Лемматизация в Excel, или «Робот-распознаватель 2.0»
Кто работал с онлайн-рекламой, тот в цирке не смеётся знает, что поисковики порой выдают неожиданные ответы на запросы или подкидывают совершенно не те объявления, которые могут быть интересны. В последнем случае корень проблемы зачастую кроется в наборе ключевых слов, которые использует рекламодатель в своих кампаниях. Бездумная автоматизация подбора ключевиков приводит к печальным последствиям, среди которых самое удручающее — пустые показы и клики. Excel-изобретатель и рационализатор Realweb Дмитрий Тумайкин озадачился этой проблемой и создал очередной файл-робот, который рад раздать миру и Хабру. Вновь передаём слово автору.

«В моей предыдущей статье речь шла о кластеризации больших семантических ядер с помощью макросов и формул в MS Excel. На этот раз речь пойдет о ещё более интересных вещах — словоформах, лемматизации, Яндексе, Google, словаре Зализняка и снова об Excel — его ограничениях, методах их обхода и невероятных скоростях бинарного поиска. Статья, как и предыдущая, будет интересна специалистам по контекстной рекламе и SEO-специалистам.
Итак, с чего всё началось?
Как известно, ключевым отличием алгоритмов поиска Яндекса от поиска Google является поддержка морфологии русского языка. Что имеется в виду: одна из самых больших приятностей заключается в том, что в Яндекс.Директ достаточно задать одну словоформу как минус-слово (любую), и объявление не будет показываться ни по одной из всех его словоформ. Занёс в минус-слова слово «бесплатно» — и не будет показов по словам «бесплатный», «бесплатная», «бесплатных», «бесплатными» и т.д. Удобно? Конечно же!
Однако не всё так просто. На тему странностей морфологии Яндекса была написана не одна статья, включая посты на самом Хабре, да и я в ходе своей работы неоднократно сталкивался с ними. Споры идут по сей день, но я считаю, данный алгоритм несмотря ни на что можно считать преимуществом перед логикой Google.
Странность же заключается в том, что, если группа всех словоформ, скажем, глагола или прилагательного, содержит омоним с группой словоформ существительного, то Яндекс фактически «склеивает» их в некое единое множество словоформ, по всем из которых будут показываться ваши объявления.
Вот наглядный пример, да простит меня НашЛось:
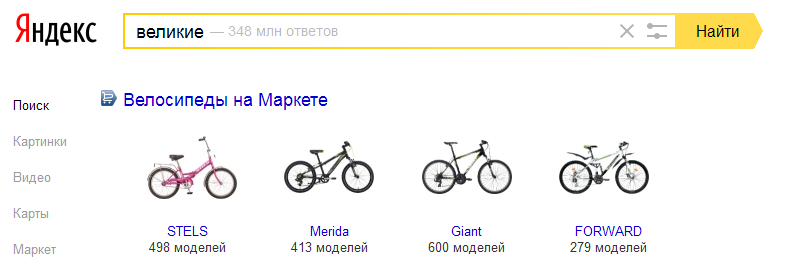
Как всем ясно, краткая форма прилагательного «великий», «велик», является омонимом слову «велик», который, в свою очередь — синоним слова «велосипед». У самого «велика» словоформы «великий», разумеется, нет, поэтому показывать его по этому запросу очевидно неправильно. Говоря языком лингвистов, Яндекс перепутал парадигмы.
Ситуация в естественной выдаче намного лучше, возможно, алгоритмы там более сложны и оптимизированы. А может, это связано с более высокой конкуренцией, т.к. SEO условно-бесплатно (если в штате есть свой вебмастер), а охотников платить за каждый клик в Директе на порядок меньше, несмотря на позитивные тренды в контекстной рекламе. Может, аукцион VCG все исправит? Поживём — увидим.
Однако у корпорации добра свои причуды. Google плохо говорить по-русски практически не распознаёт словоформы. В отличие от Директа, в AdWords нужно исключать все словоформы минус-слов (что уже само по себе морока). При этом количество исключаемых элементов на уровне одной кампании по внутренним ограничениям системы — не более 5000, а в сумме по всем кампаниям в аккаунте — не более 1 млн. Казалось бы, немало, и должно быть достаточно, но владельцам больших рекламных аккаунтов, уверен, так не покажется.
В общем, вывод, который я сделал для себя, работая с Директом и AdWords — для достижения максимальных результатов будешь вынужден копаться в словоформах, какой бы инструмент ни использовал. Поэтому мне нужна была полная база словоформ, желательно наиболее близкая к алгоритмам Яндекса. Я был невероятно рад, когда узнал о ныне ещё живущем, и дай ему Бог ещё здоровья и долгих лет жизни, Зализняке Андрее Анатольевиче, который и создал такой словарь. Данный словарь содержит порядка 100 000 смысловых парадигм, у самой «многогранной» из которых 182 словоформы. В сумме весь словарь составляет чуть более 2,5 млн. слов. Он лёг в основу множества систем распознавания морфологии. Именно этот словарь в электронной табличной форме я нашёл на просторах Интернета и успешно интегрировал в Excel для рабочих нужд.
У любопытных может возникнуть вопрос — зачем было нужно вставлять в Excel 2,5 млн. слов?
И у меня на это 5 причин, отвечаю:
- Во-первых, было просто любопытно, что за словарь. Дело в том, что Яндекс начал поддержку словоформ, взяв за основу и используя как базу данных именно его. Далее, конечно, программисты Яндекса существенно продвинулись, что видно хотя бы по последней версии Mystem, в которой присутствует алгоритм снятия омонимии, о которой написано выше (как я понимаю, алгоритм распознает части речи близлежащих слов, и на базе этой информации строит предположения о части речи у исходного «многозначного» слова). Но тем не менее, основное конкурентное преимущество нашего интернет-гиганта — поддержка морфологии «великого и могучего» — результат проделанной работы и частично дело рук 80-летнего профессора.
- Бесплатные лемматизаторы (например, от K50 или Андрея Кашина) с простым интерфейсом, известные мне и находящиеся в открытом доступе, не отвечают моим требованиям, т.к. их выдача не соответствует алгоритмам Яндекса. И мне, не будучи их разработчиком, данную ситуацию никак не исправить.
- Поскольку основная часть работы с текстом происходит в таблицах Excel, и веб-интерфейсы не всегда могут быть доступны или «тормозят» на больших объемах данных, для меня удобнее иметь все инструменты «под рукой», локально.
- «Робот-распознаватель 1.0» без встроенной нормализации был никуда не годен, и я сам это осознавал. Какой смысл специалисту по контекстной рекламе кластеризовать не нормализованное ядро? Все равно придётся заходить в веб-интерфейс, там нормализовать запросы, копировать и далее уже обрабатывать в Excel.
- После того, как я открыл для себя бинарный поиск в Excel, захотелось опробовать его в действии, на действительно больших объемах данных. А чем 2,5 млн. ячеек не большой объём для MS Excel?
Рождение лемматизатора и бинарный поиск
Поэтому я и решил, что создам свой лемматизатор, с блэкджеком пресловутыми макросами и формулами. По ходу дела внесу ясность: лемматизация — процесс приведения слоформы к лемме — начальной словарной форме (инфинитив для глагола, именительный падеж единственного числа — для существительных и прилагательных).
Результат стараний можно скачать по ссылке: Робот-распознаватель — 2
Визуально файл практически не отличается от предыдущей версии. Разница лишь в том, что в него добавлены два дополнительных листа (словарь) и макрос, выполняющий поиск по ним, и возвращающий начальную форму. Поскольку ограничения Excel — 2 в 20-й степени строк минус одна строка (чуть больше миллиона), пришлось разделить словарь на 2 листа и составлять макрос исходя из этой особенности. Изначально предполагалось, что данные займут 3 листа, но на счастье, в словаре оказалось порядочное количество дублей. Дублями они являются для компьютера, для человека это могут быть разные словоформы разных парадигм.
В основе файла — гигантский по меркам файла Excel массив. Обработка такого массива данных требует больших ресурсов и может быть довольно медленной. Эту проблему как раз и решил бинарный (двоичный) поиск в Excel, который я упомянул в начале. Линейный алгоритм поиска может построчно пробегать по всем 2,5 млн.+ записей — это займёт очень много времени. Бинарный поиск позволяет обрабатывать массивы данных очень быстро, так как выполняет четыре основных шага:
- Массив данных делится пополам и позиция чтения перемещается в середину.
- Найденное значение (пусть n) сравнивается с тем, которое мы ищем (пусть m).
- Если m > n, то берется вторая часть массива, если m < n — первая часть.
- Далее шаги 1–3 повторяются на выбранной части массива данных.
Проще выражаясь, алгоритм двоичного поиска похож на то, как мы ищем слово в словаре. Открываем словарь посередине, смотрим, в какой из половин будет нужное нам слово. Допустим, в первой. Открываем первую часть посередине, продолжаем половинить, пока не найдем нужное слово. В отличие от линейного, где нужно будет сделать 2 в 20 степени операций (при максимальной заполненности столбца в Excel), при бинарном нужно будет сделать всего 20, например. Согласитесь, впечатляет. В скорости работы двоичного поиска вы можете убедиться, поработав с файлом: по 3 млн. ячеек он ищет каждое из слов в запросах за считанные секунды
Все формулы и макросы работают только в оригинальном файле, и не будут работать в других. И ещё. Если вы будете дополнять словарь в файле, то перед обработкой файла, необходимо отсортировать словарь в алфавитном порядке — как вы уже поняли, этого требует логика бинарного поиска.
Конечно, назвать решение самым изящным не получится хотя бы ввиду использования огромной формулы на 3215 символов. Желающие увидеть её воочию и попробовать разобраться в логике могут зайти и посмотреть.
СЖПРОБЕЛЫ (ЕСЛИ (substring (A1;» »;1)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;" ";1);'А-Л'!$A:$B;1;1)
Однако огромная формула — не единственная проблема, с которой пришлось столкнуться в ходе работы над лемматизатором.
- Словарь Зализняка — старое издание (1977 год) и среди словоформ нет некоторых самых простых и привычных для 2015 года слов, например, «компьютерный». Именно поэтому его дорабатывает Яндекс, дорабатываю я и при необходимости может доработать любой. Проблема до конца не решена, но ждите скорые апдейты «Робота» — всё будет.
- В словаре нет имён собственных — их тоже нужно туда добавлять. Я поработал над этим и добавил имена, страны мира и города России.
Проблема отсутствия современных слов решается путём добавления слов, собранных из различных открытых источников. В частности, на момент публикации поста уже собрана база из 300 000 коммерческих запросов, которые будут сравнены с базой. Слова, которых в ней не хватает, будут добавлены в словарь в нужных словоформах. Может показаться, что 300 тысяч слов — это немного, однако, поверьте, это достаточно для значительного расширения словаря Зализняка.
Кроме того, в «Роботе-распознавателе 2» не будет вышеупомянутых ошибок других лемматизаторов, в которых, например, «авито» считается словоформой и возвращает глагол «авить» и генерируются многочисленные словоформы этого несуществующего глагола.
P.S.: Пожелания и багрепорты приветствуются.
Сейчас Дмитрий работает над очередным инструментом, который будет производить обратные операции: генерировать словоформы заданных слов, а не возвращать лемму. Мы ждём очередной поток макросов и гигантских формул. Мы в Realweb активно пользуемся роботами-распознавателями в Excel — это серьёзное подспорье в работе с семантическим ядром, необходимым для работы с web в целом и с онлайн-рекламой в частности. Уверены, что эти инструменты пригодятся и вам!
