Курс «PostgreSQL для начинающих»: #4 — Анализ запросов (ч.1 — как и зачем читать планы)
Продолжаю публикацию расширенных транскриптов лекционного курса «PostgreSQL для начинающих», подготовленного мной в рамках «Школы backend-разработчика» в «Тензоре».
В этой лекции мы узнаем, что такое план выполнения запроса, как и зачем его читать (и почему это совсем непросто), и о каких проблемах с производительностью базы он может сигнализировать. Разберем, что такое Seq Scan, Bitmap Heap Scan, Index Scan и почему Index Only Scan бывает нехорош, чем отличается Materialize от Memoize, а Gather Merge от «просто» Gather.
Как обычно, для предпочитающих смотреть и слушать, а не читать — доступна видеозапись (часть 1, часть 2):

Краткий путеводитель:
Основы SQL
Простые SELECT
Сложные SELECT
Анализ запросов
Индексы
Транзакции
Блокировки
Содержание текущей лекции:
Сегодня мы говорим про анализ запросов. В свое время, порядка 10 лет назад, я уже делал подобную лекцию, но с тех пор произошло достаточно много изменений, которые произошли вплоть до 15-й версии PostgreSQL. Последнюю вышедшую 16-ю мы рассматривать сегодня не будем, да там и нет значимых новшеств в контексте сегодняшней темы.
Как мы говорили на первой лекции, SQL — это декларативный язык. То есть вы сначала должны описать, что вы хотите получить, что ждете от данных, которые должны вам вернуться. А база искренне считает, что она лучше вас знает, как конкретно это сделать: какие индексы стоит использовать, как именно, в каком порядке соединять таблицы, как накладывать условия, будут ли они вообще накладываться после соединения или подойдут под WHERE-условие индекса… Здесь все — на откуп СУБД.
Конечно, вы можете предполагать, что ваш красивый «запрос о 10 джойнах», который вы нарисовали, будет при выполнении выглядеть как на левой картинке… К сожалению, обычно бывает как на правой.

СУБД строит план запроса с 10 JOIN
Обычно это случается из-за того, что PostgreSQL всегда уверен в своей правоте, что даже не принимает «подсказки» в отличие от некоторых других СУБД (где вы можете прямо в комментарии в теле запроса написать «хинт», который подскажет базе, как здесь лучше действовать: с какой из таблиц начать соединение, каким индексом лучше воспользоваться или, может, не пользоваться ими вообще).
В отличие от них, PostgreSQL не хочет работать с подсказками. Точнее, есть небольшой модуль-расширение pg_hint_plan (github), который позволяет чуть-чуть «похачить», в ручном режиме подсказав базе, как стоит себя вести относительно каждого конкретного запроса. Но в эксплуатации он достаточно сложен, поскольку вместо прямых указаний базе »делай так» превращает «хинты» в рекомендации »не так делай в последнюю очередь», увеличивая «стоимость» операций, о которой мы поговорим далее.
PostgreSQL не принимает подсказки
Поэтому, раз PostgreSQL не готов позволить нам настраивать себя «снаружи» в рамках конкретного запроса, и считает, что лучше нас все знает, он готов этим знанием поделиться с нами. То есть с удовольствием готов рассказать нам, как конкретно он хочет выполнять наш запрос (или уже выполнил).
Что такое план и зачем он нужен
То, что база нам готова рассказать — это план выполнения запроса, который представляет из себя некоторую древовидную структуру в виде либо текста, либо (в зависимости от выбранного формата) JSON, XML или YAML.
Как правило, вам придется сталкиваться именно с текстовым форматом и, много реже, с JSON. Причем его обычно ставят только в системах, предполагающих какую-то автоматизированную обработку логов, поскольку человеку «прочитать» с листа JSON-объект на несколько сотен килобайт почти нереально.
Впрочем, если вам такой JSON встретился — не отчаивайтесь, наш сервис визуализации планов explain.tensor.ru вполне успешно «переваривает» и их.

План запроса PostgreSQL
Впрочем, текстовый формат плана хоть и существенно компактнее, прочитать его ничуть не легче, не имея соответствующих навыков — их мы и постараемся наработать в рамках этой лекции.
Во-первых, узлом дерева плана является какая-то атомарная операция, с точки зрения PostgreSQL: каким образом данные надо получить, какой индекс стоит использовать или даже сразу несколько и надо ли строить по ним битовые карты, какой вид соединения или операции над множествами надо использовать, …
Во-вторых, когда такое дерево построено на фазе планирования выполнения запроса, оно передается executor’у и представляет для него готовый алгоритм работы, который реализуется при обходе «снизу-вверх». То есть сначала выполняются все нижележащие узлы, а только потом их «предок» — и результат самого верхнего «корневого» узла и есть результат выполнения всего нашего запроса.
В третьих, на каждом узле плана в ходе реального выполнения запроса аккумулируются фактически затраченные на выполнение поддерева ресурсы: процессорное время, прочитанные блоки данных, задержки доступа к диску, …
Собственно, ради этих данных о ресурсах мы и хотим получить план — чтобы выяснить «Кто самое слабое звено?» в этом оркестре.

«Кто самое слабое звено?»
Либо мы написали плохой алгоритм — например, заставили PostgreSQL сначала делать соединение, а затем уникализировать «размножившиеся» записи, либо написали запрос «о десяти джойнах», шансы которого эффективно распланироваться крайне малы — слишком уж велика становится комбинаторная вероятность, как его можно выполнить «нехорошо».
Если мы подразумеваем, что надо сначала «проджойнить» таблички №1 и №2, а только потом к ним №3, то база об этом может, в целом, не догадываться. А происходить это может по той простой причине, что у нас неактуальная статистика — ведь алгоритм планирования опирается именно на статистическое распределение данных, поскольку никакой другой компактной информации у него просто не существует.
Например, вы берете и «заливаете» в таблицу данные, где идентификаторы 1, 2, 3, 4, 5, … и так далее до миллиона — база будет искренне считать, что у вас все идентификаторы независимы, различны и у них равномерное распределение.
Все будет работать хорошо, пока вы не «зальете» дополнительно миллион записей с одинаковым идентификатором. После чего, продолжая считать, что распределение все еще нормальное, относительно этого конкретного идентификатора она «промахнется», а вы можете получить «боль» при выполнении этого конкретного запроса.
Причем она будет выражаться во вполне конкретных вещах. Вы либо потратите избыточное процессорное время, либо «прокачаете» слишком много данных — и хорошо, если все они уже окажутся закэшированы в памяти, а то ведь еще придется ожидать чтения с диска.
И чтобы это все выяснить, нам как раз и нужен план. Выглядит в логах обычно он примерно как-то вот так или еще страшнее.
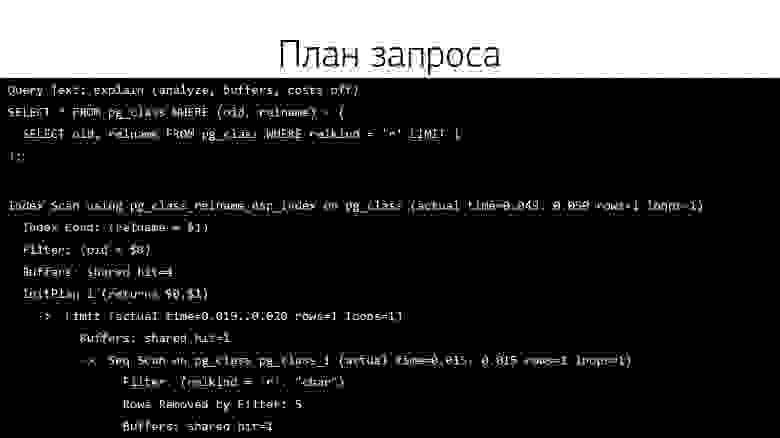
Запрос и его план в текстовом формате в логе сервера
И если человек неподготовлен, и никогда не занимался чтением планов PostgreSQL «с листа», то наиболее подходящей картинкой в этом случае будет вот такая:

«Что это за цифры?! Что это за буквы?! Что это все значит-то?!!!»
Получаем и читаем план запроса
Чтобы получить от базы план запроса, как и любую другую вещь в PostgreSQL, мы должны выполнить определенную команду — EXPLAIN:
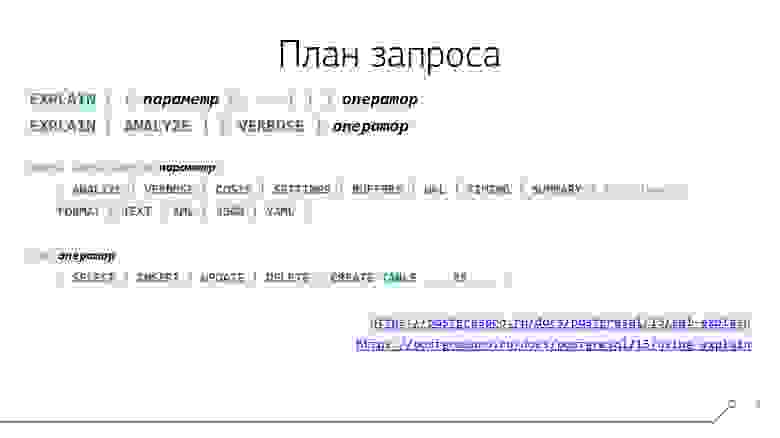
Синтаксис команды EXPLAIN
Выполнение просто EXPLAIN SELECT ... даст нам сам план выполнения — то есть покажет, как база собирается выполнять такой запрос, а вот EXPLAIN ANALYZE SELECT ... даст нам план с результатами уже выполненного запроса — поэтому EXPLAIN ANALYZE DELETE ... стоит применять с большой осторожностью.
Помимо ANALYZE, команду EXPLAIN можно снабдить дополнительными опциями, которые определяют, что мы увидим (или нет) в плане:
VERBOSE— возвращаемые узлом столбцыCOSTS— «стоимость» операцииSETTINGS— настройки базы, влияющие на выполнение запросаWAL— статистика формирования WAL-файловTIMING— время выполнения операцииSUMMARY— сводные данные планирования/исполнения
Также можно задать один из 4 поддерживаемых форматов.

EXPLAIN
Получаемый с помощью EXPLAIN план зависит только от накопленной базой статистики распределения данных и не меняется от запуска к запуску, если статистика не изменялась сильно или мы какие-то настройки сервера не «подкрутили».
Структура узлов плана
Если мы выполним EXPLAIN самого простого запроса SELECT * FROM, возвращающего все записи из системной таблички pg_class, которая есть в любой базе, то увидим одну строку:
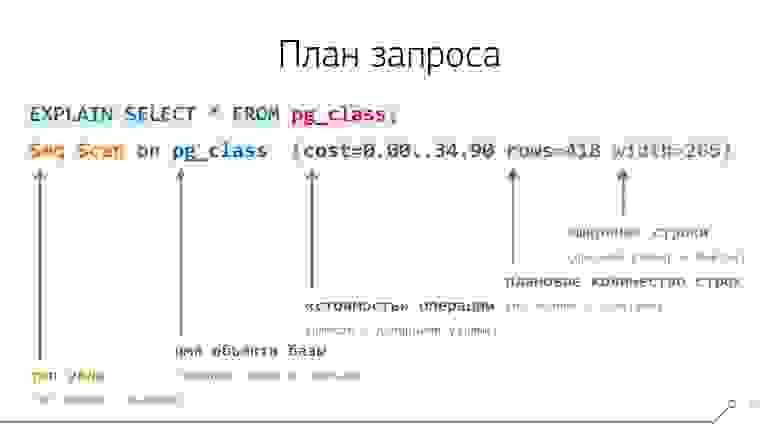
Атрибуты строки плана
Эта строка содержит в себе некоторые данные о конкретном узле плана. До скобок — это тип узла (что мы делаем с данными) и имя объекта базы (таблицы, индекса, функции, …), с которым это происходит. В нашем примере мы последовательно сканируем (Seq Scan) таблицу pg_class.
А внутри первых скобок (потому что потом возникнут еще и вторые) записано то, что база об этой операции «думает»: ее условная «стоимость» в «попугаях» — 34.90, вернет она нам 418 строк и их «ширина» в среднем составит 265 байт.
Тут «стоимость» — это некоторая абстрактная расчетная величина, вычисляемая от заданных в БД параметров и планового количества записей. Такими параметрами выступают «стоимость» обращения к таблице, «стоимость» извлечения из нее одной записи, «стоимость» одной атомарной операции обработки над ней с точки зрения CPU, …
Фактически, «стоимость» является тем самым камнем на распутье («Налево пойдешь — коня потеряешь, направо — голову сложишь.»), который позволяет PostgreSQL принять решение, какой из возможных планов (а их вариантов могут получаться сотни и тысячи) лучше/хуже.

PostgreSQL на распутье
То есть, с точки зрения СУБД, нет «хороших» планов — есть только плохие. И из всего множества планов, которые она способна «придумать», старается выбрать наименее «плохой» — то есть имеющий минимальную «стоимость».
Управление планами и «тюнинг» сервера
Например, мы можем захотеть не просто прочитать все записи из pg_class, но и отсортировать по столбцу relname — для этого как раз есть подходящий индекс:

Разные планы одного запроса
Использование индекса в плане мы видим как узел Index Scan, «стоимость» которого 44.15 хоть и выше, чем 34.90 для Seq Scan, зато позволяет избежать лишней операции сортировки и дает более «дешевый» суммарно план.
Кстати, в этом примере мы «выключили» возможность использовать Index Scan с помощью команды SET и параметра enable_indexscan. Таких «настроечных» параметров несколько десятков, но использовать их надо с большой осторожностью:

Не все параметры одинаково полезны
С их помощью мы можем запретить серверу использовать ту или иную операцию в планах, но не можем заставить его применять ровно ту, которую хочется нам. Зато, управляя «стоимостью» отдельных операций типа обращения к странице данных или обработки отдельной строки, можем попытаться побудить его делать это.
Например, при использовании в качестве хранилища какого-нибудь ленточного накопителя мы можем задать, что seq_page_cost («стоимость» извлечения страницы данных при последовательном чтении) будет совсем небольшим, а вот random_page_cost («стоимость» обращения к произвольной странице) — запредельным.
Если мы хотим увидеть в плане значения оказавших влияние параметров, используем опцию SETTINGS, которая добавит строку Settings: ... с набором установленных параметров и их значений в конец плана:

Параметры сервера в выводе плана
Объем данных
Следующая пара значений, которые нам выводит EXPLAIN — это «длина» и «ширина» данных. То есть предполагаемое количество записей, которое должен вернуть этот узел «вверх» по дереву плана и средняя «ширина» строки в байтах, определяемая на основании размерности типов тех данных, которые мы хотим получить в каждом из полей:

Количество и «ширина» записей позволяют оценить объем resultset
Понять, что это за поля, нам поможет опция VERBOSE, которая к каждому узлу добавит атрибутную строку Output: ... со списком столбцов:

VREBOSE позволяет увидеть возвращаемые поля
Банально умножив rows x width, можно грубо оценить, что SELECT oid вернет в нашем примере примерно 1.6KB данных, а SELECT * — в 66 раз больший объем!
Поэтому, если вдруг вы где-то по привычке и собственного удобства для пишете SELECT * из достаточно «широкой» таблички, а потом из всех полученных полей используете лишь одно-два, задумайтесь, насколько ваше удобство весомо относительно нагрузки на СУБД — база ведь достаточно «наивная» и делает ровно то, что вы ей написали.
Фактические показатели выполнения плана
Все описанные выше метрики можно получить без реального выполнения запроса. Но если надо увидеть именно реальные показатели, протокол фактического выполнения, необходимо воспользоваться формой EXPLAIN ANALYZE ... или «скобочной» опцией ANALYZE:

Синтаксис EXPLAIN ANALYZE
Если EXPLAIN говорит нам «планирую делать так», то EXPLAIN ANALYZE — «планировал делать вот так и в ходе выполнения получил такие-то показатели».
Причем надо понимать, что реальное выполнение запроса в этот момент таки происходит. То есть делать EXPLAIN ANALYZE DELETE, не завернув в откатываемую транзакцию, точно не стоит — можно лишиться части нужных данных.
Да и EXPLAIN ANALYZE SELECT бесконтрольно, особенно на бою, тоже запускать не стоит, если там вызывается какая-нибудь функция с сайд-эффектами — будет беда. Не факт, что будет обязательно, но запросто может случиться…
Но если мы все сделали правильно, то увидим у каждого узла еще и вторые скобочки, а в них — среднее время однократного выполнения в миллисекундах (actual time), фактическое среднее количество возвращенных строк за один цикл(rows) и количество циклов (loops) выполнения этого узла:
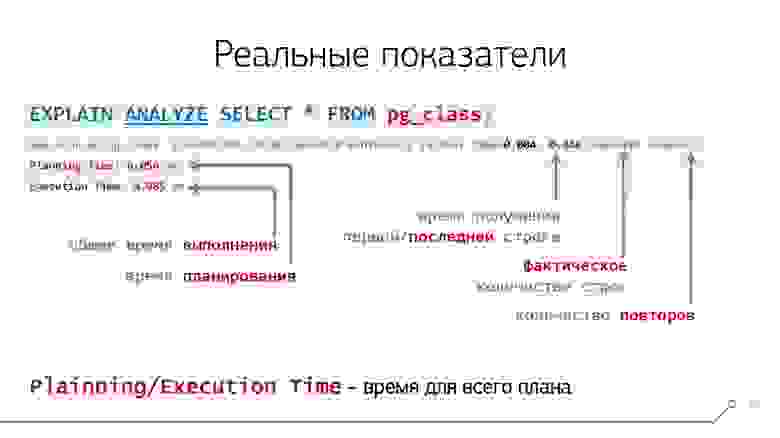
Фактические показатели выполнения
Например, для плана «для каждой записи в таблице A найди подходящую в таблице B» у узла чтения из таблицы A будет всего один цикл, который вернет все N записей (rows=N loops=1), а вот у узла чтения из таблицы B будет N циклов по одной записи (rows=1 loops=N).
Дополнительно, мы обычно получаем строки Planning Time, отражающую время, тоже в миллисекундах, затраченное на планирование запроса (да-да, оно ни разу не бесплатное!), и Execution Time, содержащую полное время самого выполнения, включая передачу результата клиенту.
То есть в нашем примере на планирование ушло 56 микросекунд, а на все выполнение — еще 85. Причем, 44 из них — по плану, а еще 41 «потерялось» на передаче данных.
Но если эта информация нам неинтересна, мы можем «выключить» ее с помощью опции SUMMARY off, равно как и «стоимости» через COSTS off:

«Выключаем» часть избыточной информации
Если мы «выключили» COSTS off, то скобочки у узла останутся только одни, но показатели в них будут — реальные, actual time.
А вот если в этих скобках будет написано (never executed), то узел вовсе не выполнялся — как в случае отсутствия записей в таблице A из примера выше:

Часть узлов в плане может так и не начать выполняться
На что обратить внимание
Если время планирования запроса сравнимо со временем его выполнения или, тем более, больше, то стоит крепко задуматься, стоит ли это планирование выполнять каждый раз.
Ведь если мы один раз поняли, что нам из этой таблички эффективнее всего читать Seq Scan'ом, она невелика, и других вариантов особо не предвидится, то зачем тратить на это время каждый раз для каждого запроса?

Подготовленные запросы помогут «обнулить» время планирования
Этого можно избежать — для этого существует функционал подготовленных запросов (prepared statements). В документации вы можете познакомиться с командами PREPARE, EXECUTE и DEALLOCATE, которые позволяют подготовить план запроса однократно.
Он «сохранится» на вашем подключении к базе, а дальше вы будете по его имени только подставлять в него необходимые значения («дай пользователя с логином Petya», «дай пользователя с логином Vasya», …) — заодно и трафик до сервера СУБД сэкономите, раз текст самого запроса каждый раз передавать уже не надо.
Второй момент, который в плане достаточно хорошо заметен — это несовпадение планируемого и фактического количества строк, возвращаемых узлом.

Идеальная статистика — ключ к успеху
Сильное отклонение в любую сторону — это плохо, оно дезинформирует базу, из-за чего она может выбирать неэффективные планы — и с этим «плохо» надо бороться. Как правило, это вызвано неактуальностью статистики после большого по объему удаления данных, или импорта данных с другим распределением — как я рассказывал в примере в начале.
Если база самостоятельно автоматически не успела пересобрать статистику, она будет ошибаться при планировании ваших запросов.
Выправить ситуацию нам помогут команды ANALYZE и VACUUM ANALYZE — первая из них позволяет «пересобрать» статистику по таблице, а вторая еще и разметит пространство под удаленными/измененными версиями записей как свободное.
Но все-таки лучше заставить PostgreSQL делать все это самостоятельно, правильно настроив параметры autovacuum для каждой из таблиц в соответствии с их смыслом:

Параметры autovacuum можно задать для таблицы
Но если у нас все настроено, статистика актуализируется вовремя, но что-то нам все равно не подходит, это может быть вызвано тем фактом, что статистика у нас все-таки недостаточна.
Например, в таблице у вас есть миллион разных идентификаторов с разной частотой появления для разных их диапазонов, а база по умолчанию собирает данные о распределении относительно всего лишь 100 значений (параметр default_statistics_target).
Понятно, что эти значения будут достаточно равномерно распределены по всему миллиону, но между ними будут интервалы по 10K значений, где распределение может быть совсем-совсем другим. Поэтому иногда для столбцов, содержащих большое количество уникальных значений, имеет смысл увеличить количество отсчетов гистограммы распределения с помощью команды SET STATISTICS, например, поставив вместо 100 значение 10000:

Улучшаем доступную статистику
Другой вариант — создать отдельный срез расширенной статистики сразу по нескольким столбцам одной таблицы с помощью команды CREATE STATISTICS — подойдет для функционально связанных данных.
Это может быть полезно, например, когда у вас типовая задача искать сразу по паре полей в EAV-представлениях объектов, или идентификатор пользователя является хэшем от его логина и поля имеют зависимые распределения.
Делаем выводы
Но вернемся к самим узлам плана и посмотрим, почему умение читать и понимать план — это искусство, как сказано в документации.
Начнем с самого простого, что из плана можно «вычитать»:

Время узла надо умножать на количество циклов
В общем-то про время сказать особо нечего, кроме того, что это walltime — то есть при оптимизации параллельных запросов гораздо эффективнее уделять внимание полному времени выполнения, суммарному по всем worker-процессам.
Следующий немаловажный параметр — объем передаваемых данных — «вверх» по дереву между узлами или «наружу», если это корневой узел:

«Ширину» записи — на их количество и снова на количество циклов
В нашем примере мы вычитываем из базы 418 строк «шириной» 265 байт, что дает примерно 108KB трафика. А теперь просто представьте, что это делают одновременно по какому-нибудь сигналу 100 подключенных клиентов — и вот мы уже получили в пике почти 100 мегабит трафика с сервера БД!
А дальше варианты, каких ресурсов не хватит раньше: производительности CPU сервера, объема сетевого буфера или пропускной способности сети…
И тут надо понимать, что если «внутри» PostgreSQL достаточно хорошо оптимизирован, и все повторные результаты может почти мгновенно формировать на основе кэша, то «наружу» он отдаст вам ровно то, что вы просите. Если на уровне драйвера работы с ним вы используете получение результата в подобном кейсе по одной записи чем-то вроде .fetchOne, то это еще ничего, а вот использование .fetchAll или «свертка» всего результата в JSON заставляет сервер одномоментно «выплюнуть» во внешний мир тонну трафика — лучше не стоит до такого доводить.
От «внешних» сетевых вещей погрузимся внутрь сервера: опция BUFFERS позволяет увидеть количество 8KB-страниц данных (подробнее, как устроено хранение данных в PostgreSQL, можно прочитать в документации), которые пришлось откуда-то прочитать (из памяти или с носителя):

А вот объем прочитанных данных умножать ни на что не надо!
В отличие от времени выполнения, количества строк или объема трафика, Buffers-значения уже не надо умножать на количество циклов узла — они и так просуммированы. Зато если умножить на «умолчательные» 8KB, можно вычислить физический объем.
При этом мы сразу видим, откуда данные были прочитаны, и можем оценить, насколько быстро/медленно это происходило:
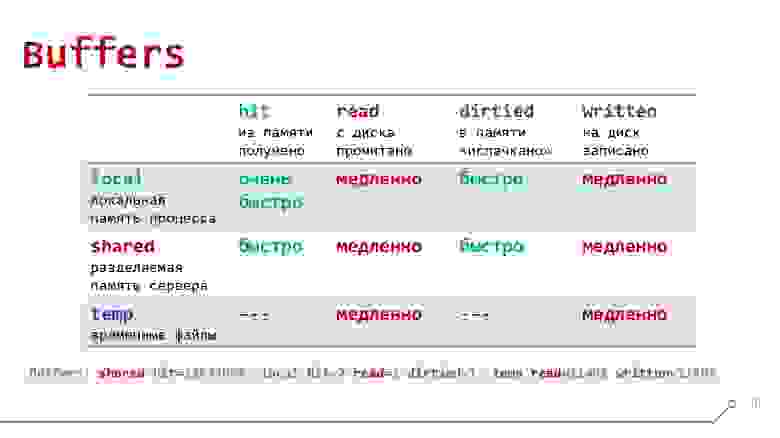
Варианты источников данных
local— самая быстрая работа с локальной памятью процесса, обслуживающего наше соединение с базойshared— все еще быстрое обращение к разделяемой между всеми процессами памяти сервера, где уже могут включаться семафоры для разделения доступаtemp— работа с временными файламиhit— получение из памятиread— чтение с диска с помещением в памятьdirtied— количество страниц, которые кто-то успел перезаписать, пока наш запрос до них добиралсяwritten— количество записанных нами страниц
Наиболее часто встречающиеся на практике комбинации:
shared hit— обычное быстрое чтение из кэш-памяти сервераshared read— медленное и грустное чтение с дискаlocal written/hit— обращение к небольшой временной таблице (TEMPORARY TABLE)temp written— сброс большого объема данных во временный файл — например, для сортировки миллиарда записей в ходе выполнения запроса
Но тут надо отметить, что buffers — это не «сами» прочитанные данные, а их «трафик». То есть если нам пришлось 100 раз обратиться к одной и той же странице данных (например, вся таблица из одной страницы и состоит), то мы увидим в плане именно значение 100, а не 1.
Тут важно отметить, что время выполнения может достаточно сильно меняться между запусками одного и того же (особенно «быстрого») запроса из-за нагрузки на сервер СУБД, наведенной процессами-соседями.
А вот суммарные значения
buffersостаются практически неизменны и представляют хороший критерий для оценки оптимизации запроса. Разве что отсутствующие в кэше или ранее вытесненные из него страницы при первом запуске окажутся вshared read, а при последующих «переедут» вshared hit.
Одна из типовых проблем, которая хорошо заметна при оптимизации «по buffers» — большой объем shared read — читаемого с диска. Традиционными симптомами являются периодические крики «Да вы одни всю СХД загрузили!» от админов-«железячников» и неудовлетворительное время отработки запросов.

Как уменьшить shared read
Для решения подобной проблемы есть два пути — быстрый и правильный.
Раз у нас данные читаются с диска, а не из памяти (что, конечно, было бы много быстрее) — значит, этой самой памяти нам не хватает! (Ваш К.О.) Поэтому для быстрого «затыкания дыры» подойдет возможность быстро «докинуть» памяти — это может быть как физическое увеличение на сервере, если база у вас постепенно со временем «подросла», и теперь весь доступный объем уже используется под pagecache, так и банальное увеличение параметра shared_buffers, если сервер был сконфигурирован несоответствующим нагрузке образом.
Конечно, увеличение shared_buffers может быть актуально, только если разные подключения к базе читают одни и те же данные, как правило. Если же, например, каждый коннект пишет-читает только «свои» сегменты данных, и они никак не пересекаются, то эффекта не будет.
А вот правильный путь гораздо сложнее — не читать так много, особенно лишнего. Например, банальное отсутствие подходящего индекса заставит PostgreSQL прочитать много больше данных, чем стоило бы, равно как и неправильно сделанное секционирование или плохо реализованная постраничная навигация.
То есть, как правило, правильный путь для уменьшения чтений с диска — изменение самого алгоритма работы запроса, что может быть недешево.

Как уменьшить temp written
На другой чаше весов — запись на диск. И если избежать записи самих данных не удастся никак, то вот над объемом временно записываемых файлов temp written можно «поколдовать».
И базовой рекомендацией опять-таки будет обратить внимание на ваш алгоритм. Вспомните слайд, где мы отключали возможность использования индекса и получили Seq Scan + Sort — понятно, что если нам придется для сортировки все вычитанные записи куда-то на диск предварительно «свапнуть», это не будет работать быстро. А с подходящим индексом, который вообще избавит нас от лишней операции сортировки — будет! Кстати, от сортировок можно избавляться разными способами, а не только созданием индексов.
Но если вдруг сортировать все равно надо, то стоит посмотреть, сколько там надо места-то. Возможно, стоит просто немного увеличить значение параметра work_mem с исходных 4MB пропорционально возможностям сервера и сложности ваших запросов (поскольку этот объем выделяется под узел плана). В этом случае операция будет происходить в памяти, без «свапа» на диск, с гораздо большей вероятностью, а ваш диск вздохнет с облегчением.
Но когда данных так много, что ни в какую память узла они не помещаются, можно рассмотреть вариант с промежуточной «ручной» выгрузкой в TEMPORARY TABLE, а их — вынести на RAMdrive с помощью параметра temp_tablespaces.
Следующая атрибутная строка I/O Timings, содержащая время, затраченное на обращение к диску в миллисекундах, может появиться в узлах плана, если на вашем сервере включен параметр track_io_timing (или вы включили его принудительно с помощью команды SET):

Время доступа к диску умножать — тоже не надо
read/write-время ходит обычно вместе с read/write-buffers, и, поделив одно на другое, мы можем узнать «скорострельность» нашего диска с базой в моменте выполнения запроса:

Определяем скорость диска
Если она оказывается сильно меньше, чем вы ожидали, то или всю его пропускную способность «пожрал» какой-то соседний процесс — вполне возможно вовсе не имеющий отношения к PostgreSQL, или он уже сильно деградировал на аппаратном уровне, и пора его заменить — например, SSD, который выдает единицы MB/s вместо GB/s.
Правда, тут необходимо разделять последовательный доступ к данным в Seq Scan-узлах, который на хороших SSD может и несколько GB/s демонстрировать и произвольный во всяких Index Scan, который всегда будет заведомо медленнее.
Подводя итоги анализа показателей узлов плана, вспомним еще раз фразу про «понимать план — это искусство». Поскольку для решения нашей исходной задачи «Кто самое слабое звено?» нам необходимо взять с узла его показатели, часть из них (actual time, rows) умножить на loops, а часть (Buffers, I/O Timings) — нет, а затем из полученного вычесть данные с подузлов по иерархии дерева:

Что-то надо умножать, а что — нет
При этом нельзя забывать о проблемах округления времени (оно выводится с точностью лишь до микросекунд, что при больших значениях loops дает ощутимую погрешность) и распределения ресурсов между CTE…
В общем, пользуйтесь нашим сервисом визуализации планов explain.tensor.ru, и не будете знать горя! Если вдруг не доверяете безопасность своих данных сторонним сервисам — можете приобрести self-hosted версию для развертывания в собственном закрытом контуре.
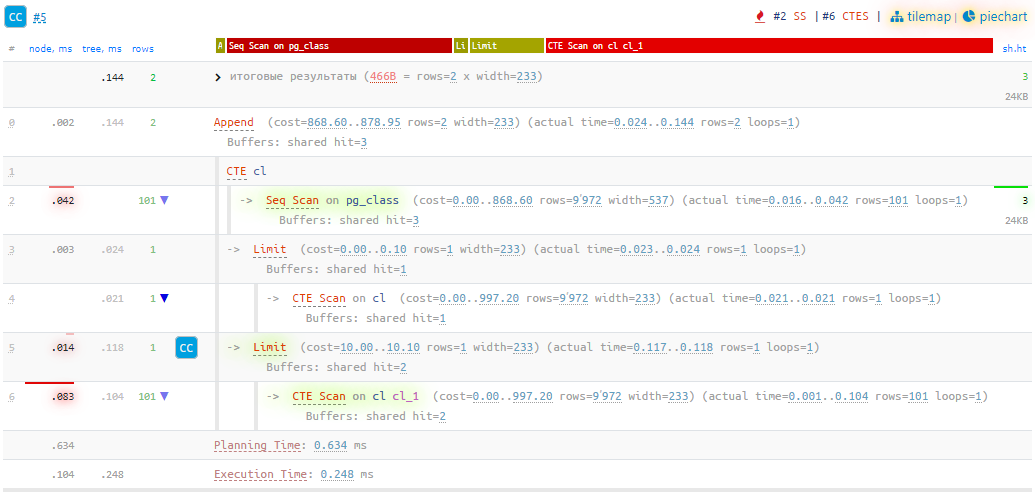
Пример визуализации на explain.tensor.ru
Если вам надо анализировать производительность сервера PostgreSQL в целом — включите на нем модуль auto_explain, и наш сервис поможет и здесь, предоставляя возможность сквозного анализа проблем от распределения нагрузки между типами запросов до интеллектуальных подсказок к конкретному неудачному плану.
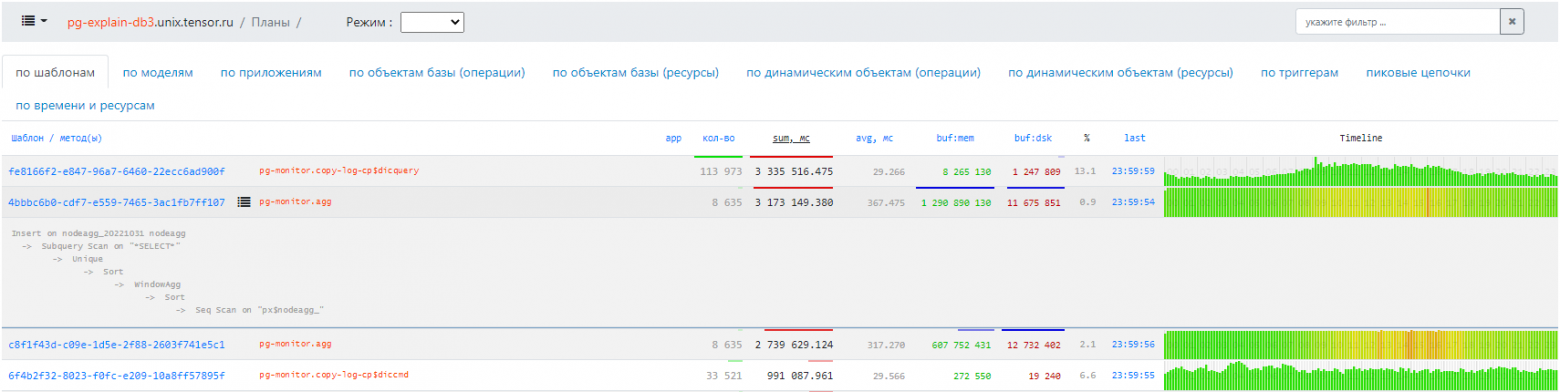
Пример визуализации сводки по шаблонам планов
В следующей части поговорим, а что это вообще за типы узлов — Seq Scan, Index Scan, какие они вообще бывают и чем отличаются друг от друга.
