Логика сознания. Часть 7. Самоорганизация пространства контекстов
Ранее мы говорили о том, что любая информация имеет как внешнюю форму так и внутренний смысл. Внешняя форма — это то, что именно мы, например, увидели или услышали. Смысл — это то, какую интерпретацию этому мы дали. И внешняя форма, и смысл могут быть описаниями, составленными из определенных понятий.
Было показано, что если описания удовлетворяют ряду условий, то давать им интерпретацию можно, просто заменяя понятия исходного описания на другие понятия, применяя определенные правила.
Правила трактовки зависят от тех сопутствующих обстоятельств в которых мы пытаемся дать интерпретацию информации. Эти обстоятельства принято называть контекстом в котором трактуется информация.
Кора мозга состоит из нейронных миниколонок. Мы предположили, что каждая миниколонка коры — это вычислительный модуль, который работает со своим информационным контекстом. То есть каждая зона коры содержит миллионы независимых вычислителей смысла в которых одна и та же информация получает свою собственную трактовку.
Был показан механизм кодирования и хранения информации, который позволяет каждой миниколонке коры иметь свою полную копию памяти о всех предыдущих событиях. Наличие собственной полной памяти позволяет каждой миниколонке проверить насколько ее интерпретация текущей информации согласуется со всем предыдущим опытом. Те контексты в которых трактовка оказывается «похожа» на что-то ранее знакомое составляют набор смыслов, содержащихся в информации.
За один такт своей работы каждая зона кора проверяет миллионы возможных гипотез относительно того как можно трактовать поступающую информацию и выбирает самые осмысленные из них.
Чтобы кора могла так работать необходимо предварительно сформировать на ней пространство контекстов. То есть, выделить все те «наборы обстоятельств», которые влияют на правила трактовки.
Наш мозг возник в результате эволюции. Его общая архитектура, принципы работы, система проекций, структура зон коры — все это создано естественным отбором и заложено в геном. Но далеко не все можно и имееет смысл передавать через геном. Некоторые знания должны приобретаться живыми организмами самостоятельно уже после их рождения. Идеальная адаптация к окружающей среде не в том, чтобы наследственно хранить правила на все случаи жизни, а в умении обучаться и самим находить оптимальные решения в любых новых обстоятельствах.
Контексты — это как раз те самые знания, что должны формироваться под воздействием внешнего мира и его законов. В этой части мы опишем как могут создаваться контексты и то, как уже внутри пространства контекстов может происходить последующая самоорганизация.
Для каждого типа информации работают свои «трюки», позволяющие сформировать пространство контекстов. Опишем два наиболее очевидных приема.
Создание контекстов при наличии примеров
Предположим, что есть учитель, который дал нам некие описания и показал, как их надо толковать. При этом он не просто дал правильную интерпретацию, но и объяснил как она получена, то есть какие понятия во что перешли при трактовке. Таким образом, для каждого примера нам стали известны правила трактовки. Чтобы из этих правил создать контексты их надо объединить в группы так, чтобы, с одной стороны, этих групп было как можно меньше, а с другой стороны, чтобы правила внутри одной группы не противоречили друг другу.
Например, у вас есть предложения и их переводы на другой язык. При этом есть сопоставления того какие слова как переводятся. Для разных предложений может оказаться, что одни и те же слова будут переводиться по-разному. Задача — найти такие смысловые области, они же контексты, в которых правила перевода будут устойчивы и однозначны.
Запишем это формально. Допустим, что у нас есть память M, состоящая из примеров вида «описание — трактовка — правила преобразования».
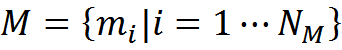

Описание и его трактовка связаны между собой правилами преобразований r. Правила говорят о том, как из исходного описания была получена его трактовка. В самом простом случае правила преобразования могут быть просто набором правил замены одних понятий на другие
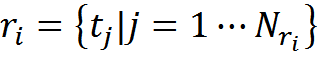
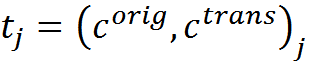
То есть правила преобразования — это набор трансформаций «исходное понятие — понятие-интерпретация». В более общем случае одно понятие может перейти в несколько или несколько понятий могут преобразоваться в одно, или одно описание из нескольких понятий может перейти в другое сложное описание.

Введем следующие функции согласованности для двух правил преобразований. Количество совпадающих трансформаций

Количество противоречий
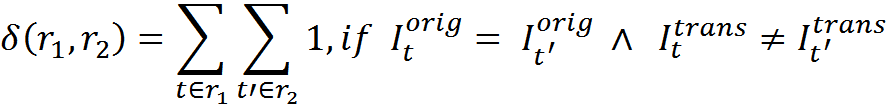
Количество противоречий показывает сколько присутствует трансформаций, в которых одна и та же исходная информация преобразуется правилами по-разному.
Теперь, решим задачу кластеризации. Разобьем все воспоминания на минимальное количество классов с тем условием, что все воспоминания одного класса не должны противоречить друг другу своими правилами преобразований. Полученные классы будут являться пространством контекстов {Conti|i=1⋯NCont}.
Для каждого класса-контекста будем считать правила преобразований R, как совокупность всех правил для элементов, входящих в этот класс
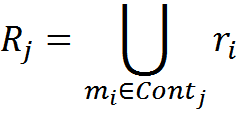
Для требуемой кластеризации можно использовать идею EM (expectation-maximization) алгоритма с добавлением. EM алгоритм подразумевает, что сначала мы разбиваем объекты на классы любым разумным способом, чаще всего случайным отнесением. Считаем для каждого класса его портрет, который может быть использован для расчета функции правдоподобия отнесения к этому классу. Затем заново перераспределяем все элементы по классам, исходя из того какой класс правдоподобнее соответствует каждому из элементов.
Если какой-либо элемент не получается правдоподобно отнести ни к одному из классов, то создаем новый класс. После отнесения к классам возвращаемся к предыдущему шагу, то есть опять пересчитываем портреты классов, в соответствии с тем, кто попал в этот класс. Повторяем процедуру до сходимости.
В реальных случаях, например в нашей жизни, информация не появляется одномоментно сразу вся. Она накапливается постепенно по мере приобретения опыта. При этом, новые знания сразу включаются в информационный оборот вместе со старыми. Можно предположить, что наш мозг использует двухэтапную обработку новой информации. На первом этапе новый опыт запоминается и может сразу быть использован. На втором этапе происходит соотнесение нового опыта со старым и более сложная совместная обработка этого обработка.
Можно предположить, что первый этап происходит во время бодорствования и не мешает остальным информационным процессам. Второй же этап, похоже требует «остановки» основной активности и перехода мозга в специальный режим. Похоже, что таким специальным режимом и является сон.
Исходя из этого, изменим немного классический EM алгоритм, приблизив его к возможной двухтактной схеме работы мозга. Будем начинать с пустого набора классов. Будем использовать фазу «бодрствования» для получения нового опыта. Будем менять портрет каждого из классов сразу после отнесения к нему нового элемента. Будем использовать фазу «сна» для переосмысления накопленного опыта.
Функцию правдоподобия отнесения элемента памяти с правилами преобразований r к классу контекста с номером j выберем
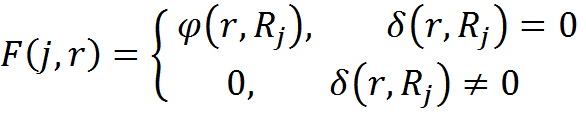
Алгоритм примет вид:
- Создадим пустой набор классов
- В фазе «бодрствования» будем последовательно подавать новую часть опыта.
- Будем сравнивать r составляющую элементов и портреты классов R. Для каждого элемента будем выбирать классы с δ (r, Rj)=0 и среди них класс с максимальным φ (r, Rj), что соответствует
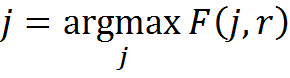
- Если классов без противоречий не окажется, то создадим для такого элемента новый класс и поместим его туда.
- При добавлении элемента к классу будем пересчитывать портрет класса R.
- По завершении фазы «бодрствования» перейдем к фазе «сна». Будем реконсолидировать накопленный опыт. Для опыта, полученного во время «бодрствования», и для части старого опыта (в идеале для всего старого опыта) произведем переотнесение к классам контекста с созданием, если это необходимо, новых классов. При изменении отнесения какого-либо опыта будем менять портреты обоих классов, того откуда элемент выбыл и того куда теперь отнесен.
- Будем повторять фазы «бодрствования» и «сна», подавая новый опыт и реконсолидируя старый.
Поиск правил преобразования для фиксированных контекстов
Описанный выше механизм создания контекстов подходит для обучения, когда учитель объясняет смысл фраз и при этом указывает трактовку для каждого из понятий. Другой вариант создания контекстов связан с ситуацией, когда для обучающих примеров известно контекстное преобразование и есть два информационных описания, соответствующие исходной информации и ее трактовке. Но при этом неизвестно какое именно из понятий во что перешло.
Именно такая ситуация возникает, например, во время обучения первичной зрительной коры. Быстрые скачкообразные движения глаз называются саккадами и микросаккадами. До и после скачка глаз видит одну и ту же картинку, но в разном контексте смещения. Если скачек определенной амплитуды и направления сопоставить с определенным контекстом, то вопрос будет в том по каким правилам меняется любое зрительное описание в этом контексте? Очевидно, что имея достаточный набор пар «исходная картинка — картинка после смещения», относящихся к одинаковым смещениям, можно построить универсальный набор правил трансформации.
Другой пример. Предположим вы хотите узнать перевод на другой язык какого-либо слова в определенном контексте. У вас есть набор предложений в некоторых из которых есть это слово. И есть переводы всех этих предложений. Пары «предложение — перевод» заранее разбиты на контексты. Это значит, что для всех переводов, относящихся к одному контексту, это слово переводится одинаково. Но вы не знаете какое именно слово в переводах соответствует тому, что вы ищите.
Задача с переводом решается очень просто. Вам надо в том контексте в котором ищется перевод отобрать те пары «предложение — перевод» в которых есть искомое слово и посмотреть, что общее есть во всех переводах. Это общее и будет искомым переводом слова.
Формально это можно записать так. У нас есть память M, состоящая из воспоминаний вида «описание — трактовка — контекст».
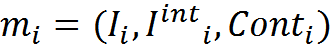
Описание и его трактовка связаны между собой правилами преобразований Rj, которые нам неизвестны. Зато нам известен номер контекста Conti в котором совершены эти преобразования.
Теперь, предположим, что в текущем описании нам встретился информационный фрагмент Iorig и у нас есть номер контекста j в котором мы хотим получить трактовку этого описания Itrans.
Выберем из памяти M подмножество элементов M» таких, что их контекстное преобразование совпадает с j и в исходном описании содержится фрагмент Iorig, преобразование для которого мы хотим найти
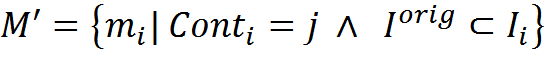
Во всех преобразованиях Iinti будет содержаться фрагмент искомого нами преобразования (если контекст допускает такое преобразование). Наша задача сводится к определению такого максимального по длине описания, которое присутствует во всех трактовках элементов множества M».
Интересно, что идеология нахождения такого описания совпадает с идеологией алгоритмов для квантовых вычислений, основанной на усилении требуемой амплитуды. В описаниях Iinti множества M» все остальные элементы, кроме искомых, встречаются случайным образом. Это означает, что можно организовать интерференцию описаний так, чтобы нужная информация усиливалась, а ненужная интерферировала случайно и гасила друг друга.
Чтобы проделать «фокус» с подскоком амплитуды требует чтобы данные были представлены соответствующим образом. Напомню, что мы используем для кодирования каждого понятия разряженный бинарный код. Описанию из нескольких понятий соответствует бинарный массив, получающийся при логическом сложении бинарных кодов входящих в описание понятий.
Оказывается, что если взять бинарные массивы, соответствующие трактовкам и выполнить с ними «интерференцию», связанную с усилением нужного нам кода, то в результате получится бинарный код требуемого нам преобразования.
Предположим, что M» содержит N элементов. Сопоставим каждому описанию Iint битовый массив b из m бит, полученный из логического сложения кодов входящих в описание понятий. Сформируем массив амплитуд A размерности m

При увеличении количества примеров N полезные элементы кода останутся равными 1 (или будут около 1 если данные содержат погрешность), ненужные элементы уменьшатся до величины, равной вероятности случайного появления единицы в коде описания. Произведя отсечение по порогу, гарантированно превосходящему случайный уровень, (например, 0.5), мы получим искомый код.
Коррелированные контексты
Обычно, при определении смысла информации оказывается, что в пространстве контекстов, возникает достаточно много высоких значений функции соответствия. Это обусловлено двумя причинами. Первая причина — наличие в информации нескольких смыслов. Вторая причина — узнавание в контекстах, близких к основному.
Предположим, что в памяти хранятся эталонные изображения цифр. Для простоты допустим, что образы в памяти отцентрированы и приведены к одному масштабу. Опять же, для простоты предположим, что на подаваемых изображениях цифры совпадают с эталонными, но могут находиться в произвольных местах. В такой ситуации узнавание цифр на картинке сводится к рассмотрению описаний в различных контекстах смещений по горизонтали и вертикали. Пространство контекстов можно изобразить так, как показано на рисунке ниже. Каждому контексту, который обозначен кружочком, соответствует определенное смещение, применяемое к рассматриваемой картинке.

Пространство контекстов горизонтального и вертикального смещения (смещение приведено в условных единицах)
Подадим изображение с двумя буквами A и B (рисунок ниже).
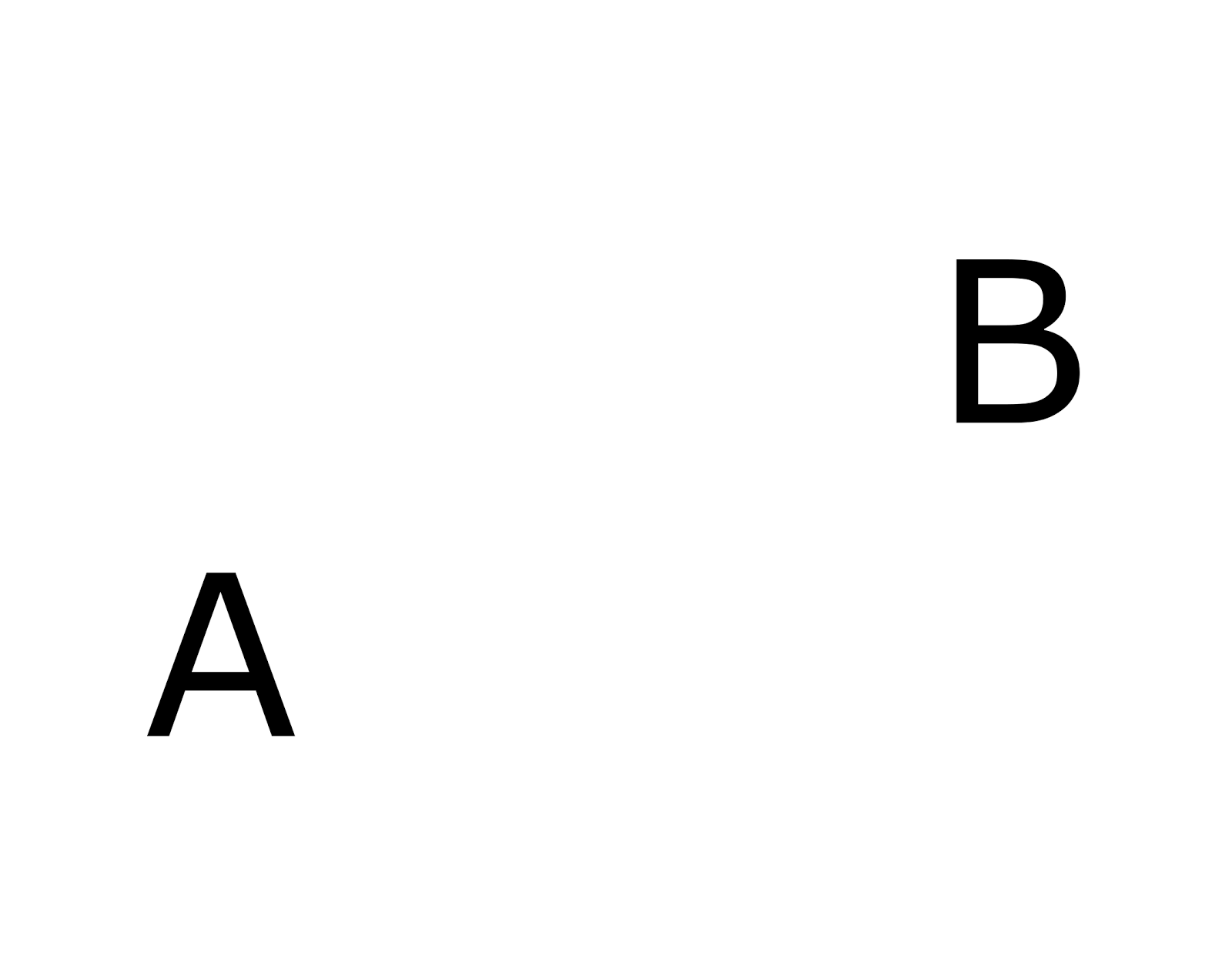
Изображение с двумя буквами
Каждая из букв будет узнана в том контексте, который приводит ее к соответствующему эталону, хранящемуся в памяти. На рисунке ниже наиболее подходящий для букв контекст выделен красным.

Пространство контекстов. Цветом выделены контексты с высоким значением функции соответствия
Но алгоритм определения соответствия может быть построен так, что соответствие, в той или иной степени, будет определяться не только при точном совпадении, но и при сильной схожести описаний (такие меры будут показаны позже). Тогда определенный уровень функции соответствия будет не только в наиболее подходящих контекстах, но и в контекстах, близких к ним по правилам преобразований. При этом близость подразумевает не количество совпавших правил, а некую близость получаемых описаний. В том смысле, что два правила, переводящие одно и то же понятие, в разные, но близкие понятия — это два разных правила, но, при этом, два близких преобразования. Близкие контексты показаны на рисунке выше розовым цветом.
После выделения смысла в исходном изображении, мы ожидаем получить описание вида: буква A в контексте сдвига (2,1) и буква B в контексте сдвига (-2,-1). Но для этого надо оставить всего два главных контекста, то есть избавления от лишних контекстов. Лишними в данном случае являются контексты близкие по смыслу к локальным максимумам, те, что на рисунке выше обозначены розовым.
Мы не можем при определении смысла взять глобальный максимум функций соответствия и на этом остановиться. В этом случае мы определим только одну букву из двух. Не можем мы ориентироваться и только на некий порог. Может так оказаться, что уровень соответствия во втором локальном максимуме будет ниже, чем уровень контекстов, окружающих первый локальный максимум.
Во многих реальных задачах контексты допускают введение неких обоснованных мер близости. То есть для любого контекста можно указать контексты похожие на него. В таких ситуациях полное определение смысла становится невозможно без учета этой взаимной похожести.
В приведенном примере мы не изобразили контексты как отдельные независимые сущности, а расположили их на плоскости таким образом, что близость точек, изображающих контекст, стала соответствовать близости контекстных преобразований. И тогда мы смогли описать искомые контексты, как локальные максимумы на плоскости точек, изображающих контексты. А лишние контексты стали ближайшим окружением этих локальных максимумов.
В общем случае можно воспользоваться тем же принципом, то есть расположить на плоскости или в многомерном пространстве точки, соответствующие контекстам, так, чтобы их близость наилучшим образом соответствовала близости контекстов. После этого выделение набора смыслов, содержащихся в информации, сводится к поиску локальных максимумов в пространстве, содержащем точки контекстов.
Для ряда задач близость контекстов можно определить аналитически. Например, для задачи зрительного восприятия основными контекстами являются геометрические трансформации, для которых можно рассчитать степень их похожести. В искусственных моделях для некоторых задач такой подход хорошо работает, но для биологических систем необходим более универсальный подход, основанный на самоорганизации.
Предположим, что каким-либо методом нам удалось сформировать контексты. Близкими можно считать такие контексты, функции соответствия которых реагируют сходным образом на одну и ту же информацию. Соответственно, коэффициент корреляции Пирсона между функциями соответствия контекстов можно использовать как меру похожести контекстов:
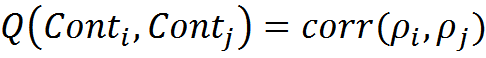
Для всей совокупности контекстов можно рассчитать корреляционную матрицу R, элементами которой будут парные корреляции функций соответствия.
Тогда можно описать следующий алгоритм выделения смыслов в описании:
- В каждом из контекстов исходное описание получает трактовку и, соответственно, оценку соответствия трактовки и памяти.
- Определяется глобальный максимум функции соответствия ρmax и соответствующий максимуму контекст-победитель.
- Если ρmax превосходит порог отсечения L0, то формируется одно из смысловых значений, как трактовка в контексте-победителе.
- Активность (значение функций соответствия) всех контекстов корреляция с которыми, исходя из матрицы R, превосходит некий порог L1 подавляется.
- Процедура повторяется с шага 2 до тех пор, пока ρmax не опустится ниже порога отсечения L0.
В результате мы получаем все независимые смысловые трактовки и избавляемся от менее точных, но близких к ним по смыслу интерпретаций.
В сверточных нейронных сетях свертка по различным координатам аналогична рассмотрению изображения в различных контекстах смещения. Использование набора ядер для свертки аналогично наличию разных воспоминаний. Когда свертка по какому-либо ядру в определенном месте показывает высокое значение, в соседних простых клетках, отвечающих за свертку по тому же ядру в соседних координатах, тоже возникает повышенное значение, образующее «тень» вокруг максимального значения. Причина этой «тени» аналогична причине, вызывающей повышения функции соответствия в окрестности контекста с максимальным значением.
Чтобы избавится от дублирующих значений и понизить размер сети используется процедура max-pooling. После слоя свертки пространство изображения разбивается на непересекающиеся области. В каждой области выбирается максимальное значение свертки. После чего получается слой меньшего размера, где за счет пространственного огрубления эффект «теневых» значений значительно ослабевает.
Пространственная организация
Матрица корреляций R, определяет сходство контекстов. В наших предположения кора мозга — это размещенные на плоскости миниколонки, каждая из которых является процессором определенного контекста. Видится вполне разумным разместить миниколонки не случайным образом, а так, чтобы похожие контексты располагались максимально близко друг к другу.
Для такого размещения есть несколько причин. Во-первых, это удобно для поиска локальных максимумов в пространстве контекстов. Собственно, само понятие локальный максимум применимо только к набору контекстов у которых есть некая пространственная организация.
Во-вторых, это позволяет «заимствовать» трактовки. Может оказаться, что память определенного контекста не содержит трактовки для какого-либо понятия. В таком случае можно попробовать воспользоваться трактовкой какого-либо близкого по смыслу контекста, у которого эта трактовка есть. Есть и другие очень важные причины, но о них мы поговорим позже.
Задача размещения на плоскости, исходя из похожести, близка к задаче укладки взвешенного неориентированного графа. Во взвешенном графе ребра не только задают связи между вершинами, но и определяют веса этих связей, которые можно трактовать, например, как меру близости этих вершин. Укладка графа — это построение такого его изображения, которое наилучшим образом передать меру близости, заданную весами ребер, через расстояние между вершинами изображенного графа.
Для решения этой задачи используется пружинная аналогия (Eades P., A heuristic for graph drawing, Congressus Nutnerantiunt — 42, pp. 149–160. — 1984.). Связи между вершинами представляются пружинами. Сила натяжения пружин зависит от веса соответствующего ребра и расстояния между соединяемыми вершинами. Чтобы вершины не упали в одну точку добавляется сила отталкивания, действующая между всеми вершинами.
Для полученной пружинной системы можно записать уравнение потенциальной энергии. Минимизация энергии соответствует нахождению требуемой укладки графа. На практике эта задача решается либо моделированием движения вершин под действием возникающих сил, либо решением системы уравнений, возникающих при записи условий минимизации энергии (Kamada, T., Kawai, S., An algorithm for drawing general undirected graphs, Information Processing Letters, Vol. 31. — pp. 7–15. — 1989).
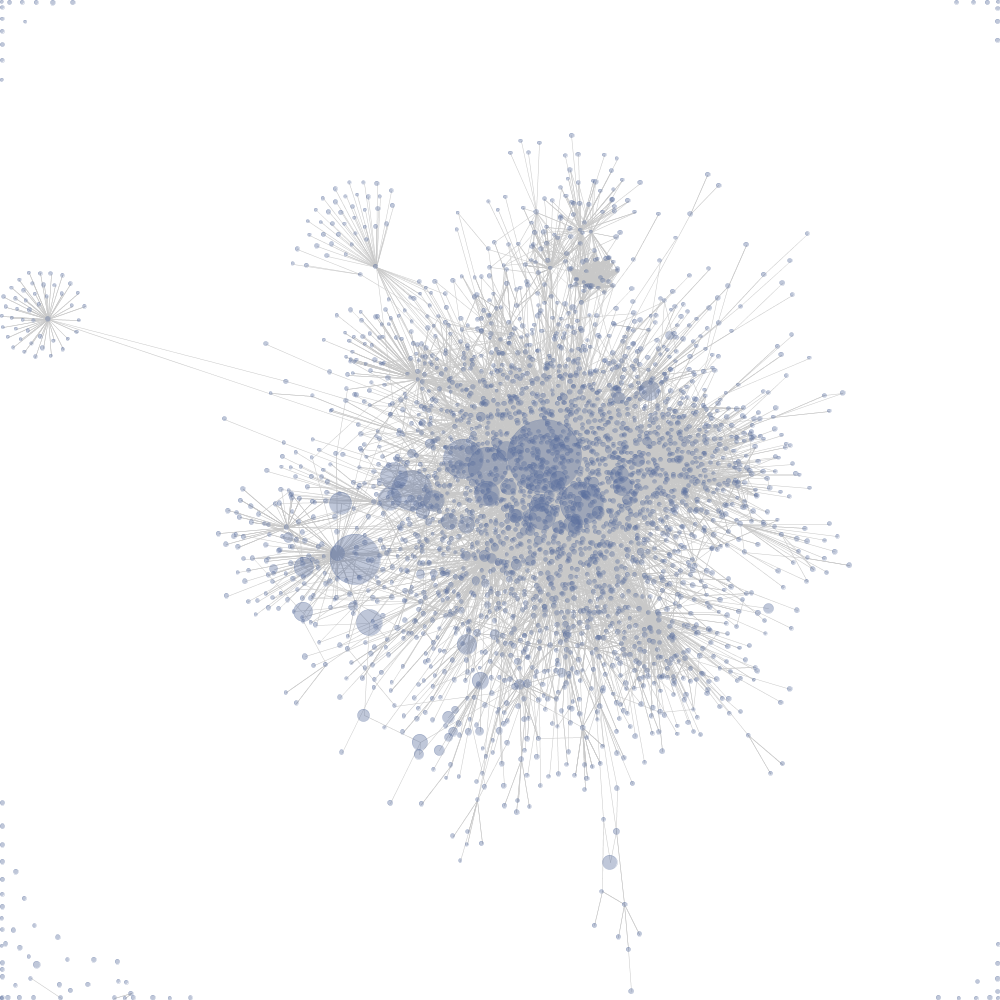
Визуализация графа связанности страниц википедии, построенная под действием направленных сил
Определенным аналогом укладки графа для случая клеточных автоматов является модель сегрегации Шеллинга (The Journal of Mathematical Sociology Volume 1, Issue 2, 1971. Dynamic models of segregation Thomas C. Schelling pages 143–186). В этой модели клетки автомата могут принимать значения разных типов (цветов) или быть пустыми. Для непустых клеток рассчитывается функция удовлетворенности, которая зависит от того насколько окружение клетки похоже на саму клетку. Если удовлетворенность оказывается слишком низкой, то значение этой клетки перемещается в какую-либо свободную клетку. Цикл повторяется пока состояние автомата не стабилизируется. В результате, если параметры системы это позволяют начальный случайный беспорядок сменяется островами, состоящими из значений одного типа (рисунок ниже). Модели сегрегации используются, например, для моделирования расселения людей с разными доходами, верой, рассой и тому подобным.


Начальное и конечное состояние сегрегации при четырех цветах
Идею минимизации энергии графа и принцип сегрегации клеточного автомата можно с некоторыми изменениями применить для пространственной организации контекстов. Возможен следующий алгоритм:
- Определяем контексты, характерные для поступающей информации.
- Определяем матрицу взаимных корреляций контекстов.
- Случайным образом распределяем контексты по клеткам клеточного автомата, размер которого позволяет вместить все контексты.
- Выбираем случайную клетку, содержащую контекст.
- Перебираем соседние клетки, например, восемь ближайших соседей, как потенциальное место для перемещения контекста, если клетка пустая или для обмена контекстами если непустая.
- Вычисляем изменение энергии автомата в случае каждого из потенциально возможных перемещений (обменов).
- Совершаем перемещение (обмен), которое лучше всего минимизирует энергию. Если такого нет, то остаемся на месте.
- Повторяем с шага 4 пока состояние автомата не стабилизируется.
В результате, контексты получаются расставлены так, что похожие контексты, по возможности, оказываются поблизости друг от друга. Посмотреть, как происходит такая самоорганизация можно на видео ниже.
Каждая цветная точка на видео соответствует своему контексту. Каждый контекст имеет несколько параметров, которые его определяют. Корреляция контекстов рассчитывается, исходя из близости этих параметров. В приведенном примере нет создания контекстов из исходной информации, это, просто, иллюстрация пространственной организации для случая, когда корреляции между контекстами уже рассчитаны заранее. Программа, иллюстрирующая самоорганизацию методом перестановок, доступна по ссылке.
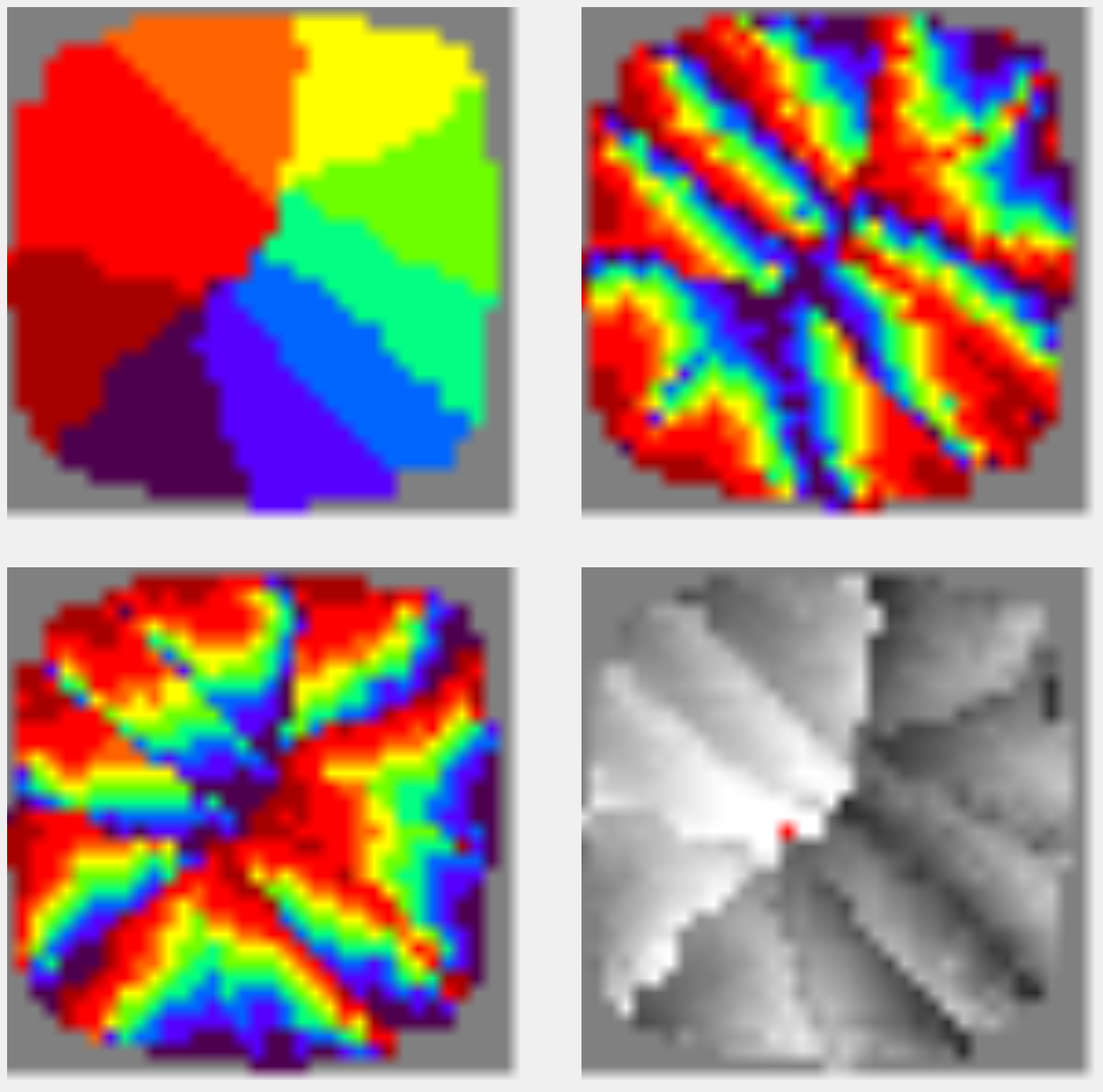
В приведенном примере контексты соответствуют всевозможным комбинациям четырех параметров. Первый параметр является кольцевым, два параметра линейны, четвертый принимает два значения. Это соответствует контекстам, которые можно использовать для анализа изображений. Первый параметр описывает поворот, второй и третий смещения по горизонтали и вертикали, соответственно, четвертый параметр говорит о том к какому глазу относится информация.
Каждому параметру сопоставлен цветовой спектр. По близости цветов в спектре можно судить о близости значений параметра. В примере каждый контекст имеет четыре значения. То есть, свое значение для каждого из параметров и, соответственно, свой цвет в каждом из них. В квадратах показаны цвета контекстов в каждом из параметров. Все цветные картинки показывают одни и те контексты, но в цветах разных параметров (рисунок ниже).

Результат самоорганизации для контекстов с четырьмя независимыми параметрами
Суть пространственного упорядочивания в том, что контекстам в процессе перемещения приходится найти компромисс между всеми параметрами. В примере на видео этот компромисс достигается за счет того, что линейные параметры выстраивают линейное поле. То есть контексты встают так, что формируют некое соответствие координатной сетки. Кстати, именно так были расставлены контексты на примере выше, когда мы говорили об узнавании букв.
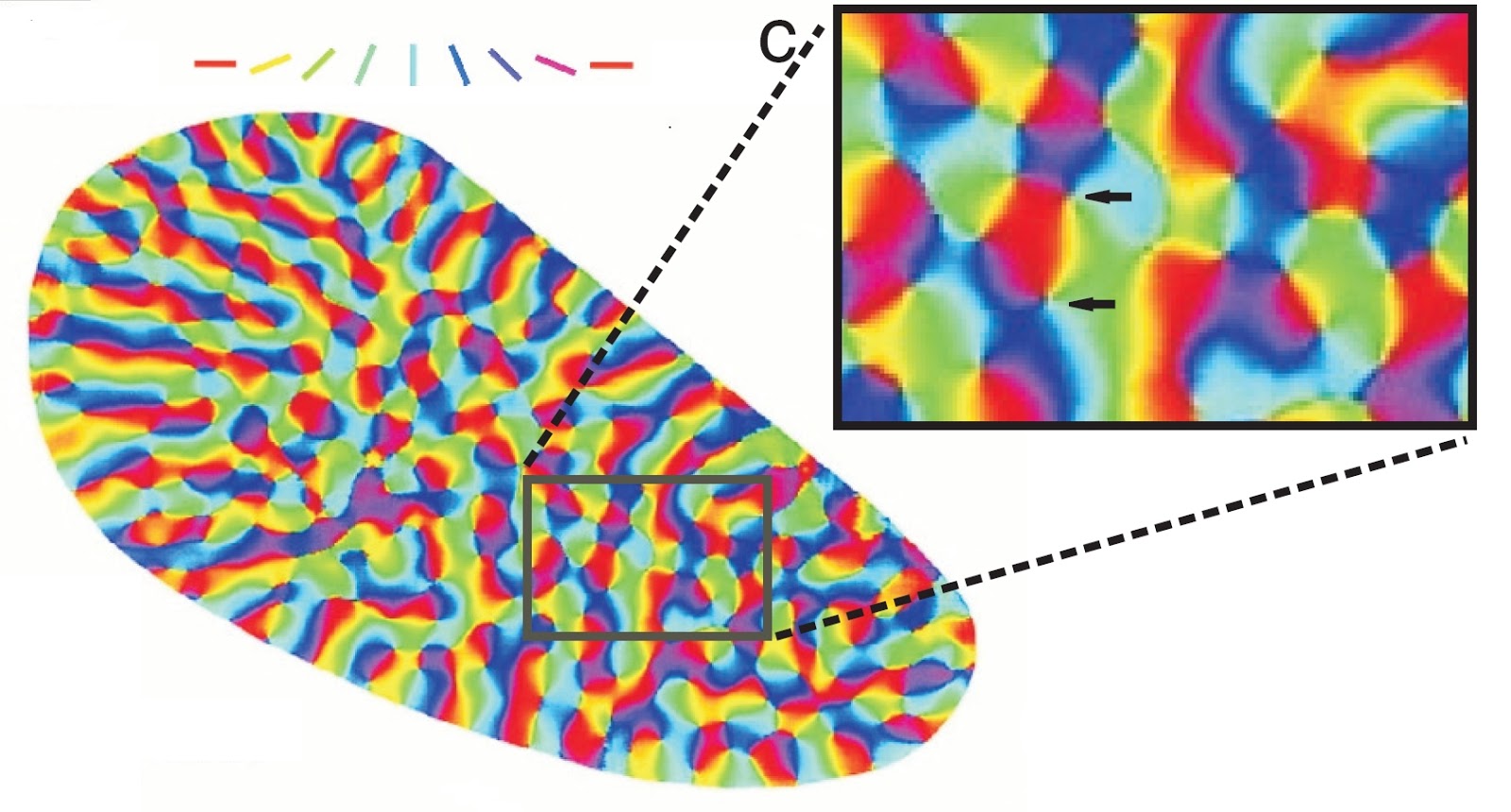
Для кольцевого параметра поворота по всей поверхности сформировались группы, содержащие по полному набору цветов. В зрительной коре такие конструкции называют «вертушками» или «волчками». Как выглядят «вертушки» в первичной зрительной коре показано на заглавной картинке. Подробнее об этом и о четвертом квадрате с колонками глазодоминантности будет рассказано в следующей части.
В зависимости от того на сколько интервалов разбит каждый из параметров получается разное количество контекстов, стремящихся непременно оказаться рядом. При большем дроблении кольцевого параметра по сравнению с линейными может получиться картина, когда контексты выстроятся в одну большую «вертушку» (рисунок ниже). При этом линейные параметры сформируют локальные линейные поля, распределенные по всему пространству.
Пространственная организация контекстов для случая с тремя независимыми параметрами. Кольцевой параметр доминирует и образует глобальную «вертушку», два линейных параметра образуют локальные линейные поля. Правый нижний квадрат показывает элементы близкие к тому, который выделен красной точкой
Независимо от того к чему сойдется процесс перестановок похожие контексты оказываются преимущественно рядом друг с другом. На рисунках ниже показаны примеры такой близости. На каждом рисунке один из контекстов выделен красным, яркость остальных контекстов соответствует степени их близости к выделенному контексту.

Распределение близости контекстов по отношению выбранному
При применении описанного алгоритма требуется учитывать все взаимные корреляции контекстов. Сами корреляции можно изобразить как связи клеток автомата. Каждая клетка оказывается связана со всеми остальными клетками. Каждая связь отвечает за парную корреляцию тех клеток между которыми она проходит. Можно значительно уменьшить количество связей если воспользоваться методом Barnes-Hut (Barnes J., Hut P., A hierarchical O (N log N) force-calculation algorithm. Nature, 324(4), December 1986). Его суть заключается в замене влияния удаленных элементов на влияние квадрантов, включающих эти элементы. То есть, удаленные элементы можно объединять в группы и рассматривать их как один элемент с усредненным для группы расстоянием и усредненной силой связи. Такой метод особенно хорошо работает для расчета взаимного притяжения звезд в звездных скоплениях.
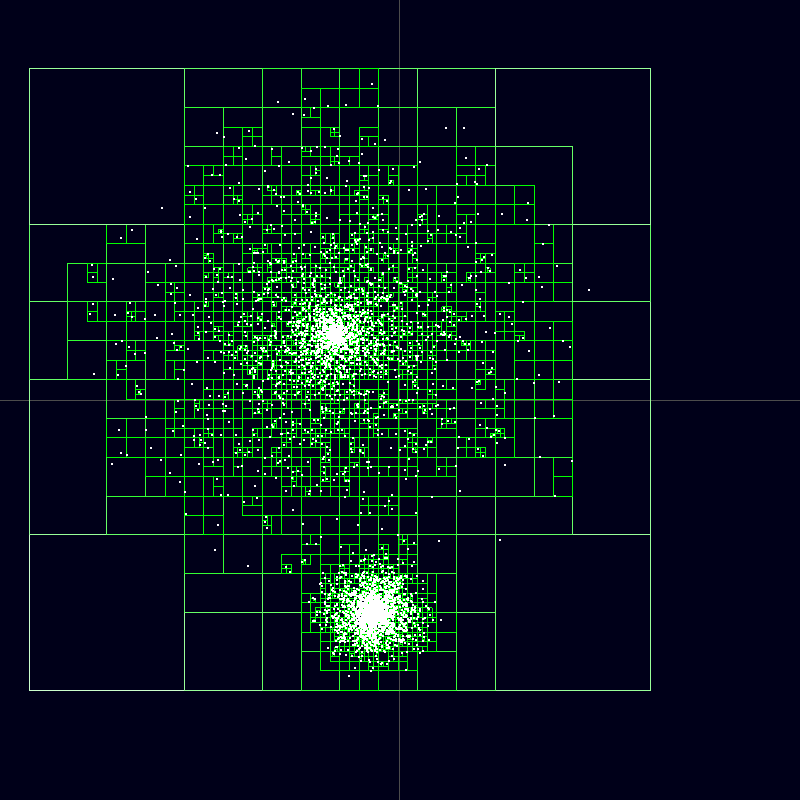
Пространственные квадранты, заменяющие отдельные звезды
Имея организованную подобным образом карту контекстов, можно несколько упростить решение задачи поиска локальным максимумов. Теперь каждый контекст требуется связать с другими похожими контекстами, расположенными поблизости от него и с островками похожих контекстов, отнесенных на некоторое расстояние. Длина таких связей после пространственной организации будет меньше, чем до организации, так как именно такой критерий лежал в основе расчета энергии системы.
Выгода пространственной организации
Вернемся к примеру с переводом. Контесты — это смысловые области в которых действуют общие правила перевода. Расставив контексты пространственно, мы получаем соседствующие в пространстве группы контекстов, относящиеся приблизительно к одной тематике. Внутри группы каждый из отдельных контекстов выражает тонкости перевода в определенном уточненном смысле.
Сколько всего надо контекстов? Казалось бы, чем больше тем лучше. Чем больше доступно контекстов, тем больше деталей и оттенков смысла можно учесть при выборе перевода. Но обратная сторона детализации — это дробление опыта трактовок. Чтобы знать правила перевода для каких-либо слов в конкретном контексте надо иметь опыт их перевода именно в этом контексте. Каждый пример перевода дает нам набор правил перевода. Если отнести эти правила к какому-либо одному контексту, который оказался самым удачным, то они окажутся недоступны для других контекстов.
Пространственная организация и корреляционные связи позволяют для любого выбранного контекста понять какие контексты близки ему по смыслу. Это значит, что если в выбранном контексте отсутствует собственный опыт перевода, то можно воспользоваться опытом перевода соседних близких по смыслу контекстов, если такой опыт есть там.
Обращение к опыту соседей позволяет искать компромисс между детализацией контекстов и дроблением опыта. Для перевода это может выглядеть так, что группа контекстов, относящихся к общей тематике и расположенных поблизости друг от друга, совместно хранит правила перевода для этой предметной области. При этом каждый отдельный контекст содержит определенные собственные уточнения, отражающие нюансы смысла.
Кроме того, ограниченность числа доступных контекстных модулей в реальных задачах потребует поиска наилучшего приближенного решения. В этом может сильно помочь тот факт, что сама пространственная карта контекстов во многом учитывает специфику обрабатываемой информации.
Еще одна выгода пространственной организации заключается в возможности «делать несколько дел одновременно». Разговор не идет о том, что мы можем, например, одновременно вести машину и разговаривать по телефону. Если для этого задействованы разные зоны коры, то ничего удивительного в этом нет. Но все становится интереснее, когда нам приходится разговаривать с кем-то и думать о чем-то своем или разговаривать сразу на две разные темы с разными собеседниками, или
