Книга «Производительность систем»
 Привет, Хаброжители!
Привет, Хаброжители!
Книга посвящена концепциям, стратегиям, инструментам и настройке операционных систем и приложений на примере систем на базе Linux. Понимание этих инструментов и методов критически важно при разработке современного ПО. Применение стратегий, изложенных в обновленном и переработанном издании, позволит перформанс-инженерам улучшить взаимодействие с конечными пользователями и снизить затраты, особенно для облачных сред.
Брендан Грегг — эксперт в области производительности систем и автор нескольких бестселлеров — лаконично, но емко излагает наиболее важные сведения о работе операционных систем, оборудования и приложений, которые позволят специалистам быстро добиться результатов, даже если раньше они никогда не занимались анализом производительности. Далее автор дает детальные объяснения по применению современных инструментов и методов, включая расширенный BPF, и показывает, как добиться максимальной эффективности ваших систем в облачных, веб- и крупных корпоративных средах.
Как перформанс-инженеру в компании с гигантской вычислительной инфраструктурой (Netflix), мне часто приходится работать с SRE-инженерами и разработчиками, которым просто физически не хватает времени для решения сразу нескольких проблем с производительностью. Мне тоже доводилось работать дежурным инженером в Netflix CORE SRE, и я знаком с этой нехваткой времени на собственном опыте. Для многих людей обеспечение производительности не является их основной работой, и им достаточно знать ровно столько, чтобы решать текущие проблемы. Я понимаю, что у вас может быть мало времени, и я постарался сделать эту книгу как можно короче и проще по структуре.
Другая целевая аудитория — студенты. Книга поможет при изучении курса производительности систем. Я вел подобные курсы раньше и знаю, что лучше всего помогает студентам решать проблемы с успеваемостью. Этими знаниями я руководствовался при работе над книгой.
Кем бы вы ни были, упражнения в главах позволят проверить себя и надежнее усвоить материал. Среди них вы найдете особенно сложные упражнения, которые необязательно решать. (Они могут представлять проблемы, не имеющие решения, главная их цель — заставить задуматься.)
Наконец, с точки зрения размера компании эта книга содержит достаточно подробностей, чтобы удовлетворить потребности компаний от мала до велика. Для многих небольших компаний эта книга послужит справочником, в котором лишь некоторые части используются ежедневно.
МЕТОДОЛОГИЯ
В этом разделе описаны различные методологии и упражнения для анализа и настройки памяти. Краткий перечень методологий приводится в табл. 7.3.
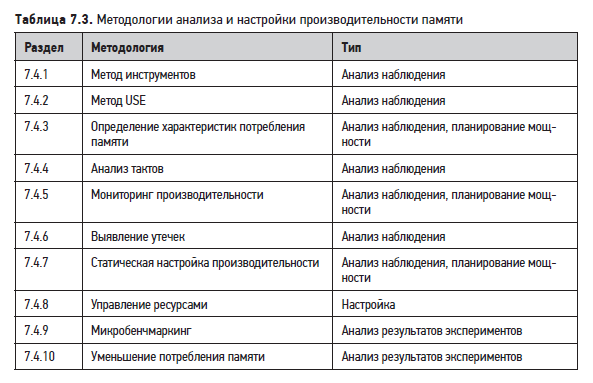
Список дополнительных методологий и краткое введение ищите в главе 2 «Методологии». Эти методологии можно применять по отдельности или в сочетании друг с другом. При устранении проблем с памятью предлагаю начать с использования следующих стратегий в таком порядке: мониторинг производительности, метод USE и определение характеристик потребления памяти.
В разделе 7.5 «Инструменты наблюдения» показано применение этих методологий с использованием инструментов ОС.
7.4.1. Метод инструментов
Метод инструментов — это процесс перебора доступных инструментов с целью изучения ключевых метрик, которые они возвращают. Это очень простая методология, но при ее использовании могут оставаться незамеченными некоторые проблемы, которые плохо обнаруживаются или вообще не обнаруживаются инструментами. Также на ее применение может уйти много времени.
При анализе производительности памяти метод инструментов можно использовать для проверки следующих метрик (в Linux):
- Сканирование страниц: обращайте внимание на продолжительные периоды сканирования страниц (более 10 с), которые могут служить признаком нехватки памяти. Это можно сделать с помощью команды sar -B и проверки столбцов pgscan в ее выводе.
- Информация о задержках доступа (pressure stall information, PSI): с помощью команды cat /proc/pressure/memory (Linux 4.20+) можно проверить статистики, характеризующие насыщение памяти, и их изменение с течением времени.
- Подкачка (swapping): если подкачка включена, то подкачка страниц памяти (так в Linux называется подкачка) может служить еще одним признаком нехватки памяти. Для анализа можно использовать столбцы si и so в выводе vmstat (8).
- vmstat: запустите vmstat 1 и проверьте столбец free, показывающий объем доступной памяти.
- События OOM Killer: эти события можно увидеть в системном журнале /var/log/messages или в dmesg (1). Ищите сообщения «Out of memory» (недостаточно памяти).
- top: посмотрите, какие процессы и пользователи являются основными потребителями физической (резидентной) и виртуальной памяти (описание столбцов в выводе команды top смотрите на странице справочного руководства man, они могут различаться в зависимости от версии). top (1) также сообщает об объеме свободной памяти.
- perf (1)/BCC/bpftrace: проанализируйте операции распределения памяти по трассировкам стека, чтобы выявить конкретные причины повышенного потребления памяти. Имейте в виду, что трассировка может быть сопряжена со значительным оверхедом. Более дешевое, хотя и грубое решение — профилирование процессора (выборка трассировок стека по времени) и поиск в коде путей, ведущих к распределению памяти.
Дополнительные сведения о каждом инструменте вы найдете в разделе 7.5 «Инструменты наблюдения».
7.4.2. Метод USE
Метод USE можно использовать на ранних этапах исследования производительности для выявления узких мест и ошибок во всех компонентах, прежде чем переходить к более глубоким и трудоемким стратегиям.
Для системы в целом проверьте:
- Потребление: сколько памяти используется и сколько доступно. Проверять нужно и физическую, и виртуальную память.
- Насыщенность: частоту сканирования страниц, подкачки страниц и событий OOM Killer как основных признаков мер, предпринимаемых системой для уменьшения давления на память.
- Ошибки: программные или аппаратные ошибки.
Сначала можно проверить насыщенность, так как постоянное насыщение является ярким признаком проблем с памятью. Соответствующие метрики обычно легко получить с помощью инструментов ОС. Например, статистики, характеризующие частоту подкачки страниц, можно получить с помощью vmstat (8) и sar (1), а сообщения OOM Killer — с помощью dmesg (1). Для систем с настроенным отдельным устройством подкачки любые операции с этим устройством — это один из признаков нехватки памяти. Статистика насыщения памяти в Linux также предоставляется как часть информации о задержках доступа (pressure stall information, PSI).
Уровень потребления физической памяти сообщают разные инструменты, но они могут учитывать или не учитывать страницы кэша файловой системы, на которые нет ссылок, или неактивные страницы. Система может сообщить, что в ее распоряжении всего 10 Мбайт доступной памяти, тогда как на самом деле 10 Гбайт занято кэшем файловой системы, и эта память при необходимости может быть немедленно освобождена приложениями. Загляните в документацию с описанием инструмента, чтобы узнать, какие сведения он предоставляет.
Желательно проверить и потребление виртуальной памяти, если система поддерживает стратегию overcommit. В системах, не поддерживающих эту стратегию, попытки распределения памяти потерпят неудачу сразу же, как только виртуальная память будет исчерпана, с сообщениями об ошибке.
Ошибки распределения памяти могут быть вызваны ПО, например попыткой выделить слишком большой объем памяти, или действиями механизма OOM Killer в Linux, или аппаратным обеспечением, например ошибками ECC. Традиционно обязанность сообщать об ошибках распределения памяти возлагается на приложения, но не все приложения делают это (а с учетом поддержки стратегии выделения памяти без ограничений в Linux многие разработчики не считают это нужным). Аппаратные ошибки тоже сложно диагностировать. Некоторые инструменты могут сообщать об ошибках, исправляемых с помощью ECC (например, dmidecode (8), edac-utils, ipmitool sel в Linux), когда используется память ECC. Эти исправимые ошибки могут использоваться как метрики ошибок в методе USE и служить признаком того, что вскоре могут появиться неисправимые ошибки. При фактических (неисправимых) ошибках памяти можно столкнуться с необъяснимыми и невоспроизводимыми сбоями (включая ошибки сегментации и сигналы ошибок шины) в любых приложениях.
В средах, поддерживающих ограничения или квоты памяти (средствами управления ресурсами), как в некоторых облачных средах, для оценки потребления и насыщения памяти могут потребоваться другие подходы к измерениям. Для экземпляра ОС может быть установлен программный предел объема доступной памяти и пространства подкачки, даже если на хосте достаточно физической памяти. См. главу 11 «Облачные вычисления».
7.4.3. Определение характеристик потребления памяти
Определение характеристик потребления памяти — важный шаг при планировании мощностей, сравнительном анализе и моделировании рабочих нагрузок. Это также поможет значительно увеличить производительность за счет выявления и исправления неправильных настроек. Например, в базе данных может быть настроен либо слишком маленький кэш, который из-за этого имеет низкую частоту попаданий, либо слишком большой, что вызывает подкачку.
Определение характеристик потребления памяти включает выяснение того, где и сколько памяти используется:
- Потребление физической и виртуальной памяти в масштабе всей системы.
- Степень насыщения: наличие событий подкачки и сообщений OOM Killer.
- Потребление памяти для кэшей ядра и файловой системы.
- Потребление физической и виртуальной памяти каждым процессом.
- Использование средств управления ресурсами памяти, если есть.
Пример ниже показывает, как эти атрибуты можно выразить в одном описании:
Система имеет 256 Гбайт основной памяти, из которых 1% используется процессами и 30% занято кэшем файловой системы. Самый главный потребитель памяти — процесс базы данных, занимающий 2 Гбайт основной памяти (Resident Set Size, RSS), что является настроенным для него пределом, унаследованным из предыдущей системы при переносе.
Эти характеристики могут меняться со временем, потому что для кэширования рабочих данных может потребоваться больше памяти. Кроме обычного увеличения размера кэша, память, занимаемая ядром или приложением, тоже может увеличиваться с течением времени из-за утечек памяти, обусловленных ошибками в ПО.
Расширенный анализ потребления/чек-лист
В списке ниже перечислены дополнительные характеристики для рассмотрения. Он также может служить чек-листом для более тщательного изучения проблем с памятью:
- Каков размер рабочего набора (working set size, WSS) для приложений?
- На какие нужды ядро использует память? Сколько памяти выделяется ядром на каждый блок (slab)?
- Какая доля кэша файловой системы активна/неактивна?
- Для каких целей используется память процесса (инструкции, кэши, буферы, объекты и т. д.)?
- Почему процессы выделяют дополнительную память (пути в коде)?
- Почему ядро выделяет дополнительную память (пути в коде)?
- Наблюдаются ли странности с отображением библиотек в память процессов (например, изменения с течением времени)?
- Какие процессы активно используют подкачку?
- Какие процессы ранее использовали подкачку?
- Могут ли процессы или ядро иметь утечки памяти?
- Насколько хорошо память распределена между узлами в системе NUMA?
- Как часто следуют холостые такты в ожидании доступа к памяти и сколько инструкций выполняется за такт (IPC)?
- Насколько сбалансированы шины памяти?
- Каково соотношение операций чтения/записи с локальной и удаленной памятью?
Ответы на некоторые из этих вопросов можно найти в следующих разделах. Более подробное описание этой методологии и метрик, которые нужно измерить (кто, что, почему и как), вы найдете в главе 2 «Методологии».
7.4.4. Анализ тактов
Нагрузку на шину памяти легко определить с помощью счетчиков мониторинга производительности процессора (performance monitoring counters, PMC), которые можно запрограммировать для подсчета холостых тактов в ожидании доступа к памяти, использования шины памяти и т. д. Для начала можно определить количество инструкций на такт (IPC), отражающее, насколько нагрузка на процессор зависит от памяти. См. главу 6 «Процессоры».
7.4.5. Мониторинг производительности
Мониторинг производительности может помочь обнаружить проблемы и модели поведения, проявляющиеся со временем. Ключевые метрики для памяти:
- Потребление: процент использованной памяти, который можно определить по объему доступной памяти.
- Насыщенность: наличие событий подкачки и сообщений OOM Killer в журнале.
В средах, реализующих ограничения или квоты памяти (средствами управления ресурсами), может также потребоваться собрать статистики, характеризующие наложенные ограничения.
Также можно выполнить мониторинг ошибок (если есть такая возможность), как описано в разделе 7.4.2 «Метод USE».
Мониторинг потребления памяти с течением времени, особенно по процессам, может помочь выявить наличие и величину утечек памяти.
7.4.6. Выявление утечек
Эта проблема возникает, когда объем памяти, потребляемой приложением или модулем ядра из списка свободных страниц, из кэша файловой системы и в итоге из других процессов, постоянно увеличивается. Это можно заметить по появлению событий подкачки страниц или по сообщениям OOM Killer о завершении приложения в ответ на чрезмерное потребление памяти.
Проблемы этого типа обычно обусловлены одной из причин:
- Утечка памяти: из-за программной ошибки, вследствие которой выделенная и больше не используемая память не освобождается. Такие проблемы исправляются изменением программного кода или применением исправлений или обновлений (которые изменяют код).
- Рост потребляемой памяти: программа потребляет ровно столько памяти, сколько ей необходимо, но с гораздо большей скоростью, чем желательно для системы. Такие проблемы исправляются настройкой конфигурации программного обеспечения или изменением способа потребления памяти приложением в программном коде.
Проблему роста потребляемой памяти часто ошибочно принимают за утечку памяти. Чтобы избежать этого, в первую очередь нужно ответить на вопрос: должно ли так быть? Проверьте потребление памяти, конфигурацию приложения и поведение распределителей памяти в нем. Приложение может быть настроено на быстрое заполнение кэша, и наблюдаемый рост потребления может быть обусловлен разогревом кэша.
Анализ утечек памяти зависит от ПО и типа языка, на котором оно написано. Некоторые распределители поддерживают режимы отладки и предоставляют подробную информацию об операциях распределения памяти, которую затем можно проанализировать, чтобы выявить пути в коде, порождающие утечки. В некоторых средах времени выполнения имеются методы для анализа дампа кучи и другие инструменты, помогающие исследовать утечки памяти.
В наборе инструментов трассировки для BCC в Linux есть инструмент memleak (8) для анализа роста потребления и утечек памяти: он наблюдает за выделяемыми блоками памяти и отмечает те из них, которые не были освобождены в течение определенного интервала, а также пути в коде, которые выделили эти блоки. Он не различает утечки и нормальный рост потребления, поэтому проанализируйте пути в коде, чтобы определить конкретный тип проблемы. (Обратите внимание, что у этого инструмента высокий оверхед при высокой частоте следования операций распределения памяти.) BCC рассматривается в главе 15 «BPF», в разделе 15.1 «BCC».
7.4.7. Статическая настройка производительности
Статическая настройка производительности фокусируется на проблемах сконфигурированной среды. Анализируя производительность памяти, рассмотрите следующие аспекты статической конфигурации:
- Сколько всего основной памяти?
- Какой объем памяти выделен для использования приложениями (в их собственных конфигурациях)?
- Какие распределители памяти используются приложениями?
- Какова скорость работы основной памяти? Это самый быстрый доступный тип (DDR5)?
- Тестировалась ли когда-нибудь основная память (например, с помощью memtester в Linux)?
- Какова архитектура системы? NUMA, UMA?
- Поддерживает ли ОС архитектуру NUMA? Предоставляет ли она настройки NUMA?
- Подключена ли память к одному и тому же физическому процессору или разделена между несколькими физическими процессорами?
- Сколько шин памяти?
- Сколько кэшей и какого размера имеют процессоры? TLB?
- Какие настройки сделаны в BIOS?
- Настроены ли и используются ли большие страницы?
- Доступна ли и настроена ли стратегия overcommit?
- Какие еще настройки системной памяти используются?
- Есть ли программные ограничения на потребление памяти (средствами управления ресурсами)?
Ответы на эти вопросы могут помочь выявить варианты конфигурации, которые были упущены из виду.
7.4.8. Управление ресурсами
Операционная система может предоставлять низкоуровневые средства управления, регулирующие выделение памяти процессам или группам процессов и позволяющие устанавливать фиксированные ограничения на потребление основной и виртуальной памяти. Как это работает, зависит от реализации и обсуждается в разделе 7.6 «Настройка» и в главе 11 «Облачные вычисления».
7.4.9. Микробенчмаркинг
Микробенчмаркинг можно использовать для определения быстродействия основной памяти и таких характеристик, как объем кэша процессора и размеров строк кэша. Они пригодятся при анализе различий между системами, потому что скорость доступа к памяти может влиять на производительность больше, чем тактовая частота процессора, в зависимости от особенностей приложения и рабочей нагрузки.
В главе 6 «Процессоры» в подразделе «Задержка» (раздел 6.4.1 «Аппаратное обеспечение») показан результат микробенчмаркинга задержки доступа к памяти для определения характеристик кэшей процессора.
7.4.10. Уменьшение потребления памяти
Это метод оценки размера рабочего набора (working set size, WSS), основанный на проведении отрицательного эксперимента и требующий настройки устройств подкачки для этого эксперимента. В ходе эксперимента объем основной памяти, доступной приложению, постепенно уменьшается и одновременно измеряются его производительность и объем подкачки: точка, в которой производительность начинает резко падать, а подкачка увеличиваться, показывает, когда WSS перестает умещаться в доступной памяти.
Отрицательный эксперимент — это пример, достойный упоминания, но не рекомендую проводить его в промышленном окружении, так как при этом намеренно снижается производительность. Информацию о других методах оценки WSS ищите в описании экспериментального инструмента wss (8) в разделе 7.5.12 «wss», а также в статье, посвященной оценке WSS, на моем сайте [Gregg 18c].
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Системы
