Краудсорсинг в тестировании

Регрессионное тестирование — очень важная часть работы над качеством продукта. А чем больше продуктов и чем быстрее они развиваются, тем больше усилий оно требует.
В Яндексе научились масштабировать задачи ручного тестирования для большинства продуктов с помощью асессоров — удаленных сотрудников, работающих по совместительству на сдельной основе, и теперь в тестировании продуктов Яндекса, помимо штатных тестировщиков, принимают участие сотни асессоров.
В этом посте рассказано:
- Как удалось сделать задачи ручного тестирования максимально формализованными и обучить им сотни удаленных сотрудников
- Как удалось поставить процесс на промышленные рельсы, обеспечить тестирование в различных окружениях, выдерживать SLA по скорости и качеству
- С какими трудностями столкнулись и как их решали (а некоторые еще не решили)
- Какой вклад внесло тестирование асессорами в развитие продуктов Яндекса, как оно сказалось на частоте релизов и количестве пропускаемых багов.
В основе текста — расшифровка докладаОльги Мегорской с нашей майской конференции Heisenbug 2018 Piter:
Со дня доклада некоторые числа успели измениться, в таких случаях мы указали актуальные данные в скобках. Далее речь идёт от первого лица:
Сегодня мы поговорим про использование методик краудсорсинга для масштабирования задач ручного тестирования.
У меня довольно странное название должности: руководитель управления экспертных оценок. Попробую рассказать на примерах, чем я занимаюсь. В Яндексе у меня есть два основных вектора ответственности:

С одной стороны, это всё, что связано с краудсорсингом. Я отвечаю за нашу краудсорсинговую платформу Яндекс.Толока.
А с другой — команды, которые, если пытаться дать универсальное определение, можно отнести к «массовым неразработческим вакансиям». Туда входит много разного, и в том числе один из наших недавних проектов: ручное тестирование с помощью крауда, которое у нас называется «тестирование асессорами».
Моя основная деятельность в Яндексе заключается в том, что я свожу между собой левый и правый столбики с картинки и пытаюсь оптимизировать задачи и процессы в массовом производстве с помощью краудсорсинга. И сегодня мы поговорим как раз про это на примере задач тестирования.
Что такое краудсорсинг?
Начнём с того, что такое краудсорсинг. Можно сказать, что это замена экспертизы одного конкретного специалиста на так называемую «мудрость толпы» в тех случаях, когда экспертиза специалиста или очень дорога, или сложно масштабируется.
Краудсорсинг активно используется в самых разных областях далеко не первый год. Например, в NASA очень любят краудсорсинговые проекты. Там с помощью «толпы» исследуют и открывают новые объекты в галактике. Кажется, что это очень сложная задача, но с помощью краудсорсинга она сводится к достаточно простой. Есть специальный сайт, на который выкладывают сотни тысяч фотографий, сделанных космическими телескопами, и просят любых желающих поискать там определенные объекты. И когда много людей нашло подозрительно похожий на нужный им объект, дальше уже подключаются высокоуровневые специалисты и начинают это исследовать.
Если говорить в общем, то краудсорсинг — это такой метод, когда мы берём какую-то большую высокоуровневую задачу и делим её на много простых и однородных подзадач, на которые собираются множество независимых друг от друга исполнителей. Каждый из исполнителей может решить одну или несколько этих маленьких задачек, а все вместе они в итоге работают на одно большое общее дело и собирают большой результат для высокоуровневой задачи.
Краудсорсинг в Яндексе
Мы уже несколько лет как начали развивать нашу систему краудсорсинга. Изначально использовали её для задач, связанных с машинным обучением: для сбора обучающих данных, для настройки нейронных сетей, алгоритмов поиска и так далее.
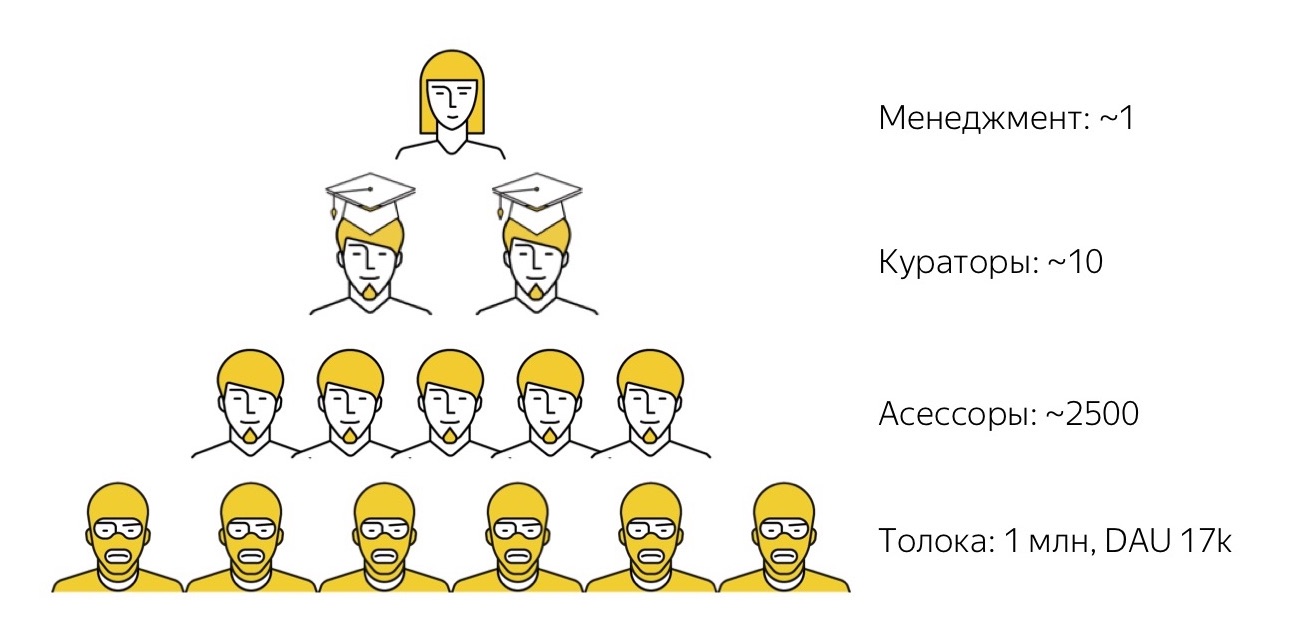
Как устроена наша экосистема краудсорсинга? Во-первых, у нас есть Яндекс.Толока. Это открытая краудсорсинговая платформа, на которой любой желающий может зарегистрироваться или как заказчик (разместить свои задания, выставить за них цену и собирать данные), или как исполнитель (находить интересные задания, выполнять их и получать небольшое вознаграждение). Толоку мы запустили несколько лет назад. Сейчас у нас больше миллиона зарегистрированных исполнителей (мы называем их толокерами), и каждый день в системе около 17 000 человек выполняют задания.
Так как мы изначально создавали Толоку с прицелом на задачи, связанные с машинным обучением, то традиционно повелось, что большинство задач, которые выполняют толокеры, — это такие задачки, которые очень просто и тривиально сделать человеку, но пока ещё довольно сложно алгоритму. Например, посмотреть на фотографию и сказать, есть на ней взрослый контент или нет, или прослушать аудиозапись и расшифровать то, что вы услышали.
Толока — это очень мощный инструмент в плане производительности и количества данных, которые он помогает собирать, но довольно нетривиальный в использовании. Люди на картинке одеты в жёлтые балаклавы, потому что все исполнители в Толоке анонимны и неизвестны для заказчиков. И управлять этими тысячами анонимусов, делать так, чтобы они делали именно то, что вам нужно — совершенно не простая задача. Поэтому не все задачи, которые у нас есть, мы пока что умеем решать с помощью вот такого абсолютно «дикого» крауда. Хотя к этому и стремимся, позже об этом ещё скажу.
Поэтому для более высокоуровневых задач у нас есть следующий уровень исполнителей. Это люди, которых мы называем асессорами. Само слово «асессоры», может быть, немножко странное. Оно пошло от слова «assessment», то есть «оценка», потому что изначально асессоры использовались у нас для сбора субъективных оценок качества поисковой выдачи. Эти данные потом использовались как target для машинного обучения функции ранжирования поиска. С тех пор прошло много времени, асессоры стали выполнять много самых разных других задач, поэтому теперь это уже нарицательное слово: задачи изменились, но слово осталось.
По сути, наши асессоры — это штатные сотрудники Яндекса, но работающие part-time и полностью удалённо. Это ребята, которые работают на собственном оборудовании. Мы с ними взаимодействуем только удалённо: мы их удалённо отбираем, удалённо обучаем, удалённо с ними работаем и, при необходимости, удалённо увольняем. С большинством из них мы никогда в жизни очно не пересекаемся. Они работают по любому удобному для себя графику, днём или ночью: у них есть минимальные нормы, эквивалентные примерно 10–15 часам в неделю, и они могут отрабатывать это время так, как им удобно. Асессоры решают самые разные задачи: они связаны и с поиском, и с техподдержкой, и с какими-то низкоуровневыми переводами, и с тестированием, о котором мы будем дальше говорить.
Как правило, какое бы задание мы ни взяли, из группы выполняющих его асессоров всегда выделяются наиболее талантливые люди, у которых это получается лучше, которым именно эта задача более интересна. Мы их выделяем, наделяем громким званием суперасессоров, и эти ребята выполняют уже более высокоуровневые функции кураторов: проверяют качество работы других людей, консультируют их, поддерживают и так далее.
И только на самом верху нашей пирамиды у нас появляется первый full-time-сотрудник, который сидит в офисе и управляет этими процессами. Таких людей, которые уже куда более высокого уровня и имеют сильные технические и менеджерские скиллы, у нас гораздо меньше, буквально единицы. Такая система позволяет нам приходить к тому, что эти единицы «высокоуровневых» людей выстраивают пайплайны и управляют производственными цепочками, в которых дальше задействованы десятки, сотни и даже тысячи человек.
Сама по себе эта схема не нова, ещё Чингисхан её успешно применял. У неё есть несколько интересных свойств, которые мы стараемся использовать. Первое свойство довольно понятное — такая схема очень легко масштабируется. Если какую-то задачу нужно вдруг начать делать больше, то нам не нужно искать дополнительные площади в офисе, чтобы куда-то посадить человека. Нам вообще можно очень мало о чём думать: просто залить побольше денег, на эти деньги нанять побольше исполнителей, и из этих исполнителей наверняка вырастут более талантливые ребята в академических шапочках, и вся эта система будет масштабироваться и дальше.
Второе свойство (и это было удивительно для меня) — такая пирамида очень хорошо тиражируется вне зависимости от предметной области, в которой её применять. Это относится и к той области, о которой мы сегодня будем говорить, — задачам ручного тестирования.
Тестирование краудом
Когда мы запускали процесс тестирования с помощью крауда, самой большой проблемой было отсутствие позитивного референса. Не было никакого опыта, на который мы могли сослаться и сказать: «Ну вот эти ребята так сделали, они уже тестируют с помощью крауда в очень похожей на нас схеме, и там всё хорошо, значит, и у нас всё будет хорошо». Поэтому нам приходилось опираться только на свой личный опыт, который был отделён от предметной области тестирования и больше связан с настраиванием аналогичных производственных процессов, но в других областях.
Поэтому нам пришлось делать то, что мы умеем. Что мы умеем? По сути — декомпозировать одну задачу на задачи разных уровней сложности и раскидывать их по этажам нашей пирамиды. Посмотрим, что у нас получилось.
Во-первых, мы посмотрели на задачи, которыми заняты наши тестировщики в Яндексе, и попросили их условно раскидать эти задачи по разным уровням сложности. Это такое «среднее по больнице»:
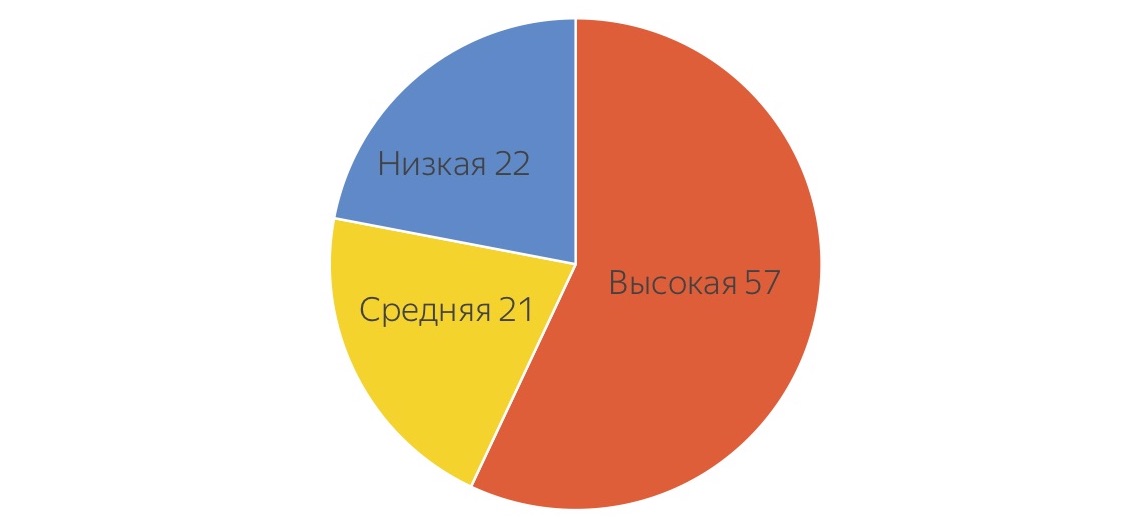
Они оценили, что только 57% своего времени тратят на сложные высокоуровневые задачи, а где-то по 20% уходит на совсем низкоуровневую рутину, от которой все мечтают избавиться, и на задачи чуть посложнее, которые тоже вроде бы можно делегировать. Ободрённые этими цифрами, показывающими, что можно почти половину работы куда-то передать, мы приступили к построению тестирования с помощью крауда.
Какие цели мы перед собой ставили?
- Сделать так, чтобы тестирование перестало быть узким местом, которым оно периодически являлось в производственных процессах, когда релиз готов, но он ждёт, пока пройдёт тестирование.
- Разгрузить наших классных, очень умных, высокоуровневых специалистов — штатных тестировщиков — от рутины, заняв их действительно интересными и более высокоуровневыми задачами.
- Повысить разнообразие окружений, в которых мы тестируем продукты.
- Научиться обрабатывать пиковые нагрузки, потому что наши тестировщики говорили, что у них часто бывает неравномерная нагрузка. Даже если в среднем команда справляется с задачами, при возникновении какого-то пика его потом приходится очень долго разгребать.
- Так как мы в Яндексе всё равно в некоторых проектах тратили довольно заметные деньги на аутсорс-тестирование, мы подумали, что хотелось бы за те деньги, которые мы тратим, получать чуть больше результатов, оптимизировать наши траты на аутсорс.
Хочу подчеркнуть, что среди этих целей нет задачи заменить тестировщиков краудом, как-то их ущемить и так далее. Всё, что мы хотели сделать — помочь командам тестирования, избавив их от низкоуровневой рутинной нагрузки.
Давайте посмотрим, что у нас в итоге получилось. Я сразу скажу, что основные задачи по тестированию сейчас выполняются не самым нижним уровнем «пирамидки», толокерами, а асессорами, нашими штатными сотрудниками. Дальше речь пойдёт в основном про них, кроме самого конца.
Сейчас асессоры выполняют у нас задачи регрессионного тестирования и проходят всякие опросы вроде «посмотрите на это приложение и оставьте свой фидбэк». На полноценной задаче регресса у нас сейчас квалифицировано около 300 человек (прим.: с момента доклада стало 500). Но эта цифра условная, потому что система, которая у нас построена, работает на произвольное количество людей: столько, сколько нам нужно. Сейчас наши производственные нужды покрываются примерно таким количеством людей. Это не значит, что в каждый момент времени все они сидят наготове и готовы выполнять задание: поскольку асессоры работают в гибком графике, в каждый момент времени готовы подключиться где-то 100–150 человек. Но всего пул исполнителей примерно такой. А простые задания, вроде опросов, когда нужно просто собрать неформализованный фидбэк от пользователей, у нас проходит через гораздо большее количество людей: в таких опросах участвуют сотни и тысячи асессоров.
Так как это люди, которые работают на собственном оборудовании, у каждого асессора есть свои личные девайсы. Это, по дефолту, десктоп и какое-то мобильное устройство. Соответственно, мы тестируем наши продукты на личных устройствах асессоров. Но понятно, что у них есть не все возможные устройства, поэтому если нам нужно тестирование в каком-то редком окружении, мы используем удалённый доступ через ферму устройств.
Сейчас тестирование краудом используют уже как стандартный продакшн-процесс около 40 (прим.: теперь уже 60) сервисов и команд Яндекса: это и Почта, и Диск, и Браузер (мобильный и десктопный), и Карты, и Поиск, и много-много кто. Это любопытно. Когда мы осенью 2017-го ставили себе планы на конец третьего квартала, у нас была амбициозная цель: привлечь хоть как-нибудь, «хоть обманом, хоть подкупом», хотя бы пять команд, которые бы использовали наши процессы тестирования с помощью крауда. И мы очень сильно уговаривали всех, говорили: «Да вы не бойтесь, давайте, попробуйте!» Но спустя буквально несколько месяцев у нас оказались десятки команд.
И теперь мы решаем другую задачу: как успевать подключать всё новые и новые команды, которые хотят присоединиться к этим процессам. Так что можно считать, что сейчас это уже стандартная практика в Яндексе, которая летит очень хорошо.
Что у нас получилось с точки зрения производственных показателей? Сейчас мы делаем в день около 3 000 кейсов регрессионного тестирования (прим.: на октябрь 2018-го уже 7000 кейсов). Тестовые запуски в зависимости от величины проходят от нескольких часов до (в пике) 2 суток. Большая часть проходит за несколько часов, в пределах суток. Внедрение такой системы позволило нам снизить стоимость примерно на 30% по сравнению с тем периодом, когда мы использовали аутсорс. Это позволило командам релизиться намного чаще, в среднем где-то в несколько раз, потому что релизы стали проходить с той скоростью, которая доступна разработке, а не той, которая доступна тестированию, когда оно иногда становилось узким местом.
Теперь я постараюсь рассказать, как мы вообще выстроили производственный процесс, который позволил нам прийти к этой схеме.
Инфраструктура
Начнём с технической инфраструктуры. Те из вас, кто видел Толоку как платформу, представляют себе, как выглядит её интерфейс: можно прийти в систему, выбирать задания, которые вам интересны, и выполнять их. Для внутренних сотрудников у нас есть внутренний инстанс Толоки, в котором мы в том числе раздаём задания разного типа для наших aсессоров.
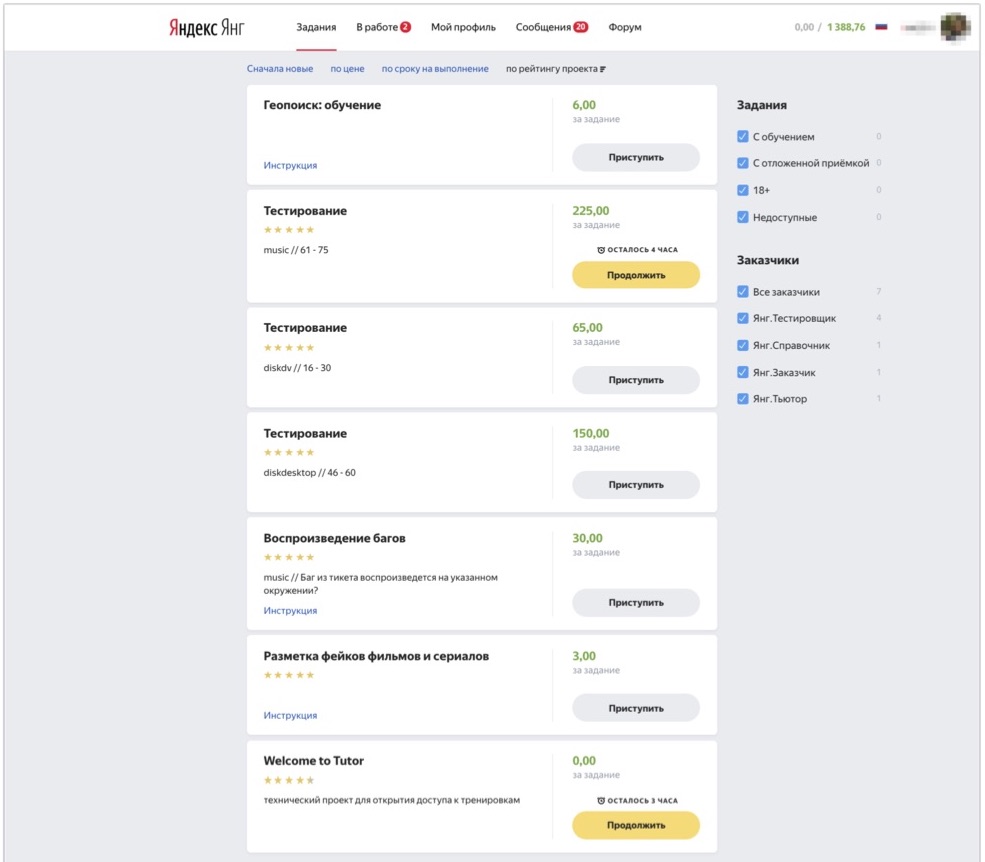
На картинке показано, как выглядит этот интерфейс. Тут можно видеть задания, доступные асессору: здесь есть несколько задач по тестированию и несколько задач другого типа, которые асессор из этого примера тоже умеет выполнять. И вот человек приходит, видит доступные ему в данный момент задания, нажимает «Приступить», получает тест-кейсы на разбор и начинает их выполнять.
Важная часть нашей инфраструктуры — это фермы. Не все устройства есть на руках, поэтому задание — это, по сути, пара: тест-кейс и окружение, в котором его нужно проверить. Когда человек нажимает на кнопку «Приступить», система проверяет, есть ли у него окружение, в котором нужно провести тест. Если есть, то человек просто берёт задание и тестирует его на личном девайсе. Если нет, то мы отправляем его через удалённый доступ к ферме.
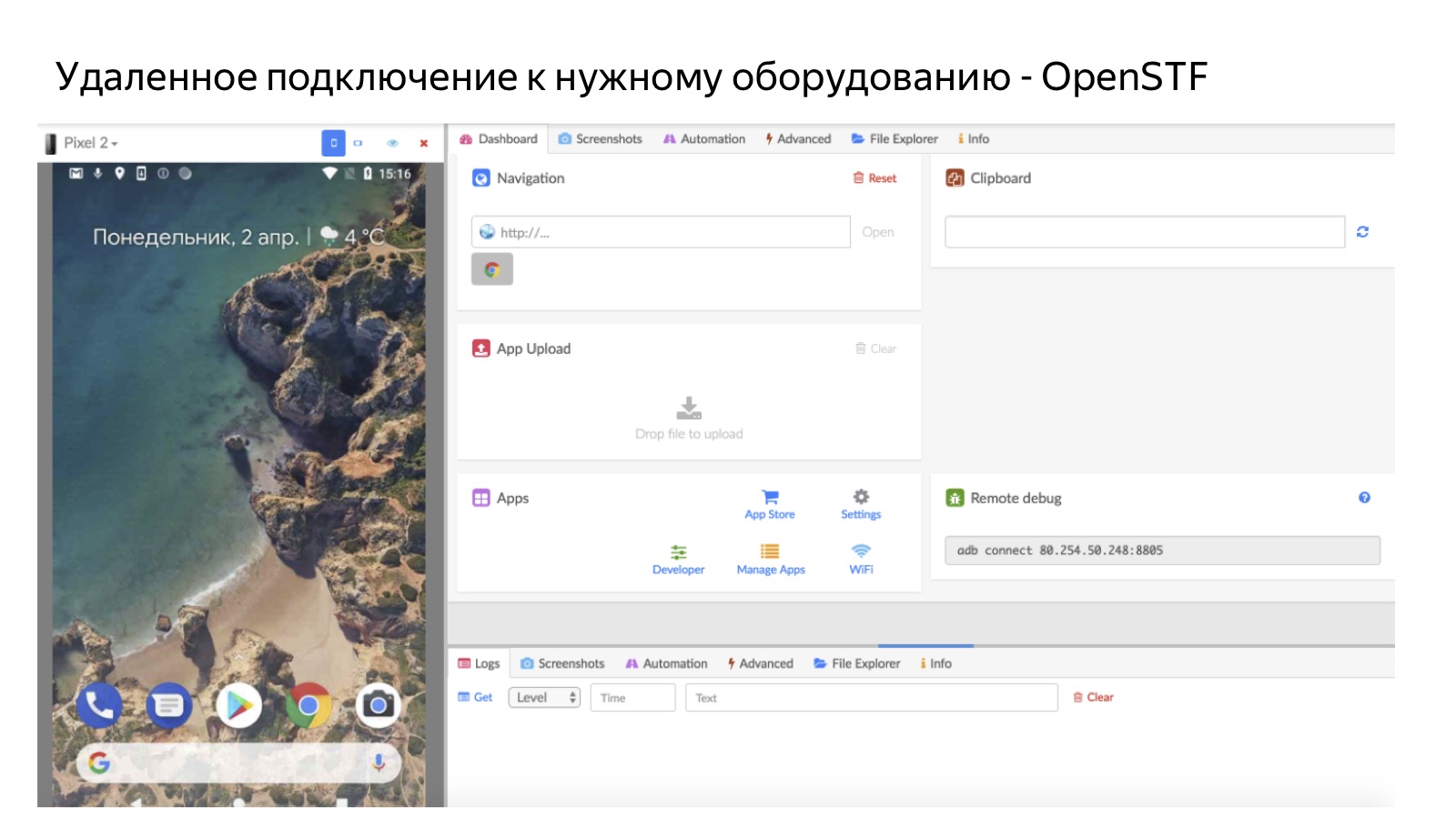
На картинке показано, как это выглядит, на примере мобильной фермы. Так человек удалённо подключается к мобильному телефону, который лежит у нас в офисе на ферме. Для Android мы используем опенсорсные решения OpenSTF. Для iOS хороших решений нет — до такой степени, что мы уже сделали свое собственное (но об этом расскажем подробно как-нибудь в следующий раз), потому что не смогли найти ни опенсорс, ни то, что имело бы смысл покупать. Понятно, что ферма полезна в тех случаях, когда у нас нет людей, которые имеют нужные устройства. И ещё важный её плюс в том, что у фермы очень высокий коэффициент утилизации: когда бы и какой бы человек ни пришел, мы в любой момент можем направить его на ферму. Это лучше, чем раздавать устройства лично, потому что устройства, выданные на руки человеку, доступны для работы только тогда, когда этот человек готов работать.
Немного поговорили о том, как это реализовано для наших асессоров с технической точки зрения, а теперь самая интересная для меня часть: принципы того, как мы вообще организовывали это производство.
Для меня в этом проекте было интересно, что вроде бы предметная область очень специфичная, но все принципы организации производства достаточно универсальны: те же самые, которые используются при организации массового производства в других предметных областях.
1. Формализация
Первый принцип (не самый важный, но один из самых важных, один из наших «китов, слонов и черепах») — это формализация задач. Я думаю, что все вы знаете это по себе. Почти любую задачу проще всего сделать самому. Чуть сложнее объяснить вашему коллеге, который сидит рядом с вами в комнате, чтобы он сделал именно то, что нужно. А задача сделать так, чтобы сотни исполнителей, которых вы никогда не видели, которые работают удалённо, в любое произвольное время, сделали именно то, что вы от них ожидаете, — это задача на несколько порядков более сложная и подразумевает довольно высокий порог вхождения в то, чтобы вообще начать этим заниматься. В контексте задач тестирования задание у нас, понятно, — это тест-кейс, который нужно пройти и обработать.
И каким же должны быть тест-кейсы для того, чтобы можно было их использовать в такой задаче, как тестирование краудом?
Во-первых — и оказалось, что это совсем не само собой разумеющийся факт — тест-кейсы вообще должны быть. Бывали такие случаи, когда к нам приходили команды, которые хотели подключиться к тестированию асессорами, мы говорили: «Отлично, приносите ваши тест-кейсы, мы будем их проходить!» В этот момент заказчик грустнел, уходил, даже не всегда возвращался. После нескольких таких обращений мы поняли, что, наверное, в этом месте нужна помощь. Потому что если тестировщик из команды какого-то сервиса сам регулярно тестирует свои сервисы, ему не особо нужны полные, хорошо описанные тест-кейсы. А если мы хотим эту задачу делегировать большому количеству исполнителей, то без этого просто не обойтись.
Но даже в тех случаях, когда тест-кейсы вообще были, почти всегда они были понятны только тем людям, которые очень глубоко погружены в сервис. А всем остальным людям, которые вне контекста, было очень тяжело понять, что здесь происходит и что нужно делать. Поэтому важно было переработать тест-кейсы так, чтобы они были понятны не погруженному в контекст человеку.
И последнее: если мы сводим задачу тестирования к строго формальному прохождению конкретных кейсов, очень важно следить за тем, чтобы эти кейсы постоянно актуализировались, обновлялись и пополнялись.
Приведу несколько примеров.
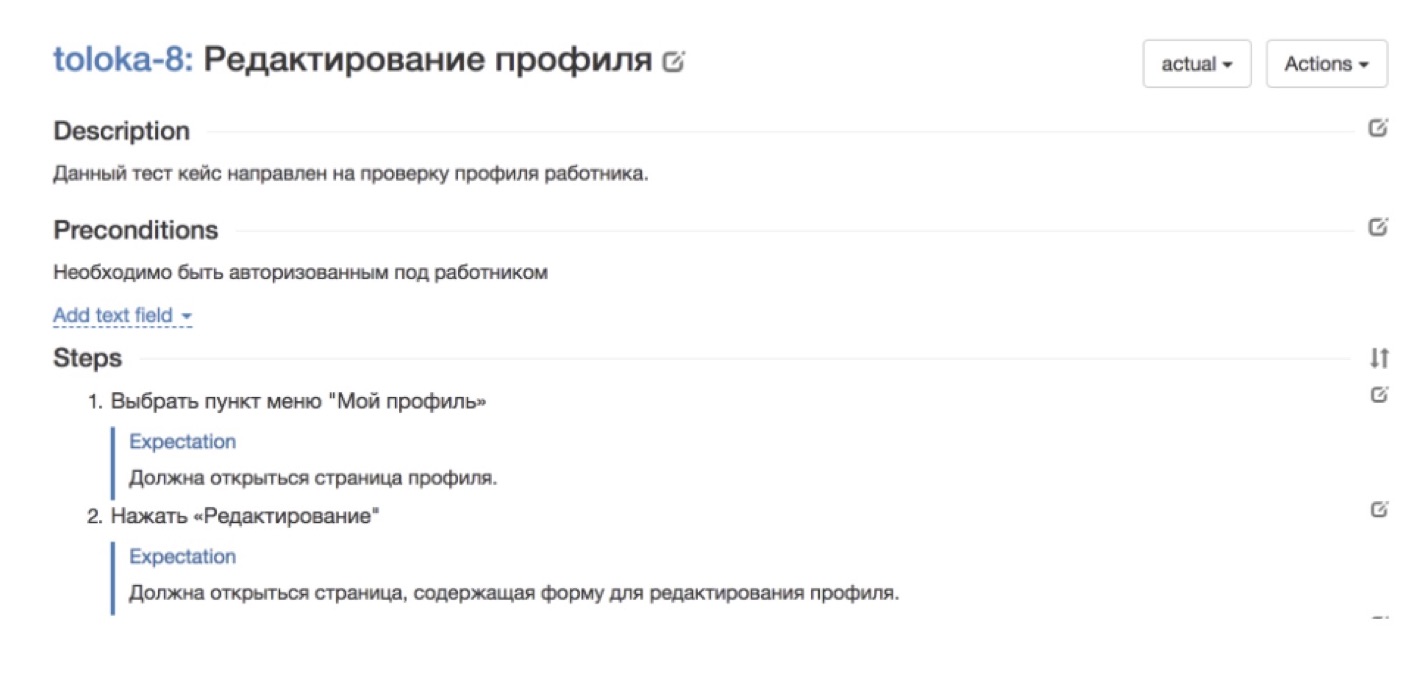
На картинке выше, например, показан хороший кейс из нашего родного сервиса Толока, в котором нужно проверить корректность работы профиля исполнителя. Здесь всё разбито по шагам. Есть каждый шаг, который нужно сделать. Есть ожидание, что должно произойти на каждом шаге. Такой кейс будет понятен кому угодно.
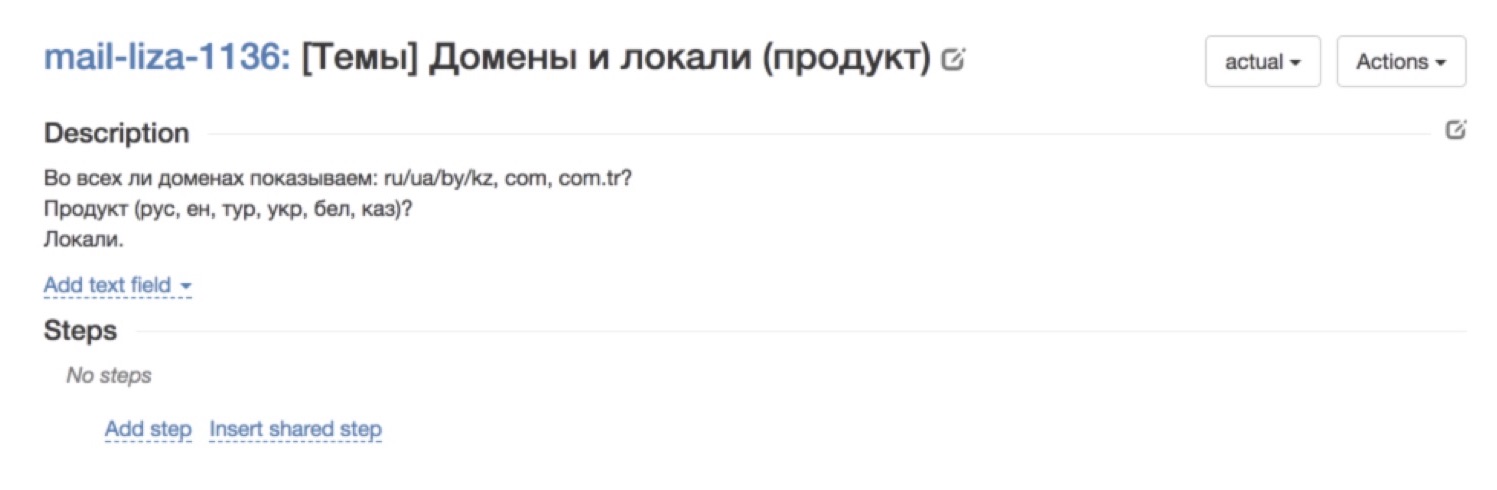
А вот пример не такого успешного кейса. Вообще непонятно, что происходит. Описание вроде есть, но на самом деле — что это, что вы от меня хотите? Такого рода кейсы — это сразу нет, очень плохо проходят.
Как же мы построили процесс формализации тест-кейсов, чтобы, во-первых, они вообще у нас были, постоянно появлялись и пополнялись, и, во-вторых, чтобы они были достаточно понятными для асессоров?
Путём проб и ошибок мы пришли к такой схеме:
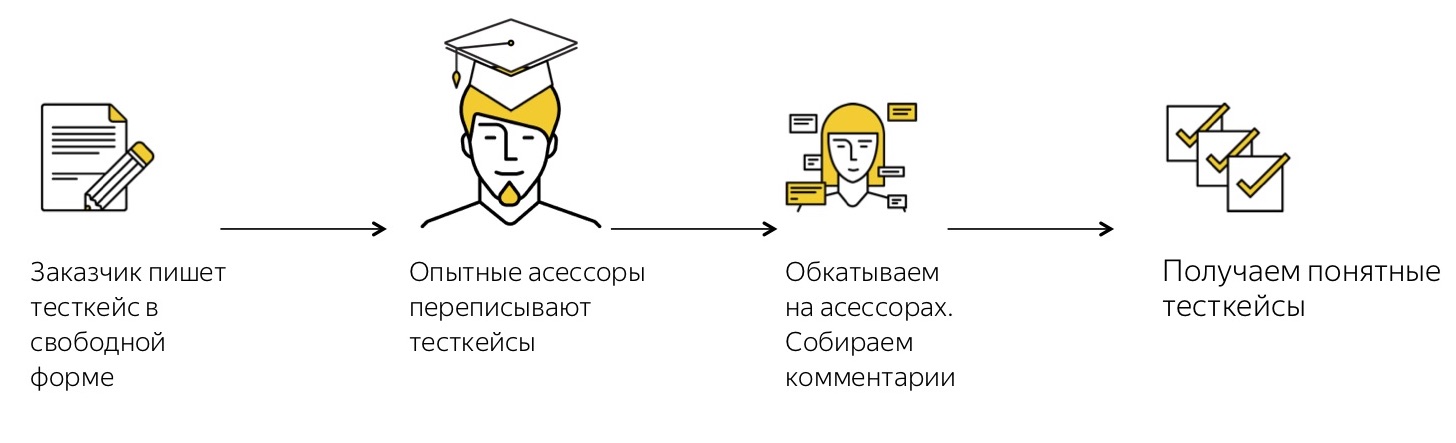
Наш заказчик, то есть какой-то сервис или команда, приходит и в сколь угодно произвольной форме, удобной для него, описывает те тест-кейсы, которые ему нужны.
После этого приходит наш умничка-асессор, который смотрит на этот свободно сформулированный текст и переводит его уже в хорошо формализованные и расписанные на мелкие детали тест-кейсы. Почему важно, что это асессор? Потому что он сам был в шкуре тех людей, которые проходят тест-кейсы из совершенно разных областей, и понимает, насколько детализированным должен быть тест-кейс, чтобы коллеги его поняли.
После этого мы обкатываем кейс: выдаём асессорам задания и собираем фидбэк. Процесс организован так, что если человек не понял, что от него требуется в тест-кейсе, он его пропускает. Как правило, после первого раза есть достаточно большой процент пропусков. Всё равно, как бы хорошо мы на предыдущей стадии ни формализовали тест-кейсы, никогда невозможно угадать, что окажется непонятным людям. Поэтому первый прогон — это почти всегда тестовый вариант, самые важные его функции — это собрать фидбэк. После того как мы собрали фидбэк, получили комментарии от асессоров, узнали, что им было понятно, а что нет, мы ещё раз переписываем, дописываем тест-кейсы. И через несколько итераций получаем классные, очень чётко сформулированные тест-кейсы, которые понятны всем.
У такого наведения порядка есть интересный side effect. Во-первых, оказалось, что для очень многих команд это вообще killer feature. Все к нам приходят и говорят: «А что, вы правда можете написать за меня тест-кейсы?» Это самое главное, чем мы привлекаем наших заказчиков. Второй эффект, неожиданный для меня — порядок в тест-кейсах имеет и другие отложенные эффекты. Например, у нас есть технические писатели, которые пишут пользовательскую документацию, и писать на основе таких хорошо разобранных и понятных тест-кейсов им гораздо легче. Раньше им приходилось отвлекать сервис, чтобы выяснить, что нужно описать, а теперь можно использовать наши понятные и классные тест-кейсы.
Приведу пример.

Вот так выглядел тест-кейс до того, как он прошёл через нашу мясорубку: очень куцый, не заполнено поле description, сказано «ну вот смотрите на скриншот в приложении» и всё.
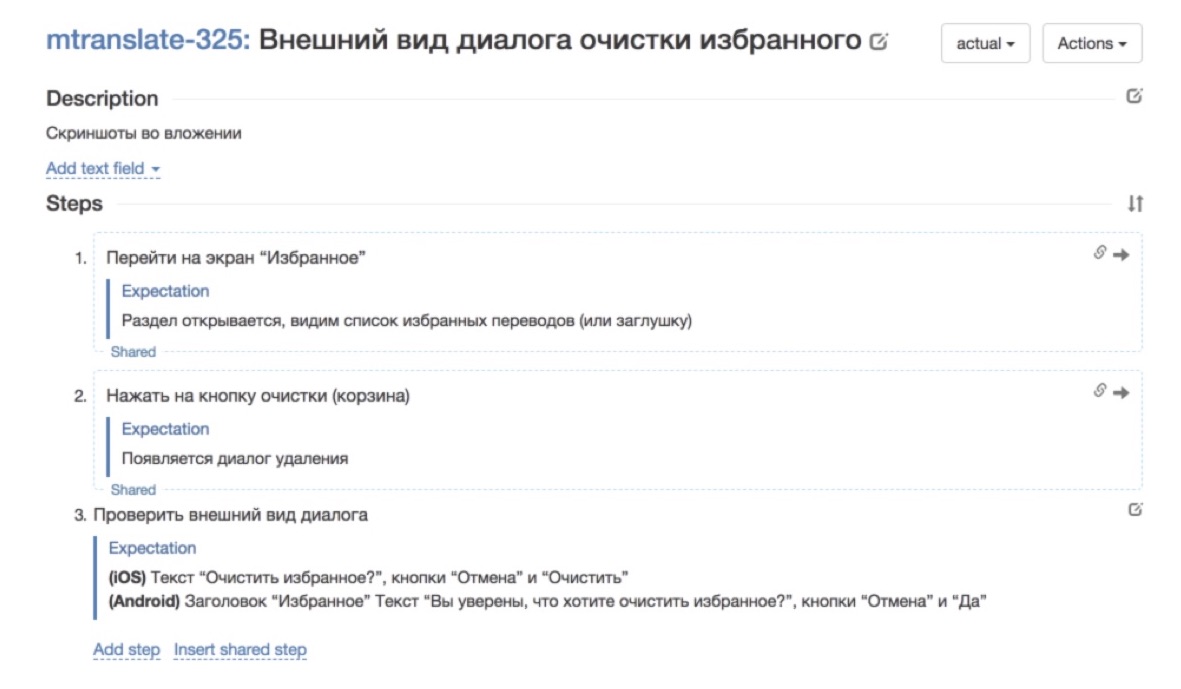
Вот как он стал выглядеть после того, как его переписали — добавили шаги и ожидания на каждом из шагов. Так уже намного лучше. С таким тест-кейсом гораздо приятнее работать.
2. Масштабируемое обучение
Следующая задача — моя любимая, самая, мне кажется, креативная в этом всём. Это задача масштабируемого обучения. Для того чтобы мы могли оперировать такими числами — «тут у нас 200 асессоров, тут 1 000, а тут вообще 17 000 толокеров каждый день работает» — важно уметь быстро и масштабируемо обучать людей.
Очень важно прийти к такой системе, когда на обучение произвольного количества людей вы тратите не больше времени, чем на обучение одного конкретного специалиста. Это, например, то, с чем мы сталкивались, когда работали с аутсорсом. Специалисты очень классные, но для того чтобы погрузить их в контекст работы, у сервиса уходило довольно много времени, а на выходе у нас всё равно получается один человек, который полгода погружается в контекст. И это такая очень не масштабируемая схема. Получается, что каждого следующего человека нужно ещё по полгода погружать в контекст задачи. И нужно было это узкое место расширить.
На любые массовые вакансии, не только в тестировании, мы набираем людей по нескольким каналам. Для тестирования мы делаем так. Во-первых, привлекаем людей, которые в принципе интересуются задачами тестирования, ребят где-то уровня junior-тестировщиков, для них это хороший старт, погружение в предметную область. Но таких людей всё равно на рынке ограниченное количество, а нам нужно, чтобы у нас не было никаких ограничений в найме людей, чтобы мы никогда не упирались в количество исполнителей.
Поэтому, помимо поиска тестировщиков специально на эти задачи, мы проводим набор из людей, которые просто откликнулись на общую позицию асессора. Мы пропагандируем примерно такой подход: каких бы людей вы ни взяли, если их много, то можно выстроить процесс так, чтобы из них отобрать наиболее способных и направить их на решение той задачи, которую вы преследуете. В контексте тестирования мы строим обучение так, чтобы можно было произвольных людей, которые даже ничего не знали о тестировании, обучить хотя бы минимальным азам, чтобы они начинали что-то понимать. Благодаря такому подходу мы никогда не упираемся в недостаток исполнителей и количество людей, которые у нас работают на этих задачах, всё сводится только к вопросу количества денег, которые мы готовы на это тратить.
Я не знаю, насколько часто вы соприкасаетесь с этой темой, но во всяких научно-популярных статьях, особенно про машинное обучение и нейронные сети, часто пишут, что обучение машины очень похоже на обучение человека. Мы показываем ребёнку 10 карточек с изображением мячика, и на 11-й раз он поймёт и скажет: «О! Это мячик!» Так же, по сути, работает и компьютерное зрение, и любые другие технологии машинного обучения.
Я хочу поговорить об обратной ситуации: обучение людей можно построить по такой же формальной схеме, как обучение машин. Что нам для этого нужно? Нам нужен training set — набор заранее размеченных примеров, на которых человек будет обучаться. Нужен контрольный набор, на котором мы сможем проверить, хорошо он обучился или нет. Как в машинном обучении, нужно проверочное множество, на котором мы понимаем, как наша функция вообще работает. И нужна формальная метрика, которая будет измерять качество выполняемой работы. Именно на таких принципах мы построили обучение задачам простейшего регрессионного тестирования.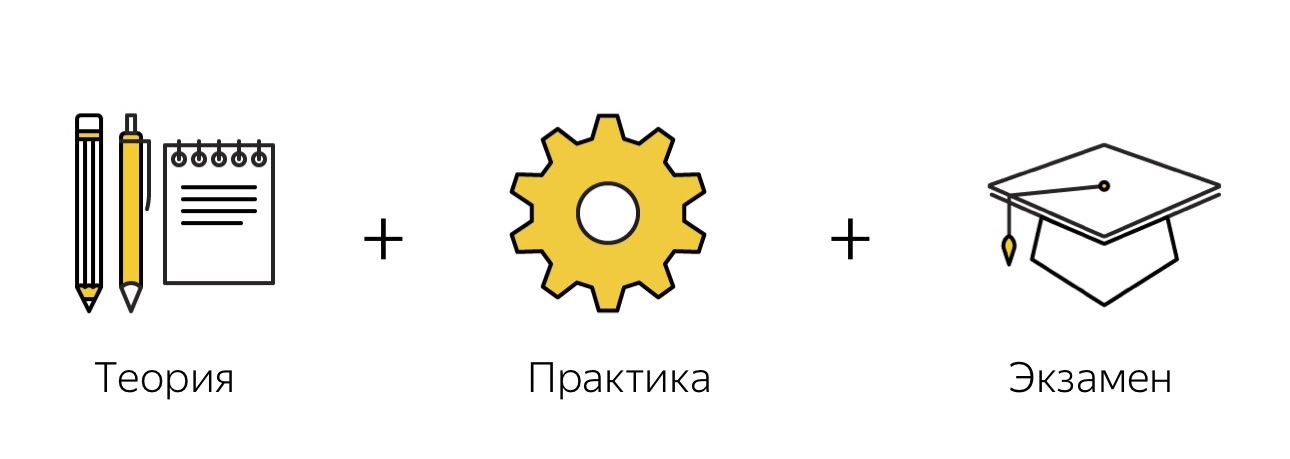
На картинке показано, как это обучение у нас выглядит. Оно состоит из нескольких частей. Во-первых, есть теория, потом практика и потом идёт экзамен, на котором мы проверяем, понял человек суть задачи или не понял.
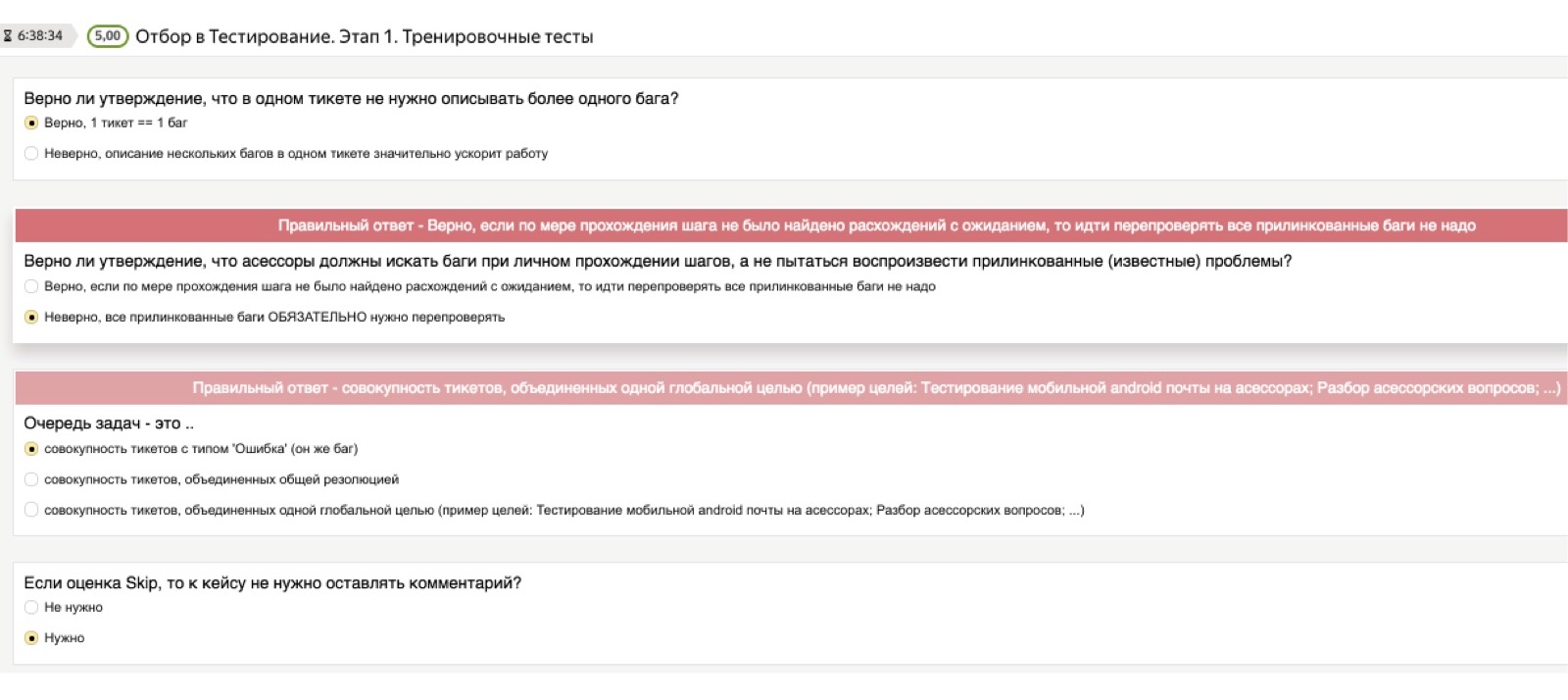
Начнём с теории. Понятно, что для любой задачи, которую выполняет асессор, у нас есть большая развесистая полноценная инструкция с большим количеством примеров, где всё очень подробно разобрано. Но её никто не читает.
Поэтому, чтобы проконтролировать, что теоретические знания реально осели у человека в голове, мы всегда даём доступ к инструкции, но после этого используем то, что мы условно называем «теоретическим тестом». Это такой тест, в который мы заранее загружаем важные для нас вопросы и правильные ответы. Вопросы могут быть самые дурацкие. Я думаю, что для вас это будут комичные примеры, но для людей, которые первый раз в жизни столкнулись с задачами тестирования, это всё совсем не очевидные вещи. Например: «Если я встретил несколько багов, мне нужно заводить несколько тикетов — по одному на каждый баг — или сваливать всё в одну кучу?» Или: «Что делать, если я хочу сделать скриншот, но скриншотилка у меня не работает?»
Это могут быть самые разные, сколь угодно низкоуровневые вопросы, и нам важно, чтобы человек проработал их самостоятельно на стадии изучения теории. Поэтому теоретический тест состоит из вопросов такого типа: «Я нашёл несколько багов, мне завести один тикет или несколько?» Если человек выбирает неправильный ответ, ему вываливается красная плашка, которая говорит: «Нет, подожди, правильный ответ здесь другой, обрати на это внимание». Даже если человек не прочитал инструкцию, мимо этого теста он пройти не может.

Следующий момент — это практика. Как сделать так, чтобы люди, которые вообще ничего не знали о тестировании и не откликались конкретно на вакансию тестировщика, поняли, что вообще дальше нужно делать? Здесь мы приходим к тому самому обучающему набору. Я думаю, что вы сразу найдёте большое количество багов, которые есть на этой картинке. Так выглядит обучающее задание для асессора: вот перед тобой скриншот, найди на нём все баги. Что здесь не так? Калькулятор торчит. Что ещё? Вёрстка поехала.

Или вот более сложный пример, «со звёздочкой». Открыт почтовый ящик основного получателя, я — тот, кому отправлено это письмо. Вот я вижу перед собой такую картину. В чём здесь баг? Самая большая проблема здесь в том, что показывается скрытая копия, и я как получатель письма вижу, кому оно стояло в скрытой копии.
Пройдя пару десятков таких примеров, даже человек, бесконечно далёкий от тестирования, уже начинает понимать, что это такое и что от него требуется дальше при прохождении тест-кейсов. Практическая часть — это набор примеров, баги в которых нам уже известны; мы просим человека их найти и в конце показываем ему: «Смотри, баг был здесь», — чтобы он соотносил свои догадки с нашими правильными ответами.
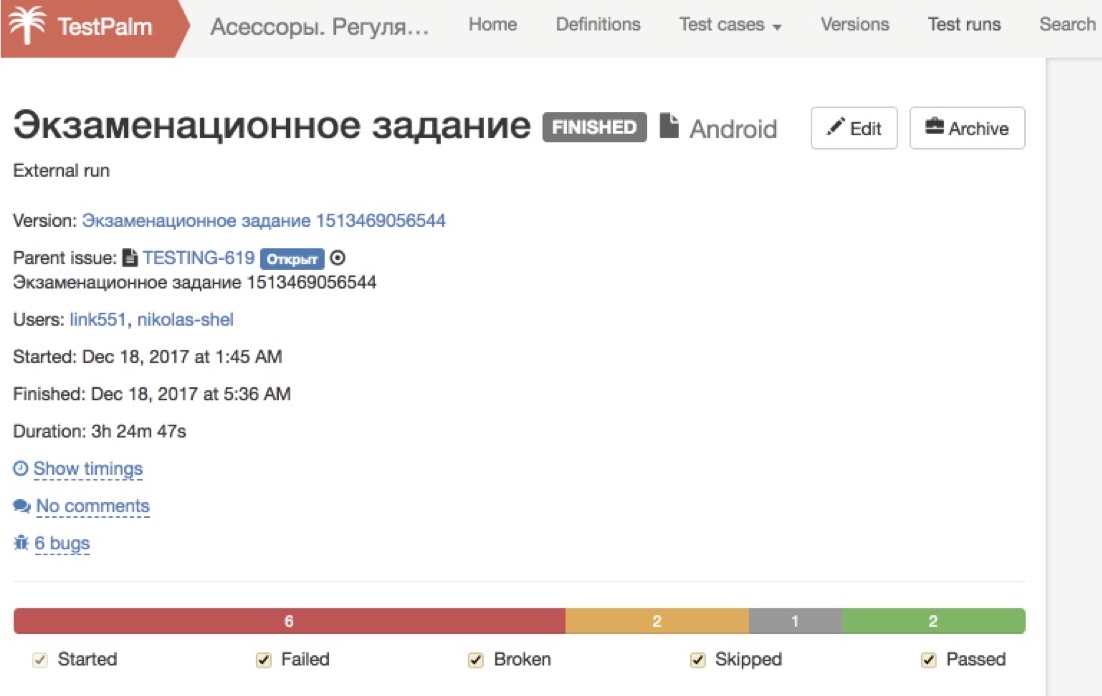
И последняя часть — это то, что мы называем экзаменом. У нас есть специальная тестовая сборка, баги которой нам уже известны, и мы просим человека её пройти. Здесь мы уже не показываем ему правильные и неправильные варианты ответа, а просто смотрим, что он смог найти.
Прелесть этой системы и её масштабируемость заключаются в том, что все эти процессы происходят абсолютно автономно, без участия менеджера. Мы запускаем сколько угодно людей: все желающие читают инструкцию, все желающие проходят теоретический тест, все желающие проходят практику — всё это происходит автоматически по нажатию ими кнопки, а нас вообще никак не касается.
Последнюю часть — экзамен — тоже проходят все, кто хочет, и тут, наконец, мы начинаем смотреть на них внимательно. Поскольку это тестовая сборка и мы заранее знаем все её баги, мы можем автоматически определить, какой процент багов был найден человеком. Если он совсем низкий, то мы дальше не смотрим, пишем автоматическую отбивку: «Спасибо большое за ваши старания!» — и не даём этому человеку доступ к боевым заданиям. Если же мы видим, что найдены почти все баги, то в этот момент уже подключается человек, который смотрит, насколько корректно оформлены тикеты, насколько всё сделано правильно по процедуре, с точки зрения наших инструкций.
Если мы видим, что человек самостоятельно освоил и теорию, и практику и хорошо сдал экзамен, то таких людей мы на выходе пускаем в наши продакшн-процессы. Эта схема хороша тем, что она не зависит от того, сколько людей мы через неё пропускаем. Если нам нужно больше людей, мы просто зальём больше людей на вход и больше получим на выходе.
Это классная система, но, естественно, было бы наивно полагать, что после этого можно уже иметь готового тестировщика. Даже у ребят, которые успешно прошли наше обучение, возникает много вопросов, с которыми им нужно оперативно помогать. И тут мы столкнулись с большим количеством неожиданных для нас проблем.
Люди задают очень много вопросов. Причём эти вопросы могут быть настолько странными, что вы никогда в жизни бы не подумали, что ответы на эти вопросы нужно добавить в инструкцию, описать в тесте или что-то подобное. Если подумать, это нормальная ситуация. Каждый из нас с вами, когда попадает в неизвестную для себя область, с небольшой вероятностью, но задаст какой-нибудь вопрос, который специалисту покажется глупым.
Здесь ситуация усугубляется тем, что у нас этих людей несколько сотен, и если даже у каждого задать конкретного вероятность задать глупый вопрос низкая, в сумме получается: «А-а-а! Боже! Что происходит? Нас заваливает!»
Иногда вопросы кажутся странными. Например, человек пишет: «Я не понимаю, что значит «тапнуть в Undo». Ему говорят: «Друг! Это то же самое, что нажать кнопку «Отмена». Он: «О! Спасибо! Теперь я всё понял».
Или другой человек говорит: «Вроде всё нормально, но что-то фоточка битая, я не могу понять, это ошибка или нет». Но через минуту сам понимает, куда он попал — в задачу тестирования; наверное, битая фоточка — это не очень нормально. Здесь он сам понял, и окей.
Или вот интересный пример, который реально надолго погрузил нас в пучину исследований. Человек приходит и говорит:
