Контейнеры: Поиски «магического фреймворка» и почему им стал Kubernetes

Мы в «Латере» занимаемся созданием биллинга для операторов связи. В блоге на Хабре мы не только рассказываем об особенностях нашей системы и деталях ее разработки (например, обеспечении отказоустойчивости), но и публикуем материалы о работе с инфраструктурой в целом. Инженер проекта Haleby.se написал в блоге материал, в котором рассказал о причинах выбора в качестве инструмента оркестрации Docker-контейнеров технологии Kubernetes. Мы представляем вашему вниманию основные мысли этой заметки.
Предыстория
Инженерная команда проекта изначально использовала методологию непрерывного развертывания (continuous delivery) Jenkins для каждого сервиса. Это позволяло запускать по каждому коммиту интеграционные тесты, генерировать артефакт и образ Docker, после чего разворачивать его на тестовом сервере. С помощью одного клика любой образ можно было развернуть на «боевом» сервере. Схема выглядела примерно так:
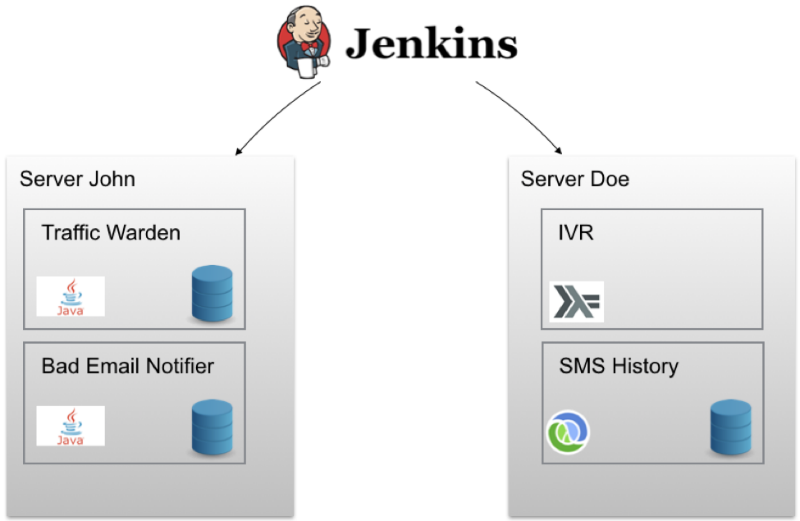
В ячейках под названием John и Doe содержатся наборы Docker-контейнеров, развернутых на конкретном узле. Кроме того для провижининга применяется Ansible. В итоге создать новый облачный сервер и установить на него корректную версию Docker/Docker-Compose, сконфигурировать правила межсетевого экрана и выполнить прочие настройки можно с помощью одной команды. Для каждого работающего в Docker-контейнере сервиса есть сторожевые скрипты, которые «поднимают» его в случае сбоя. Но в такой конфигурации возможны и проблемы.
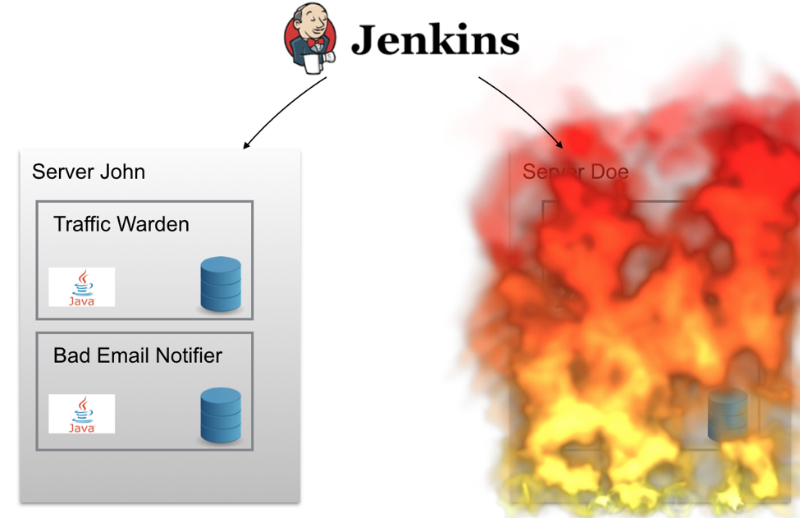
Если сервер Doe «сгорит» однажды ночью (или просто на нем произойдет кратковременный серьезный сбой), технической команде проекта придется подниматься среди ночи, чтобы вернуть систему в работоспособное состояние. Сервисы, установленные на Doe, автоматически не перемещаются на другой сервер — например, John, поэтому на некоторое время работа системы была бы прекращена.
Есть и другие сложности — расположение на одном узле максимального количества контейнеров, обнаружение сети (service discovery), «заливка» обновлений, агрегирование лог-данных. Нужно было как-то со всем этим справиться.
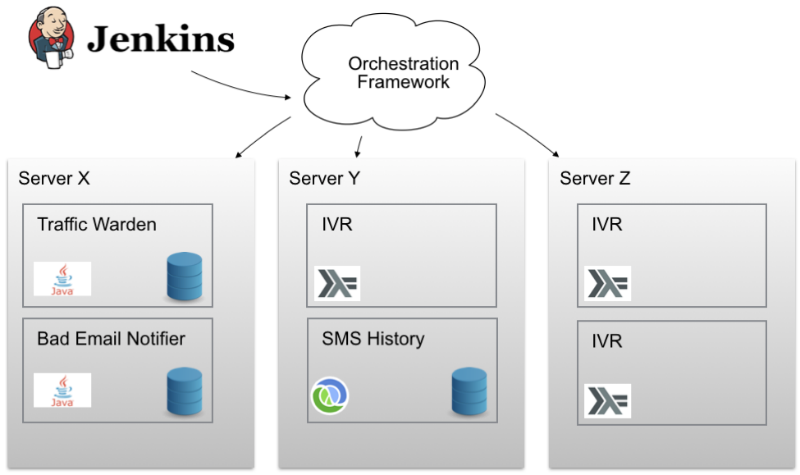
Нужен был некий волшебный фреймворк оркестрации (orchestration framework), с помощью которого можно было бы распределять контейнеры по узлам кластера. Нужно было добиться того, чтобы работать с множеством узлов можно было бы, как с одним-единственным. Нужно было, чтобы этому волшебному фреймворку можно было сказать «разверни 3 экземпляра вот такого Docker-контейнера где-нибудь в кластере и проследи, чтобы все работало». Отличный план! Дело оставалось за малым — найти такой фреймворк.
Список пожеланий
Технологии развиваются очень быстро, так что даже для соответствия весьма умеренным стандартам, все равно необходимо выбирать инструменты таким образом, чтобы они были живы и поддерживались на протяжении какого-то времени. Инженеры Haleby хотели бы, чтобы их «фреймворк мечты» использовал что-то вроде уже применявшегося ими docker-compose — это позволило бы избавиться от необходимости проведения большого количества работ по реконфигурации и настройке.
Кроме того, плюсом была бы простота фреймворка и отсутствие в нем слишком большого количества волшебных фич, которые сложно контролировать. Отлично подошло бы какое-то модульное решение, что оставляло бы возможности по замене некоторых частей при необходимости. Открытая лицензия также была бы плюсом — в таком случае можно было бы легко отслеживать прогресс проекта и убедиться в том, что у него есть активное сообщество.
Помимо этого члены команды Haleby хотели бы, чтобы в выбранном инструменте присутствовала поддержка работы с контейнерами в нескольких облаках одновременно, а также наличие функциональности сетевого обнаружения. Также инженерам не хотелось тратить много времени на настройку, поэтому предпочтительным был бы вариант использования модели «framework as service».
Выбор фреймворка
Анализ существующих на рынке вариантов позволил выделить несколько фреймворков-кандидатов. В их числе:
AWS ECS
AWS ECS Container Service — это высокомасштабируемый и быстрый инструмент управления контейнерами, с помощью которого их можно запускать, останавливать и работать с контейнерами Docker в кластере инстансов Amazon EC2. Если какой-либо проект уже работает в этом облаке, то не рассмотреть данный вариант просто странно. Однако Haleby не работал на Amazon, поэтому переезд показался инженерам компании не самым лучшим решением.
Кроме того, выяснилось, что система не обладает встроенной функциональностью сетевого обнаружения, что было одним из ключевых требований. Кроме того, в случае AWS ECS не получилось бы запустить множество контейнеров с помощью одного порта на одном узле.
Docker Swarm
Docker Swarm — это нативный инструмент кластеризации для Docker. Поскольку Swarm использует Docker API, то любое средство, умеющее работать с демоном Docker, может быть масштабировано с его помощью. Поскольку Haleby использует docker-compose, последняя опция звучала очень заманчиво. Кроме того, использование нативного инструмента знакомой технологии означало, что команде не придется изучать что-то новое.
Однако не все было так радужно. Несмотря на то, что Swarm поддерживает несколько движков для сетевого обнаружения, но настроить работоспособную интеграцию — непростое занятие. Кроме того, Swarm — это не managed-сервис, поэтому настраивать и поддерживать его работу пришлось бы самостоятельно, что изначально не входило в планы команды проекта.
Более того, обновление контейнеров также невозможно было бы провести в автоматическом режиме. Для этого пришлось бы, к примеру, настраивать Nginx в качестве балансировщика нагрузки на различные группы контейнеров. Также многие инженеры в интернете выражали сомнения в работоспособности Swarm — среди них, к примеру, сотрудники Google.
Mesosphere DCOS
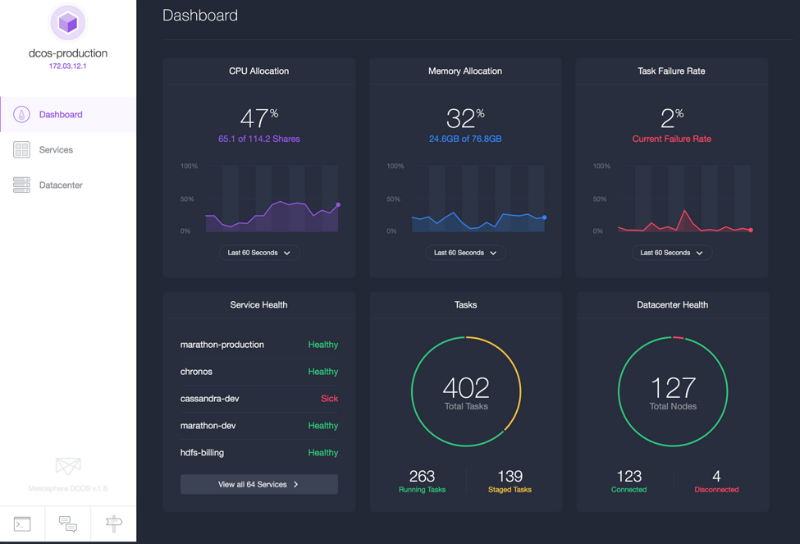
После настройки DCOS (операционной системы дата-центра) на AWS и старта работы, Mesosphere кажется неплохим вариантом. С помощью удобного интерфейса можно получить всю информацию о кластере, включая запущенные сервисы, загрузку процессора и потребление памяти. DCOS может работать в любом облаке и сразу с несколькими облаками. Mesos же — это инструмент, проверенный работой в крупных кластерах. Также DCOS позволяет запускать не только контейнеры, но и отдельные приложения, вроде Ruby, а устанавливать важные сервисы можно с помощью простой команды dcos install (это как apt-get для дата-центра).
Более того, с помощью этого инструмента можно работать с несколькими кластерами одновременно — можно запустить Marathon, Kubernetes, Docker и Swarm в рамках одной системы.
Однако наряду с плюсами, у этого варианта были и свои недостатки. К примеру, поддержка работы с несколькими облаками присутствует только в Enterprise-версии Mesosphere DCOS, однако цена этой версии не указана на сайте, а на запросы никто не ответил.
Также в документации на тот момент (октябрь/ноябрь 2015 года) не было информации о том, как переехать на новый кластер без необходимости прерывания работы системы — тут важно понимать, что это также не managed-сервис, так что во время переезда могут возникнуть проблемы.
Tutum
Команда проекта описывает его как «Docker-платформа для Dev и Ops», а слоган звучит как «стройте, разворачивайте и управляйте своими приложениями в любом облаке». Интерфейс выглядит вот так:
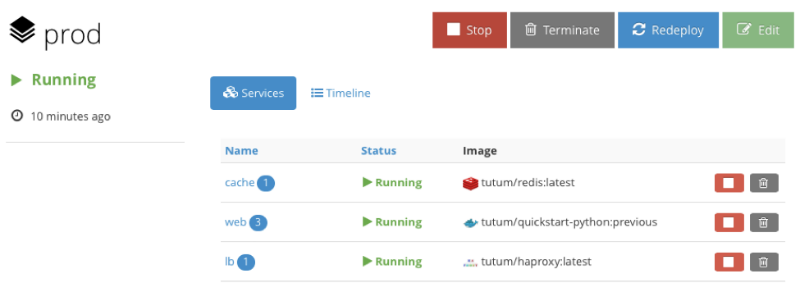
Кому-то он может показаться не столь эффектным, как у DCOS, но тем не менее система позволяет производить большинство нужных манипуляций с помощью простых кликов мышкой, хотя у Tutum есть и хорошая поддержка командной строки. Для начала работа с системой нужно установить Tutum-агент на каждом узле кластера, после чего узел начинает отображаться в административной панели. Интересный момент — Tutum использует формат объявления стэков из нескольких сервисов или контейнеров, который похож на docker-compose — поэтому специалистам, знакомым с Docker будет еще проще начать работу.
Кроме того, Tutum поддерживает тома с помощью интеграции в кластер Flocker. Тесты, в ходе которых определенные контейнеры «убивались» были пройдены успешно — они воссоздавались в том же состоянии (иногда на разных узлах). Еще одним плюсом стала функция создания ссылок между контейнерами — с ее помощью можно связывать определенные контейнеры в группе.
Для балансировки нагрузки используется HAProxy, который поддерживает виртуальные хосты, так что за одним экземпляром HAProxy можно размещать несколько сервисов. Развертывание сервисов также можно осуществлять разными способами, а для обновления Docker во всем кластере достаточно сделать пару кликов. В дальнейшем компания Docker купила сервис Tutum, так что в будущем он будет полностью интегрирован в экосистему.
Однако на момент поисков лучшего фреймворка Tutum находился в стадии бета-тестирования. И все же главным аргументом против этого варианта стал инцидент, когда в ходе теста инженеры специально добились полной недоступности узла — загрузка CPU 100% не позволяла даже подключиться к машине по SSH, контейнеры с него не были перенесены на другой узел. Техподдержка Tutum заявила о том, что знакома с этой проблемой, но она еще не устранена. Нужно было искать дальше.
Kubernetes
Команда Kubernetes описывает проект как инструмент для «управления кластером Linux-контейнеров в качестве единой системы для ускорения Dev и упрощения Ops». Это открытый проект, который поддерживает Google, также его развитием занимается ряд других компаний, в числе которых Red Hat, Microsoft, SaltStack, Docker, CoreOS, Mesosphere, IBM.
Что по-настоящему хорошо в Kubernetes, так это то, что в нем объединен десятилетний опыт Google по построению и работе с кластерами — и все это бесплатно! Запустить Kubernetes можно на своем железе или на мощностях облачных провайдеров вроде AWS для которого даже есть специальные шаблоны формаций.
Кроме того, Google предлагает managed-версию Kubernetes под названием Google Container Engine. Из-за недостатков интерфейса начать работать с ней не так легко, как к примеру с Tutum, однако после того, как пользователю удастся разобраться в системе, работать с ней становится просто.
Команда инженеров провела множество тестов, в ходе которых узлы «убивались» в процессе заливки обновлений, случайным образом уничтожались контейнеры, их число увеличивалось выше заявленной максимальной планки и т.п. Не всегда все проходило без проблем, однако в каждом случае после определенных поисков удавалось обнаружить способ исправить ситуацию.
Еще одним существенным плюсом Kubernetes стала возможность обновления всего кластера без прерывания работы. Также тесты подтвердили работоспособность сетевого обнаружения — нужно лишь вбить в адресную строку имя нужного сервиса (http://my-service), и Kubernetes создать подключение к нужному контейнеру. Kubernetes представляет собой модульную систему, компоненты которой можно комбинировать.
Есть у фреймворка и свои минусы — при работе с Google Container Engine система ограничивается одним дата-центром. Если с ним что-нибудь случится, ничего хорошего не будет. Из любой ситуации можно выйти, например, организовав несколько кластеров с помощью балансировщика нагрузки, но «из коробки» решения нет. Однако поддержка работы с несколькими ЦОД планируется в новых версиях более легкой версии фреймворка Ubernetes. Кроме того, Kubernetes использует свой yaml-формат, что приводит к необходимости конвертации файлов docker-compose. Помимо этого, проект еще не настолько развит, как тот же Mesos, который позволяет работать с большим количеством узлов.
Заключение
После исследования доступных на рынке вариантов команда Haleby остановилась на Kubernetes, который показался инженерам наиболее подходящим инструментом для решения их задач. При этом другие рассмотренные сервисы также показали себя с хорошей стороны, однако у них были свои минусы, которые именно в данном случае оказались неприемлемыми.
