Как в C# быстро извлечь подстроку
Извлечение подстроки. Казалось бы, что тут может быть сложного? В любом современном языке программирования это можно сделать через функцию substring или через slicing. За время работы C# разработчиком я повидал разный код, в том числе разные способы извлечения подстроки. В этой статье мы рассмотрим самые распространённые из них, сделаем замеры производительности и проанализируем результаты.
Дисклеймер
Информация в этой статье верна только при определённых условиях. Я допускаю, что бенчмарк может показать другие результаты на другом ПК, с другим ЦП, с другим компилятором или при другом сценарии использования рассматриваемого функционала языка. Всегда проверяйте ваш код на конкретно вашем железе и не полагайтесь лишь на статьи из интернета.
Бенчмарк
Замер производительности будет осуществляться на массиве из 100 000 строк, представляющих собой путь к файлу. Данные генерируются библиотекой Bogus и выглядят примерно вот так:
/usr/libdata/gb.m4p
/srv/facilitator_optical_borders.cw
/Users/internal.dbk
/etc/defaults/cliffs.pptm
/home/connecting_factors_mint_green.luac
...Наша задача — извлечь имя файла с расширением стандартным инструментарием C#. Проверять мы будем следующие способы:
string.Substring.
Оператор range.
string.Split.
Regex.Match.
Метод TakeLast из LINQ.
Для замеров производительности я использовал библиотеку BenchmarkDotNet. Код бенчмарка можно найти в GitHub.
Результаты
Результаты замеров времени и памяти представлены на диаграмме ниже. Попробуем разобраться почему они именно такие.
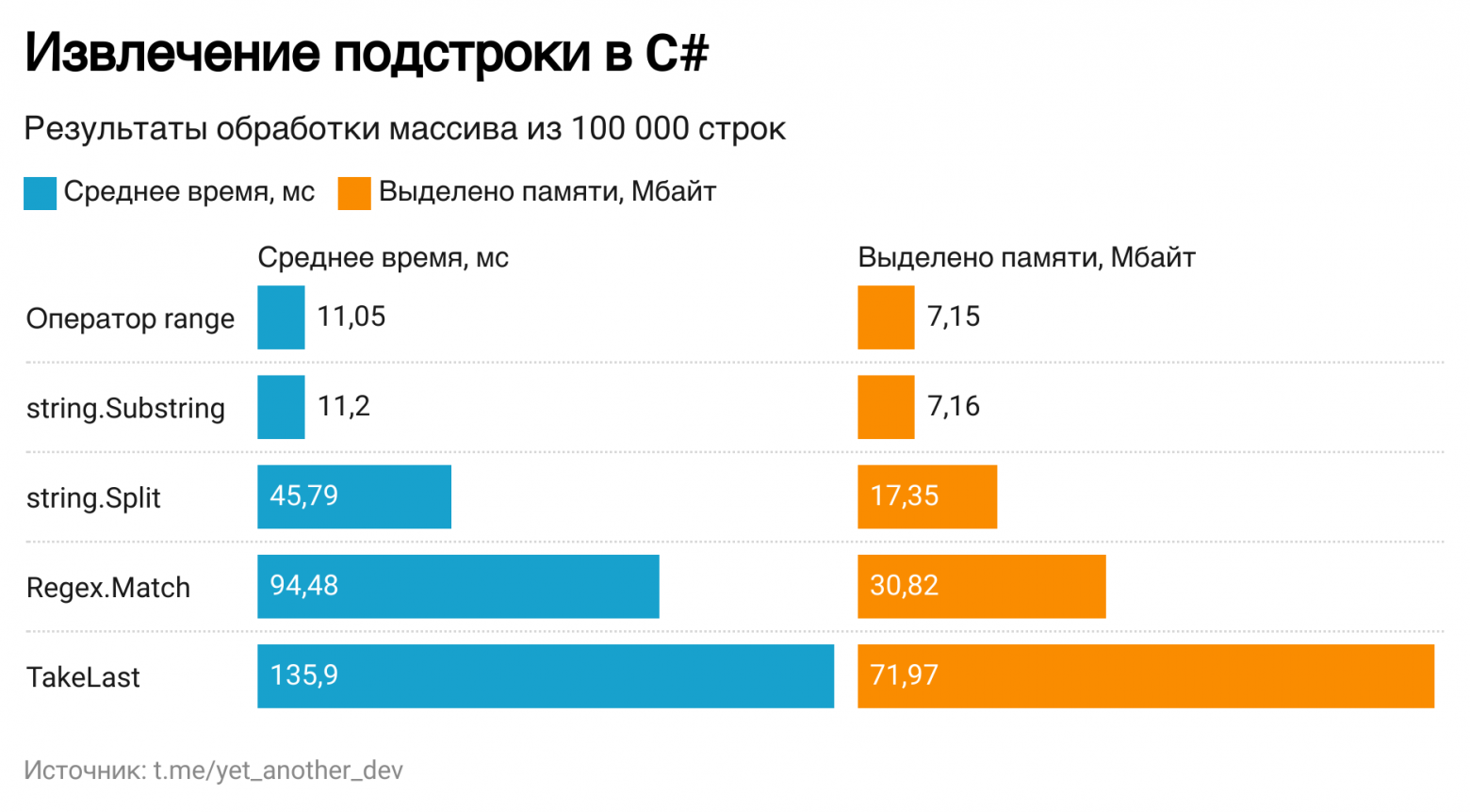
Результаты выполнения бенчмарка
Метод string.Substring и оператор range
Результаты у двух этих способов одинаковые, т.к. оператор range — это синтаксический сахар. Убедиться в этом можно, рассмотрев простой пример ниже.
var str = "Hello, World!";
var substr = str[..5];
Console.WriteLine(substr);Этот C# код компилируется в IL код, в котором вызывается метод Substring.
IL_0000: ldstr "Hello, World!"
IL_0005: ldc.i4.0
IL_0006: ldc.i4.5
IL_0007: callvirt instance string [System.Runtime]System.String::Substring(int32, int32)
IL_000c: call void [System.Console]System.Console::WriteLine(string)
IL_0011: retЗаглянем под капот .NET. Если отбросить валидацию входных параметров и граничные случаи, то метод Substring просто вызывает метод InternalSubString.
public string Substring(int startIndex, int length)
{
/* валидация и обработка граничных случаев */
return InternalSubString(startIndex, length);
}В InternalSubString выделяется память через метод FastAllocateString и копируется подстрока в выделенный участок памяти.
private string InternalSubString(int startIndex, int length)
{
string result = FastAllocateString(length);
Buffer.Memmove(
elementCount: (uint)length,
destination: ref result._firstChar,
source: ref Unsafe.Add(ref _firstChar, (nint)(uint)startIndex));
return result;
}Используя Substring явно или через оператор range, выделение памяти происходит один раз, а непосредственно извлечение подстроки происходит через копирование памяти. Теперь посмотрим, что происходит в других методах.
Метод string.Split
Очевидно, что использование метода string.Split для извлечения подстроки не самый оптимальный вариант. Достаточно взглянуть на возвращаемый тип — это массив строк. Но всё же рассмотрим внутреннюю реализацию метода подробнее.
private string[] SplitInternal(ReadOnlySpan separators, int count, StringSplitOptions options)
{
/* валидация и обработка граничных случаев */
// StackallocIntBufferSizeLimit = 128
var sepListBuilder = new ValueListBuilder(stackalloc int[StackallocIntBufferSizeLimit]);
MakeSeparatorListAny(this, separators, ref sepListBuilder);
ReadOnlySpan sepList = sepListBuilder.AsSpan();
string[] result = (options != StringSplitOptions.None)
? SplitWithPostProcessing(sepList, default, 1, count, options)
: SplitWithoutPostProcessing(sepList, default, 1, count);
sepListBuilder.Dispose();
return result;
} В этом методе происходит следующее:
В стеке инициализируется массив
int[]размеромStackallocIntBufferSizeLimit. На момент написания статьи значение этой константы было 128.Инициализируется внутренняя структура ValueListBuilder
c массивом int[].Разделяемая строка, разделители и структура
ValueListBuilderпередаются в метод MakeSeparatorListAny. В нём осуществляется поиск индексов разделителей в строке путём её обхода в цикле.В нашем случае, завершается всё вызовом SplitWithoutPostProcessing. В нём инициализируется массив строк, затем, в очередном цикле, исходная строка разделяется путём копирования подстрок с использованием метода
Substring.
Теперь стало понятнее, почему метод Split медленнее. Вызов этого метода сопряжён с циклами, инициализацией массива и копированием ненужных подстрок.
Регулярные выражения
Извлекать подстроку регулярными выражениями — это как стрелять из пушки по воробьям. Но и такой подход встречался на практике.
Для извлечения подстроки нами использовался метод Match статического класса Regex. Вызов этого метода приводит к следующему:
Вызывается метод GetOrAdd внутреннего класса
RegexCache.В кэше ищется экземпляр
Regexдля нашего паттерна"[^\/]+$".Если в кэше такой экземпляр есть, то он возвращается, иначе создаётся новый, помещается в кэш и только после этого возвращается.
Вызывается метод Match, что приводит к инициализации regex-движка и поиска совпадений по нашему паттерну.
public partial class Regex
{
public static Match Match(string input, string pattern) =>
RegexCache.GetOrAdd(pattern).Match(input);
}Очевидно, что выполнение такого большого количества операций требует больше ресурсов ЦП и памяти.
Методы расширения LINQ
Это самый не подходящий способ для извлечения подстроки. Используя LINQ нужно быть всегда готовым к аллокациям памяти. Для каждой строки был создан Enumerator, а также Queue
Заключение
Наиболее эффективный способ извлечения подстроки в C# — это метод Substring. Я предпочитаю range оператор из-за более лаконичного кода, который получается при его использовании. Конечно, другими способами тоже можно добиться нужного результата, но это будет менее эффективно. Поэтому используете методы по назначению. :)
