Контейнерно-ориентированное интеграционное тестирование
Интеграционное тестирование остается важной частью производственного цикла CI/CD, в том числе при разработке контейнерных приложений. Интеграционные тесты, как правило, представляют собой не очень продолжительные, но очень ресурсоемкие рабочие нагрузки. Посмотрим, как можно объединить технологии и инструменты интеграционного тестирования со средствами оркестрации контейнеров (в частности, с Red Hat OpenShift), чтобы ускорить тестирование, повысить его динамичность, и более эффективно использовать ресурсы.
Создадим интеграционные BDD-тесты (behavior-driven development — разработка через поведение) с помощью Cucumber, Protractor и Selenium и выполним их на платформе OpenShift, используя Zalenium.
BDD-тестирование
При разработке интеграционных тестов BDD позволяет создавать дефиниции интеграционных тестов бизнес-аналитикам (ВА), а не только программистам. Благодаря BDD процесс разработки можно организовать так, что функциональные требования и дефиниции интеграционной тестов готовятся одновременно, и при этом создаются они бизнес-аналитиками.
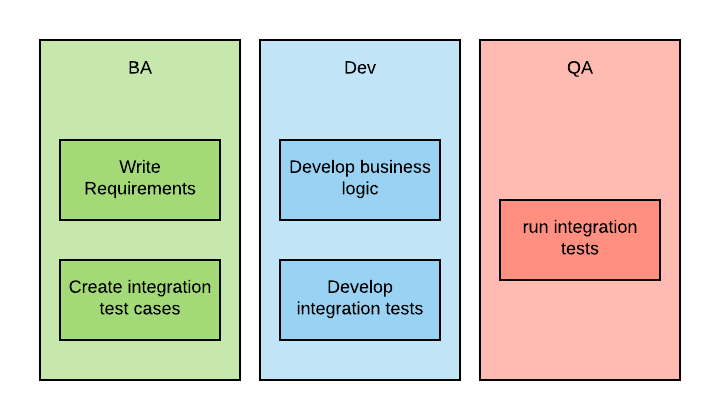
Это гораздо лучше традиционных подходов, когда вначале определяется бизнес-функционал приложения, а затем отдел контроля качества (QA) создает интеграционные тесты, как показано на диаграмме ниже:

А вот как все выглядит при использовании BDD:
Кроме того, в этой новой схеме каждая итерация, как правило, занимает меньше времени.
Бизнес-аналитики могут создавать дефиниции интеграционных тестов потому, что в BDD эти тесты описываются на простом и понятном языке Gherkin, главными ключевыми словами которого являются Given (При условии), When (Когда) и Then (Затем). Каждое утверждение на языке Gherkin в обязательном порядке должно начинается с одного из этих слов.
Например:
Given the user navigated to the login page (При условии, что пользователь зашел на страницу входа в систему)
When the user enters username and password (Когда пользователь вводит логин и пароль)
When username and password are correct (Когда логин и пароль верны)
Then the system logs them in (Затем система разрешает ему войти)
Одной из популярных сред выполнения, способных интерпретировать Gherkin-тесты, является Cucumber. Для использования Cucumber разработчик должен реализовать определенные функции, чтобы можно было выполнять любые директивы Gherkin. Cucumber имеет привязки ко многим языкам программирования. Тесты рекомендуется (но не требуется) писать на том же языке, что и тестируемое приложение.
Стек технологий тестирования
Разберем процедуру тестирования на примере веб-приложения TodoMVC в реализации AngularJS. AngularJS — это популярный фреймворк для создания одностраничных приложений (Single-Page Applications, SPA).
Поскольку AngularJS — это JavaScript, мы будем использовать Cumcumber.js, привязку Cucumber к JavaScript.
Для эмуляции работы пользователя в браузере воспользуемся Selenium. Selenium — это процесс, который может запускать браузер и воспроизводить в нем действия пользователями по командам, получаемым через API.
И наконец, мы будем использовать Protractor, чтобы учесть нюансы эмуляции SPA-приложений, написанных на AngularJS. Protractor возьмет на себя проблемы с ожиданиями, чтобы представления внутри страницы загружались правильно.
Итак, наш стек тестирования выглядит следующим образом:
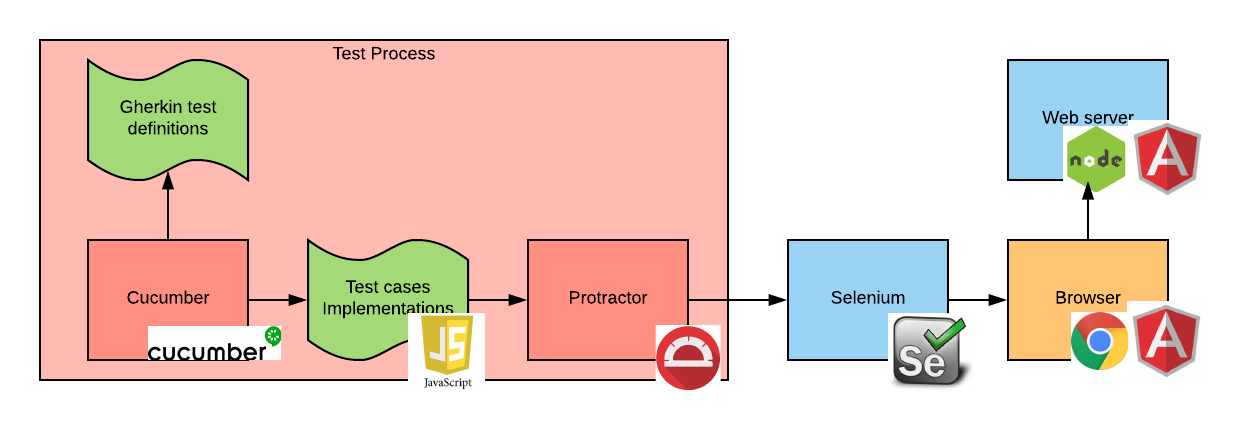
Процесс, представленный на этой диаграмме, описывается следующим образом:
- Когда запускается тест Cucumber, Cucumber читает определение теста из файла Gherkin.
- Затем он запускает вызов кода реализации тестового сценария.
- Код реализации тестового сценария использует Protractor, чтобы выполнить действия на веб-странице
- Когда это происходит, Protractor подключается к серверу Protractor и выдает команды Selenium«у через API-интерфейс.
- Selenium выполняет эти команды в экземпляре браузера.
- Браузер, при необходимости, подключается к веб-серверу (ам). В нашем примере используется SPA-приложение, поэтому такого подключения не происходит, поскольку приложение уже загрузилось при загрузке с сервера первой страницы.
Развертывание такого стека в неконтейнеризованной инфраструктуре — дело непростое. И не только из-за большого числа используемых процессов и фреймворков, но и потому, что запускать браузер на сервере без монитора всегда было затруднительно. К счастью, в контейнеризованном мире все это можно автоматизировать.
Ферма интеграционного тестирования
Корпоративные веб-приложения необходимо тестировать для различных комбинаций клиентской ОС и браузера. Обычно при этом ограничиваются неким базовым набором вариантов, который отражает ситуацию на машинах конечных пользователей приложения. Но даже в этом случае число тестовых конфигураций для каждого приложения редко опускается ниже полудюжины.
Если последовательно развертывать стек для каждой тестовой конфигурации и прогонять на нем соответствующие тесты, то это слишком затратно в смысле времени и ресурсов.
В идеале хотелось бы прогонять тесты параллельно.
В этом нам может помочь Selenium-Grid — решение, которое включает в себя брокер запросов Selenium Hub и один или несколько узлов, на которых эти запросы выполняются.

Каждый Selenium-узел, который обычно работает на отдельном сервере, можно сконфигурировать под определенную комбинацию клиентской ОС и браузера (в Selenium эти и другие характеристики узла называется capabilities — свойства). При этом Selenium Hub достаточно умен, чтобы отправлять запросы, для которых требуются определенные Selenium-свойства, тем узлам, у которых эти свойства есть.
Кластеры Selenium-Grid довольно сложны в установке и управлении, причем настолько, что на рынке даже появились компании, предлагающие соответствующие услуги. В частности, среди основных игроков можно назвать фирмы SauceLabs и BrowserStack.
Контейнерно-ориентированное интеграционное тестирование
Очень часто хотелось бы иметь возможность создавать кластер Selenium-Grid, который предоставлял бы необходимые для наших тестов Selenium-свойства и выполнял бы сами тесты с высокой степенью распараллеливания. Затем, после завершения тестирования, хотелось бы иметь возможность полностью уничтожить этот кластер. Иначе говоря, самому научиться работать так, как работают поставщики услуг интеграционных тест-ферм.
Эта область технологий пока находится на раннем этапе формирования, однако, один многообещающий проект с открытым кодом — Zalenium — предлагает кое-что из того, что нам нужно.
Zalenium использует модифицированный Hub, который может создавать узлы по запросу и уничтожать их, когда они больше не нужны. В данный момент Zalenium поддерживает только браузеры Chrome и Firefox на платформе Linux. Но с появлением Windows-узлов для Kubernetes, возможно появится поддержка Explorer и Edge на Windows.
Если собрать все вместе, то технологический стек выглядит следующим образом:

Каждый овал на схеме — это отдельный под (pod) в Kubernetes. Поды тестового плейера и эмуляторов эфемерны и уничтожаются по завершении теста.
Выполнение интеграционных тестов в рамках конвейера CI/CD
Создадим простой конвейер в Jenkins, чтобы показать, как встроить данный тип интеграционного тестирования в остальной процесс управления релизами. Выглядит он следующим образом:

Ваш конвейер может отличаться, но у вас все равно есть возможность повторно использовать фазу интеграционного тестирования без существенного рефакторинга кода.
Поскольку большинство подов эфемерны, одной из задач конвейера является сбор результатов тестирования. В Jenkins это можно делать с помощью примитивов archive и publishHTML.
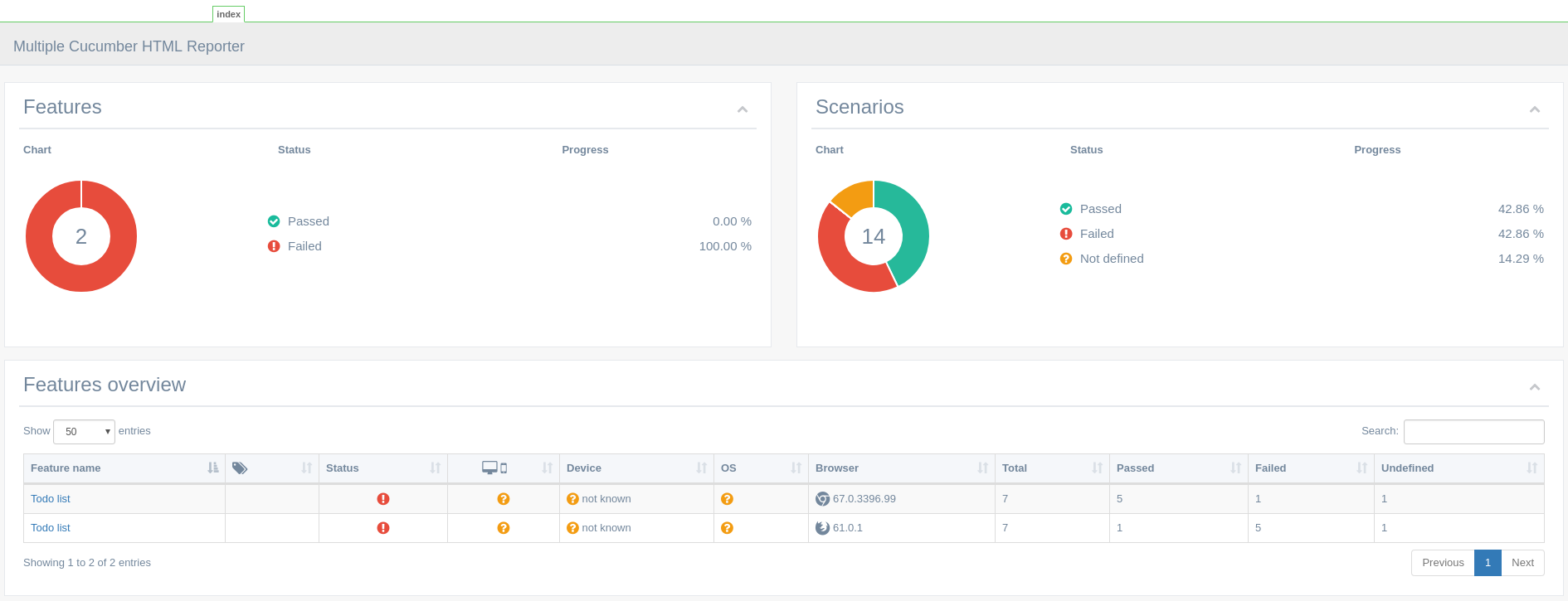
А это пример отчета по результатам выполнения тестов (обратите внимание, что тесты прогонялись на двух браузерах):
Заключение
Таким образом, при всей сложности организации сквозной инфраструктуры интеграционного тестирования, подход «инфраструктура как код» позволяет упростить процесс. Выполнение интеграционных тестов на различных комбинациях ОС и браузеров отнимает массу времени и ресурсов, но средства контейнерной оркестрации и эфемерные рабочие нагрузки помогают справиться с этой проблемой.
Даже в отсутствие сформировавшихся инструментов для организации контейнерно-ориентированного интеграционного тестирования уже сегодня можно выполнять интеграционное тестирование на базе контейнерных платформ и использовать преимущества контейнерного подхода.
Если вы разрабатываете контейнерные приложения, попробуйте использовать этот подход в рамках конвейера CI/CD и посмотреть, поможет ли он упростить интеграционное тестирование.
Примеры кода из этой статьи можно найти на сайте GitHub по адресу redhat-cop/container-pipelinesh.
