, которую предоставляет модуль геокодирования, — это возможность найти георасстояние между двумя почтовыми индексами. Это можно сделать с помощью метода Geodistance().
data = pgeocode.GeoDistance('ru')
print(data.query_postal_code("123242", "394000"))
465.6646876561527Яндекс карты утверждают, что такое расстояние равно приблизительно 520 километров, то есть небольшая погрешность в измерениях есть.
Или можно вычислить расстояние сразу между несколькими почтовыми индексами
dist = pgeocode.GeoDistance('fr')
dist.query_postal_code(["75013", "75014", "75015"], ["69006", "69005", "69004"])Результат:
array([391.19457381, 391.67923449, 391.86183777])6. Pendulum
Модуль Pendulum является заменой встроенного модуля datetime. Модуль поддерживает часовые пояса и предоставляет полезные методы для форматирования, синтаксического анализа и манипуляций с датой и временем, такие как добавление интервалов, вычитание дат и преобразование между часовыми поясами.
Установка
pip install pendulumили
conda install -c anaconda pendulumИмпортируем модуль:
import pendulumСоздать экземпляр даты и времени можно, используя различные методы, такие как datetime(), local(), now(), from_format().
# использование datetime()
dt = pendulum.datetime(2023, 10, 17)
# использование local()
local = pendulum.local(2023, 10, 17)
# использование now()
utc = pendulum.now('UTC')
print(dt)
print(local)
print(utc)Результат:
DateTime(2023, 10, 17, 0, 0, 0, tzinfo=Timezone('UTC'))
DateTime(2023,10,17,0,0,0, tzinfo=Timezone('Europe/Moscow'))
# время 16:14 по MSK
DateTime(2023,10,18,13,14,40,909807, tzinfo=Timezone('UTC'))Можно использовать функции add() и subtract() для манипуляций с датой и временем. Каждый метод возвращает новый экземпляр DateTime.
Метод add()
utc = utc.add(years=5)
utcРезультат:
# время 16:14 по MSK
DateTime(2028,10,18,13,14,40,909807, tzinfo=Timezone('UTC'))Метод subtract()
utc = utc.subtract(months=2)
utcРезультат:
DateTime(2028,8,18,13,14,40,909807, tzinfo=Timezone('UTC'))Pendulum предлагает методы для преобразования даты и времени в строку стандартного формата, а также имеет функцию strtime() с помощью которой можно указать свой собственный формат.
print(utc.to_iso8601_string())
print(utc.to_formatted_date_string())
print(utc.to_w3c_string())
print(utc.to_date_string())Результат:
2028-08-18T13:14:40.909807Z
Aug 18, 2028
2028-08-18T13:14:40+00:00
2028-08-18Рассмотрим еще метод duration():
time_delta = pendulum.duration(days = 5,hours = 11,years = 1)
print(time_delta)
print('future date =', pendulum.now() + time_delta)Результат:
# сегодня 18 октября 2023 16:54
7 years 1 day 5 hours
future date = 2030-10-19T21:54:19.008828+03:00Pendulum тоже интересная библиотека, на которую стоит обратить внимание. Библиотека упрощает проблему сложных манипуляций с датами, связанных с часовыми поясами, которые неправильно обрабатываются в собственных экземплярах datetime.
7. Rembg
Библиотека rembg — это ещё одна полезная библиотека, которая легко поможет удалить фон с изображений. Она использует модели глубокого обучения, предварительно обученные на больших наборах данных.
Часто в задачах компьютерного зрения удаление фона изображения с целью вырезания избыточной информации позволяет повысить производительность модели. Однако это может быть довольно утомительно, но использование такой библиотеки как rembg позволит сделать всего за пару строк кода.
Основные возможности библиотеки:
Автоматическое удаление фона с использованием нейросетей
Возможность точной настройки для сложных изображений
Поддержка изображений разных форматов — JPG, PNG, GIF и др.
Установка:
pip install rembgПопробуем работу библиотеки на некоторых изображениях. Стоит обратить внимание, что при первом запуске библиотеки сначала загружается модель сети, поэтому это может занять некоторое время, зато после завершения, удаление фона не будет занимать много времени.
# импортируем необходимый модуль
from rembg import remove
import cv2
# читаем изображение
input = cv2.imread('test.jpg')
# удаляем задний фон
output = remove(input)
# сохраняем полученное изображение
cv2.imwrite('output1.jpg', output)Результат:



Простое использование библиотеки rembg делают ее полезным инструментом для различных задач.
Надеюсь, что какие-то из этих библиотек привлекли ваше внимание в качестве дополнительного инструмента к основным библиотекам машинного обучения.
Больше про машинное обучение и Data Science коллеги из OTUS рассказывают в рамках онлайн-курсов, подробнее о которых вы можете узнать в данном каталоге.
