Конспект доклада «Что мы знаем о микросервисах» (HL2018, Avito, Вадим Мадисон)
Привет, %username%!
Совсем недавно закончилась конференция Highload++ (еще раз спасибо всей команде организаторов и olegbunin лично. Было очень круто!).
Накануне конференции Алексей fisher предложил создать инициативную группу «сталкеров» на конференции. Мы, во время докладов, писали небольшие конспекты, которыми обменивались. Некоторые конспекты получились достаточно детальными и подробными.
Сообщество в соц сетях позитивно оценило такой формат, поэтому я (с разрешения) решил опубликовать конспект первого доклада. Если данный формат будет интересен, то я смогу подготовить еще несколько статей.

Погнали
В авито много сервисов и очень много связей между ними. Это порождает проблемы:
- Много репозиториев. Сложно менять код одновременно везде
- Команды ограничены своим контекстом. Максимум пересекаются незначительно и не все
- Добавляется фрагментарность данных.
Большое количество инфраструктурных элементов:
- Логирование
- Трассировка запросов (Jaeger)
- Агрегация ошибок (Sentry)
- Статусы / сообщения / события из Kubernetes
- Race limit / Circuit Breaker (Hystrix)
- Связность сервисов (Istio)
- Мониторинг (Grafana)
- Сборка (Teamcity)
- Общение
- Трекер задач
- Документация
- …
Есть ряд слоев, доклад описывает только один (PaaS).
В платформе 3 основные части:
- Генераторы, которые управляются через cli
- Аггрегатор (коллектор), который управляется через дашборд
- Хранилище (storage) с триггерами на определенные действия.
Стандартный конвейер разработки микросервиса
CLI-push → CI → Bake → Deploy → Test → Canary → Production
CLI-push
Долго учили делать правильно разработчиков. Все равно осталось слабым местом.
Автоматизировали через cli утилиту, которая помогает создать базис под микросервис:
- Создаёт сервис по шаблону (поддерживаются шаблоны для ряда ЯП).
- Автоматически разворачивает инфраструктуру для локальной разработки
- Подключает БД (не требует конфигурирования, разработчик не думает о доступах к любой базе).
- Live-сборка
- Генерация болванок автотестов.
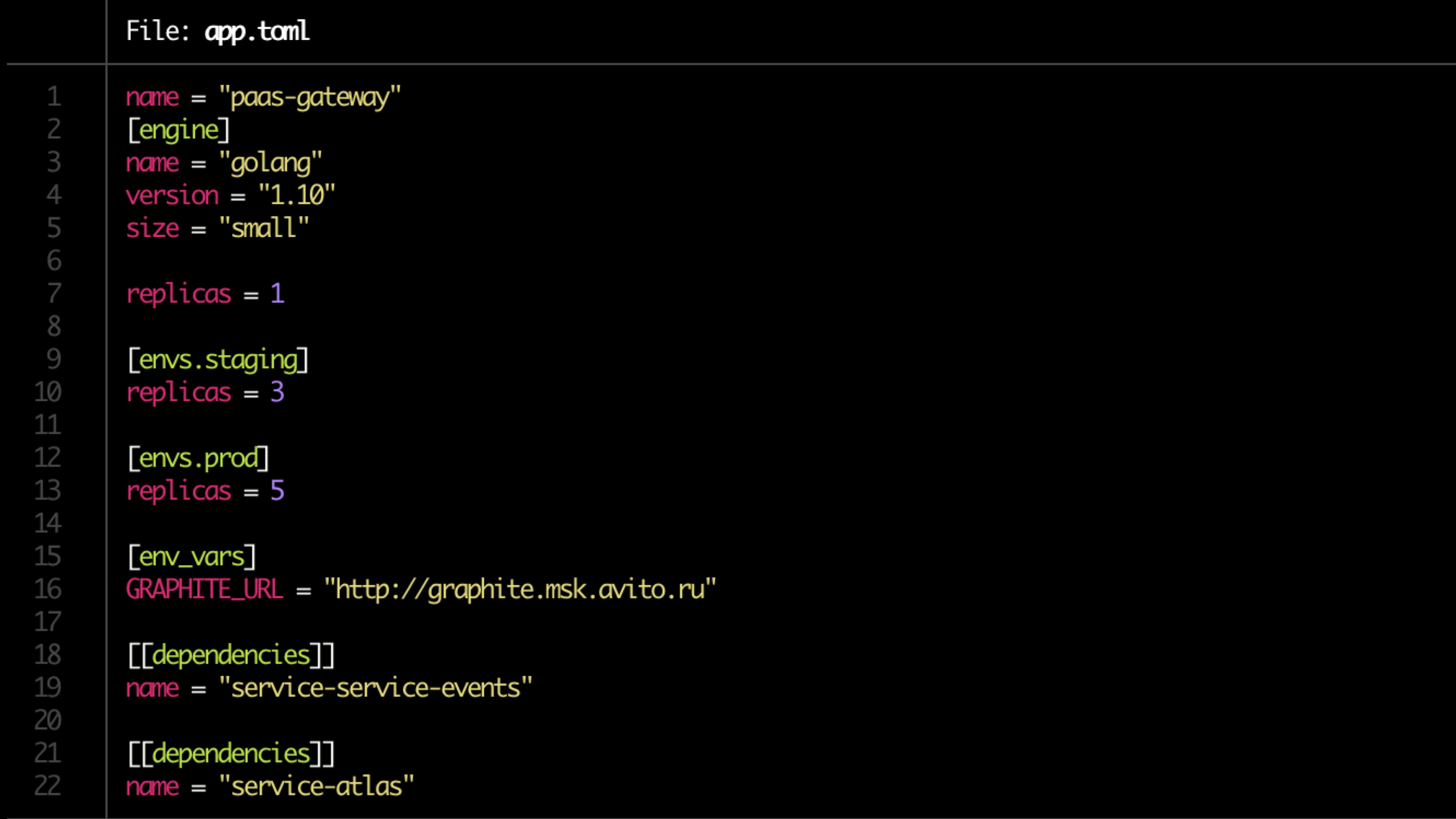
Конфиг описывается в toml файле.
Пример файла:
Валидация
Базовая валидация проверяет:
- Наличие Dockerfile
- app.toml
- Наличие документации
- Зависимостии
- Правила алертов для мониторинга (задаёт владелец сервиса)
Документация
Документация должны быть у всех, но ее почти ни у кого нет
В документации должно быть:
- Описание сервиса (краткое)
- Ссылка на диаграмму архитектуры
- Runbook
- FAQ
- Описание endpoint API
- Labels (привязка к продукту, функциональности, структурному продразделению)
- Владелец (цы) сервиса (может быть несколько, в большинстве случаев можно определять автоматически).
Документацию нужно ревьюить.
Подготовка пайплайна
- Готовим репозитории
- Делаем пайплайн в TeamCity
- Выставляем права
- Ищем владельца (двух, одного ненадежно)
- Регистрируем сервис в Atlas (внутренний продукт)
- Проверяем миграции.
Bake
- Сборка приложения в docker image.
- Генерация helm-чартов для самого сервиса и связанных ресурсов (БД, кэш)
- Создаются тикеты админам на открытие портов, учитываются ограничения по памяти и cpu.
- Прогон unit-тестов. Ведётся учёт по code-coverage. Если ниже определённого, то деплой заворачивается. Если объём покрытия не прогрессирует, пушатся уведомления.
Поиск owner определяется по пушам (количество пушей и количество кода в них).
Если есть потенциально опасные миграции (alter), то регистрируется триггер в Атлас и сервис помещается в карантин.
Через пуши владельцам разруливается карантин (в ручном режиме?)
Проверка конвенций
Проверяем:
- Сервисные endpoint
- Соответствие ответов схеме
- Формат логов
- Выставление заголовков (в том числе X-Source-ID при отправке сообщений в шину для отслеживания связности через шину)
Тесты
Тестирование выполняться в закрытом контуре (например hoverfly.io) — записывается типовая нагрузка. Затем по ней эмулируется в закрытом контуре.
Проверяется соответствие потреблений ресурсов (отдельно смотрим крайние случаи — слишком мало / много ресурсов), отсечка по rps.
Нагрузочное тестирование также показывает дельту производительности между версиями.
Canary тесты
Начинаем запуск на очень малом количестве пользователей (
Минимальная нагрузка 5 минут. Основная 2 часа. Затем увеличивается объём пользователей если все ок.
Смотрим:
- Продуктовые метрики (в первую очередь) — их много (100500)
- Ошибки в Sentry
- Статусы ответов,
- Respondents time — точное и среднее время ответов
- Latency
- Исключения (обработанные и необработанные)
- Специфичнее для языка метрики (например, воркеры php-fpm)
Squeeze testing
Тестирование через выдавливание.
Нагружаем реальными пользователями 1 инстанс до точки отказа. Смотрим его потолок. Далее добавляем ещё инстанс и догружаем. Смотрим следующий потолок. Смотрим регрессию. Обогащаем или заменяем данные из нагрузочного тестирования в Atlas.
Масштабирование
Только по cpu плохо, надо добавлять продуктовые метрики.
Итоговая схема:
- CPU + RAM
- Кол-во запросов
- Время ответа
- Прогноз по историческим данным
При масштабировании не забывать смотреть зависимости по сервисам. Помним про каскад масштабирования (+1 уровень). Смотрим исторические данные инициализирующего сервиса.
Дополнительно
- Обработка триггеров — миграции, если не осталось версии ниже Х
- Сервис давно не обновлялся
- Карантин
- Secure updates
Дашборд
Смотрим на все сверху в аггрегированном виде и делаем выводы.
- Фильтрация по сервису и лейблам
- Интеграция с трассировкой, логированием, мониторингом
- Единая точка документации по сервисам
- Единая точка показа всех событий по сервисам
Пример:

