Ко дню рождения Далай-ламы
После перехода от Perl к JavaScript много лет тому назад, я всё испытывал за свой новый язык некоторый комплекс неполноценности из-за недостаточной поддержки Юникода. За всё то время, пока JavaScript совершал в этом направлении свой большой скачок (при переходе от ES5 к ES6), у меня в закладках осталось несколько хороших статей.
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
JavaScript has a Unicode problem
Unicode-aware regular expressions in ECMAScript 6
ES6 Strings (and Unicode,) in Depth
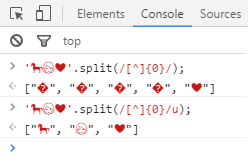
В последней из них предлагался рецепт разбиения строки на символы с учётом Юникода при помощи нового оператора ... Например (хабровский парсер не даёт почему-то ввести этот пример кодом, заменяет мультибайтовые символы на пустые строки):

И вот я вчера задумался, можно ли реализовать то же самое при помощи новых регулярных выражений. В голову пришла простая идея, которая на поверку оказалась верна:
Сегодня я внезапно понял, что вчера как раз был день рождения Далай-ламы. Поэтому мне показалось, что завершить эту заметку можно небольшой шуткой на JavaScript в честь виновника торжества.
const nothingness = /[^]{0}/;
const nothing = '';
console.log(nothing.search(nothingness));
// 0
console.log(nothing.match(nothingness));
// [ '', index: 0, input: '' ]
console.log(nothing.split(nothingness));
// []
console.log(nothing.replace(nothingness, nothing));
// ''
console.log(nothingness.test(nothing));
// true

Комментарии (5)
7 июля 2016 в 15:47
0↑
↓
Unicode — это нечто просто.Достоинство у него единственное — он таки действительно содержит всё. Дальше остаются только недостатки. Доступ по индексу за O (n) — пожалуй, самый видный невооружённым взглядом, хотя вообще говоря их сильно больше.
 vmb
vmb
7 июля 2016 в 15:50
0↑
↓
Ну, пока ещё не всё. Но Emoji — значительный шаг ко всему)
7 июля 2016 в 15:57
0↑
↓
Ну, как бы, этих самых эмодзи было не избежать, они же есть в какой-то японской кодировке, придуманной NTT.
7 июля 2016 в 16:22
0↑
↓
Строго говоря доступ по индексу к юникоду не имеет прямого отношения.
Полагаю вы подразумевали конкретный способ представления — utf-8.
Ничто не мешает вам использовать UTF-32. Получите константный доступ по индексу.7 июля 2016 в 16:53
0↑
↓
>>Ничто не мешает вам использовать UTF-32И кто его поддерживает? Никто его не поддерживает.
Да и в UTF32 можно забодяжить линейный доступ если злоупотреблять «безногими» конструкциями.
