Лишние элементы или как мы балансируем между серверами
Привет, Хабр! Какое-то время назад люди осознали, что увеличивать мощность сервера в соответствии с ростом нагрузки просто невозможно. Тогда-то мы и узнали слово «кластер». Но как бы красиво это слово не звучало, всё равно приходится технически объединять разрозненные серверы в единое целое — тот самый кластер. По городам и весям мы добрались до наших узлов в моём предыдущем опусе. А сегодня мой рассказ пойдёт о том, как делят нагрузку между членами кластера системные интеграторы, и как это сделали мы.
Внутри публикации вас также ждёт бонус в виде трёх сертификатов на месячную подписку ivi+.
Делай как всеКакие задачи ставят для кластера?1. Много трафика2. Высокая надёжность03d63a0996fbКак этого добиться? Самый простой способ поделить нагрузку между серверами — не делить её. Вернее так: дадим полный список серверов — пусть клиенты сами разбираются. Как? Да просто прописав все IP-адреса серверов в DNS для заданного имени. Древняя и знаменитейшая балансировка round-robin DNS. И в целом неплохо работает, пока не возникает потребность добавить узел — я уже писал про инертность DNS-кэшей. Выглядит DNS-балансировка так:
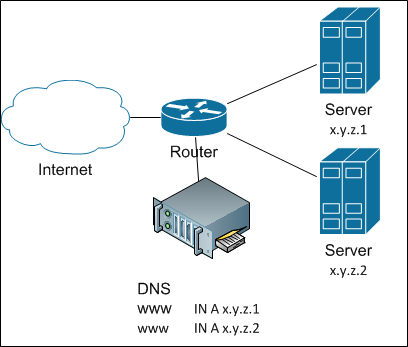 А если надо убрать сервер из кластера (ну, сломался он), наступает каюк. Чтобы каюк на нас не наступил, надо куда-то быстро повесить IP сломавшегося сервера. Куда? Ну, допустим, на соседа. Окей, а как мы это можем автоматизировать? Для этого придумана куча протоколов вроде VRRP, CARP со своими достоинствами и недостатками.Первое, во что обычно упираются, это ARP-кэш на роутере, который не хочет понимать, что IP-адрес переехал на другой MAC. Впрочем, современные реализации либо «пингуют» роутер с нового MAC’а (обновляя кэш таким образом), либо вообще используют виртуальный MAC, который не меняется во время работы.
А если надо убрать сервер из кластера (ну, сломался он), наступает каюк. Чтобы каюк на нас не наступил, надо куда-то быстро повесить IP сломавшегося сервера. Куда? Ну, допустим, на соседа. Окей, а как мы это можем автоматизировать? Для этого придумана куча протоколов вроде VRRP, CARP со своими достоинствами и недостатками.Первое, во что обычно упираются, это ARP-кэш на роутере, который не хочет понимать, что IP-адрес переехал на другой MAC. Впрочем, современные реализации либо «пингуют» роутер с нового MAC’а (обновляя кэш таким образом), либо вообще используют виртуальный MAC, который не меняется во время работы.
Второе, что бьёт по голове — это серверные ресурсы. Мы ведь не будем держать один сервер из двух в горячем standby? Сервер должен работать! Поэтому мы будет резервировать по VRRP два адреса на каждом сервере: один — primary и один backup. Если один из серверов пары сломается, второй примет на себя всю его нагрузку… может быть… если справится. И вот такая «парность» и будет главным недостатком, ибо не всегда есть возможность или целесообразность держать двойной запас серверной мощности.
Также нельзя не заметить, что каждый сервер требует своего собственного, глобально маршрутизируемого IP-адреса. В наше нелёгкое время это может стать большой проблемой.
В целом, мне скорее не нравится такой способ балансировки и резервирования, но для целого ряда задач и объёмов трафика он хорош. Прост. Не требует дополнительного оборудования — всё делается серверным софтом.
На шару Продолжая перечисление простых решений, а может, стоит просто навесить один и тот же IP-адрес на несколько серверов? Ну, в IPv6 есть возможность сделать anycast в одном домене (и то балансировка там будет только для хостов внутри него, а для внешних — совсем не так), а вот в IPv4 такая штука просто создаст ARP-конфликт (более известный как конфликт адресов). Но это если «в лоб».А если использовать небольшой наворот под кодовым названием «shared address» (разделяемый адрес), то такое возможно. Суть трюка заключается в том, чтобы сначала превратить входящий уникаст в броадкаст (ладно, если кто хочет — пусть делает мультикаст), а затем только один из серверов отвечает на пакеты от данного клиента. Как осуществляется превращение? Очень просто: все серверы кластера в ответ на ARP-запрос возвращают один и тот же MAC: либо несуществующий на сети, либо мультикастовый. После этого сеть сама размножит входящие пакеты на все члены кластера. А как серверы договариваются о том, кто отвечает? Для простоты скажем так: по остатку от деления srcIP на количество серверов в кластере. Дальше — дело техники.
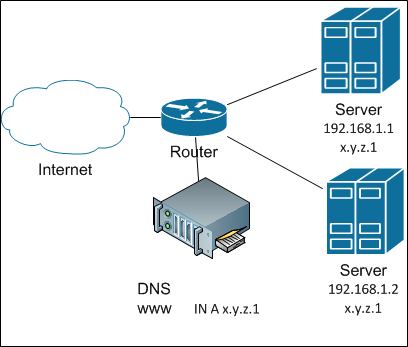 Балансировка с разделяемым адресомТакую технику реализуют разные модули и разные протоколы. Для FreeBSD такая возможность реализована в CARP. Для Linux в прошлой жизни мне доводилось использовать ClusterIP. Сейчас он, видимо, не развивается. Но я уверен, что есть и другие реализации. Для Windows такая штука есть во встроенных средствах кластеризации. В общем, выбор есть.
Балансировка с разделяемым адресомТакую технику реализуют разные модули и разные протоколы. Для FreeBSD такая возможность реализована в CARP. Для Linux в прошлой жизни мне доводилось использовать ClusterIP. Сейчас он, видимо, не развивается. Но я уверен, что есть и другие реализации. Для Windows такая штука есть во встроенных средствах кластеризации. В общем, выбор есть.
Преимуществом такой балансировки всё так же является чисто серверная реализация: никакой особой настройки со стороны сети не требуется. Публичный адрес используется всего один. Добавление или отключение одного сервера в кластере происходит быстро.
В недостатках же, во-первых, числится необходимость дополнительной проверки на уровне приложения, а во-вторых (и даже «в главных») — это ограничение по входящей полосе: количество входящего трафика не может превышать полосу в физическом подключении серверов. И это очевидно: ведь входящий трафик попадает на все серверы одновременно.
Так что в целом это неплохой способ балансировать трафик, если у вас немного входящего трафика, но употреблять его следует с умом. И тут я скромно скажу, что сейчас мы этот метод не используем. Как раз из-за проблемы входящего трафика.
Никогда не заговаривайте с интеграторами Мне почему-то кажется, что задача балансировки между серверами должна быть типовой. А для типовой задачи должны быть типовые решения. А кто хорошо продаёт типовые решения? Интеграторы! И мы спросили…Надо ли говорить, что нам предложили решения из вагонов самого разного оборудования? От Cisco ACE и до всяческих F5 BigIP LTM. Дорого. Но хорошо ли? Ладно, есть ещё прекрасный бесплатный софтовый L7-балансировщик haproxy.
В чём же смысл этих штучек? Смысл в том, что балансировку они делают на уровне приложения — Layer 7. Фактически, такие балансировщики являются полными прокси (full proxy): они устанавливают соединение с клиентом и с сервером от своего имени. В теории это хорошо тем, что они могут осуществлять прилипание клиента к определённому серверу (server affinity) и даже выбирать бэкэнд в зависимости от запрошенного контента (крайне полезная штука для такого ресурса как ivi.ru). А при определённой настройке — и фильтровать запросы по URL, защищаясь от различного рода атак. Главное же преимущество — такие балансировщики могут определять жизнеспособность каждого узла в кластере самостоятельно.
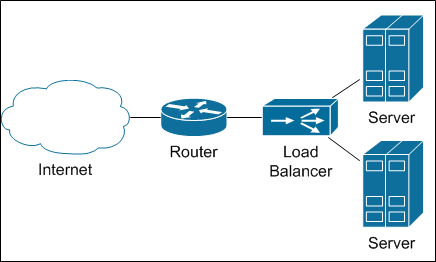 Балансировщики включаются в сеть как-то такПризнаюсь, мой прошлый опыт кричал «Без балансировщиков сделать ничего не возможно». Мы посчитали… И ужаснулись.
Балансировщики включаются в сеть как-то такПризнаюсь, мой прошлый опыт кричал «Без балансировщиков сделать ничего не возможно». Мы посчитали… И ужаснулись.
Самые производительные балансировщики, которые нам предложили, имели пропускную способность 10Гбит/с. По нашим меркам не смешно (серверы с тяжелым контентом у нас подключаются 2×10Гбит/с). Соответственно, чтобы получить нужную полосу, надо было бы набить целую стойку такими балансировщиками, с учётом резервирования. Посмотрите вот на эту схему:
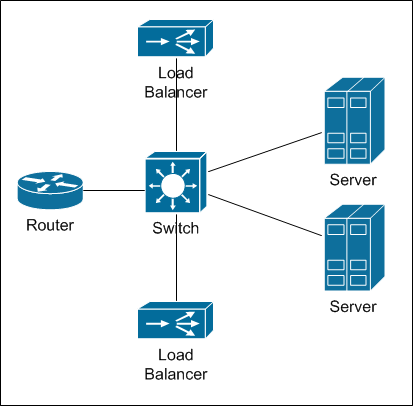 Так выглядит физическое подключение балансировщика.Конечно, есть ещё режим частичного прокси (half-proxy), когда через балансировщик проходит только половина трафика: от клиента к серверу, а обратно от сервера — идёт напрямую. Но такой режим отключает L7 функциональность, и балансировщик становится L3-L4, что резко снижает его ценность. А дальше последовательно возникает две проблемы: сначала нужно сделать достаточную мощности сети (в первую очередь — по портам, потом — по надёжности). Затем возникает вопрос:, а как балансировать нагрузку между балансировщиками? В Москве поставить стойку с оборудованием для балансировки, в теории, наверно, можно. А вот в регионах, где наши узлы минималистичны (серверы да циска) добавление нескольких балансировщиков уже как-то не смешно. К тому же, чем длиннее цепочка, тем ниже надёжность. А оно нам надо?
Так выглядит физическое подключение балансировщика.Конечно, есть ещё режим частичного прокси (half-proxy), когда через балансировщик проходит только половина трафика: от клиента к серверу, а обратно от сервера — идёт напрямую. Но такой режим отключает L7 функциональность, и балансировщик становится L3-L4, что резко снижает его ценность. А дальше последовательно возникает две проблемы: сначала нужно сделать достаточную мощности сети (в первую очередь — по портам, потом — по надёжности). Затем возникает вопрос:, а как балансировать нагрузку между балансировщиками? В Москве поставить стойку с оборудованием для балансировки, в теории, наверно, можно. А вот в регионах, где наши узлы минималистичны (серверы да циска) добавление нескольких балансировщиков уже как-то не смешно. К тому же, чем длиннее цепочка, тем ниже надёжность. А оно нам надо?
ECMP или ничего лишнего Решение нагуглилось почти случайно. Оказывается, современный роутер сам по себе умеет балансировать трафик. Если подумать, это разумно: ведь одна и та же подсеть может быть доступна через разные каналы с одинаковым качеством. Такая функция называется ECMP — Equal Cost Multiple Paths. Видя одинаковые по своей метрике (в общем смысле этого слова) маршруты, роутер просто делит пакеты между этими маршрутами.ОК, идея интересная, но будет ли это работать? Тестовый запуск мы провели, прописывая статические маршруты с роутера в сторону нескольких серверов. Концепт оказался работоспособным, но потребовалась дополнительная проработка.
Во-первых, необходимо обеспечить попадание всех IP-пакетов, относящихся к одной TCP-сессии на один и тот же сервер. Ведь иначе TCP-сессия просто не состоится. Это так называемый режим «per-flow» (или «per-destination»), и он вроде как включен по умолчанию на роутерах Cisco.
Во-вторых, статические маршруты не подходят — ведь нам надо иметь возможность автоматически убирать сломанный сервер из кластера. Т.е. надо применять какой-либо протокол динамической маршрутизации. Для единообразия мы выбрали BGP. На серверах установлен программный роутер (сейчас это quagga, но в ближайшем будущем перейдём на BIRD), который анонсирует «серверную» сеть на роутер. Как только сервер перестаёт слать анонсы, роутер перестаёт распределять трафик. Соответственно, для балансировки на роутере настроено значение maximum-paths ibgp равное количеству серверов в кластере (с некоторыми оговорками):
router bgp 57629 address-family ipv4 maximum-paths ibgp 24 Но сам BGP гарантирует только сетевую доступность сервера, но не прикладную. Чтобы проверять работоспособность прикладного софта, на сервере запущен скрипт, который осуществляет ряд проверок, и если что-то пошло не так, просто гасит BGP. Дальше дело роутера — перестать слать пакеты на этот сервер.В третьих, была замечена неоднородность распределения запросов между серверами. Небольшая, и компенсируемая нашим ПО кластеризации, Но хотелось-то равномерности. Выяснилось, что по умолчанию роутер балансирует пакеты исходя из адресов отправителя и получателя пакета, то есть L3-балансировка. Исходя из того, что адрес получателя (сервера) всегда один и тот же, это указывает на неоднородность в адресах-источниках. Учитывая массовую NAT’изацию интернета, это неудивительно. Решение оказалось простым — заставить роутер учитывать порты получателя и источника (L4-балансировка) при помощи команды вроде
platform ip cef load-sharing full
или ip cef load-sharing algorithm include-ports source destination
в зависимости от IOS. Главное только, чтобы у вас не было такой команды:
ip load-sharing per-packet
Итоговая схема выглядит вот так: 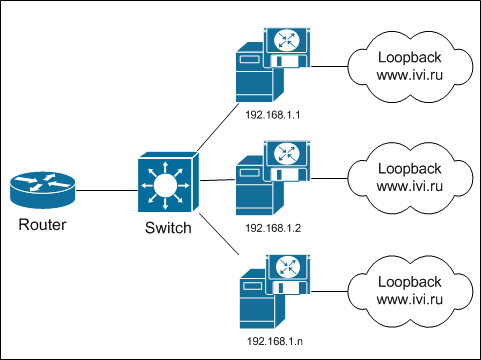 Ничего знакомого не заметили? Ну там, что это фактически anycast, только не между регионами, а внутри одного узла? Так это он и есть! Преимуществами L3-L4 балансировки можно назвать эффективность: роутер должен быть, без него никак. Надёжность тоже на должном уровне — если вдруг сломается роутер, то дальше уже неважно. Дополнительное оборудование не приобретается — это хорошо. Публичные адреса тоже не расходуются — один и тот же IP обслуживается сразу несколькими серверами.
Ничего знакомого не заметили? Ну там, что это фактически anycast, только не между регионами, а внутри одного узла? Так это он и есть! Преимуществами L3-L4 балансировки можно назвать эффективность: роутер должен быть, без него никак. Надёжность тоже на должном уровне — если вдруг сломается роутер, то дальше уже неважно. Дополнительное оборудование не приобретается — это хорошо. Публичные адреса тоже не расходуются — один и тот же IP обслуживается сразу несколькими серверами.
Есть, увы, и недостатки.
1. На сервер приходится ставить дополнительный софт, настраивать его и т.п. Правда, этот софт достаточно скромен, и не расходует ресурсы сервера. Так что — терпимо.
2. Переходные процессы одного сервера (включение в кластер или исключение) влияют на весь кластер. Ведь роутер ничего не знает о серверах — он думает, что имеет дело с роутерами и каналами. Соответственно, все соединения распределяются на все доступные каналы. Никакого server-affinity. В результате при выключении сервера все соединения перетасовываются между всеми оставшимися серверами. И все активные TCP-сессий разрываются (строго говоря — не все, есть шанс, что часть вернётся на тот же сервер). Это плохо, но учитывая нашу защиту от таких ситуаций (плеер перезапрашивает контент при разрыве соединений) и некоторые финты ушами (о которых я ещё расскажу), жить можно.
3. Существуют ограничения, на сколько равных маршрутов роутер может разделить трафик: на cisco 3750X и 4500-X это 8, на 6500+Sup2T — это 32 (но там есть один прикол). В целом этого достаточно, к тому же есть трюки, которые позволяют раскрутить это ограничение.
4. При такой схеме нагрузка на все серверы распределяется равномерно, что накладывает требование одинаковости на все серверы. И если добавлять в кластер более современный, мощный, сервер, нагрузка на него будет не больше, чем на соседа. К счастью, наш софт кластеризации эту проблему в значительной степени нивелирует. К тому же, в роутерах еще есть функция unequal cost multiple paths, которую мы пока не задействовали.
5. Типовые таймауты BGP могут приводить к таким ситуациям, когда сервер уже недоступен, а балансирующий роутер всё ещё распределяет на него нагрузку. Но с этим нам поможет справиться BFD. Подробнее о протоколе — читайте wikipedia. Собственно, именно из-за BFD мы и решили перейти на BIRD.
Промежуточный итог Исключение балансировщиков из цепочки прохождения трафика позволило сэкономить на оборудовании, повысило надёжность системы и сохранило минималистичность наших региональных узлов. Нам пришлось применить несколько трюков, чтобы компенсировать недостатки такой схемы балансировки (надеюсь, у меня ещё будет шанс рассказать об этих трюках). Но в существующей схеме всё ещё есть лишний элемент. И я очень надеюсь убрать его в этом году и рассказать, как нам это удалось.Кстати, пока я писал (точнее, черновик вылёживался) эту статью, коллеги на Хабре написали очень неплохую статью про алгоритмы балансировки. Рекомендую к прочтению!
P.S. Сертификаты одноразовые, так что «кто первый встал, тот и посс попал в душ».
Наши предыдущие публикации:» Blowfish на страже ivi» Неперсонализированные рекомендации: метод ассоциаций» По городам и весям или как мы балансируем между узлами CDN» I am Groot. Делаем свою аналитику на событиях» Все на одного или как мы построили CDN
