Коды избыточности: простыми словами о том, как надёжно и дёшево хранить данные

Так выглядит избыточность.
Коды избыточности* широко применяются в компьютерных системах для увеличения надёжности хранения данных. В Яндексе их используют в очень многих проектах. Например, применение кодов избыточности вместо репликации в нашем внутреннем объектном хранилище экономит миллионы без снижения надёжности. Но несмотря на широкое распространение, понятное описание того, как работают коды избыточности, встречается очень редко. Желающие разобраться сталкиваются примерно со следующим (из Википедии):

Меня зовут Вадим, в Яндексе я занимаюсь разработкой внутреннего объектного хранилища MDS. В этой статье я простыми словами опишу теоретические основы кодов избыточности (кодов Рида — Соломона и LRC). Расскажу, как это работает, без сложной математики и редких терминов. В конце приведу примеры использования кодов избыточности в Яндексе.
Ряд математических деталей я не буду рассматривать подробно, но дам ссылки для тех, кто хочет погрузиться глубже. Также замечу, что некоторые математические определения могут быть не строгими, так как статья рассчитана не на математиков, а на инженеров, желающих разобраться в сути вопроса.
* В англоязычной литературе коды избыточности часто называют erasure codes.
Суть всех кодов избыточности предельно простая: хранить (или передавать) данные так, чтобы они не пропадали при возникновении ошибок (поломках дисков, ошибках передачи данных и т. д.).
В большинстве* кодов избыточности данные разбиваются на n блоков данных, для них считается m блоков кодов избыточности, всего получается n + m блоков. Коды избыточности строятся таким образом, чтобы можно было восстановить n блоков данных, используя только часть из n + m блоков. Далее мы рассмотрим только блочные коды избыточности, то есть такие, в которых данные разбиваются на блоки.

Чтобы восстановить все n блоков данных, нужно иметь минимум n из n + m блоков, так как нельзя получить n блоков, имея только n-1 блок (в этом случае пришлось бы 1 блок брать «из воздуха»). Достаточно ли n произвольных блоков из n + m блоков для восстановления всех данных? Это зависит от типа кодов избыточности, например коды Рида — Соломона позволяют восстановить все данные с помощью произвольных n блоков, а коды избыточности LRC — не всегда.
Хранение данных
В системах хранения данных, как правило, каждый из блоков данных и блоков кодов избыточности записывается на отдельный диск. Тогда при поломке произвольного диска исходные данные все равно можно будет восстановить и прочитать. Данные можно будет восстановить даже при одновременной поломке нескольких дисков.
Передача данных
Коды избыточности можно использовать для надёжной передачи данных в ненадёжной сети. Передаваемые данные разбивают на блоки, для них считают коды избыточности. По сети передаются и блоки данных, и блоки кодов избыточности. При возникновении ошибок в произвольных блоках (вплоть до некоторого количества блоков), данные все равно можно безошибочно передать по сети. Коды Рида — Соломона, например, используют для передачи данных по оптическим линиям связи и в спутниковой связи.
* Есть также коды избыточности, в которых данные не разбиваются на блоки, например коды Хэмминга и коды CRC, широко применяемые для передачи данных в сетях Ethernet. Это коды для помехоустойчивого кодирования, они предназначены для обнаружения ошибок, а не для их исправления (код Хэмминга также позволяет частично исправлять ошибки).
Коды Рида — Соломона — одни из наиболее широко распространённых кодов избыточности, изобретённые ещё в 1960-х и впервые получившие широкое применение в 1980-х для серийного выпуска компакт-дисков.
Ключевых вопросов для понимания кодов Рида — Соломона два: 1) как создавать блоки кодов избыточности; 2) как восстанавливать данные с помощью блоков кодов избыточности. Найдем на них ответы.
Для упрощения далее будем считать, что n=6 и m=4. Другие схемы рассматриваются по аналогии.
Как создавать блоки кодов избыточности
Каждый блок кодов избыточности считается независимо от остальных. Для подсчёта каждого блока используются все n блоков данных. На схеме ниже X1-X6 — блоки данных, P1–P4 — блоки кодов избыточности.
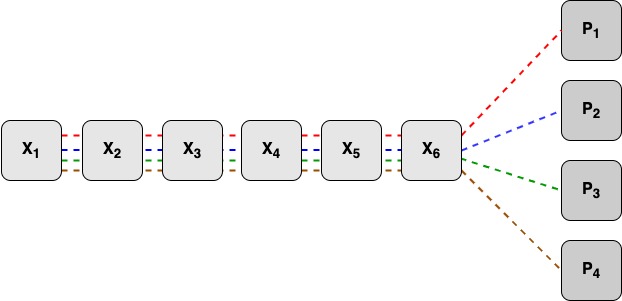
Все блоки данных должны быть одинакового размера, для выравнивания можно использовать нулевые биты. Полученные блоки кодов избыточности будут иметь тот же размер, что и блоки данных. Все блоки данных разбиваются на слова (например, по 16 бит). Допустим, мы разбили блоки данных на k слов. Тогда все блоки кодов избыточности тоже будут разбиты на k слов.

Для подсчёта i-го слова каждого блока избыточности будут использоваться i-е слова всех блоков данных. Они будут считаться по следующей формуле:

Здесь значения x — слова блоков данных, p — слова блоков кодов избыточности, все альфа, бета, гамма и дельта — специальным образом подобранные числа, одинаковые для всех i. Сразу нужно сказать, что все эти значения — не обычные числа, а элементы поля Галуа, операции +, -, *, / — не привычные всем нам операции, а специальные операции, введённые над элементами поля Галуа.
Зачем нужны поля Галуа

Казалось бы, всё просто: разбиваем данные на блоки, блоки — на слова, с помощью слов блоков данных считаем слова блоков кодов избыточности — получаем блоки кодов избыточности. В целом это так и работает, но дьявол в деталях:
- Как сказано выше, размер слова — фиксированный, в нашем примере 16 бит. Формулы выше для кодов Рида — Соломона таковы, что при использовании обычных целых чисел результат вычисления p может быть не представим с помощью слова допустимого размера.
- При восстановлении данных формулы выше будут рассматриваться как система уравнений, которую нужно решить, чтобы восстановить данные. В процессе решения может появиться необходимость выполнить деление целых чисел друг на друга, результатом чего будет вещественное число, которое нельзя точно представить в памяти компьютера.
Эти проблемы не позволяют использовать для кодов Рида — Соломона целые числа. Решение проблемы оригинальное, его можно описать следующим образом: давайте придумаем специальные числа, которые можно представить с помощью слов нужной длины (например, 16 бит), и результат выполнения всех операций над которыми (сложение, вычитание, умножение, деление) также будет представлен в памяти компьютера при помощи слов нужной длины.
Такие «специальные» числа давно изучает математика, их называют полями. Поле — это множество элементов с определёнными для них операциями сложения, вычитания, умножения и деления.
Поля Галуа* — это поля, для которых существует и единственен результат каждой операции (+, -, *, /) для любых двух элементов поля. Поля Галуа можно построить для чисел, являющихся степенью 2: 2, 4, 8, 16 и т. д. (на самом деле степенью любого простого числа p, но на практике нас интересуют только степени 2). Например, для слов размером 16 бит это поле, содержащее 65 536 элементов, для каждой пары которых можно найти результат любой операции (+, -, *, /). Значения x, p, альфа, бета, гамма, дельта из уравнений выше для расчётов будут считаться элементами поля Галуа.
Таким образом, мы имеем систему уравнений, с помощью которых можно построить блоки кодов избыточности, написав соответствующую компьютерную программу. С помощью этой же системы уравнений можно выполнить восстановление данных.
* Это не строгое определение, скорее описание.
Как восстанавливать данные
Восстановление нужно тогда, когда из n + m блоков часть блоков отсутствует. Это могут быть как блоки данных, так и блоки кодов избыточности. Отсутствие блоков данных и/или блоков кодов избыточности будет означать, что в уравнениях выше неизвестны соответствующие переменные x и/или p.
Уравнения для кодов Рида — Соломона можно рассматривать как систему уравнений, в которых все значения альфа, бета, гамма, дельта — константы, все x и p, соответствующие доступным блокам, — известные переменные, а остальные x и p — неизвестные.
Например, пусть блоки данных 1, 2, 3 и блок кодов избыточности 2 недоступны, тогда для i-й группы слов будет следующая система уравнений (неизвестные отмечены красным):

Мы имеем систему из 4 уравнений с 4 неизвестными, значит можем решить её и восстановить данные!
Из этой системы уравнений следуют ряд выводов про восстановление данных для кодов Рида — Соломона (n блоков данных, m блоков кодов избыточности):
- Данные можно восстановить при потере любых m блоков или меньше. При потере m+1 и более блоков данные восстановить нельзя: нельзя решить систему из m уравнений с m + 1 неизвестными.
- Для восстановления даже одного блока данных нужно использовать любые n из оставшихся блоков, при этом можно использовать любой из кодов избыточности.
Что ещё нужно знать
В описании выше я обхожу стороной ряд важных вопросов, для рассмотрения которых нужно глубже погружаться в математику. В частности, ничего не говорю про следующее:
- Система уравнений для кодов Рида — Соломона должна иметь (единственное) решение при любых комбинациях неизвестных (не более m неизвестных). Исходя из этого требования подбираются значения альфа, бета, гамма и дельта.
- Систему уравнений нужно уметь автоматически строить (в зависимости от того, какие блоки недоступны) и решать.
- Нужно построить поле Галуа: для заданного размера слова уметь находить результат любой операции (+, -, *, /) для любых двух элементов.
В конце статьи есть ссылки на литературу по этим важным вопросам.
Выбор n и m
Как на практике выбрать n и m? На практике в системах хранения данных коды избыточности используют для экономии места, поэтому m выбирают всегда меньше n. Их конкретные значения зависят от ряда факторов, в том числе:
- Надёжность хранения данных. Чем больше m, тем большее количество отказов дисков можно пережить, то есть выше надёжность.
- Избыточность хранения. Чем выше соотношение m / n, тем выше будет избыточность хранения, и тем дороже будет стоить система.
- Время обработки запросов. Чем больше сумма n + m, тем дольше будет время ответа на запросы. Так как для чтения данных (во время восстановления) нужно прочитать n блоков, хранящихся на n разных дисках, то время чтения будет определяться самым медленным диском.
Кроме того, хранение данных в нескольких ДЦ накладывает дополнительные ограничения на выбор n и m: при отключении 1 ДЦ данные всё ещё должны быть доступны для чтения. Например, при хранении данных в 3 ДЦ должно выполняться условие: m >= n/2, в противном случае возможна ситуация, когда данные недоступны для чтения при отключении 1 ДЦ.
Для восстановления данных с помощью кодов Рида — Соломона приходится использовать n произвольных блоков данных. Это очень существенный минус для распредёленных систем хранения данных, ведь для восстановления данных на одном сломанном диске придётся читать данные с большинства остальных, создавая большую дополнительную нагрузку на диски и сеть.
Наиболее часто встречающиеся ошибки — недоступность одного блока данных из-за поломки или перегруженности одного диска. Можно ли как-то уменьшить избыточную нагрузку для восстановления данных в таком (наиболее частом) случае? Оказывается, можно: специально для этого существуют коды избыточности LRC.
LRC (Local Reconstruction Codes) — коды избыточности, придуманные в Microsoft для применения в Windows Azure Storage. Идея LRC максимально проста: разбить все блоки данных на две (или более) группы и считать часть блоков кодов избыточности для каждой группы по отдельности. Тогда часть блоков кодов избыточности будет подсчитана с помощью всех блоков данных (в LRC они называются глобальными кодами избыточности), а часть — с помощью одной из двух групп блоков данных (они называются локальными кодами избыточности).
LRC обозначается тремя числам: n-r-l, где n — количество блоков данных, r — количество глобальных блоков кодов избыточности, l — количество локальных блоков кодов избыточности. Для чтения данных при недоступности одного блока данных нужно прочитать только n/l блоков — это в l раз меньше, чем в кодах Рида — Соломона.
Для примера рассмотрим схему LRC 6–2–2. X1–X6 — 6 блоков данных, P1, P2 — 2 глобальных блока избыточности, P3, P4 — 2 локальных блока избыточности.
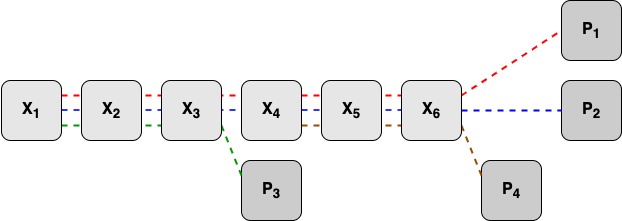
Блоки кодов избыточности P1, P2 считаются с помощью всех блоков данных. Блок кодов избыточности P3 — с помощью блоков данных X1–X3, блок кодов избыточности P4 — с помощью блоков данных X4–X6.
Остальное делается в LRC по аналогии с кодами Рида — Соломона. Уравнения для подсчёта слов блоков кодов избыточности будут такими:

Для подбора чисел альфа, бета, гамма, дельта нужно выполнить ряд условий, гарантирующих возможность восстановления данных (то есть решения системы уравнения). Подробнее о них можно прочитать в статье.
Также на практике для подсчёта локальных кодов избыточности P3, P4 применяют операцию XOR.
Из системы уравнений для LRC следует ряд выводов:
- Для восстановления любого 1 блока данных достаточно прочитать n/l блоков (n/2 в нашем примере).
- Если недоступно r + l блоков, и при этом все блоки входят в одну группу, то данные восстановить нельзя. Это легко объяснить на примере. Пусть недоступны блоки X1–X3 и P3: это r + l блоков из одной группы, 4 в нашем случае. Тогда у нас есть система из 3 уравнений с 4 неизвестными, которую нельзя решить.
- Во всех остальных случаях недоступности r + l блоков (когда из каждой группы доступен хотя бы один блок) данные в LRC можно восстановить.
Таким образом, LRC выигрывает у кодов Рида — Соломона в восстановлении данных после одиночных ошибок. В кодах Рида — Соломона для восстановления даже одного блока данных нужно использовать n блоков, а в LRC для восстановления одного блока данных достаточно использовать n/l блоков (n/2 в нашем примере). С другой стороны, LRC проигрывает кодам Рида — Соломона по максимальному количеству допустимых ошибок. В примерах выше коды Рида — Соломона могут восстановить данные при любых 4 ошибках, а для LRC существует 2 комбинации из 4 ошибок, когда данные восстановить нельзя.
Что более важно — зависит от конкретной ситуации, но зачастую экономия избыточной нагрузки, которую даёт LRC, перевешивает чуть меньшую надёжность хранения.
Помимо кодов Рида — Соломона и LRC, есть много других кодов избыточности. Разные коды избыточности используют разную математику. Вот некоторые другие коды избыточности:
- Код избыточности с помощью оператора XOR. Операция XOR выполняется над n блоками данных, и получается 1 блок кодов избыточности, то есть схема n+1 (n блоков данных, 1 код избыточности). Используется в RAID 5, где блоки данных и кодов избыточности циклически записываются на все диски массива.
- Алгоритм even-odd, основанный на операции XOR. Позволяет построить 2 блока кодов избыточности, то есть схема n+2.
- Алгоритм STAR, основанный на операции XOR. Позволяет построить 3 блока кодов избыточности, то есть схема n+3.
- Pyramide codes — ещё одни коды избыточности от Microsoft.
Ряд инфраструктурных проектов Яндекса применяет коды избыточности для надёжного хранения данных. Вот несколько примеров:
- Внутреннее объектное хранилище MDS, о котором я писал в начале статьи.
- YT — MapReduce-система Яндекса.
- YDB (Yandex DataBase) — распределённая база данных newSQL.
В MDS используются коды избыточности LRC, схема 8–2–2. Данные с кодами избыточности пишутся на 12 разных дисков в разных серверах в 3 разных ДЦ: по 4 сервера в каждом ДЦ. Подробнее об этом читайте в статье.
В YT используются как коды Рида — Соломона (схема 6–3), которые были реализованы первыми, так и коды избыточности LRC (схема 12–2–2), причём LRC — предпочтительный способ хранения.
В YDB используются коды избыточности, основанные на even-odd (схема 4–2). Про коды избыточности в YDB уже рассказывали на Highload.
Применение разных схем кодов избыточности обусловлено разными требованиями, предъявляемыми к системам. Например, в MDS данные, хранимые с помощью LRC, размещаются сразу в 3 ДЦ. Нам важно, чтобы данные оставались доступными для чтения при выходе из строя 1 любого ДЦ, поэтому блоки должны быть распределены по ДЦ так, чтобы при недоступности любого ДЦ количество недоступных блоков было не больше допустимого. В схеме 8–2–2 можно разместить по 4 блока в каждом ДЦ, тогда при отключении любого ДЦ будет недоступно 4 блока, и данные можно будет читать. Какую бы схему мы ни выбрали при размещении в 3 ДЦ, в любом случае должно быть (r + l) / n >= 0,5, то есть избыточность хранения будет минимум 50%.
В YT ситуация другая: каждый кластер YT целиком располагается в 1 ДЦ (разные кластеры в разных ДЦ), поэтому там нет такого ограничения. Схема 12–2–2 даёт избыточность 33%, то есть хранить данные выходит дешевле, при этом они также могут переживать до 4 одновременных отключений дисков, как и схема в MDS.
Есть ещё много особенностей применения кодов избыточности в системах хранения и обработки данных: нюансы восстановления данных, влияние восстановления на время выполнения запросов, особенности записи данных и т. д. Я собираюсь отдельно рассказать об этих и других особенностях применения кодов избыточности на практике, если тема будет интересна.
- Серия статей про коды Рида — Соломона и поля Галуа: https://habr.com/ru/company/yadro/blog/336286/
https://habr.com/ru/company/yadro/blog/341506/
В них доступным языком глубже рассматривается математика. - Статья от Microsoft про LRC: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/LRC12-cheng20webpage.pdf
В разделе 2 кратко объясняется теория, далее рассматривается опыт применения LRC на практике. - Схема even-odd: https://people.eecs.berkeley.edu/~kubitron/courses/cs262a-F12/handouts/papers/p245-blaum.pdf
- Схема STAR: https://www.usenix.org/legacy/event/fast05/tech/full_papers/huang/huang.pdf
- Pyramid codes: https://www.microsoft.com/en-us/research/publication/pyramid-codes-flexible-schemes-to-trade-space-for-access-efficiency-in-reliable-data-storage-systems/
- Коды избыточности в MDS: https://habr.com/ru/company/yandex/blog/311806
- Коды избыточности в YT: https://habr.com/ru/company/yandex/blog/311104/
- Коды избыточности в YDB: https://www.youtube.com/watch? v=dCpfGJ35kK8
