Логические поля в базах данных, есть ли противоядие

Часто в таблицах содержится большое количество логических полей, проиндексировать все из них нет возможности, да и эффективность такой индексации низка. Тем не менее, для работы с произвольными логическими выражениями в SQL пригоден механизм многомерной индексации о чем и пойдёт речь под катом.
В SQL логические поля используются в основном в двух случаях. Во-первых, когда действительно нужен бинарный атрибут, например, «купля/продажа» в таблице сделок. Такие атрибуты редко меняются со временем.
Во-вторых, для записи состояния конечного автомата, которым описывается запись. Имеется в виду, что логический объект, соответствующий записи таблицы, проходит ряд состояний, число которых и переходы между которыми определяются прикладной логикой. Простой пример — техника «soft-delete», когда запись физически не уничтожается, а только помечается как удалённая.
Если автомат сложный, таких полей может быть изрядное количество, в одной из наших таблиц 58 (+14 устаревших) таких полей (включая наборы флагов) и это не что-то из ряда вон выходящее. Так не было задумано изначально, но по мере развития продукта и изменения внешних требований развиваются и соответствующие автоматы, приходят и уходят разработчики, меняются аналитики… в какой-то момент может оказаться безопаснее завести новый флаг, нежели разбираться во всех хитросплетениях. Тем более что накопились исторические данные и их состояния обязаны оставаться адекватными.
Завести флаг означает не только добавить поле соответствующего типа, но и учесть его в работе автомата, какие состояния оно затрагивает, в каких переходах участвует. На практике это выглядит так:
- процесс или ряд процессов, назовём их «писателями», создают новые записи в начальном состоянии (возможно, в одном из начальных состояний)
- ряд процессов, назовём их «читателями», время от времени читают объекты, находящиеся в нужных им состояниях
- ряд процессов, назовём их «обработчиками», следят за конкретными состояниями и исходя из прикладной логики меняют эти состояния. Т.е. осуществляют деятельность конечного автомата.
Для того чтобы выбрать записи, находящиеся в конкретном состоянии, редко когда достаточно фильтрации по одному из булевых полей. Обычно это целое выражение, иногда нетривиальное. Казалось бы, надо проиндексировать эти поля и SQL-процессор сам разберётся. Но не всё так просто.
Во первых, булевых полей может быть много, индексировать их все было бы слишком расточительно.
Во вторых, это может оказаться бесполезным т.к. селективность по каждому из полей будет низкой, а совместная вероятность статистикой SQL-процессора не покрывается.
Пусть, в таблице T1 есть два булевых поля: F1 & F2, а запрос
select F1, F2, count(1) from T1 group by F1, F2
выдаёт
Т.е. хотя, по F1 & F2 выпадение true и false равновероятно, сочетание (true, false) выпадает только один раз из тысячи. В результате, если раздельно проиндексировать F1 & F2 и принудить использовать эти индексы в запросе, SQL-процессору пришлось бы прочитать по половине обоих индексов и пересечь результаты. Возможно, дешевле прочитать всю таблицу и вычислить выражение для каждой строчки.
И даже если собирать статистику по исполненным запросам, толку от нее будет мало т.к. статистика конкретно по полям, отвечающим за состояние автомата очень сильно плавает. Ведь в любой момент может прийти «обработчик» и половину строк из состояния S1 перевести в S2.
Для работы с такими выражениями напрашивается многомерный индекс, алгоритм которого был представлен ранее и неплохо себя зарекомендовал.
Но прежде требуется разобраться каким образом произвольное логическое выражение превратится в запрос (ы) к индексу.
Дизъюнктивная нормальная форма
Единичный запрос к многомерному индексу представляет собой многомерный прямоугольник, ограничивающий пространство запроса. Если поле участвует в запросе, для него задаётся ограничение. Если нет, прямоугольник по этой координате ограничен только разрядностью данной координаты. Логические координаты имеют разрядность 1.
Поисковый запрос в таком индексе является цепочкой из & (конъюнкцией), например, выражение: v1 & v2 & v3 & (! v4), эквивалентно v1:[1,1], v2:[1,1], v3:[1,1], v4:[0,0]. А все остальные поля имеют диапазон: [0,1].
Учитывая это, наш взор сразу обращается в сторону ДНФ — одной из канонических форм логических выражений. Утверждается, что любое выражение может быть представлено к виду дизъюнкции конъюнкций литералов. Под литералом здесь понимается логическое поле или его отрицание.
Иными словами, путём нехитрых манипуляций, любое логическое выражение может быть представлено в виде дизъюнкции нескольких запросов к многомерному логическому индексу.
Есть и одно НО. Такое преобразование в некоторых случаях может привести к экспоненциальному росту размера выражения. Например, преобразование из
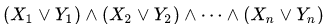
приводит к выражению размером в 2**n термов. В таких случаях прикладному разработчику стоит задуматься о физическом смысле того, что он делает, а со стороны SQL процессора всегда можно отказаться от использования логического индекса, если число конъюнкций превышает пределы разумного.
Алгоритм многомерной индексации
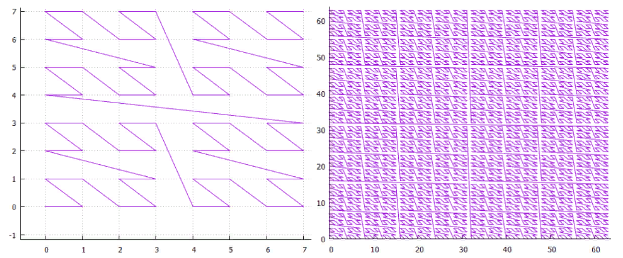
Для многомерной индексации используются свойства самоподобной нумерующей кривой на основе гипер-кубических симплексов со стороной 2. Как оказалось, практическое значение имеют два варианта таких кривых — Z-кривая и кривая Гильберта.
Фиг.1 двумерная Z-кривая, 3 и 6 итерации
Фиг.2 двумерная кривая Гильберта, 3 и 6 итерации
- N-мерный симплекс со стороной 2 имеет 2**n вершин и (2**n-1) переходов между ними.
- Элементарная итерация симплекса превращает каждую вершину симплекса в симплекс нижнего уровня.
- Проделав нужное число итераций, можно построить гипер-кубическую решетку любого размера.
- При этом каждый узел этой решетки будет иметь свой уникальный номер — путь, проделанный по нумерующей кривой от ее начала. При этом каждый узел этой решетки имеет значение по каждой из координат. Фактически, нумерующая кривая переводит многомерную точку в одномерное значение, пригодное для индексации обычным B-деревом.
- Все узлы, находящиеся внутри симплекса любого уровня, находятся в пределах одного интервала и этот интервал не пересекается ни с одним симплексом того же уровня.
- Следовательно, любой поисковый прямоугольник (параллелепипед) может быть разбит на небольшое число гипер-кубических подзапросов, в пределах каждого из которых индекс может быть прочитан одним поиском/траверзом.
- К этому добавим магию низкоуровневой работы с B-деревом для того, чтобы не делать бесполезные запросы и … алгоритм готов.
Вот как это работает на практике:

Фиг.3 Пример поиска в двумерном индексе (Z-кривая)
На фиг.3 показано разбиение исходного поискового экстента на подзапросы и найденные при этом точки. Использовался двумерный индекс, построенный на случайном равномерно распределенном наборе 100 000 000 точек в экстенте [1 000 000, 1 000 000].
Логический многомерный индекс
Раз уж речь зашла о многомерном индексировании, самое время задуматься, а насколько многомерным он может быть? Есть ли какие-то объективные ограничения?
Конечно, ведь B-дерево имеет страничную организацию и для того, чтобы быть деревом, на странице должно гарантированно помещаться не менее двух элементов. Если принять страницу за 8К, значит на хранение одного элемента не может уходить больше 4К. В 4К без сжатия влезает около 1000 32-разрядных значений. Это довольно много, выше пределов любого разумного применения, можно сказать, что физические пределы практически не доступны.
Есть и другая сторона, каждое дополнительное измерение отнюдь не бесплатно, на него уходит дисковое пространство и замедляется работа. С точки зрения «физического смысла», в один индекс должны попадать поля, которые меняются одновременно и поиск по ним тоже идёт совместно. Никакого смысла индексировать всё подряд нет.
С логическими полями всё по другому. Как мы видели, в одних и тех же механизмах могут быть задействованы десятки логических полей. А затраты на хранение/чтение довольно малы. Есть соблазн собрать всё без исключения логические поля в одном индексе и посмотреть что получится.
Правда, есть нюансы:
- До сих пор в индексируемом значении разряды разных координат перемешивались, в младших разрядах ключа оказывались младшие разряды координат … Поэтому порядок следования полей при индексации не имел значения.
- Теперь же на хранение значения одного логического поля тратится один разряд. Т.е. какие-то логические поля попадут в конец ключа, а какие-то в начало. А это означает, что фильтрация по части полей будет проходить очень эффективно, а по некоторым очень неэффективно. В самом деле, если мы делаем поиск по самому младшему разряду, придётся прочитать весь индекс чтобы получить ответ. Но это (скорее всего) лучше, чем прочитать всю таблицу, чтобы ответить на тот же вопрос.
- Возникает проблема выбора — все логические поля равны, но некоторые окажутся равнее прочих. Из общих соображений, необходимо смотреть на перекосы статистики, чем сильнее соотношение true/false для конкретного поля отстоит от равновесного, тем старше должен быть разряд, в котором окажется его значение.
- Исчезает разбиение по типу нумерующей кривой, если раньше приходилось выбирать между Z-кривой и кривой Гильберта, на одноразрядных данных практической разницы нет.
- NULL-ы. Если исходить из того, что NULL — это не неизвестное значение, а отсутствие какого бы то ни было значения, то такие записи не должны попадать в индекс. В одномерных индексах так и происходит. Но в нашем случае может оказаться, что часть логических полей содержит значения, а часть нет. В результате мы не можем положить это в индекс т.к. алгоритм поиска не умеет работать с троичной логикой. А следовательно, такие записи должно быть невозможно вставить в таблицу (при наличии многомерного индекса, необязательно логического, кстати)
Ожидается, что логический многомерный индекс может в некоторых случаях работать не слишком эффективно. Строго говоря, любой индекс может работать неэффективно, если слишком большое количество данных попадает в область поиска. Но для логического многомерного индекса это усугубляется описанной выше зависимостью от порядка полей, когда ради небольшого результата придётся прочитать весь индекс. Насколько это является проблемой на практике, может показать только эксперимент.
Численный эксперимент
Построение индекса:
- индекс будет 128-разрядным, т.е. построен по 128 логическим полям
- и будет содержать 2**30 элементов
- значением элемента индекса будет число от 0 до 2**30
- ключом элемента индекса будет то же число, сдвинутое на 48 разрядов влево, т.е. логические поля с 48 по 78 будут заполнены разрядами числа в том же порядке
- в результате получим 30 значимых логических полей в середине ключа, остальные разряды будут заполнены 0
- Каждое из логических полей имеет равную статистику true/false
- Все они статистически независимы
Поиск:
- Каждому эксперименту соответствует выбор нескольких подряд идущих логических полей и задание для них поисковых значений. Не потому, что алгоритм умеет искать только полосами, а из-за того, что так можно нагляднее представить результаты эксперимента, имеем всего две размерности — ширина полосы и её положение
- Всего 24 серии экспериментов. В каждой серии будем искать такие значения, где полоса логических полей соответствующей ширины N (от 1 до 24 разрядов) принимает значение true.
- В каждой серии будет подсерия экспериментов, в которой полоса логических полей выбранной ширины располагается с различными сдвигами S от начала полосы в 30 значимых логических полей. Всего (30-N) экспериментов в подсерии.
- В каждом эксперименте делается поиск всех элементов индекса, удовлетворяющих условию, т.е. поля с номерами в интервале [48 + S, 48 + S + N -1] будем искать в интервале [1,1], остальные — в интервале [0,1]
- Поиск делается с холодного старта
- Результатом является число прочитанных дисковых страниц, с учетом кэширования (кэш на 4096 страниц)
- Контроль правильности работы делается двумя путями — число найденных элементов должно быть равно 2**(30-N) и в найденных значениях можно проверить соответствующие разряды
Итак,
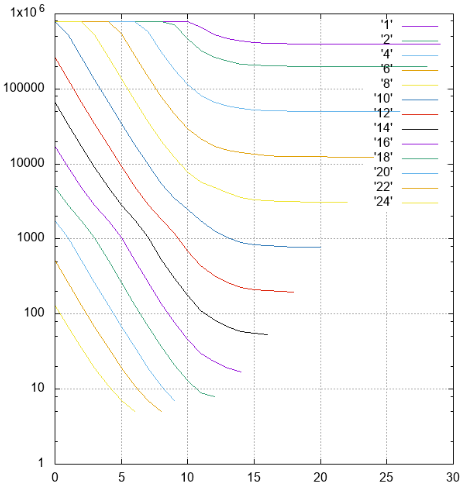
Фиг.4 Результаты, число прочитанных страниц в разных сериях
По Y — отложены количества прочитанных страниц.
По X — сдвиг полос от самого младшего (48) разряда к старшему. Полосы разной ширины подписаны и отмечены разными цветами.
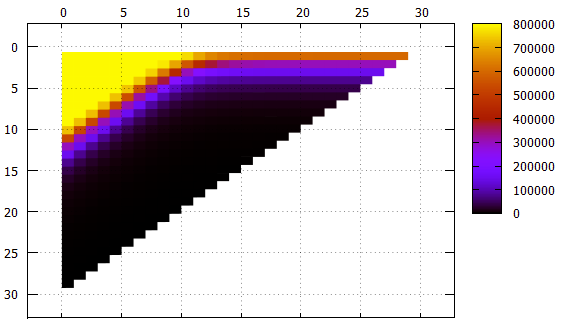
Фиг.5 Те же данные что и Фиг.4, другое представление
По X — сдвиг полосы
По Y — ширина полосы
Что следует отметить:
- хотя на картинках это прямо не видно, индекс работает правильно, это видно и по числу найденных элементов и по содержанию самих элементов
- все полосы шириной не больше 10 со сдвигом 0 требуют сплошного чтения индекса
- полосы шириной от 1 до 18 с ростом сдвига выходят на асимптоту 2**(-N) от размера всего индекса, что логично
- для более широких полос асимптота — высота дерева, меньше неё чтений быть не может
- на листовой странице индекса помещается чуть больше 1000 элементов, это видно по полосе шириной 10, которая при сдвиге 0 уже не требует чтения всего индекса, некоторые страницы удаётся пропускать
- низкоуровневая фильтрация работает на удивление хорошо. Рассмотрим полосу шириной 10. Идеальный для поиска вариант — со сдвигом 20 (всего 30 значимых полей), когда в префиксе вообще нет неопределенных полей, данные можно найти единственным траверзом. В этой ситуации при поиске читается примерно 1/1000 индекса — 779 страниц.
Промежуточный случай — сдвиг 10, у нас префикс и суффикс в 10 неизвестных полей. Число страниц — 2484, всего втрое хуже, чем в идеальном случае.
И даже в худшем случае со сдвигом в 0 (префикс в 20 неизвестных полей) удаётся пропускать какие-то страницы.
В целом можно признать алгоритм многомерной индексации работоспособным даже в таком доведенном до абсурда случае. А ведь рассматривается самый неудачный с точки зрения логического индекса вариант — равновероятные состояния по всем независимым логическим полям.
Эксперимент на реальных данных
Таблица Trades, всего 278 479 918 строк, данные одного из тестовых контуров.
Результаты выполнения некоторых запросов в таблице ниже:
На чтение/обработку одной страницы в среднем уходит 0.8 мсек.
Нет необходимости описывать смысл конкретных запросов, они здесь просто для демонстрации работоспособности. Которая, кстати, подтверждена.
Но прежде чем данная техника сможет принести практическую пользу, предстоит еще очень много сделать. Так что, продолжение следует.
