Компьютерное зрение: ранняя остановка для экономии времени и вычислительной мощности

 Автор статьи: Рустем Галиев
Автор статьи: Рустем ГалиевIBM Senior DevOps Engineer & Integration Architect. Официальный DevOps ментор и коуч в IBM
Привет Хабр! В очередном продолжении темы компьютерного зрения. Сегодня мы сосредоточимся на обратных вызовах, EarlyStopping и LearningRateScheduler.
Мы уже научились создавать, обучать и оценивать сверточные нейронные сети. Сегодня мы сосредоточимся на дополнительных инструментах, которые обычно используются для достижения лучших результатов: обратные вызовы.
Давайте создадим файл Python, который будет содержать функции для очистки наших изображений тренировки/теста и создания модели, чтобы мы могли использовать ее непосредственно на последующих шагах.
touch preparation.py
Открываем только что созданный файл prepare.py.
import numpy as np
import tensorflow as tf
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(3, 3), activation='relu', input_shape=(32,32,1)),
tf.keras.layers.AveragePooling2D(),
tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.AveragePooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation='relu'),
tf.keras.layers.Dense(units=84, activation='relu'),
tf.keras.layers.Dense(units=10, activation='softmax')
])
return model
def prepare_data(images):
# Normalize the image pixels
images = images / 255.0
# Add an extra dimension to the matrix
images = np.expand_dims(images,-1)
# Pad the images to get it into 32x32 size
images = np.pad(images, ((0,0),(2,2),(2,2),(0,0)), 'constant')
return images
Что произойдет, если мы запустим слишком много эпох? Скорее всего, модель «переоснащает» обучающие данные, что означает, что она «слишком идеально подходит» к обучающим данным, и начинает хуже работать с тестовыми данными. Мы хотим избежать этого. Было бы здорово, если бы мы могли остановить обучение, когда достигнем максимальной точности (или любого другого ценного показателя)?
Например, если мы отслеживаем точность, мы должны иметь возможность остановить обучение, если точность нашей модели перестала улучшаться в течение n последовательных эпох. К счастью, мы можем сделать это с помощью обратного вызова с ранней остановкой!
Давайте создадим новый файл, в котором будет находиться наш код:
touch step1.py
Открываем только что созданный файл step1.py.
Мы будем использовать тот же набор данных Fashion MNIST. Мы добавляем весь следующий код, который будет импортировать библиотеки, очищать данные для обучения и создавать модель.
import tensorflow as tf
import matplotlib.pyplot as plt
# Function to clean up the data and create the model
from preparation import prepare_data, create_model
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images = prepare_data(training_images)
test_images = prepare_data(test_images)
model = create_model()
print(model.summary())
Давайте выполним код
python step1.py
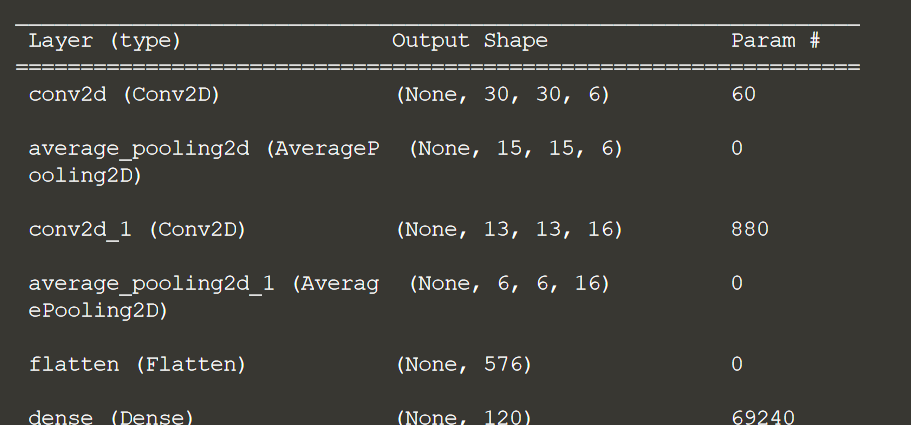
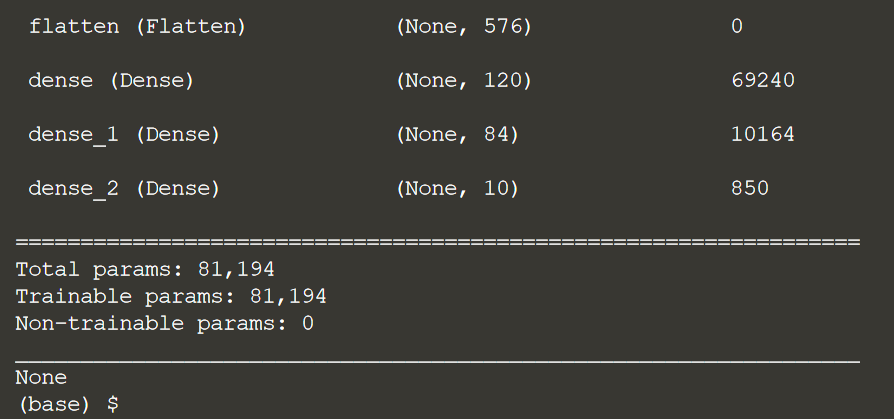
Давайте теперь определим обратный вызов, чтобы включить его, когда мы собираемся соответствовать модели.
callback1 = tf.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
mode='max', min_delta=0.001,
patience = 5)Аргументы включают:
monitor: передает точность для контроля в экземпляре обратного вызова EarlyStoppingmode: max, так как мы стремимся к максимальной точности; для потери, это было бы минmin_delta = 0,001: минимальное изменение отслеживаемой величины, которое можно квалифицировать как улучшение, т. е. абсолютное изменение меньше, чем min_delta, не будет считаться улучшением.patience: количество эпох без улучшения, после которых обучение будет остановлено
Определив наш обратный вызов, мы теперь перейдем к компиляции и подгонке нашей модели.
Давайте теперь скомпилируем, подгоним модель и построим график, чтобы увидеть, что произошло.
Добавьте обратный вызов в метод model.fit:
# compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# add a high number(100) of epochs to witness early stopping
model.fit(training_images, training_labels, validation_data=(test_images,test_labels), epochs=100, callbacks=[callback1], batch_size=1024)
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.savefig('accuracy_plot_1.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.savefig('loss_plot_1.png')
Выполним код, чтобы просмотреть выходные данные и графики. Это может занять некоторое время, так что можно заварить кофе, пока ждем
python step1.py
Щелкните по accuracy_plot_1.png, чтобы просмотреть график точности.
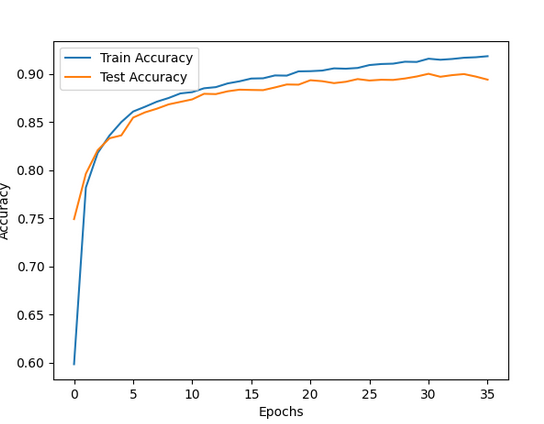
Нажмите loss_plot_1.png, чтобы визуализировать график потерь.
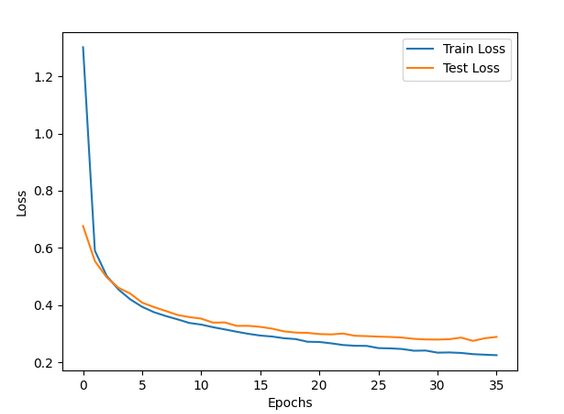
Вы можете видеть, что по мере того, как точность модели начала снижаться после достижения максимума, обратный вызов EarlyStopping позволил модели остановиться в этой точке.
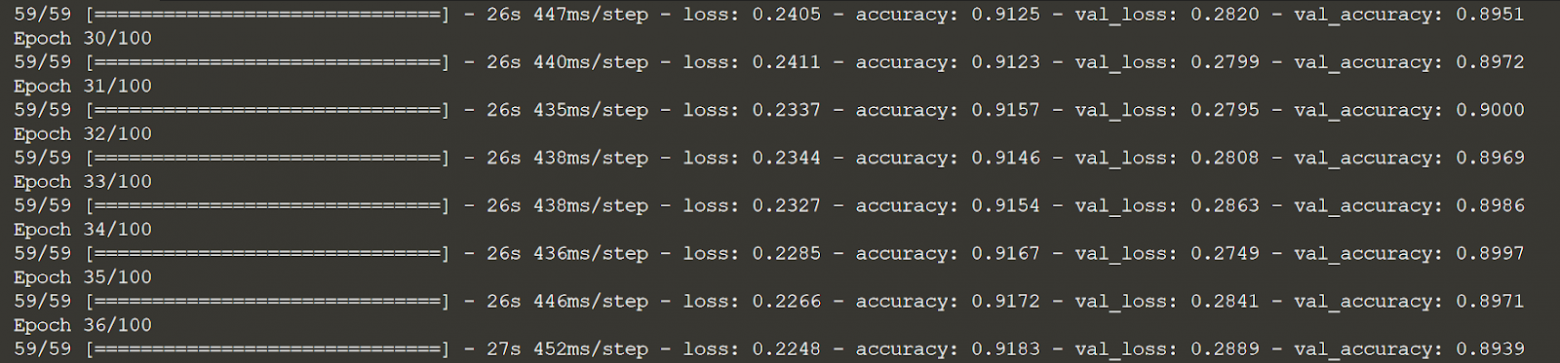
У каждого оптимизатора (который мы устанавливаем в методе компиляции) есть аргумент скорости обучения. Хотя он принимает значение по умолчанию, это параметр, требующий настройки. Слишком низкое значение потребует много времени (больше эпох) для достижения хорошей точности уровня, а слишком высокое значение будет превышать минимум и просто колебаться при плохих значениях точности. В любом случае, один из способов работать со скоростью обучения — зафиксировать ее на средне-высоком значении, а затем уменьшать ее в каждую эпоху. Это приводит к большим шагам к минимуму в начале, но к более медленным шагам через некоторое время.
Мы можем сделать это с помощью LearningRateScheduler. Посмотрим как!
Мы создаем новый файл, в котором будет находиться наш код:
touch step2.py
Открываем только что созданный нами файл step2.py
Мы будем использовать тот же набор данных Fashion MNIST. Добавьте весь следующий код, который будет импортировать библиотеки, очищать данные для обучения и создавать модель. Не беспокойтесь о двух функциях, которые мы импортируем; мы просто хотим иметь возможность быстро очистить данные и получить модель.
import tensorflow as tf
import matplotlib.pyplot as plt
# Function to clean up the data and create the model
from preparation import prepare_data, create_model
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images = prepare_data(training_images)
test_images = prepare_data(test_images)
model = create_model()
print(model.summary())
Давайте теперь определим обратный вызов, чтобы включить точку, в которой мы будем соответствовать модели.
# Scheduler function that reduces the learning rate by a factor of e^-0.1.
def scheduler(epoch, lr):
if epoch < 5:
return lr
else:
return lr * tf.math.exp(-0.1)
callback2 = tf.keras.callbacks.LearningRateScheduler(schedule=scheduler,verbose=1)
Аргументы:
scheduler: функция, которая принимает индекс эпохи (целое число, индексированное от 0) и текущую скорость обучения (с плавающей запятой) в качестве входных данных и возвращает новую скорость обучения в качестве вывода (с плавающей запятой)verbose: int. 0: quiet, 1: обновить сообщения
Определив наш обратный вызов, мы теперь перейдем к компиляции и подгонке нашей модели.
Давайте теперь скомпилируем, подгоним модель и построим график, чтобы посмотреть, что происходит. Кроме того, проверьте параметр скорости обучения в оптимизаторе Adam в методе компиляции.
Открываем файл: step2.py.
# Compile the Model
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(training_images, training_labels, validation_data=(test_images,test_labels), epochs=30, callbacks=[callback2], batch_size=1024)
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.savefig('accuracy_plot_2.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.savefig('loss_plot_2.png')
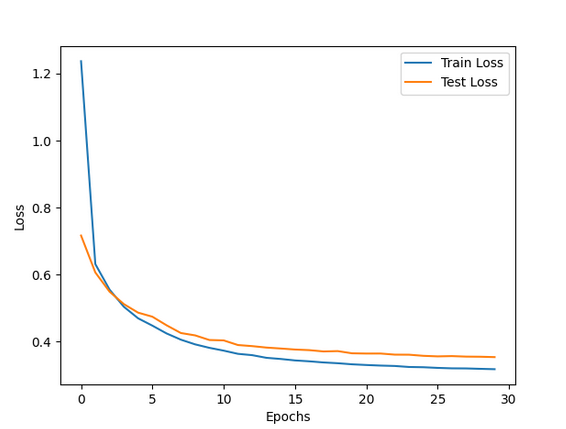
Мы выполняем код для просмотра вывода и графиков. Посмотрите на выходные данные model.fit() и на то, как скорость обучения уменьшается в зависимости от функции планировщика. Подгонка может занять некоторое время.
python step2.py
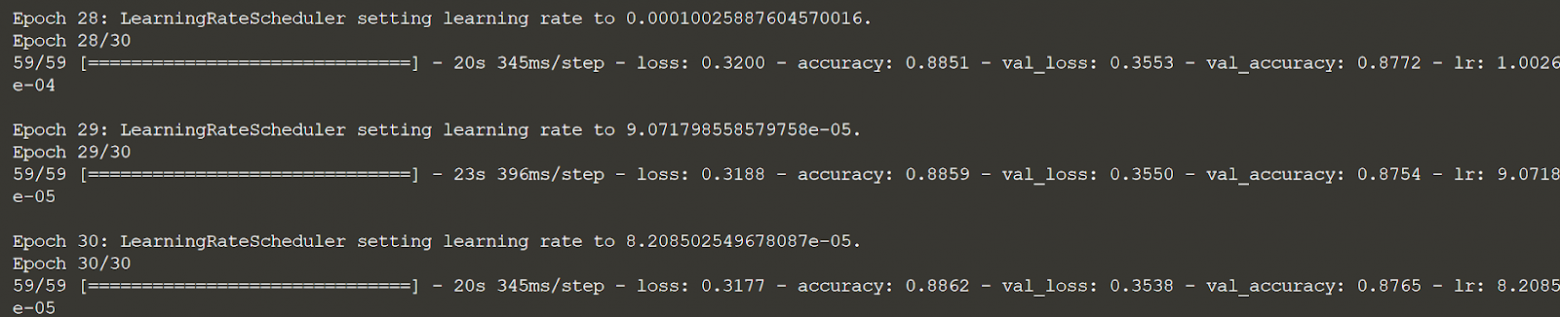
Щелкните по accuracy_plot_2.png, чтобы просмотреть график точности.
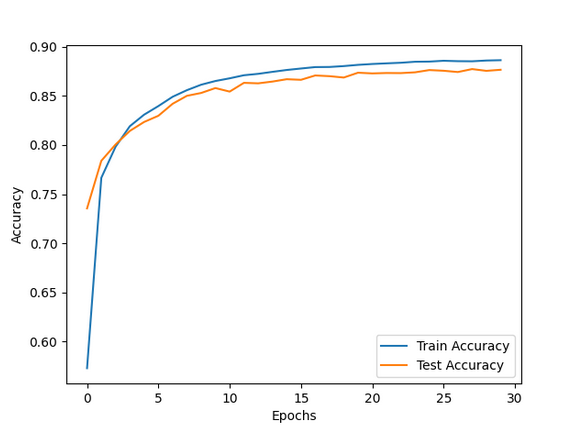
Нажмите loss_plot_2.png, чтобы визуализировать график потерь.
 Полный код
Полный код
Preparation.py:
import numpy as np
import tensorflow as tf
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=(3, 3), activation='relu', input_shape=(32,32,1)),
tf.keras.layers.AveragePooling2D(),
tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu'),
tf.keras.layers.AveragePooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=120, activation='relu'),
tf.keras.layers.Dense(units=84, activation='relu'),
tf.keras.layers.Dense(units=10, activation='softmax')
])
return model
def prepare_data(images):
# Normalize the image pixels
images = images / 255.0
# Add an extra dimension to the matrix
images = np.expand_dims(images,-1)
# Pad the images to get it into 32x32 size
images = np.pad(images, ((0,0),(2,2),(2,2),(0,0)), 'constant')
return images
Step1.py
import tensorflow as tf
import matplotlib.pyplot as plt
Function to clean up the data and create the model
from preparation import prepare_data, create_model
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images = prepare_data(training_images)
test_images = prepare_data(test_images)
model = create_model()
print(model.summary())
callback1 = tf.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
mode='max', min_delta=0.001,
patience = 5)
compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
add a high number(100) of epochs to witness early stopping
model.fit(training_images, training_labels, validation_data=(test_images,test_labels), epochs=100, callbacks=[callback1], batch_size=1024)
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.savefig('accuracy_plot_1.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.savefig('loss_plot_1.png')
Step2.py
import tensorflow as tf
import matplotlib.pyplot as plt
Function to clean up the data and create the model
from preparation import prepare_data, create_model
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images = prepare_data(training_images)
test_images = prepare_data(test_images)
model = create_model()
print(model.summary())
Scheduler function that reduces the learning rate by a factor of e^-0.1.
def scheduler(epoch, lr):
if epoch < 5:
return lr
else:
return lr * tf.math.exp(-0.1)
callback2 = tf.keras.callbacks.LearningRateScheduler(schedule=scheduler,verbose=1)
Compile the Model
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(training_images, training_labels, validation_data=(test_images,test_labels), epochs=30, callbacks=[callback2], batch_size=1024)
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.savefig('accuracy_plot_2.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.savefig('loss_plot_2.png')
В заключение статьи приглашаю всех желающих на бесплатный урок по теме «Kornia — убийца OpenCV?», на котором участники узнают:
Почему Kornia применяется в обучении нейронных сетей и PyTorch, а OpenCV — нет.
За счет чего Kornia работает в разы быстрее, чем OpenCV.
Какие продвинутые функции потерь и алгоритмы для моделей Компьютерного Зрения предоставляет Kornia.
Как написать алгоритм, которые автоматически сшивает несколько фотографий в панорамный снимок.
Почему Kornia — это лучший инструмент для задач, связанных с геометрией изображений.
Регистрация на мероприятие открыта по ссылке.
