Lock-free стек для Windows
 Windows принято не любить. Однако, зачастую, фраза: «Книгу писателя не читал, но осуждаю» очень хорошо описывает эту ситуацию. Несмотря на укоренившееся презрение к «Винде», отдельные вещи в ней реализованы весьма удачно и именно об одной из них мы хотели бы написать. Отдельные фрагменты WinAPI, хотя и были реализованы достаточно давно, по разным причинам, и часто незаслуженно, выпали из поля зрения широкой аудитории.В этой статье речь пойдёт о встроенной в ОС реализации lock-free стека и сравнении его производительности с кросс-платформенными аналогами.Итак, уже довольно давно в WinAPI есть реализация неблокирующего стека на основе односвязного списка (Interlocked Singly Linked Lists), который сокращенно называют SList. Реализованы операции инициализации такого списка и стековые примитивы над ним. Не вдаваясь в подробности реализации своих SList, Майкрософт лишь указывает, что использует некий неблокирующий алгоритм для реализации атомарной синхронизации, увеличения производительности и проблем с блокировками.Неблокирующие односвязные списки можно реализовать самостоятельно, и об этом, в частности, уже много и подробно писал Максим Хижинский (khizmax) в своем монументальном цикле статей о lock-free алгоритмах на Хабре. Однако до Windows 8 не существовало 128-битной операции CAS, что иногда создавало проблемы при реализации подобных алгоритмов в 64-битных приложениях. Slist, таким образом, помогает решать эту задачу.
Windows принято не любить. Однако, зачастую, фраза: «Книгу писателя не читал, но осуждаю» очень хорошо описывает эту ситуацию. Несмотря на укоренившееся презрение к «Винде», отдельные вещи в ней реализованы весьма удачно и именно об одной из них мы хотели бы написать. Отдельные фрагменты WinAPI, хотя и были реализованы достаточно давно, по разным причинам, и часто незаслуженно, выпали из поля зрения широкой аудитории.В этой статье речь пойдёт о встроенной в ОС реализации lock-free стека и сравнении его производительности с кросс-платформенными аналогами.Итак, уже довольно давно в WinAPI есть реализация неблокирующего стека на основе односвязного списка (Interlocked Singly Linked Lists), который сокращенно называют SList. Реализованы операции инициализации такого списка и стековые примитивы над ним. Не вдаваясь в подробности реализации своих SList, Майкрософт лишь указывает, что использует некий неблокирующий алгоритм для реализации атомарной синхронизации, увеличения производительности и проблем с блокировками.Неблокирующие односвязные списки можно реализовать самостоятельно, и об этом, в частности, уже много и подробно писал Максим Хижинский (khizmax) в своем монументальном цикле статей о lock-free алгоритмах на Хабре. Однако до Windows 8 не существовало 128-битной операции CAS, что иногда создавало проблемы при реализации подобных алгоритмов в 64-битных приложениях. Slist, таким образом, помогает решать эту задачу.
РеализацияК особенностям реализации SList стоит отнести требование выравнивания памяти для элементов списка по границе MEMORY_ALLOCATION_ALIGNMENT. Впрочем, схожие требования предъявляются и при прочих interlocked операциях в WinAPI. Для нас это означает необходимость использовать aligned_malloc/aligned_free при работе с памятью элементов списка.Другой особенностью является требование, чтобы указатель на следующий элемент списка типа SLIST_ENTRY располагался в самом начале структуры: до наших собственных полей.
Ниже приводится реализация шаблона на C++, оборачивающего нативные функции WinAPI для работы с SList:
Код шаблона C++
template
Так вызываем тест
template
// Initiate a timer to measure performance boost: timer: cpu_timer timer;
cout << T::get_name() << "\t" << producers << "\t" << consumers << "\t";
// Reset the counters after the previous test producer_count = consumer_count = 0; done = false; ResetEvent (hEvtDone);
// Start all the producer threads with a given thread proc for (int i = 0; i!= producers; ++i) producer_threads.create_thread (T: producer);
// Start all the consumer threads with a given thread proc for (int i = 0; i!= consumers; ++i) consumer_threads.create_thread (T: consumer);
// Waiting for the producers to complete producer_threads.join_all (); done = true; SetEvent (hEvtDone);
// Waiting for the consumers to complete
consumer_threads.join_all ();
// Report the time of execution
auto nanoseconds = boost: chrono: nanoseconds (timer.elapsed ().user + timer.elapsed ().system);
auto seconds = boost: chrono: duration_cast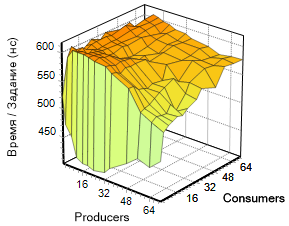 Вариации параметров по двум измерениям (consumers, producers) дают нам функцию t (p, c), чей график приведен на изображении слева.
Вариации параметров по двум измерениям (consumers, producers) дают нам функцию t (p, c), чей график приведен на изображении слева.
Для того, чтобы не пришлось глазами считать число нулей в результатах, вместо подсчёта числа заданий в секунду, мы приводим время на выполнение одного задания в наносекундах, посчитанное как общее время теста, деленное на общее число заданий. Чем ниже эта величина, тем быстрее работает алгоритм.
Число потоков каждого типа менялось по последовательности:
int NumThreads[] = { 2, 4, 8, 12, 16, 20, 24, 32, 36, 48, 56, 64, 72 };
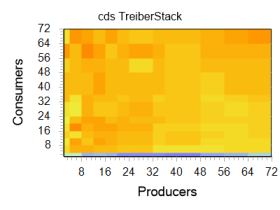
Обратим внимание на эту поверхность. Заметно серьезное ускорение алгоритма при малом числе потребителей (область графика, окрашенная зеленым цветом). Дальнейшее наращивание числа потоков обоих типов не приводит к заметному изменению скорости работы, хотя видно, что показатель несколько «плавает» в узком коридоре, но график сохраняет успокаивающий оранжевый тон.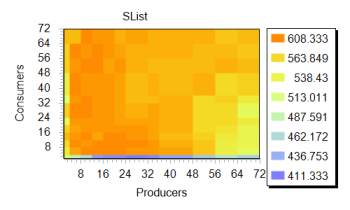 Если рассмотреть тот же график в другом исполнении, эта граница видна еще отчетливее. На изображении справа весьма чётко различима благодатная зелено-голубая полоса, отмечающая весь регион с четырьмя «потребителями» и произвольным числом «производителей», что, кстати, совпадает с числом ядер в эксперименте. Далее будет показано, что остальные реализации демонстрируют схожую динамику. Это наталкивает на мысль о схожести алгоритма, использованного Майкрософт, с тем, что применяется в сторонних библиотеках.
Если рассмотреть тот же график в другом исполнении, эта граница видна еще отчетливее. На изображении справа весьма чётко различима благодатная зелено-голубая полоса, отмечающая весь регион с четырьмя «потребителями» и произвольным числом «производителей», что, кстати, совпадает с числом ядер в эксперименте. Далее будет показано, что остальные реализации демонстрируют схожую динамику. Это наталкивает на мысль о схожести алгоритма, использованного Майкрософт, с тем, что применяется в сторонних библиотеках.
Отрадно видеть, что lock-free подход блистает здесь во всей красе: сложно представить 72(+72) потока, с 1 млн заданий каждый, висящие в lock-е. Впрочем, с этого обычно начинаются статьи о lock-free
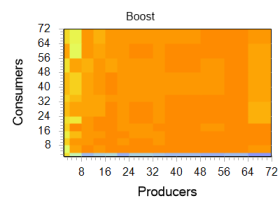
Сравнение Идентичный тест запускался на том же компьютере и для двух других реализаций неблокирующих контейнеров, взятых из известных библиотек (boost: lockfree и libcds) в следующем цикле: int NumThreads[] = { 2, 4, 8, 12, 16, 20, 24, 32, 36, 48, 56, 64, 72 };
for (int p: NumThreads)
for (int c: NumThreads)
{
run_test
Библиотека Boost.Lockfree Эта библиотека вошла в состав boost сравнительно недавно. В её составе реализованы три контейнера: очередь, стек и кольцевой буфер. Пользоваться их классами, как всегда удобно. Есть документация и, даже, примеры.Ниже приводится код для аналогичного теста, использующего boost: stack.
Тест boost
class test
{
private:
static: boost: lockfree: stack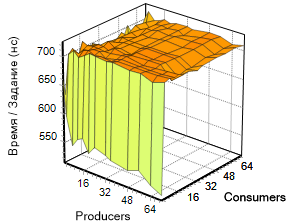
 Библиотека libcds
На эту библиотеку часто ссылается khizmax в своих статьях. Вне зависимости от своих потребительских качеств, она показалось нам несколько громоздкой и плохо документированной (больше всего информации удалось почерпнуть здесь, на Хабре). Кроме того, в каждом потоке, где используются их lock-free контейнеры, требуется выполнять attach своего потока к их «движку» (вероятно, из-за TLS?), потом делать его detach и еще необходимо где-то инициализировать Hazard Pointer синглтон.Несмотря на немыслимое количество реализованных lock-free контейнеров, на любой вкус, эту библиотеку сложно назвать красивой — к ней нужно привыкать.
Библиотека libcds
На эту библиотеку часто ссылается khizmax в своих статьях. Вне зависимости от своих потребительских качеств, она показалось нам несколько громоздкой и плохо документированной (больше всего информации удалось почерпнуть здесь, на Хабре). Кроме того, в каждом потоке, где используются их lock-free контейнеры, требуется выполнять attach своего потока к их «движку» (вероятно, из-за TLS?), потом делать его detach и еще необходимо где-то инициализировать Hazard Pointer синглтон.Несмотря на немыслимое количество реализованных lock-free контейнеров, на любой вкус, эту библиотеку сложно назвать красивой — к ней нужно привыкать.
Ниже приводится код для аналогичного теста, использующего cds: container: TreiberStack:
Тест libcds
class xxxstack: public cds: container: TreiberStack
for (int i = 0; i!= iterations; ++i) { //int value = ++producer_count; while (! stack.push (++producer_count)); }
// Detach thread when terminating cds: threading: Manager: detachThread (); } static void consumer (void) { // Attach the thread to libcds infrastructure cds: threading: Manager: attachThread ();
int64_t value; while (WaitForSingleObject (hEvtDone, 10) != WAIT_OBJECT_0) { while (stack.pop (value)) { ++consumer_count; } } while (stack.pop (value)) { ++consumer_count; }
// Detach thread when terminating
cds: threading: Manager: detachThread ();
}
};
Приводим результаты данного теста в виде графиков: 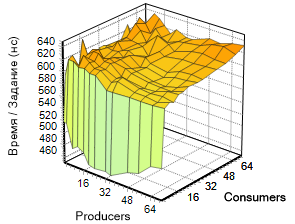
 Сравнение производительности
Несмотря на то, что SList — нативное решение, а два остальных — «почти» кросс платформенные, мы считаем, что приводимое нами ниже сравнение правомочно, так как все тесты были проведены в одинаковых условиях и демонстрируют поведение библиотек в этих условиях.
Сравнение производительности
Несмотря на то, что SList — нативное решение, а два остальных — «почти» кросс платформенные, мы считаем, что приводимое нами ниже сравнение правомочно, так как все тесты были проведены в одинаковых условиях и демонстрируют поведение библиотек в этих условиях. В связи с линейным ростом числа заданий в тесте по мере роста числа потоков, полное выполнение всех вариантов занимает приличное время. Для стабилизации результата было выполнено три прохода, так что представленные вам выше результаты есть усреднение между тремя запусками.По приведённым выше трехмерным графикам заметно, что диагональ (значения аргументов {p=c}) выглядит почти прямой линией, поэтому для наглядного сравнения трех библиотек мы сделали выборку результатов именно по этому критерию.
В связи с линейным ростом числа заданий в тесте по мере роста числа потоков, полное выполнение всех вариантов занимает приличное время. Для стабилизации результата было выполнено три прохода, так что представленные вам выше результаты есть усреднение между тремя запусками.По приведённым выше трехмерным графикам заметно, что диагональ (значения аргументов {p=c}) выглядит почти прямой линией, поэтому для наглядного сравнения трех библиотек мы сделали выборку результатов именно по этому критерию.
Слева показано то, что у нас получилось.
Видно, что boost проигрывает двум остальным реализациям, хотя и демонстрирует большую устойчивость к изменению входных параметров.
Реализации на libcds и SList отличаются не так значительно, но на всем протяжении входного интервала.
Выводы Необходимо признать, что в этот раз Майкрософт создало весьма неплохую реализацию (хотя и всего одного контейнера), которая может с успехом соревноваться с алгоритмами из известных библиотек. Несмотря на то, что описанная реализация не является кросс-платформенной, она может оказаться полезной разработчикам Windows приложений.Скачать архив с исходным кодом проекта Visual Studio можно здесь
Использованные материалы Картинка в начале статьиMSDN описание slistБиблиотека boost.lockfreeБиблиотека libcdsLock-free структуры данных. Эволюция стека
