Каждому по потребностям: как мы решали задачу с «нарезкой» vCPU

Всем привет! Возникал ли у вас вопрос, как можно ограничить виртуальную машину по используемым CPU?
У нас в Selectel он возник, когда мы хотели сделать облачную платформу гибче и удешевить инфраструктуру для клиентов. В результате получилась линейка виртуальных машин Shared Line. Это облачные серверы с гарантированной долей производительности ядра — их арендуют те, кому не нужна полная загрузка CPU.
Под катом расскажу, как мы учились «резать» мощности облачных серверов на кусочки.
Зачем нужно управление производительностью виртуальных машин
Можно выделить пару сценариев, где будет полезно управлять производительностью виртуалок:
1. Хотим ограничивать доступный объем ресурсов.
Подобное требование может возникнуть, когда необходимо быть уверенным, что виртуальная машина не потребует весь доступный ресурс по CPU и оперативной памяти. В таком случае мы говорим о жестком ограничении на используемые ресурсы.
2. Хотим приоритизировать процессы.
С приоритизацией все интереснее, так как здесь мы не ограничиваем виртуальную машину напрямую, а лишь устанавливаем ее приоритет в очереди на использование ресурсов.
Зачем это пользователям
Представим человека, который хочет развернуть виртуальную машину и разместить там pet-проект. Если проект будет крутиться на домашнем компьютере (все же дома используют Linux, да?), то может не хватить ресурсов на другой pet-проект, браузер или катку в Dota. А если разворачивать такой проект в облаке, то под него пришлось бы брать целый процессор.
Если на начальном этапе больших нагрузок не предвидится, даже минимальная конфигурация «виртуалки» может быть избыточна — будем платить за простаивающие ресурсы. И тут как раз пригодилась бы возможность создать виртуальную машину с определенной долей ядра.
А организациям пригодится?
Точно пригодится!
Рассмотрим сферическую компанию в вакууме. Допустим, она содержит свою или арендует облачную инфраструктуру у провайдера. На виртуальных машинах развернуто суперважное ПО — например, Jira и Confluence, а также ряд сервисов поменьше — какой-нибудь телеграм-бот для напоминаний. Возможно, есть еще ряд экспериментальных служб и приложений — отдельные сотрудники сделали себе удобные инструменты.
Для надежности каждое приложение или сервис запущено на своей виртуальной машине. Со временем сервисов будет становиться все больше. Какие-то из них станут тяжелее. Часть хостов нужно будет выключать на обслуживание и, рано или поздно, наступит момент, когда ресурсы в инфраструктуре закончатся. Проблема.
Даже оркестрация контейнеров и подобные фокусы все равно не гарантируют полной утилизации мощностей.
Самое очевидное, что можно сделать — докупить мощностей если вам не перестали продавать. Это рабочее решение, но не все могут его себе позволить.

Если не докупать, то придется оптимизировать использование ресурсов. Здесь как раз пригодится ограничение виртуальных машин по производительности.
Раньше мы уже писали, как оптимизировать «расход» инфраструктуры →
Нетребовательные или редко используемые сервисы можно перевезти на виртуалки с ограничением по CPU и памяти без ухудшения качества работы. Важным сервисам, в свою очередь, можно повысить приоритет, чтобы у них всегда было достаточное количество ресурсов.
И вот мы уже сэкономили на аренде новых серверов, более мудро распределив существующие ресурсы. При этом качество работы сервисов не снизилось, даже еще место освободилось. Win!

А провайдерам инфраструктуры это зачем?
Если обуться в ботиночки облачного провайдера (допустим, Selectel), появится еще несколько причин управлять производительностью виртуальных машин.
Более плотная утилизация ресурсов
Не секрет, что виртуальные машины создаются на специальных «железных» хостах облачного провайдера. В них много памяти и ядер. Иногда возникают ситуации, когда на хосте есть свободные ресурсы, но их столько, что адекватная конфигурация для еще одного виртуального сервера не помещается. То есть вроде бы и в железе есть ресурс, но ни одна конфигурация в него не лезет по параметрам (память, ядра).
В итоге эти «остатки» просто не используются.
Чтобы избежать такой ситуации, провайдеру приходится играть в тетрис (нет, правда). Перекладывать виртуальные машины с хоста на хост, чтобы более плотно упаковать их. Это очень затратный процесс.
Возможность создавать более дешевую инфраструктуру в облаке
Если будет возможность управлять производительностью виртуальных машин, то можно будет оптимизировать стоимость виртуалок. Так, например, в линейке Shared Line можно арендовать 10% мощности сервера с 1 CPU, 512 МБ RAM и сетевым диском на 5 ГБ за 193,60 ₽/мес. При правильных подсчетах можно сэкономить на запуск еще одного проекта.
Итак, зачем это все, мы немного определились. Теперь рассмотрим, какие существуют инструменты и способы ограничения виртуальных машин по использованию ресурсов.
Способы ограничения ВМ по использованию CPU
Сразу оговоримся, что речь в основном пойдет о способах управления производительностью в ОС Linux. Почему так? В лучших традициях ответим мемом:

При разработке линейки Shared Line у нас не было готового ответа, какой именно инструмент использовать. Перед реализацией проводили исследование существующих способов. По понятным причинам в основном искали опенсорсные решения.
В самом начале поисков стало понятно: мы не первые, у кого возникла подобная задача. Сходу нашлось несколько способов ограничения виртуальных машин по используемым ядрам.
Перечислю инструменты в порядке их обнаружения.
CPUTool
Эту утилиту поисковик выдал первой. Очень простой инструмент, который позволяет установить ограничение сверху на потребление CPU для любого процесса по его Process ID. Также утилита умеет устанавливать ограничение при достижении заданного load-average.
Принцип работы
В официальном мануале есть немного информации о принципе работы и примерах использования.
Утилита распределяет процессорное время через механизм таймслайсов. Длительность таймслайса составляет 100 мс. Каждому процессу/группе процессов под управлением CPUTool дается возможность работать только в течение какой-то части таймслайса. Рабочая доля времени внутри него определяется переданным значением аргумента --cpu-limit.
В рамках одного таймслайса CPUTool отправляет процессу сигналы SIGSTOP и SIGCONT. Первый останавливает процесс, а второй — возобновляет.
Плюсы
- Простой и понятный инструмент.
- Может ограничивать потребление процессорного времени.
- Умеет учитывать загрузку системы и останавливать процесс, если нагрузка в системе больше заданного значения.
Минусы
- К каждому процессу добавляется еще и контролирующий процесс cputool. Сам процесс cputool может упасть, и никаких ограничений не останется.
- Постоянно шлет сигналы SIGCONT и SIGSTOP. Обработка большого количества сигналов может сильно нагрузить систему.
- SIGCONT может быть обработан приложением, из-за чего эта утилита подойдет не каждому приложению. Обычно заранее неизвестно, перехватывает ли приложение какие-то сигналы и как их обрабатывает. При использовании CPUTool придется помнить эту особенность.
Вывод
Утилита CPUTool отлично подойдет, когда нужно запустить пару приложений, которые не должны мешать друг другу. Контролировать виртуальные машины с помощью такого инструмента можно, но, какой будет эффект, неясно.
Этот вариант мы отбросили из-за минусов с большим количеством сигналов и необходимостью запускать процесс cputool и следить за ним.
cgroups
Второй находкой был механизм контрольных групп в ядре Linux.
Принцип работы
Механизм cgroups предоставляет возможность объединять процессы в группы. Группами можно управлять, и мониторить потребляемые ресурсы.
Интерфейс контрольных групп представляет собой псевдофайловую систему cgroupfs. То есть настройку работы можно вести через запись значений в специальные файлы. Группировка процессов реализована в коде ядра, а отслеживание потребления и ограничение ресурсов предоставляются набором подсистем — memory, CPU и другими.
Более подробно про cgroups можно прочитать в официальной документации. Вообще возможности cgroups намного шире, чем просто управление потреблением CPU, но мы сконцентрируемся на решении нашей задачи.
Контрольные группы содержат несколько частей, которые вместе дают возможность квотировать CPU у процессов, — Freezer и CPU controller.
Freezer
Для остановки/возобновления работы процесса есть Freezer. Эта подсистема была введена, так как отправка сигналов SIGSTOP/SIGCONT — ненадежный способ остановки и возобновления процесса (пруф).
Проблема с этими сигналами в том, что они видны процессу, в который их отправляют. Более того, сигнал SIGCONT может быть перехвачен и кастомно обработан. Таким образом, остановка/возобновление может сломать приложение, которое перехватывает сигналы.
Подсистема Freezer, в свою очередь, использует внутренние механизмы ядра для остановки и возобновления процессов. Поэтому ее работа не видна процессу, на который он воздействует.
СPU controller
Для управления и мониторинга использования процессора в контрольных группах есть CPU controller. Он позволяет задавать параметры планировщика для группы процессов.
Как вариант, для ограничения процессов по потреблению CPU можно использовать два параметра — cpu.cfs_period_us и cpu.cfs_quota_us. Первый параметр задает период времени, после которого должно произойти перераспределение ресурсов — таймслайс. Второй параметр — cpu.cfs_quota_us — задает доступное для работы время в рамках этого периода. Все показатели времени задаются в микросекундах (на это намекает суффикс _us, но лучше уточнить).
Еще можно использовать параметр cpu.shares.
В этом файле для каждой группы процессов содержится ее вес, который определяет, какую долю процессорного времени может использовать группа. По умолчанию этот параметр равен 1024 единицам для каждой группы. Самое интересное, что реальный, действующий вес определяется исходя из суммы всех весов на текущем уровне иерархии (завернул нормально).
Более наглядно показать особенности работы cpu.shares можно с помощью такой иллюстрации:
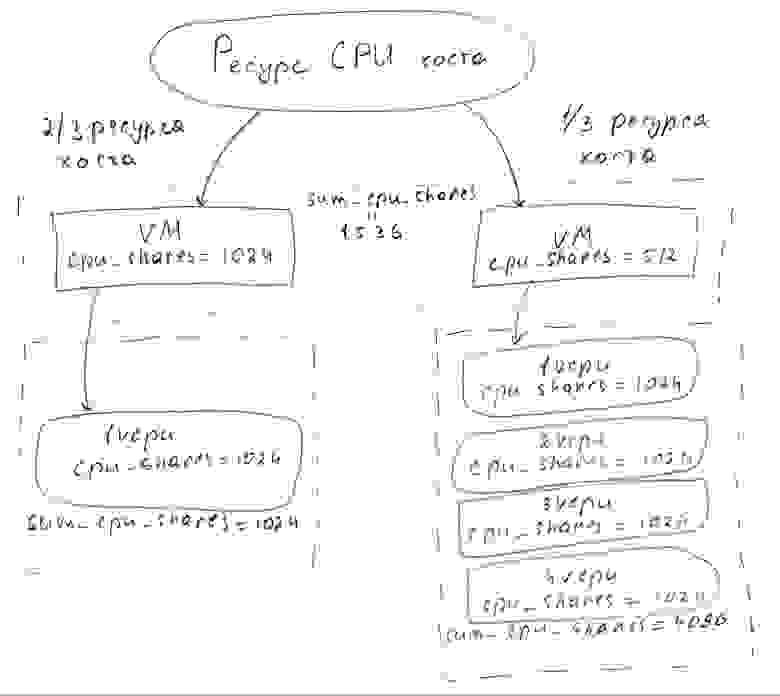
Здесь такое поведение, что левой виртуальной машине будет доступно 2/3 ресурсов хоста, а правой — только ⅓. При этом доступный ресурс по CPU для правой виртуальной машины будет делиться поровну между каждым ее ядром.
Действующее значение cpu_shares ядер правой машины будет равно 512/4 = 128, или 8,3% от общего времени. Действующее значение cpu_shares ядра левой машины будет равно 1024, или 66% общего времени.
Поддержка в OpenStack Nova
Облако Selectel построено на базе OpenStack. Поэтому при поиске инструмента мы также оценивали затраты на внедрение в OpenStack.
Нам повезло, и в проекте OpenStack уже предусмотрели использование контрольных групп (дока, дока2). По ходу тестов мы выяснили, что в Nova указанное значение cpu.shares применяется на всю виртуальную машину (пруф). Ну выяснили и выяснили, в чем проблема-то? А проблему будет проще показать на примере.
Посмотрим внимательнее на кусок кода, в котором происходит установка значения cpu_shares для виртуальной машины. На строке 18 видно, что по умолчанию значение cpu_shares для виртуалки масштабируется в зависимости от количества ядер.
Однако далее, в цикле на 22 строке, выполняется проверка наличия кастомного значения cpu_shares в характеристиках ВМ. Если проверка проходит успешно, то есть мы указали свое значение для cpu_shares, указанное значение не масштабируется на количество ядер и устанавливается как есть (строка 23).

Подобное поведение не очень удобно для использования из коробки.
Мы смогли придумать пару вариантов обхода такого поведения:
- Подправить код так, чтобы переданное значение cpu_shares тоже масштабировалось
- Заранее учитывать количество ядер и сразу задавать правильное значение cpu_shares в конфигурации виртуальной машины
Первый вариант предлагает нам гибкость. Хочешь виртуалку с 73%? Пожалуйста. Просто укажи в cpu_shares вес 1024×0.73 и округли до целого. Profit!
Второй же вариант ближе тем, кто любит говорить «Работает — не трогай». Можно же просто держать в голове эту особенность и не писать никакого кода. Просто напиши в конфигурацию нужный вес и все. Profit!
Плюсы
- Нативное решение для ОС Linux.
- Работает незаметно для процесса, которым управляет.
- Поддерживается в OpenStack из коробки.
- Не ограничивает виртуальную машину, если есть свободные ресурсы. Следовательно, виртуалка может работать без ограничений, если есть свободный ресурс.
Минусы
- Нужно учитывать иерархичность cpu.shares при использовании.
- Может показаться, что, установив веса для всех vCPU, мы добьемся успеха по ограничению потребления CPU виртуальной машиной. Однако такой трюк сработает не так, как ожидается. На самом деле сработает, только если указать корректное значение cpu_shares для всей виртуальной машины.
- В случае с OpenStack нужно проделать работу для масштабирования значения cpu_shares. Согласен, правка кода небольшая, но нужно будет хорошенько протестировать это решение.
Вывод
Очень классное решение, которое подойдет для управления большим числом процессов или виртуальных машин. Хорошо масштабируется и автоматизируется.
Ограничиваем «на коленке»
Есть еще более простое решение без использования дополнительного ПО.
Принцип работы

В самом простом варианте можно попробовать запустить больше виртуальных ядер, чем «железных» на хосте. Так, если на хосте шесть CPU, то, запустив шесть виртуальных машин с 2 vCPU, можно считать, что каждое vCPU будет иметь в распоряжении только 0,5 CPU.
В таком подходе отсутствует гибкость в виде установки разных ограничений разным виртуальным машинам. Но это лучше жесткого ограничения на потребление сверху, как в случае с --cpu-limit.
Этот способ хорошо масштабируется за счет добавления хостов. Виртуальные машины не будут ограничены в принципе и будут испытывать steal time, только когда всем резко потребуется процессорное время.
Плюсы
- Не требует дополнительной разработки.
- Простое в понимании.
- Точно так же, как с cgroups, у виртуалки будет возможность занимать больше процессорного времени, чем заявлено, если будет свободный ресурс.
Минусы
- Нужно следить, сколько виртуальных машин запущено на хосте и не превышать заданное соотношение CPU/vCPU. При нарушении соотношения мы рискуем получить виртуалки с меньшим гарантированным процентом, чем заявлено.
- Масштабируется только добавлением новых хостов. Так как виртуальные машины по сути ограничены только параметрами железа, на котором они запущены. Если виртуальную машину, ограниченную через cgroups, можно будет запустить где угодно, то в текущем решении только на специальных хостах.
Вывод
Такой способ организации процентных инстансов удобен тем, что очень прост в реализации и понимании. Несмотря на потерю гибкости в выборе гарантированной доли CPU, можно быстро проверить востребованность подобных виртуальных машин.
Какой путь выбрали мы и почему
Иииии… мы приняли решение использовать ограничение «на коленке».

Почему?
Потому что для начала нам нужно было проверить гипотезу ценности услуги — понять, нужны ли вообще кому-то дешевые серверы с частичной мощностью ядра.
В разработке облачной платформы Selectel мы всегда стараемся найти баланс между профитом и трудозатратами. То есть можно было бы угореть и сделать контрольные группы, наткнувшись по пути на парочку ограничений. Внести патч в OpenStack Nova либо заранее заложить в flavor нужное значение shares.
Но все это было бы нерационально без подтверждения востребованности процентные инстансов у клиентов. Мы сделаем и будем молодцами, а время, потраченное на разработку, не окупится.
Поэтому на данный момент процентные инстансы в Selectel — это виртуальные машины, запущенные на хостах с определенным соотношением CPU/vCPU.
Визуально это выглядит как на картинке:

К слову, благодаря такому решению у Shared Line есть ощутимый профит. В таком варианте нет явного ограничения сверху на потребление CPU. Виртуалка может потреблять хоть 100% CPU до тех пор, пока не возникнет борьба за ресурс. В случае, когда есть конкуренция за ресурсы, всем будет выдано одинаковое количество процессорного времени, но ни в коем случае не меньше выбранного процента производительности — он гарантирован.
Планы
В целом, видно, что интерес к более дешевым виртуальным машинам есть. В пике ими пользовались до 400 клиентов, но какого-то постоянного роста пользователей месяц к месяцу не наблюдается. К слову, Shared Line сейчас можно арендовать в Москве, Санкт-Петербурге и регионе «Амстердам».
Кстати, если у вас есть мысли, почему вам такой сервер не подойдет, пишите в комментариях!
В дальнейшем, конечно же, мы хотим заехать на использование контрольных групп. Да, в OpenStack можно задать cpu.shares и cpu.cfs_period_us с cpu.cfs_quota_us из коробки. Но для грамотного использования нужно либо патчить OpenStack Nova, либо иначе адаптировать решение.
Переход на контрольные группы чуть облегчит архитектуру решения. Так, например, сейчас под Shared Line у нас выделены отдельные хосты. Рабочая схема, но при ней мы даем гибкость клиентам и отчасти лишаем гибкости себя.
Контрольные группы дадут следующие преимущества:
- можно будет помещать процентные виртуальные машины на любой хост, рядом с любыми другими,
- не нужно будет выделять отдельные хосты под линейку,
- откроется путь к более гибким конфигурациям — например, к 83% ядра (ну, а вдруг именно столько вам нужно).
На этом все. Жду в комментариях знающих людей, которые прочитают текст, прежде чем заявлять, что мы пошли слишком легким путем и вообще — атата, Selectel;)
