Куда катится мир нейросетей: интервью с создателем iPavlov
Под катом — о глубоком обучении, текущем направлении развития ИИ, привязке нейросети GPT к логическому представлению о мире, нехватке кадров и о том, как начинался iPavlov: проект разговорного искусственного интеллекта.

Сегодня у нас физтех-беседа с Михаилом Бурцевым — заведующим лабораторией нейросетей МФТИ. Среди его научных интересов — нейросетевые модели обучения, нейрокогнитивные и нейрогибридные системы, эволюция адаптивных систем и эволюционные алгоритмы, нейроконтроллеры и робототехника. Про это все и пойдет речь.

— С чего началась история Лаборатории нейросетей и глубокого обучения на Физтехе?
— В 2015 году я принял участие в инициативе Агентства стратегических инициатив (АСИ) под названием «Форсайт-флот» — это такая многодневная площадка для обсуждения при Национальной технической инициативе. Ключевая тема касалась технологий, которые необходимо развивать, чтобы в России появились компании с потенциалом выхода на лидирующие позиции на глобальных рынках. Основной посыл был таков, что на сформированные рынки выйти крайне сложно, однако технологии открывают новые территории и новые рынки, и именно на них и надо выходить.
И вот мы плавали на теплоходе по Волге и обсуждали, какие же технологии могут позволить создать такие рынки и сломать текущие технологические барьеры. И в этой дискуссии о будущем выросла тематика с персональными помощниками. Понятно, что мы уже сейчас начали ими пользоваться — Alexa, Алиса, Сири… и было очевидно, что есть технические барьеры в понимании между человеком и компьютером. С другой стороны, накопилось немало наработок в исследованиях, например в области обучения с подкреплением, в обработке естественного языка. И становилось понятно: многие трудные задачи все лучше и лучше решаются с помощью нейросетей.
А я как раз занимался исследованиями нейросетевых алгоритмов. По результатам обсуждений «Форсайт-флота» мы сформулировали концепцию проекта по развитию технологий на ближайшее будущее, которая позднее трансформировалась в проект iPavlov. Это и стало началом моего взаимодействия с Физтехом.
Если говорить детальнее, то мы сформулировали три задачи. Инфраструктурная — создание открытой библиотеки для ведения диалогов с пользователем. Вторая — проведение исследований в области обработки естественного языка. Плюс решение конкретных бизнес-задач.
Партнером выступил Сбербанк, а сам проект сформировали под крылом Национальной технической инициативы.
Нам удалось быстро собрать очень хорошую команду на Физтехе, так как мы с 2015 года занимались развитием ИИ-сообщества: организовывали deephack.me — научные хакатоны на построение глубоких моделей, а также проводили научные школы, куда приглашали с онлайн-лекциями известных исследователей, таких как Йошуа Бенжио или Юрген Шмидхубер. Плюс сотрудничали с сообществом Open Data Science.
В начале 2018-го мы опубликовали первый репозиторий нашей открытой библиотеки DeepPavlov и последние два года видим стабильный рост ее пользователей (она ориентирована на русский язык и английский язык): у нас примерно 50% установок из США, 20–30% — из России. Получился в целом довольно успешный открытый проект.
Мы занимаемся не только разработкой, но и стараемся внести вклад в глобальную повестку исследований по разговорному ИИ. Понимая необходимость проведения академических соревнований в данной области, мы начали серию Conversational AI Challenges в рамках ведущей конференции в области машинного обучения NeuIPS.
При этом мы не только организуем соревнования, но и участвуем. Так, команда нашей лаборатории в прошлом году приняла участие в конкурсе от Amazon под названием Alexa Prize — создание чат-бота, с которым человеку было бы интересно разговаривать 20 минут.
Очередное соревнование начнется в ноябре
Это университетский конкурс, и ядро участников должно было состоять из студентов и сотрудников университета. Всего было 350 команд, семь отбираются в топ и три приглашают по результатам прошлого года — мы прошли в топ.
Наша диалоговая система провела порядка 100 тысяч диалогов с пользователями в США и под конец имела рейтинг порядка 3,35–3,4 из 5, что весьма неплохо. Это говорит о том, что нам удалось за довольно короткое время сформировать команду мирового уровня на Физтехе.
Сейчас лаборатория ведет проекты с разными компаниями, из крупных это Huawei и Сбербанк. Проекты в разных направлениях: AutoML, теории нейросетей и, конечно же, наше главное направление — NLP.
— Про задачи, которые раньше вызывали трудности у машинного обучения: почему именно глубокое обучение выстрелило в решении этих задач?
— Сложно сказать. Я сейчас немного упрощенно опишу мою интуицию. Все дело в том, что если в модели очень много параметров, то она удивительным образом может хорошо обобщать результаты на новые данные. В том плане, что число параметров может быть соизмеримо с количеством примеров. По этой же причине классический ML долгое время сопротивлялся напору нейросетей — кажется, что ничего хорошего не должно получиться при таком раскладе.
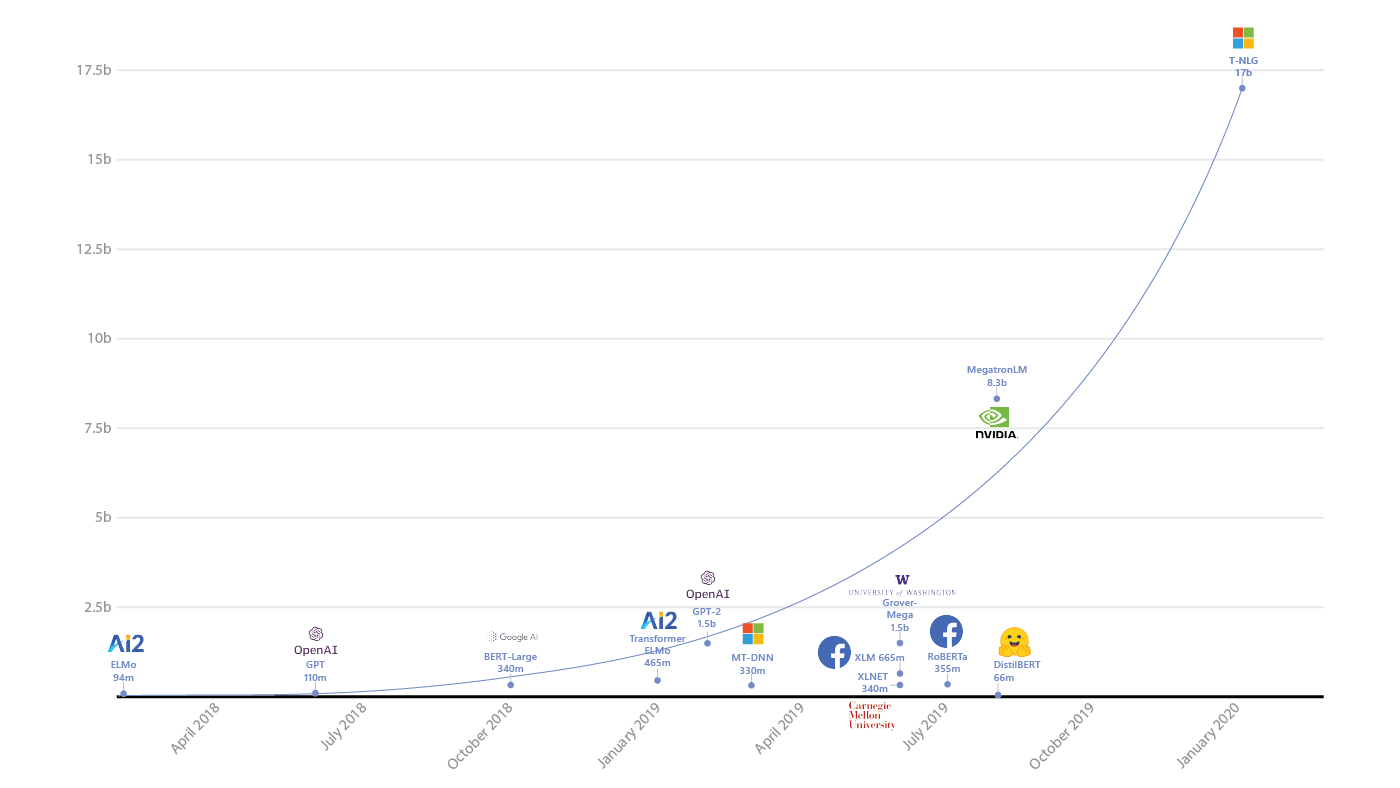
Рост количества параметров в моделях глубокого обучения (источник)
Удивительно, но это не так. Иван Скороходов из нашей лаборатории показал (.pdf), что в пространстве функции потерь нейросети можно найти практически любой двухмерный паттерн.
Вы можете выбрать такую плоскость, что каждая точка на этой плоскости будет соответствовать одному набору параметров нейросети. А их loss будет соответствовать произвольному паттерну, и, соответственно, можно подобрать такие нейросети, что они лягут прямо на эту картинку.
Очень забавный результат. Это говорит о том, что даже при таких абсурдных ограничениях нейросеть может выучить поставленную перед ней задачу. Вот примерно такая тут интуиция, да.

Примеры паттернов из статьи Ивана Скороходова
— В последние годы заметен существенный прогресс в области глубокого обучения, а виден ли уже горизонт, где мы уткнемся в предел показателей?

Рост размеров моделей ИИ и потребляемых ими ресурсов (источник: openai.com/blog/ai-and-compute/)
— У нас в NLP предел еще не ощущается, хотя кажется, что, например, в обучении с подкреплением что-то уже начало пробуксовывать. То есть за последние пару лет качественных изменений нет. Был большой бум от Atari до AlphaGo с гибридизацией c Monte Carlo Tree Search, а вот сейчас чего-то прям прорывного не ощущается.
А вот в NLP наоборот: рекуррентные сети, сверточные и вот наконец архитектура трансформера и сама GPT (одна из самых новых и интересных моделей трансформеров, часто используемая для генерации текстов — прим. автора) — это уже чисто экстенсивное развитие. И тут кажется, что еще есть запас для достижения чего-то нового. Поэтому в NLP планка сверху еще не видна. Хотя, конечно, тут почти невозможно ничего предсказать.
— Если представить развитие разработки языков и фреймворков для машинного обучения, то мы прошли от написания (условно) на чистом numpy, scikit-learn до tensorflow, keras — уровни абстракции росли. Что нас ждет дальше?
— Люди уже давно работают над фреймворками, где буквально из кубиков Лего складываются системы: взял пару коннекторов и бизнес-аналитику получил. В машинном же обучении, мне кажется, всегда будет баланс между low level и high level code: на чистом numpy модели уже никто не пишет и в основном используют высокоуровневые фреймворки. Но, например, у нас в NLP и разговорных системах присутствует фактически весь спектр: в целом мы покрываем нашими разработками существенную часть иерархии.
- Tensorflow / Pytorch — в начале у основания: тут именно написание конкретной модели машинного обучения.
- Библиотеки пайплайнов и конвейеров: оперируют NLP-моделями первого уровня — DeepPavlov.
- Библиотеки отдельных разговорных навыков: навык уже работает на уровне целого пайплайна — наш DeepPavlov Dream оперирует на данном уровне.
- Система переключения между навыками/пайплайнами, в том числе наш DeepPavlov Agent.
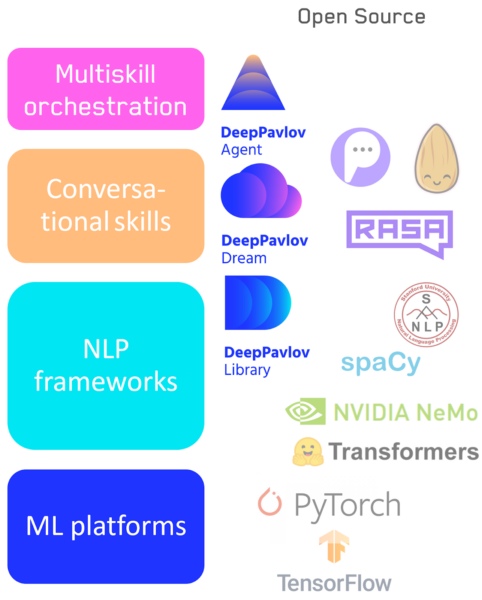
Технологический стек в области разговорного искусственного интеллекта
Разным приложениям и задачам нужна разная гибкость инструментов, и поэтому я не думаю, что какие-то элементы этой иерархии уйдут. Будут развиваться и низкоуровневые, и высокоуровневые системы по мере надобности и необходимости. Например, визуальные, доступные не программистам, но также и низкоуровневые библиотеки для разработчиков никуда не уйдут.
— А проводят ли сейчас социальные эксперименты по аналогии с классическим тестом Тьюринга, где люди должны понять, нейросеть перед ними или человек?
— Такие эксперименты проводятся регулярно. В Alexa Challenge человек должен был оценить качество разговора, при этом он не знал, с кем говорит — с ботом или человеком. Пока с точки зрения живого разговора разница между машиной и человеком существенна, но она с каждым годом сокращается. Кстати, наша статья об этом только что вышла в AI Magazine.
За рамками научной среды подобное делают регулярно. Вот недавно кто-то обучил GPT-модель, завел в Твиттере для нее аккаунт и стал постить ответы. Много людей подписалось, аккаунт набрал популярность, и никто не знал, что это нейросеть.Такой короткий формат, как в Твиттере, когда формулировки общие и «глубокомысленные», как раз хорошо подходит под систему вывода нейросетей.
— Какие направления вы считаете наиболее перспективными, где ждать скачок?
— (Смеется.) Я бы мог сказать, что именно в объединении всех моих любимых направлений и будет скачок. Попробую описать подробнее в рамках проблематизации. У нас есть текущие модели GPT на основе трансформера — у них нет никакой цели в жизни, они просто генерируют текст, похожий на человеческий, абсолютно бесцельно. И не могут привязать его к ситуации и к целям в контексте самого мира.
И один из путей — создать привязку логического представления о мире к GPT, который прочитал очень много-много текста, и в нем уже, и правда, немало логических связок. Например, через гибридизацию с «Викидатой» (это граф, описывающий знания о мире, в вершинах которого — статьи «Википедии»).
Если бы могли их соединить, чтобы GPT мог использовать базу знаний, это был бы скачок вперед.
Второй подход к проблеме бесцельности NLP моделей основан на интеграции в них понимания целей человека. Если у нас есть модель, которая может управлять генеративной языковой моделью, привязанной к графу знаний, то мы могли бы обучать ее помогать человеку достигать его целей. И такой помощник должен понимать человека через NLP, и цели человека, и ситуацию — далее ему нужно планировать действия. А в планировании лучше всего работает обучение с подкреплением.
Как это все объединить вместе и оптимизировать — вопрос открытый.
И последнее — поиск нейросетевых архитектур. Когда, например, с помощью эволюционных подходов мы ищем в пространстве архитектур оптимальные для данной задачи. Но это все будет решено не сегодня — тут слишком большое пространство для поиска.
Из хороших новостей: железо эволюционирует очень быстро и, возможно, это позволит нам лет через 5–10 объединить нейросетевые языковые модели, графы знаний и обучение с подкреплением. И вот тогда у нас будет качественный скачок в понимании машиной человека.
С помощью такого помощника можно будет запускать решение уже и других задач: анализ изображений, анализ медкарт или экономической ситуации, подбор товаров.
Поэтому я бы сказал, что с научной точки зрения в ближайшие лет пять мы увидим бурное развитие в области гибридизации — есть очень много крутых задач.
Ребята, дефицит кадров будет огромный, и есть отличный шанс получить новые и интересные результаты, да и оказать влияние на развитие индустрии. Подключайтесь — надо пользоваться моментом!
(Автор активно поддерживает этот ответ, ибо занимается именно такими системами.)
— Как начать погружение в глубинное обучение?
— Самый простой способ, мне кажется, — это пройти курс в deep learning school: изначально он был предназначен для старшеклассников, но и студентам вполне зайдет. Вообще, это отличное начинание, я помогал составлять расписание и читаю там вводные лекции.
Также рекомендую посмотреть вводные курсы от университетов, поделать задачки — в интернете просто куча всего. Самое лучшее из всех средств для «поиграть» — Colab от Google, там есть миллионы примеров задач, можно разобраться и запустить самые современные решения — без установки софта вообще на ваш компьютер.
Другой путь — поучаствовать в соревнованиях на Kaggle. А также вступить в Open Data Science — это русскоязычное сообщество по Data Science, где есть несколько каналов, посвященных deep learning. Там всегда есть люди, готовые помочь советом и кодом.
Вот такие основные пути.
Leader-ID: друзья, к стартовавшему сейчас отбору на акселератор по продвижению AI-проектов мы продумали вариант входа для инди-разработчиков. Нет, это не отменяет основных условий, по которым в интенсиве участвуют только команды. Но у нас много вопросов от одиночек, у которых сейчас нет своего проекта, а участвовать хочется (и это не только программисты, большой интерес к AI-проектам у дизайнеров). И мы нашли решение: поможем собрать команду и единомышленников через бесплатный онлайн-хакатон. Он начнется 10 октября в 12:00 и закончится ровно через сутки. На нем бот распределит вас на команды, а потом вы под его руководством пройдете основные этапы разработки проекта и подадите его на Архипелаг 20.35. Все подробности в личном кабинете, надо лишь успеть зарегистрироваться.