Лучшие публикации социальных сетей
Здравствуйте. В свободное от работы время я занимаюсь социальными проектами. У меня и моих друзей есть достаточное количество «пабликов» в разных социальных сетях, что позволяет нам проводить различные эксперименты. Остро стоит вопрос нахождения актуального контента и новостей, которые можно публиковать. В связи с этим, пришла идея написать сервис, который будет собирать посты из самых популярных страниц и выдавать их по указанному фильтру. Для начального теста выбрал социальную сеть вконтакте и твиттер.ТехнологииПервым делом, нужно было определиться с хранилищем данных (к слову, сейчас количество сохраненных записей больше 2 млн) и эта цифра растает каждый день. Требования были такие: очень частая вставка большого количества данных и быстрая выборка среди них.До этого уже слышал о nosql-базах данных и захотелось их попробовать. Не буду описывать в статье сравнения баз, которые я проводил (mysql vs sqlite vs mongodb).В качестве кеширования выбрал memcached, позже объясню зачем и в каких случаях.В качестве сборщика данных был написан демон на python, который параллельно обновляет все группы из базы.
MongoDB и демон Первым делом, написал прототип сборщика публикаций из групп. Видел несколько проблем: Объем хранилища Ограничения API Одна публикация со всеми метаданными занимает около 5–6КБ данных, а в средней группе около 20,000–30,000 записей, получается около 175МБ данных на одну группу, а этих самых групп очень много. Поэтому пришлось поставить задачу в фильтрации неинтересных и рекламных публикациях.Слишком много выдумывать не пришлось, у меня есть всего 2 «таблицы»: groups и posts, первая хранит записи групп, которые нужно парсить и обновлять, а второе — scope всех публикаций всех групп. Сейчас мне кажется это излишним и даже плохим решением. Лучше всего было бы создавать по таблице на каждую группу, так будет проще происходить выборка и сортировка записей, хотя скорость даже с 2 млн не теряется. Зато такой подход должен упростить общую выборку для всех групп.
API В случаях, когда вам нужна серверная обработка каких-то данных из социальной сети вконтакте, создается standalone-приложение, которое может выдать токен на любое действие. Для таких случаев у меня сохранена заметка с таким адресом: http://oauth.vk.com/authorize? client_id=APP_ID&redirect_uri=https://oauth.vk.com/blank.html&response_type=token&scope=groups, offline, photos, friends, wall
Вместо APP_ID вставляете идентификатор вашего standalone-приложения. Сгенерированный токен позволяет в любое время обращаться к указанным действиям.
Алгоритм работы парсера такой: Берем id группы, в цикле получаем все публикации, на каждой итерации производим фильтрацию «плохих» постов, сохраняем в базу.Основная проблема — скорость. API vkontakte позволяет выполнить 3 запроса в секунду. 1 запрос позволяет получить всего 100 публикаций — 300 публикаций в секунду.В случае с парсером это не так и плохо: группу можно «слить» за одну минуту, а вот с обновлением уже будут проблемы. Чем больше групп — тем дольше будет происходить обновление и, соответственно, выдача будет не так быстро обновляться.
Выходом стало использование метода execute, который позволяет собирать запросы к api в кучу и выполнять за раз. Таким образом я в одном запросе делаю 5 итераций и получаю 500 публикаций — 1500 в секунду, что дает «слив» группы за ~13 секунд.
Вот так выглядит файл с кодом, который передается в execute:
var groupId = -|replace_group_id|; var startOffset = |replace_start_offset|;
var it = 0; var offset = 0; var walls = [];
while (it < 5) { var count = 100; offset = startOffset + it * count; walls = walls + [API.wall.get({"owner_id": groupId, "count" : count, "offset" : offset})];
it = it + 1; }
return { «offset» : offset, «walls» : walls }; Код читается в память, делается замена токенов replace_group_id и replace_start_offset. В результате получаю массив публикаций, формат которых можете посмотреть на официальной странице VK API vk.com/dev/wall.get
Следующий этап — фильтр. Я брал разные группы, просматривал публикации и придумывал возможные варианты отсеивания. Первым делом решил удалять все публикации с ссылками на внешние страницы. Почти всегда это реклама.
urls1 = re.findall ('http[s]?://(?:[a-zA-Z]|[0–9]|[$-_@.&+]|[!*\(\),]|(?:%[0–9a-fA-F][0–9a-fA-F]))+', text) urls2 = re.findall (ur»[-a-zA-Z0–9@:%._\+~#=]{2,256}\.[a-z]{2,6}\b ([-a-zA-Z0–9@:%_\+.~#?&//=]*)», text)
if urls1 or urls2: # Игнорировать эту публикацию Далее решил полностью исключить репосты — это в 99% реклама. Мало кто будет просто так делать репост чужой страницы. Проверить на репост очень просто:
if item['post_type'] == 'copy': return False item — очередной элеменрт из коллекции walls, которую вернул метод execute.
Также заметил, что очень много древних публикаций пустые, у них нет никаких вложений и текст пустой. Для фильтра достаточно првоерить что item['attachments'] и item['text'] пустые.
И последний фильтр, который я просто вывел со временем:
yearAgo = datetime.datetime.now () — datetime.timedelta (days=200) createTime = datetime.datetime.fromtimestamp (int (item['date'])) if createTime <= yearAgo and not attachments and len(text) < 75: # Игнорировать эту публикацию Как и в предыдущем пункте, много старых публикаций были с текстом (описанием картинки во вложении), но сами картинки уже не сохранились.
Следующим шагом было очистка неудачных публикаций, которые просто «не зашли»:
db.posts.aggregate ( { $match: { gid: GROUP_ID } }, { $group: { _id:»$gid», average: {$avg:»$likes»} } } ) Этот метод выполняется на таблицу posts, у которой есть поле likes (количество лайков у публикации). Он возвращает среднее арифметическое лайков по этой группе.Теперь можно просто удалить все публикации старше 3 дней, у которых количество лайков меньше среднего:
db.posts.remove ( { 'gid' : groupId, 'created' : { '$lt' : removeTime }, 'likes': { '$lt' : avg } } ) removeTime = datetime.datetime.now () — datetime.timedelta (days=3) avg = результату предыдущего запроса, разделенного на два (методом подбора). Результирующую и отфильтрованную публикацию добавляю в базу данных, на этом парсинг заканчивается. Разница между парсингом и обновлением групп я сделал только в одном пункте: обновление вызывается ровно 1 раз для группы, т.е. получаю только 500 последних записей (5 по 100 через execute). В общем этого вполне достаточно, учитывая, что вконтакте ввели лимит на количество публикаций: 200 в сутки.
Front-end Не буду сильно подробно расписывать, javascript + jquery + isotope + inview + mustache.Isotope используется для современного вывода публикаций в виде плитки. Inview позволяет легко реагировать на события попадания во viewport опредлеенного элемента. (в моем случае — запоминаю просмотренные публикации, а новые выделяю особым цветом). Mustache позволяет строить dom-объекты по шаблону. Фильтр публикаций по группе Для вывода данных по группам был написан простой php-скрипт.Это вспомогательная функция, которая по типу фильтра времени создавала объект, который можно использовать напрямую в запросе. function filterToTime ($timeFilter) { $mongotime = null; if ($timeFilter == 'year') $mongotime = new Mongodate (strtotime (»-1 year», time ())); else if ($timeFilter == 'month') $mongotime = new Mongodate (strtotime (»-1 month», time ())); else if ($timeFilter == 'week') $mongotime = new Mongodate (strtotime (»-1 week», time ())); else if ($timeFilter == 'day') $mongotime = new Mongodate (strtotime («midnight»)); else if ($timeFilter == 'hour') $mongotime = new Mongodate (strtotime (»-1 hour»));
return $mongotime; } А следующий код уже получает 15 лучших постов за месяц:
$groupId = 42; // Какой-то id группы $mongotime = filterToTime ('week'); $offset = 1; // Первая страница
$findCondition = array ('gid' => $groupId, 'created' => array ('$gt' => $mongotime)); $mongoHandle→posts→find ($findCondition)→limit (15)→skip ($offset * $numPosts); Логика index страницы Смотреть статистику по группе интересно, но куда интереснее построить общий рейтинг абсолютно всех групп и их публикаций. Если задуматься, задание очень сложное: Мы можем строить рейтинг только по 3 факторам: количество лайков, репостов и подписчиков. Чем больше подписчиков — тем больше лайков и репостов, но это не гарантирует качество контента.Большинство групп-миллионников публикуют часто и всякий мусор, который уже несколько лет бродит по интернету, и среди миллиона подписчиков постоянно находятся те, кто будет репостить и лайкать.Построить рейтинг по голым цифрам легко, но полученный результат никак не можно назвать рейтингом публикаций по их качеству и уникальности.Были идеи вывести коэффициент качества каждой группы: строить шкалу времени, смотреть активность пользователей за каждый промежуток времени и так далее.К сожалению, адекватного решения я не придумал. Если у вас будут какие-то идеи, буду рад выслушать.
Первое, что я понял, было осознание того, что содержимое index-страницы нужно просчитывать и кешировать для всех пользователей, потому что это очень медленная операция. Здесь и приходит на помощь memcached. За самую простую логику был выбран следующий алгоритм:
Проходим циклом по всем группам Берем все публикации i-й группы и выбираем 2 лучшие из них за указанный промежуток времени Как результат, в выдаче от одной группы будет не более 2 публикаций. Конечно, это не самый правильный результат, но на практике показывает неплохую статистику и актуальность контента.
Вот как выглядит код потока, который раз в 15 минут генерирует index-страницу:
# timeDelta — тип фильтра по времени (hour, day, week, year, alltime) # filterType — likes, reposts, comments # deep — 0, 1, … (страница)
def _get (self, timeDelta, filterTime, filterType='likes', deep = 0): groupList = groups.find ({}, {'_id' : 0}) allPosts = [] allGroups = [] for group in groupList: allGroups.append (group) postList = db['posts'].find ({'gid' : group['id'], 'created' : {'$gt' : timeDelta}}) \ .sort (filterType, -1).skip (deep * 2).limit (2) for post in postList: allPosts.append (post)
result = { 'posts' : allPosts[:50], 'groups' : allGroups }
# Этот код позволяет сгенерировать timestamp из mongotime, при конвертировании в json dthandler = lambda obj: (time.mktime (obj.timetuple ()) if isinstance (obj, datetime.datetime) or isinstance (obj, datetime.date) else None) jsonResult = json.dumps (result, default=dthandler)
key = 'index_' +filterTime+ '_' +filterType+ '_' + str (deep) print 'Setting key: ', print key self.memcacheHandle.set (key, jsonResult) Опишу фильтры, которые влияют на выдачу: Время: час, день, неделя, месяц, год, все времяТип: лайки, репосты, комментарии
Для всех пунктов времени были сгенерированы объекты
hourAgo = datetime.datetime.now () — datetime.timedelta (hours=3) midnight = datetime.datetime.now ().replace (hour=0, minute=0, second=0, microsecond=0) weekAgo = datetime.datetime.now () — datetime.timedelta (weeks=1) monthAgo = datetime.datetime.now () + dateutil.relativedelta.relativedelta (months=-1) yearAgo = datetime.datetime.now () + dateutil.relativedelta.relativedelta (years=-1) alltimeAgo = datetime.datetime.now () + dateutil.relativedelta.relativedelta (years=-10) Все они по очереди передаются в функцию _get вместе с разными вариациями фильтра по типу (лайки, репосты, комментарии). Еще ко всему этому, нужно сгенерировать по 5 страниц для каждой вариации фильтров. Как результат, в memcached проставляются следующие ключи:
Setting key: index_hour_likes_0Setting key: index_hour_reposts_0Setting key: index_hour_comments_0Setting key: index_hour_common_0Setting key: index_hour_likes_1Setting key: index_hour_reposts_1Setting key: index_hour_comments_1Setting key: index_hour_common_1Setting key: index_hour_likes_2Setting key: index_hour_reposts_2Setting key: index_hour_comments_2Setting key: index_hour_common_2Setting key: index_hour_likes_3Setting key: index_hour_reposts_3Setting key: index_hour_comments_3Setting key: index_hour_common_3Setting key: index_hour_likes_4Setting key: index_hour_reposts_4Setting key: index_hour_comments_4Setting key: index_hour_common_4Setting key: index_day_likes_0Setting key: index_day_reposts_0Setting key: index_day_comments_0Setting key: index_day_common_0Setting key: index_day_likes_1Setting key: index_day_reposts_1Setting key: index_day_comments_1Setting key: index_day_common_1Setting key: index_day_likes_2Setting key: index_day_reposts_2Setting key: index_day_comments_2Setting key: index_day_common_2Setting key: index_day_likes_3Setting key: index_day_reposts_3…
А на стороне клиента лишь генерируется нужный ключ и вытаскивается json-строка из memcached.
Twitter Следующим интересным заданием было сгенерировать популярные твиты по странам СНГ. Задание тоже непростое, хотелось бы получать актуальную и не «трешовую» информацию. Я очень удивился ограничениям твиттера: не получится так просто взять и слить все твиты определенных пользователей. API очень ограничивает количество запросов, поэтому уже нельзя сделать так, как это делает вк: составить список популярных аккаунтов и постоянно парсить их твиты.Через день пришло решение: создаем аккаунт в твиттере, подписываемся на всех важных людей, тематика публикаций которых нам интересна. Трюк в том, что почти в 80% случаев, кто-то из этих людей сделает ретвит какого-то популярного твита. Т.е. нам не нужно иметь в базе список всех аккаунтов, достаточно набрать базу из 500–600 активных людей, которые постоянно в тренде и делают ретвиты реально интересных и популярных твитов.В API твиттера есть метод, который позволяет получить ленту пользователя, которая включает твиты тех, на кого мы подписаны и их репосты. Все, что нам нужно теперь — раз в 10 минут считывать по максимуму нашу ленту и сохранять твиты, фильтры и все остальное делаем так же, как и в случае с вконтакте.
Итак, был написан еще один поток внутри демона, который раз в 10 минут запускал такой код:
def __init__(self): self.twitter = Twython (APP_KEY, APP_SECRET, TOKEN, TOKEN_SECRET)
def logic (self): lastTweetId = 0
for i in xrange (15): # Цифра подобрана методом тыка self.getLimits () tweetList = []
if i == 0: tweetList = self.twitter.get_home_timeline (count=200) else: tweetList = self.twitter.get_home_timeline (count=200, max_id=lastTweetId)
if len (tweetList) <= 1: print '1 tweet, breaking' # Все, больше твитов API нам не выдаст break
# … lastTweetId = tweetList[len (tweetList)-1]['id'] Ну, а дальше обычный и скучный код: у нас есть tweetList, проходим циклом и обрабатываем каждый твит. Список полей в официальной документации. Единственное, на чем хочу акцентировать внимание:
for tweet in tweetList: localData = None if 'retweeted_status' in tweet: localData = tweet['retweeted_status'] else: localData = tweet В случае с ретвитом, нам нужно сохранять не твит одного из наших подписчиков, а оригинальный. Если текущая запись это ретвит, то она содержит внутри по ключу 'retweeted_status' точно такой же объект твита, только оригинального.
Финал С дизайном сайта и версткой есть проблемы (сам я ни разу не веб-программист), но, надеюсь, кому-то будет полезная информация, которую я описал. Сам уже очень много времени работаю с соц. сетями и их API и знаю много трюков. Если у кого-то будут какие-то вопросы — буду рад помочь.Ну и несколько картинок:
Index-страница:
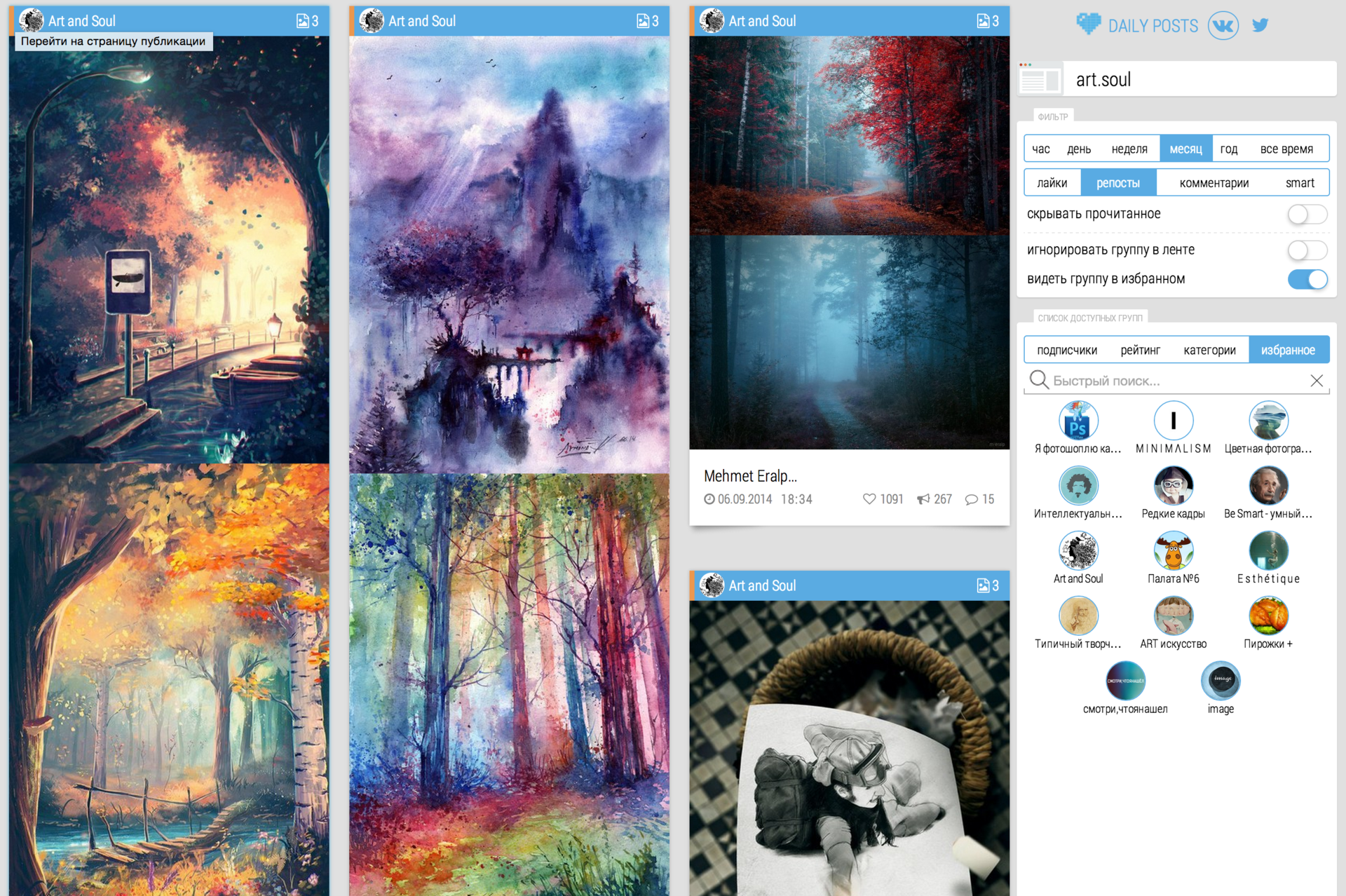
 Страница одной из групп, которую я постоянно мониторю:
Страница одной из групп, которую я постоянно мониторю:
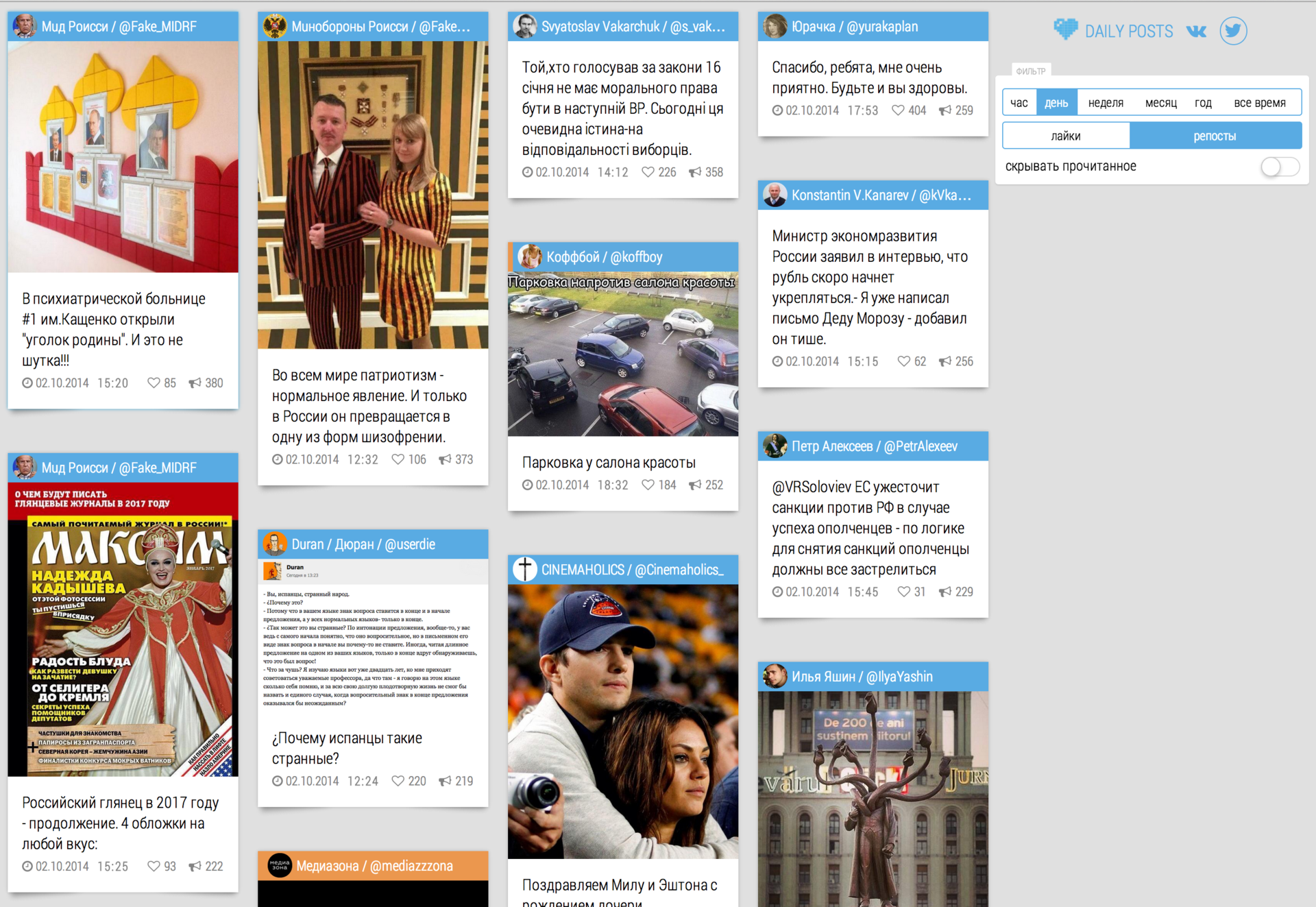
 Твиттер за день:
Твиттер за день:
 Спасибо за внимание.
Спасибо за внимание. — dailymap.org
— dailymap.org
