Kubernetes Observability: логгинг с EFK

 Автор статьи: Рустем Галиев
Автор статьи: Рустем ГалиевIBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Привет Хабр!
Сегодня поговорим про логирование (или же ведение журналов) в Kubernetes посредством EFK стека.
Приложения в контейнерах должны создавать журналы только в виде потоков событий и оставлять агрегацию и маршрутизацию другим службам в Kubernetes. Этот шаблон подчеркивается как фактор 11 журналов методологии The Twelve Factors App.
Обычно для стека объединяются три компонента: ElasticSearch, Fluentd и Kibana (EFK). Иногда стек использует Fluent Bit вместо Fluentd. Fluent Bit в основном функционально такой же, но легче по функциям и размеру. Другие решения иногда используют Logstash (ELK) вместо Fluentd.
Forwarding: Fluent Bit
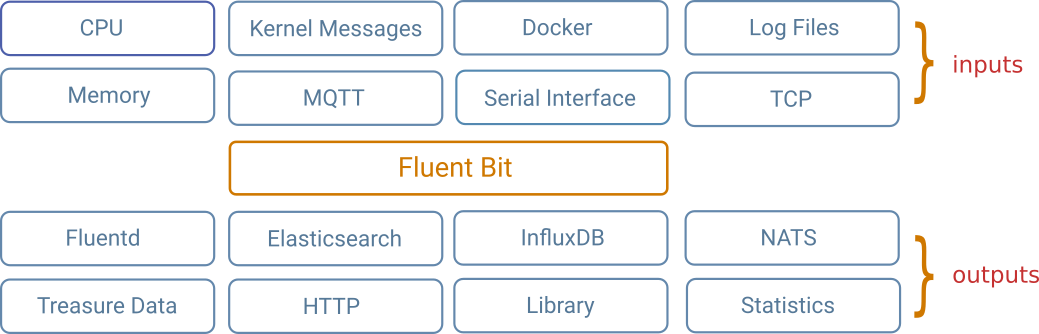
Fluentd — это сборщик данных с открытым исходным кодом, который позволяет унифицировать сбор и потребление данных для лучшего использования и понимания данных. В этом стеке Fluent Bit запускается на каждом узле (DaemonSet), собирает все журналы из /var/logs и направляет их в ElasticSearch. Мы используем более легкую вариацию Fluentd под названием Fluent Bit.
Другим вариантом ведения журнала является стек ELK, который включает Logstash в качестве замены решения для агрегации Fluent.
Агрегация: ElasticSearch.
Elasticsearch — поисковая система, основанная на библиотеке Lucene. Он предоставляет распределенную многопользовательскую полнотекстовую поисковую систему с веб-интерфейсом HTTP и документами JSON без схем.
Визуализация: Кибана.
Kibana — это плагин визуализации данных с открытым исходным кодом для Elasticsearch. Он предоставляет возможности визуализации поверх контента, проиндексированного в кластере Elasticsearch. Пользователи могут создавать гистограммы, линейные и точечные диаграммы, а также круговые диаграммы и карты на основе больших объемов данных.
Для Kubernetes существует множество способов собрать стек EFK, особенно с производственными или критически важными для бизнеса кластерами. Некоторые решения могут использовать службу ElasticSearch за пределами кластера, возможно, предлагаемую облачным провайдером. Для любого решения, развернутого в Kubernetes, рекомендуется использовать чарты Helm. Даже с чартами Helm существует множество решений, которые развиваются и конкурируют друг с другом.
Начнем.
Сперва проверим наш кластер:
{ clear && \
echo -e "\n=== Kubernetes Status ===\n" && \
kubectl get --raw '/healthz?verbose' && \
kubectl version --short && \
kubectl get nodes && \
kubectl cluster-info;
} | grep -z 'Ready\| ok\|passed\|running'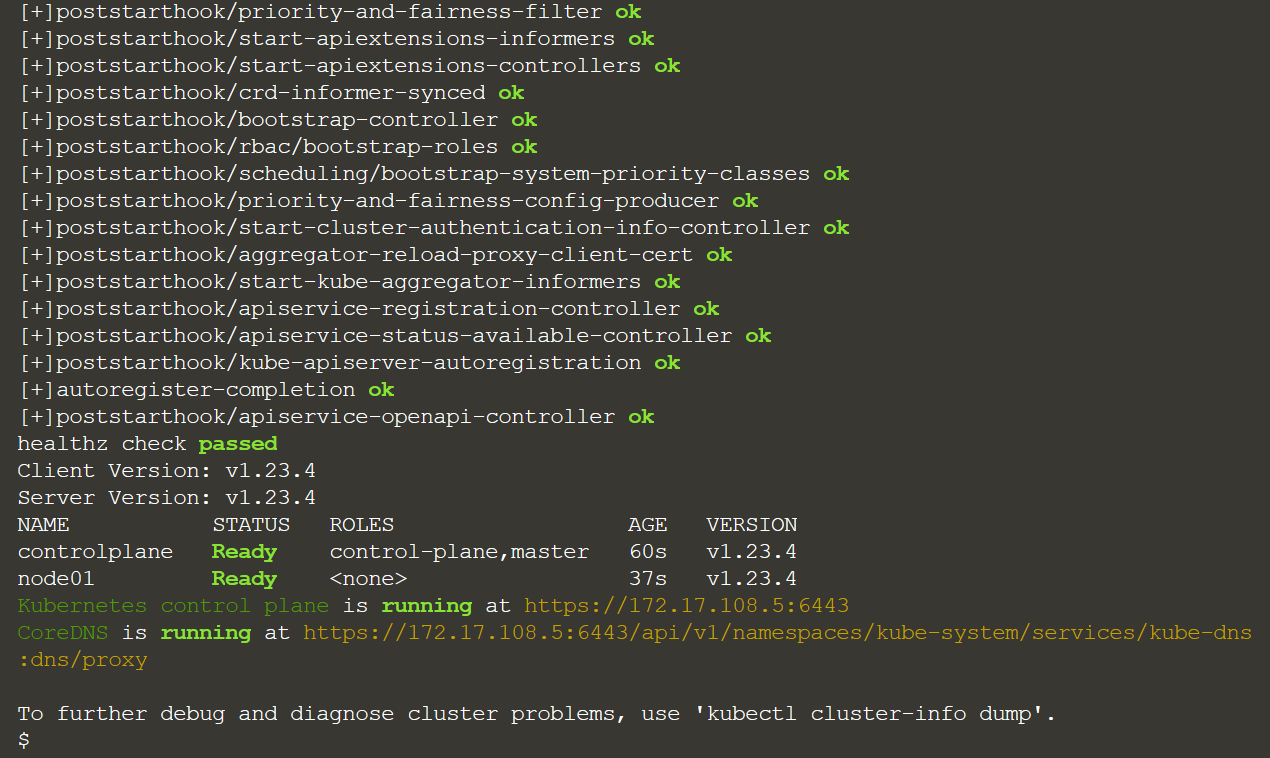
Также Helm:
helm version --short

Деплоим ElasticSearch.
Elasticsearch — это поисковая система RESTful, основанная на библиотеке Lucene. Он предоставляет распределенную многопользовательскую полнотекстовую поисковую систему с веб-интерфейсом HTTP и документами JSON без схем. Elasticsearch имеет открытый исходный код и разработан на Java.
Добавляем репозиторий чартов для установки чарта Helm:
helm repo add elastic https://helm.elastic.co && helm repo list

Добавим версию. Я использовал эту версию, просто потому что она привычнее, вы можете использовать любую другую.
VERSION=7.17.3
helm install elasticsearch elastic/elasticsearch \
--version=$VERSION \
--namespace=logs \
--create-namespace \
--set replicas=2 \
--set resources.requests.memory="600Mi" \
--set resources.limits.memory="600Mi" \
-f elastic-values.yaml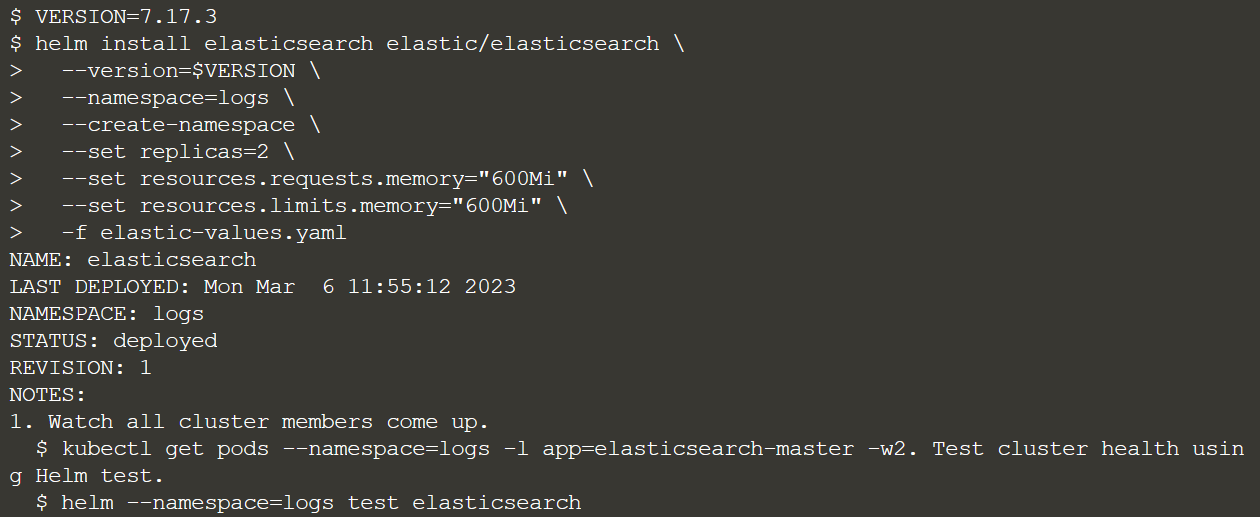
Деплоим Fluent Bit.
Fluent Bit — специализированный сборщик данных с открытым исходным кодом. Он предоставляет встроенные метрики и выходные интерфейсы общего назначения для централизованных сборщиков, таких как Fluentd. Создаем конфигурацию для Fluent Bit.
Мы устанавливаем чарт Fluent Bit Helm и передаем эндпоинт службы ElasticSearch в качестве параметра чарта.
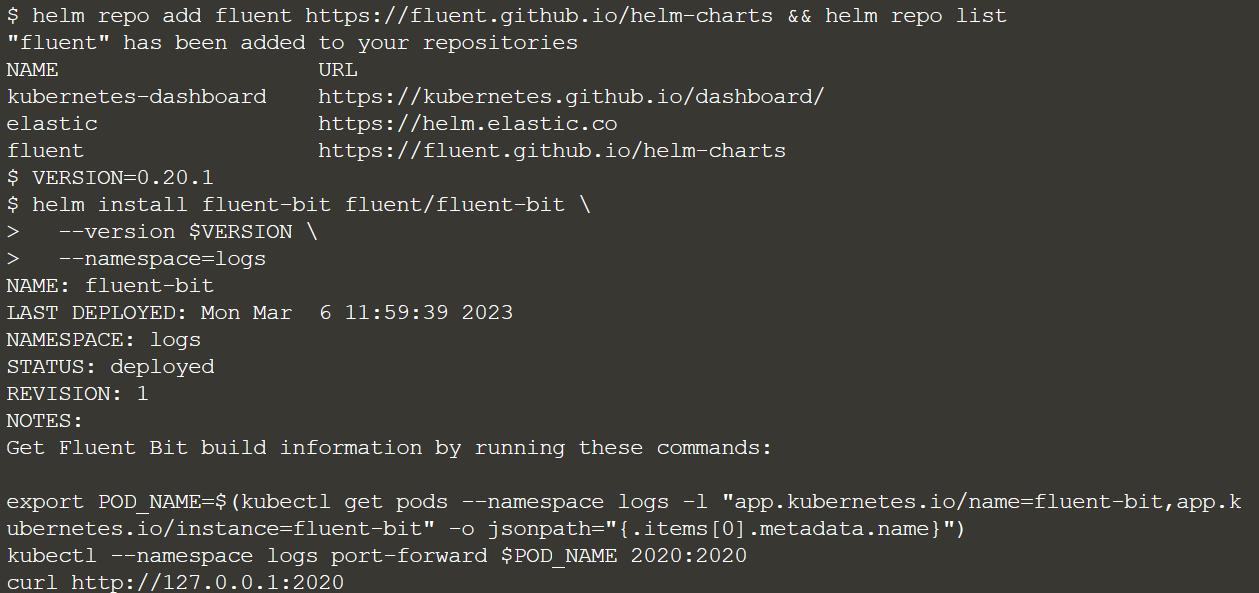
Добавляем репозиторий чартов для установки чарта Helm:
helm repo add fluent https://fluent.github.io/helm-charts && helm repo list
Версия (опять же можете использовать любую другую):
VERSION=0.20.1
Деплой:
Этот чарт установит DaemonSet, который запустит под Fluent Bit Pod на каждой рабочей ноде, убедимся.
kubectl get pods,daemonset --namespace logs -o wide

Деплой Kibana.
Kibana — это популярный пользовательский интерфейс с открытым исходным кодом, который позволяет визуализировать данные Elasticsearch и перемещаться по Elastic Stack. Мы можем сделать что угодно, от отслеживания загрузки запросов до понимания того, как запросы проходят через ваши приложения.
Установите Kibana Helm Chart. Сервис будет доступен через NodePort по адресу 31000:
VERSION=7.17.3
helm install kibana elastic/kibana \
--version=$VERSION \
--namespace=logs \
--set service.type=NodePort \
--set resources.requests.memory="1Gi" \
--set resources.limits.memory="1Gi" \
--set service.nodePort=31000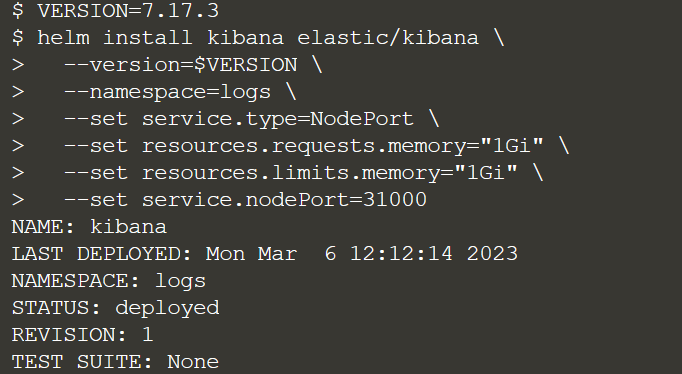
Внимание на безопасность. Этот NodePort преднамеренно выставляет логирование во «внешний мир» за пределы кластера, сделано это в демонстрационных целях. Тем не менее, для продакшн кластеров Kubernetes никогда не открывается сервис панели мониторинга Kibana без хотя бы защиты аутентификации.
Проверяем работающий стек.
Все три установки ElasticSearch, Fluent Bit и Kibana могут все еще инициализироваться. Чтобы проверить состояние этих развертываний, запустим watch:
watch kubectl get deployments,pods,services --namespace=logs
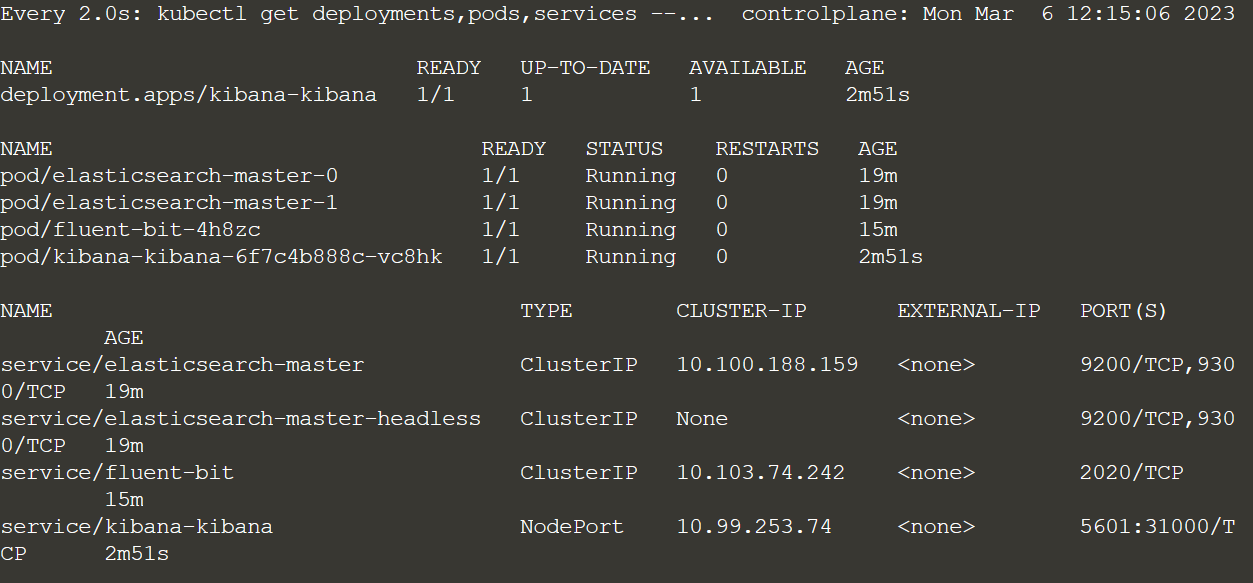
Все запущено, а значит выходим из watch:
ctrl+C или clear
Генерируем лог эвенты:
Имея стек наблюдения за логами, мы запускаем этот под, чтобы начать генерировать случайные логи:
kubectl run random-logger --image=chentex/random-logger
Проверим под:
kubectl get pods

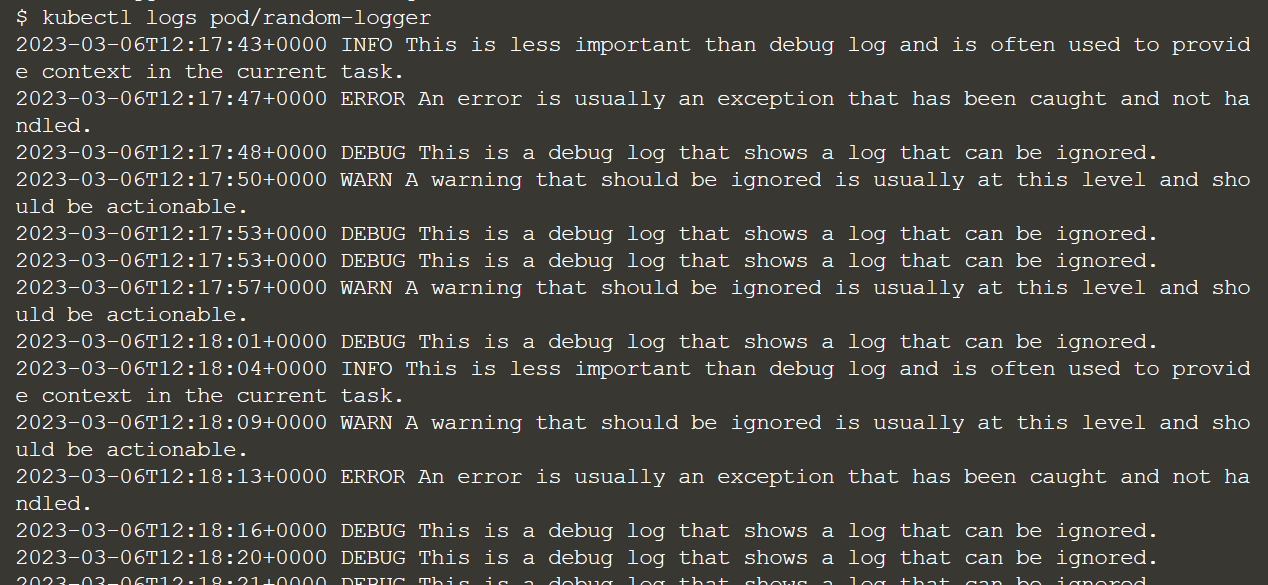
Работает, идем дальше. Мы проверяем фактические логи, которые сейчас генерируются с помощью этой команды:
kubectl logs pod/random-logger
Смотрим логи в Kibana.
Заходим в нашу Кибану и выбираем explore on my own:
Menu → Discover
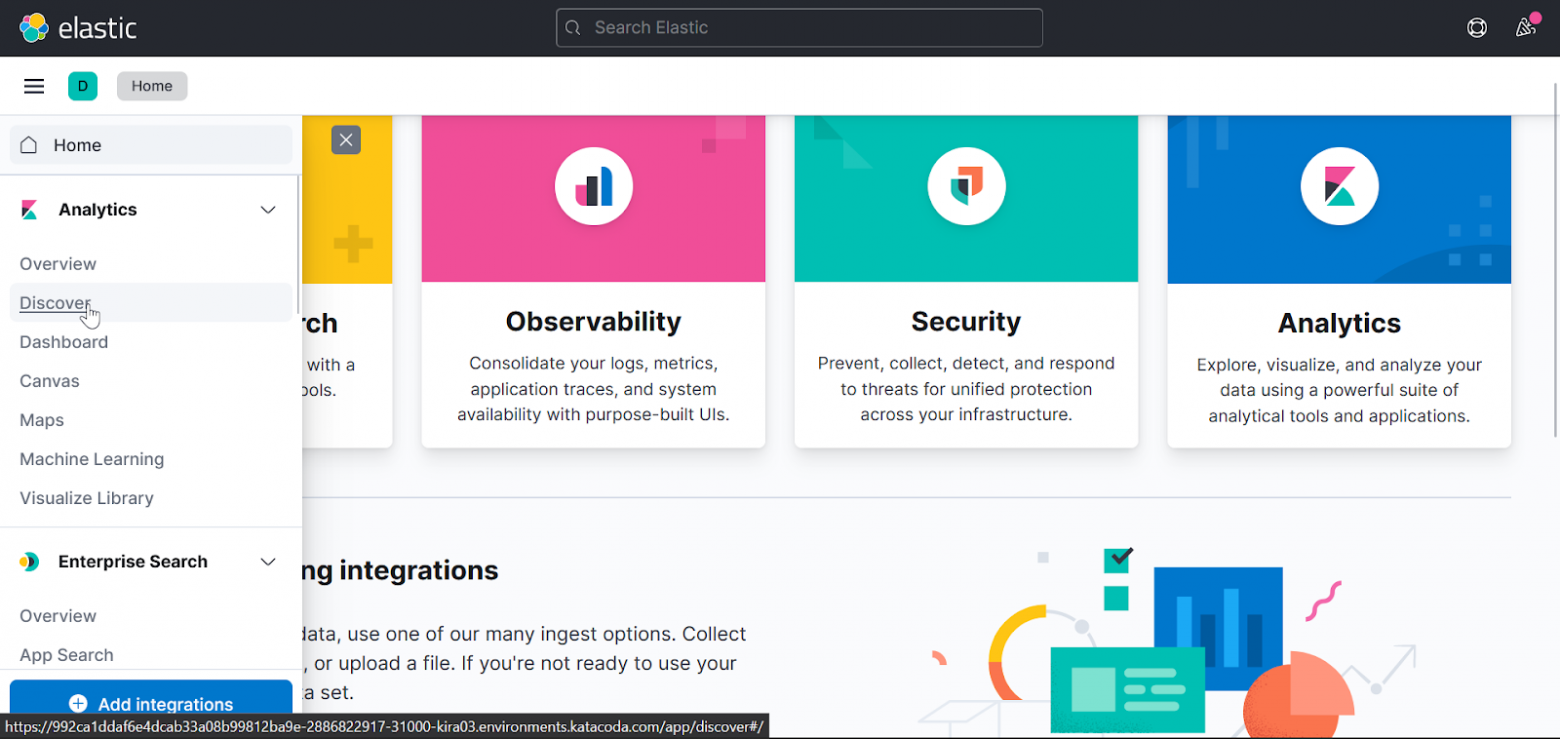
Create index pattern:
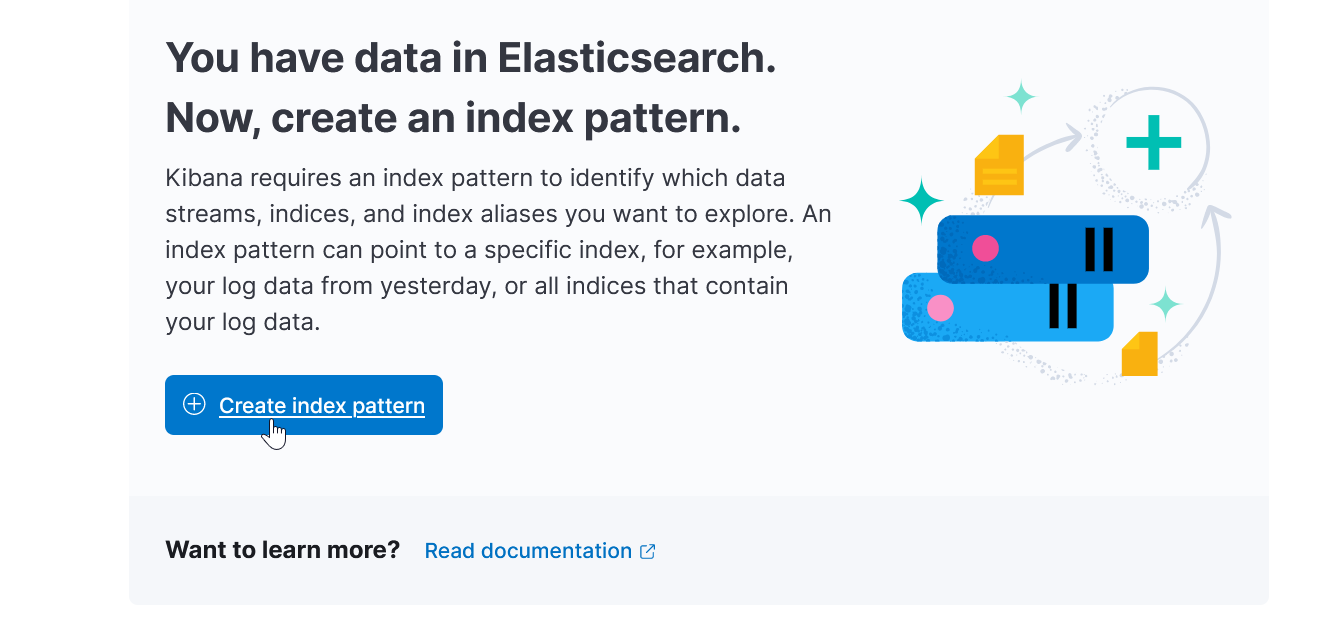
Далее:
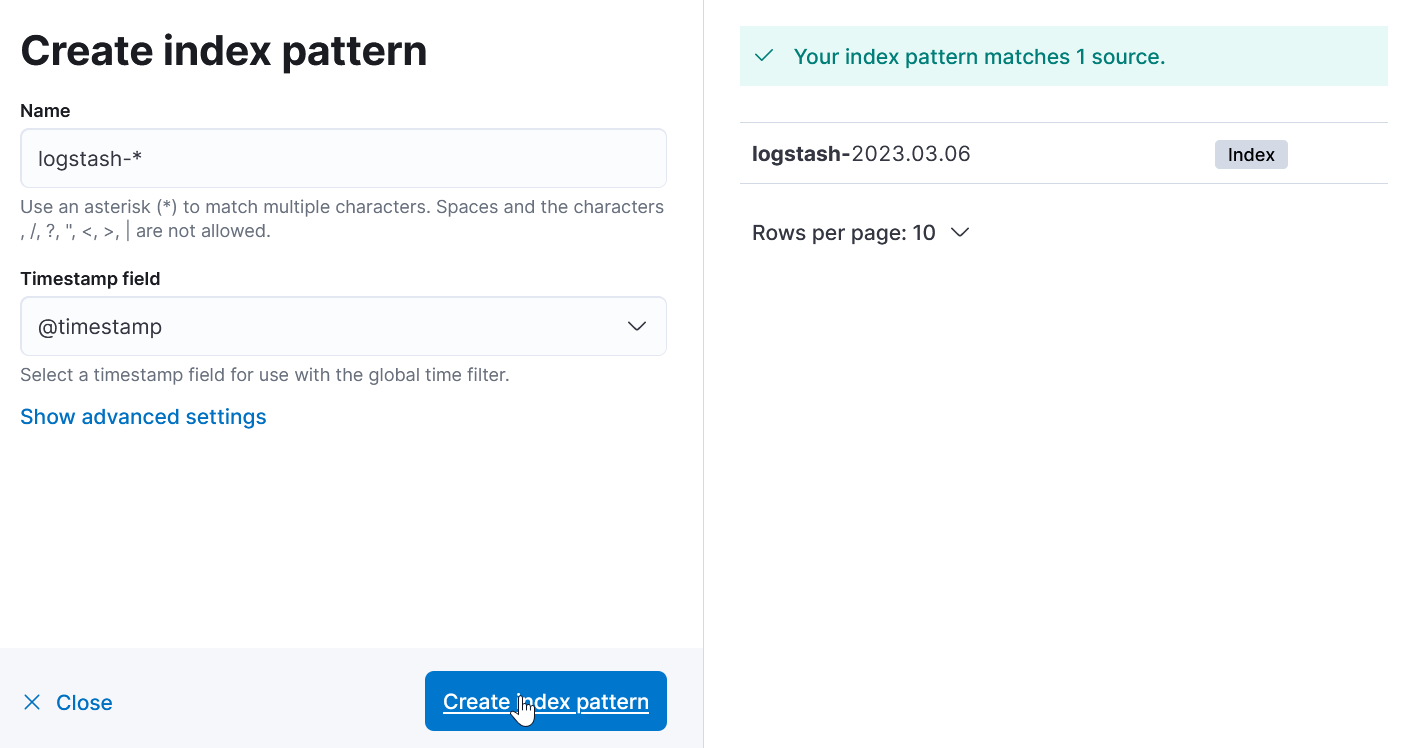
Вернемся на главную и опять discover:
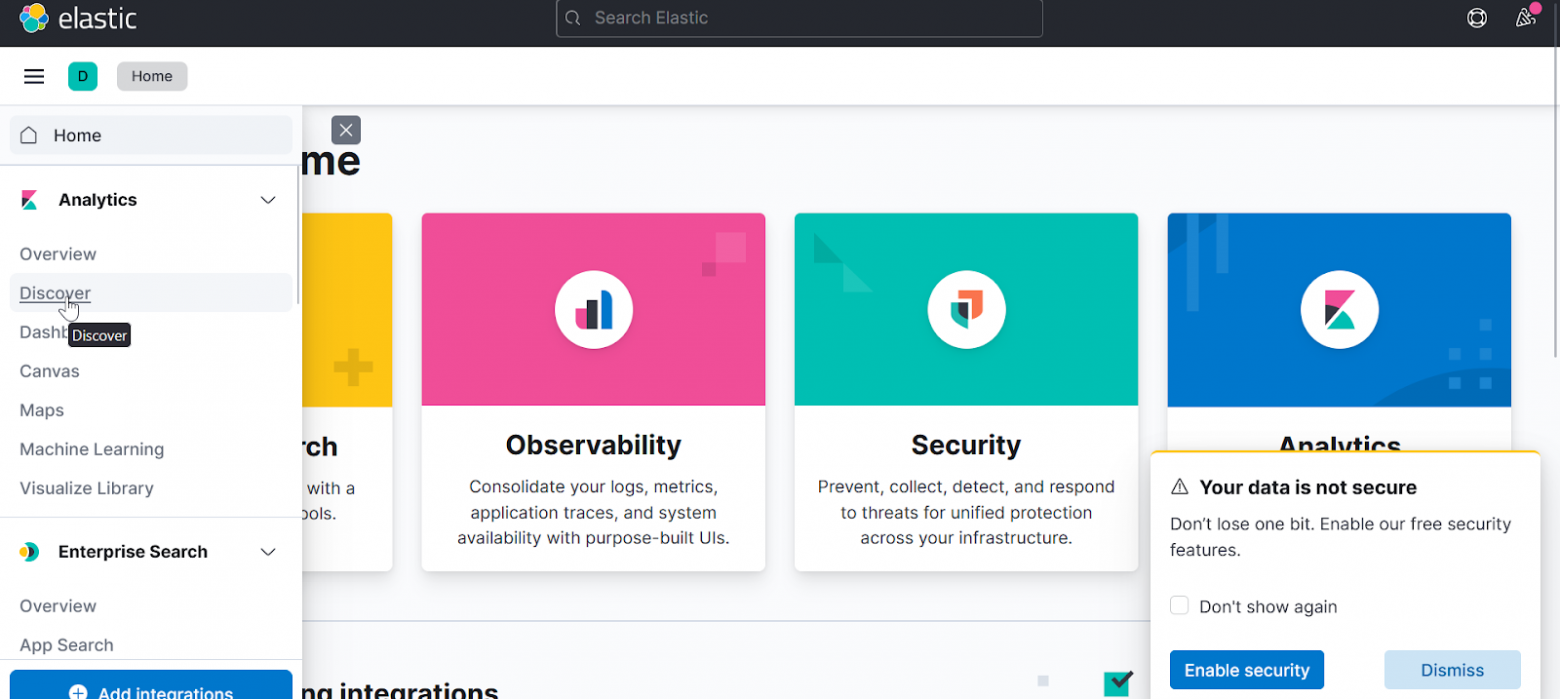
В поле available fields выбираем log:
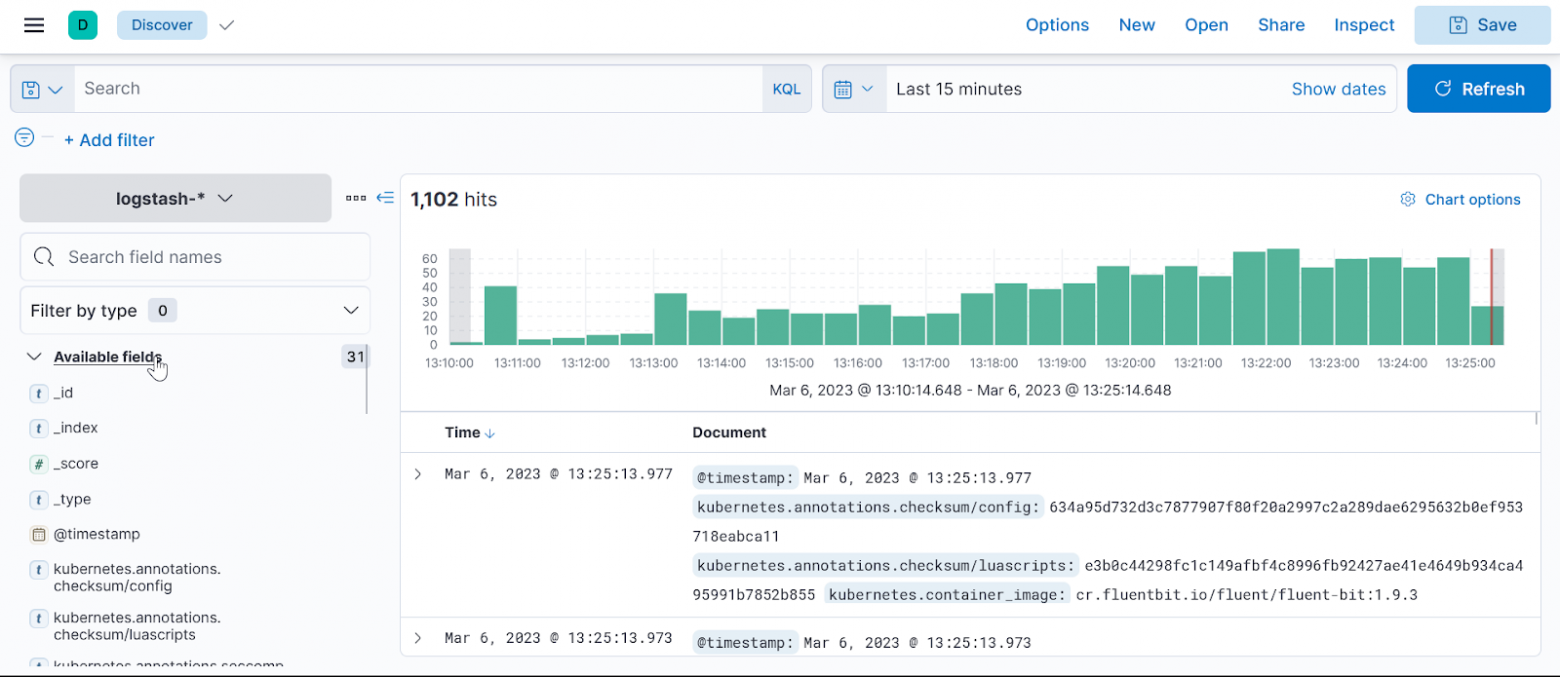
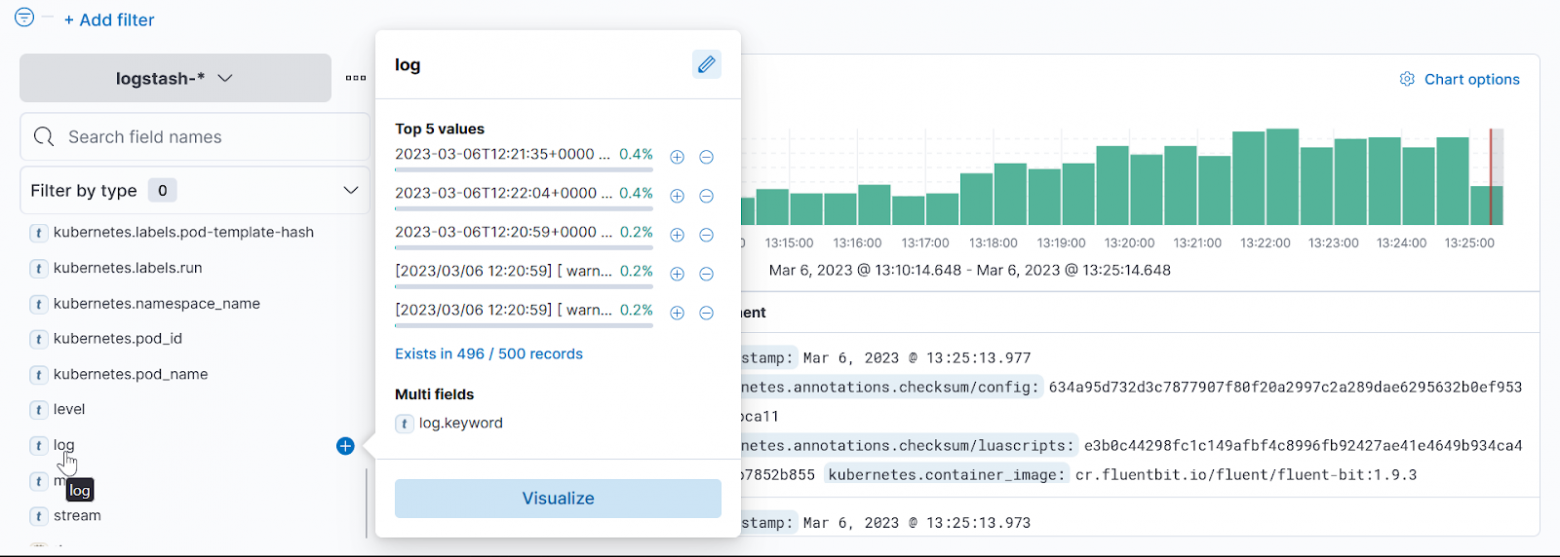
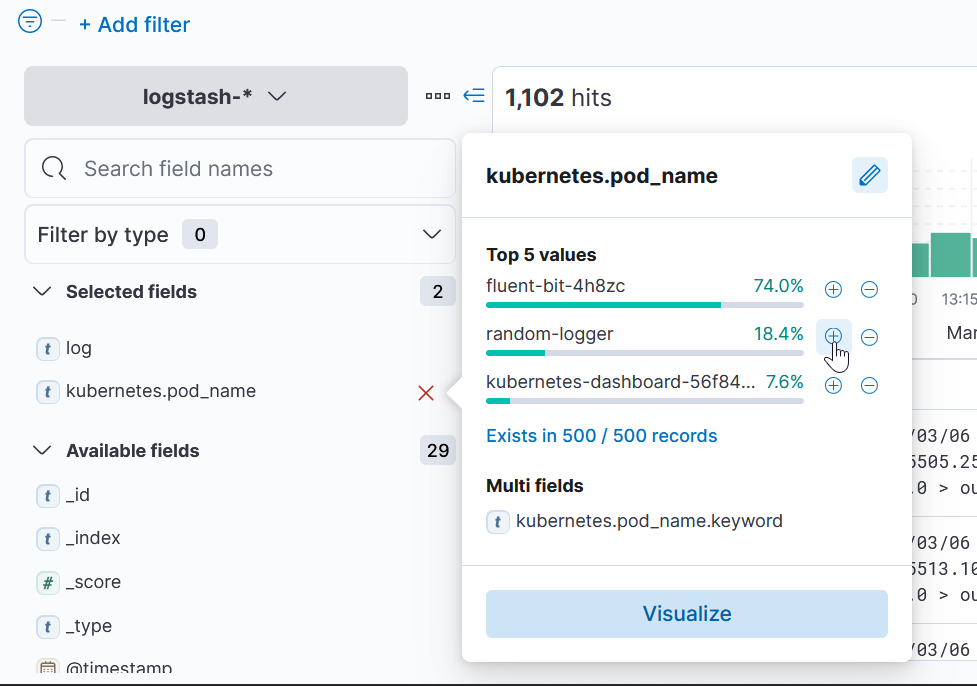
Еще возьмем kubernetes.pod-name и random logger:
Готово, мы отфильтровали логи нашего пода.
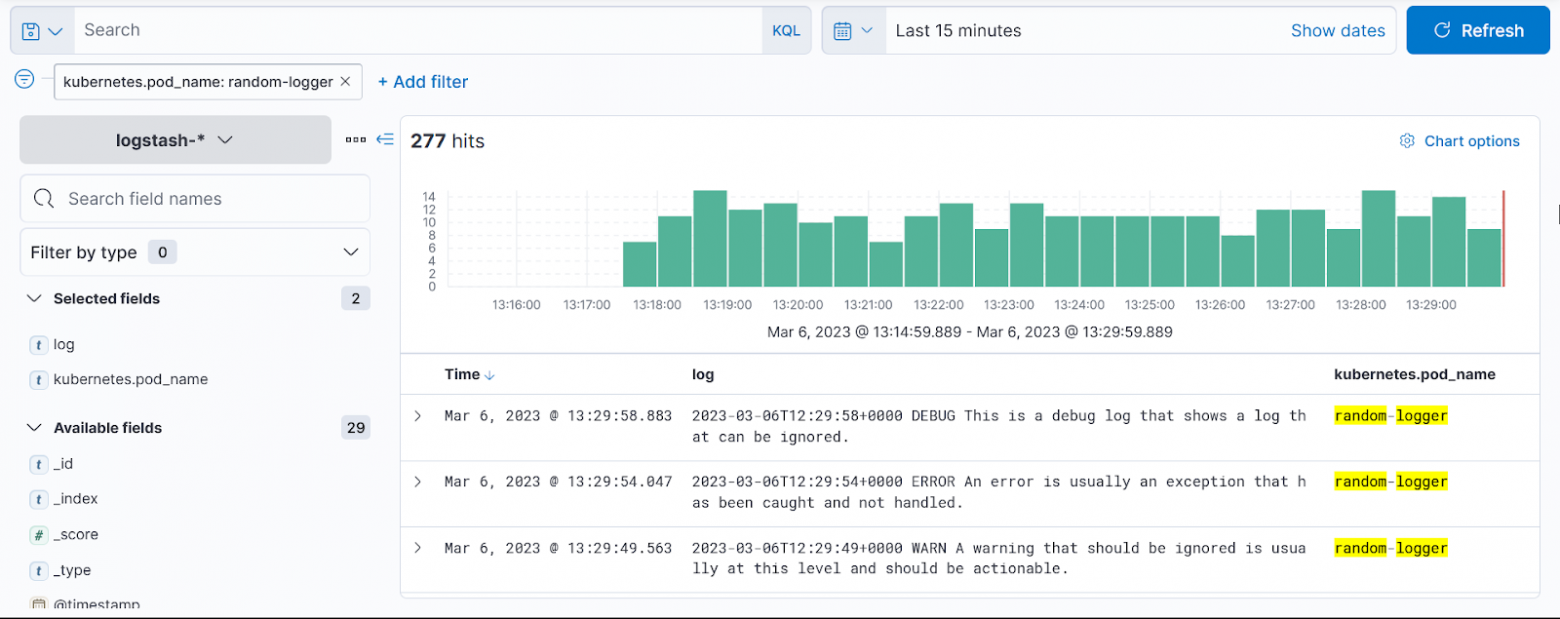
Этот стек — хороший пример того, как можно использовать Kubernetes для объединения различных инструментов, чтобы они могли работать согласованно для более крупного решения. В данном случае для агрегации логов. Поскольку Fluent Bit устанавливается как DaemonSet, он будет на каждом узле собирать логи и отправлять их в ElasticSearch, где, в свою очередь, Kibana предложит визуализировать конкретные данные на основе наших запросов.
В завершение хочу порекомендовать бесплатный урок от моих коллег из OTUS, где вы познакомитесь с новым инструментом лог-менеджмента Loki. Узнаете как его установить и настроить, а так же как проводить анализ с его помощью.
