KDD 2018, день второй, семинары

Сегодня на KDD 2018 день семинаров — вместе с большой конференцией, которая начнется завтра, несколько групп собрали слушателей по некоторым специфичным темам. Побывал на двух таких тусовках.
Анализ временных рядов
С утра хотел пойти на семинар по анализу графов, но его задержали на 45 минут, поэтому перешел на соседний, по анализу временных рядов. Неожиданно открывает семинар профессор-блондинка из Калифорнии с темой «Искусственный интеллект в медицине». Странно, потому что для этого отдельный трек в соседнем зале. Потом выясняется, что у неё есть несколько аспирантов, которые будут рассказывать здесь про временные ряды. Но, собственно, к делу.
Искусственный интеллект в медицине
Врачебные ошибки — причина 10% смертей в США, это одна из трёх главных причин смертности в стране. Проблема в том, что врачей не хватает; те, что есть, перегружены, а компьютеры, скорее, создают проблемы врачам, чем решают, по крайней мере, врачи это так воспринимают. При этом большая часть данных реально не используется для принятия решений. Со всем этим надо бороться. Например, одна бактерия Clostridium difficile отличается высокой вирулентностью и устойчивостью к лекарствам. За прошлый год она нанесла урона на 4 миллиарда долларов. Давайте попробуем оценить риск заражения на основе временного ряда медицинских записей. В отличие от предыдущих работ, возьмем очень много признаков (10k-вектор на каждый день) и будем строить индивидуальные модели для каждого госпиталя (во многом, судя по всему, вынужденная мера, так как во всех больницах свой набор данных). В итоге получаем точность порядка 0.82 AUC при прогнозе риска CDI через 5 дней.
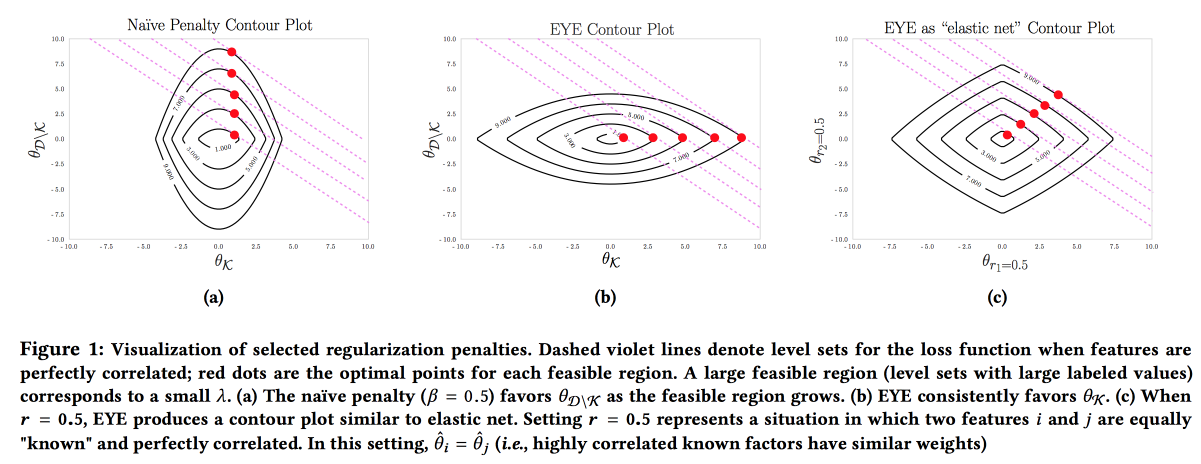
Важно, чтобы модель была точной, интерпретируемой и устойчивой, нужно показать, что мы можем сделать для предотвращения заболевания. Такую модель можно построить, активно используя знания из предметной области. Именно стремление к интерпретируемости часто снижает количество фич и приводит к созданию простых моделей. Но даже простая модель при большом пространстве признаков теряет интерпретируемость, а использование L1-регуляризации часто ведет к тому, что модель выбирает случайно одну из коллинеарных фич. В итоге врачи не верят модели, несмотря на хороший AUC. Авторы предлагают использовать другой тип регуляризации EYE (expert yield estimate). С учетом того, есть ли известные данные по влиянию на результат, получается сфокусировать модель на нужных фичах. Дает неплохие результаты, даже если эксперт облажался, более того — сравнив качество со стандартными регуляризациями, можно оценить, насколько эксперт прав.
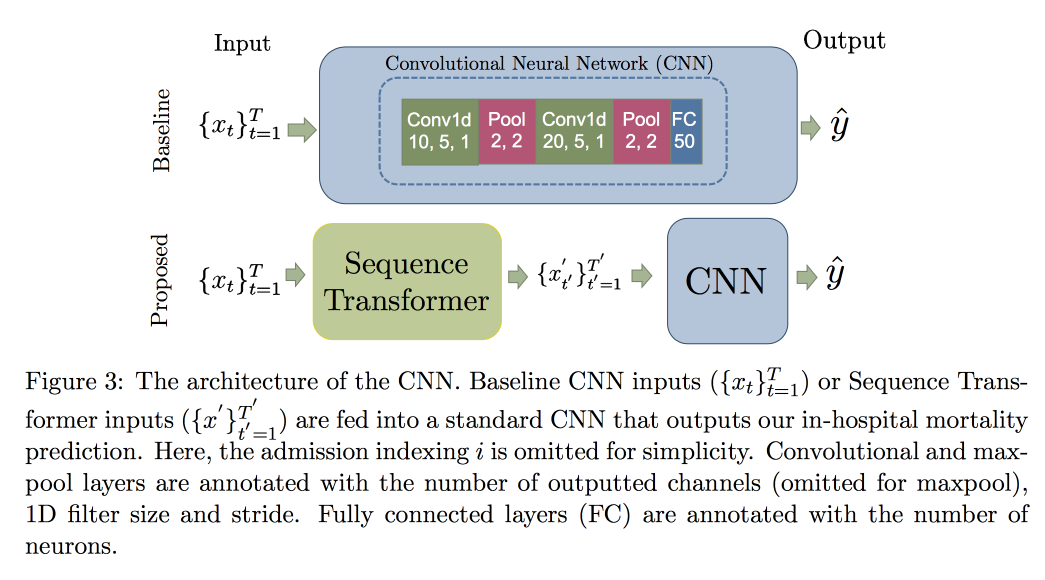
Далее переходим к анализу временных рядов. Оказывается, для улучшения качества в них важно искать инварианты (по сути — приводить к некоторой канонической форме). В недавней статье группа профессорши предложила подход на базе двух сверточных сетей. Первая, Sequence Transformer, приводит ряд к каноническому виду, а вторая, Sequence Decoder, решает задачу классификации.
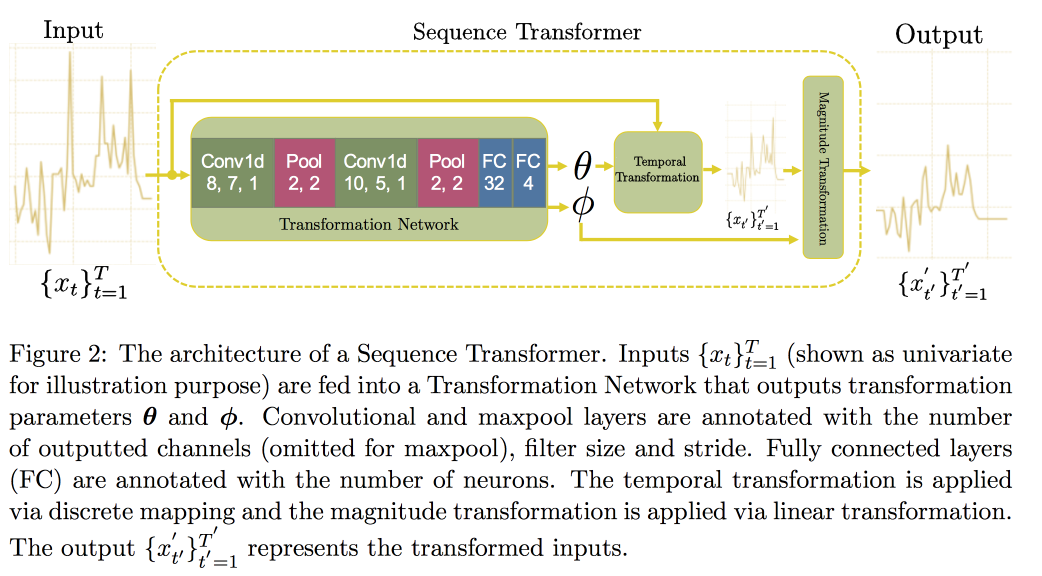
Использование CNN, а не RNN, объясняется тем, что работают с рядами фиксированной длины. Проверяли на датасете MIMIC, пытались предсказать смерть в больнице в течении 48 часов. В результате получили улучшение на 0.02 AUC по сравнению с простой CNN с дополнительными слоями, но доверительные интервалы пересекаются.
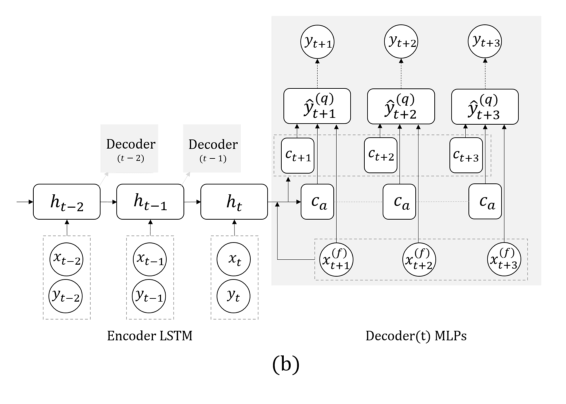
Теперь другая задача: будем прогнозировать исключительно на базе собственно ряда, без внешних сигналов (о том, что съели и т.д.). Здесь команда предложила заменить RNN для прогнозирования на несколько шагов вперед сеткой с несколькими выходами, без рекурсии между ними. Объяснение такого решения заключается в том, что не накапливается ошибка при рекурсии. Совмещают эту технику с предыдущей (поиск инвариантов). Сразу следом за выступлением профессора постдок детально рассказывал про эту модель, поэтому здесь на этом закончим, отметив только, что при валидации важно смотреть не только на общую ошибку, но и на ошибку классификации опасных случаев слишком высокой или низкой глюкозы.
Набросил вопрос про обратную связь модели: пока это больной открытый вопрос, говорят, что надо пытаться понять, какие изменения в распределении признаков происходят в результате факта вмешательства, а какие — естественные сдвиги, вызванные внешними факторами. Собственно, наличие таких сдвигов сильно усложняет ситуацию: не переобучать модель нельзя, так как деградирует качество, подмешать рандом (не лечить кого-то и проверить, умрет ли) не этично, а учить на данных, где всех лечили по рекомендации модели — это гарантированный биас…
Sample Path Generation
Пример того, как не надо делать презентации: очень быстро, сложно даже услышать, а уловить идею практически невозможно. Сама работа доступна здесь.
Ребята развивают свой предыдущий результат по прогнозированию на несколько шагов вперед. Основных идей в прошлой работе две: вместо РНН использовать сеть с несколькими выходами для разных моментов времени, плюс вместо конкретных чисел пытаемся прогнозировать распределения и оценивать квантили. Называется это всё MQ-RNN/CNN (Multi-Horizont forecasting Quantile regression).
В этот раз попробовали еще уточнить прогноз с помощью постпроцессинга. Рассмотрели два подхода. В рамках первого пытаемся «откалибровать» распределения нейросети, используя апостериорные данные и выучив матрицу ковариации выходов и наблюдений, так называемый Covariance Shrinkage. Метод достаточно простой и рабочий, но хочется большего. Второй подход заключался в использовании генеративных моделей для построения «сэмпла пути»: используют генеративный подход для прогнозирования (GAN, VAE). Хорошие, но нестабильные результаты удалось получить с помощью разработанной для генерирования звука WaveNet.
Graph Structured Networks
Интересная работа по перенесению «знания о предметной области» в нейросеть. Показывали на примере прогнозирования уровня преступности в пространстве (по регионам города) и времени (по дням и часам). Основная сложность: сильная разреженность данных и наличие редких локальных событий. В результате многие методы работают плохо, в среднем по дню еще угадать получается, но по конкретным районам и часам — нет. Попробуем совместить высокоуровневую структуру и микропатерны в одной нейросети.
Строим граф связи по почтовым кодам и определяем влияния одних на другие с помощью Multivariate Hawkes Process. Далее на основе полученного графа строим топологию нейронной сети, связывая блоки регионов города преступность в которых показала корреляцию.
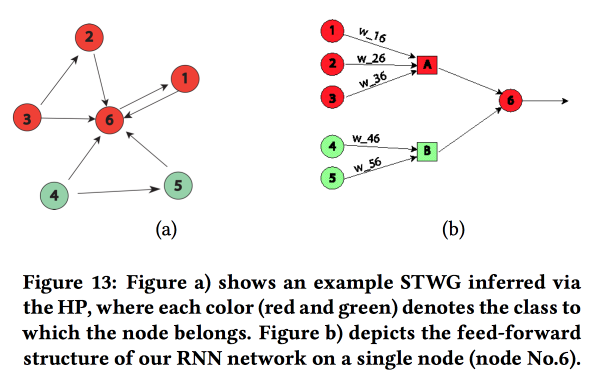
Сравнили такой подход с двумя другими: тренировать по сетке на район или по сетке на группу районов со сходным уровнем преступности, показали рост точности. Для каждого района вводится двухслойный LSTM с двумя полносвязными слоями.
Помимо преступлений показали еще примеры работы над предсказанием трафика. Здесь уже граф для построения сети берется географически по kNN. Не до конца понятно, насколько можно их результаты сравнивать с другими (достаточно вольно меняли метрики в анализе), но в целом эвристика для построения сети выглядит адекватно.
Nonparametric approach for ensemble forecasting
Ансамбли это очень популярная тема, но то, как из отдельных прогнозов вывести результат, не всегда очевидно. В своей работе авторы предлагают новый подход.
Часто простое среднее в ансамблях работает хорошо, даже лучше. чем новомодные Bayesian model averaging и averaging-NN. Регрессия тоже неплоха, но часто дает странные результаты в плане выбора весов (например, каким-то прогнозам даст отрицательный вес и т.д.). На самом деле, причина этого часто заключается в том, что метод агрегации использует некоторые допущения относительно того, как распределена ошибка прогнозов (например, по Гауссу или нормально), но при его применении выполнение этого допущения забывают проверить. Авторы попытались предложить свободный от допущений подход.
Рассматриваем два случайных процесса: Data Generation Process (DGP) моделирует реальность и может зависеть от времени, а Forecast Generation Process (FGP) моделирует построение прогнозов (их много — по одному на участника ансамбля). Разность этих двух процессов тоже случайный процесс, которые мы попробуем проанализировать.
- Соберем исторические данные и построим плотность распределения ошибки для прогнозаторов, используя Kernel Density Estimation.
- Далее строим прогноз и превращаем в случайную величину добавлением построенной ошибки.
- После чего решаем задачу максимизации правдоподобия.
Полученный метод почти как EMOS (Ensemble Model Output Statistics) при Гауссовой ошибке и гораздо лучше при не-Гауссовой. Часто в реальности, например, (Wikipedia Page Traffic Dataset) — не-Гауссова ошибка.
Nested LSTM: Modeling Taxonomy and Temporal Dynamics in Location-Based Social Network
Работу представляют авторы из Google. Пытаемся предсказать следующий чекин пользователя. используя его историю недавних чекинов и метаданные мест, в первую очередь их отношения к меткам/категориям. Категории трехуровневые, используем два верхних уровня: родительская категория описывает намерение пользователя (например, желание поесть), а дочерняя — предпочтения пользователя (например, пользователь любит испанскую еду). Дочернюю категорию следующего чекина и надо показать для получения большего дохода от онлайн-рекламы.
Используем два вложенных LSTM: верхний, как обычно, по последовательности чекинов, а вложенный — по переходам в дереве категорий от родительской к дочерней.
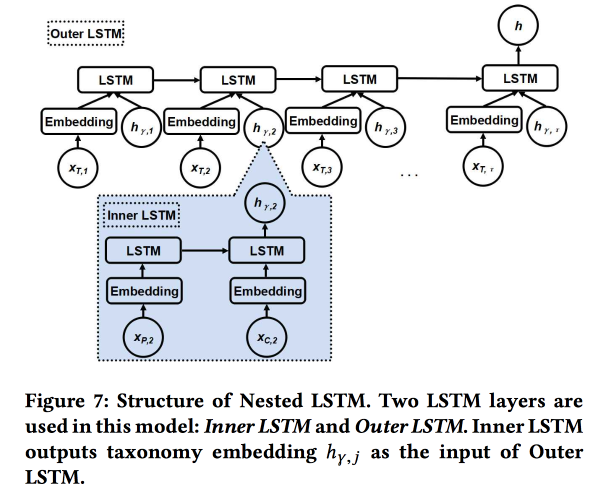
Получается на 5–7% лучше по сравнению с простым ЛСТМ с сырыми эмбедингами категорий. Кроме того, мы показали, что ЛСТМ-эмбединги переходов в дереве категорий выглядят более красивыми по сравнении с простыми и лучше кластеризуются.
Identifying Shifts in Evolutionary Semantic Space
Достаточно бодрое выступление китайского профессора. Суть в том, чтобы попытаться понять, как слова меняют свой смысл.
Сейчас все успешно тренируют эмбединги слов, они хорошо работают, но будучи обучены в разное время для сравнения не подходят — надо сделать аллайнинг.
- Можно взять старые за инициализацию, но это не дает гарантий.
- Можно выучить функцию-трансформацию для аллайнинга, но получается не всегда, так как размерности не всегда разделяются одинаково.
- А можно использовать топологическое, а не векторное пространство!
В итоге суть решения: строим кНН-граф по соседям слова в разные периоды для оценки изменения смысла, и пытаемся понять, есть ли тут значимое изменение. Для этого используем модель Байесовского Сюрприза. По сути, смотрим на KL-дивергенцию распределения гипотезы (приор) и гипотезы при условии наблюдений (постериор) — это и есть сюрприз. Со словами и кНН-графами в качестве априорного распределения используем Дирихле на базе частот соседей в прошлом и сравниваем с реальным multinomial по недавней истории. Итого:
- Режем историю.
- Строим эмбединги (LINE с сохранением инициализации).
- Считаем кНН на эмбедингах.
- Оцениваем сюрприз.
Валидируем, взяв два случайных слова с одинаковой частотой, и меняем друг на друга — прирост в качестве от сюрприза равен 80%. Потом возьмем 21 слово с известными дрейфами смысла и посмотрим, сможем ли найти их автоматически. В открытых источниках пока детального изложения этого подхода нет, но есть на SIGIR 2018.
AdKDD & TargetAd
После обеда переместился на семинар по онлайн-рекламе. Здесь гораздо больше докладчиков от индустрии и все думают о том, как заработать больше денег.
Ad Tech at AirBnB
Будучи крупной компанией с большой ДС-командой, AirBnB достаточно много вкладывается в то, чтобы грамотно рекламировать себя и свои внутренние предложения на внешних площадках. Один из разработчиков рассказал немного о возникающих задачах.
Начнем с рекламы в поисковике: при поиска отелей в Google первые две страницы — реклама :(. Но пользователь часто даже не понимает этого, потому что реклама очень релевантная. Стандартная схема: матчим запросы к рекламе по ключевикам и извлекаем смысл по патерну/патернам (город, дешевый или люксовый и т.д.)
После того, как кандидаты отобраны, устраиваем между ними аукцион (сейчас везде используется Generalized Second Price). При участии в аукционе стоит задача максимизации эффекта при фиксированном бюджете, используется модель с комбинацией вероятности клика и дохода: Bid = P (click | search query) * booking value. Важный момент: не потратить все деньги слишком быстро, поэтому добавляем Spend pacer.
В AirBnB мощная система для А/Б-тестов, но здесь её не применить, так как рулит большей частью процесса Google. Там обещали добавить для рекламодателей больше инструментов, крупные игроки очень ждут.
Отдельная проблема: контакт пользователя с рекламой в нескольких местах. Путешествуем в среднем пару раз в год, цикл подготовки поездки и бронирования очень долгий (недели и даже месяцы), есть несколько каналов, где мы можем дотянутся до пользователя, и надо делить бюджет по каналам. Тема эта очень больная, есть простые методы (линейно, взвешенно, по последнему клику или по результатам uplift test). В AirBnB попробовали два новых подхода: на базе Марковских моделей и модели Шепли.
С Марковской моделью всё более-менее понятно: строим дискретную цепь, узлы в которой соответствуют точкам контакта с рекламой, есть также узел для конверсии. По данным подбираем веса для переходов, больше бюджета даем тем узлам, где вероятность перехода больше. Накинул им вопрос: почему используют простую цепь Маркова, тогда как логичнее применять MDP; сказали, что на эту тему ведут работы.
Интереснее с Шепли: по сути, это давно известная схема оценки аддитивного эффекта, при которой рассматриваются разные комбинации воздействий, оценивается эффект от каждой из них, а затем определяется некий агрегат для каждого отдельного воздействия. Сложность в том, что между воздействиями может быть синергия (реже антагонизм), и результат от суммы не равен сумме результатов. В общем, достаточно интересная и красивая теория, советую почитать.
В случае с AirBnB применение модели Шепли выглядит примерно так:
- Имеем в наблюдаемых данных примеры с разными комбинациями воздействий и фактическим результатом.
- Заполняем пробелы в данных (не все комбинации представлены) с помощью ML.
- Вычисляем кредит для каждого из типов воздействия по Шепли.
Майкрософт: Pushing {AI} Boundaries
Дальше немного о том. как рекламой занимаются в Microsoft, теперь со стороны площадки, в первую очередь Bing-а. Немного боянов:
- Рынок рекламы растет очень быстро (по экспоненте).
- Реклама на одной странице каннибализирует друг друга, надо анализировать всю страницу.
- Конверсия на некоторых страницах выше, несмотря на то, что СТР хуже.
В движке рекламы Bing порядка 70 моделей, 2000 экспериментов в офлайне, 400 в онлайне. Одно существенное изменение в платформе каждую неделю. В общем, работают не покладая рук. Какие происходят изменения в платформе:
- Миф об одной метрике: не получается так, метрики растут и конкурируют.
- Переделали систему матчинга рекламы запросам с НЛП на ДЛ, который обсчитывают на FPGA.
- Используют федеративные модели и контекстных бандитов: внутренние модели продуцируют вероятность и неопределенность, бандит сверху принимает решение. Про бандитов говорила много, используют их для старта моделей и выведения на крейсерскую скорость, обходят с их помощью факт, что часто улучшение модели приводит к снижению доходов :(
- Очень важно оценивать неопределенность (ну да, без нее бандита не построишь).
- Для маленьких рекламодателей не работает заведение рекламы через бандитов, мало статистики, надо делать отдельные модели для холодного старта.
- Важно следить за производительностью на разных когортах пользователей, у них есть автоматическая система для слайсинга по результатам эксперимента.
Немного поговорили про анализ оттока. Не всегда гипотезы продажников о причинах оттока верны, надо копать глубже. Для этого приходится строить интерпретируемые модели (или специальную модель для объяснения прогнозов) и много думать. А потом проводить эксперименты. Но с оттоком эксперименты всегда делать сложно, рекомендуют использовать метрики второго порядка и статью от Google.
Еще используют такую штуку, как Commercial Knowledge Graph, представляющий описание предметной области: бренды, продукты и т.д. Строят граф полностью в автоматическом режиме, unsupervised. Бренды помечают категориями, это важно, так как в целом не всегда удается unsupervised выделить бренд в целом, но в рамках какой-то категории-темы сигнал сильнее. К сожалению, открытых работ по их методу не нашел.
Google Ads
Рассказывает тот же чувак, что вчера рассказывал про графы, всё так же грустно и высокомерно. Прошлись по нескольким темам.
Часть первая: Robust Stochastic Ad Allocation. У нас есть бюджетированные ноды (объявления) и онлайн-ноды (пользователи), а также есть некоторые веса между ними. Теперь надо выбирать, какие рекламные объявления показать новой ноде. Можно делать это жадно (всегда по максимальному весу), но тогда рискуем преждевременно выработать бюджет и получить неэффективное решение (теоретический предел — ½ от оптимума). Можно по-разному с этим бороться, по сути, здесь мы имеем традиционный конфликт revenu и wellfair.
При выборе метода аллокаций можно предполагать случайный порядок появления онлайн-нод в соответствии с некоторым распределением, но на практике может оказаться и adversarial-порядок (т.е. с элементами некоторого противящегося воздействия). Методы в этих случаях применяются разные, дают ссылки на свои свежие статьи: 1 и 2.
Часть вторая: Inceptive-aware learning/Robust Pricing. Теперь пытаемся решить вопрос выбора цены резервации для увеличения дохода рекламных площадок. Также рассматриваем использование других аукционов типа Myerson auction, BINTAC, откат к аукциону первой цены при попадании на резервацию. В подробности не вдаются, отправляют к своей статье.
Часть третья: Online Bundling. Снова решаем проблему с увеличением дохода, но теперь заходим с другой стороны. Если бы можно было покупать рекламу оптом (offline bundling), то во многих ситуациях можно предложить более оптимальное решение. Но провернуть это в онлайн-аукционе не получается, надо строить сложные модели с памятью, а в жестких условиях RTB это не впихнуть.
Тут появляется магическая модель, где вся память сводится к одной цифре (bank account), но время поджимает, и докладчик начинает неистово листать слайды. За ответами, в своем лучшем стиле, отправляет к статье.
Deep Policy optimization by Alibaba
Работаем со «sponsored search». Решили использовать RL, как следует из названия — глубокий. Детальную информацию можно найти в статье.
Как про один из важных моментов рассказывали о разделении offline-части обучения, где тренируется собственно глубокая сеть, и online-части, где происходит адаптация признаков.
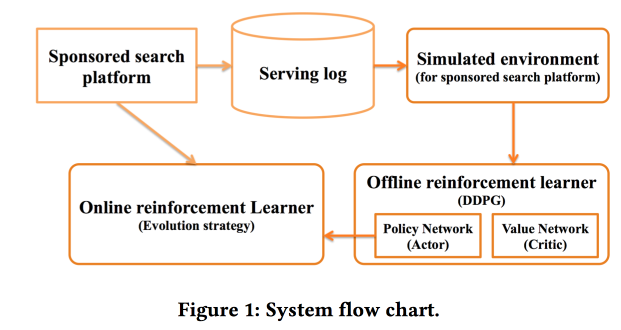
В качестве награды используют смесь CTR и дохода, применяют модель DDPG.
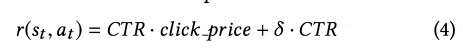
В конце докладчик адресовал три открытых вопроса-проблемы к аудитории, «на подумать»:
- Нет реальной среды для РЛ.
- Много шума в реальности, который сильно усложняет анализ.
- Как работать с меняющейся средой?
Criteo Large Scale Benchmark for Uplift Modeling
Снова возвращаемся к задаче выявления аплифта (эффекта от конкретного воздействия среди многих). В Criteo для анализа подходов к решению задачи сделали новый датасет Criteo-UPLIFT1 (450 Мб) и прогнали бенчмарк.
Идея достаточно простая. Есть начальное желание купить что-нибудь, возможно, пользователь купил бы и без лечения (выздоровел сам). Смотрим на разность двух условные вероятностей с и без лечения — это и есть аплифт (помним, что смотрим на конкретного пользователя).
Как оценивать такую модель? Посмотрим на ситуацию как на задачу ранжирования. Зачем-то перейдя к ранжированию, вводят странную модель оценки — берем кумулятивный по рангу аплифт с нашим ранжированием и случайным порядком, сравниваем площадь между кривыми (AUUC). Также смотрим на Qini-коэфициент (генерализация Gini для аплифта), можно сравнить с идеальным по Qini, а не рандомным.
Тестировали в рамках бенчмарка два подхода. В первом случае тренируем две модели: одну на группе с лечением, другую на группе без лечения для предсказания вероятности. Ранжируем по дельте прогнозов.
Другой подход назвали revert label. Переразметили датасет так, что единицами стали те, кто получил лечение и конвертировался, а также те, кто не получил и не конвертировался; остальные нули. Ранжируем, ставя вверх тех, кто похож на единицы.
По результатам бенчмарка, с точки зрения визитов модель с ревертом работает лучше. С конверсиями улучшение достигается по мере увеличения объема данных.
Deep Net with Attention for Multi-Touch Attribution
Про то, как работать с многими каналами, на этот раз от Adobe. Простые модели мы сразу отбрасываем и начинаем учить, конечно, сетку! Причем не просто сетку, а с attention-слоем поверх LSTM, как раз для моделирования вклада отдельных источников. Для моделирования статичных фич добавим рядом с LSTM-ом полносвязную сетку из нескольких слоев и получим лучший результат.
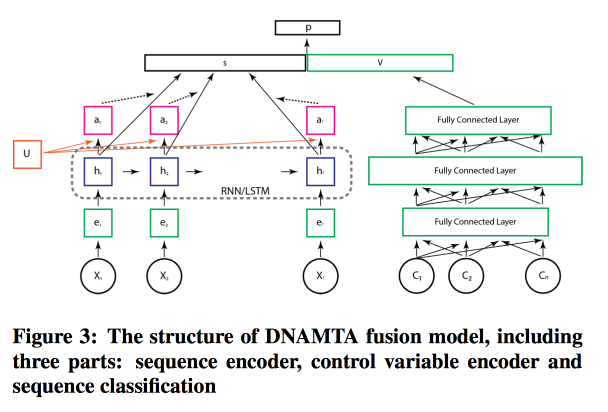
В целом модель не выглядит такой уж безумной, а attention-слой действительно дает шанс на интерпретируемость модели.
Заключение
Дальше была пафосная сессия открытия с IMAX-роликом в лучших традициях трейлеров к блокбастерам, много спасибо всем, кто помогал это всё организовать — рекордный KDD по всем параметрам (в том числе $1,2 млн спонсорской помощи), напутствие от лорда Байтса (министра инновационного развития UK) и постер-сессия, на которую уже не осталось сил. Надо готовиться к завтрашнему дню.
