Лаборатория Тинькофф: как студенты разрабатывают визуального робота

В Тинькофф есть образовательный проект «Лаборатория «Финансовые технологии». Мы отбираем студентов и магистров московских технических вузов, которые хотят работать с ИТ-проектами банка. Оформляем их на работу в штат на 20, 30 или 40 часов в неделю, даем задачи, ментора и помогаем расти профессионально. Мы работаем в партнерстве с МФТИ: преподаватели и старшекурсники вуза выступают менторами для студентов.
Лаборант может выбрать, в какой из пяти команд работать:
- Computer Vision;
- Speech-to-text;
- Аналитика;
- Обработка естественного языка;
- Рекомендательные системы.
У каждой команды свои задачи и специфика. Но принцип общий: учим решать сложные академические задачи на реальных кейсах.
Рассказываем о внутренней кухне Лаборатории на примере работы команды Computer Vision весной-летом 2020 года.
Проект команды Computer Vision: «Говорящие головы»
Куратор проекта: Константин Осминин, Тинькофф
Ментор: Аркадий Ильин, Лаборатория гибридных интеллектуальных систем МФТИ
Лаборанты: Кирилл Рыжиков (2 курс) и Дмитрий Гадецкий (1 курс магистратуры)
В Лаборатории мы решаем наукоемкие задачи, которые в перспективе можно применить на практике в работе банка. В команде Computer Vision в этом году работали над задачей audio-to-video. Это генерация реалистичного видео с человеком на основе его речи на русском языке.
Изначально тут был не только бизнес, но в значительной степени исследовательский интерес. Если кратко: нужно было обучить компьютерную модель генерировать видеоизображение на основе только фото человека и аудиодорожки. То есть мы даем модели аудио и картинку, а на выходе получаем видео с говорящим человеком.
Такая технология впервые появилась в Китае, а в России представлена сервисом по генерации виртуальных ведущих в «Мейл.ру». У Сбербанка робот-ведущий Елена читает 30-секундные новости.
Потенциально такую технологию можно применить для реализации виртуальных ведущих, помощников, визуализации образовательных курсов или даже генерации изображения собеседника при звонках, чтобы не гонять трафик видео, а значит, снизить стоимость звонка.
Константин Осминин, куратор команды Computer Vision в Тинькофф
Область виртуальных аватаров сейчас очень востребована в индустрии. Лаборатория — это больше образовательный проект, для нас важно поработать с самой технологией, проверить уже существующие решения и придумать что-то свое.
Сначала мы работали над исследовательской частью, а потом поняли, как можно применить технологию в бизнесе. Теперь мы разрабатываем свой прототип ориентированного на бизнес сервиса, визуально общающегося с пользователем.
Задача: разработать «говорящую голову»
У нас было два этапа работы. Первый — провести исследование в области Neural Voice Puppetry, выяснить, что уже сделано другими исследователями и разработчиками. Потом реализация.
Работа над ней делилась на два больших блока:
- создание правдоподобной мимики лица на основе аудио (сгенерировать движение глаз, губ, бровей);
- рендеринг видео.
Первый челлендж: исследовать чужие наработки
Сначала нам нужно было глубоко разобраться в области. Некоторые компании уже работали над этой задачей, например Samsung AI Center, Сбербанк. Но код у них закрытый и получить доступ к нему нельзя. Поэтому мы работали с открытыми источниками, они все в основном на английском. Больше всего информации нашли на агрегаторе Arxiv.

Пример статьи c arxiv.org
Это не научный журнал, а агрегатор статей в открытом доступе. Поэтому каждую статью и все, что там написано, нужно проверять. То есть посмотреть, насколько рабочий код приложен в статье.
Обычно код к статьям выкладывают на «Гитхабе». Если авторы не выложили код, команда искала имплементации на том же «Гитхабе», но уже от простых пользователей-энтузиастов.
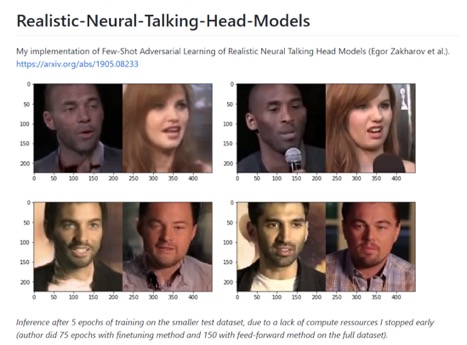
Пример неофициальной имплементации архитектуры генератора говорящих голов из статьи Few-Shot Adversarial Learning of Realistic Neural Talking Head Models (Egor Zakharov et al.)
Дмитрий Гадецкий, лаборант Тинькофф, студент 1 курса магистратуры
В первый месяц мы почти все время читали статьи на Arxiv и проверяли разные подходы. По опыту скажу: чтобы разобраться в вопросе, нужно вдумчиво изучить около десяти статей и проверить их код на работоспособность. Только когда понимаешь архитектуру кода, появляется возможность применить описанные принципы к конкретным задачам.
У нас был случай, когда мы проверяли подход к генерации из статьи китайских коллег. Мы не могли запустить код несколько дней. Пришлось писать авторам статьи с просьбой о помощи. В итоге они ответили, дописали код, чтобы все заработало.
Второй челлендж: датасет, лэндмарки и моргание
Дальше мы перешли к поиску собственных решений, как сгенерировать реалистичное видео говорящего человека только по фото и аудио.
Теоретически можно было использовать наработки зарубежных разработчиков и код их нейронной сети, как, например, на «Гитхабе».
Но возникла серьезная проблема. Нейросети, которые уже решали задачу генерации видео по аудио, не работали с русским языком. Все они были заточены под английский язык. А значит, нужно было разработать сеть и обучить ее на собственном датасете.
Встал вопрос, на каких данных обучать свой комплекс нейросетей. Готовых данных у нас не было. В сети датасетов с видео на английском языке — тысячи часов (например, voxceleb, voxceleb2), а на русском их просто нет.
Нужно было собрать свой датасет:
- видео на русском языке;
- где четко видно лицо;
- без шумов.
Изначально для парсинга мы выбрали лекции на «Курсере». У них есть API, которая позволяет скачивать видео. Мы скачали видео с ресурса и приступили к его обработке.
Для этого написали программный модуль: он нарезал видео на отдельные кусочки, проверял, что на этом кусочке речь одного человека. Еще он искал в кадре того человека, кто говорил. Вырезанные куски с головой говорящего человека в кадре складывали в датасет.
С «Курсеры» мы собрали 20 часов видео. Но качество видео этого датасета было не очень. Лицо получалось в плохом разрешении. Поэтому нам пришлось собирать второй датасет уже с «Ютуба». Оттуда скачали видео, которые больше соответствовали нашим требованиям: лицо говорящего человека занимало не меньше 40% экрана, смотрело в камеру. Этот датасет был в 60 часов.

Параметры датасета
На собранной базе видео мы запустили работу модели по разметке лиц. Мы прогнали одну модель (FaceAlign), которая искала на лице определенные ключевые точки — лэндмарки. Всего их 68.

Сеть извлекает на каждом кадре видео эти точки и переводит их вот в такое представление:
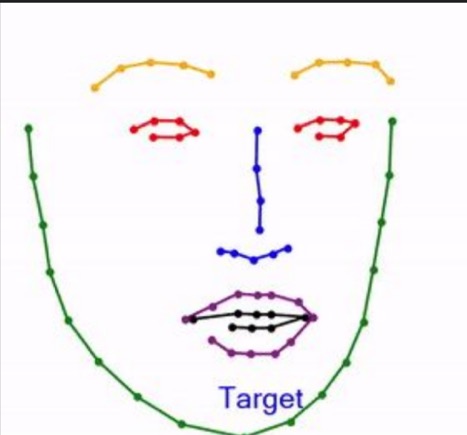
Данные о точках описывали движение челюстей, губ, подвижность бровей и синхронное движение носа.
На этих данных о ключевых точках обучался пререндер, построенный и обученный нами с оглядкой на архитектуру, предложенную Захаровым (a.k.a. Samsung)). Ему подавалась входная аудиодорожка, а он должен был сгенерировать видео. Сначала модуль генерировал абсолютное положение точек, но модель на таком подходе генерировала неправдоподобное изображение.

Итерации обучения генератора абсолютных положений лэндмарок. На последних итерациях видно, что рот перестает полностью закрываться, а брови приобретают статичное положение и присутствует общая деградация выразительности мимики
Кирилл Рыжиков, лаборант
Чтобы наша сеть генерировала правдоподобное изображение, мы искали другой подход. Попробовали генерировать не абсолютное положение ключевых точек, а отклонение от их положения на нейтральном лице, когда человек смотрит на вас прямо с закрытым ртом и спокойными бровями. И — эврика! — сеть сгенерировала правдоподобную мимику. Мы поняли, что идем в правильном направлении, и начали работать именно с этим подходом.
Отдельно мы решали задачу генерации моргания, чтобы лицо на видео выглядело реалистично. Без моргания говорящее лицо смотрится жутко. Выяснилось, что моргание не синхронизировано с речью. Поэтому наша модель его просто сэмплировала.
Третий челлендж: пререндеринг и рендеринг
Когда мы обучили сеть генерить правдоподобную мимику, пришла очередь работать над пререндером и рендером, то есть переводом данных в видео. Лаборанты использовали технологии First Order Modu и Samsung. После двух-трех этапов рендера получилось сгенерировать более проработанную мимику, более качественное изображение и приятную текстуру лица.
В качестве пострендера использовали LipGAN, чтобы уточнить движение губ.
Где готовый продукт
Ребята показали результат в июле этого года. На общей презентации было 60 сотрудников Тинькофф, что необычно для Лаборатории. Как правило, проекты защищаются перед меньшей аудиторией.
Результат команды понравился куратору, коллеги решили продолжить работу над проектом и перевести его в практическую плоскость.
Готовый результат ждем к концу этого года. Скорее всего, это будет 3D-модель, как тут:
Встречались вживую только один раз
Лаборанты с ментором и куратором встречались вживую только один раз, на собеседовании. Остальное время общались в «Телеграме» и «Зуме». Это принцип Лаборатории: удаленная работа в удобное участникам время.
Аркадий Ильин, ментор
Каждый работает в комфортное ему время, в комфортной для себя обстановке. Например, вчера Кирилл прислал мне ответ в час ночи и, пока он спал до обеда, я его прочитал. Думаю, такой подход только повышает эффективность работы.
Три раза в неделю — рабочие созвоны, где обсуждают текущие задачи, гипотезы, методы решений.
Два раза в месяц — отчетные созвоны с куратором Тинькофф, на которых лаборанты рассказывают о проделанной работе.

Обычный рабочий созвон с обсуждением найденной архитектуры генератора мимики
Лаборанты — готовые R&D-специалисты
Так как работа в Лаборатории идет на стыке науки и практики, ее результаты публикуют и в академических кругах. Например, первые результаты работы в проекте «Говорящие головы» ментор и студенты готовят для доклада на 63-ю научную конференцию в МФТИ в ноябре этого года.
Аркадий Ильин, ментор
То, что делаем мы, мало кто делает в бизнес-сообществе. Поэтому хотим донести результаты и до академической среды.
До 27 сентября открыт прием заявок в лабораторию, подробнее об открытых проектах и сроках
