Логистическая регрессия в пакете машинного обучения «XGboost»

В этой статье речь пойдет о логистической регрессии и ее реализации в одном из наиболее производительных пакетов машинного обучения «R» — «XGboost» (Extreme Gradient Boosting).
В реальной жизни мы довольно часто сталкиваемся с классом задач, где объектом предсказания является номинативная переменная с двумя градациями, когда нам необходимо предсказать результат некого события или принять решения в бинарном выражении на основании модели данных. Например, если мы оцениваем ситуацию на рынке и нашей целью является принятие однозначного решения, имеет ли смысл инвестировать в определенный инструмент в данный момент времени, купит ли покупатель исследуемый продукт или нет, расплатится ли заемщик по кредиту или уволится ли сотрудник из компании в ближайшее время и.т.д.
В общем случае логистическая регрессия применяется для предсказания вероятности возникновения некоторого события по значениям множества признаков. Для этого вводится так называемая зависимая переменная (исход события), принимающая лишь одно из двух значений (0 или 1), и множество независимых переменных (также называемых признаками, предикторами или регрессорами).
Сразу оговорюсь, что в «R» существует несколько линейных функций для обучения логит-модели, таких как «glm» из стандартного пакета функций, но здесь мы рассмотрим более продвинутый вариант, имплементированный в пакете «XGboost». Эта модель, многократный победитель соревнований Kaggle, основана на построении бинарных деревьев решений способна поддерживать многопоточную обработку данных. Об особенностях реализации семейства моделей «Gradient Boosting» можно прочитать здесь:
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3885826/
https://en.wikipedia.org/wiki/Gradient_boosting
Возьмем тестовый набор данных (Train) и построим модель для предсказания выживаемости пассажиров при катастрофе:
data(agaricus.train, package='xgboost')
data(agaricus.test, package='xgboost')
train <- agaricus.train
test <- agaricus.test Если после преобразования матрица содержит много нулей, то такой массив данных нужно предварительно преобразовать в sparse matrix — в таком виде данные займут намного меньше места, а соответственно и время обработки данных намного сократится. Здесь нам поможет библиотека «Matrix» на сегодняшний день последняя доступная версия 1.2–6 содержит в себе набор функция для преобразования в dgCMatrix на колоночной основе.
В случае, когда уже уплотненная матрица (sparse matrix) после всех преобразований не помещается в оперативной памяти, то в таких случаях используют специальную программу «Vowpal Wabbit». Это внешняя программа, которая может обработать датасеты любых размеров, читая из многих файлов или баз данных. «Vowpal Wabbit» представляет собой оптимизированную платформу для параллельного машинного обучения, разработанную для распределенных вычислений компанией «Yahoo!» Про нее довольно подробно можно прочесть по этим ссылкам:
https://habrahabr.ru/company/mlclass/blog/248779/
https://en.wikipedia.org/wiki/Vowpal_Wabbit
Использование разреженных матриц дает нам возможность строить модель с использованием текстовых переменных с предварительным их преобразованием.
Итак, для построения матрицы предикторов сначала загружаем необходимые библиотеки:
library(xgboost)
library(Matrix)
library(DiagrammeR) При конвертации в матрицу все категориальные переменные будут транспониваны, соответственно функция со стандартным бустером включит их значения в модель. Первое что нужно сделать, это удалить из набора данных переменные с уникальными значениями, такими как «Passenger ID», «Name» и «Ticket Number». Такие же действия проводим и с тестовым набором данных, по которым будут рассчитывается прогнозные исходы. Для наглядности я загрузил данные из локальных файлов, которые скачал в соответствующем датасете Kaggle. Для модели, ним понадобятся следующие колонки таблицы:
input.train <- train[, c(3,5,6,7,8,10,11,12)]
input.test <- test[, c(2,4,5,6,7,9,10,11)] 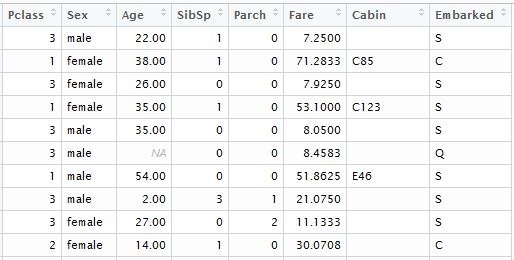
отдельно формируем вектор известных исходов для обучения модели
train.lable <- train$Survived Теперь необходимо выполнить преобразование данных, дабы при обучении модели в учет были приняты статистически значимые переменные. Выполним следующие преобразования:
Заменим переменные содержащие категориальные данные на числовые значения. При этом нужно учитывать что упорядоченные категории, такие как 'good', 'normal', 'bad' можно заменить на 0,1,2. Не упорядоченные данные с относительно небольшой селективностью, такие как «gender» или «Country Name» можно оставить факторными без изменения, после преобразование в матрицу они транспонируются в соответствующее количество столбцов с нулями и единицами. Для числовых переменных, необходимо обработать все неприсвоенные и пропущенные значения. Здесь есть как минимум три варианта: их можно подменить на 1, 0 либо более приемлемый вариант будет замена на среднее значение по колонке этой переменной.
При использовании пакета «XGboost» со стандартным бустером (gbtree), масштабирование переменных можно не выполнять, в отличии от других линейных методов, таких как «glm» или «xgboost» c линейным бустером (gblinear).
Основную информацию о пакете можно найти по следующим ссылкам:
https://github.com/dmlc/xgboost
https://cran.r-project.org/web/packages/xgboost/xgboost.pdf
Возвращаясь к нашему коду, в результате мы получили таблицу следующего формата:

далее, заменяем все пропущенные записи на среднее арифметическое значение по столбцу предиктора
if (class(inp.column) %in% c('numeric', 'integer')) {
inp.table[is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE) после предварительной обработки делаем преобразование в «dgCMatrix»:
sparse.model.matrix(~., inp.table) Имеет смысл создать отдельную функцию для предварительной обработки предикторов и преобразования в sparse.model.matrix формат, например вариант с «for» циклом приведен ниже. C целью оптимизации производительности можно векторизовать выражение используя функцию «apply».
spr.matrix.conversion <- function(inp.table) {
for (i in 1:ncol(inp.table)) {
inp.column <- inp.table [ ,i]
if (class(inp.column) == 'character') {
inp.table [is.na(inp.column), i] <- 'NA'
inp.table [, i] <- as.factor(inp.table [, i])
}
else
if (class(inp.column) %in% c('numeric', 'integer')) {
inp.table [is.na(inp.column), i] <- mean(inp.column, na.rm=TRUE)
}
}
return(sparse.model.matrix(~.,inp.table))
} Тогда воспользуемся нашей функцией и преобразуем фактическую и тестовую таблицы в разреженные матрицы:
sparse.train <- preprocess(train)
sparse.test <- preprocess(test) 
Для построения модели нам потребуется два набора данных: матрица данных, которую мы только что создали и вектор фактических исходов с бинарным значением (0,1).
Функция «xgboost» является наиболее удобной в использовании. В «XGBoost» имплементирован стандартный бустер основан на бинарных деревьях решений.
Для использования «XGboost», мы должны выбрать один из трех параметров: общие параметры, параметры бустера и параметров назначения:
• Общие параметры — определяем, какой бустер будет использован, линейный или стандартный.
Остальные параметры бустера зависят от того, какой бустер мы выбрали на первом шаге:
• Параметры задач обучения — определяем назначение и сценарий обучения
• Параметры командной строки — используются для определения режима командной строки при использовании «xgboost.».
Общий вид функции «xgboost» который мы используем:
xgboost(data = NULL, label = NULL, missing = NULL, params = list(), nrounds, verbose = 1, print.every.n = 1L, early.stop.round = NULL, maximize = NULL, ...) «data» — данные матричном формате («matrix», «dgCMatrix», local data file or «xgb.DMatrix».)
«label» — вектор зависимой переменной. Если данное поле было составляющей исходной таблицы параметров, то перед обработкой и преобразованием в матрицу, его следует исключить, дабы избежать транзитивности связей.
«nrounds» –количество построенных деревьев решений в финальной модели.
«objective» — через данный параметр мы передаем задачи и назначения обучения модели. Для логистической регрессии существуют 2 варианта:
«reg: logistic» — логистическая регрессия с непрерывной величиной оценки от 0 до 1;
«binary: logistic» — логистическая регрессия с бинарной величиной предсказания. Для этого параметра можно задать специфическую пороговую величину перехода от 0 к 1. По умолчанию это значение 0.5.
Детально про параметризацию модели можно прочесть по этой ссылке
http://xgboost/parameter.md%20at%20master%20·%20dmlc/xgboost%20·%20GitHub
Теперь приступаем к созданию и обучению модели «XGBoost»:
set.seed(1)
xgb.model <- xgboost(data=sparse.train, label=train$Survived, nrounds=100, objective='reg:logistic') при желании можно извлечь структуру деревьев с помощью функции xgb.model.dt.tree (model = xgb). Далее, используем стандартную функцию «predict» для формирования прогнозного вектора:
prediction <- predict(xgb.model, sparse.test) и наконец, сохраним данные в приемлемом для чтения формате
solution <- data.frame(prediction = round(prediction, digits = 0), test)
write.csv(solution, 'solution.csv', row.names=FALSE, quote=FALSE) добавляя вектор предсказанных исходов, получаем таблицу следующего вида:

Теперь немного вернемся и вкратце рассмотрим саму модель, которую мы только что создали. Для отображения деревьев решения, можно воспользоваться функциями «xgb.model.dt.tree» и «xgb.plot.tree». Так, последняя функция выдаст нам список выбранных деревьев с коэффициентом подгонки модели:

Используя функцию xgb.plot.tree мы также увидим графическое представление деревьев, хотя нужно отметить что в текущей версии, оно далеко не лучшим способом имплементировано в данной функции и является мало полезным. По этому, для наглядности, мне пришлось воспроизвести вручную элементарное дерево решений на базе стандартной модели данных Train.
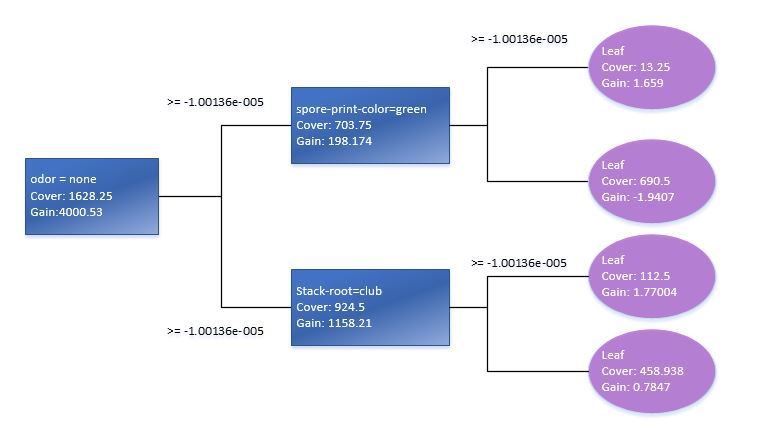
Проверка статистической значимости переменных в модели подскажет нам как оптимизировать матрицу предикторов для обучения XGB-модели. Лучше всего использовать функцию xgb.plot.importance в которую мы передадим агрегированную таблицу важности параметров.
importance_frame <- xgb.importance(sparse.train@Dimnames[[2]], model = xgb)
xgb.plot.importance(importance_frame) 
Итак, мы рассмотрели одну из возможных реализаций логистической регрессии на базе пакета функции «xgboost» со стандартным бустером. На данный момент я рекомендую использовать пакет «XGboost» как наиболее продвинутую группу моделей машинного обучения. В настоящие время предиктивные модели на базе логики «XGboost» широко используются в финансовом и рыночном прогнозировании, маркетинге и многих других областях прикладной аналитики и машинного интеллекта.
