Локализация приложения и поддержка RTL. Доклад Яндекс.Такси
При локализации сервиса важно внимательно отнестись к согласованию переводов между собой. Руководитель группы клиентской Android-разработки Яндекс.Такси Александр Бонель рассказал, какие практики и инструменты упрощают локализацию. Во второй части доклада Саша поделился опытом поддержки языка RTL в приложении: что хорошо, а что не совсем работает у Андроида из коробки, какие проблемы возникают из-за поддержки RTL и как их минимизировать в будущем.
— В своем докладе я хочу рассказать, какие основные идеи и практики мы используем в командах разработки мобильных приложений Такси для решения вопросов, связанных с локализацией и актуализацией перевода в наших приложениях. Затем расскажу, как мы внедряли в приложение поддержку работы в режиме отрисовки справа налево.

Начну с локализации. В первую очередь хотелось бы внести ясность в терминологию. По моим наблюдениям, большое количество людей считают, что локализация ограничена всего-навсего переводами, хотя на самом деле она также решает проблемы, связанные с форматированием чисел, дат, времени, работу с текстом и символами, правовые аспекты, подачу контента потребителю таким образом, что он имел для него смысловую ценность и не был воспринят неоднозначно. И многое другое. (Общение с залом о том, у кого сколько языков поддерживается в приложениях — прим. ред.)
Хочу рассказать вам историю, которая произошла у нас в 2014 году. Мы тогда сделали крупный редизайн приложения Такси. В одном из очередных релизов мы предоставили пользователям возможность указывать номер подъезда, а также смотреть на эту информацию на экране информации о поездке и, что самое главное, на экране оценки заказа, которую мы показывали всем пользователям, потому что мы обязательно хотели получить оценку за поездку.
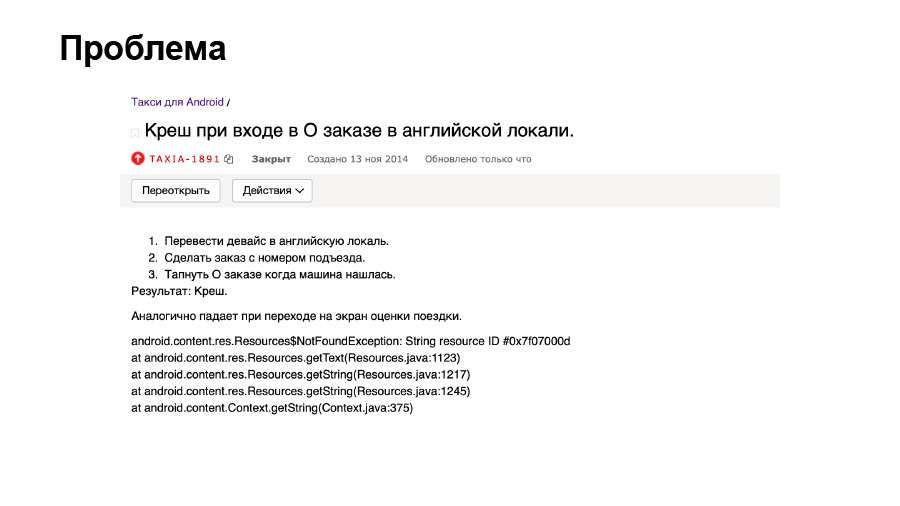
Мы тогда достаточно фривольно относились к процессу локализации и к переводам. По большей части, весь процесс был ручной. Обновление текстов в нужных XML-файлах, добавление новых переводов проводилось вручную. И сыграл свою роль человеческий фактор. Разработчик определил не в дефолтной локале очередной перевод. Это приводило к тому, что у пользователей с отличной от русского языка системной локалью, если они задавали подъезд, приложение по окончанию поездки крэшилось. И люди не могли сделать еще один заказ.
На тот момент у нас в приложении поддерживалось два языка: русский и английский. И мы работали только в России в трех городах: Москве, Екатеринбурге, Санкт-Петербурге.

Сейчас мы работаем в 16 странах и переведены на 18 языков. Я думаю, вы понимаете всю сугубость проблемы, если мы в таком состоянии находились на тот момент. Мы уже тогда поняли, что нужно что-то менять.

В Яндексе бо́льшая часть разработчиков мобильных приложений для решения проблем, связанных с локализацией, пользуется разработанным внутри сервисом. У него очень удобный UI-интерфейс, есть возможность определить свой проект, задать набор ключей, набор языков, на которые необходимо переводить проект. И после того, как переводы появляются, их можно выгрузить в любом удобном формате. У него также очень хорошая интеграция с нашими внутренними сервисами. Есть версионированность. Но лично для меня как для разработчика самое главное то, что у него есть API, потому что это уже наводит на мысль о том, что вся ручная работа, связанная с переводами, может быть автоматизирована. Что мы и сделали. Мы разработали плагин для Gradle. По сути, актуализация перевода в приложении теперь сводится к тому, что разработчик выполняет один-единственный task: updateTranslations.

В первом приближении он ходит в сервис локализации. Проверяет наличие актуальных переводов, закачивает их в проект, раскладывает по нужным файлам. Но помимо этого он также проводит верификацию состояния переводов в сервисе локализации по отношению к тому, что сейчас есть в проекте.

При очередном выполнении git status разработчик видит у себя в рабочей директории, какие файлы поменялись.
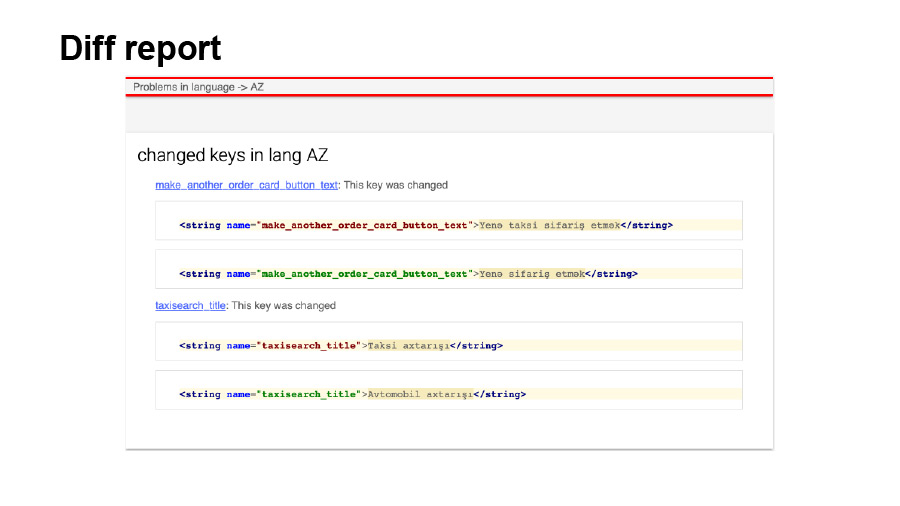
Также он может посмотреть в сгенерированном HTML-отчете о том, какой ключ на какое значение в каком языке поменялся.

И также он может посмотреть, какие проблемы на данный момент присутствуют в переводах его проекта.

Плагин конфигурируемый. Мы можем определить количество языков, которые наше приложение поддерживает. Очень актуально, если локализаторы заводят новый язык, и он нечаянно просачивается в проект, будучи не пройденным через корректуру и вычитку.

Также есть специфическая возможность ремаппинга. Я расскажу о ней чуть позже более подробно, когда буду рассказывать про RTL.
Какие проблемы этот плагин сейчас анализирует? Та проблема, с которой мы столкнулись в 2014 году — банальная, отсутствие перевода. Теперь для того, чтобы добавить новую строчку, новый перевод в проект, разработчику недостаточно просто определить его в XML-файле.

Во-первых, если он сделает это не в дефолтной локале, то его вновь заведенный ключ просто пропадет при очередной синхронизации, и он узнает об этом на этапе компиляции.

Если же он определит ключ в дефолтном файле, но забудет это сделать в сервисе локализации, то при очередном выполнении таска updatetranslations он получит ошибку от плагина, которая скажет ему: «Этот ключ есть в вашем проекте, но он отсутствует в сервисе локализации, его там нужно завести».

Вторая типичная проблема — это отсутствие перевода. Мы получаем список ссылок на те ключи, для которых нет перевода, и, как правило, относим их нашему менеджеру для того, чтобы они настроили впоследствии коммуникацию с переводчиками. Третий момент часто встречается, когда решили пересмотреть использование формат-аргументов в каком-то ключе, и, например, вместо целочисленного формата стали использовать строковый формат.
Но при этом в каком-то из переводов забыли поменять чиселку на строку.

И четвертая проблема также обусловлена человеческим фактором, в основном при переводе. Если в переводе используются Unicode-символы, очень легко запутаться в позиционировании символов и вместо неразрывного пробела получить перенос на другую строку — то, от чего мы пытаемся избавиться.
Это всё про локализацию.
Теперь я хочу рассказать про опыт внедрения поддержки отрисовки справа налево в приложении на примере Израиля. Мы запустились в 2018 году под брендом Yango в Израиле. Как оказалось, в Израиле люди читают не так, как мы с вами. Они читают справа налево.

С чего хочется начать? Что в Android в принципе поддержка отрисовки справа налево реализована из коробки достаточно хорошо.
Начинается она с того, что в манифесте приложения, в элементе Application вам необходимо объявить атрибут supportRtl=«true». Но хочу вас обрадовать: если вы у себя в приложениях интегрируете Facebook SDK для социальной авторизации, заботливые разработчики Facebook это уже сделали за вас. И если вы не валидируете манифест при мерджинге, у вас этот атрибут со значением true встанет в ваше приложение, и оно уже будет уметь в Rtl. Это то, о чем можно задуматься.
Думаю, что большинство из сидящих в аудитории наверняка минимально поддерживают версию Android 4.4. Кому-то больше повезло — это 5.0 и выше. Кому-то могло меньше повезти, и они поддерживают 4.0, или, упаси, господи, 2.3. В этом случае у вас будут большие проблемы, потому что полноценная поддержка Rtl в Android появилась начиная с версии 4.2. Поэтому с minSdk 17-м вы на порядок упростите себе жизнь.
Перевод проекта на работу с Rtl начинается с refactoring tool в Android Studio — Add RTL Support Where Possible. Надо отдать должное, работает достаточно хорошо. Он проходит по XML-файлам ваших разметок, смотрит на наличие атрибутов со значениями left и right у gravity, у paddings, margins, и заменяет их на start и end. Если вы хотите посмотреть, как ваше приложение по умолчанию работает при отрисовке в режиме справа налево, вам необязательно иметь на руках контент с так называемыми RTL strong символами — на иврите или на арабском языке. Вам достаточно в настройках разработчика включить опцию Force RTL Layout Direction.
Какие возможности для кастомизации UI и рендеринга текста Android предоставляет для RTL?

Первый момент — это атрибут layoutDirection, который использует описанная опция Force RTL Layout Direction. У нее всего четыре возможных значения. То есть она по умолчанию наследуется от родителя. Можно сказать о том, чтобы layout отрисовывался, исходя из выбранной локале. Можно сказать четко, чтобы он отрисовывался справа налево или слева направо.
Второй элемент, которые многие наверняка по привычке обходят стороной, когда занимаются выравниванием текста — это textAlignment. Многие до сих пор продолжают использовать gravity. Для выравнивания текста не используйте gravity, а используйте textAlignment.
Третий атрибут — это направление рендеринга текста, textDirection. У него достаточно гибкая настройка. Она позволяет определить, как текст рендерится в зависимости от того, какой первый strong символ попался в тексте, будь то из латинского набора символов strong LTR или из иврита strong RTL. Но если вы поддерживаете полноценно RTL в приложении, его не нужно обходить стороной, потому что при игнорировании происходит такой забавный артефакт.

То ли это пасхалочка, то ли это такой side effect в реализации editText: у вас начинает hint у editText разъезжаться. Поэтому какое-никакое значение вы ему в любом случае должны задать.

Ссылка со слайда
Если вам нужно соблюсти определенную отрисовку каких-то графических ресурсов или разметки в режиме RTL, то Android предоставляет возможность задать qualifier ldrtl в вашей папочке, в которую вы можете положить любой ресурс, и он в режиме отрисовки RTL будет отрисован так, как вы задали.
Иногда бывает потребность в runtime приходящий с бэкэнда текст отрисовывать как есть, как он пришел, игнорируя то, в каком режиме сейчас работает ваше приложение. По сути, в text renderer это осуществляется за счет того, что текст обрамляется так называемыми Bidi Unicode control символами. Логику для работы с этими символами в себе содержит класс BidiFormatter, предоставляя только один-единственный метод unicodeWrap. Он принимает СharSequence на вход, и возвращает вам строку, обрамленную этими символами. Там их исчерпывающее количество, и, в принципе, он должен решать бо́льшую часть ваших проблем.
Но если есть что-то такое специфическое, у w3.org есть хорошая статья на тему того, как этими символами пользоваться.
Какие проблемы мы приобрели, когда начинали поддержку RTL в нашем приложении? В первую очередь это конфликт стандартов локализации.
BCP47 — это более новый стандарт локализации, который в частности поменял коды некоторых локалей. И дело в том, что есть проблема с классом locale Java. Он по умолчанию работает в режиме обратной совместимости, и приходящие ему locale коды из BCP конвертирует в ISO. То есть мы это увидели, когда на наш бэкэнд в заголовке Accept-Language вместо кода he стал уходить код iw.

Ссылка со слайда
Если вы помните слайд с конфигурацией нашего плагина, remapping был нужен как раз таки для этого — для того, чтобы переводить контент из he в iw.
Если вам необходимо использовать BCP формат, это в полной мере реализовано в проекте Apache Cordova. У них есть класс Globalization и реализация localeToBcp47Language.

Еще один момент, который «доставляет» при поддержке RTL в приложении — это анимации. Здесь, благо, по сути, аффектятся только анимации по оси X, и, пожалуй, единственное решение или подход, который вам поможет избежать большего количества проблем — это возможность пересмотреть анимации абсолютные в стороны анимаций относительных.
Одна проблема, которая решается, пожалуй, только reflection, потому что она жестко реализована так в самом компоненте — это выравнивание hint у TextInputLayout. Дело в том, что если hint задан в RTL strong символах на иврите, он будет четко выровнен по правому краю, даже несмотря на то, что контент, который вы вводите в edit text, может быть из латинских символов. И наоборот. Если hint у вас на латинице, он будет четко выровнен по левому краю. Это решить можно только с помощью reflection.

В конечном итоге, после того, как вы внедрили RTL у вас в приложении, имеет смысл пересмотреть, severities для RTL-issues, которые анализирует Lint. Их всего четыре. Если вы не поддерживаете RTL в вашем приложении, но явно где-то используете RTL specific атрибуты, то это RtlEnabled (Lint вам об этом скажет).

Ссылка со слайда
Если вы поддерживаете RTL в приложении, но minSdkVersion вашего приложения ниже 17, то вы обязаны также продолжать использовать атрибуты типа left и right, вы не можете использовать только атрибуты start и end в вашей разметке. Это то, что анализирует RtlCompat. RtlSymmetry ругается, когда видит асимметричные paddings. Вообще, мое мнение такое, что aapt при процессинге ресурсов должен крэшиться, если он натыкается на симметричные paddings. Если вам нужны какие-то асимметричные доступы, пользуйтесь margins как полноценным layout параметром.
Наконец, четвертая проблема — захардкоженый RTL. Это как раз то, что в атрибутах указаны только значения left и right. По сути, это сводит на нет refactoring tool Add RTL Support Where Possible. Это всё грепается из Lint по вхождению RTL. Также реализация анализа доступна в AOSP в классе RtlDetector. То есть если вам фантазия позволяет, вы можете придумать что-то свое, подсмотрев то, как анализ проходит сейчас.
Мой доклад подходит к концу. Я хочу привести несколько тезисов на тему выстраивания правильной локализации у нас в приложении, к которым мы со временем пришли.

В первую очередь, на старте проекта задумайтесь об интернационализации. Я о ней толком не обмолвился. Это совсем не то же самое, что локализация. По сути, интернационализация делает возможной локализацию в приложении, в продукте. Это у Java из коробки работает за счет того, что есть полноценная поддержка Unicode, а у Android — за счет богатой системы ресурсов. Пожалуй, единственное, что здесь может случиться — наша фиксация как разработчиков на тему того, что «Я приложение пишу только для русского, значит, я буду проверять его только с русским языком». А когда вы начинаете использовать в приложении армянский, грузинский, иврит или арабский язык, картина выглядит совсем иначе и ломается об вашу привычную парадигму.
Второй момент. Подумайте над встраиванием локализации в ваш CI. Очень обидно узнать о проблемах, связанных с переводами, на этапе тестирования релиз-кандидата, к которому вы могли готовиться несколько недель. То есть у нас сейчас на каждый пул-реквест прогоняется этот таск, чтобы мы заранее были уверены в том, что с переводами все хорошо и мы можем замерджить новый код в основную ветку проекта.
Третий момент. Уважайте труд переводчиков и свой бюджет. Во-первых, удаляйте неиспользуемые ресурсы, потому что люди могут продолжать тратить время и деньги на то, чтобы переводить строки, которые, в конечном итоге, вы у себя в проекте не используете. Во-вторых, следите за переводами, которые есть в вашем хранилище в сервисе локализации, но которых нет в вашем коде.
В идеале, если API вашего сервиса локализации предоставляет информацию о том, когда тот или иной ключ был заведен, и вы можете использовать эвристики вроде «Если ключ заведен больше месяца назад», проверьте его присутствие в последней ревизии мастер-бранчи. Если его там нет, скорее всего, это явный кандидат на то, чтобы его удалить и чтобы локализаторы не тратили на него время.
Более-менее универсальный кандидат на серебряную пулю — хранить строки на бэкэнде, а не на клиенте. По крайней мере, это даст вам возможность их всегда держать актуальными на стороне приложения.
У нас очень разнообразная аудитория пользователей, каждый воспринимает окружающий мир и контент приложения по-своему. Наша задача как разработчиков — помочь соблюсти это восприятие. Мой доклад на этом окончен. Спасибо большое!
