LLTR Часть 2: Алгоритм определения топологии сети по собранной статистике

В предыдущих частях…
Q: Что у нас есть?
A: Статистика, собранная с хостов.
Q: Что мы хотим получить?
A: Топологию сети! Точнее, нужно построить правильную цепочку пиров (хостов) для RingSync.
Нам предстоит придумать алгоритм, который вначале превратит статистику в топологию сети, а затем — в цепочку пиров. Пока алгоритм выглядит так:
статистика –-[*магия*]--> топология сети --[*магия*]--> цепочка пиров
Если понравилось читать «Часть 1«на GitHub Pages, то вот ссылка на эту часть в GitHub Pages.
Warning: Ниже будут встречаться те же самые артефакты Хабра‑парсера, о которых я предупреждал в «Части 1».

Note: далее вместо »–-[*магия*]-->» я буду использовать »–-[???]-->».
Собранная статистика показывает нам, на каких хостах упала скорость получения broadcast трафика. Например, посмотрим на результат нулевой итерации в сети «N2_2» (»Network» из предыдущей статьи «LLTR Часть 1»):
{300,164,164},
Здесь четко видны 2 состояния хоста:
- нормальная скорость (значение »
300») — отсутствие реакции; - скорость упала (значение »
164») — есть реакция.
К чему я клоню? К бинаризации! Если мы закодируем отсутствие реакции как 0, а присутствие реакции как 1, то сможем поместить все реакции хостов, отдельно взятой итерации, в одну переменную (32 — 512 bit [AVX‑512]). Помимо экономии памяти (и места, занимаемого в кэшах), это увеличит скорость обработки — за одну инструкцию будут обрабатываться сразу все реакции хостов конкретной итерации (SIMD).
Note: т.к. использовать LLTR Basic для большого числа хостов весьма накладно (см. начало раздела «LLTR Часть 0:: LLTR Advanced»), то все поместится в 64 bit регистры x86‑64.
Note: В текст ссылки на раздел, расположенный в другой статье (другая часть), я буду добавлять номер части в формате:»LLTR Часть #:: ‹название раздела›». А в »title» ссылки буду записывать название части, например, для «LLTR Часть 0::» будет всплывать «Автоматическое определение топологии сети и неуправляемые коммутаторы. Миссия невыполнима?».
Возьмем тот же пример нулевой итерации, и посмотрим, как он будет выглядеть после бинаризации:
{300,164,164} --[бинаризация]--> 011
Весьма компактно, однако я бы хотел, чтобы »1» (присутствие реакции) сразу бросались в глаза при просмотре списка из всех итераций. Сейчас »1» не сильно выделяется на фоне »0» (фейковые данные, для визуального примера):
0101011010110
1100010110010
0101101010111
0100010110100
Чтобы выделить »1», я введу обозначения:
- »
1» означает 1 — есть реакция; - »
.» означает 0 — отсутствие реакции.
Посмотрим опять на «фейковые данные»:
.1.1.11.1.11.
11...1.11..1.
.1.11.1.1.111
.1...1.11.1..
Так значительно лучше (IMHO).
Алгоритм, на данный момент, выглядит так:
статистика –-[бинаризация]--> реакции хостов --[???]--> топология сети --[???]--> цепочка пиров
Оставим детали бинаризации для конца статьи, и сконцентрируемся на остальной части алгоритма.
Создавать алгоритм, проще всего, отталкиваясь от конкретных исходных/входных данных (частные случаи, граничные условия; тесты — в терминах TDD). В нашем случае исходные данные зависят от топологии сети, поэтому нужно придумать такую сеть, которая была бы одновременно небольшой, и в то же время содержала разные схемы соединения свитчей (звезда, последовательное соединение). Возможно, в нее удастся включить нечто особенное… В общем, воображение нарисовало такую сеть (обозначения элементов аналогичны обозначениям, используемым в конце раздела «LLTR Часть 0:: Топология: «последовательное соединение свитчей»):
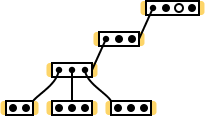
Note: смотря на эту сеть, вспоминается вопрос «а можно ли в данной топологии провести полноценное сканирование, если к одному из свитчей …» (ближе к концу раздела «LLTR Часть 0:: Топология: «последовательное соединение свитчей»), и замечаешь, что к одному из свитчей напрямую не подключен ни один хост. Причем в этом нет никаких проблем, т.к. к этому свитчу подключены еще 3 свитча (я считал только свитчи, подключенные «снизу», без учета того, что он подключен к еще одному свитчу «сверху»), у каждого из которых есть хосты.
Однако, в этой диаграмме присутствуют несколько лишних (отвлекающих) деталей. Я собираюсь ее подчистить, убрав:
- broadcast хост (он отсутствует во входных данных/статистике);
- порты, соединяющие свитчи между собой.

Здесь сразу виден свитч «без хостов». К тому же все свитчи я расположил таким образом, чтобы хосты в них не перекрывали друг друга по вертикали. Это будет полезно, если я в будущем захочу показать «реакции хостов» не в виде текстовой записи ».....1......», а в виде диаграммы (на одной вертикали находится только один хост):
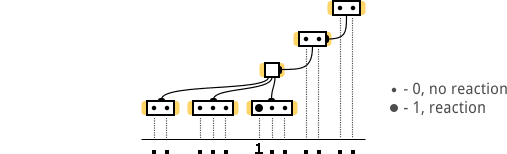
А теперь представьте статистику, которую мы получим, по завершению всех итераций сканирования этой сети. В сети 12 хостов (без учета broadcast хоста), следовательно, у нас будут данные по 132 итерациям. Однако не все результаты итераций нам пригодятся, например, будут бесполезны:
После очистки, из всех 132 результатов итераций, останется только 5 (реакции хостов):
1111111111..
11111111....
..111.......
.....111....
11..........
Note: для наглядности я расположил итерации в порядке от большего количества »1» к меньшему.
Алгоритм стал выглядеть так:
статистика –-[бинаризация]--> реакции хостов --[очистка от единичных реакций]--[очистка от дублей]--[???]--> топология сети --[???]--> цепочка пиров
Я размышлял над включением всего этого в спойлер, но в итоге понял, что это важная часть повествования, которую лучше не пропускать при чтении.
¬(Не пропускать в мозг при чтении :)
[reset point] В оставшихся 5 результатах итераций, внимание привлекают первые две: первая включает в себя вторую, а вторая включает оставшиеся 3 нижние. Здесь вспоминается «тень» из раздела «LLTR Часть 0:: Топология: «последовательное соединение свитчей». В том же разделе, по завершении каждой итерации мы формировали (или не формировали) новые кластеры на основе только что полученных данных. Сейчас нужно сделать то же самое.
Но как мы формировали новые кластеры? По сути все (не единичные) реакции »1» хостов текущей итерации и были «новым кластером», нам оставалось только найти пересечения (»∩»; не пустые »∅») с существующими кластерами, чтобы убрать (»∖») из большего кластера хосты, входящие в меньший кластер.
Однако, в наших действиях присутствовало условие/ветвление (if): нужно определить какой из кластеров больше, и уже затем совершить простую операцию (A∖B) — из большего кластера (A) вычесть меньший (B). Представляя мучения CPU с длинным конвейером, вызванные необходимостью сброса конвейера при неверном предсказании ветвления (если в нем вообще «блок предсказания ветвлений» присутствует), я почти решил использовать тернарный оператор "?:», но в этот момент…
Я стоял на унитазе и вешал часы. Вдруг поскользнулся, ударился головой о раковину, а когда очнулся мне было видение, картинка в моём мозгу, видение вот этого — потоковый накопитель потоковый разделитель (Назад в будущее):

// Flux Divider
c=a^b;
aa=a&c;
bb=b&c;
cc=a&b;
И сразу посмотрим его работу на примере перекрывающихся кластеров (точнее, одно множество (кластер) строго включено »⊊» в другое множество):
.....11..... - a
..11111111.. - b
..111..111.. - c=a^b
............ - aa=a&c
..111..111.. - bb=b&c
.....11..... - cc=a&b
Непересекающиеся кластеры:
..111....... - a
.......111.. - b
..111..111.. - c=a^b
..111....... - aa=a&c
.......111.. - bb=b&c
............ - cc=a&b
Получается, что:
- в »
aa» попадают элементы, уникальные для »a»; - в »
bb» — уникальные для »b»; - в »
cc» — общие для »a» и »b».
Еще один пример с пересекающимися кластерами («невозможный», но наглядный пример):
...1111..... - a
.....1111... - b
...11..11... - c=a^b
...11....... - aa=a&c
.......11... - bb=b&c
.....11..... - cc=a&b
Note: такой вариант отклика (реакции хостов) — отсутствует в исходных данных.
Этим же способом можно избавляться от дублей:
.....11..... - a
.....11..... - b
............ - c=a^b
............ - aa=a&c
............ - bb=b&c
.....11..... - cc=a&b
Но, чуть позже…
Голова перестает болеть после удара об раковину, разум проясняется, и всплывают очевидные проблемы…
На входе у нас 2 переменные (результаты итераций / реакции хостов / кластеры / множества / …), но на выходе их уже 3, причем хотя бы один из них будет пуст (»∅»). Если сразу не избавится от »∅», то их в дальнейшем придется включить в обработку. Поэтому лучше избавится от »∅» сразу. Но как это сделать? Использовать условие/ветвление! … В общем, я вернулся к тому, с чего начал. К тому же если все сделать, как было описано выше, плюс избавится от »∅», то в итоге мы получим из:
1111111111..
11111111....
..111.......
.....111....
11..........
Это:
........11..
- здесь должно было быть "............", но мы его стерли :(
..111.......
.....111....
11..........
Пора задаться вопросом: «Как из этого получить топологию сети?». Сейчас эти данные могут «сказать», о том, к какому кластеру принадлежит конкретный хост (т.е. к какому свитчу подключен хост), но в этих данных теперь полностью отсутствует информация о топологии свитчей (т.е. о том, как соединены свитчи между собой) — мы потеряли эту информацию в ходе преобразования данных. К тому же, к какому кластеру (свитчу) принадлежат 2 крайних справа хоста? Если рассматривать каждую строку как отдельный кластер (или как указание на то, какие хосты подключены к конкретному свитчу), то окажется, что эти 2 крайних хоста никуда не подключены! Более того, в сети у нас 6 свитчей, а строк осталось 4, где же еще 2 строки? Одну мы стерли (как гласит комментарий выше), а в другой как раз и должны были быть »2 крайних справа хоста».
[goto reset point] Дальше развивать эту идею бесполезно. Тупиковая ветвь (git branch). Придется откатиться назад к метке «reset point», забыв все, что было после нее, но оставив эту ветвь для истории.
Теперь же, чтобы не попасть в еще одну «мертвую ветвь», нужно определиться с итоговой структурой (представлением) топологии сети в памяти. То есть, с тем, что мы хотим получить к моменту «топология сети»:
статистика –-[бинаризация]--> реакции хостов --[очистка от единичных реакций]--[очистка от дублей]--[???]--> топология сети --[???]--> цепочка пиров
Во‑первых, должны присутствовать все хосты:
..........11 <--
1111111111..
11111111....
..111.......
.....111....
11..........
Во‑вторых, должны быть указаны родители (родительский кластер для каждого кластера; на данный момент: родитель ⊋ ребенок; на диаграмме сети, родителей я располагал выше детей) (слева добавлены номера кластеров):
0) ..........11 parent: ?
1) 1111111111.. parent: ?
2) 11111111.... parent: 1
3) ..111....... parent: 2
4) .....111.... parent: 2
5) 11.......... parent: 2
Note: если вы заметили здесь что‑то странное, сравнивая диаграмму этой сети с этими данными, то вам like от меня.
По сути (по диаграмме), родителем для кластера 1 является кластер 0, но тогда не выполняется условие »родитель ⊋ ребенок». Возможно в »Во‑первых» мы ошиблись, и вместо »..........11» стоило добавить »111111111111»?
В‑третьих, должен быть один «корневой» родитель, связывающий отдельные деревья (т.е. лес) в одно дерево:
-1) 111111111111
0) ..........11 parent:-1
1) 1111111111.. parent:-1
2) 11111111.... parent: 1
3) ..111....... parent: 2
4) .....111.... parent: 2
5) 11.......... parent: 2
В‑четвертых, неплохо было бы иметь списки детей у каждого родителя:
-1) 111111111111 children: 0,1
0) ..........11 parent:-1
1) 1111111111.. parent:-1, children: 2
2) 11111111.... parent: 1, children: 3,4,5
3) ..111....... parent: 2
4) .....111.... parent: 2
5) 11.......... parent: 2
И наконец, именно теперь можно исключить детей из родителей:
-1) ............ children: 0,1
0) ..........11 parent:-1
1) ........11.. parent:-1, children: 2
2) ............ parent: 1, children: 3,4,5
3) ..111....... parent: 2
4) .....111.... parent: 2
5) 11.......... parent: 2
Теперь каждая строка описывает один кластер, т.е. указывает на хосты, подключенные к одному и тому же свитчу. Однако, постойте, в нашей сети 6 свитчей, а кластеров получилось 7 ! Пора, наконец, прочитать текст из спойлера выше »Спойлер, лучше не открывать до прочтения всего списка», и исправить ситуацию:
0) ..........11 children: 1
1) ........11.. parent: 0, children: 2
2) ............ parent: 1, children: 3,4,5
3) ..111....... parent: 2
4) .....111.... parent: 2
5) 11.......... parent: 2
Эти данные как раз и являются «топологией сети» — они описывают дерево свитчей, и по ним можно определить все хосты, подключенные к конкретному свитчу.
статистика –-[бинаризация]--> реакции хостов --[очистка от единичных реакций]--[очистка от дублей]--[???]--> топология сети --[???]--> цепочка пиров
Осталось понять, как привести данные к такому виду. По сути, все, что мы сделали (во‑первых, во‑вторых, …) можно преобразовать в алгоритм:
- «во‑первых» (после внесения исправлений из спойлера становится аналогичен действию «в‑третьих») — добавить «корневой» кластер »
111111111111» (универсум), включающий (хосты всех деревьев в лесу ∪ хосты, находящиеся на одном свитче с broadcast хостом), т.е. он включает в себя все хосты сети; - «во‑вторых» — поиск родителя для каждого кластера;
- «в‑четвертых» — построение списка детей для каждого родителя;
- «и наконец» — исключение детей из родителей.
Теперь можно внести эти действия в общий алгоритм (немного изменил вид):
● статистика ●
[бинаризация] ► реакции хостов
[очистка от единичных реакций]
[очистка от дублей] ► кластеры/лес
[добавить "корневой" кластер] ► кластеры/дерево
[поиск родителя для каждого кластера]
[построение списка детей для каждого родителя]
[исключение детей из родителей] ► топология сети ●
[???] ► цепочка пиров ●
● статистика ► [бинаризация]
▬ реакции хостов ► [очистка от единичных реакций]
[очистка от дублей]
▬ кластеры/лес ► [добавить "корневой" кластер]
▬ кластеры/дерево ► [поиск родителя для каждого кластера]
[построение списка детей для каждого родителя]
[исключение детей из родителей]
● топология сети ► [???]
● цепочка пиров ●
Посмотрим, что произойдет, если применить этот алгоритм к другой сети. Я бы хотел взять сеть »Network_serial» и ее результаты симуляции (статистику) из раздела «LLTR Часть 1:: Больше сетей с разными топологиями, добавляем новые сети».
Note: Почему я выбрал именно эту сеть? Она достаточно большая, и в собранных с нее данных присутствуют недочеты (см. конец спойлера «Результаты симуляции» для этой сети).
Поехали!
Реакции хостов:
.111111..
.111111..
.111111..
.111111..
.111111..
.111111..
.......11
.......11
..1......
...1111..
...1111..
...1111..
...1111..
.......11
.......11
1........
...1111..
...1111..
...1111..
...1111..
.......11
.......11
1........
.1.......
....1....
.....11..
.....11..
.......11
.......11
1........
.1.......
..1......
.....11..
.....11..
.......11
.......11
1........
.1.......
..1......
...1.....
......1..
.........
.........
.........
.1.......
..1......
...1.....
....1....
.........
.........
.........
.1.......
..1......
...1.....
....1....
.....1...
........1
1........
.111111..
.111111..
.111111..
.111111..
.111111..
.111111..
1........
.111111..
.111111..
.111111..
.111111..
.111111..
.111111..
.......1.
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.......11 --> .......11
.......11 --> .......11
..1...... -->
...1111.. --> ...1111..
...1111.. --> ...1111..
...1111.. --> ...1111..
...1111.. --> ...1111..
.......11 --> .......11
.......11 --> .......11
1........ -->
...1111.. --> ...1111..
...1111.. --> ...1111..
...1111.. --> ...1111..
...1111.. --> ...1111..
.......11 --> .......11
.......11 --> .......11
1........ -->
.1....... -->
....1.... -->
.....11.. --> .....11..
.....11.. --> .....11..
.......11 --> .......11
.......11 --> .......11
1........ -->
.1....... -->
..1...... -->
.....11.. --> .....11..
.....11.. --> .....11..
.......11 --> .......11
.......11 --> .......11
1........ -->
.1....... -->
..1...... -->
...1..... -->
......1.. -->
......... --> .........
......... --> .........
......... --> .........
.1....... -->
..1...... -->
...1..... -->
....1.... -->
......... --> .........
......... --> .........
......... --> .........
.1....... -->
..1...... -->
...1..... -->
....1.... -->
.....1... -->
........1 -->
1........ -->
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
1........ -->
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.111111.. --> .111111..
.......1. -->
Очистка от дублей (получаем «кластеры/лес»):
.111111..
.......11
...1111..
.....11..
.........
Дополнительно, для удобства, отсортирую по убыванию количества »1»:
.111111..
...1111..
.....11..
.......11
.........
Note: Возможно стоит включить сортировку в алгоритм. Как думаете?
Добавление «корневого» кластера (получаем «кластеры/дерево»):
111111111
.111111..
...1111..
.....11..
.......11
.........
В него вошли хосты 2‑х деревьев (левая ».111111..» и правая ».......11» часть сети) и 1 хост (»1........», расположенный на одном свитче с broadcast хостом).
Поиск родителя для каждого кластера:
0) 111111111
1) .111111.. parent: 0
2) ...1111.. parent: 1
3) .....11.. parent: 2
4) .......11 parent: 0
5) ......... parent: 4
Note: Вот здесь как раз и проявилось негативное влияние недочетов в данных — 4‑й кластер стал родителем для 5‑го! Вообще, родителем 5‑го кластера может стать любой кластер, т.к. он пуст (∅).
Построение списка детей для каждого родителя:
0) 111111111 children: 1,4
1) .111111.. parent: 0, children: 2
2) ...1111.. parent: 1, children: 3
3) .....11.. parent: 2
4) .......11 parent: 0, children: 5
5) ......... parent: 4
Исключение детей из родителей:
0) 1........ children: 1,4
1) .11...... parent: 0, children: 2
2) ...11.... parent: 1, children: 3
3) .....11.. parent: 2
4) .......11 parent: 0, children: 5
5) ......... parent: 4
На этом шаге мы должны были получить «топологию сети». И мы ее получили. Если нам интересно только местоположение хостов, то такая «топологию сети» нас вполне устраивает. Однако, в нашей сети появился еще один свитч, в котором 0 хостов!
Чтобы все исправить, достаточно будет после одного из первых шагов исключить эти «недочеты в данных». Это можно сделать сразу же после «бинаризации»:
● статистика ●
[бинаризация] ► реакции хостов
[очистка от пустоты (∅), и от универсумов (⦱)]
[очистка от единичных реакций]
[очистка от дублей] ► кластеры/лес
[добавить "корневой" кластер] ► кластеры/дерево
[поиск родителя для каждого кластера]
[построение списка детей для каждого родителя]
[исключение детей из родителей] ► топология сети ●
[???] ► цепочка пиров ●
Мы удаляем пустые множества (∅;».........»), но зачем удалять универсумы (⦱;»111111111»)? Ответ станет очевидным, когда мы начнем реализовывать этап «бинаризации». Разные варианты реализации «бинаризации» могут на одних и тех же данных (данных с описанным недочетом) выдать как ».........», так и »111111111». И, т.к. получить в корректных входных данных »111111111» на столько же невозможно, как и получить ».........», то мы можем удалить все »111111111» (к тому же они не несут никакой информации, кроме той, что в данных присутствуют «недочеты»).
Если применить этот (дополненный, исправленный) алгоритм к этой же сети (»Network_serial»), то «топология сети» станет выглядеть так:
0) 1........ children: 1,4
1) .11...... parent: 0, children: 2
2) ...11.... parent: 1, children: 3
3) .....11.. parent: 2
4) .......11 parent: 0
Note: Красиво, получилась диагональ. Напоминает единичную матрицу, но ее в чистом виде получить не удастся. Можно сделать, чтобы в каждом кластере было по 2 хоста (для этого нужно добавить один хост в «switch0»), но мы не сможем получить в каждых кластерах только 1 хост (в крайних кластерах всегда будут как минимум 2 хоста):
0) 11........ children: 1,4
1) ..11...... parent: 0, children: 2
2) ....11.... parent: 1, children: 3
3) ......11.. parent: 2
4) ........11 parent: 0
0) 1...... children: 1,4
1) .1..... parent: 0, children: 2
2) ..1.... parent: 1, children: 3
3) ...11.. parent: 2
4) .....11 parent: 0
Мы смогли дописать алгоритм до получения корректной «топологии сети». Осталось построить «цепочку пиров» из «топологии сети». В статье про RingSync я уже описывал, как это сделать (обход дерева в глубину: Pre‑order). В итоге «цепочка пиров» должна получиться такой:
1 1........ hostS/seed -> host0 ->
. .11...... host1 -> host2 ->
. ...11.... host3 -> host4 ->
. .....11.. host5 -> host6 ->
. .......11 host7 -> host8/leech
Note: в первую строчку (левый, отделенный столбец) добавлен сид, он же broadcast хост.
Кажется, что ничего не изменилось по сравнению с порядком кластеров в «топологии сети» (все та же диагональ), и это действительно так для этой сети (»Network_serial»). Чуть ниже я проделаю то же самое с нашей предыдущей сетью (которой я так и не дал название), возможно на ней будут видны изменения. А пока я покажу путь движения трафика для построенной цепочки:

Как и обещал, делаю то же самое для «предыдущей сети» («цепочка пиров»):
..........11 1 hS/seed -> h10 -> h11 ->
........11.. . h8 -> h9 ->
..111....... . h2 -> h3 -> h4 ->
.....111.... . h5 -> h6 -> h7 ->
11.......... . h0 -> h1/leech
Изменений (по сравнению с расположением кластеров в «топологии сети») практически нет. Единственное, что изменилось — это исчез кластер 2, т.к. он был пуст (∅). Означает ли это, что «обход дерева в глубину» не нужен, и достаточно взять кластеры из «топологии сети» (в том же порядке, в котором они будут на этот момент), и удалить все пустые (∅) кластеры? Однако, это не так: во‑первых, чтобы кластеры выстроились в таком «удобном» порядке я использовал сортировку, но она до сих пор не была включена в алгоритм (надо бы включить, но пока еще рано ;); во‑вторых, не для всех сетей этот трюк сработает (попробуйте придумать такую сеть без заглядывания в спойлер).

Я попробовал применить алгоритм (вместе с сортировкой) к этой сети, и, на момент получения «топологии сети», расположение кластеров стало сильно что‑то напоминать…
Ладно, вернемся к построенной «цепочке пиров», и посмотрим на путь движения трафика…
Note: Здесь должна была быть картинка, но изображение пути движения трафика на такой маленькой диаграмме, стало напоминать спагетти. Не рекомендую смотреть на это.
Я даже изменил последовательность соединения пиров, подключенных к одному свитчу (их все равно можно соединять в любой последовательности), но и это не помогло.

Цепочка пиров:
..........11 1 hS/seed -> h11 -> h10 ->
........11.. . h9 -> h8 ->
..111....... . h2 -> h3 -> h4 ->
.....111.... . h5 -> h6 -> h7 ->
11.......... . h0 -> h1/leech
В этот момент мне захотелось опять взглянуть на путь движения трафика в »Network_serial»…
Теперь я обратил внимание, на то в какой последовательности трафик проходит через свитчи:
switch0 -> switch1 -> switch2 -> switch3 -┐
switch4 <- switch0 <- switch1 <- switch2 <-----------┘
… и мне очень не понравился «крюк» через »switch0 <- switch1 <- switch2». Хотелось получить на выходе алгоритма такую последовательность:
switch0 -> switch4 -┐
switch3 <- switch2 <- switch1 <- switch0 <-----------┘
Путь движения трафика для нее:
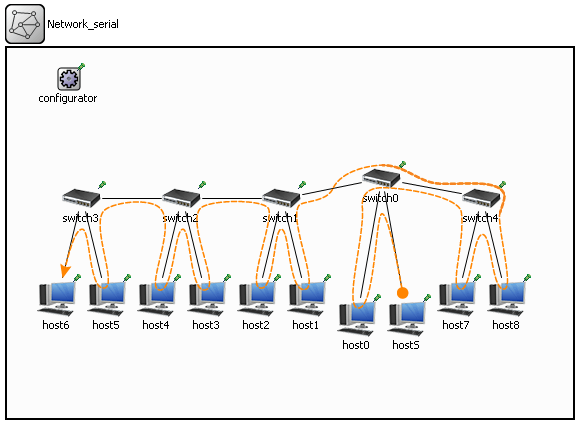
Путь стал короче, и, главное, нагрузка на сеть уменьшилась!
Note: , но меня все же больше привлекает уменьшение количества промежуточных сетевых узлов, т.е. «путь стал короче».
Note: имеется ввиду именно «количество промежуточных сетевых узлов», а не «суммарная длина канала» (длина сетевого кабеля; длина пути прохождения сигнала на физическом уровне — L0) — она вполне могла и увеличится.
Чтобы этого добиться, достаточно добавить в «обход дерева в глубину» небольшую эвристику.
Note: эту эвристику я изначально создавал для другой цели, но у нее оказался очень полезный побочный эффект — уменьшение количества промежуточных сетевых узлов.
Эвристика (правило): при «входе в поддерево» (LLTR Часть 0:: Топология: «звезда из свитчей») отдавать приоритет узлам с меньшей вложенностью:
- узел — хост;
- узел — один свитч;
- узел — два свитча (соединенных последовательно);
- узел — много свитчей (соединенных как угодно) — чем больше, тем ниже приоритет.
Note: если в тексте этого списка заменить »узел –» на »порт свитча, к которому подключен», то, возможно, он станет понятнее.
Note: Изначальная цель этих правил — вначале пустить трафик через ближайшие хосты (хосты до которых меньше всего промежуточных устройств). Меньше промежуточных устройств — меньше вероятность возникновения ошибки (при передаче данных) в самом начале пути. Сравните две дорожные ситуации, приводящие к временной пробке (одна полоса): затор случился в начале дороги (буферная зона практически отсутствует); затор случился ближе к концу дороги (размер буферной зоны достаточен для смягчения последствий затора).
Обновим алгоритм:
● статистика ●
[бинаризация] ► реакции хостов
[очистка от пустоты (∅), и от универсумов (⦱)]
[очистка от единичных реакций]
[очистка от дублей] ► кластеры/лес
[добавить "корневой" кластер] ► кластеры/дерево
[поиск родителя для каждого кластера]
[построение списка детей для каждого родителя]
[исключение детей из родителей] ► топология сети ●
[обход дерева в глубину с учетом приоритетов/весов] ► цепочка пиров ●
И обновленная «цепочка пиров» для »Network_serial» сети станет выглядеть так:
1 1........ hostS/seed -> host0 ->
. .......11 host7 -> host8 ->
. .11...... host1 -> host2 ->
. ...11.... host3 -> host4 ->
. .....11.. host5 -> host6/leech
Что полностью соответствует измененному «пути движения трафика», который изображен выше.
А вот на «прежнюю сеть» обновление алгоритма никак не повлияло. «Цепочка пиров» осталась прежней:
s0) ..........11 1 hS/seed -> h10 -> h11 ->
s1) ........11.. . h8 -> h9 ->
s3) ..111....... . h2 -> h3 -> h4 ->
s4) .....111.... . h5 -> h6 -> h7 ->
s5) 11.......... . h0 -> h1/leech
Почему не изменилось? Обновление алгоритма влияет на последовательность свитчей, однако, в этой сети, последовательность уже была оптимальной (обновление алгоритма не смогло ни улучшить и ни ухудшить ее):
s0 -> s1 -> s2 -> s3 -┐
┌- s4 <- s2 <------┘
└------> s2 -> s5
Note: номер свитча »s#» соответствует номеру кластера в «топологии сети» для этой сети (см. выше).
# TL; DR
Алгоритм определения топологии сети и построения цепочки пиров по собранной статистике:
- Бинаризация (~~ k‑medoids ~~) + очистка от пустоты (∅), и от универсумов (⦱) + очистка от единичных реакций:
- середина между
aminиamax - разделить на 2 части посередине
- + очистка от пустоты (∅), и от универсумов (⦱)
- найти медиану массива левой и правой части:
- (Мой любимый алгоритм: нахождение медианы за линейное время)
- (Сортировка на односвязном списке за O (nlogn) времени в худшем случае с O (1) дополнительной памяти)
- (nth_element implementations complexities)
- найти середину между
amedL(medLow) иamedR(medHi) - разделить на 2 части по новой середине, и сразу представить в двоичном виде
- + очистка от единичных реакций
- середина между
- Дедупликация + добавление «корневого» кластера:
- + добавить «корневой» кластер
- + отсортировать по
bitCount(от max к min) - убрать дубликаты
- Поиск родителя для каждого кластера:
- начиная с min элемента искать снизу (min) вверх (max) тот (первый попавшийся) элемент, куда входит текущий;
искать при помощи проверкиbitCount(ai)==bitCount(ai|amin), либо более простая проверка:ai==ai|amin - предыдущий шаг выполнять рекурсивно, попутно фиксировать цепочку элементов (путь рекурсии) — к текущему элементу добавлять идентификатор следующего элемента
- найти следующий min элемент (не участвующий в цепочке) и повторить рекурсию
- начиная с min элемента искать снизу (min) вверх (max) тот (первый попавшийся) элемент, куда входит текущий;
- Построение списка (карты) детей для каждого родителя:
- создать обратную цепочку (от «родителей» к «потомкам»)
- Исключение детей из родителей:
- когда все элементы будут в «цепочке», то начиная с max элемента, сделать or|=ai над его потомками, и применить
amax&=~or
(либо »amax^=or» — при корректных данных результат совпадет) - рекурсивно повторить с потомками потомков
(либо просто двигаемся отamaxдоamin, т.к. это дерево, и его вершины отсортированы в массиве)
- когда все элементы будут в «цепочке», то начиная с max элемента, сделать or|=ai над его потомками, и применить
- Обход дерева в глубину с учетом приоритетов/весов:
- построить маршрут для трафика (RingSync)
Note: примерно в таком виде я записал алгоритм ![]() , перед его реализации в коде.
, перед его реализации в коде.
Гипотеза. Чем умнее программист (чем более объёмной рабочей памятью он располагает), тем более длинные методы и функции он пишет.
Из «Горе от ума, или Почему отличники пишут непонятный код»
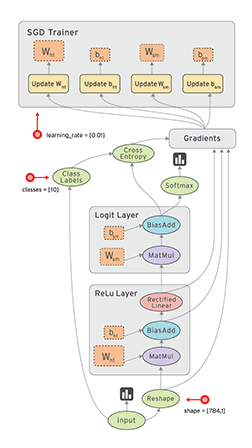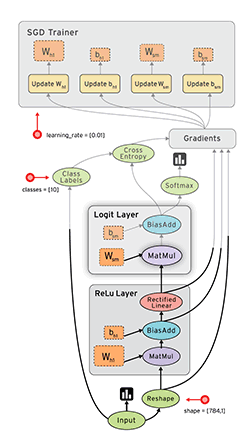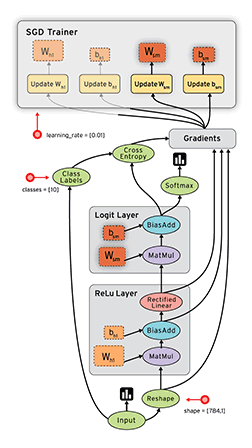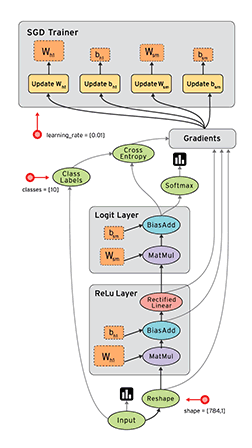
Я не настолько умный, чтобы создавать такие большие функции с таким большим количеством переменных, поэтому я использую области видимости (»{…}») для структурирования (упрощения) кода. Получается аналог вложенных анонимных функций (пример):
// вначале перечислены переменные "возвращаемые из функции"
int ...;{
// а здесь тело "функции"
}
Если надо дать название «функции», то оно записывается в комментарии перед блоком (пример):
//==[Name]==//
int ...;{
...
}
Если такой код визуализировать, то получится подобная диаграмма:
НЛОприлетелоиоставилоэтотпробелздесь? TensorsFlowing
т.е. каждая область видимости — это отдельный блок на диаграмме, а «переменные, возвращаемые из функции» — связи между блоками.
Что дает такой подход к структурированию?
Это дает:
- Свободу перемещения частей кода — я могу (если это потребуется) быстро перенести часть кода из одного блока в другой блок, реорганизуя тем самым последовательность действий. Мне не нужно заботиться о передаваемых в «функцию» параметрах, т.к. любая «функция» уже «видит» все переменные из внешних областей видимости. Также, если для оптимального выполнения кода нужно будет сделать «нечто странное», то это можно будет сделать.
- Все в одном месте — не нужно «прыгать» по множеству функций / файлов в проекте, чтобы понять, что конкретно делает этот код. Достаточно прочесть его последовательно от начала до конца. Это похоже на чтение дизассемблированной программы, при сборке которой линкер (Interprocedural optimization, Whole program optimization; Link‑time optimization) большинство функций «заинлайнил» — это очень упрощает чтение.
Note: Мой ответ на тему статьи из которой была взята цитата: т.к. еще до создания своих программ они успели поработать с множеством ресурсоемких приложений (2D/3D графические редакторы, рендеры, другие приложения для моделирования *, …). И им со временем начали надоедать лаги (задержки), возникающие при редактировании проекта, а также тот факт, что финальный просчет может занимать несколько жарких летних дней (в течение которых компьютер, расположенный в спальне, работает 24 часа, и мешает заснуть; это происходило во времена, когда ACPI только появился), в процессе одного из которых взрываются (выстреливают оболочкой) конденсаторы на материнской плате, что явно не добавляет им дофамина :(. Дальше они знакомятся с тонкостями разгона (тайминги, системы фазового перехода, …) и тюнинга операционной системы, чтобы хоть как‑нибудь подправить ситуацию подручными средствами. И наконец, они встречают первое в своей жизни демо, и узнают про демо‑сцену. Уровень их дофамина повышается (они словно видят лучик «нитро» в мире «тормозов»), и просят родителей купить первую в их жизни книгу «по программированию на *». В общем, они — это те люди, которые сами используют то, что создают, и хотят максимально утилизировать доступные ресурсы. А также у них есть нечеткое разделение (правило)&nb
