Как выбрать In-memory NoSQL базу данных с умом. Тестируем производительность

Дмитрий Калугин-Балашов (Mail.RU)
Доклад у меня по базам данных In-Memory NoSQL. Кто знает, что такое In-Memory NoSQL база данных? Поднимите руки, пожалуйста… Как вам не стыдно? Зал по базам данных, и только половина знает, что это такое.
Если вы выбираете базу данных, ориентируясь на ее популярность, то так делать не надо. Как, вообще, выбираем базы данных?
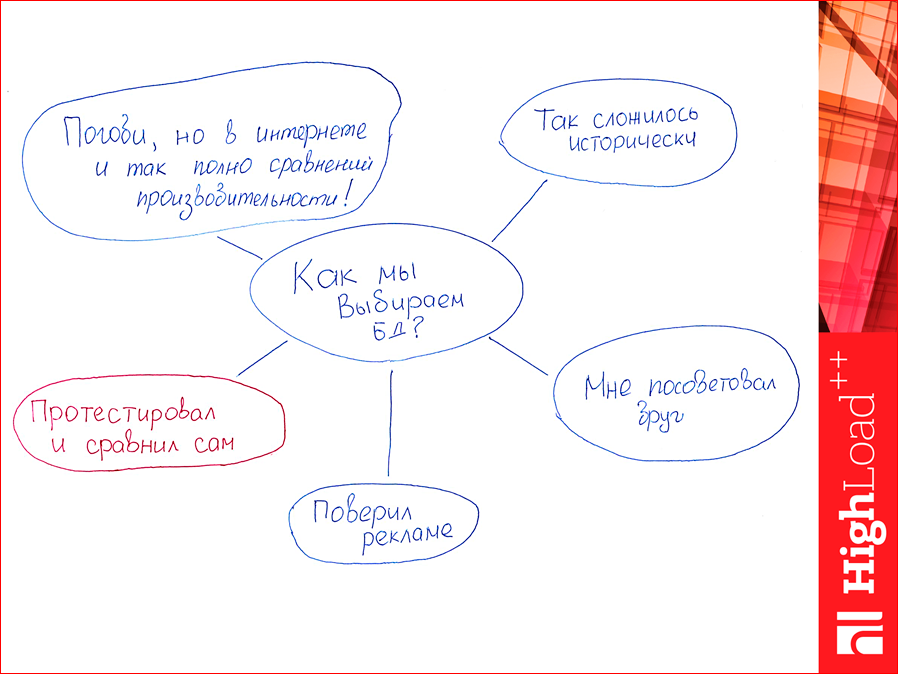
Первый вариант — популярность. Так сложилось исторически, т.е. вы пришли на работу, и у вас там такая база данных, вы ее не выбирали, вы просто хотите, например, ее сменить.
Второй вариант — мне посоветовал друг. Этот вариант тоже достаточно популярный.
Третий вариант — поверил рекламе. Это тоже связанно с популярностью, прочитали какую-нибудь статью: «О, Redis — классная база данных, давайте его использовать».
А теперь у меня такой вопрос: кто из вас считает себя инженером? Т.е. вы закончили вуз и имеете инженерное образование. Я предлагаю использовать инженерный подход к выбору базы данных. Я предлагаю их тестировать. Самостоятельно. Вы можете разумно мне возразить, что в Интернете уже полно тестирований баз данных, и вы можете просто посмотреть, как люди тестировали. Так делать тоже не надо, потому что вы увидите, что все очень сильно зависит от конкретной ситуации. Т.е. вы можете посмотреть, как протестирована база данных, запустить у себя и не получить то, что было у того человека. Т.е. вам надо тестировать на своей нагрузке, на своих машинах — виртуальных или невиртуальных, на своем окружении. Поэтому весь мой доклад будет про инженерный подход к выбору баз данных.
Смотрите, этот человечек — это вы. Вы считаете себя инженером. Т.е. этот человечек крутой.
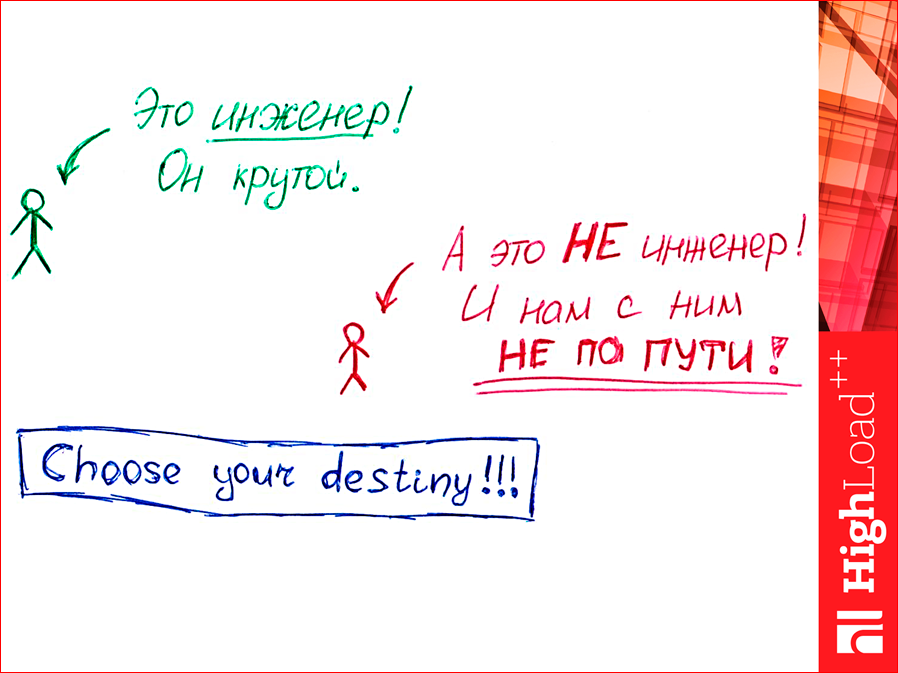
А есть человечек, который не инженер, который может быть повелся на рекламу, может быть поверил другу, или просто выбрал Redis, потому что все выбирают его. Так вот, нам с ним не по пути. И поэтому мы будем выбирать зеленого человечка, будем действовать как инженеры.
Теперь вопрос: что мы будем тестировать? Как думаете, что можно тестировать? Какое количество данных можно вместить?
Смотрите, есть два параметра — throughput и latency.
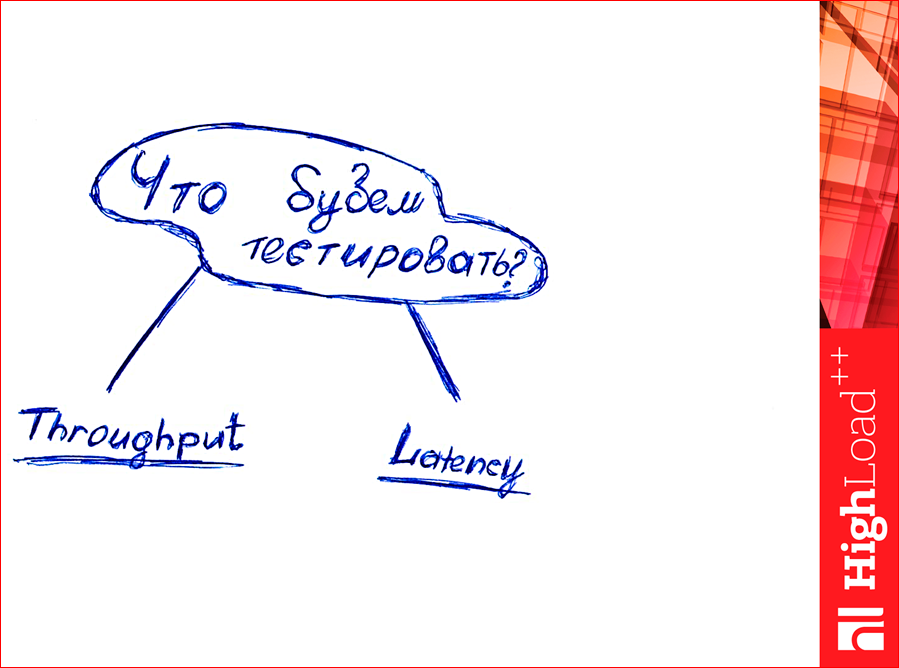
Поднимите руки, кто понимает различие между этими параметрами? Где-то 10% слушателей в зале. Тогда я объясню. Кто ходил в такой магазин когда-нибудь?

Есть курящие? Вы куда за сигаретами ходите, в Ашан или поближе? Поближе, наверное, да? Так вот, этот магазин — он особенный, у него очень маленькая latency. Latency — это ожидаемое время, когда вы идете за сигаретами, например, между принятием решения и, собственно, как вы их получили. Т.е. вы поняли, что их надо купить, спустились во двор, зашли в магазин, взяли, подошли к кассам, купили, вернулись. Прошло 15 минут. Это ваше latency.
Throughput — это уже параметр магазина — сколько человек таких, как вы, он в единицу времени может пропустить. Т.е. в этом магазине обычно одна касса, с кучей народу, и там проходит один человек в две минуты.

Т.е. достаточно медленно. С одной стороны, для нас это довольно быстро, но если таких, как мы, будет очень много, то магазин захлебнется, будут большие очереди и ничего хорошего из этого не выйдет. Если мы перегрузим этот магазинчик, то у нас еще и latency вырастет, потому что придется всем стоять в очередях.
Есть другая сторона, обратн ая сторона Луны. Выглядит вот так:

Кто был в Ашане? Все были. Отлично. Видели, как он устроен? Там касс много. И они работают параллельно, в одно и то же время.

Таким образом, в один момент Ашан пропускает через себя больше людей. Но если вы захотите что-то купить в Ашане, вам надо сперва сесть в машину, доехать куда-то за МКАД, припарковаться, выйти, взять тележку, проторчать там два часа, купить и приехать домой. Т.е. latency для вас будет очень большим, но throughput у этого магазина маленький.
Все поняли, что такое throughput и latency, если мы говорим о базах данных? Ожидаемое время исполнения запросов — это latency, а throughput — это сколько запросов в секунду мы способны обработать.
И еще один параметр, который надо тестировать — это memory footprint.
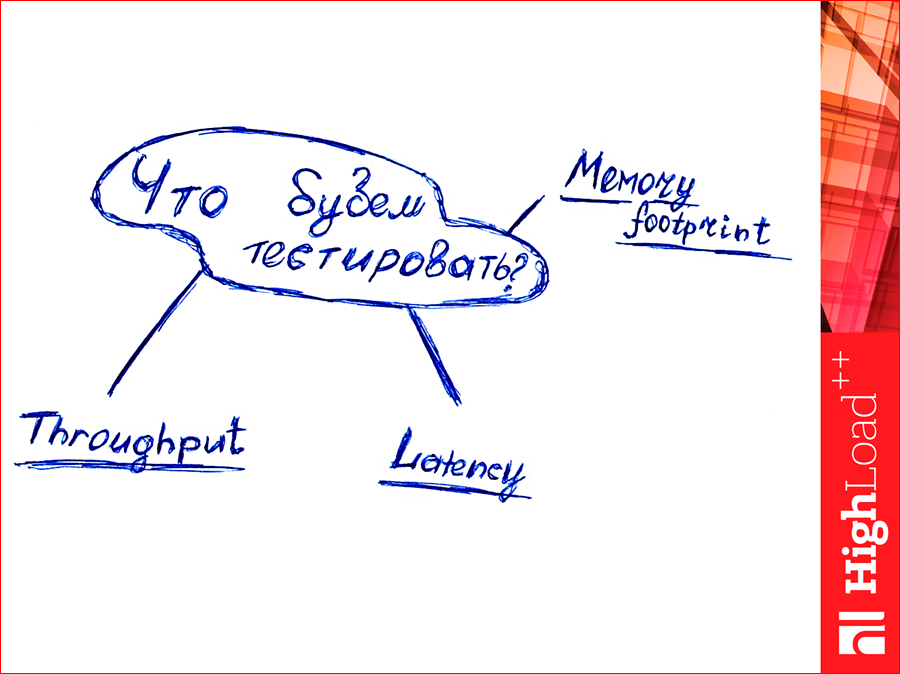
Знаете, как с английского «footprint» переводится? Отпечаток ноги. Такой вот.

Специально с утра обвел ногу жены, пока она спала, подписал, это memory footprint. Что же это такое? Если мы Гбайт чистых данных засунем в базу данных и посмотрим, сколько в СУБД наша сама программа в памяти занимает, то это будет не Гбайт, это будет больше. На сколько больше — это и есть величина memory footprint. Даже «во» сколько больше раз, т.е. сколько байт мы на 1 байт дополнительно расходуем. Это важный параметр, потому что он определяет, сколько нам надо покупать оперативной памяти. Т.е. это такой денежный параметр.
И как мы будем базы данных тестировать? Есть утилита YCSB — Yahoo! Cloud Serving Benchmark. По этой ссылочке есть ее клон:

Это мой репозиторий в github, там некоторые изменения, я про них расскажу.
Почему именно эту утилиту надо использовать?

- Во-первых, она является отраслевым стандартом, ему все доверяют, т.е. ею, вообще, тестируют NoSQL базы данных.
- Дальше, там очень легко написать свои профили нагрузок, т.е. если он у вас какой-то нестандартный профиль, то вы можете легко конфигурацию написать и
протестировать. - Там легко написать драйвера для других баз данных, там и так стандартных много, но если у вас что-то нестандартное, вы можете сами написать.
А почему ее не стоит использовать? Я нашел одну большую причину:
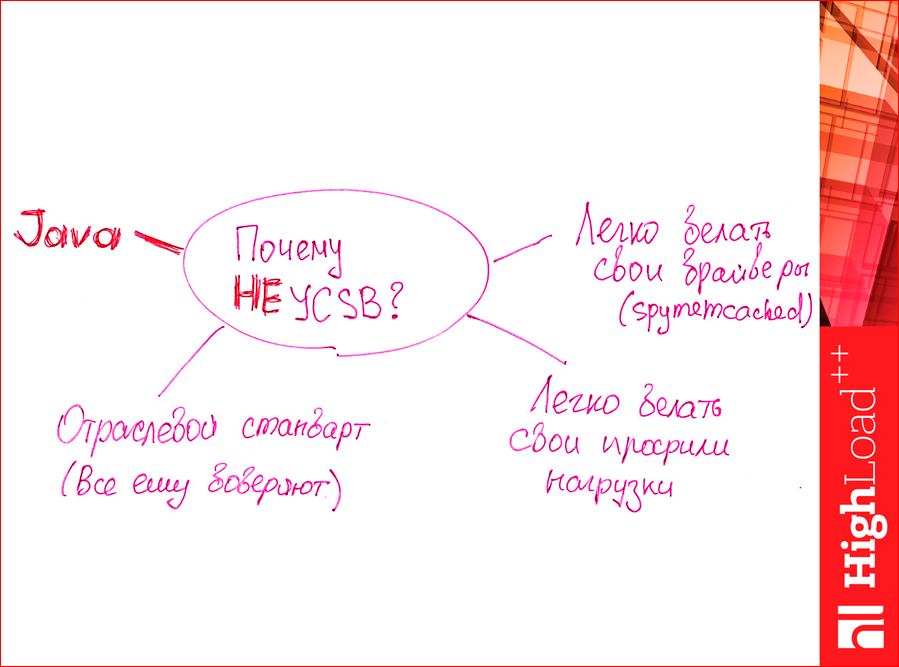
Те, кто любит Java, вы лучше всех, наверное, знаете, ее отрицательные стороны. Она тратит много ресурсов. И, как раз, Костя рассказывал про деньги, так именно Java съела мои деньги, потому что машину-тестер пришлось заказывать более мощную, чем если бы… Я думал, там чуть-чуть потребуется, а Java не влезает ни в память, и по CPU там много ядер требуется. Мне потребовалась более дорогая машинка, чтоб протестировать, поэтому это я записал в минус. Но это минус мой личный, может быть, вы миллионер, и Java вам не помешает в этом деле.
У этого YCSB есть стандартные workload«ы. Workload — это профиль нагрузки. Какие они есть? Их шесть стандартных видов:

A — это 50% запросов на чтение, 50% — на запись. Простой workload.
B — это 95% на чтение, 5% на update, на запись.
C — это 100% read-only.
Дальше идут более интересные.
D — это 95% на чтение, 5% на insert, но там одна специфика есть — он читает только то, что недавно вставлено. Это, например, вы в ВК пишете новость, написали, отправили — это insert. 5% insert. А ваши друзья, у вас их тонна, они начинают читать, F5 теребят, и нагрузка вот так создается. Т.е. такой профиль — это что-то вроде ленты новостей.
Профиль E — это тяжелые запросы типа scan. Это запрос по диапазону. 5% insert и 95% scan. Т.е. это когда у вас какой-то поиск происходит по куче данных, которые рядом не лежат.
И последний — это тоже интересный workload. Там 50% голых read«ов, а 50% такой композиции — сперва read, потом modify, потом write. Т.е. мы прочитали какой-то кусочек, изменили и записали. Довольно часто такая комбинация.
Мы можем очень легко написать любой слой. Там очень простые конфиги — в пять строчек, просто процентовку пишем и способ воздействия, например, если insert, то мы потом селектим самые свежие данные — это для workload D.
Итак, как написать свой драйвер? Потому что там не было драйвера memcached. Я понимаю, что многие memcached за базу данных, вообще, не считают. Что делаем?
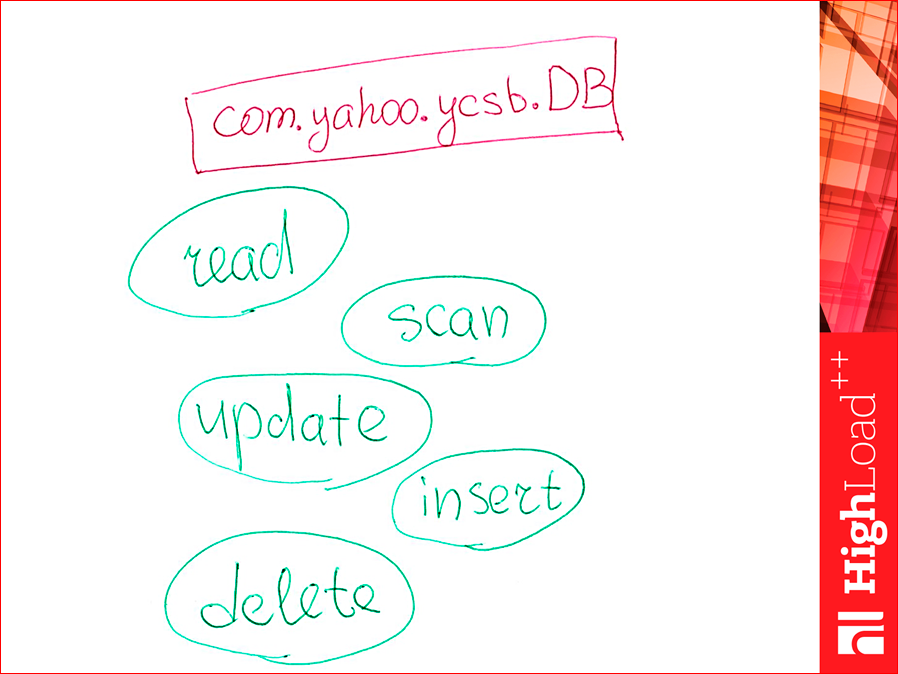
Есть такой java класс, можем от него отнаследоваться. Реализуем вот такие. Там их пять методов. Их просто реализуем. Если какой-то workload не подразумевает метод, например, у нас не было workload с методом delete, то мы можем его даже не реализовывать.
Будем строить такие графики:
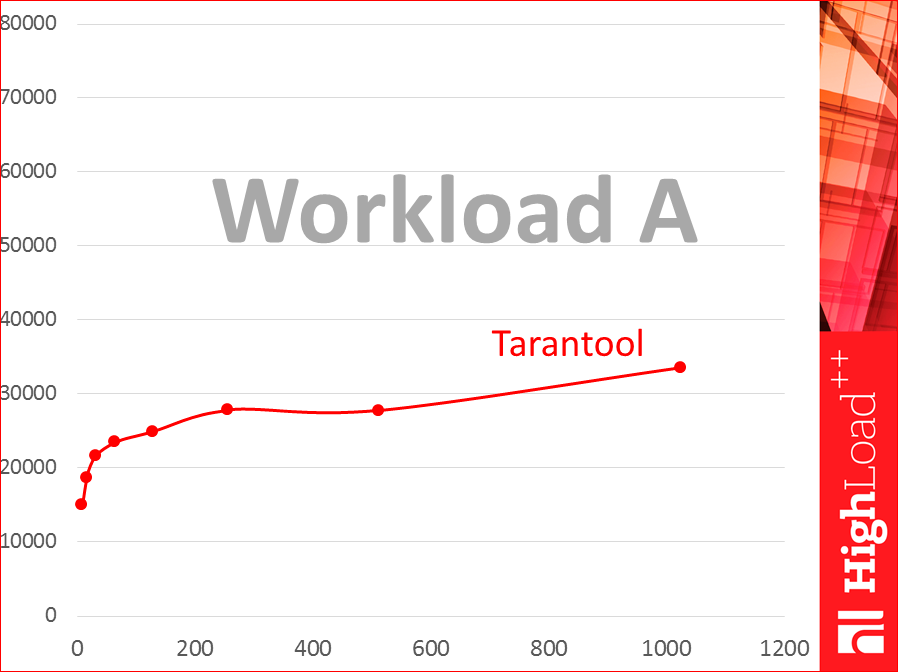
Смотрите, по горизонтали у нас число потоков, и мы точки указываем логарифмически — 8 потоков, 16, 32 и так до 1024. А по вертикали — график throughput — сколько запросов в секунду. Это слабая хилая виртуалка. Это база данных Tarantool. Это workload A.
Как мы будем тестировать?

Очень важно, чтобы машина-тестер и машина с базой данных находились в рамках одного датацентра и как можно ближе, чтобы исключить влияние сети на latency.
Почему нельзя тестировать на одной машине? Я протестировал. Видите, это один и тот же Tarantool на одной и той же машине. Зелененькая — это на одной машине, а красненькое — это на двух машинах. Это раздельно, это вместе.
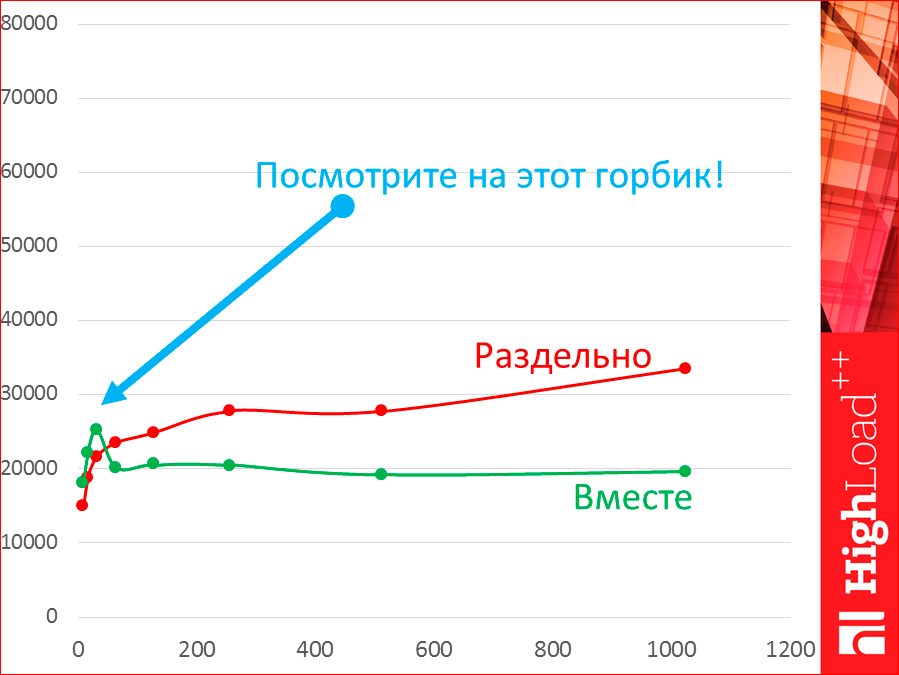
Давайте посмотрим на этот горбик. Пока у нас 8, 16, 32 потоков у нас действительно throughput выше на одной машине, но как только появляется больше, из двух потоков, у нас сам тестер начинает конкурировать за ресурсы с базой данных и начинает отнимать ресурсы, и мы обратно падаем.
Однако, с latency картина другая.
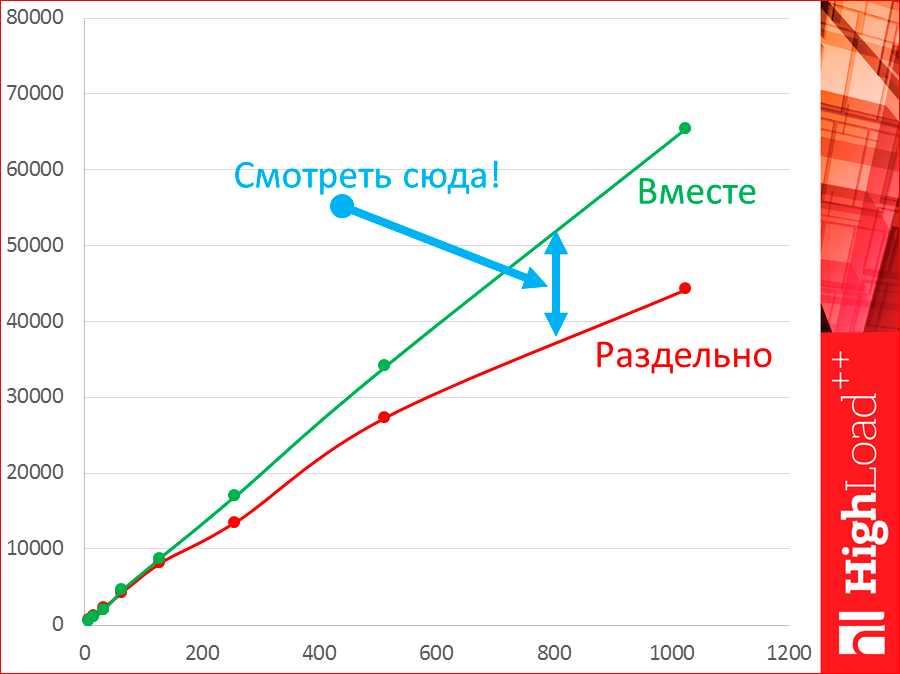
Latency, когда раздельно, ниже, потому что у нас есть какая-то сеть, которая latency и поедает, т.е. у нас такое расстояние. Когда мы тестируем вместе, у нас latency будет лучше.
Реальная история, эт, конечно, раздельное тестирование.

Дальше, все тесты были на очень хилых виртуалках, очень зажатые по ресурсам. Если у нас будет выделенный сервер, то у нас форма кривой сохранится, но у нас будет огромное расстояние.
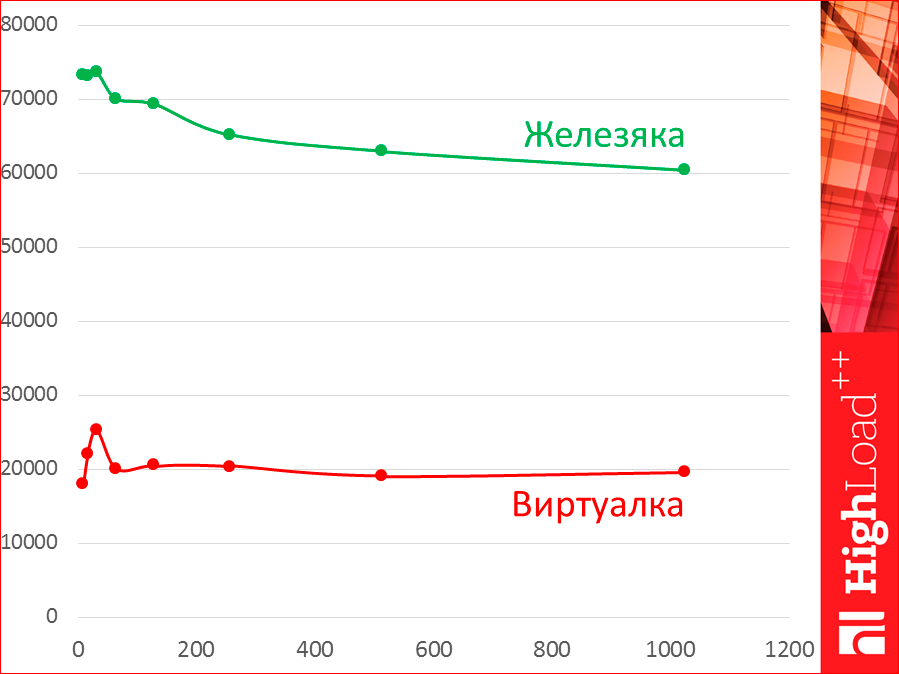
Это была Azure самая маленькая, которая можно, или почти самая маленькая, с парой ядер.
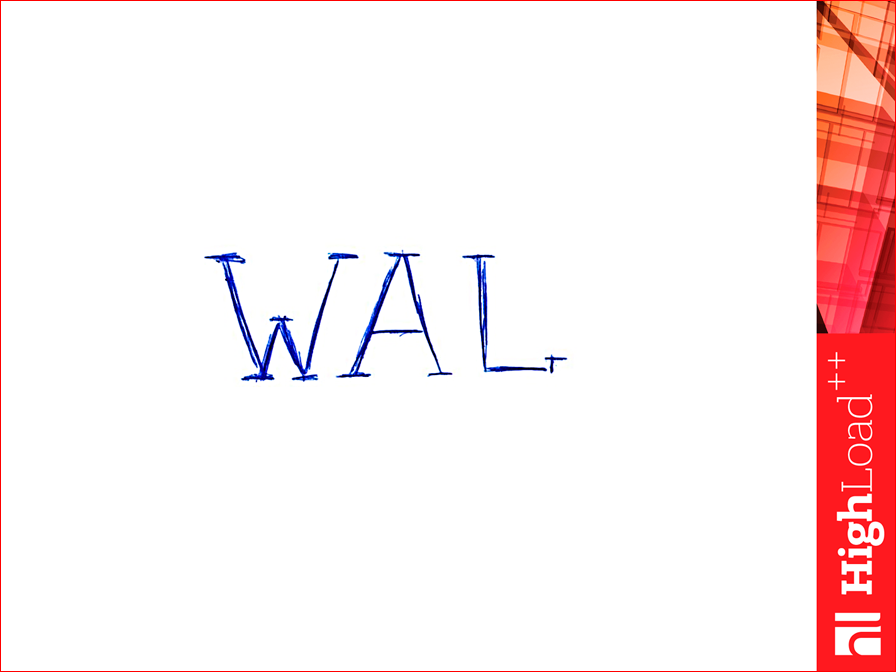
Знаете, что такое WAL? Это средство сохранения персистентности, Write-Ahead Log. Как это работает? Вы добавляете что-то в базу данных, это лог транзакции — туда в конец записывается, что вы сделали с базой данных, т.е. все изменения. Если у нас по какой-то причине выключили питание, просто перезагрузили, при старте мы это прочитываем — вдоль этот лог — и считываем все команды, восстанавливаем посмертное такое состояние.
С WAL оно работать будет по-другому. Эти все тесты были без WAL. Как оно будет работать с WAL, разницу покажу:
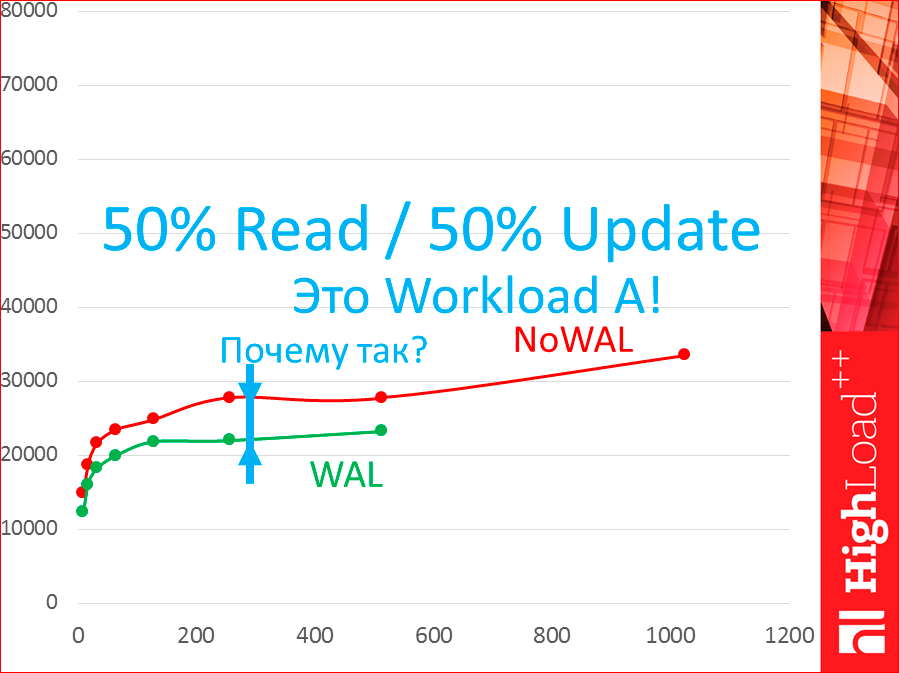
Видите, зеленая — это с WAL. Тут есть разница. Это без WAL, это с WAL. И тут есть. Почему разница? Это workload A, что значит, что 50% read, 50% update.
Если мы возьмем latency по read, смотрите, что будет:

Тут нет никакой разницы. Т.е. на чтение вообще WAL не влияет. Видите, как получилось?
А когда мы делаем update, разница есть:

Потому что нам приходится писать на диск и, разумеется, это замедляет все дело.

Виртуалки тоже бывают разные. Т.е. почему нельзя брать из Интернета готовые результаты тестов? Смотрите, это две виртуалки:
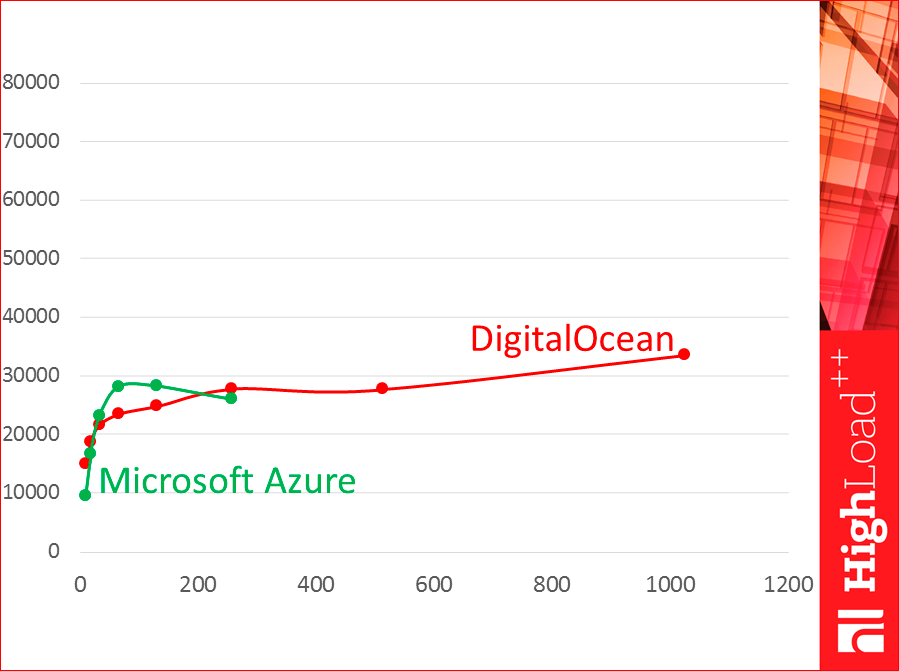
Это DigitalOcean, это Azure. Видите, они совсем по-разному работают.
И теперь — как мы, вообще, выбираем базу данных? У нас будет, если мы говорим про инженерный подход, несколько этапов. Первый этап — мы выбираем ее как-то качественно.
Я взял четыре базы данных. Первая — это редиска.

И я просто выписываю то, что важно для моего проекта, какие-то качественные значения, т.е. просто, что придет в голову, mind map рисую. Что есть у Redis? Есть Append Only Files — это WAL, как раз, т.е. мы можем какую-то персистентность хранить. Что еще есть? У него, что важно для проекта, например, развитое комьюнити. Если мне это важно, то я это вписываю себе. Что еще у Redis хорошего? У него текстовый протокол, но это нехорошее, т.е. оно выписано как минус. Обычно текстовые протоколы медленнее, чем бинарные. Это хорошо видно на примере memcached, где есть и такой, и такой протоколы, и бинарный быстрее. И есть хранимые процедуры, которые часто в бизнес-логике мы пишем с хранимыми процедурами, поэтому они есть.
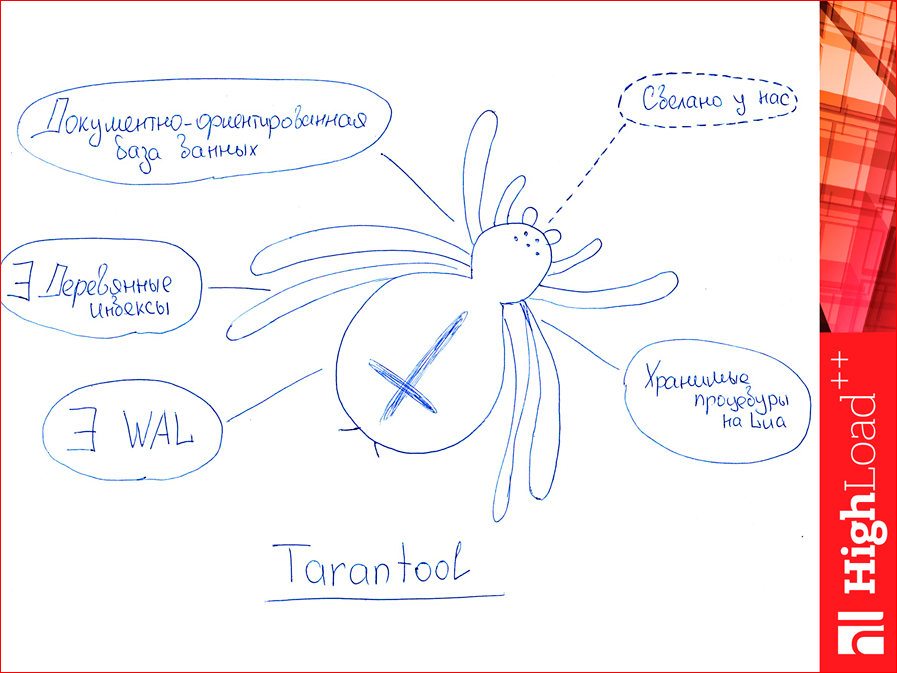
Tarantool. Кто, вообще, пользуется Tarantool? Немного в зале. Первое, Tarantool — это документно-ориентированная база данных, такая настоящая. Основные ее конкуренты — это key value. Во-вторых, есть деревянные индексы (или древесные? B-дерево, бинарное дерево — это оно и есть, в общем-то, это жаргон такой). Еще есть WAL в Tarantool, т.е. может персистентность иметь. Там еще и снепшоты есть. Есть хранимые процедуры на Lua, их тоже можно сравнивать. Здесь у меня тестов не будет, но их можно сравнивать с тем же Redis, получаются весьма интересные результаты. И еще один кусочек был только для меня, для вас это, скорее, не так, но Tarantool был сделан у нас, в Mail.ru, и если у меня какие-то вопросы (т.е. это то же самое, что комьюнити Redis), а здесь могу прийти к Косте Осипову и спросить: «А что это такое?». Поэтому это я себе выписал в плюсик. Специально пунктиром.
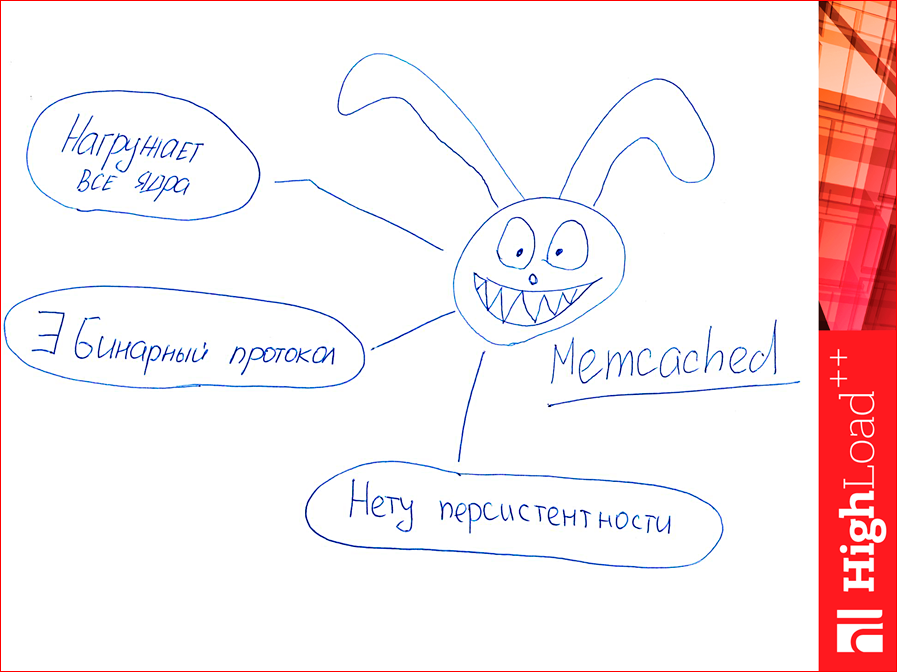
Дальше, Memcached. Знаете, откуда заяц? На главной странице Memcached такие вот зайцы есть. Memcached, в отличие от предыдущих двух, нагружает все ядра, он имеет бинарный протокол, т.е. по старинке использует текстовый, но еще у него есть бинарный, который быстрее. И еще у него нет персистентности, если мы упали, мы все потеряли. Т.е. можно как кэш использовать, как что-то иное — нельзя.
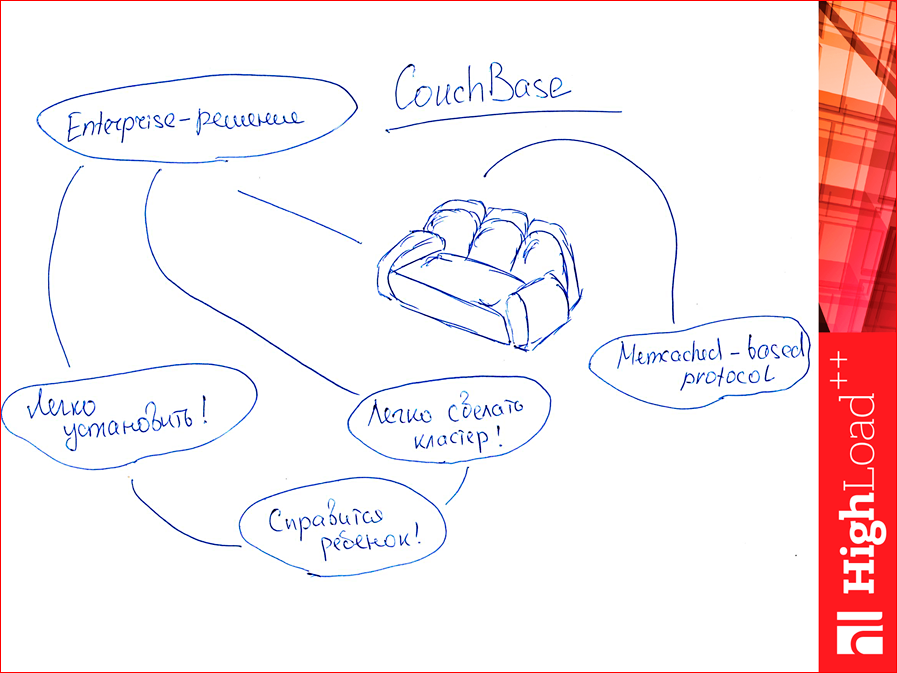
И есть CouchBase. Почему, вообще, CouchBase в этой подборке? Он немного отличается. Он является полноценным enterprise-решением. Настолько полноценным, что его очень легко устанавливать. Настолько легко, что справится ребенок. Более того, можно кластер сделать очень легко. И тоже ребенок справится. Т.е. это на уровне пары кликов мыши. Это его сильно отличает от предыдущих баз данных. И у него еще memcached-протокол как у memcached, ну, очень похож, поэтому можно один и тот же драйвер использовать, и нам грех не протестировать его, этот CouchBase, поэтому мы его взяли в тест.

И давайте тестировать по Throughput. Что у нас получилось? Получилась вот такая картинка:

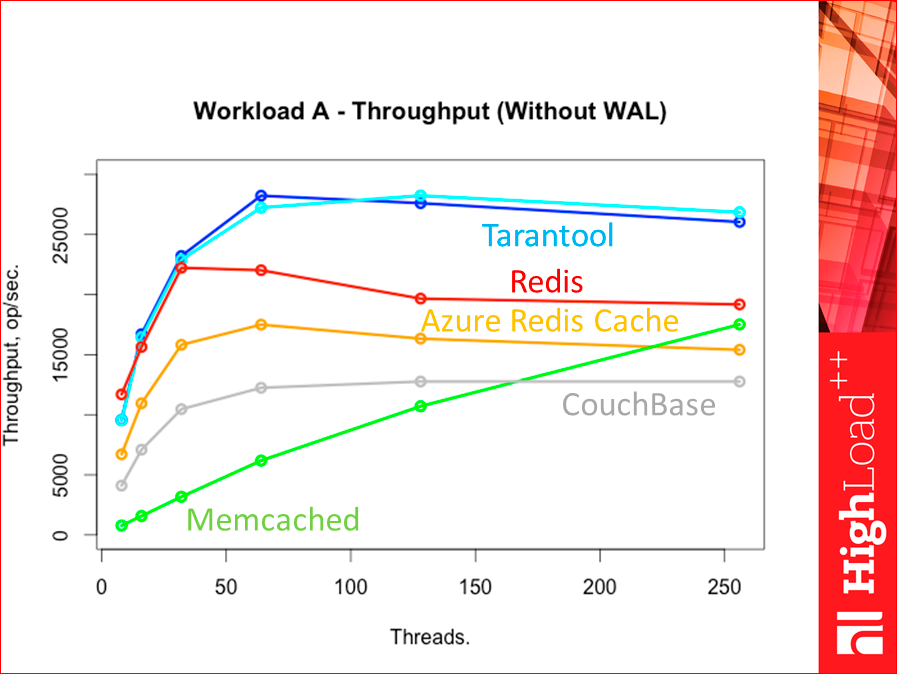
Синий цвет — это база данных Tarantool. Темно-синий — это hash-индексы, светло-синий — это tree-индексы. Красный у нас Redis. Оранжевый, вообще говоря, тоже Redis, но особенный, он называется Azure Redis Cache. Это сервис от Microsoft. Он облачный, его можно установить в том же датацентре, что и вашу тестовую виртуалку, поэтому можно так протестить. Серенькое у нас CouchBase. И зелененькое — Memcached. Смотрите, как memcached интересно пошел. Есть гипотеза, потому что он все ядра нагружает, то он потолка позже достигает, но она не проверена пока.
Если мы меняем Workload«ы на всех, то картинка особо не меняется.
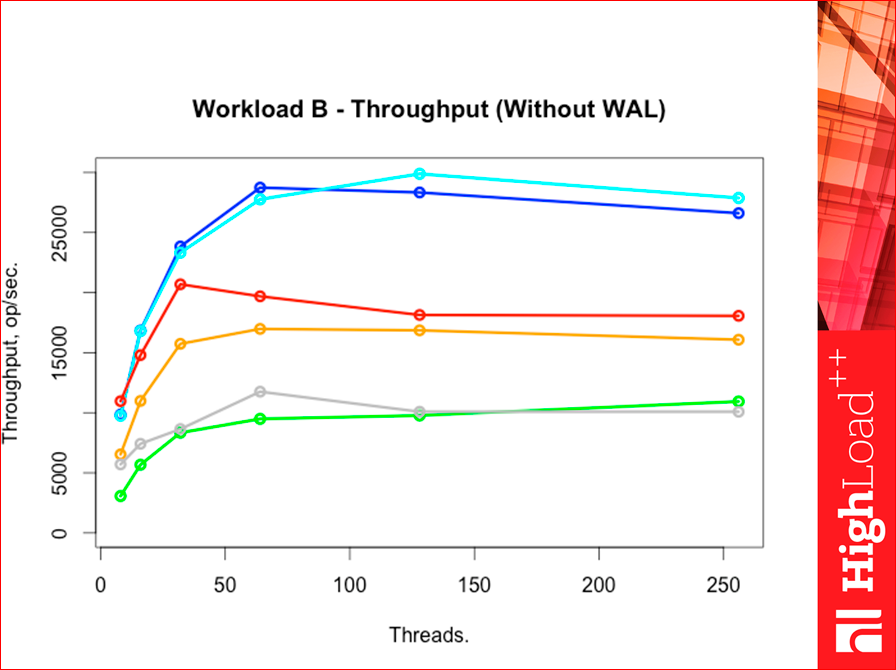
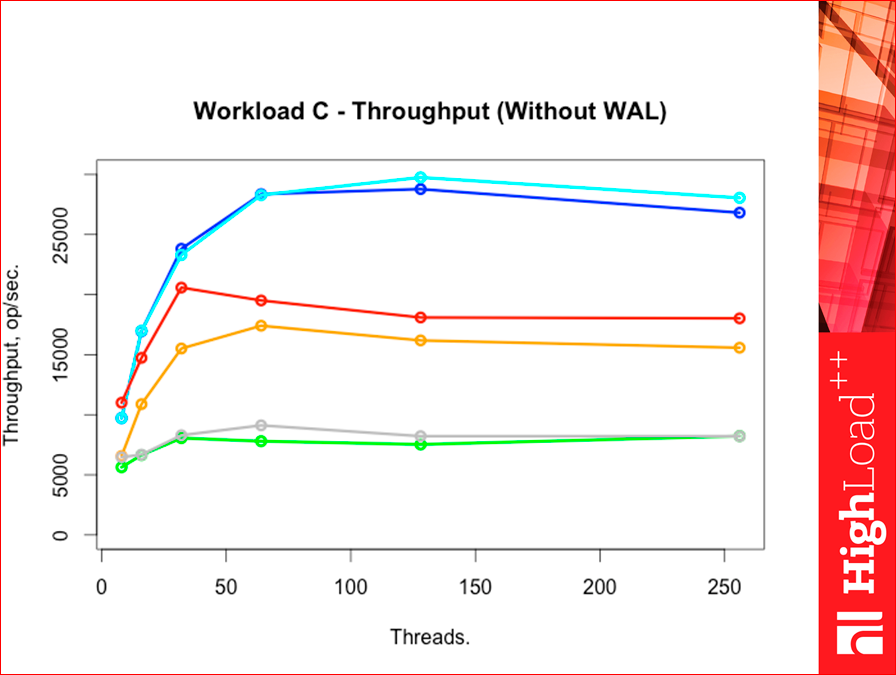
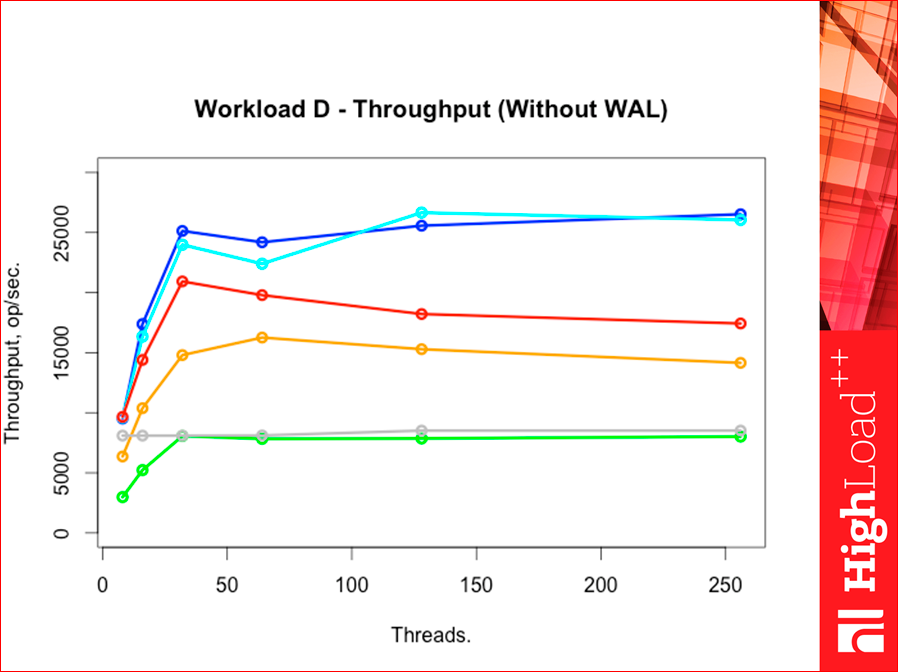
Workload F — это тяжелый workload.
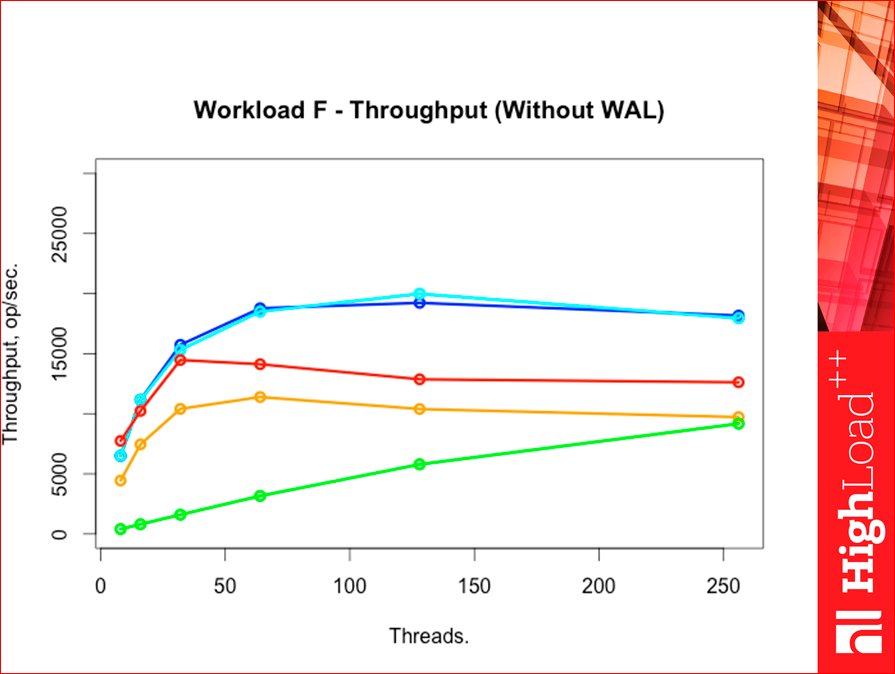
Такая вот картинка. Tarantool по throughput сильно выше оказался всех конкурентов, прямо прилично.

Если тестировать с WAL, что будет?
Это наша картинка без WAL:
И теперь мы добавляем WAL:
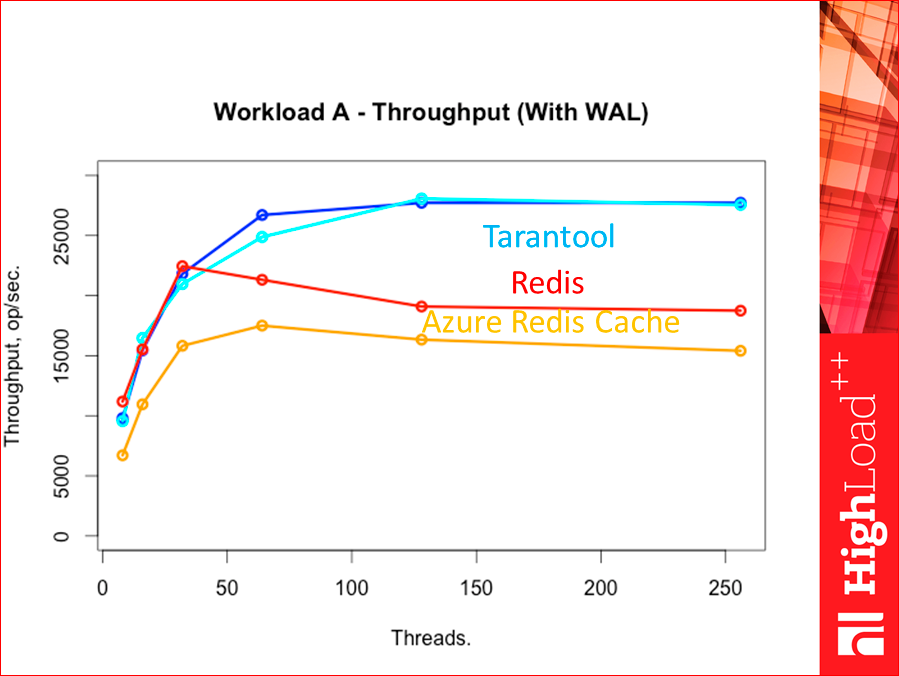
В принципе чуть-чуть понизилась, но ничего не меняется. Tarantool и Redis — основная конкуренция, такая картинка выходит. CouchBase и Memcached — они сильно ниже, но у них WAL нет. У CouchBase есть, но не тестировал еще, у Memcached нет.

По поводу latency. Эта утилита Yahoo!, она latency по всем типам команд считает отдельно. И Read latency так вот выглядит:
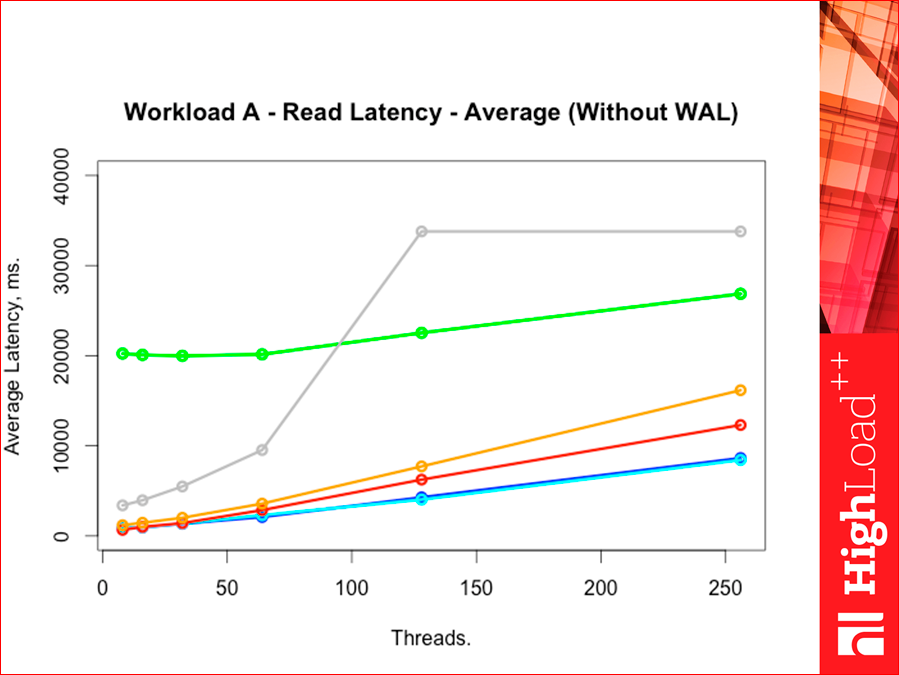
И смотрите, latency чем ниже, тем лучше. Т.е. если throughput мы смотрели вверх, то тут смотреть надо вниз. Цвета те же самые, Tarantool ниже, потом Redis. Это latency средний.

Yahoo! уже дает две перцентили из коробки, но можно пропатчить, он гистограммы умеет строить, можно любую перцентиль сделать, он дает 95-ую.
И смотрите вот сюда:
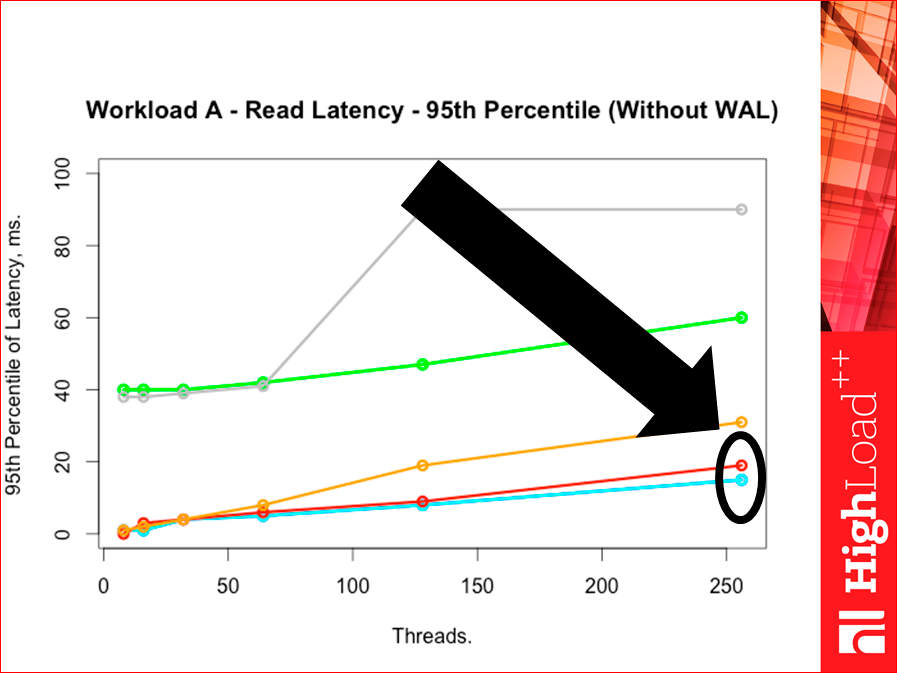
У нас Redis чуть-чуть хуже Tarantool на 95-ой перцентили. А вот на 99-ой наоборот:

Т.е. они очень близки, но они меняются местами на 95-ой перцентили. Тут никакой погрешности, тут точные данные. Здесь число запросов было 5 млн. запросов, и перцентиль все эти данные построил на 5 млн. запросов на 2-х млн. записей.

Если у нас Upadate будут (у нас workload A до сих пор), то, что будет:
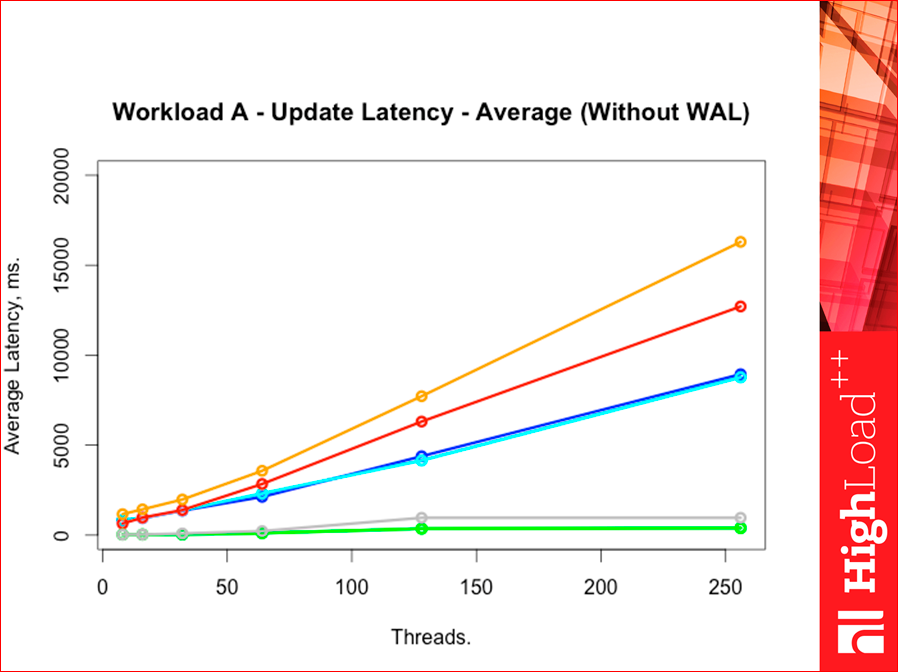
Average у нас вот такой будет. Видите, где Memcached оказался, интересно как.
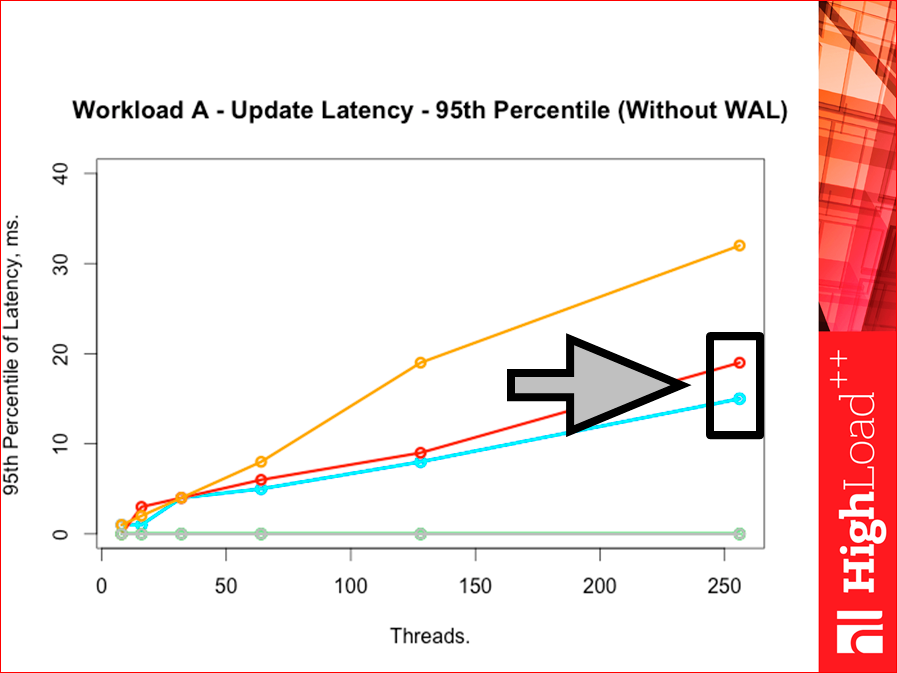
А вот 95-ая перцентиль, и Tarantool опять лучше:
Но, когда мы идем в 99-ую перцентиль, тут опять лучше Redis, но тут уже расстояние между ними сильнее:
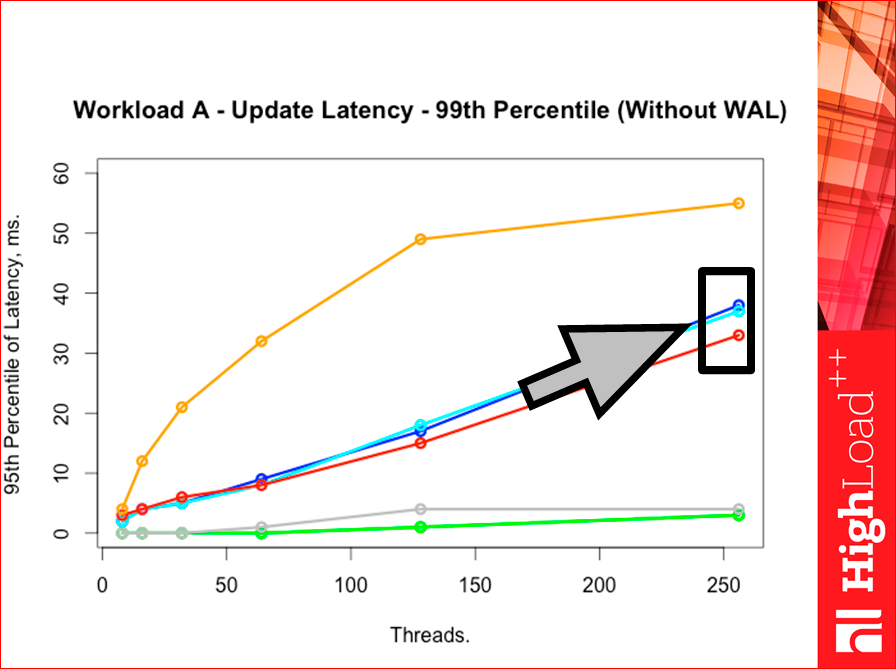
Почему так, что это означает? У Tarantool очень много быстрых запросов, но есть хвостик медленных запросов, а у Redis все запросы больше в серединке, т.е. его гистограмма чуть-чуть правее уходит. У Tarantool два «горба», т.е. сперва быстрые запросы, много их — 95%, а потом идем дальше и много медленных запросов, где-то после 99-ой перцентили уходит за Redis. А у Redis один «горб» в середине. И если построить гистограммы, Yahoo! тест умеет их строить, то мы это увидим. Единственное, если там их будете строить сами, то в логарифмической шкале по Х надо строить, иначе ничего не увидите.

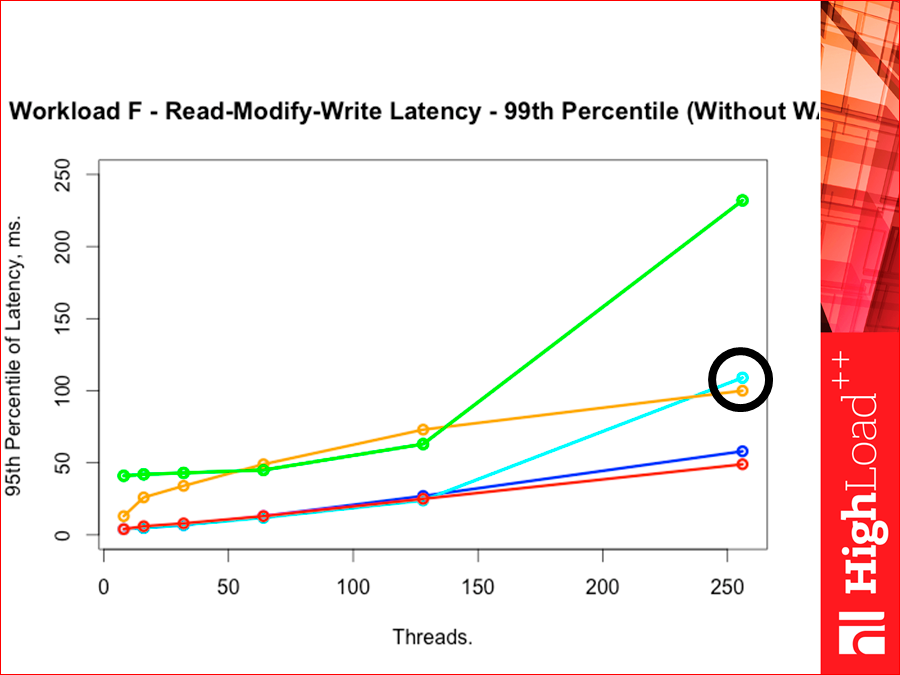
Есть такая интересная команда Read-Modify-Write. Это workload F.Т. е. прочитать-изменить-записать. Это тяжелая команда, потому что там throughput зависит очень сильно от latency, потому что мы должны дождаться данных от ридеров, чтобы пропустить запрос через себя.
Смотрите, там выходит картинка такая вот:

Т.е. Tarantool по latency сильно ниже. И смотрите, тут очень высоко ушел облачный наш Redis.
Если у нас 95-ая перцентиль, Redis красненький прижался к Tarantool, облачный с memcached убежали:
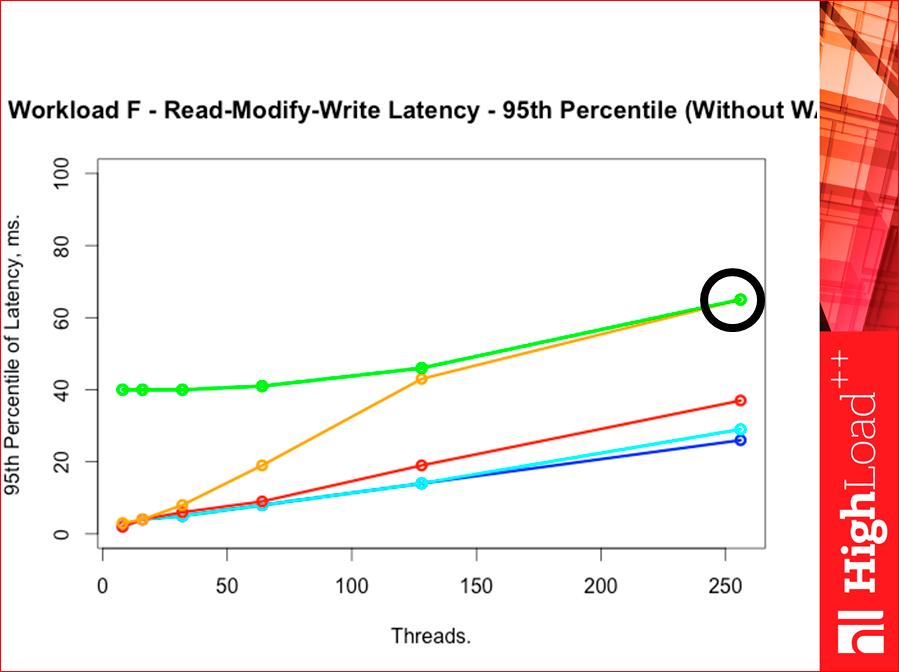
Если у нас 99-ая перцентиль, то уже Redis опять Tarantool чуть-чуть обогнал, т.е. на 99-ой перцентили Redis чуть-чуть Tarantool обгоняет. Tarantool, который с деревянным индексом, ушел вверх. Такая вот интересная картина:
Теперь смотрите, это один из способов тестирования, Yahoo! тест. Я попробовал написать другой тест, попробовал изменить немножко подход к тестированию, не сильно, попытался выжать максимум throughput, в-первую очередь, из базы данных, т.е. прямо до предела ее дожать без всяких workload«ов. Такой тест состоит из двух частей: сперва мы данные забиваем, потом мы данные вычитываем. Есть страничка, это очень простой тест.

Сейчас расскажу, как он устроен. Он дал довольно интересные результаты, не считая того, что он дал четыре бага в Tarantool, из них две корки, которые оперативно исправили, т.е. они уже в релизе вышли.
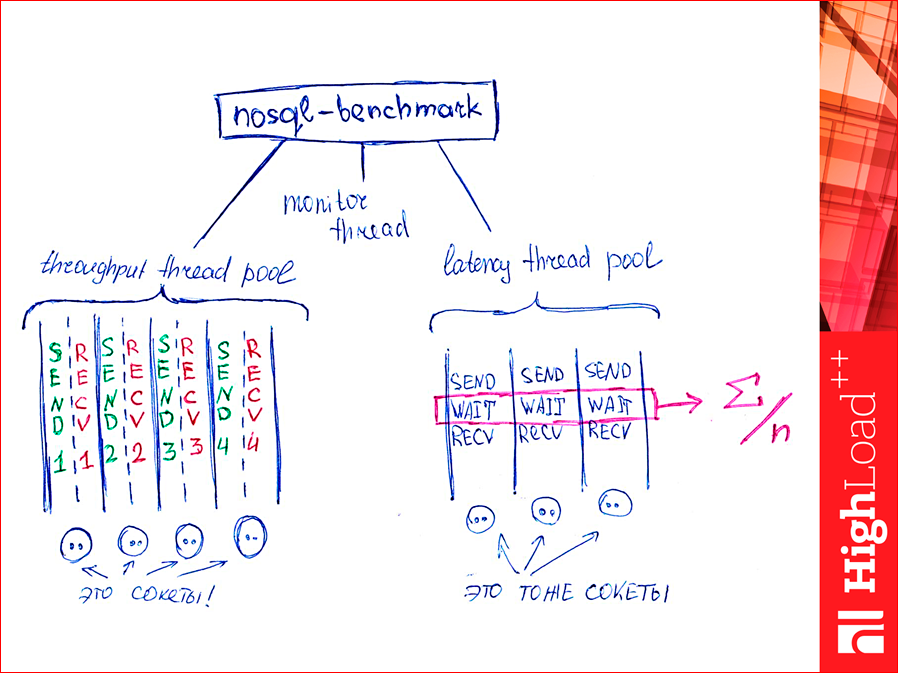
Как это работает? У нас есть куча pool-потоков для нагнетания запросов в базу для throughput. Тут есть сокеты, их там n штук, сколько хотим, и каждому сокету у нас по два потока. Один пишет, вообще, без разбора, пишет-пишет-пишет, прямо автоматом. А второй вычитывает данные по готовности. И есть потоки для подсчета latency. Их немного. Первых потоков много и они парами, потоки для latency — их один, иногда два-три, и они сперва пишут, потом ожидают ответа, вычитывают ответ и то, что выделено там, они просуммируют. Специальные переменные атомарно суммируются, и считается среднее. Т.е. пока еще перцентиль не считается. В ближайшее время я ее сделаю, но пока считается среднее. Конечно, они друг друга аффектят, но за счет того, что у latency потоков две-три штуки, а thoughput — там их сотни, то аффектят они несильно. К тому же, throughput сильно больше нагнетает без остановки, а latency ожидает. И есть поток, который монитором раз в секунду считывает все переменные из памяти и выводит на экран.
И что у нас получается?
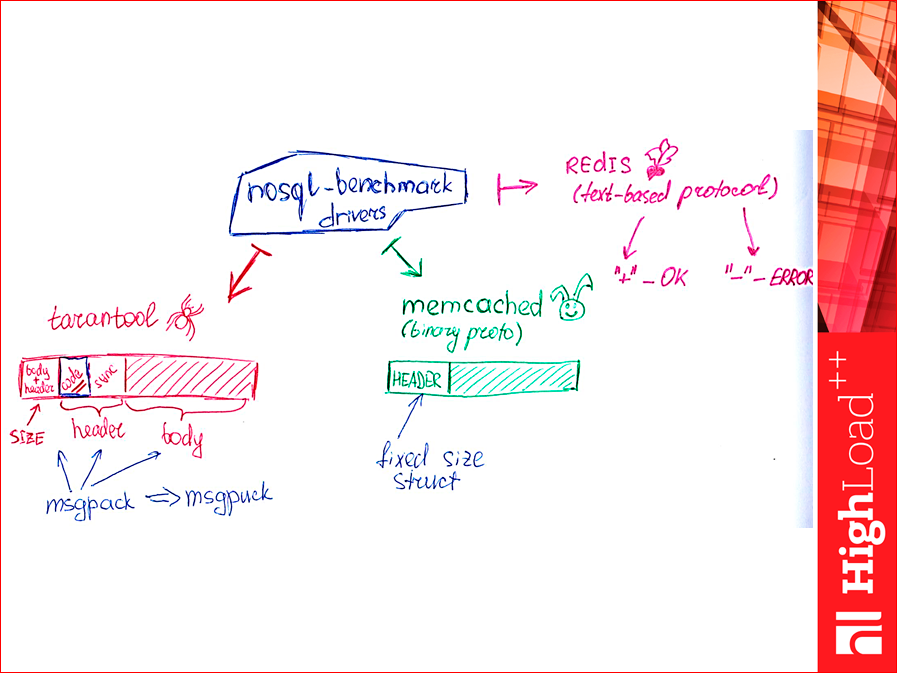
Что плохо в тесте Yahoo!, это то, что он использует стандартные клиенты, т.е. он тестирует не саму базу данных, а базу данных в связке с клиентом. Когда я писал клиент для Memcached, использовал spymemcached. Это библиотека от авторов CouchBase, довольно быстрая, но, тем не менее, для нас это черный ящик. И я поставил себе цель, вообще, от клиентов избавиться и сделать самый простой клиент, который только для теста, он вообще не несет функциональности, в работе его использовать нельзя, он умеет только отправлять запросы и читать ответы. Как это сделать? Смотрите, у Tarantool там три кусочка: первый — это размер, header + body, а второй — это header, два числа. Нас интересует то, что синеньким выделено. Это наш код возврата — либо ошибка, либо не ошибка. И зная первое поле размера, мы считали первое поле, считали header и считали остальное, зная размер. И просто считываем-считываем-считываем это дело без разбора в этих парах потоков (см. слайд еще выше), там зелененькие и красненькие, которые просто считывают ломовым способом.
Msgpack — это такой бинарный протокол реализации. Обычная библиотека от него медленная и т.к. я старался избавиться от всех библиотек, есть реализация, написанная тоже у нас в компании, называется msgpuck. Она быстрая, я ее немного доработал для этого дела.
С Memcached все еще проще. Протокол у нее бинарный, fixed size структурка и плюс переменные длины поля. Вычитали структурку, получили код возврата, вычитали поле. Все. Т.е. очень просто.
С Redis сложнее, у него протокол текстовый. Если мы залезем в протокол Redis, то увидим, что любой успешный ответ на select начинается с плюсика, т.е.»+» и там дальше что-то вернется. Любая ошибка — с минусиком. И если мы договоримся, что ни в ключах, ни в значениях наших наборов данных, которые мы записываем и читаем, не будет ни »+» ни »-», то читая голый поток байт из сокета, можно просто считать плюсы и считать минусы.»+» — это сколько вернулось успешных ответов,»-» — это сколько вернулось ошибок. Такая реализация будет быстрой, т.е.»+» и »-», все. Считываем, если байт не »+», не »-», мы его пропускаем, если »+» или »-» — просто счетчики добавляем. И начинаем эту штуку гонять. Гонялась она на Azure и получили такие результаты:
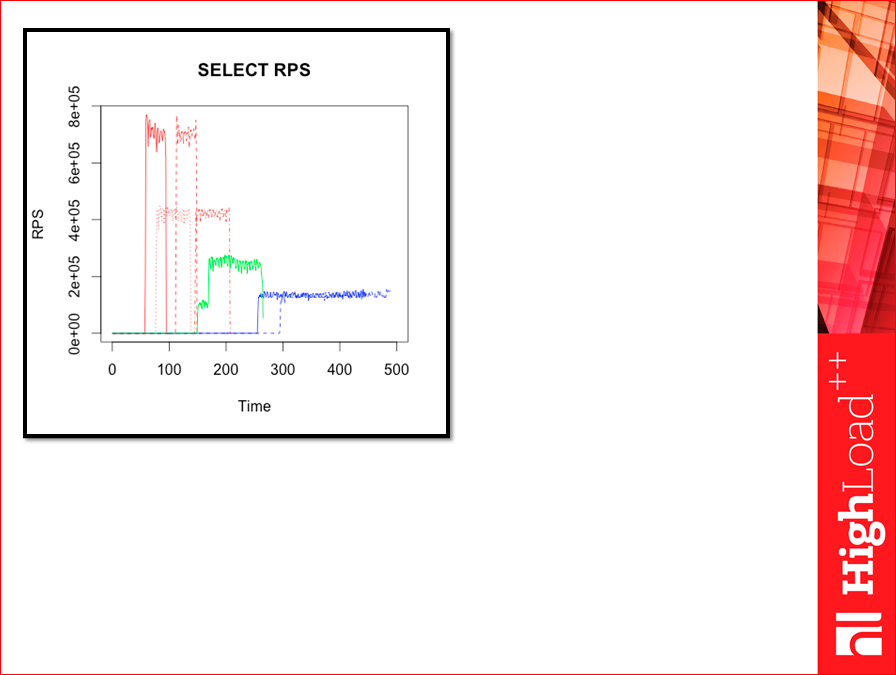
Такие картинки я сперва приготовил. Это весь тест. Видите, там начало, это фазы селектов, что-то происходит там, RPS довольно высокие, они сильно выше получались, чем в тесте Yahoo!… Там, где пунктиры, там WAL, там, где не пунктиры — без WAL. Красный — Tarantool, оранжевый — Tarantool с деревом, зеленый — Memcached, синий — Redis версии 2.
Так у нас были инсерты:
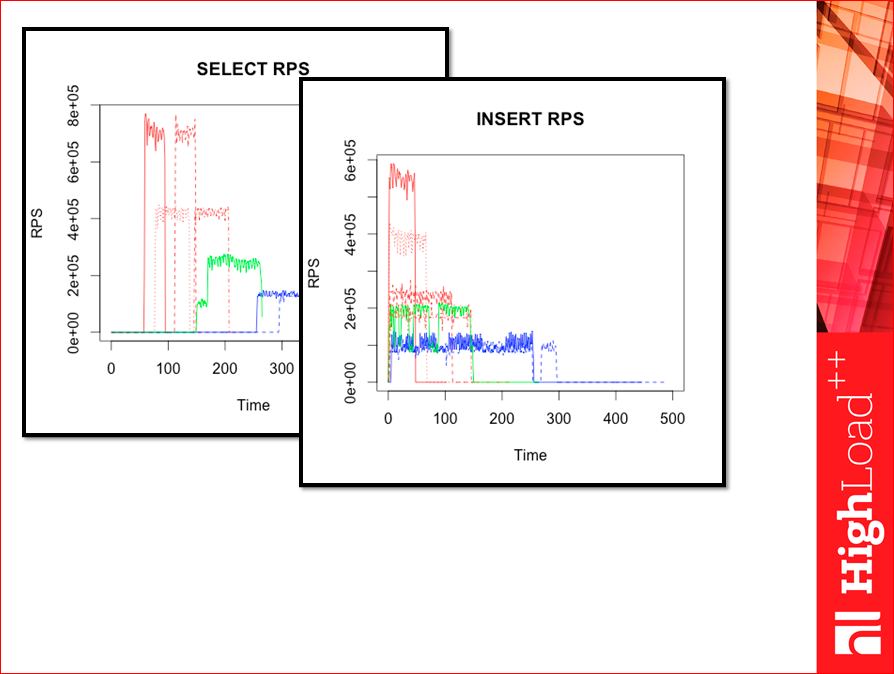
Чем больше у нас throughput, тем меньше тест длится, потому что быстрее запихиваются данные.
И так у нас считается latency:
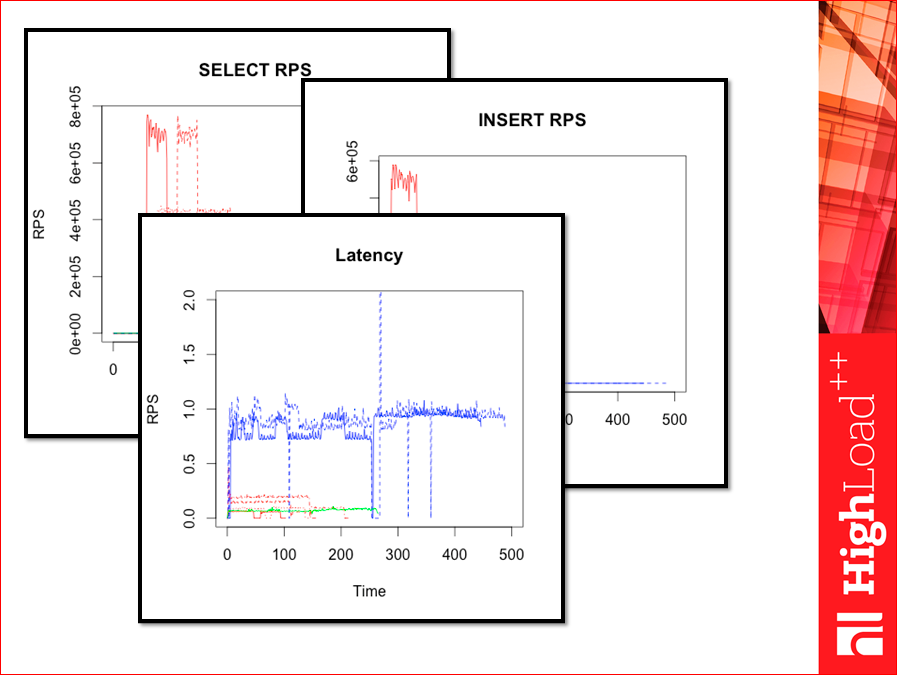
Сразу обратите внимание, этот тест не от числа потоков графики тут построены, а от времени.

И тут есть «провалы», т.е. иногда тест Yahoo! может показать хороший результат, но когда начинаем работу, в какие-то моменты начинает резко тупить. Среднее, вроде, бы нормальное, а тупежи такие могут проходить. И графики по времени желательно строить. В Yahoo! это можно, если построить небольшие костыли. Тут оно строится довольно естественным способом, там сразу csv экспортируется в excel или еще куда-нибудь. Эти графики я принес начальнику, начальник сказал, ерунда, нечитаемо. Поэтому я их перерисовал. Вот так вот:
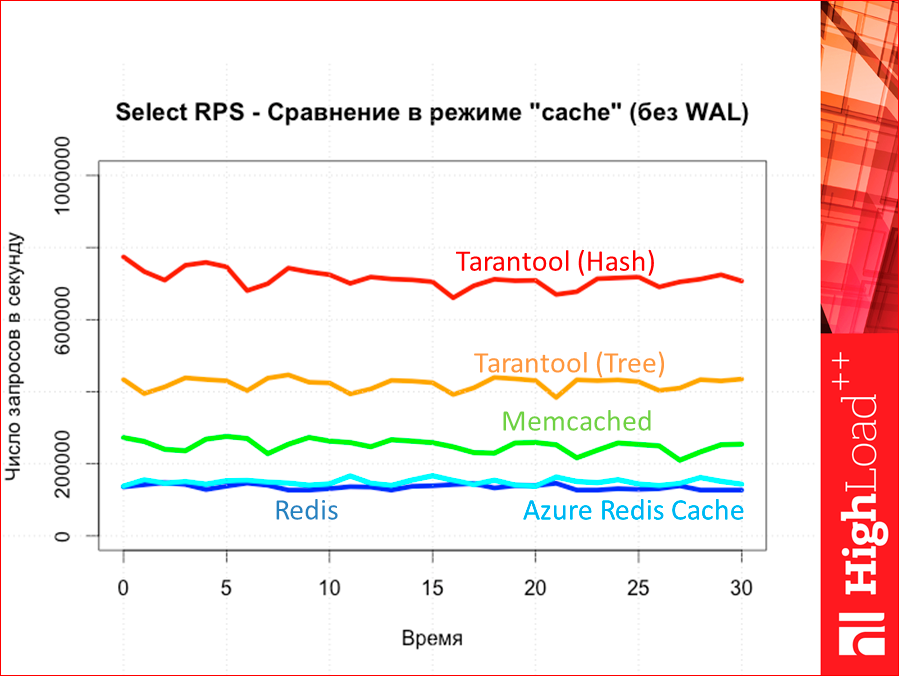
Это у нас throughput по селекту. Красное — Tarantool (hash), а оранжевый — Tarantool (tree). Потом Memcached и только потом у нас Redis и Azure Redis Cached. Тут Redis версии 2. Не 3-ий, последний, 3-ий чуть выше или в районе Memcached будет.
Если у нас с WAL, то картина не меняется:

А если у нас latency, то мы можем увидеть, как раз, те самые «провалы».
Т.е., вроде бы, у нас большой throughput, но такая штука появляется, которая может нам в какие-то моменты портить все, что у нас тут работает. Это видно.
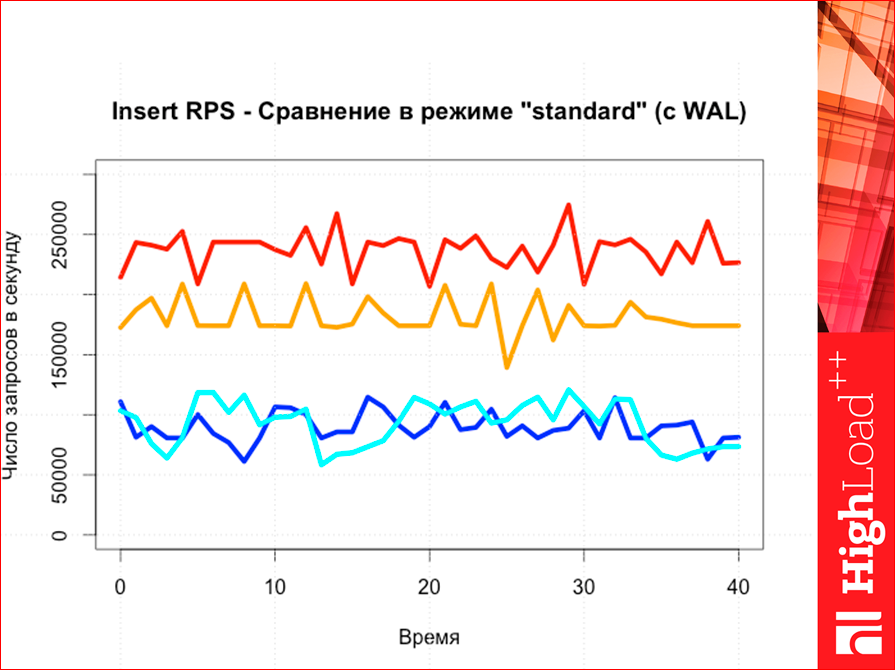
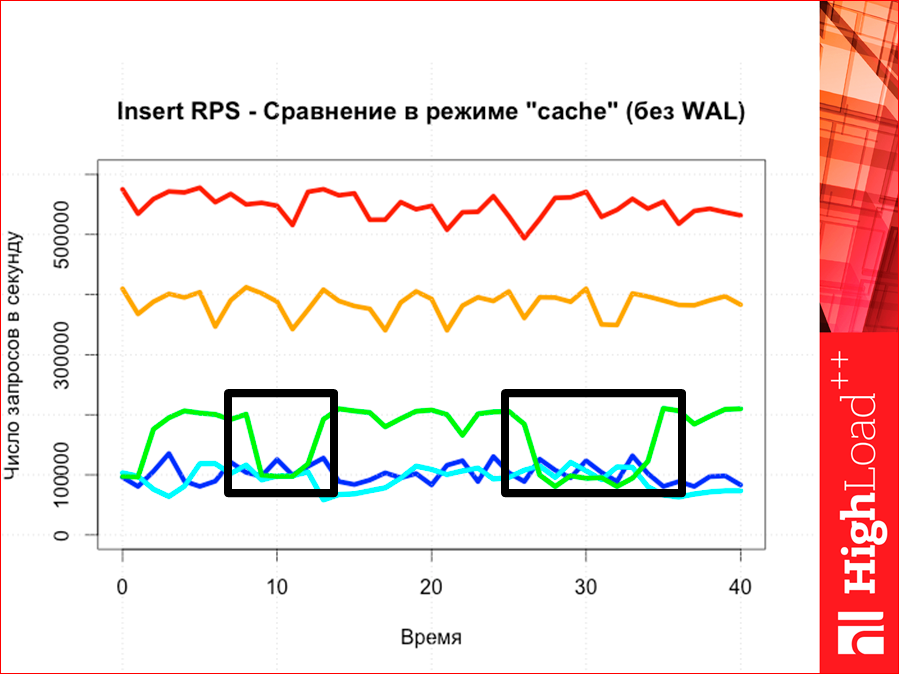
Если мы сравниваем инсерты, то картина опять же абсолютно предсказуема, как мы видим, т.е. опять же Tarantool выше.
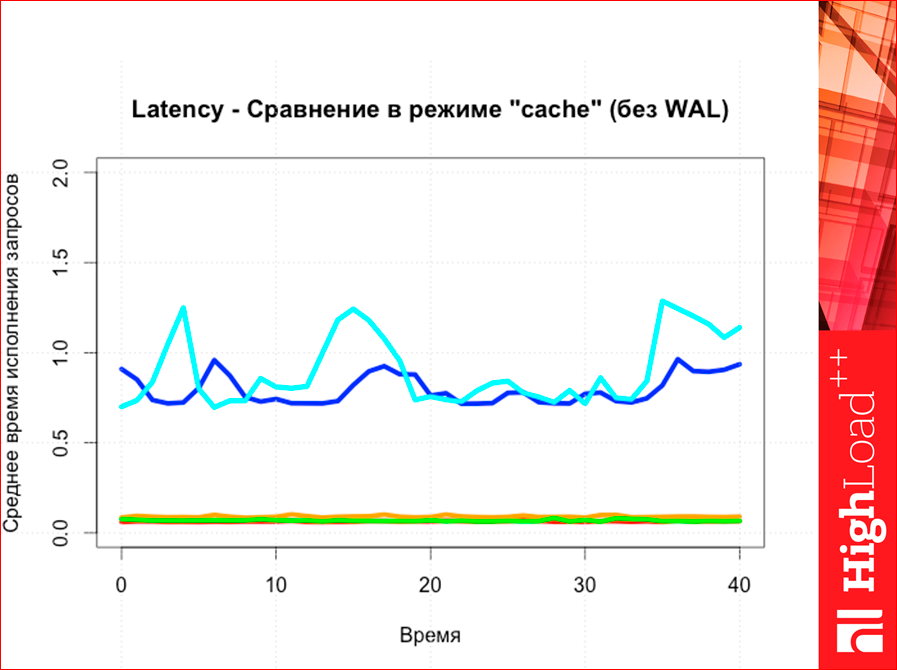
И latency. Latency у Redis сильно выше, чем у всех остальных, т.е. там три линии — все в одну.
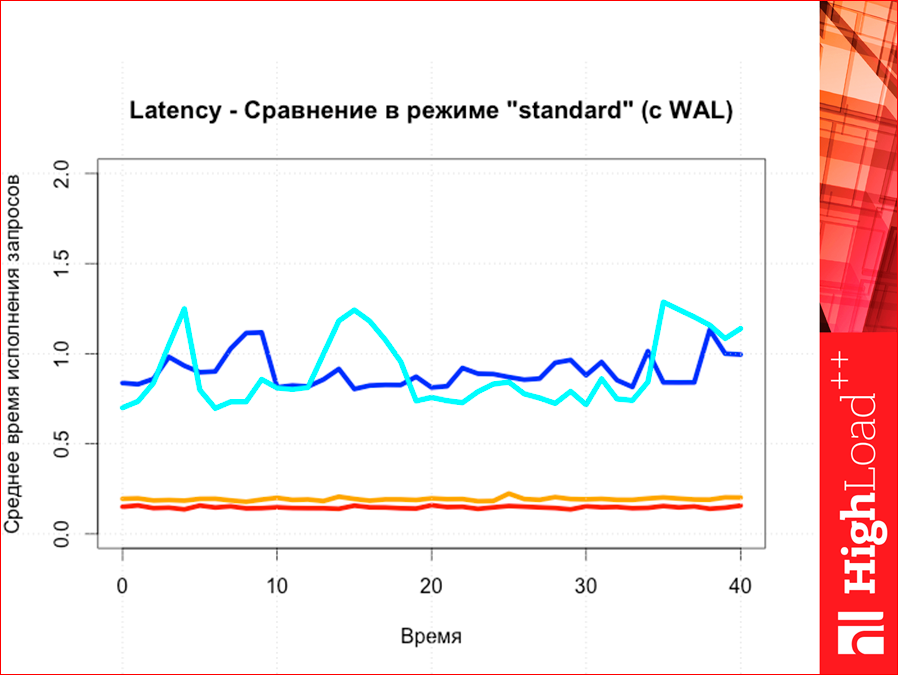
И здесь тоже таким вот образом.
И как измерять memory footprint?

Для этого маленький скриптик написан. Он просто считает, сколько памяти занимает данный бит у нас, данный идентификатор процесса. Скрипт вот такой:

Читаем просто RSS и складываем эти кусочки RSS и через bc суммируем. И мы выводим его на стороне сервера с timeout«ом и складываем.

И одновременно, мы знаем, сколько у нас данных ушло, потому что на стороне тестера мы знаем, сколько у нас отправилось запросов в базу данных. И можно построить график.
Графики интересны сами по себе, но самое интересное тут посмертное состояние. И здесь очень неожиданная картина, т.е. ее размах будет очень неожиданный.
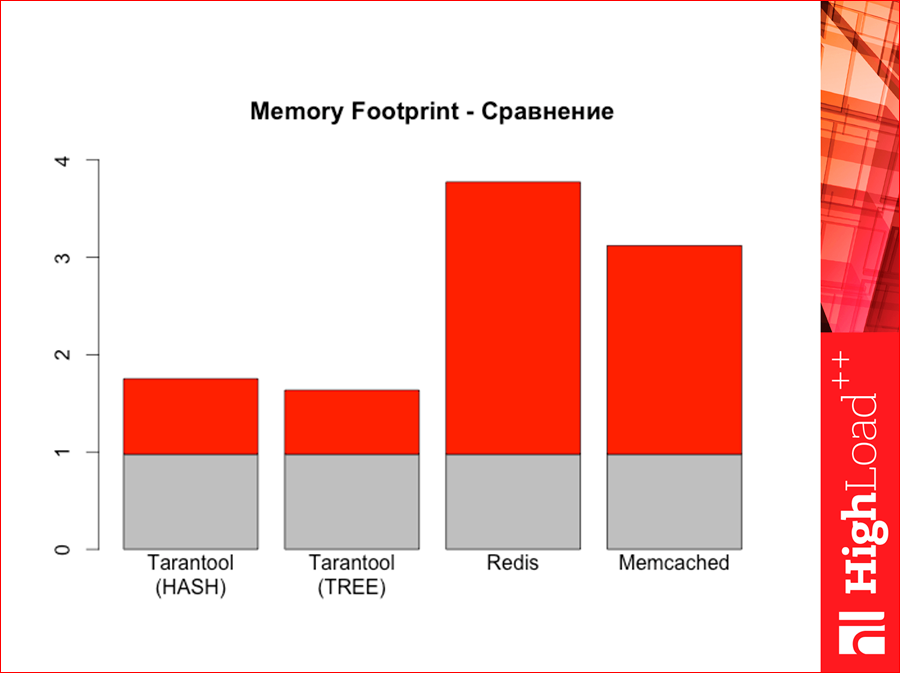
Tarantool с хэшем, вот Tarantool с деревом… Тут серенькие — это сколько у нас байт физически находится в базе данных, а серенькое + красное — это сколько памяти занимает сама наша СУБД, т.е. сколько оперативной памяти она тратит. Смотрите, что происходит здесь — сильно много выхода по памяти у нас. С Memcached — поменьше. Такие вот картинки.
И мы подходим к концу. Т.е. начинал я с инженерного подхода, как мы вообще выбираем базу данных, и я его напомню. У нас такая вороночка будет:
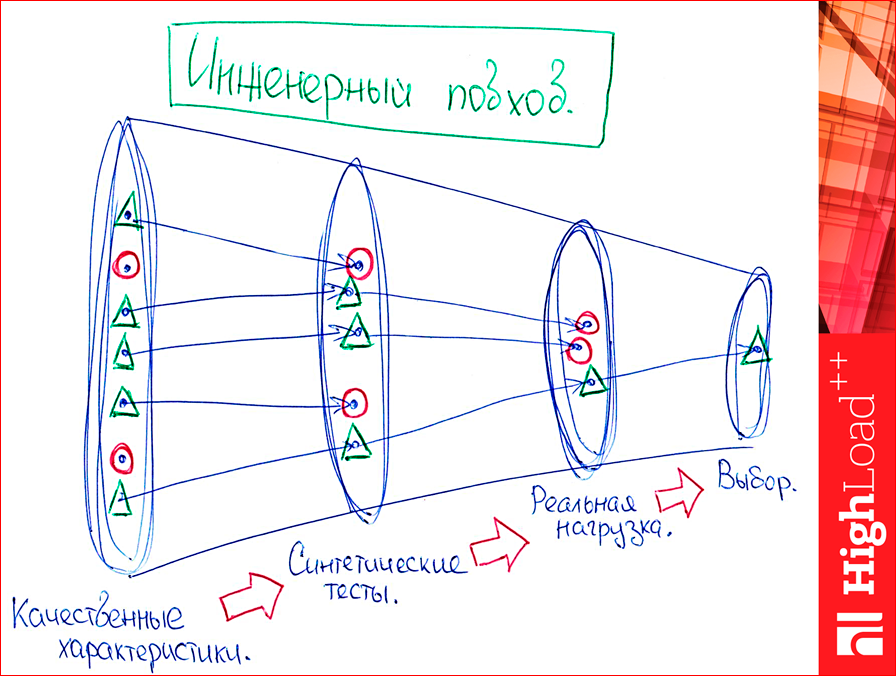
На входе у нас какие-то есть точки — это базы данных. И мы каждым ходом их отсеиваем.
Есть разумный вопрос: «А на хрена, вообще, тестировать на синтетике?». Сразу отвечу.
У нас есть много баз данных. Я тестировал четыре, их, конечно, больше. Можно и нужно больше тестировать. Мы сперва выбираем именно по качественным характеристикам, например, нам нужен селект по range from to, нам обязательно нужно B-дерево, и мы можем отсеять то, что у нас с только с хэшем, какой-нибудь Memcached или прочее. Или нам нужен обязательно WAL, тоже Memcached отсеется. И мы отсеем сперва по качественным характеристикам. У нас есть задача какая-нибудь, и мы просто удаляем именно те базы данных. Красненьким отмечены те, которые не подходят.
Дальше мы тестируем на синтетике. Смотрите, баз данных у нас много, на картинке у нас пять штук. Почему на синтетике? Потому что если мы будем сразу тестировать на реальных данных, мы помрем. Нам придется реализовать бизнес-логику для всех баз данных, а это сложно. Синтетика пишется очень быстро. Всякие утилитки, вообще, «на коленке» делаются, отлаживаются, конечно, верифицируются, чтоб похоже на правду, но все-таки делаются недолго. Если писать еще бизнес-логику, то она делается дольше, сильно дольше.
И только потом, когда мы уже отсеяли на синтетике то, что нам явно не подходит, там совсем плохие результаты в каких-то там кейсах, мы начинаем тестировать на реальных данных и что-то в итоге выбираем.
Такой подход. Моей целью было показать, как надо выбирать базу данных.
Контакты
rvncerr
Блог компании Mail.ru
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Комментарии (1)
7 октября 2016 в 18:36
+1↑
↓
Жирный минус тарантулу в сравнении в редисом — в удобстве структуры документации. В редисе есть команды и типы и с этим всё понятно. А чем и как правильно оперировать в тарантуле — огромный вопрос.
