Компоненты связности в динамическом графе за один проход
Люди встречаются, люди ссорятся, добавляются и удаляют друзей в социальных сетях. Этот пост о математике и алгоритмах, красивой теории, любви и ненависти в этом непостоянном мире. Этот пост о поиске компонент связности в динамических графах.
Большой мир генерирует большие данные. Вот и на нашу голову свалился большой граф. Настолько большой, что мы можем удержать в памяти его вершины, но не ребра. Кроме того, относительно графа приходят обновления — какое ребро добавить, какое удалить. Можно сказать, что каждое такое обновление мы видим в первый и последний раз. В таких условиях необходимо найти компоненты связности.
Поиск в глубину/ширину здесь не пройдут просто потому, что весь граф в памяти не удержать. Система неперескающихся множеств могла бы сильно помочь, если бы ребра в графе только добавлялись. Что же делать в общем случае?
Задача. Дан неориентированный граф на
вершинах. Изначально, граф — пустой. Алгоритму приходит последовательность обновлений
, которую можно прочитать в заданном порядке ровно один раз. Каждое обновление — это команда удалить или добавить ребро между парой вершин
и
. Гарантируется, что ни в какой момент времени между парой вершин не будет удалено ребер больше чем есть. По прочтении последовательности алгоритм должен вывести все компоненты связности с вероятностью успеха
. Разрешается использовать
памяти, где
— некоторая константа.
Решение задачи состоит из трех ингридиентов.
- Матрица инцидентности как представление.
- Метод стягивания как алгоритм.
-сэмплирование как оптимизация.
Реализацию можно посмотреть на гитхабе: link.
Матрица инцидентности как представление
Первая структура данных для хранения графа будет крайне неоптимальна. Мы возьмем матрицу инцедентности размера
, в которой преимущественно будут нули. Каждая строка в матрице соответствует вершине, а столбец — возможному ребру. Пусть
. Для пары вершин
, соединенных ребром, зададим
и
, в противном случае значения равны нулю.
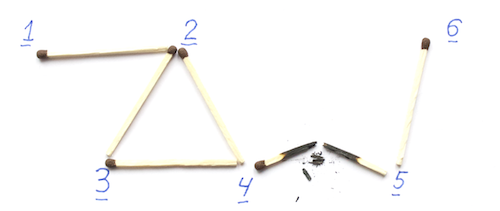
Как пример, посмотрим на граф на картинке ниже.

Для него матрица инцидентности будет выглядеть так.
Невооруженным глазом видно, что у такого представления есть серьезный недостаток — размер . Мы его оптимизируем, но позже.
Есть и неявное преимущество. Если взять множество вершин и сложить все вектора-строки матрицы
, которые соответствуют
, то ребра между вершинами
сократятся и останутся только те, что соединяют
и
.
Например, если взять множество и сложить соответствующие вектора, мы получим
Ненулевые значения стоят у ребер ,
и
.
Стягивание графа как алгоритм
Поймем, что такое стягивание ребра. Вот есть у нас две вершины и
, между ними есть ребро. Из
и
могут исходить и другие ребра. Стягивание ребра
это процедура, когда мы сливаем вершины
и
в одну, скажем
, ребро
удаляем, а все оставшиеся ребра, инцидентные
и
, проводим в новую вершину
.
Интересная особенность: в терминах матрицы инцидентности, чтобы стянуть ребро , достаточно сложить соответствующие вектора-строки. Само ребро
сократится, останутся только те, что идут наружу.
Теперь алгоритм. Возьмем граф и для каждой неизолированной вершины выберем соседа.

Стянем соответствующие ребра.

Повторим итерацию раз.

Заметим, что после каждой итерации стягивания компоненты связности нового графа взаимнооднозначно сопоставляются компонентам старого. Мы можем даже помечать, какие вершины были слиты в результирующию, чтобы потом восстановить ответ.
Заметим также, что после каждой итерации, любая компонента связности хотя бы из двух вершин уменьшается как минимум в два раза. Это естественно, поскольку в каждую вершину новой компоненты было слито как минимум две вершины старой. Значит, после итераций в графе останутся только изолированный вершины.
Переберем все изолированный вершины и по истории слияний восстановим ответ.
-сэмплирование как оптимизация
Все было бы замечательно, но приведенный алгоритм работает что по времени, что по памяти . Чтобы его оптимизировать, мы построим скетч — специальную структуру данных для компактного представления векторов-строк.
От скетча потребуется три свойства.
Во-первых, компактность. Если мы строим скетч для вектора размера
, то сам скетч
должен быть размера
.
Во-вторых, сэмплирование. На каждой итерации алгоритма, нам требуется выбирать соседа. Мы хотим способ получать индекс хотя бы одного ненулевого элемента, если такой есть.
В-третьих, линейность. Если мы построили для двух векторов и
скетчи
и
. Должен быть эффективный метод, получить скетч
. Это поможет стягивать ребра.
Мы воспользуемся решением задачи -сэмплирования.
Задача. Дан вектор нулевой вектор размерности
. Алгоритму приходит последовательность из
обновлений вида
: прибаваить
к значению
.
может быть как положительным, так и отрицательным целым числом. Результирующий вектор на некоторых позициях может иметь ненулевые значения. Эти позиции обозначим через
. Требуется выдать любую позицию из
равновероятно. Все обновления нужно обработать за один проход, можно использовать
памяти. Гарантируется, что максимальное значение в
укладывается в
бит.
1-разреженные вектор
Для начала мы решим более простую задачу. Пусть у нас есть гарантия, что конечный вектор содержит ровно одну ненулевую позицию. Будем говорить, что такой вектор — 1-разреженный. Будем поддерживать две переменных и
. Поддерживать их просто: на каждом обновлении прибавляем к первой
, ко второй
.
Обозначим искомую позицию через . Если она только одна, то
и
. Чтобы найти позицию, считаем
.
Можно вероятностно проверить, является ли вектор 1-разреженным. Для этого возьмем простое число , случайное целое
и посчитаем переменную
. Вектор проходит тест на 1-разреженность, если
и
.
Очевидно, что если вектор действительно 1-разреженный, то
и тест он пройдет. В противном случае, вероятность пройти тест не более (на самом деле, максимум
).
Почему?
Если мы хотим повысить точность проверки до произвольной вероятности , то нужно посчитать значение
на
случайных
.
 -разреженный вектор
-разреженный вектор
Теперь попробуем решить задачу для -разреженного вектора, т.е. содержащего не более
ненулевых позиций. Нам потребуется хэширование и предыдущий метод. Общая идея — восстановить вектор целиком, а потом выбрать какой-нибудь элемент случайно.
Возьмем случайную 2-независимую хэш-функцию . Эта такая функция, которая два произвольных различных ключа распределяет равновероятно независимо. Возьмем хэш-таблицу размера
. В каждой ячейке таблицы будет сидеть алгоритм для 1-разереженного вектора.
Когда нам приходит обновление , мы отправляем это обновление алгоритму в ячейке
.
Можно посчитать, что для отдельной ячейки, вероятность что там произойдет коллизия хотя бы по двум ненулевым координатам будет не более .
Пусть мы хотим восстановить все координаты с вероятностью успеха , или с вероятностью провала
. Возьмем не одну хэш-таблицу, а сразу
. Несложно понять, что вероятность провала в декодировании отдельной координаты будет
. Вероятность провала в декодировании хотя бы одной из
координат
. Если в сумме декодирование для 1-разреженных векторов работает с вероятностью провала
, то мы победили.

Итоговый алгоритм таков. Берем хэш-таблиц размера
. В каждой ячейке алгоритма будет находиться свой декодер для 1-разреженного вектора с вероятностью провала
.
Каждое обновление обрабатывается в каждой хэш-таблице отдельно алгоритмом в ячейке
.
По завершении, извлекаем из всех успешно отработавших 1-декодеров по координате и сливаем их в один список.
Максимум, в общей таблице будет затронутых 1-декодеров. Поэтому суммарная вероятность, что один из 1-декодеров отработает неверно не превысит
. Также вероятность, что хотя бы одна координата не будет восстановлена не превышает
. Итого, вероятность провала алгоритма
.
Еще одно хэширование для общего случая
Последний шаг в -сэмплировании, это понять, что делать с общим случаем. Мы снова воспользуемся хэшированием. Возьмем
-независимую хэш-функцию
для некоторого
.
Будем говорить, что обновление является
-интересным, если
. Иначе говоря, в бинарной записи
содержит
нулей в конце.
Запустим алгоритм для -разреженного вектора параллельно на
уровнях. На уровне
будем учитывать только
-интересные обновления. Несложно понять, что чем больше
, тем меньше шансов (а шансов
) у обновления быть учтенным.
Найдем первый уровень с наибольшим , где приходили хоть какие-то обновления, и попытаемся его восстановить. Если восстановление пройдет успешно, вернем случайно выбранную позицию.
Есть несколько моментов, на которые хочется вкратце обратить внимание.
Во-первых, как выбирать . В общем случае вектор может иметь более чем
ненулевых позиций, но с каждым увеличением
на единицу, мат. ожидание ненулевых позиций падает ровно в 2 раза. Можно выбрать такой уровень, при котором мат.ожидание будет между
и
. Тогда из оценок Чернова и
независимости хэш-функции, вероятность, что вектор будет нулевым или иметь более чем
ненулевых позиций, окажется экспоненциальна мала.
Это определяет выбор , где
— допустимая вероятность провала.
Во-вторых, из -независимости хэш-функции следует, что для любой позиции вероятность пройти фильтр окажется равной. Поскольку
-разреженные вектора мы уже умеем восстанавливать, то получить равномерное распределение уже тривиально.
Итого, мы научились выбирать случайную ненулевую позицию согласно равномерному распределению.
Смешать, но не взбалтывать
Осталось понять, как все совместить. Нам известно, что в графе вершин. Для каждой вершины, точнее каждого вектора-строки в матрице инцидентности, заведем
скетчей
для
-сэмплирования. На
-ой итерации алгоритма стягивания будем использовать для сэмплирования
-ые скетчи.
При добавлении ребра добавим во все скетчи вершин
и
соответствующие +1 и -1 соответственно.
Когда ребра закончатся и нас спросят про компоненты, запустим алгоритм стягивания. На -ой итерации, через
-сэмплирование из скетча
найдем соседа каждой вершине. Чтобы стянуть ребро
, сложим все скетчи соответствующие
и
. У каждой новой вершины сохраним список вершин, которые были в нее слиты.
Все. В конце просто проходим по изолированным вершинам, по истории слияний восстанавливаем ответ.
Кто виноват и еще раз что делать
На самом деле тема этого поста возникла не просто так. В январе к нам, в Питер в CS Клуб, приезжал Илья Разенштейн (@ilyaraz), аспирант MIT, и рассказывал про алгоритмы для больших данных. Было много интересного (посмотрите описание курса). В частности Илья успел рассказать первую половину этого алгоритма. Я решил довести дело до конца и рассказать весь результат на Хабре.
В целом, если вам интересна математика, связанная с вычислительными процессами aka Theoretical Computer Science, приходите к нам в Академический Университет на направление Computer Science. Внутри научат сложности, алгоритмам и дискретной математике. С первого семестра начнется настоящая наука. Можно выбираться наружу и слушать курсы в CS Клубе и CS Центре. Если вы не из Питера, есть общежитие. Прекрасный шанс переехать в Северную Столицу.
Подавайте заявку, готовьтесь и поступайте к нам.
Источники
