Ломаем зашифрованный диск для собеседования от RedBalloonSecurity. Part 0x01

По мотивам
Часть 0×00
А что дальше?
Уважаемые хабровчане и хабровчушки, эта статья является долгожданным продолжением моей предыдущей статьи о взломе жесткого диска для собеседования в инфосек компанию RedBalloonSecurity. Любителей поковырять железяки я спешу разочаровать, поскольку все дальнейшие манипуляции с диском будут проводиться только на уровне ассемблерного кода и логики. Поэтому, приготовьте чай/кофе или чего покрепче, ведь мы снова лезем в embeded дебри и опять пускаемся в неизвестность.
Также, спешу вам сообщить, что в этой статье будет оочень много низкоуровневой компьютерной математики. Поэтому, пока будет закипать чайник, советую запихнуть голову в морозилку на пару минут. Для полного понимания этого уровня и способа его взлома нужна холодная голова!
LEVEL2
Моему счастью не было предела, когда я залил пропатченую прошивку на Winbond Flash чип, и ядро моего Debian-неттопа распознало еще 1 раздел диска. Здесь будет намного больше информации, чем в предыдущем разделе. Ведь повышая левел, сложность нашей с вами задачи только увеличивается.
Содержимое раздела:
user@ubuntu:/media/user/LEVEL2$ file *
0001-keystone-armv5.patch: unified diff output, ASCII text
level_2.html: HTML document, ASCII text, with very long lines
level2_instructions.txt: ASCII text
level_2.lod: data
level_3.lod.7z.encrypted: 7-zip archive data, version 0.3level_2.lod — это новый файл прошивки для диска. Прошиваемся так же, как и в предыдущей статье. Здесь ничего нового.
level_3.lod.7z.encrypted — это файл прошивки для следующего уровня. Судя по его разрешению, файл находится в запароленном 7z архиве. Нам нужно решить текущий уровень чтоб достать пароль от следующего.
level2_instructions.txt — это, собственно, инструкции что и как делать. Подсказки тоже имеются.
0001-keystone-armv5.patch — это патч для Keystone Assembler. Keystone это компилятор и набор С-шных библиотек для перевода ассемблерного кода в опкоды для процессора.
level_2.html — изюминка текущего уровня. Выглядит точ-в-точ как текст, который генерирует IDA Pro при загрузке бинарника.
Для тех, кто не в курсе, IDA Pro это легендарная программа для дизассемблирования. Она настолько легендарная, что можете открыть страничку https://www.hex-rays.com/cgi-bin/quote.cgi, глянуть ценники на лицензии (которые разбиты по архитектурам), тут же закрыть вкладку, и, посвистывая, продолжить чтение этой статьи. У IDA Pro есть аналоги в виде Hopper Disassembler & Binary Ninja, и сейчас ценовая политика hex-rays чуть попроще, чем раньше (есть фришные версии). Но, опять таки — стоимость индустрии определяет стоимость инструментов.
Дело в том, что когда мы пишем код на высокоуровневых языках (C, Python и тд) и подвергаем его компиляции, мы переводим наш ± human-readable текст в язык машинного кода. То есть, мы опускаем более понятную человеку логику в логику, которая больше понятна машине. Машина не понимает что такое функция, ведь функция, это скорее абстракция в голове у программиста. Процесс дизассемблирования позволяет сделать наоборот — поднять логику из машинного на человекопонятный уровень. Некоторые дизассемблеры позволяют поднять логику даже на C-шный уровень, хоть и не всегда делают это корректно (на самом деле очень даже корректно, но читать такой код порой бывает сложнее чем ассемблер). Если работаем с чем-то мелким, и надо кабанчиком понять что там происходит — этого хватит, но для более высокоточных вещей нужен ассемблер. Это мы и получили в виде level_2.html файла.
user@ubuntu:/media/user/LEVEL2$ cat level2_instructions.txt
Congratulations... you have made it to the other side
Back when I was an intern, I designed this key generation function. My boss hated it.
I hate my boss.
1. Invoke the function with command R
2. Find the key you must!!!!!
level2.html provides disassembly of a memory snapshot of the key generator function.
To help... guide... you in this adventure, you'll find a patchfile for the keystone
assembler to force the correct architecture.
Also, AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAASCII В этой подсказке кто-то ненавидит своего босса. Но, помимо этого, мы понимаем, что для решения этой задачи надо ввести в консольник диска что-то, что начинается на «R» — так мы запустим код, который имеем в дампе. И, с помощью этого, заставить программу отдать ключи. Самой полезной подсказкой была последняя фраза. Она намекает нам на то, что мы должны заабьюзить overflow.
0001-keystone-armv5.patchuser@ubuntu:/media/user/LEVEL2$ cat 0001-keystone-armv5.patch
From 5532e7ccbc6c794545530eb725bed548cbc1ac3e Mon Sep 17 00:00:00 2001
From: mysteriousmysteries
Date: Wed, 15 Feb 2017 09:23:31 -0800
Subject: [PATCH] armv5 support
---
llvm/keystone/ks.cpp | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/llvm/keystone/ks.cpp b/llvm/keystone/ks.cpp
index d1819f0..8c66f19 100644
--- a/llvm/keystone/ks.cpp
+++ b/llvm/keystone/ks.cpp
@@ -250,7 +250,7 @@ ks_err ks_open(ks_arch arch, int mode, ks_engine **result)
if (arch < KS_ARCH_MAX) {
ks = new (std::nothrow) ks_struct(arch, mode, KS_ERR_OK, KS_OPT_SYNTAX_INTEL);
-
+
if (!ks) {
// memory insufficient
return KS_ERR_NOMEM;
@@ -294,7 +294,7 @@ ks_err ks_open(ks_arch arch, int mode, ks_engine **result)
TripleName = "armv7";
break;
case KS_MODE_LITTLE_ENDIAN | KS_MODE_THUMB:
- TripleName = "thumbv7";
+ TripleName = "armv5te";
break;
}
@@ -566,7 +566,7 @@ int ks_asm(ks_engine *ks,
Streamer = ks->TheTarget->createMCObjectStreamer(
Triple(ks->TripleName), Ctx, *ks->MAB, OS, CE, *ks->STI, ks->MCOptions.MCRelaxAll,
/*DWARFMustBeAtTheEnd*/ false);
-
+
if (!Streamer) {
// memory insufficient
delete CE;
@@ -594,7 +594,7 @@ int ks_asm(ks_engine *ks,
return KS_ERR_NOMEM;
}
MCTargetAsmParser *TAP = ks->TheTarget->createMCAsmParser(*ks->STI, *Parser, *ks->MCII, ks->MCOptions);
- if (!TAP) {
+ if (!TAP) {
// memory insufficient
delete Parser;
delete Streamer;
--
1.9.1 Патч для keystone говорит нам о том, на какой вариации ARM архитектуры работает наш IC на плате от жесткого диска — armv5te. Фотка IC есть в предыдущей статье.
Я прошил диск файлом level_2.lod. Подключившись в консольник диска, я, последовав подсказкам, нажал Ctrl+Z. После чего, меня ждала строка приглашения от Seagate F3 меню. Это меню является механизмом для диагностики HDD. Через него можно узнать сколько раз заводился сервопривод диска, количество и местоположение бэд секторов, засечь время поиска определенного сектора, и очень много прочих параметров. Через него с диском можно делать все, что угодно — даже записать какие-то данные по определенному LBA адресу. Я так понял, ребята, когда делали этот челлендж, переписали то, как должен реагировать диск на команду «R». Что же, сюда мы и будем вводить «R…».
Welcome to minicom 2.7.1
OPTIONS: I18n
Compiled on Aug 13 2017, 15:25:34.
Port /dev/ttyS0, 19:19:01
Press CTRL-A Z for help on special keys
Rst 0x08M
Servo Processor Is Reset.
RW: Disc Ctlr Initialization Completed.
ExecuteSpinRequest
(P) SATA Reset
ASCII Diag mode
F3 T>
CTRL-A Z for help | 38400 8N1 | NOR | Minicom 2.7.1 | VT102 | Offline | ttyS0Серьезно? ASM?
В этом code-box приведены первые 20 строк из level_2.html файла. В конце публикации есть файл целиком, но в процессе статьи, давайте смотреть на него кусочками:
01. ROM:00332D00
02. ROM:00332D00 ; Segment type: Pure code
03. ROM:00332D00 AREA ROM, CODE, READWRITE, ALIGN=0
04. ROM:00332D00 ; ORG 0x332D00
05. ROM:00332D00 CODE16
06. ROM:00332D00
07. ROM:00332D00 ; =============== S U B R O U T I N E =======================================
08. ROM:00332D00
09. ROM:00332D00 ; prototype: generate_key(key_part_num, integrity_validate_table, key_table)
10. ROM:00332D00 ; Function called when serial console input is 'R'. Generates key parts in R0-R3.
11. ROM:00332D00 ; The next level to reach, the key parts to print you must!
12. ROM:00332D00
13. ROM:00332D00 generate_key
14. ROM:00332D00
15. ROM:00332D00 var_28 = -0x28
16. ROM:00332D00
17. ROM:00332D00 PUSH {R4-R7,LR}
18. ROM:00332D02 SUB SP, SP, #0x10
19. ROM:00332D04 MOVS R7, R1
20. ROM:00332D06 MOVS R4, R2
...Колонка слева с ROM: XXXXXXXX — это адреса памяти. При загрузке бинарника в IDA Pro, мы должны убедиться, правильно ли IDA Pro поняла для какой архитектуры (ARM, x86, MIPS и тд) собран наш бинарник (в большинстве случаев, автоопределение работает очень хорошо, но если мы вгружаем не бинарник, а целый дамп памяти — прийдется вручную настроить IDA Pro). Считываем файл байт за байтом, и эта левая колонка автоинкрементируется каждый раз когда IDA Pro понимает что это за кусок данных. Данные в бинарнике могут быть поняты одним из следующих образов:
Данные. Самый низкий уровень понимания логики. Это когда кусок данных не представляет собой ничего конкретного. В дампе отображается как DCD, DCW, DCB — doubleword, word, byte соответственно. На такие штуки обычно есть ссылки из других участков кода. Назначение может быть самое разное.
Код. Это когда кусок данных представляет собой 1 атомарную единицу операции (записать данные из регистра в память, сравнить числа и тд).
Строка. Это когда IDA Pro натыкается на массив данных которые лежат в ASCII диапазоне. От 0×20 до 0×7E (ASCII стандарт также описывает числа ниже 0×20, но они не имеют «текстового» смысла). Вполне возможно, что диапазон расширяется и на другие кодировки, но это вне контекста данной статьи.
Подпроцедура (Subroutine). Это довольно высокий уровень понимания ассемблерной логики — когда IDA Pro видит функцию. В ней мы видим то же самое, как если бы видели код. Но, понимание того, что это не просто код, а функция дает невероятный скачок в осознании происходящего. Также, выдавать C-шный код IDA Pro может только для подпроцедур (или нет. Поправьте, если я не прав). В нашем level_2.html мы видим только подпроцедуры — имеем максимальный уровень понимания. Задачка для интерна, все-таки.
Как я и говорил, дизассемблер не всегда распознает вещи корректно. Поэтому, при работе с IDA Pro есть возможность переключать режимы понимания данных на разных участках памяти.
LSI B5502D0
На 5й строке мы видим надпись CODE16. Это очень важно, поскольку этот дамп снят с кода для ARM процессоров. У них есть 2 режима работы — ARM и Thumb.
В режиме ARM у нас есть доступ, наверное, ко всем ассемблерным операциям, но такие инструкции занимают 4 байта
В режиме Thumb мы немножко ограничены, но такие инструкции занимают 2 байта.
Причины по которым были созданы эти 2 режима мне неизвестны (знатоки в комментариях очень даже приветствуются), но могу сказать следующее:
В режиме ARM мы, скорее всего, будем исполнять желаемую логику быстрее. Как минимум, потому что, у нас есть доступ к инструкциям типа CMPEQ, которая выполнит операцию сравнения чисел только в том случае, когда результат предыдущего сравнения был успешным. Получается, что в этом режиме мы можем отдать логику if-else не просто на железо, а внутрь процессора. И сделать 2 операции (проверка предыдущего результата и выполнение новой операции) за 1 цикл (если я правильно это понимаю) без хождения по памяти. Но и размер инструкций будет больше, а значит, что нужно использовать больше памяти.
В режиме Thumb мы не можем использовать подобное, но размер инструкций будет в 2 раза меньше, а значит, и затраты памяти будут ниже.
Еще стоит сказать, что архитектура ARM (не путать с режимом) прекрасна тем, что размер инструкций у них фиксирован (2 или 4 байта), чего нельзя сказать об x86.
В общем, вот это CODE16 значит то, что в этом моменте процессор находится в Thumb режиме (CODE16 — 16 бит на инструкцию). И, как мы видим дальше, адреса памяти инкрементируются по 2 байта (конечно, только там, где есть инструкция).
Строка 13 являет собой адрес, на который есть отсылки в коде. Дело в том, что программы на ассемблере не исполняются линейно. Инструкции типа B, BL, BX, BLX переводят исполнение кода по новому адресу. И когда IDA Pro видит такие инструкции, она автоматически дает имя этому адресу. В нашем случае, ребята из RedBalloonSecurity переименовали этот адрес в generate_key. Переименовывать позиции в коде, на который есть ссылки является прекрасным способом оставить для себя заметку о том, что делает определенный кусок кода. При работе с дизассемблером, подобное переименование «отрефакторит» это имя на каждом референсе по этому адресу — это очень удобно.
На строке 15 мы видим переменную. Надеюсь, все помнят об области видимости в С? Реализация этого механизма на уровне ассемблера очень хитрая. Здесь используется структура данных типа стек.
Ëмае, вот к чему stack в stackoverflow
У каждого процессора, помимо кэша, есть встроенное хранилище временных данных — регистры. Это самая быстрая память компьютера, как такового. Все операции с регистрами выполняются невероятно быстро. А поэтому, программу нужно строить таким образом чтоб минимизировать обращения к памяти, и почаще использовать регистры. Благо, компиляторы умные — умеют оптимизировать с разной точностью, и располагают что куда, даже если С-шный код писал рак (и то, не всегда).
У ARM процессоров 15 регистров. Для большинства, можно писать код и использовать их как хочешь (хотя, внутри компилятора, все же есть определенные правила о том, какой регистр для чего использовать. А в некоторые писать напрямую запрещено). Они имеют имена вида R0, R1 … R15. Последние имеют специальное назначение:
SP (R13) — Stack Pointer. В этом регистре хранится адрес вершины стека
BP (R7 в Thumb, R11 в ARM) — Base Pointer. Здесь находится адрес начала стека
LR (R14) — Link Register. Если у бренч (B) инструкции есть приставка L, это значит, что содержимое регистра PC нужно записать в регистр LR (там есть определенная специфика, которую я не совсем понимаю. К этому адресу в LR должно добавляться +2 байта при Thumb, или +4 байта при ARM. Но, это не точно). Потом это используется для возврата на предыдущее место в коде, например через BX LR. К примеру С-шный «return» отработает именно по такой логике (и то, если так решит компилятор). Из преимуществ — он быстрее, и часть программной логики падает на CPU без хождения по памяти. Недостаток — регистр всего один, и предыдущие адреса возврата все же прийдется складывать на стек.
PC (R15) — Program Counter. Здесь находится адрес инструкции, которую процессор выполняет в данный момент. Писать сюда напрямую, кажись, нельзя. Но этот регистр полезен, если мы хотим сделать прыжок на другой адрес. Если мы работаем с 32-битной архитектурой, мы, ну никак не можем сказать процессору прыгнуть на 32-битный адрес, имея 2 или 4 байта на 1 инструкцию. Большинство инструкций для прыжка используют сдвиг от того, что находится в PC.
CSPR — Current State Process Register. Это специфический регистр. К нему нельзя обратиться целиком, как и записать сюда что-то. Данные внутри этого регистра формируются автоматически на основе того, какие инструкции выполняет процессор. Он разбит на сегменты, и хранит в себе информацию о текущем состоянии процессора. К примеру, если мы выполняем инструкцию CMP (сравнить числа), результат сравнения (0 или 1) пишется в один из битов этого регистра. А в дальнейшем это используется для условных операций.
Стек это определенное место в памяти, где хранятся значения локальных переменных, аргументы функций, адреса возвратов, а также предыдущее значение BP. Стек логически разбит на сегменты (stack frames). Каждый сегмент принадлежит какой-то определенной функции. И, когда мы вызываем из одной функции другую, мы, создавая новый stack frame, сдвигаем адреса BP & SP чуть ниже (!) в памяти. Но, перед тем как создавать новый сегмент на стеке, мы должны знать адрес, куда должен вернутся PC после завершения функции — он сохраняется на стеке (Return Address) перед вызовом новой функции. Также, чтоб при возврате, сегмент стека стал того же размера что и был, мы сохраняем предыдущее значение BP (Saved %ebp) на этот же стек. Это пример для x86, но и на ARM дела обстоят так же. Выглядит все это дело примерно так (%ebp = BP, %esp = SP):
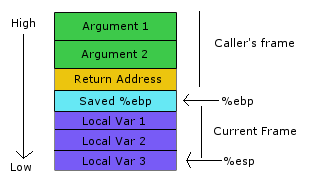
Стоит оговориться, что механизм по созданию и уничтожению stack frame’ов для меня до сих пор не совсем понятен. Поэтому, очень советую поискать что-то на ютубе. Для понимания таких вещей нужна визуальная картинка.
В предыдущем абзаце я сказал, что при создании нового сегмента стека, адреса BP & SP смещаются ниже. Дело в том, что «так сложилось исторически». Стек это FIFO конструкция, размер которой меняется в процессе исполнения программы. И компилятор не знает какого размера он может быть. То же самое касается кучи (heap) — памяти, которую мы запрашиваем у системы через семейство вызовов malloc (glibc). При выделении памяти в куче, ее адреса растут вверх, а вот когда растет стек, его адреса растут вниз. Стоит оговориться, что мы работаем с embeded устройством. Понятия кучи здесь, может и не быть (опять же, прошу экспертов меня поправить).
У ARM процессоров есть специальное семейство инструкций, которые работают со стеком: PUSH, POP, STMFD, LDMFD (уверен, есть еще, но для наших грязных делишек этого хватит).
PUSH кладет то, что в аргументе на стек, и увеличивает его (на самом деле уменьшает адрес)
POP снимает со стека данные, кладет туда, куда указывает аргумент, и уменьшает стек (на самом деле увеличивает адрес)
STMFD, LDMFD (store/load multiple) делают то же самое, но туда можно запихнуть несколько регистров, и снять со стека несколько значений в рамках одной инструкции. И, кажись, указать, стоит ли подстраивать значение в SP в зависимости от количества впихнутых/снятых значений со стека. Опять же, прелести ARM архитектуры!
Я бы не обьяснял это так детально, но понимание того, как устроен стек, и для чего он нужен — критично для взлома данного уровня. Без этого никуда!
Готовы? Ныряем!
Для того, чтоб что-то правильно сломать, нужно это правильно понять. Начнем с первых инструкций из level_2.html.
...
13. ROM:00332D00 generate_key
14. ROM:00332D00
15. ROM:00332D00 var_28 = -0x28
16. ROM:00332D00
17. ROM:00332D00 PUSH {R4-R7,LR}
18. ROM:00332D02 SUB SP, SP, #0x10
19. ROM:00332D04 MOVS R7, R1
20. ROM:00332D06 MOVS R4, R2
21. ROM:00332D08 MOVS R5, R0
22. ROM:00332D0A LDR R1, =0x6213600 ; "R"...
23. ROM:00332D0C LDRB R0, [R1,#1]
24. ROM:00332D0E CMP R0, #0x31
25. ROM:00332D10 BNE loc_332D1A
26. ROM:00332D12 ADDS R0, R1, #2
27. ROM:00332D14 BLX ahex2byte
...Строка 17. Первая инструкция это PUSH. Она сохраняет на стек переменные из регистров R4-R7 и LR на стек, то есть сохраняет предыдущий stack frame.
Дисклэймер: в отличии от всеми любимой bash консольки, где программы типа mv, cp используют схему аргументов command source destination, ассемблерные инструкции используют схему »instruction destination source». Единственным исключением является семейство инструкций для записи в память — STR.
Строка 18. Через SUB отнимаем 16 байт от SP (увеличиваем стек).
Строка 19–21. Копируем из регистров R0-R2 аргументы, которые были переданы в функцию generate_key в их «рабочие» места в рамках текущей функции. Как видим, в прототипе (строка 9) было 3 аргумента. Регистров столько же. В предыдущем разделе я говорил, что аргументы падают на стек — это правда только в том случае, когда аргументов больше, чем 3 (или 4, уже не помню). Опять таки, лучше использовать регистры, чем ходить в память.
На этом моменте заканчивается процедура под названием Function Prologue. То есть, не происходит ничего, что касается программной логики, но, выполняется подготовка стека и локальных переменных. Мне кажется, именно по подобным шаблонам IDA Pro отличает код от подпроцедур.
Строка 22. Грузим адрес, который будет указывать на первый символ того, что мы вводим в консольник диска в регистр R1. Комментарий здесь очень полезен.
Строка 23. Семейство инструкций LDR предназначено для работы с памятью. Инструкция
LDRB R0, [R1,#1] (Load Register Byte)
берет то, что лежит в регистре R1, добавляет единицу (по сути, берет адрес второго вводимого символа), лезет в память по этому адресу (если значение в квадратных скобках, сначала надо интерпретировать эти данные как адрес памяти), берет 1 байт и сохраняет его в регистр R0. Мы забрали второй вводимый символ в R0.
Строка 24–25. Идет сравнение 2 го вводимого символа с 0×31. В ASCII 0×31 это »1». Инструкция
BNE loc_332D1A (Branch If Not Equal)
выполнит прыжок на loc_332D1A только в том случае, если мы ввели не единичку.
Строка 26. Добавляем к адресу наших вводимых данных двойку и сохраняем в R0. Инструкция с тремя операндами
ADDS R0, R1, #2
возьмет значение из R1, добавит в него двойку, и сохранит результат в R0. То есть, теперь адрес в R0 указывает на третий вводимый символ — «R1_» (на то место, где underscore).
Строка 27. Здесь нас ждет безусловный прыжок на функцию ahex2byte. Но, это не просто прыжок. Инструкция
BLX ahex2byte (Branch Link Exchange)
кроме прыжка, делает еще 2 замечательные вещи — сохраняет адрес инструкции после текущего PC в LR (из-за «L» в BLX), и переключает нас в ARM режим (из-за «X» в BLX)! Внутри функции ahex2byte у нас будет 4 байта на инструкцию. В регистр R0 пишется первый аргумент при вызове функции. Получается, что мы запускаем функцию ahex2byte с одним единственным аргументом — адресом третьего вводимого символа.
Дабы подитожить, вот то, как предыдущий кусок выглядел бы в С-шном виде. Этот код не скомпилируеться и может быть неправильным. Прошу экспертов меня поправить. Он чисто для наглядности:
void generate_key (key_part_num, integrity_validate_table, key_table) {
char *input = "R1_";
if (input[1] == "1") {
&input = &input + 2;
ahex2byte(&input);
}
else {
goto: loc_332D1A;
}
}ахекс2 байт
В этом code-box представлен еще 1 кусок от level_2.html — функция ahex2byte. Здесь я настоятельно рекомендую читателям скопировать содержимое спойлера себе в блокнот, и расположить окно слева (или справа, черт вас знает) от этой статьи, иначе прийдется очень много скроллить. В процессе чтения, поглядывайте на ASM код, и вам станет все ясно.
ahex2byte...
137. ROM:00332DF8 ; =============== S U B R O U T I N E =======================================
138. ROM:00332DF8
139. ROM:00332DF8
140. ROM:00332DF8 ahex2byte ; CODE XREF: generate_key+14p
141. ROM:00332DF8 STMFD SP!, {R4-R6,LR}
142. ROM:00332DFC MOV R4, R0
143. ROM:00332E00 MOV R6, R0
144. ROM:00332E04
145. ROM:00332E04 loc_332E04 ; CODE XREF: ahex2byte+6Cj
146. ROM:00332E04 LDRB R0, [R4]
147. ROM:00332E08 CMP R0, #0xD
148. ROM:00332E0C BEQ loc_332E68
149. ROM:00332E10 BL sub_332E70
150. ROM:00332E14 CMN R0, #1
151. ROM:00332E18 BNE loc_332E2C
152. ROM:00332E1C LDRB R0, [R4]
153. ROM:00332E20 BL sub_332E98
154. ROM:00332E24 CMN R0, #1
155. ROM:00332E28 BEQ locret_332E6C
156. ROM:00332E2C
157. ROM:00332E2C loc_332E2C ; CODE XREF: ahex2byte+20j
158. ROM:00332E2C MOV R5, R0
159. ROM:00332E30 LDRB R0, [R4,#1]
160. ROM:00332E34 BL sub_332E70
161. ROM:00332E38 CMN R0, #1
162. ROM:00332E3C BNE loc_332E50
163. ROM:00332E40 LDRB R0, [R4,#1]
164. ROM:00332E44 BL sub_332E98
165. ROM:00332E48 CMN R0, #1
166. ROM:00332E4C BEQ locret_332E6C
167. ROM:00332E50
168. ROM:00332E50 loc_332E50 ; CODE XREF: ahex2byte+44j
169. ROM:00332E50 MOV R5, R5,LSL#4
170. ROM:00332E54 ADD R0, R5, R0
171. ROM:00332E58 STRB R0, [R6]
172. ROM:00332E5C ADD R4, R4, #2
173. ROM:00332E60 ADD R6, R6, #1
174. ROM:00332E64 B loc_332E04
175. ROM:00332E68 ; ---------------------------------------------------------------------------
176. ROM:00332E68
177. ROM:00332E68 loc_332E68 ; CODE XREF: ahex2byte+14j
178. ROM:00332E68 STRB R0, [R6]
179. ROM:00332E6C
180. ROM:00332E6C locret_332E6C ; CODE XREF: ahex2byte+30j
181. ROM:00332E6C ; ahex2byte+54j
182. ROM:00332E6C LDMFD SP!, {R4-R6,PC}
183. ROM:00332E6C ; End of function ahex2byte
184. ROM:00332E6C
185. ROM:00332E70
186. ROM:00332E70 ; =============== S U B R O U T I N E =======================================
187. ROM:00332E70
188. ROM:00332E70
189. ROM:00332E70 sub_332E70 ; CODE XREF: ahex2byte+18p
190. ROM:00332E70 ; ahex2byte+3Cp
191. ROM:00332E70 CMP R0, #0xD
192. ROM:00332E74 BEQ loc_332E90
193. ROM:00332E78 CMP R0, #0x30
194. ROM:00332E7C BLT loc_332E90
195. ROM:00332E80 CMP R0, #0x39
196. ROM:00332E84 BGT loc_332E90
197. ROM:00332E88 SUB R0, R0, #0x30
198. ROM:00332E8C B locret_332E94
199. ROM:00332E90 ; ---------------------------------------------------------------------------
200. ROM:00332E90
201. ROM:00332E90 loc_332E90 ; CODE XREF: sub_332E70+4j
202. ROM:00332E90 ; sub_332E70+Cj ...
203. ROM:00332E90 MVN R0, #0
204. ROM:00332E94
205. ROM:00332E94 locret_332E94 ; CODE XREF: sub_332E70+1Cj
206. ROM:00332E94 BX LR
207. ROM:00332E94 ; End of function sub_332E70
208. ROM:00332E94
209. ROM:00332E98
210. ROM:00332E98 ; =============== S U B R O U T I N E =======================================
211. ROM:00332E98
212. ROM:00332E98
213. ROM:00332E98 sub_332E98 ; CODE XREF: ahex2byte+28p
214. ROM:00332E98 ; ahex2byte+4Cp
215. ROM:00332E98 CMP R0, #0x41
216. ROM:00332E9C BLT loc_332EB4
217. ROM:00332EA0 CMP R0, #0x46
218. ROM:00332EA4 BGT loc_332EB4
219. ROM:00332EA8 SUB R0, R0, #0x41
220. ROM:00332EAC ADD R0, R0, #0xA
221. ROM:00332EB0 B locret_332EB8
222. ROM:00332EB4 ; ---------------------------------------------------------------------------
223. ROM:00332EB4
224. ROM:00332EB4 loc_332EB4 ; CODE XREF: sub_332E98+4j
225. ROM:00332EB4 ; sub_332E98+Cj
226. ROM:00332EB4 MVN R0, #0
227. ROM:00332EB8
228. ROM:00332EB8 locret_332EB8 ; CODE XREF: sub_332E98+18j
229. ROM:00332EB8 BX LR
230. ROM:00332EB8 ; End of function sub_332E98
231. ROM:00332EB8
232. ROM:00332EB8 ; ---------------------------------------------------------------------------
...Строка 141. С помощью STMFD, мы сохраняем значения регистров R4-R6 и LR на стек — сохраняем stack frame.
Строки 142–143. Копируем первый аргумент (адрес третьего вводимого символа) в регистры R4 и R6. Причина такого поведения будет ясна по ходу статьи.
Строка 146. Идем по адресу в R4, и забираем наш третий символ в R0.
Строка 147. Инструкция
CMP R0, #0xD
сравнивает его с 0×0D. 0×0D это символ новой строки. Результат сравнения (успешный, или не успешный) записывается в один из битов регистра CSPR (уже не помню какой).
Стоит оговориться, что символ новой строки на разных системах выглядит по разному, но пока что я встречал только три (и чертовски благодарен, что только три):
0×0D (Carriage Return) — Возврат Каретки (я, блин, не шучу)
0×0A (Line Feed) — Новая Строка
0×0A 0×0D (CR LF) — все вместе
В общем, тот кто клонировал git репу себе на виндовую машину, а потом скопировал папку на что-то nix*, поймет эту боль.
Строка 148. Инструкция
BEQ loc_332E68 (Branch If Equal)
является условным прыжком. Мы прыгнем только тогда, когда результат предыдущего сравнения будет успешным (Branch If Equal). Условие проверяется с помощью бита в регистре CSPR
В нашем случае, давайте допустим, что мы ввели 16 символов после R1:
R1AAAAAAAAAAAAAAAA
Если это так, прыжок на loc_332E68 не случится — третий вводимый символ не является новой строкой.
Строка 149. Здесь мы видим безусловный прыжок на sub_332E70. Этот прыжок сохраняет следующий адрес после PC в LR:
BL sub_332E70
Строка 191. Здесь, опять таки, проводиться сравнение с символом новой строки, и если это так, на строке 192, мы прыгаем на loc_332E90. Судя по тому, что мы ввели, символа новой строки у нас нету. Поэтому, прыжок не произойдет.
Строка 193. Проводиться сравнение нашего символа с 0×30 — это ASCII »0». Сейчас мы проверяем символ «А» — это 0×41. Сравнение не было успешным.
Строка 194. Инструкция BLT (Branch If Less Than) прыгнет на loc_332E90 только тогда, когда мы ввели значение меньше, чем 0×30 в предыдущем сравнении. В нашем случае, это не так. Прыжок не случится.
Строка 195. Проводиться сравнение с 0×39 — это ASCII »9». Опять таки, сравнение не будет успешным, но инструкция BGT (Branch If Greater Than) на строке 196 отработает, и здесь, мы все-таки прыгаем на loc_332E90.
Строка 203. Здесь мы видим инструкцию:
MVN R0, #0
MVN (Move Negative) сделает логическое «не» с нулем, и запишет минус один в R0. Дело в том, что любое значение у нас размером не в 1 бит (даже наш ноль). Оно, скорее всего, 32х битное. И, если перевернуть каждый бит в 32х битном нуле, получим 32 бита из единиц. По правилам two’s complement (вспоминаем, или гуглим, что это), такое значение будет равняться минус одному.
Строка 206. Прыжок со сменой режима на адрес в LR. Последний раз, LR был «залинкован» на строке 149 — возвращаемся туда (то есть, на строку 150). Здесь стоит упомянуть, что смена режима — это довольно хитрая операция. Если адрес, куда мы прыгаем непарный, мы сменим режим на Thumb, а если он парный, переключимся в ARM (это касается только тех инструкций, которые содержат Exchange (X) параметр). Короче, хоть мы и видим BX, смена режима не произойдет, и мы останемся в ARM.
Строка 150. Инструкция
CMN R0, #1 (Compare Negative)
очень интересная. Внутренняя логика инструкций CMP и CMN реализована через отнимание, или добавление операндов. CMP работаем через отнимание. Процессор понимает, что сравниваемые числа равны, когда результат отнятия одного от другого будет 0. CMN реализован через добавление — то есть, для сравнения чисел нужно добавить один операнд к другому. Если получим 0 — принимаем такой результат как успешное сравнение.
Здесь, мы добавляем 1 к -1. Получим ноль. Сравнение будет успешным.
Конечно, все эти манипуляции с негативными числами не комфортно воспринимать, но поскольку компилятор решил зарулить инструкции так — значит, машине «комфортнее» работать с таким кодом. Здесь, как и в жизни, ничего не бывает «просто так»!
Строка 151. У нас BNE. Поскольку предыдущее сравнение было успешным, прыжок на loc_332E2C не состоится.
Строка 152. Здесь, как и на строке 146, мы подгружаем 3й символ из нашего ввода в R0. Мы делаем это снова потому что дальше, будут случаи когда это необходимо.
Строка 153. Безусловный прыжок с «линковкой» в LR на sub_332E98
Строка 215. Здесь мы делаем ± то же самое, что и с цифрами на sub_332E70. Инструкция
CMP R0, #0x41
сравнит наш ввод с 0×41. 0×41 это ASCII «A». Наш 3й символ будет совпадать. Сравнение будет успешным!
Строка 216. Данный прыжок BLT не состоится, поскольку предыдущее сравнение было успешным.
Строка 217. Сравнение с 0×46 не увенчается успехом, и на строке 218 прыжок не состоится.
Строка 219–220. Здесь максимальное внимание! В итоге, на строке 215, мы наткнулись на успешное сравнение вводимых данных. Примерно здесь начинает отрабатывать логика функции ahex2byte. Инструкции
SUB R0, R0, #0x41
ADD R0, R0, #0xA
превратят наш вводимый hex символ в бинарный- в этом и смысл этой функции. Парочка примеров:
"A"
0x41 - 0x41 = 0x00
0x00 + 0x0A = 0x0A
"E"
0x45 - 0x41 = 0x04
0x04 + 0x0A = 0x0EРезультат этой операции сохранится в R0.
Если глянуть на строку 197, там мы отнимаем 0×30 — это в том случае, когда мы ввели ASCII цифру. Если глянете на ASCII таблицу, цифры от »0» до »9» имеют значения от 0×30 до 0×39. То есть, там происходит то же самое, что и с нашей буквой «А» здесь. Но, математика разная.
Строка 221. Здесь мы прыгнем на locret_332EB8, а потом прыгнем на содержимое в LR. Последний раз мы его «линковали» на строке 153. Что же, возвращаемся на строку 154.
Строка 154. Опять таки, сравниваем результат в R0 с минус единицей. Поскольку, сравнение с символом «A» было успешным, текущее сравнение успешным не будет. По сути, подобное сравнение является проверкой на ошибку в подпроцедуре. Подпроцедура вернет минус один как раз в случае ошибки.
Строка 155. Прыжок на locret_332E6C. Поскольку предыдущее сравнение не было успешным, он не состоится. Этот прыжок будет успешным только тогда, когда все сравнения чисел будут некорректными — к примеру, если после нашего «R1» мы введем символ «Q» (он вне диапазона всех наших сравнений). Данный прыжок указывает на инструкцию,
LDMFD SP!, {R4-R6, PC}
которая вернет предыдущий stack frame, и восстановит PC — это выход из функции ahex2byte.
Строка 158. В итоге, после конвертации ASCII числа в бинарное, мы записываем результат из R0 в регистр R5. На строке 21 мы копировали значение из R0 в R5. R0 является первым аргументом функции generate_key — key_part_num. И, честно говоря, в этот момент, я уже было подумал, что понял как взломать этот уровень. Судя по логике этой функции, первый аргумент отвечает за номер ключа, который мы генерируем. В Function Prologue мы поместили key_part_num именно в R5. Я думал, что могу подстроить ввод данных таким образом, что запихну в R5 желаемое значение, и программа сама зарулит исполнение по ключам. В этом участвует логика на строках 44–64. Но, скажу сразу — здесь я ошибся.
Строка 159. Помним, что R4 указывает на 3й символ нашего ввода. Здесь мы смещаем этот адрес на единицу вперед, и забираем байт из памяти в R0 — то есть, берем уже 4й символ.
Строка 160. Прыжок на sub_332E70. Сюда мы уже прыгали, когда проверяли 3й символ. Там происходит процесс сравнения с ASCII цифрой, и ее конвертация в бинарную.
Строка 161. Сравнение с минус единицей. Как я и говорил, проверяем результат сравнения символа с цифрой на ошибку.
Строка 162. Если ошибка есть, мы не прыгнем на loc_332E50. Помним, что 4й символ нашего ввода — это ASCII «A». В нашем случае, ошибка будет.
Строка 163–164. Мы снова вгружаем тот же вводимый 4й символ в R0, и прыгаем на sub_332E98 для проверки ASCII буквы
Строка 165. Опять таки, проверка на ошибку. В нашем случае, ошибки не будет, и ASCII буква сконвертируеться в бинарную.
Строка 166. Прыжок на locret_332E6C не отработает, поскольку у нас не было ошибки
Строка 169. Здесь начинается самое интересное. Инструкция
MOV R5, R5,LSL#4
скопирует содержимое R5 само на себя, но перед этим совершит бинарный сдвиг влево на 4 позиции (Logical Shift Left). Как это выглядит на примере 32-битного значения цифры «A»:
Before:
0000 0000 0000 0000 0000 0000 0000 1010 = 0x0A
After:
0000 0000 0000 0000 0000 0000 1010 0000 = 0xA0Строка 170. Инструкция
ADD R0, R5, R0
добавит к R0 сдвинутое значение цифры в R5 и сохранит в R0
Получается, что после проверки и обработки 4 го символа, на примере нашего ввода получится вот такое значение в R0:
0000 0000 0000 0000 0000 0000 1010 1010 = 0xAAСтрока 171. Инструкция
STRB R0, [R6]
возьмет значение из R0, и запишет 1 байт в адрес, куда указывает R6. Последний раз мы трогали R6 когда я только начал описывать всю функцию ahex2byte (во втором абзаце после спойлера). В нем содержится адрес 3 го символа нашего ввода.
Мог бы понять суть по названию функции
Поняли, что здесь происходит? Мы обрабатываем и перезаписываем то, что ввели в консольник диска из hex значений в бинарные с шагом в 2 символа (при этом, первые 2 символа нашего ввода «R1AAA…» игнорируются). Здесь очень важный момент! Получается, что на 2 символа hex ввода (2 байта), мы в итоге получаем 1 бинарный байт. Пример:
ASCII "CE" (0x43 0x45) --> 0xCE
ASCII "F1" (0x4
