Какая связь между червем длиной около миллиметра и OpenCL!?
 Недавно на хабре была статья про проект OpenWorm. Проект использует OpenCL для расчета гидродинамики сглаженных частиц как на CPU, так и на GPU. Среди исследователей/разработчиков есть наши соотечественники Андрей Пальянов и Сергей Хайрулин из сибирского отделения Российской академии наук.Судя по публикациям, они участвовали в проекте NeuroML и выполняли оптимизацию алгоритма PCI-SPH для GPGPU. А узнал о том, что этот проект собирается использовать OpenCL, в марте прошлого года от их коллеги по проекту Matteo Cantarelli.
Недавно на хабре была статья про проект OpenWorm. Проект использует OpenCL для расчета гидродинамики сглаженных частиц как на CPU, так и на GPU. Среди исследователей/разработчиков есть наши соотечественники Андрей Пальянов и Сергей Хайрулин из сибирского отделения Российской академии наук.Судя по публикациям, они участвовали в проекте NeuroML и выполняли оптимизацию алгоритма PCI-SPH для GPGPU. А узнал о том, что этот проект собирается использовать OpenCL, в марте прошлого года от их коллеги по проекту Matteo Cantarelli.
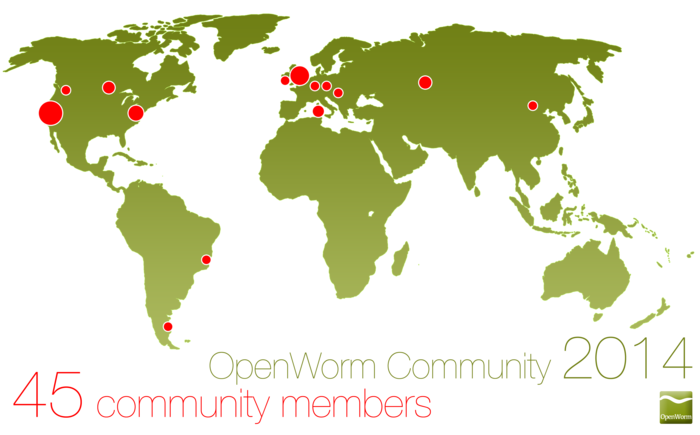
География комьюнити openworm по данным сайта:
Ситуация же с популярностью и использованием OpenCL в России странная. Судя по статистике моего блога и ссылкам на него с форума сайта консорциума khronos.org и документации JavaCL, у нас в стране тема GPGPU не популярна. Возможно, не очень репрезентативно, но рейтинг популярности разработки на OpenCL по странам (на основе моего блога и без учета последнего хабр эффекта):
1. United States2. Germany3. Ukraine4. United Kingdom5. Poland6. Latvia7. France8. Canada9. China10. Russia
Печально… При том что OpenCL — это не только GPU, CPU, но FPGA. Как вы считаете, почему сложилась такая ситуация?
Напоследок новость для тех, кому интересно. Состоялся релиз новой версии AMD APP SDK 3.0 Beta для OpenCL 2.0. Которая также включает в себя библиотеку шаблонов C++ «Bolt» и оптимизированную версию OpenCV (Open Computer Vision) для OpenCL.
Примеры в архиве SDK позволят разобраться с появившимися в 2.0 версии фичами: SVM Coarse Grain, Pipe, New Workgroup Built-in APIs, Image Read and Write, Program Scope Variable, Generic Address Space, Shared Virtual Memory pointer with offset, SVM Fine Grain Buffer, C++ 11 Atomics, Device-side Enqueue, Depth Image.
Подробное описание примеров в блоге AMD и SDK.
P.S. Предупреждая критику, я не евангелист OpenCL. На данный момент моя работа не связана с оптимизацией ПО на GPGPU и все оптимизации что я делаю сейчас — это попытка «выжать» большую производительность из кластеров Coherence, его CacheStore и Oracle database через тюнинг параметров jdbc драйвера, декомпиляция изучение oracle jdbc/coherence и прочий энтерпрайз где время передачи данных по сети и время дискового I/O преобладают над временем вычислений. Несмотря на это, слежу за новостями GPGPU и планирую вернуться к оптимизации алгоритма на OpenCL в своем проекте.
