Легко и непринужденно деплоим приложения на Tarantool Cartridge (часть 1)

Мы уже рассказывали про Tarantool Cartridge, который позволяет разрабатывать распределенные приложения и паковать их. Осталось всего ничего: научиться деплоить эти приложения и управлять ими. Не беспокойтесь, мы всё предусмотрели! Мы собрали вместе все best practices по работе с Tarantool Cartridge и написали ansible-роль, которая разложит пакет на серверы, стартанет инстансы, объединит их в кластер, настроит авторизацию, забутстрапит vshard, включит автоматический failover и пропатчит кластерный конфиг.
Интересно? Тогда прошу под кат, всё расскажем и покажем.
Мы рассмотрим только часть функциональности нашей роли. Полное описание всех ее возможностей и входных параметров вы всегда можете найти в документации. Но лучше один раз попробовать, чем сто раз увидеть, поэтому давайте задеплоим небольшое приложение.
У Tarantool Cartridge есть туториал по созданию небольшого Cartridge-приложения, которое хранит информацию о клиентах банка и их счетах, а также предоставляет API для управления данными через HTTP. Для этого в приложении описываются две возможные роли: api и storage, которые могут назначаться инстансам.
Сам Cartridge ничего не говорит о том, как запускать процессы, он лишь предоставляет возможность для настройки уже запущенных инстансов. Остальное пользователь должен сделать сам: разложить конфигурационные файлы, запустить сервисы и настроить топологию. Но мы не будем всем этим заниматься, за нас это сделает Ansible.
От слов к делу
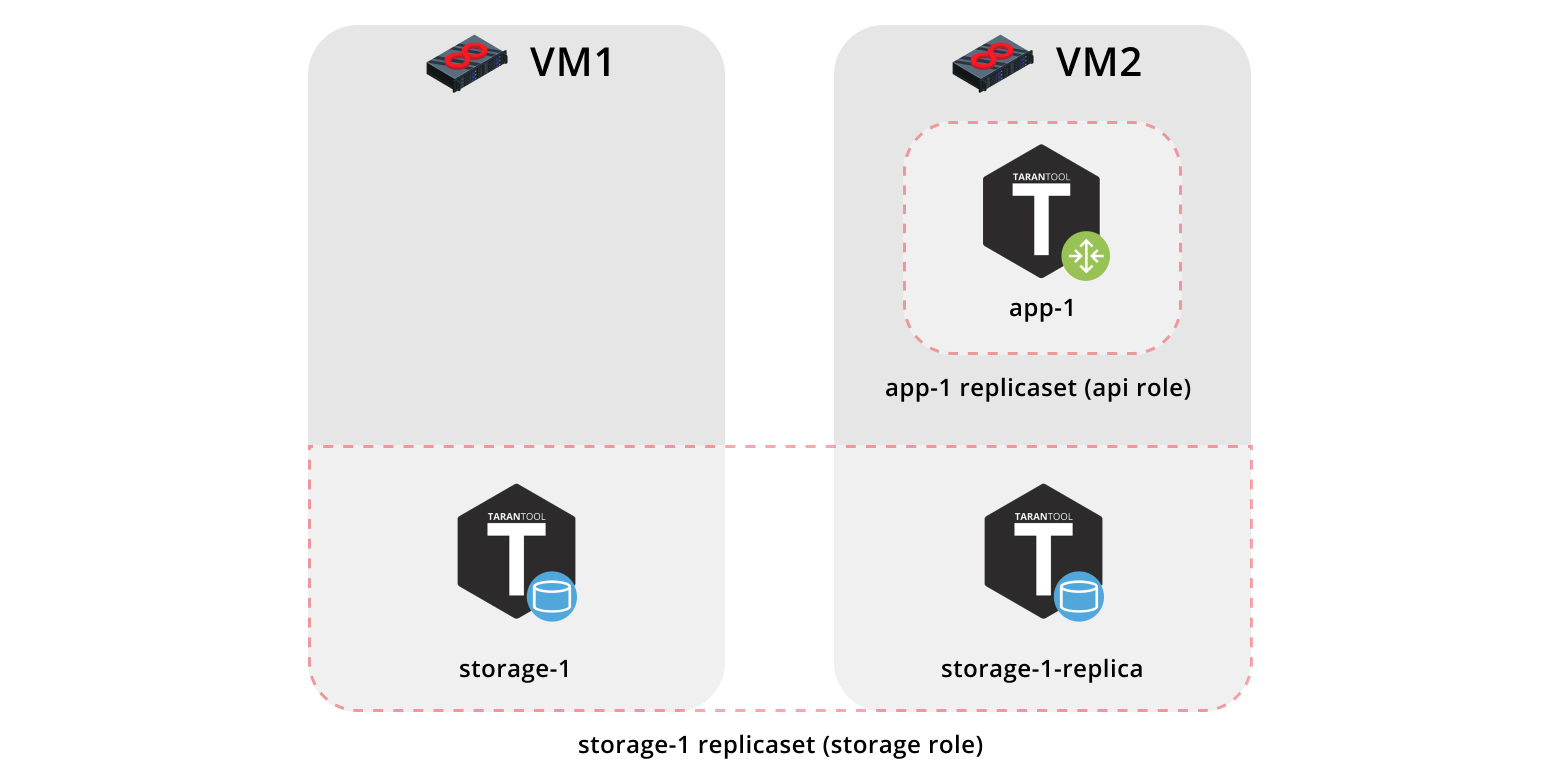
Итак, задеплоим наше приложение на две виртуалки и настроим простую топологию:
- Pепликасет
app-1будет реализовывать рольapi, которая включает в себя рольvshard-router. Здесь будет только один инстанс. - Репликасет
storage-1реализует рольstorage(и одновременноvshard-storage), сюда добавим два инстанса с разных машин.
Для запуска примера нам понадобятся Vagrant и Ansible (версии 2.8 или старше).
Сама роль находится в Ansible Galaxy. Это такое хранилище, которое позволяет делиться своими наработками и использовать готовые роли.
Склонируем репозиторий с примером:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git
$ cd deploy-tarantool-cartridge-app && git checkout 1.0.0Поднимаем виртуалки:
$ vagrant upУстанавливаем ansible-роль Tarantool Cartridge:
$ ansible-galaxy install tarantool.cartridge,1.0.1Запускаем установленную роль:
$ ansible-playbook -i hosts.yml playbook.ymlДожидаемся окончания выполнения плейбука, переходим на http://localhost:8181/admin/cluster/dashboard и наслаждаемся результатом:
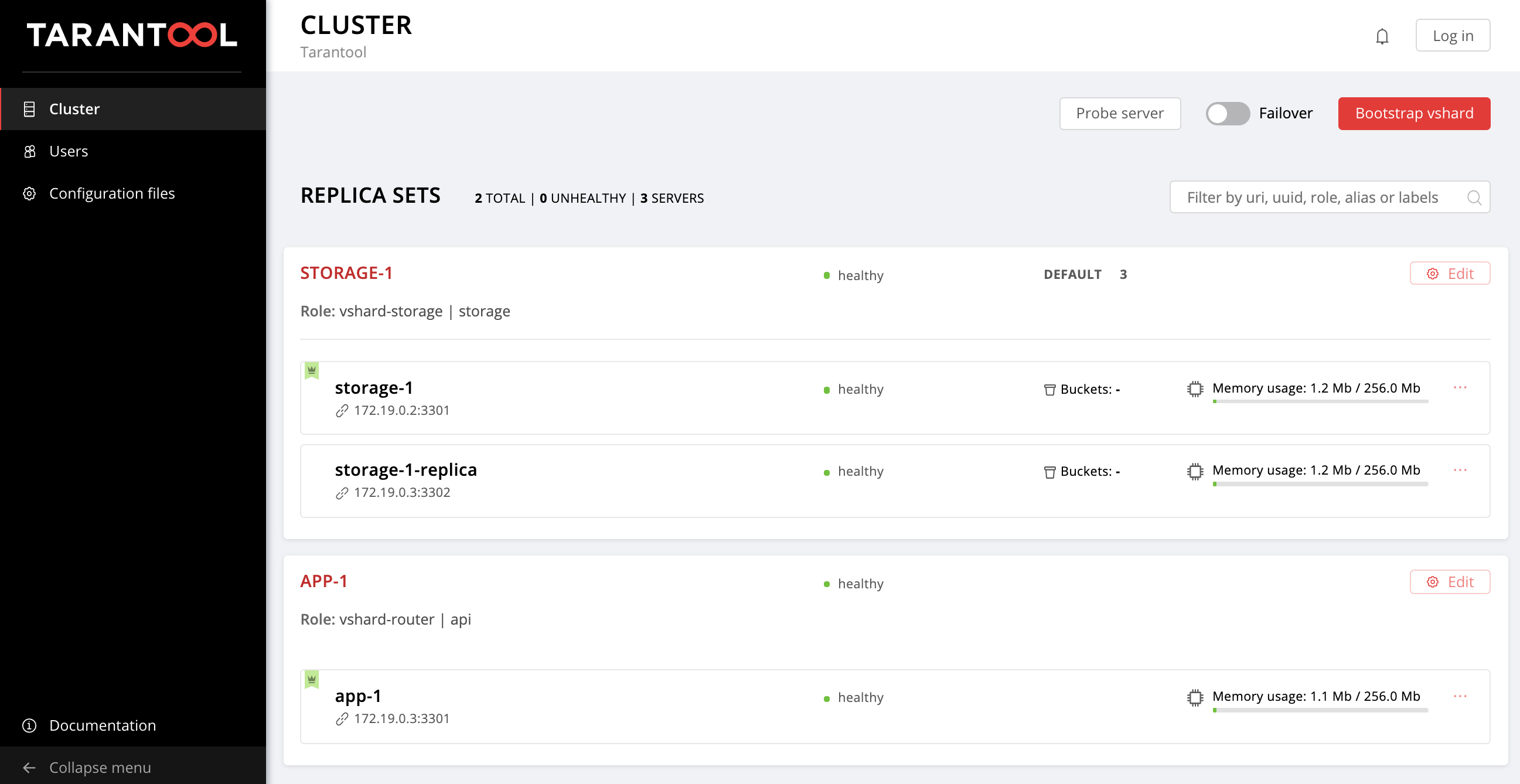
Можно лить данные. Круто, правда?
А теперь давайте разберемся, как с этим работать, и заодно добавим еще один репликасет в топологию.
Начинаем разбираться
Итак, что же произошло?
Мы подняли две виртуальные машины и запустили ansible-плейбук, который настроил наш кластер. Давайте посмотрим на содержимое файла playbook.yml:
---
- name: Deploy my Tarantool Cartridge app
hosts: all
become: true
become_user: root
tasks:
- name: Import Tarantool Cartridge role
import_role:
name: tarantool.cartridgeЗдесь ничего интересного не происходит, запускаем ansible-роль, которая называется tarantool.cartridge.
Всё самое важное (а именно, конфигурация кластера) находится в inventory-файле hosts.yml:
---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:Всё, что нам нужно — это научиться управлять инстансами и репликасетами, изменяя содержимое этого файла. Дальше мы будем добавлять в него новые секции. Чтобы не запутаться, куда их добавлять, можете подсматривать в финальную версию этого файла, hosts.updated.yml, который находится в репозитории с примером.
Управление инстансами
В терминах Ansible каждый инстанс — это хост (не путать с железным сервером), т.е. узел инфраструктуры, которым Ansible будет управлять. Для каждого хоста мы можем указать параметры соединения (такие, как ansible_host и ansible_user), а также конфигурацию инстанса. Описание инстансов находится в секции hosts.
Рассмотрим конфигурацию инстанса storage-1:
all:
vars:
...
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
...В переменной config мы указали параметры инстанса — advertise URI и HTTP port.
Ниже находятся параметры инстансов app-1 и storage-1-replica.
Нам нужно сообщить Ansible параметры соединения для каждого инстанса. Кажется логичным объединить инстансы в группы по виртуальным машинам. Для этого инстансы объединены в группы host1 и host2, и в каждой группе в секции vars указаны значения ansible_host и ansible_user для одной виртуалки. А в секции hosts — хосты (они же инстансы), которые входят в эту группу:
all:
vars:
...
hosts:
...
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:Начинаем изменять hosts.yml. Добавим еще два инстанса, storage-2-replica на первой виртуалке и storage-2 на второй:
all:
vars:
...
# INSTANCES
hosts:
...
storage-2: # <==
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica: # <==
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
...
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica: # <==
host2:
vars:
...
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2: # <==
...Запускаем ansible-плейбук:
$ ansible-playbook -i hosts.yml \
--limit storage-2,storage-2-replica \
playbook.ymlОбратите внимание на опцию --limit. Поскольку каждый инстанс кластера является хостом в терминах Ansible, мы можем явно указывать, какие инстансы должны быть настроены при выполнении плейбука.
Снова заходим в Web UI http://localhost:8181/admin/cluster/dashboard и наблюдаем наши новые инстансы:
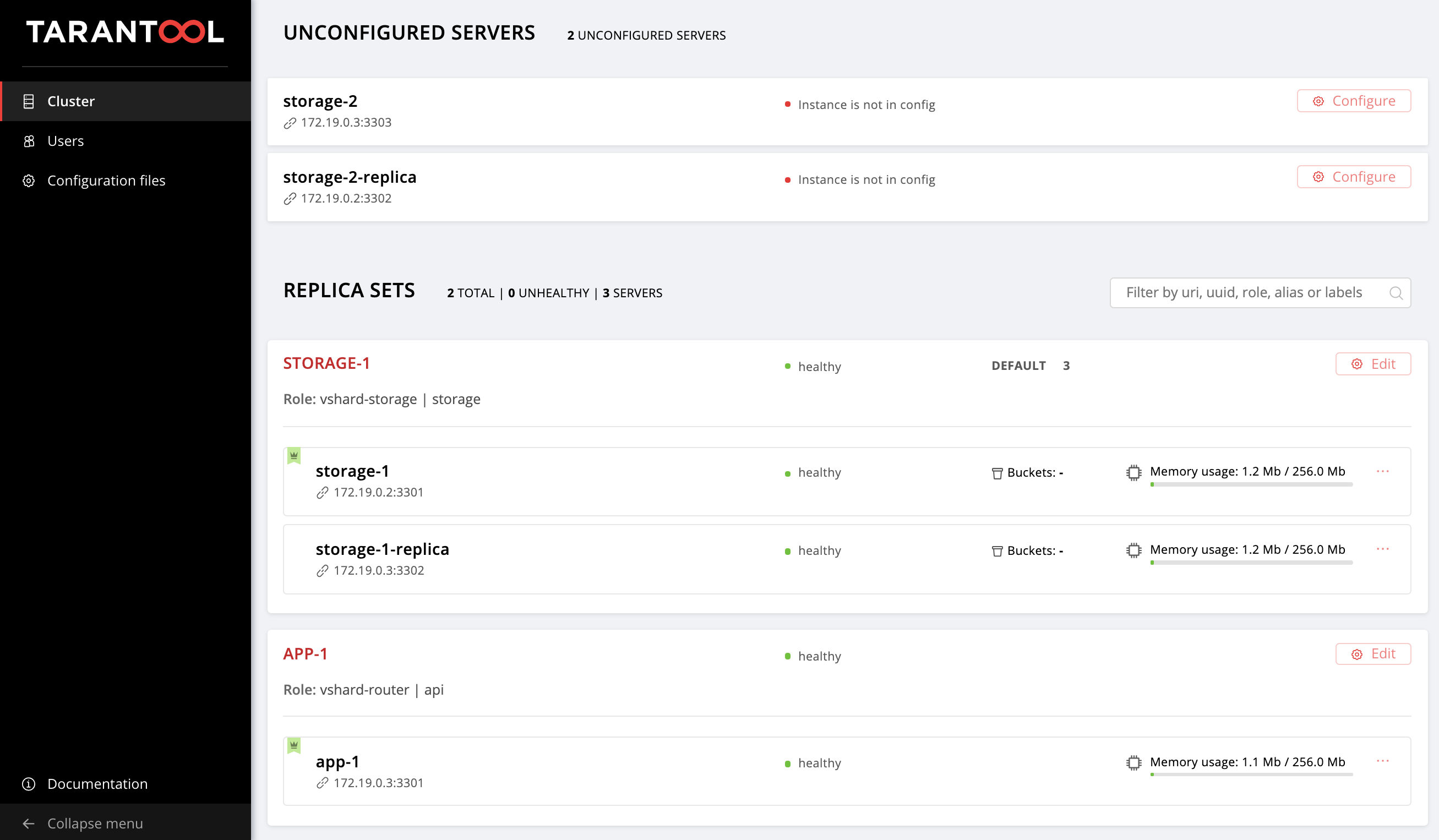
Не будем останавливаться на достигнутом и освоим управление топологией.
Управление топологией
Объединим наши новые инстансы в репликасет storage-2. Добавим новую группу replicaset_storage_2 и опишем в ее переменных параметры репликасета по аналогии с replicaset_storage_1. В секции hosts укажем, какие инстансы будут входить в эту группу (то есть наш репликасет):
---
all:
vars:
...
hosts:
...
children:
...
# GROUP INSTANCES BY REPLICA SETS
...
replicaset_storage_2: # <==
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replicaset instances
storage-2:
storage-2-replica:Снова запускаем плейбук:
$ ansible-playbook -i hosts.yml \
--limit replicaset_storage_2 \
--tags cartridge-replicasets \
playbook.ymlВ параметр --limit мы на этот раз передали имя группы, которая соответствует нашему репликасету.
Рассмотрим опцию tags.
Наша роль последовательно выполняет различные задачи, которые помечены следующими тэгами:
cartridge-instances: управление инстансами (настройка, подключение к membership);cartridge-replicasets: управление топологией (управление репликасетами и безвозвратное удаление (expel) инстансов из кластера);cartridge-config: управление остальными параметрами кластера (vshard bootstrapping, режим автоматического failover-а, параметры авторизации и конфигурация приложения).
Мы можем явно указать, какую часть работы хотим сделать, тогда роль пропустит выполнение остальных задач. В нашем случае мы хотим работать только с топологией, поэтому указали cartridge-replicasets.
Давайте оценим результат наших стараний. Находим новый репликасет на http://localhost:8181/admin/cluster/dashboard.
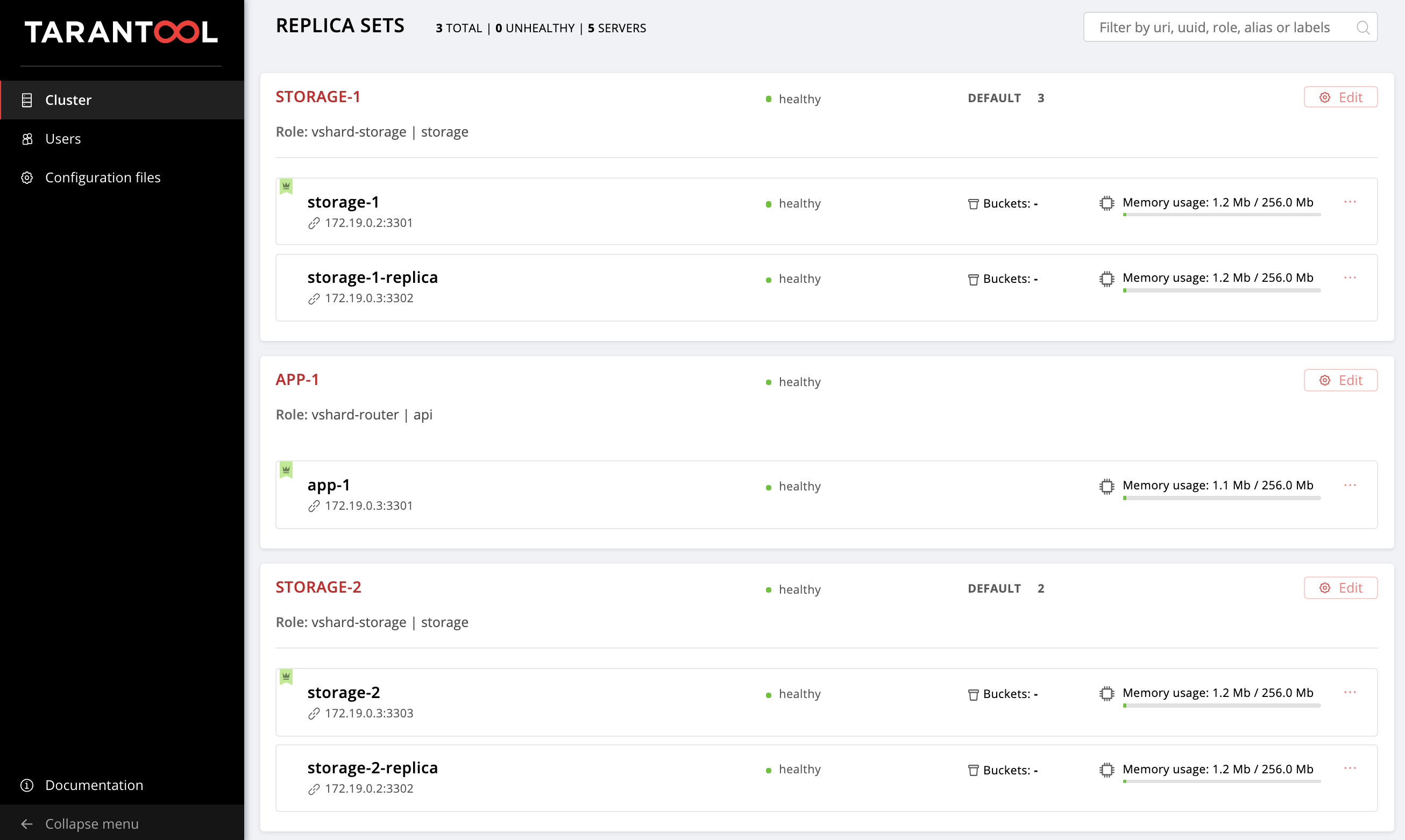
Ура!
Поэкспериментируйте с изменением конфигурации инстансов и репликасетов и посмотрите, как меняется топология кластера. Вы можете опробовать различные эксплуатационные сценарии, например, rolling update или увеличение memtx_memory. Роль попытается сделать это без рестарта инстанса, чтобы сократить возможный даунтайм вашего приложения.
Не забудьте запустить vagrant halt, чтобы остановить виртуалки, когда закончите с ними работать.
Здесь я расскажу подробнее о том, что происходило под капотом ansible-роли во время наших экспериментов.
Рассмотрим по шагам деплой Cartridge-приложения.
Установка пакета и старт инстансов
Сначала нужно доставить пакет на сервер и установить его. Сейчас роль умеет работать с RPM- и DEB-пакетами.
Дальше запускаем инстансы. Тут всё очень просто: каждый инстанс — это отдельный systemd-сервис. Рассказываю на примере:
$ systemctl start myapp@storage-1Эта команда запустит инстанс storage-1 приложения myapp. Запущенный инстанс будет искать свою конфигурацию в /etc/tarantool/conf.d/. Логи инстанса можно будет посмотреть при помощи journald.
Unit-файл /etc/systemd/system/myapp@.sevice для systemd-сервиса будет доставлен вместе с пакетом.
В Ansible имеются встроенные модули для установки пакетов и управления systemd-сервисами, тут мы ничего нового не изобрели.
Настройка топологии кластера
А вот здесь начинается самое интересное. Согласитесь, было бы странно заморачиваться со специальной ansible-ролью для установки пакетов и запуска systemd-сервисов.
Настроить кластер можно вручную:
- Первый вариант: открываем Web UI и нажимаем на кнопочки. Для разового старта нескольких инстансов вполне подойдет.
- Второй вариант: можно воспользоваться GraphQl API. Тут уже можно что-нибудь автоматизировать, например, написать скрипт на Python.
- Третий вариант (для сильных духом): заходим на сервер, коннектимся к одному из инстансов при помощи
tarantoolctl connectи производим все необходимые манипуляции с Lua-модулемcartridge.
Основная задача нашего изобретения — сделать за вас именно эту, самую сложную часть работы.
Ansible позволяет написать свой модуль и использовать его в роли. Наша роль использует такие модули для управления различными компонентами кластера.
Как это работает? Вы описываете желаемое состояние кластера в декларативном конфиге, а роль подает на вход каждому модулю его секцию конфигурации. Модуль получает текущее состояние кластера и сравнивает его с тем, что пришло на вход. Далее через сокет одного из инстансов запускается код, который приводит кластер к нужному состоянию.
Сегодня мы рассказали и показали, как задеплоить ваше приложение на Tarantool Cartridge и настроить простую топологию. Для этого мы использовали Ansible — мощный инструмент, который отличается простотой в использовании и позволяет одновременно настраивать множество узлов инфраструктуры (в нашем случае это инстансы кластера).
Выше мы разобрались с одним из множества способов описания конфигурации кластера средствами Ansible. Как только вы поймете, что готовы идти дальше, изучите best practices по написанию плейбуков. Возможно, вам будет удобнее управлять топологией при помощи group_vars и host_vars.
Очень скоро мы расскажем, как безвозвратно удалять (expel) инстансы из топологии, бутстрапить vshard, управлять режимом автоматического failover-а, настраивать авторизацию и патчить кластерный конфиг. А пока вы можете самостоятельно изучать документацию и экспериментировать с изменением параметров кластера.
Если что-то не работает, обязательно сообщите нам о проблеме. Мы оперативно всё разрулим!
