Клиентский мониторинг производительности
Привет, Хабр! Меня зовут Влад, я лид направления Web Performance в Тинькофф.
В этом цикле статей я расскажу о подходах, инструментах и показателях, с помощью которых мы наблюдаем за производительностью наших проектов. Но для начала пара слов о том, почему производительность — это важно.
Производительность как один из атрибутов качества программного обеспечения, в значительной степени может влиять на успех конечного продукта. Существует множество историй о том, как даже самые небольшие оптимизации положительно сказывались на опыте взаимодействия и бизнес-показателях компании.
Ведущие игроки IT-индустрии продолжают обращать внимание на важность производительности, проводят масштабные исследования и эксперименты, разрабатывают новые концепции, инструменты и API. А в ближайшем будущем Google и вовсе будет учитывать основные показатели производительности в поисковой выдаче.
Пользователям нравятся отзывчивые интерфейсы, а бизнесу — прибыльные проекты. И если производительность играет в этом не последнюю роль, то почему бы не заняться ее оптимизацией?
Содержание
Мониторинг
Прежде чем приступать к каким-либо оптимизациям, необходимо определить конкретные места проекта, которые в этом нуждаются. А чтобы обнаружить такие места, нужны измерения.
Когда у нас возникла потребность в подобных измерениях, найти соответствующий инструмент, удовлетворяющий всем нашим требованиям, не удалось. Поэтому было принято решение о создании собственного мониторинга производительности. Так появился проект Perfectum Client.
Perfectum Client — это легковесная библиотека для измерения клиентских показателей производительности. Рассмотрим основные принципы, которыми мы руководствовались при ее создании.
Современные методы измерения производительности
Библиотека основана на работе с PerformanceObserver API.
Ниже приведен пример использования, в котором происходит наблюдение за событием первой отрисовки контента (First Contentful Paint).
const performanceObserver = new PerformanceObserver((performanceEntryList) => {
const performanceEntries = performanceEntryList.getEntries();
for (const performanceEntry of performanceEntries) {
if (performanceEntry.name === 'first-contentful-paint') {
const firstContentfulPaint = performanceEntry.startTime;
console.log('FCP is', firstContentfulPaint);
}
}
});
performanceObserver.observe({ type: 'paint', buffered: true }); // Свойство buffered позволяет получить информацию о событиях возникших до этапа инициализации observer'аСбор метрик отражающих восприятие производительности
Библиотека сосредоточена на сборе только тех метрик, которые отражают реальное восприятие производительности проекта.
Мы не собираем статичные метрики, которые можно посмотреть в инструментах разработчика. Мы не собираем метрики, которые плохо или не всегда коррелируют с реальной производительностью. Мы не собираем ничего, что не принесет пользу в дальнейшей диагностике и оптимизации проекта.
Отсутствие влияния на производительность приложения
Библиотека нацелена на минимизацию операций, оказывающих негативное влияние на производительность приложения.
Она не требует ранней инициализации или размещения в head документа. Позволяет загружать свой код на любом этапе работы приложения. Использует не блокирующие основной поток и управляемые браузером методы Beacon API. Не включает тяжелых операций форматирования, агрегирования и тд.
Метрики
Существует огромное количество показателей производительности:
- FCP — First Contentful Paint;
- FMP — First Meaningful Paint;
- LCP — Largest Contentful Paint;
- CLS — Cumulative Layout Shift;
- FID — First Input Delay;
- FCI — First CPU Idle;
- TTI — Time To Interactive;
- TBT — Total Blocking Time;
- VC — Visually Complete;
- SP — Speed Index и тд.
И хоть это далеко не полный список, на первый взгляд даже он может показаться бессвязным набором аббревиатур и словосочетаний.
Современные метрики производительности имеют определенный набор признаков, благодаря которым их можно разделить на категории. Например — среда использования. Одни метрики предназначены для использования в промышленной среде, а другие — на этапе мониторинга производительности в CI/CD. Причин такому разделению несколько.
Первая связана с отсутствием возможности измерений как таковых. Например, измерение метрики первой задержки ввода (First Input Delay) за пределами промышленной среды не имеет практического смысла.
Вторая причина заключается в том, что алгоритм работы некоторых метрик — трудоемкий с вычислительной точки зрения процесс. Поэтому использование определенных показателей в том или ином окружении может быть нецелесообразно, а порой и вовсе недопустимо.
Единственной средой, в которой мы работаем с данными производительности реальных пользователей, является промышленная среда. Поэтому такое окружение я назову клиентским, а все остальные — синтетическими. Разделив показатели по признаку среды использования, мы можем увидеть следующую картину: 
Стоит отметить, что это не строгое разделение, и некоторые метрики могут использоваться сразу в обоих окружениях.
Нас будет интересовать первая категория показателей. Вторая, подробно рассматривается в статье о синтетическом мониторинге производительности.
Cumulative Layout Shift
Cumulative Layout Shift (CLS) позволяет обнаружить непредвиденные сдвиги макета.
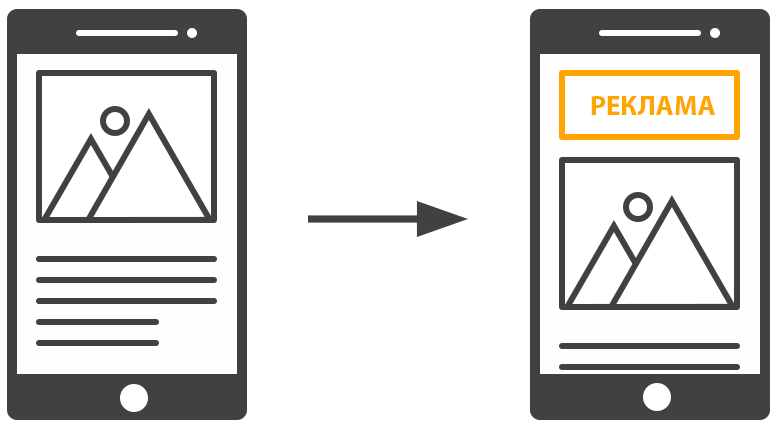
Принцип работы
В случае обнаружения сдвига алгоритм работы метрики пытается определить область вьюпорта, в которой произошло смещение.
Используя отличия между соседними фреймами страницы, происходит поиск всех сместившихся DOM-элементов.

Далее определяется их предыдущая и текущая области расположения,
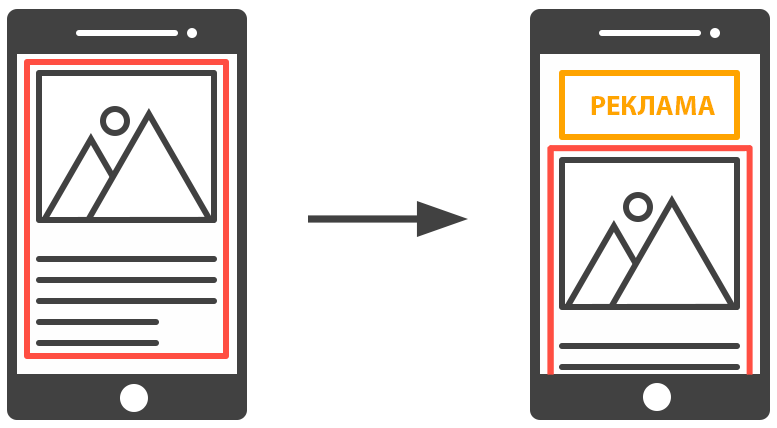
объединение которых образует область смещения макета:

После того как область смещения найдена, определяется степень ее воздействия относительно размеров вьюпорта.
Для этого производится расчет соотношения площади области смещения и площади области просмотра.

Площадь области смещения / Площадь области просмотра = (192 × 308) /(220 × 320) = 0.84
Первоначально алгоритм работы метрики не включал в себя определение других параметров сдвига. Но возникла проблема, заключающаяся в отсутствии учета расстояния.
Когда элемент смещался всего на пару пикселей, результат такого смещения был не сильно заметен пользователю. При этом, если размеры элемента изначально были большими, то даже такие незначительные сдвиги заметно влияли на область смещения и, соответственно, на значение метрики.
Поэтому в формулу оценки сдвига макета добавили учет расстояния смещения.
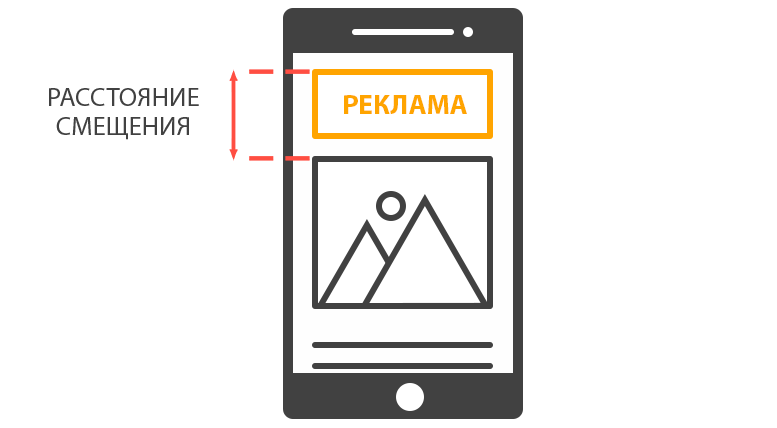
В случае сдвига сразу нескольких элементов по любой из осей макета (горизонтальной или вертикальной) происходит поиск максимального расстояния смещения.
Далее определяется наибольшая размерность вьюпорта (ширина или высота). В нашем случае это высота.
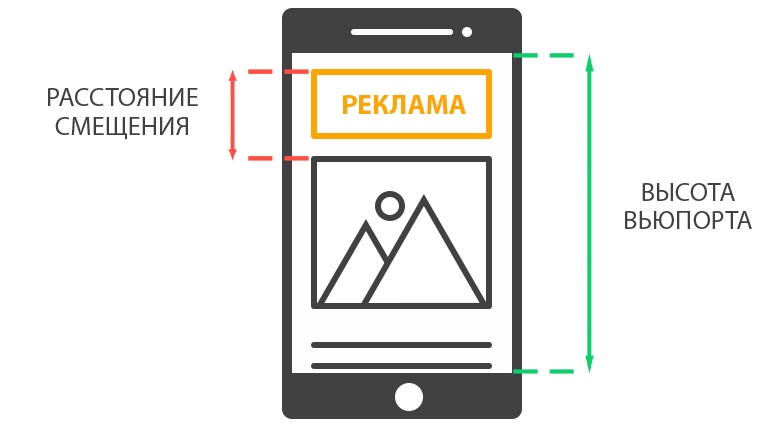
После чего производится расчет соотношения данных показателей.
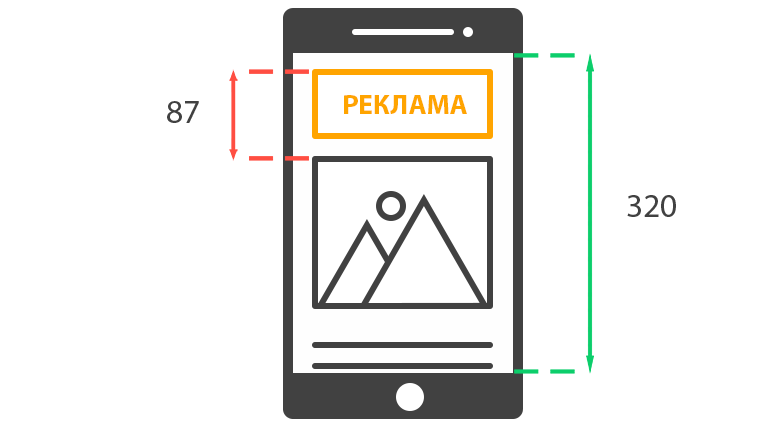
Максимальное расстояние смещения / Наибольшая размерность вьюпорта = 87 / 320 = 0.27
В итоге мы получили относительные значения двух параметров сдвига:
- Область смещения
- Расстояние смещения
Чтобы определить оценку смещения макета, необходимо найти произведение этих параметров.
Оценка смещения = Область смещения × Расстояние смещения = 0.84 × 0.27 = 0.2268
Но, так как мы оперировали результатами отличия соседних фреймов страницы, полученная оценка смещения (Layout Shift) будет показателем сдвига для одного-единственного фрейма. Для определения совокупной оценки смещения (Cumulative Layout Shift), необходимо просуммировать результаты каждого фрейма от начала загрузки страницы до ее закрытия.
Также не будет лишним рассказать и о трудностях, с которыми столкнулась команда разработки метрики.
Первоочередной проблемой был сдвиг макета, являющийся частью логики работы интерфейса. Ведь когда в ответ на взаимодействие пользователя определенные элементы страницы должны смещаться, они очевидным образом приведут к сдвигу макета, что в конечном счете отрицательно скажется на результатах метрики.
Одним из самых простых вариантов решения, являлось бы игнорирование сдвигов макета происходящих в обработчиках событий. Но события, повлекшие сдвиги макета, могут возникать не только в обработчиках, они также могут происходить после выполнения асинхронного запроса или внутри пользовательских планировщиков. А это значит, что для определения причины сдвига потребовался бы сложный анализ последовательности асинхронных шагов, что само по себе не является тривиальной задачей.
Окончательным решением стало предоставление временного окна, на протяжении которого сдвиги макета не учитываются. Временное окно возникает сразу после события пользовательского ввода. Продолжительность окна составляет 500 мс. Следовательно, любые смещения макета, случившиеся на протяжении 500 мс после условного клика мыши, не будут учитываться в общей оценке показателя.
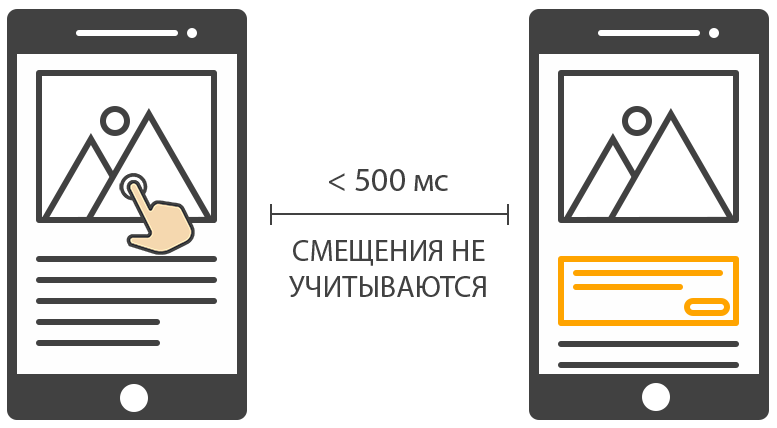
Другой проблемой стала анимация. Анимирование css-свойств, которые вызывают операцию перерасчета макета (Layout), будет влиять на конечный результат метрики.
В тоже время анимация с использованием свойств, создающих отдельный контекст наложения, подобных перерасчетов не вызывает. К таким свойствам относятся transform, opacity и все, что не связано с позиционированием и геометрией элементов страницы.
Частичным решением проблемы стало игнорирование сдвигов макета, которые были вызваны анимацией свойств, не вызывающих операций перерасчета макета. Поэтому для поддержания значения CLS на должном уровне команда разработки метрики рекомендует создавать анимации с использованием свойства transform.
Использование
Значение метрики можно получить используя уже знакомый PerformanceObserver API:
let cumulativeLayoutShift = 0;
const performanceObserver = new PerformanceObserver((performanceEntryList) => {
const performanceEntries = performanceEntryList.getEntries();
for (const performanceEntry of performanceEntries) {
if (!performanceEntry.hadRecentInput) { // Свойство hadRecentInput позволяет не учитывать события сдвига макета вызванные пользовательским вводом
cumulativeLayoutShift += performanceEntry.value;
console.log('CLS is', cumulativeLayoutShift);
}
}
});
performanceObserver.observe({ type: 'layout-shift', buffered: true });Для отображения смещений макета на экране можно включить соответствующую опцию в меню инструментов разработчика. Пример для chromium-based браузеров:
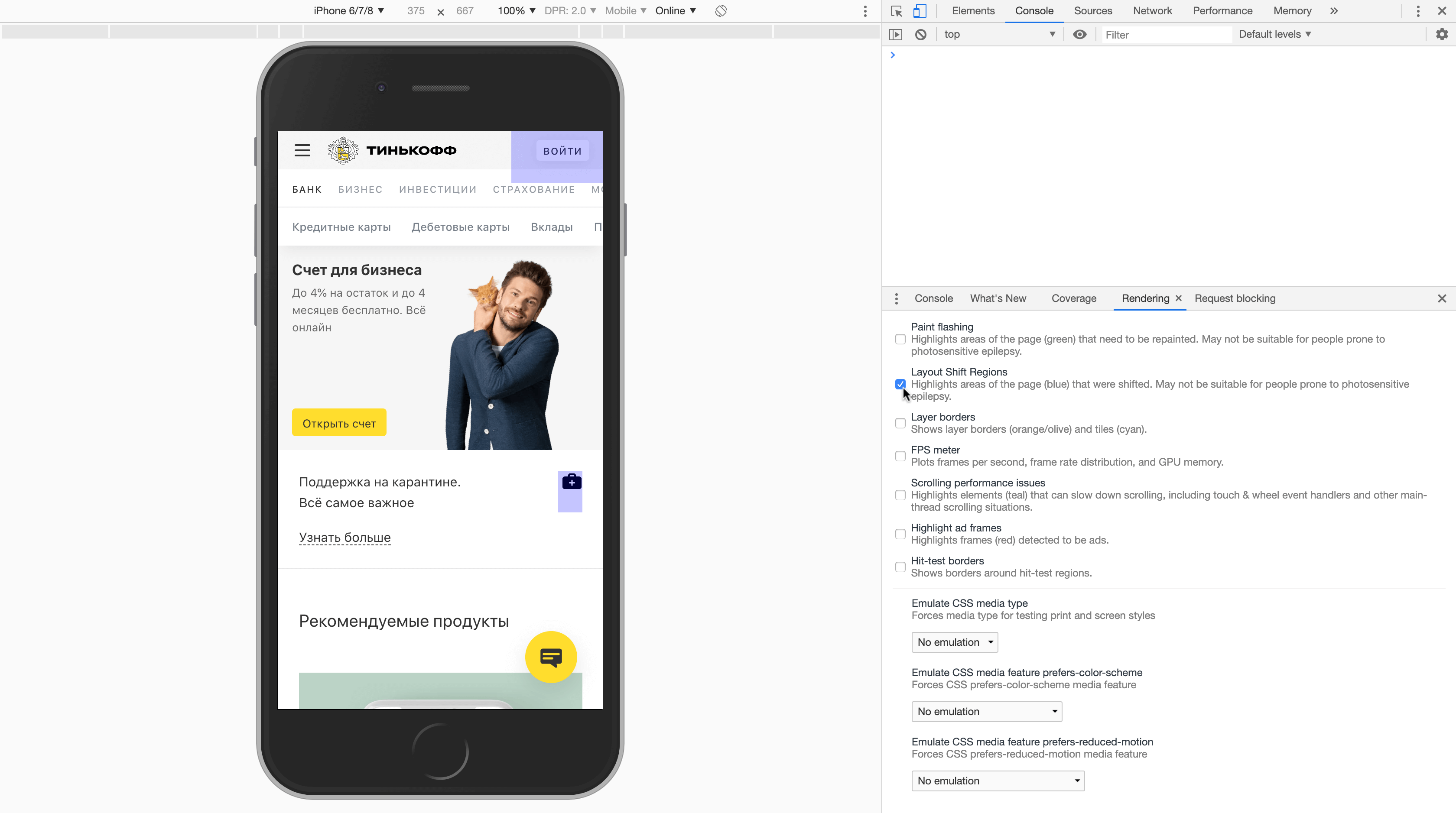
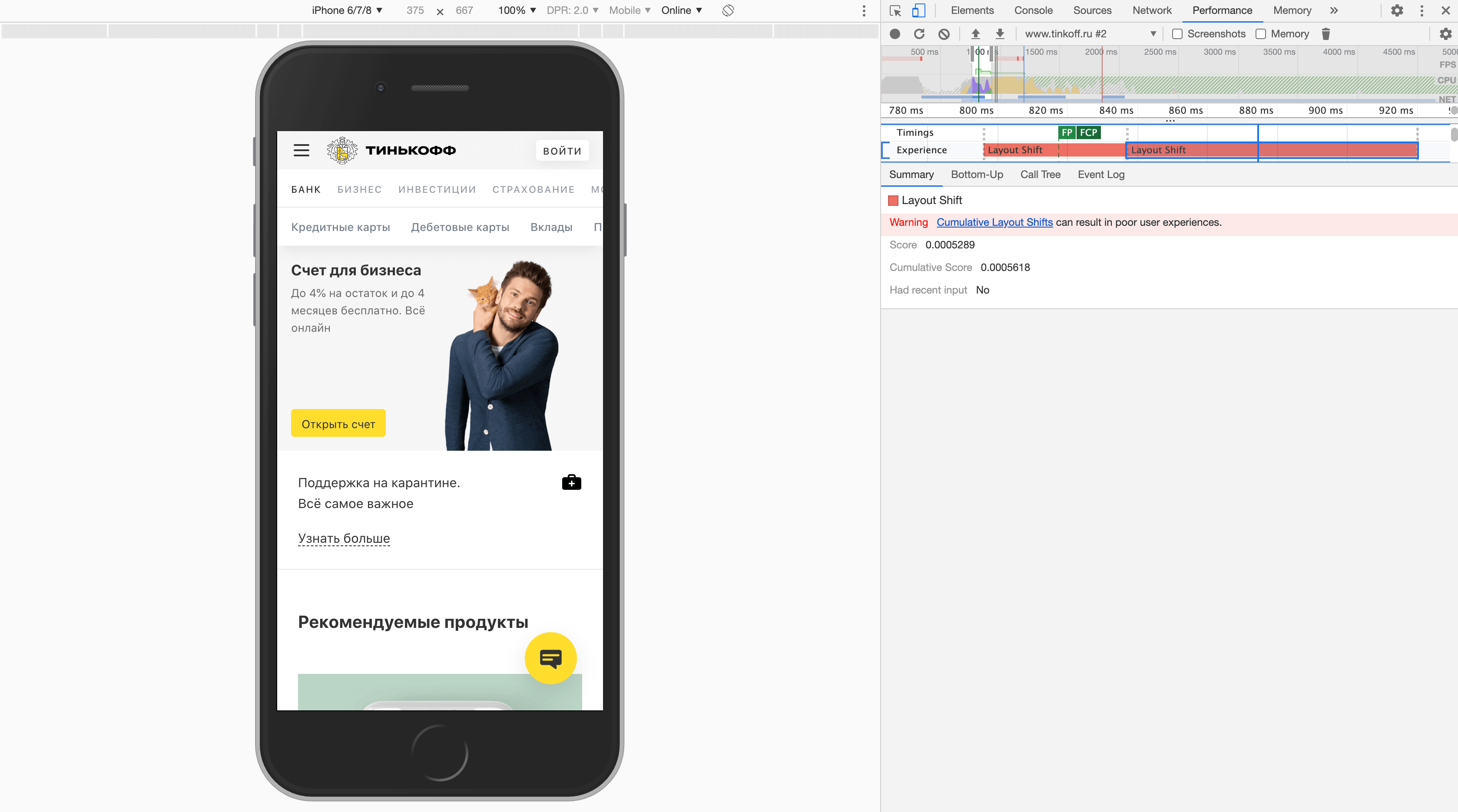
Также подробную информацию о результатах CLS можно получить на панели Performance:
Оценка результатов
В идеальном мире приложения не должны иметь каких-либо сдвигов макета, но на практике достичь такого результата получается не всегда. К тому же в любом проекте могут быть осознанные компромиссы, связанные с логикой работы интерфейса и влияющие на значение CLS.
Поэтому команда разработки метрики рекомендует использовать следующие градации при оценке результатов показателя:
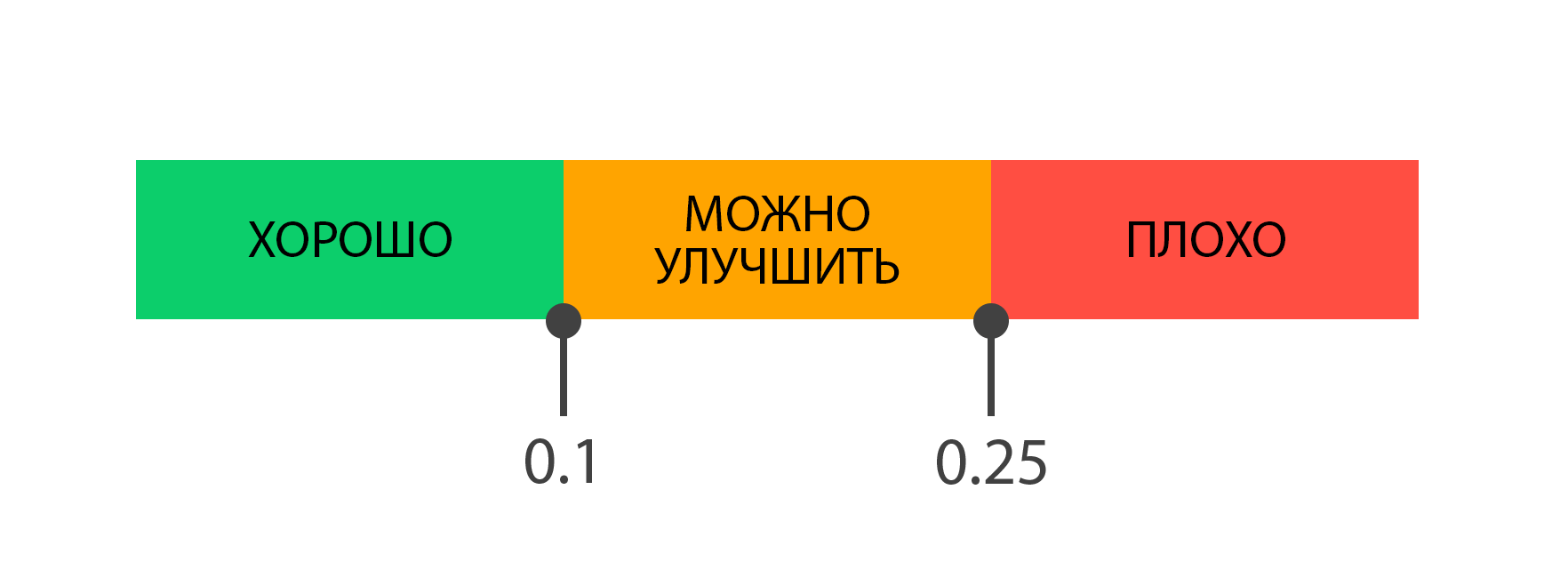
Способы оптимизации
Рассмотрим способы оптимизации наиболее частых случаев смещения макета.
Атрибуты размерности изображений
Загрузка изображений, у которых отсутствует явное указание размерности, может привести к сдвигам макета. Атрибуты ширины и высоты, указываемые в тэге , помогут избежать непредвиденных смещений.
Для получения более подробной информации рекомендую ознакомиться со статьей Setting Height And Width On Images Is Important Again.
Загрузка шрифтов и стратегия визуализации текста
В процессе загрузки шрифтов браузеры сразу или по таймауту отображают текст страницы, используя резервный шрифт.
По окончанию загрузки происходит замена резервного шрифта на основной, в результате текстовое содержимое страницы перерисовывается. В большинстве случаев подобные перерисовки вызывают смещение элементов макета, которые можно минимизировать, явно определив стратегию визуализации текста.
Для управления стратегией визуализации правило @font-face предоставляет возможность определить дескриптор font-display. Дескриптор имеет множество значений, одно из которых позволяет свести к минимуму перерисовки и сдвиги макета.
Речь идёт о значении optional, основная суть которого в том, что если за первые 100 мс основной шрифт не загрузился, то текст отрисовывается с использованием резервного, без какой-либо замены. Однако при следующем посещении страницы текстовое содержимое отобразится с использованием основного шрифта — разумеется, если он был успешно загружен и добавлен в кэш с прошлого раза.
Преимуществом такого подхода является то, что в обоих случаях пользователь не столкнется с перерисовкой текстового содержимого, а разработчик — с отрицательной оценкой сдвига макета.
Подробную информацию по использованию дескриптора совместно с предварительной загрузкой можно найти в статье Prevent layout shifting by preloading optional fonts.
Динамический контент страницы
Под динамическим контентом страницы подразумевается контент, появление которого не является прямым ответным действием на ввод пользователя. Это могут быть баннеры, реклама, блоки с просьбой подписаться на рассылку или установить мобильное приложение.
Для динамического контента небольших размеров рекомендуется использовать свойства абсолютного позиционирования. А для более крупного — заранее резервировать место на странице — например, используя скелетные экраны загрузки.
Анимация
Как упоминалось ранее, анимацию свойств, вызывающих события перерасчета макета, следует заменить на анимацию с использованием свойства transform.
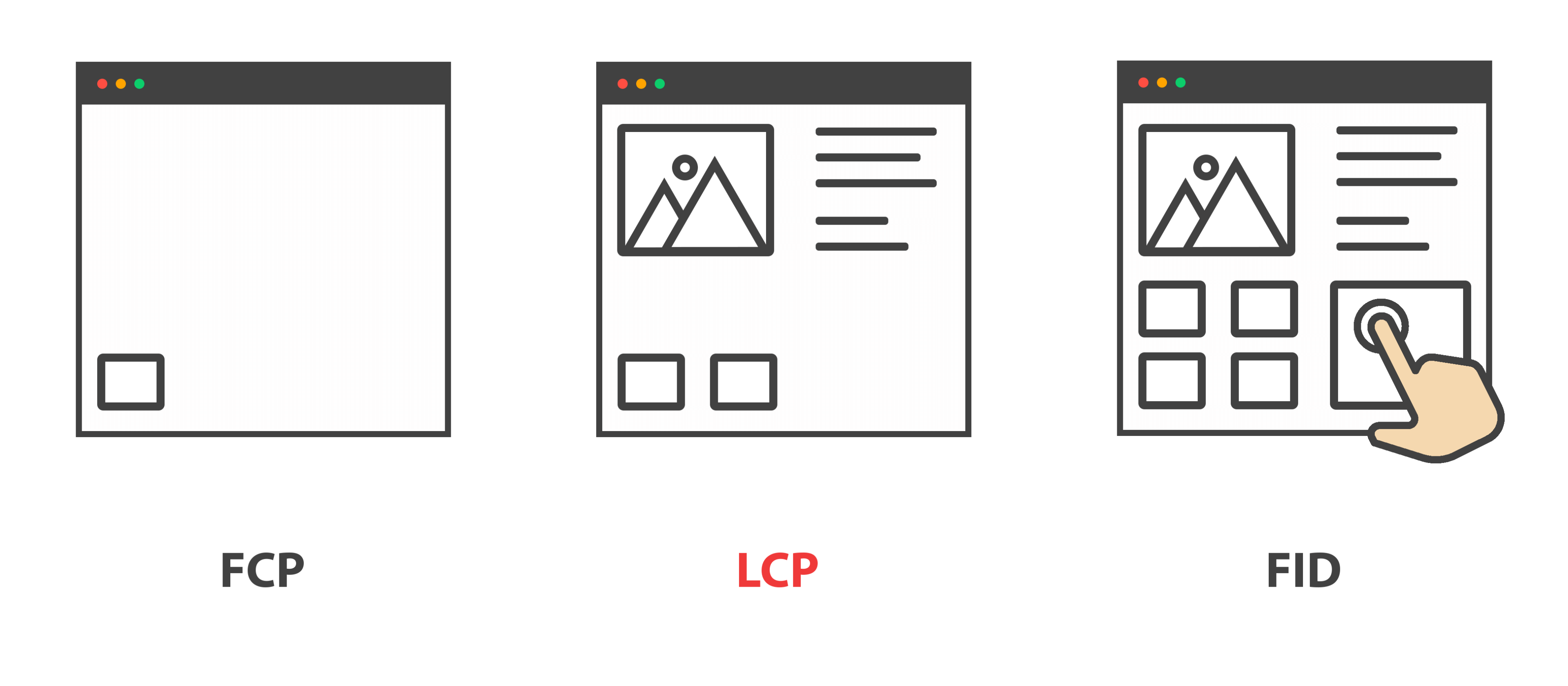
Largest Contentful Paint
Largest Contentful Paint (LCP) измеряет время отображения наибольшего элемента страницы.
Но прежде чем перейти к описанию принципов работы LCP стоит рассказать о предпосылках, которые побудили команду Chrome Speed Metrics на создание новой метрики.
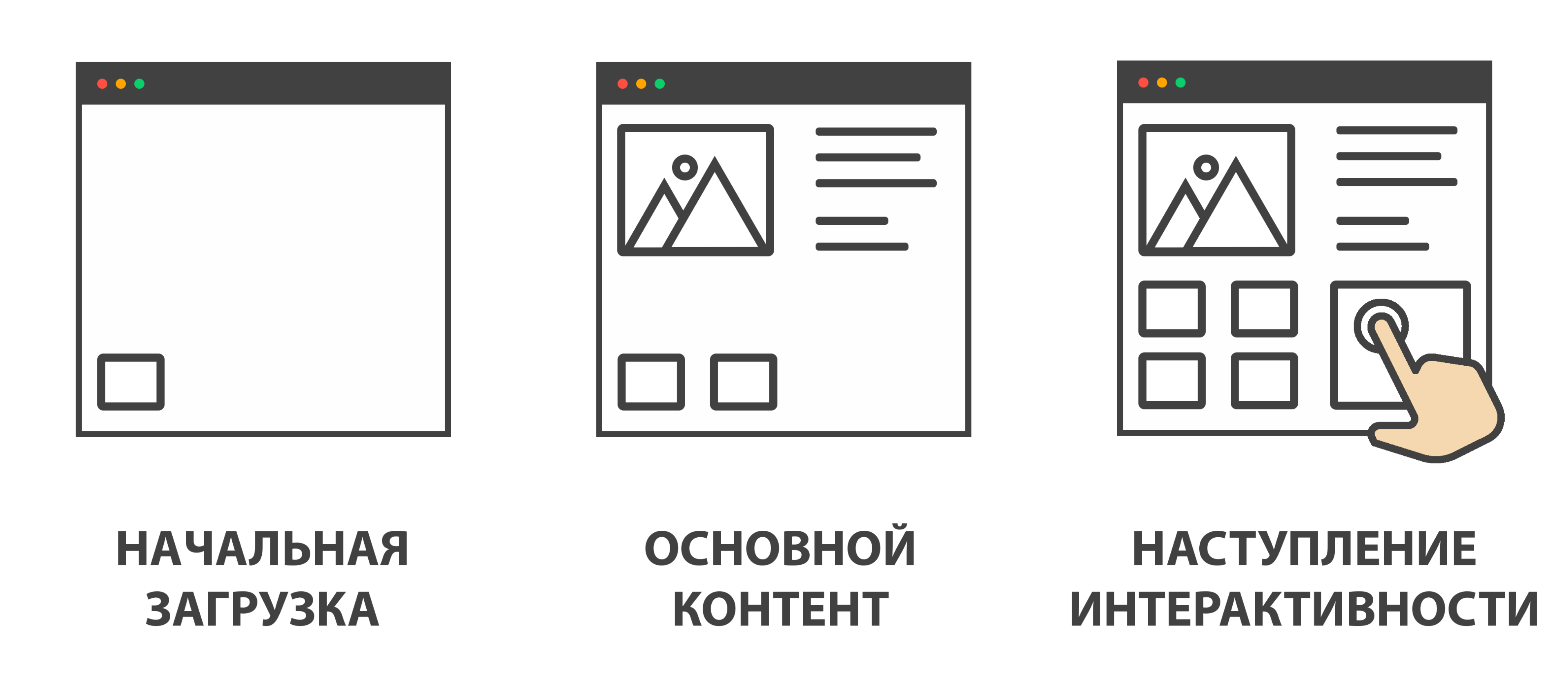
Клиентские показатели производительности, которые мы определили в самом начале, можно дополнительно разделить по фазам загрузки приложения. Я назову эти фазы следующим образом:
- фаза начальной загрузки — когда пользовать зашел в приложение;
- фаза отображения основного контента — когда на экране пользователя начинают появляться значимые элементы страницы;
- фаза наступления интерактивности — когда страница готова стабильно отвечать на действия пользователя.
Если расставить основные клиентские метрики по фазам загрузки, представив картину, использовавшуюся до недавнего времени, мы получим приблизительно следующее:

Здесь может возникнуть резонный вопрос: если все фазы загрузки приложения покрыты соответствующими метриками, зачем понадобилась ещё одна? Ответ заключается в метрике FMP (First Meaningful Paint), у которой есть ряд проблем.
Команда Chrome Speed Metrics, имея огромный опыт в создании показателей производительности, определила набор свойств, которыми должна обладать хорошая метрика.
К сожалению, метрика FMP не обладает некоторыми из них — в частности, свойствами простоты и гибкости. Первым — по причине сложности в стандартизации используемых решений, а вторым — из-за большого количества эвристики. В результате от этого показателя было решено отказаться.
После отказа от FMP фаза отображения основного контента остается без метрики, а значит, без соответствующего наблюдения.

Чтобы найти полноценную замену, команда разработки рассматривала несколько метрик-кандидатов, реализованных в Chrome:
- Largest image paint;
- Largest text paint;
- Largest image OR text paint;
- Last image paint;
- Last text paint;
- Last image OR text paint.
В ходе анализа данных, собранных с более чем тысячи сайтов, было выявлено, что метрика Largest image OR text paint является наиболее подходящим кандидатом. Впоследствии эта метрика получила название Largest Contentful Paint.
Принцип работы
Как упоминалось ранее, метрика LCP измеряет время отображения наибольшего элемента страницы. А поскольку рендеринг приложения происходит постепенно, то и кандидат на звание наибольшего элемента со временем может меняться.
Визуально этот процесс можно представить следующим образом:
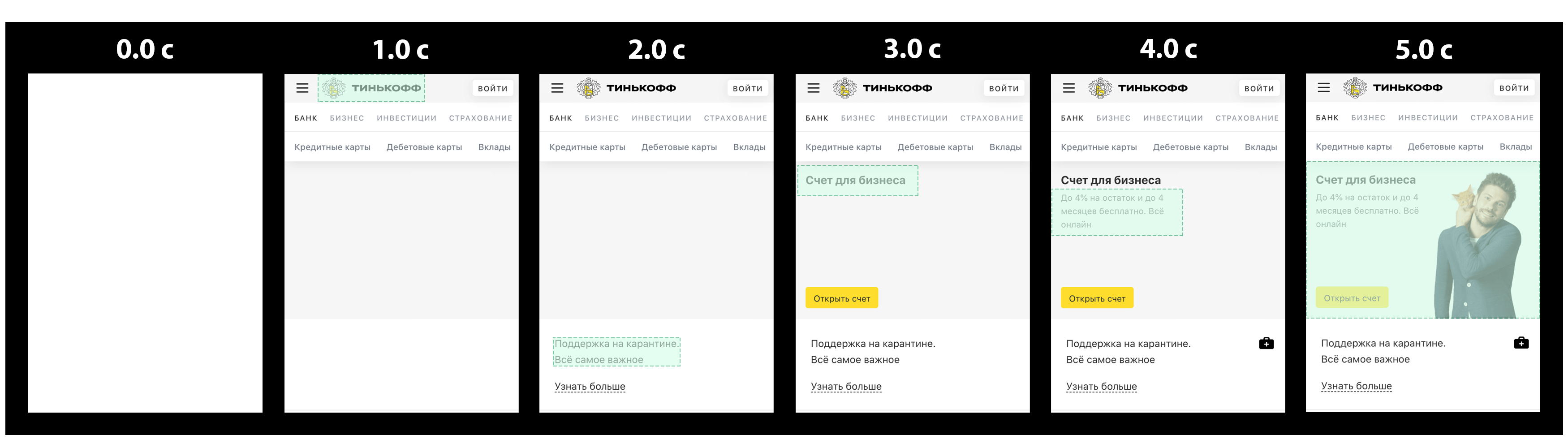
Светло-зеленым цветом выделены элементы, которые по мере загрузки страницы рассматривались как наибольшие.
Осталось разобраться, какие типы элементов учитываются, как определяется размер и время отображения.
На данный момент алгоритм работы метрики LCP отслеживает следующие типы элементов:
- изображения:
элементы,
элементы внутри SVG-документов, - элементы с фоновым изображением;
- видео с poster-изображением;
- текст в блочных элементах.
Размер наибольшего элемента определяется по следующей формуле:
Размер = Ширина × Высота
Внешние и внутренние отступы, а также рамки элемента не учитываются.
Определение времени отображения происходит следующим образом:
- Для изображений фиксируется момент отрисовки, наступающий сразу после события load ресурса. Для изображений, загружаемых из сторонних источников, необходимо наличие заголовка Timing-Allow-Origin. В противном случае временем отрисовки элемента будет считаться момент наступления события load ресурса.
- Для видеоэлементов фиксируется момент отрисовки poster-изображения. Алгоритм определения времени отображения идентичен вышеописанному для изображений.
- Для текстовых элементов фиксируется время первого отображения, независимо от будущей загрузки основного шрифта и последующей перерисовки текстового содержимого страницы.
Также не будет лишним рассказать и о некоторых особенностях работы данной метрики.
Как упоминалось ранее, в процессе загрузки приложения статус наибольшего элемента страницы может переходить от одного элемента к другому. По сути, происходит поиск последнего наибольшего элемента, появившегося в области просмотра.
Но встает вопрос о том, когда алгоритм работы метрики принимает решение остановить наблюдение за появлением новых элементов. Ведь нас интересуют исключительно этап загрузки приложения.
Очевидным вариантом решения стал момент взаимодействия пользователя с страницей — будь то клик или прокрутка. Поэтому после наступления события пользовательского ввода поиск новых кандидатов для метрики LCP останавливается.
Ещё одной особенностью является механизм работы метрики после удаления DOM-элемента. При определении наибольшего элемента страницы, который в последствии удаляется из DOM-дерева, начинается поиск нового кандидата. Наиболее частый пример — это отображение прелоадера, который впоследствии исчезает.
Логика дальнейшего поиска обусловлена тем, что элементы, которые удаляются в процессе загрузки, скорее всего, не являются значимыми с точки зрения пользователя, поэтому и учитывать результаты их отрисовки не имеет особого смысла.
Стоит упомянуть и более сложный сценарий, когда на сайте используется компонент карусели с автоматической сменой элементов по таймауту. Большинство реализаций подобных компонентов предполагает удаление отображаемого элемента карусели после его смены другим. Но если по окончании загрузки страницы пользовательского ввода не случилось, а элементы карусели были помечены как наибольшие и продолжают сменять друг друга, то с каждой последующей сменой значение метрики будет обновляться на все более и более некорректный результат.
Команда разработки метрики знает об этой проблеме и работает над ее устранением.
Использование
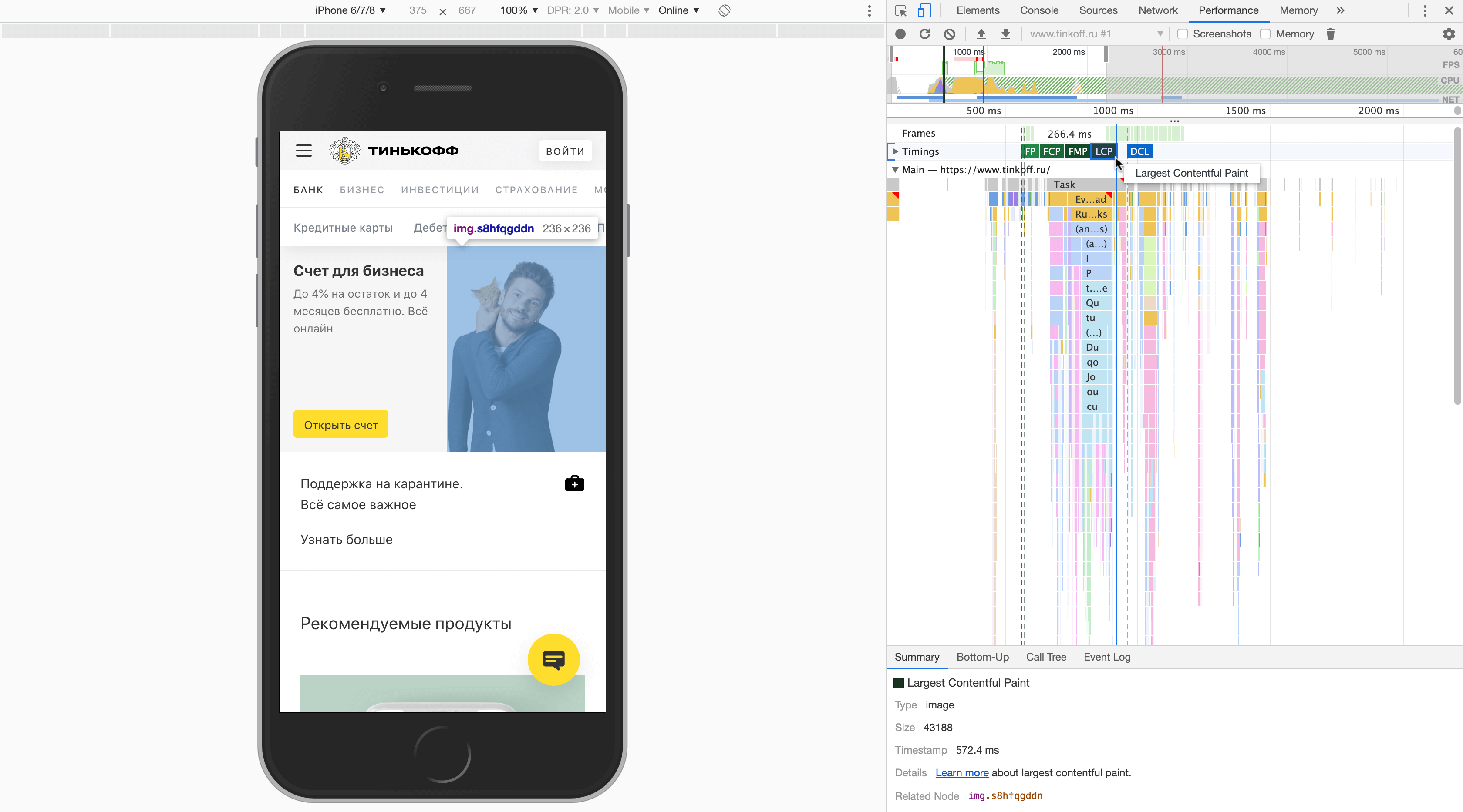
Значение метрики можно получить используя PerformanceObserver API:
const performanceObserver = new PerformanceObserver((performanceEntryList) => {
const performanceEntries = performanceEntryList.getEntries();
const lastPerformanceEntry = performanceEntries[performanceEntries.length - 1];
const largestContentfulPaint = lastPerformanceEntry.startTime;
console.log('LCP is', largestContentfulPaint);
});
performanceObserver.observe({ type: 'largest-contentful-paint', buffered: true });Также подробная информация о результатах LCP доступна на панели Performance:
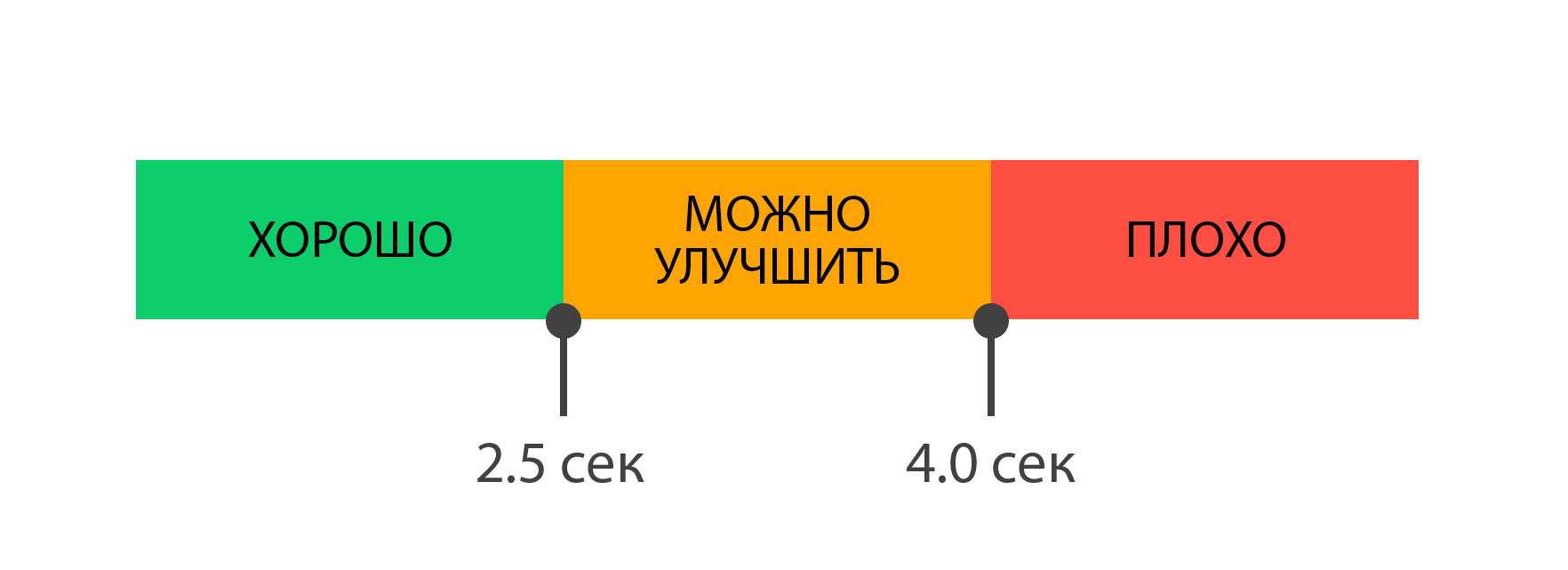
Оценка результатов
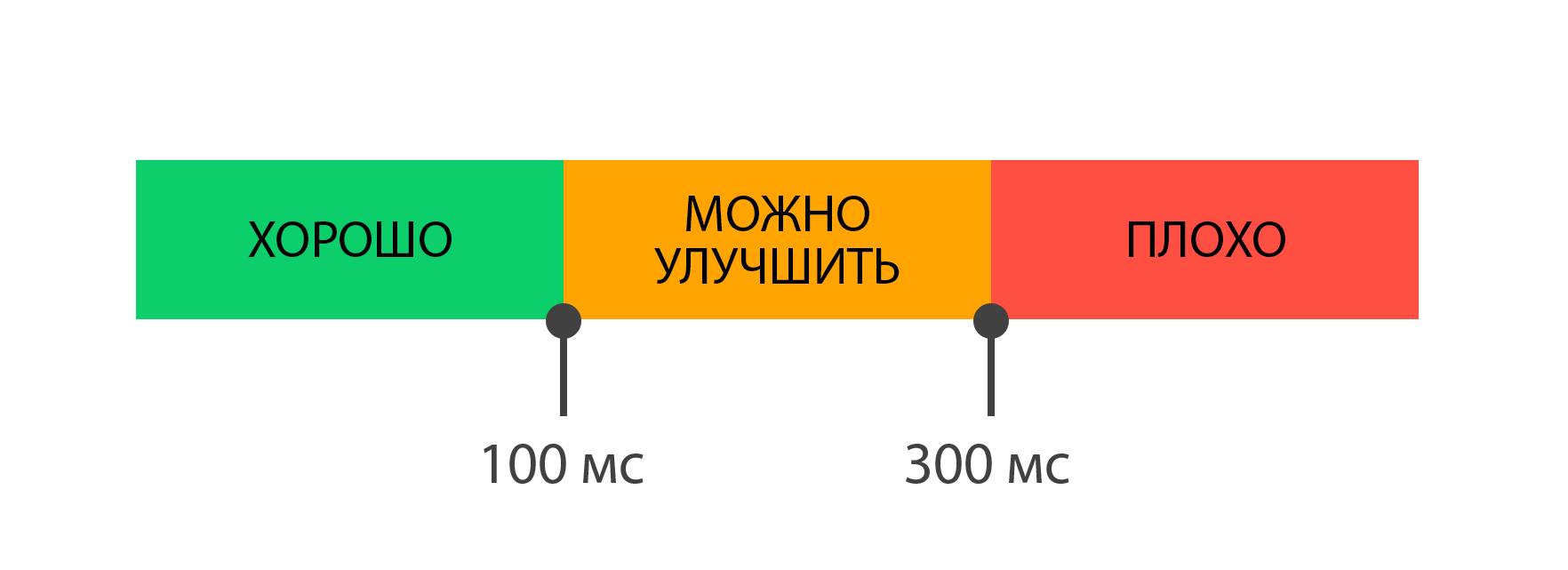
При оценке результатов показателя рекомендуется использовать следующие градации:
Способы оптимизации
Как правило, любые оптимизации, направленные на увеличение скорости загрузки страницы, положительно скажутся на показателе LCP.
Вот краткий список рекомендаций:
First Input Delay
First Input Delay (FID) измеряет продолжительность задержки пользовательского ввода при первом взаимодействии со страницей.
Принцип работы
Для начала посмотрим на временную шкалу, представляющую типичную загрузку страницы:
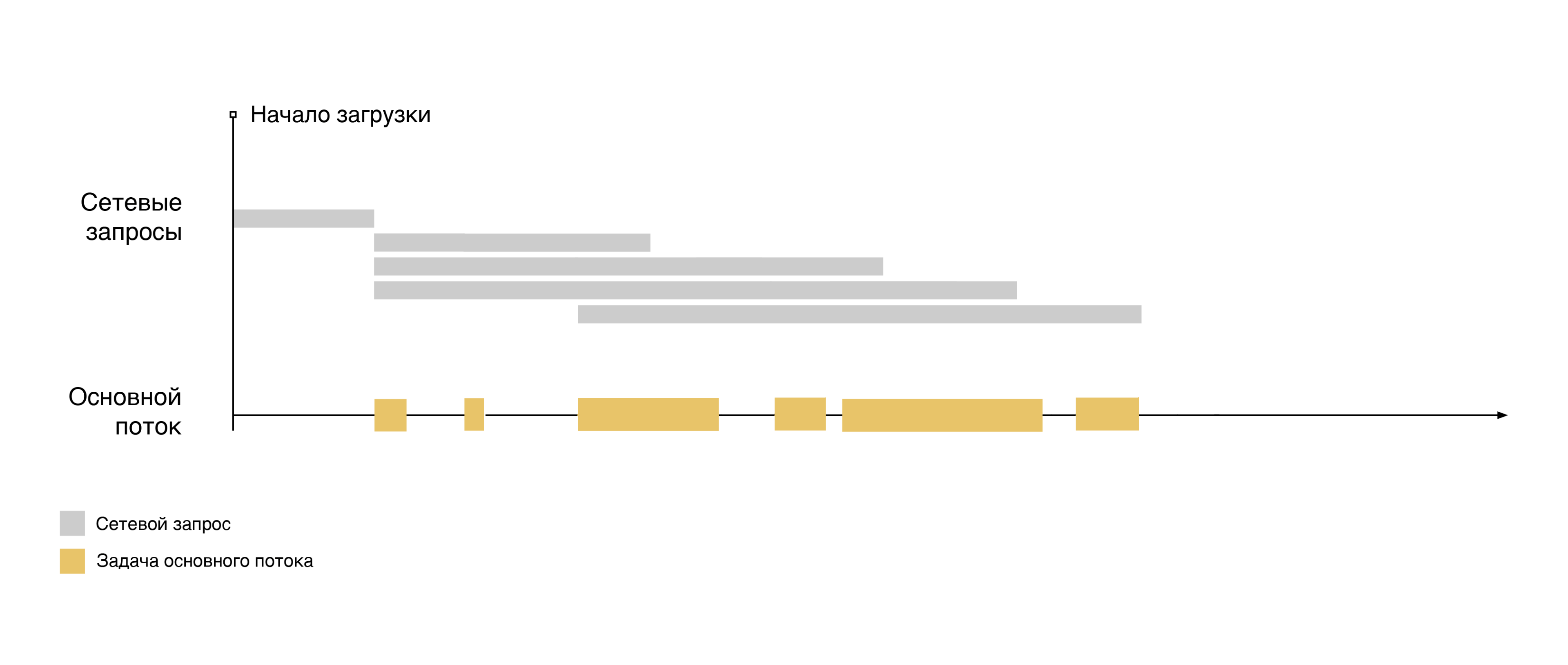
Шкала отображает выполнение сетевых запросов за основными ресурсами страницы, файлами CSS и JS (помечено серым цветом).
После загрузки ресурса происходит его обработка и выполнение в основном потоке браузера (помечено бежевым цветом).
В большинстве случаев, продолжительные задержки первого ввода (First Input Delay, FID), возникают между событиями первой отрисовки контента (First Contentful Paint, FCP) и наступлением интерактивности (Time To Interactive, TTI).
Добавим эти события на шкалу загрузки страницы:
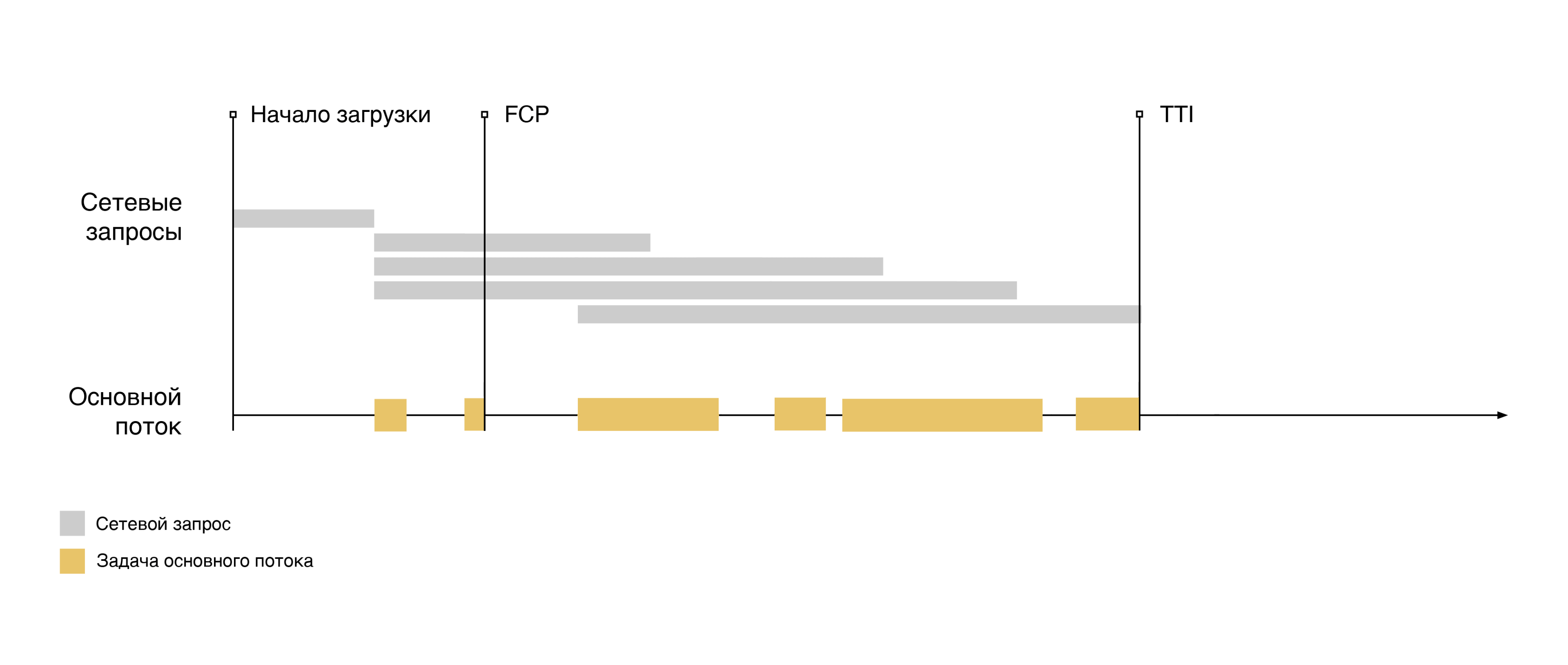
На временном отрезке между метриками FCP и TTI можно заметить выполнение некоторых задач в основном потоке браузера. Любая задача, которая длится более 50 мс, называется продолжительной. Ограничение в 50 мс соответствует одному из требований модели производительности RAIL.
Обозначим продолжительные задачи соответствующим цветом:
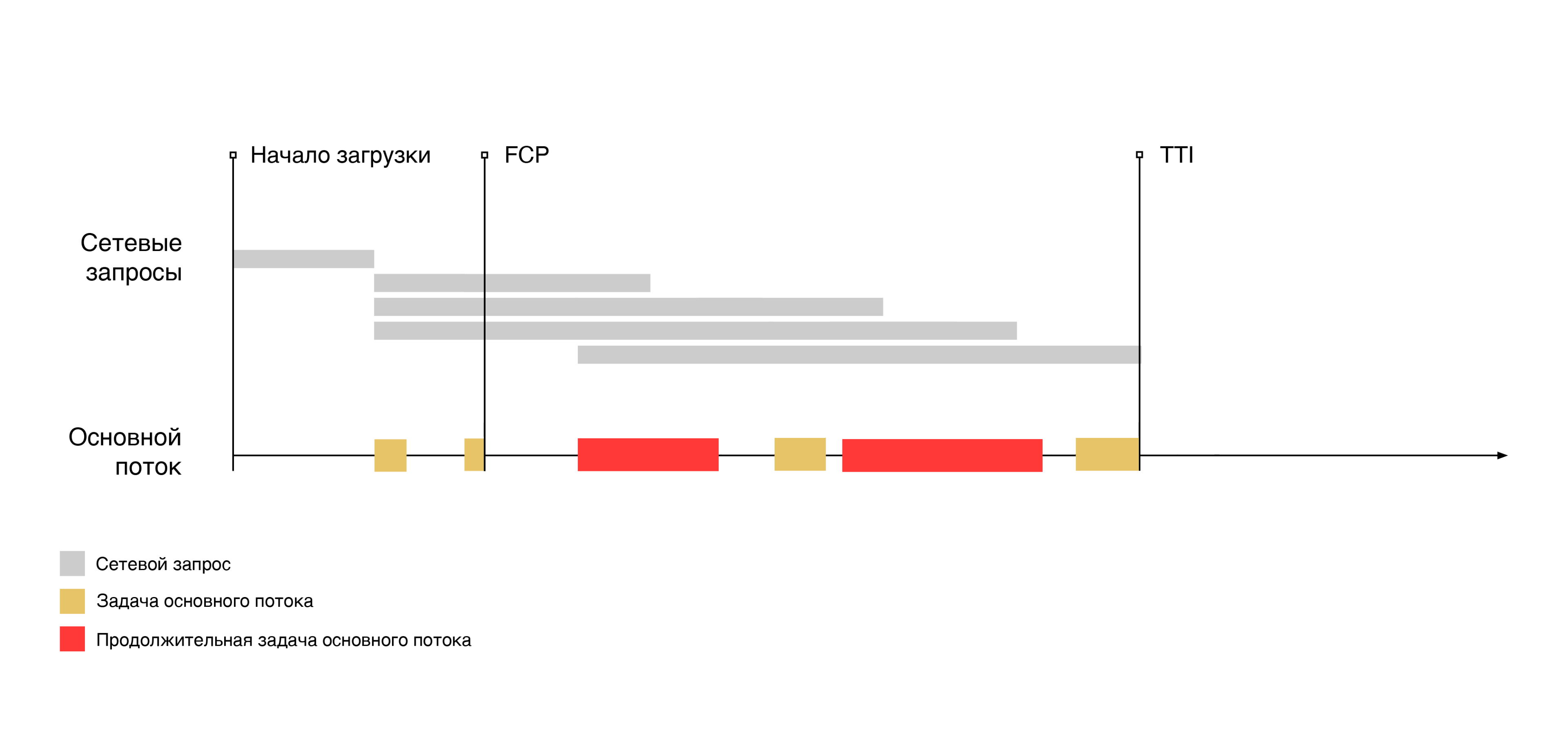
Если пользователь начнет взаимодействовать со страницей во время выполнения одной из таких задач, он столкнется с видимой задержкой. Задержка будет продолжаться до тех пор, пока основной поток браузера не завершит работу связанную с данной задачей.
Проиллюстрируем этот момент на временной шкале загрузки:
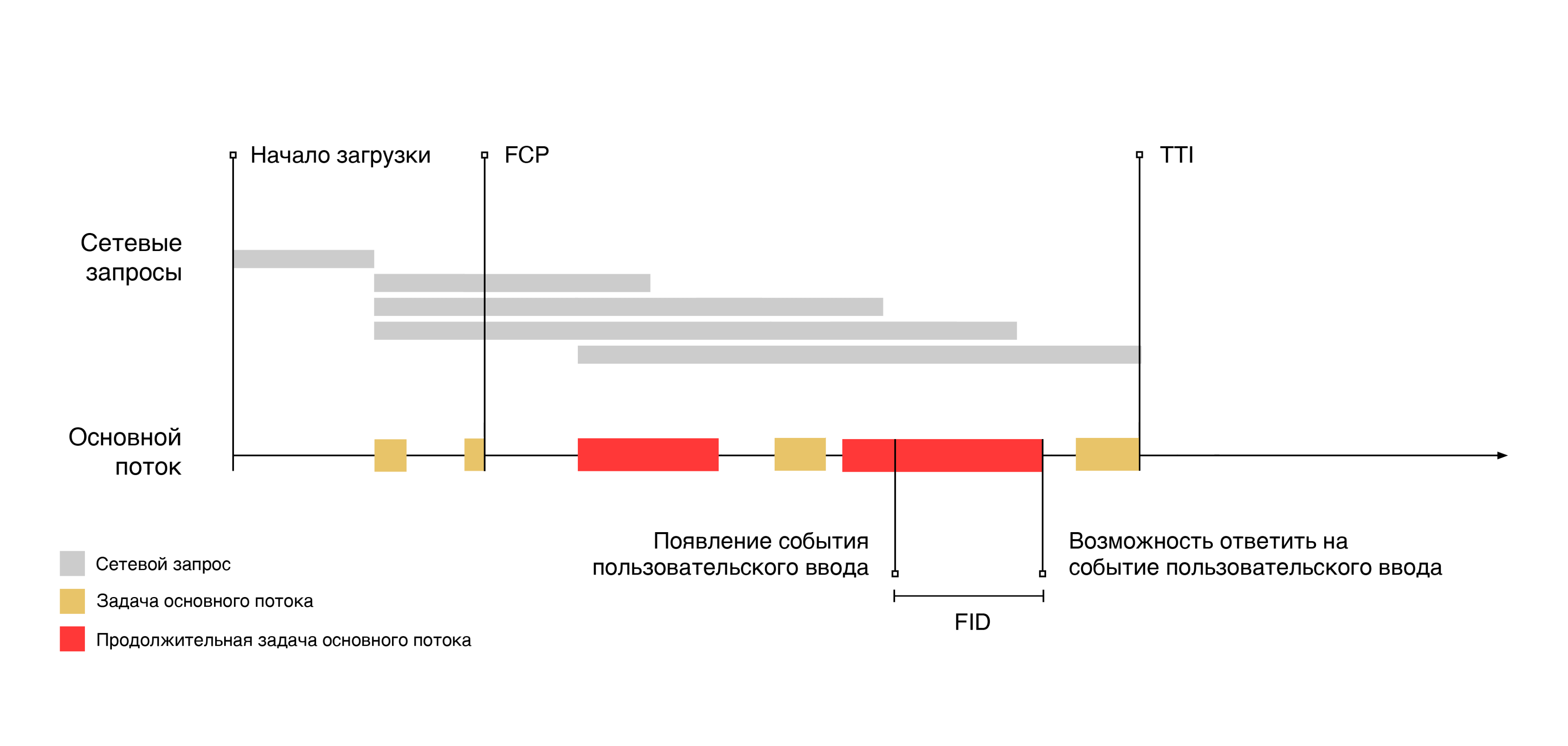
Как можно заметить, пользовательский ввод случился во время выполнения продолжительной задачи. Ответ на поступивший ввод произошел после того, как задача завершила свою работу. А время, прошедшее с момента появления события ввода до возможности его обработки, будет являться значением FID.
Значимость мониторинга данной метрики возрастает в разы, если ваш проект использует SSR (server-side rendering). Это связано с тем, что пользователь практически сразу получает наполненную контентом страницу, что дает ему мнимое ощущение готовности для взаимодействия с ней. Однако до окончания загрузки файлов скриптов и гидратации страница не сможет реагировать на ввод пользователя.
Ситуация ухудшается еще больше, когда в таком проекте пытаются улучшить время первой отрисовки контента (FCP), не обращая внимания на время наступления интерактивности (TTI). Поскольку улучшение метрик отрисовки без улучшения метрик интерактивности будет приводить к увеличению интервала между отображением интерфейса и его реальной готовностью к взаимодействию. Что, скорее всего, негативно скажется на показателе FID и впечатлениях при работе с вашим приложением.
Использование
Значение метрики можно получить используя PerformanceObserver API:
const performanceObserver = new PerformanceObserver((performanceEntryList) => {
const performanceEntry = performanceEntryList.getEntries()[0];
const { startTime, processingStart } = performanceEntry;
const firstInputDelay = processingStart - startTime;
console.log('FID is', firstInputDelay);
});
performanceObserver.observe({ type: 'first-input', buffered: true });Оценка результатов
При оценке результатов показателя рекомендуется использовать следующие градации:
Способы оптимизации
Основным улучшением, которое может оказать значительное влияние на показатель FID, является уменьшение количества JS-ресурсов на странице. Начиная от оптимизации зависимостей и удаления неиспользуемого кода, заканчивая код-сплиттингом и эффективной доставкой полифиллов.
Если вы уже проделали все вышеперечисленное, то вот пара дополнительных рекомендаций. Для SSR-проектов, есть смысл поэкспериментировать с частичной гидратацией. Подробности в следующих материалах:
Также рекомендую ознакомиться со стратегией выполнения кода Idle Until Urgent.
Custom Metrics
Еще один тип метрик, пользу которых сложно переоценить, — пользовательские метрики. Они позволяют измерять производительность отдельных элементов страницы или операций, выполняемых в приложении.
В Perfectum Client реализовано два подхода для работы с пользовательскими метриками: один — для этапа инициализации приложения, другой — для этапа взаимодействия с ним.
Рассмотрим непосредственно каждый из них.
Инициализация приложения
На данном этапе может понадобиться измерить время появления важных элементов страницы, например hero-изображения, cta-элемента, lead-формы и т.д.
Для этого необходимо добавить атрибут elementtiming к интересующему html-элементу:
Example App
После того как он отобразится на экране пользователя, в общее хранилище метрик добавится запись со значением указанного атрибута и временем появления элемента.
Взаимодействие с приложением
После инициализации приложения на странице может происходить множество ключевых событий, за производительностью которых также хотелось бы наблюдать. Это может быть выполнение приоритетных задач, рендеринг, загрузка ресурсов или даже пользовательские переходы между страницами приложения.
Для того чтобы измерить производительность таких операций, необходимо использовать интерфейс, представленный в виде двух статических методов класса Perfectum:
import Perfectum from '@perfectum/client';
Perfectum.startMeasure('metric-name');
someKindOfImportantTask();
Perfectum.stopMeasure('metric-name');После вызова метода stopMeasure в общее хранилище метрик добавится запись со значением переданного аргумента и временем, прошедшем с момента вызова метода startMeasure.
Анализ данных
За результатами работы клиентского мониторинга мы наблюдаем в Grafana. Например, так выглядит отображение показателя LCP для отдельно взятого проекта:
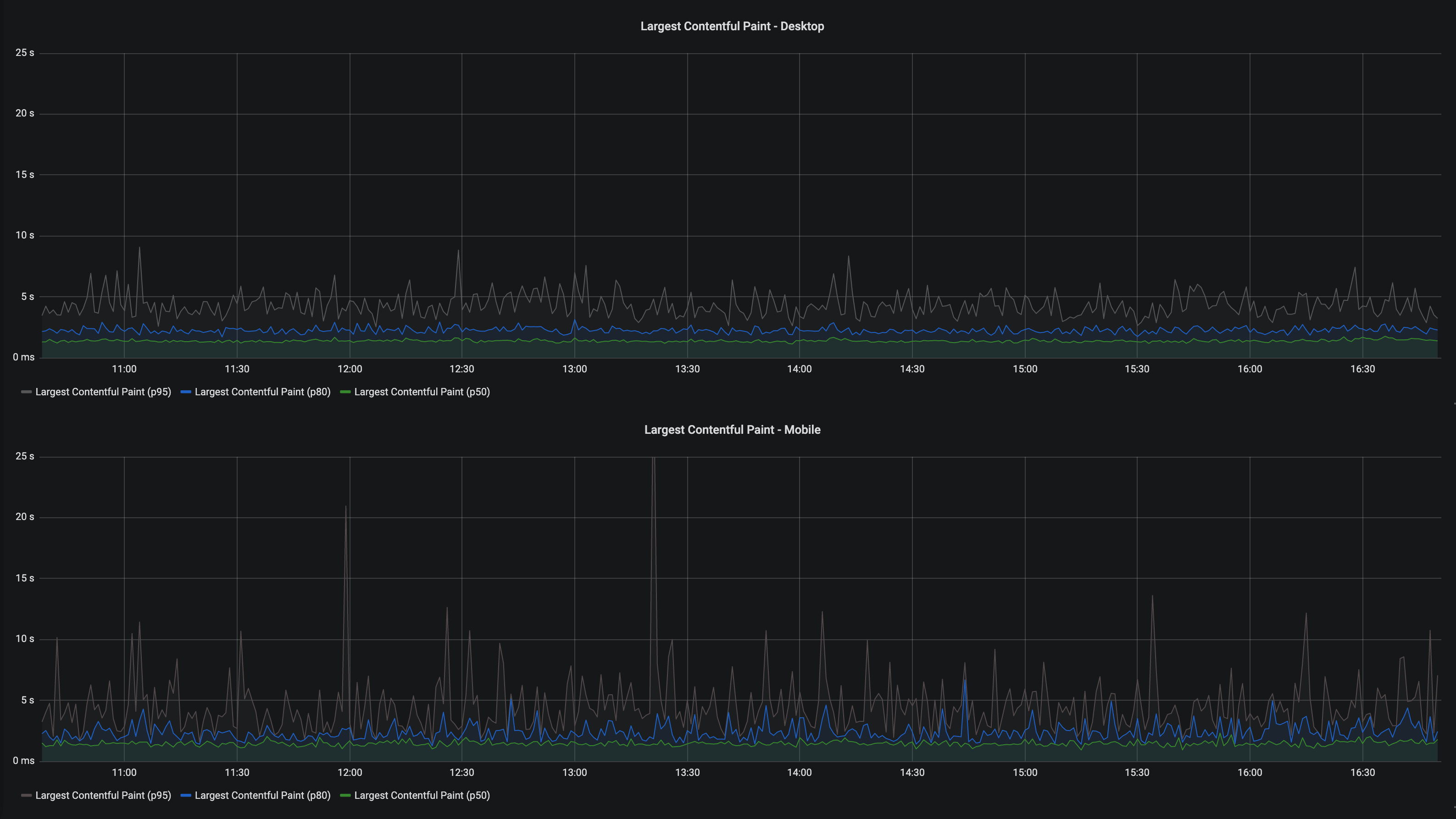
Как вы могли заметить, отображение показателей производительности разделено по типу используемых устройств (desktop/mobile). Для нас такое сегментирование крайне важно, поскольку 55% наших пользователей заходят в web-версию сайта с мобильных устройств.
Данные на графиках отображаются в агрегированном виде и показывают распределение по процентилям (50%, 80%, 95%). Процентиль — это показатель порогового значения для некоторой части данных.

Например, значение Largest Contentful Paint (p80), приведенное на графике выше, говорит о том, что у 80% desktop-пользователей показатель отрисовки наибольшего элемента не превышает 2 секунд.
Бюджеты производительности
После интеграции клиентского мониторинга и последующего анализа данных, хорошим шагом будет являться фиксирование показателей производительности. Это пригодится не только в постановке целей для будущих оптимизаций, но и для наблюдения за возможными регрессами.
Одним из вариантов такого фиксирования является практика внедрения бюджетов производительности.
Бюджет производительности — это набор ограничений, накладываемых на показатели производительности проекта.
Значения бюджетов производительности мы используем в настройке оповещений Grafana:
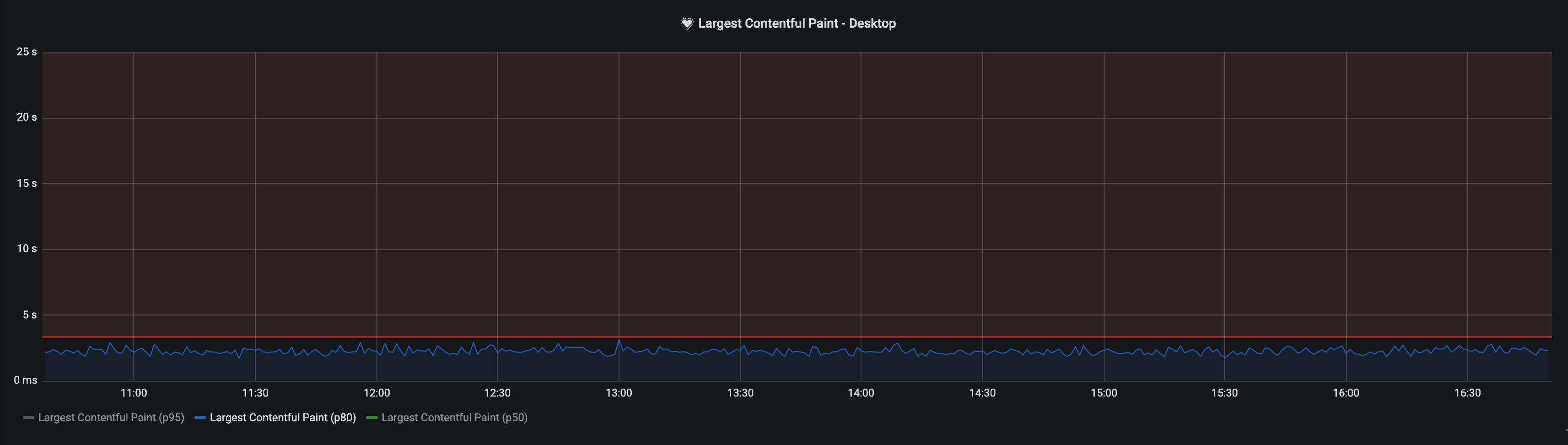
Красной линией на графике обозначен бюджет, установленный для данного показателя.
Определение бюджетов и настройка оповещений позволяет отслеживать возможные регрессы производительности.
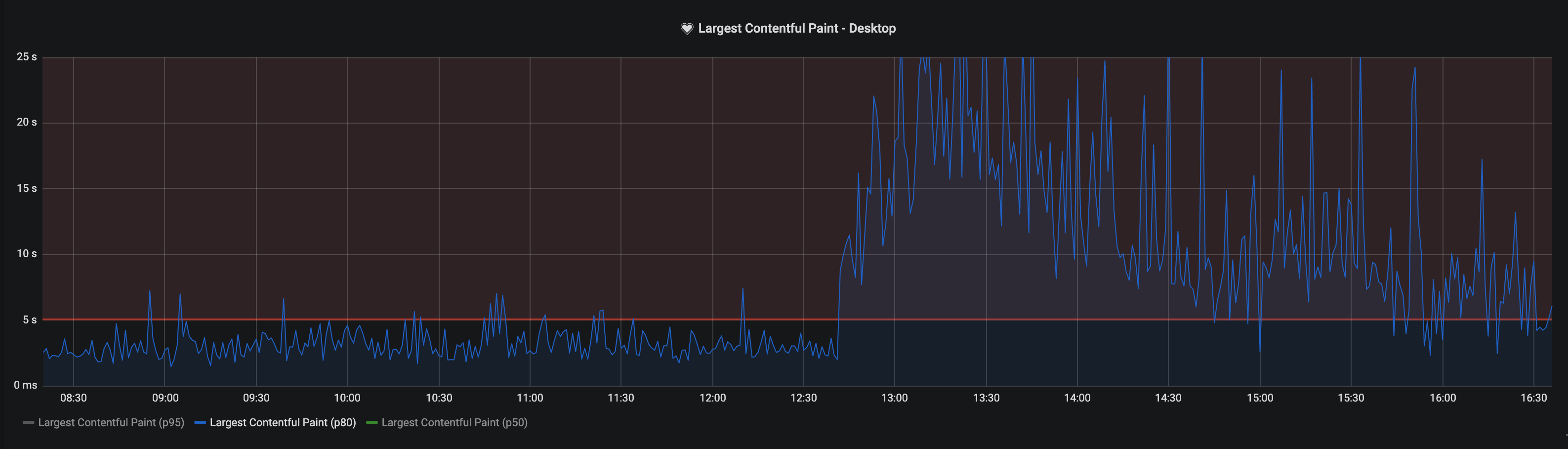
Например, в случае появления события, показанного на графике выше, мы получим соответствующее уведомление.
Что касается принципов построения бюджетов производительности, то их существует огромное множество, поэтому я ограничусь рассказом про тот, который используем мы.
Изначально мы исходим из того, что наши проекты не включают сложных технологических процессов, которые требуют создания real-time систем наблюдения. Например, таких, которые используются на атомных электростанциях (АСУ ТП, САУ, SCADA-системы).
Поэтому необходимости устанавливать строгие требования к точности, времени задержки и в целом к математической модели наблюдений у нас нет. В результате чего, мы используем упрощённую схему работы с отклонениями и определением бюджета.
Прежде всего мы предполагаем, что у нас уже есть данные необходимого нам показателя.
Далее для определения бюджета мы используем среднее значение по 80-му процентилю с добавлением допустимого отклонения в 20%.
Формула:
P — среднее значение показателя по 80-му процентилю
K — допустимое отклонение
B — бюджет
B = P + K
Пример:
P — 5000 (мс)
K — 20 (%)
B — ? (мс)
B = 5000 + (5000 × 0.20) = 6000
Среднее значение по 80-му процентилю — это медиана, то есть значение середины отсортированного списка.
Например, у нас есть список значений за определенный период времени, и этот список выглядит следующим образом: [4500, 5200, 5500, 4600, 5000]. Чтобы найти медиану, нам необходимо отсортировать данный список — [4500, 4600, 5000, 5200, 5500] — и взять значение из середины — 5000.
Использование медианы обусловлено тем фактом, что оно менее подвержено влиянию выбросов, по сравнению с обычным средним арифметическим.
Допустимое отклонение в 20% взято из принципа описанного в статье The Perception Of Time. Принцип основывается на результатах исследований в области психофизики и гласит, что минимально заметная разница, которую способен увидеть человек, в нашем случае — пользователь приложения, находится на уровне тех самых 20%.
В итоге алгоритм определения бюджета выглядит следующим образом:
- Берем выборку данных в пиковые часы работы приложения (например, с 10:00 до 19:00).
- Находим среднее значение 80-го процентиля.
- Прибавляем отклонение в 20%.
Заключение
Внедрение клиентского мониторинга — отличный шаг в сторону успешных оптимизаций проекта. Потому что любые оптимизации должны быть обоснованными, целенаправленными и, главное, измеряемыми.
А чтобы превентивно выявлять регрессы производительности, рекомендую ознакомиться с нашей статьей о синтетическом мониторинге.
