Как в 3 раза снизить затраты на отказоустойчивую инфраструктуру, переехав с Hazelcast на Redis
Redis на хайпе. Но мы переехали на него с Hazelcast не из-за этого, а потому, что в какой-то момент осознали, что не замечать сколько инцидентов у нас возникает из-за Hazelcast, дальше невозможно. Привет, меня зовут Ян Чикнизов, я Java TechLead, в Альфе работаю 4 года, из которых 1,5 курирую направление Redis. Сегодня расскажу вам замечательную историю как мы всем Альфа-Мобайлом сменяли одну технологию на другую.
В статье вас ждёт опыт переезда с Hazelcast на Redis, сравнение фич разных популярных Open Source решений, способы сделать Redis отказоустойчивым и особенности взаимодействия микросервисной архитектуры с ним. А также описание способов администрирования, мониторинга и раскатки Redis, и ответы на вопрос «Как лучше приготовить отказоустойчивый распределенный кеш?» и «Сколько же можно сэкономить денег, просто выбрав другую платформу для кешей?»

Сразу оставлю ссылку на страничку в Notion, где будет множество дополнительных материалов и источников данных, на которые я буду часто ссылаться.
Итак, сегодня пойдёт речь о пяти вопросах. И мы разберёмся с каждым:
Что собственно такое этот Cache, почему и зачем его распределяют?
Почему мы переехали с одного фреймворка на другой?
Как мы приготовили то, на что переехали?
Как мы интегрировали Redis?
И что это нам дало?
Распределённые кэши на примере YouTube и лайков
Итак, разберёмся мы на простом примере — вам приходит уведомление о том, что ваш любимый ютубер выпустил долгожданное видео.

Вы переходите на него и видите комментарий: «Лайков больше, чем просмотров».
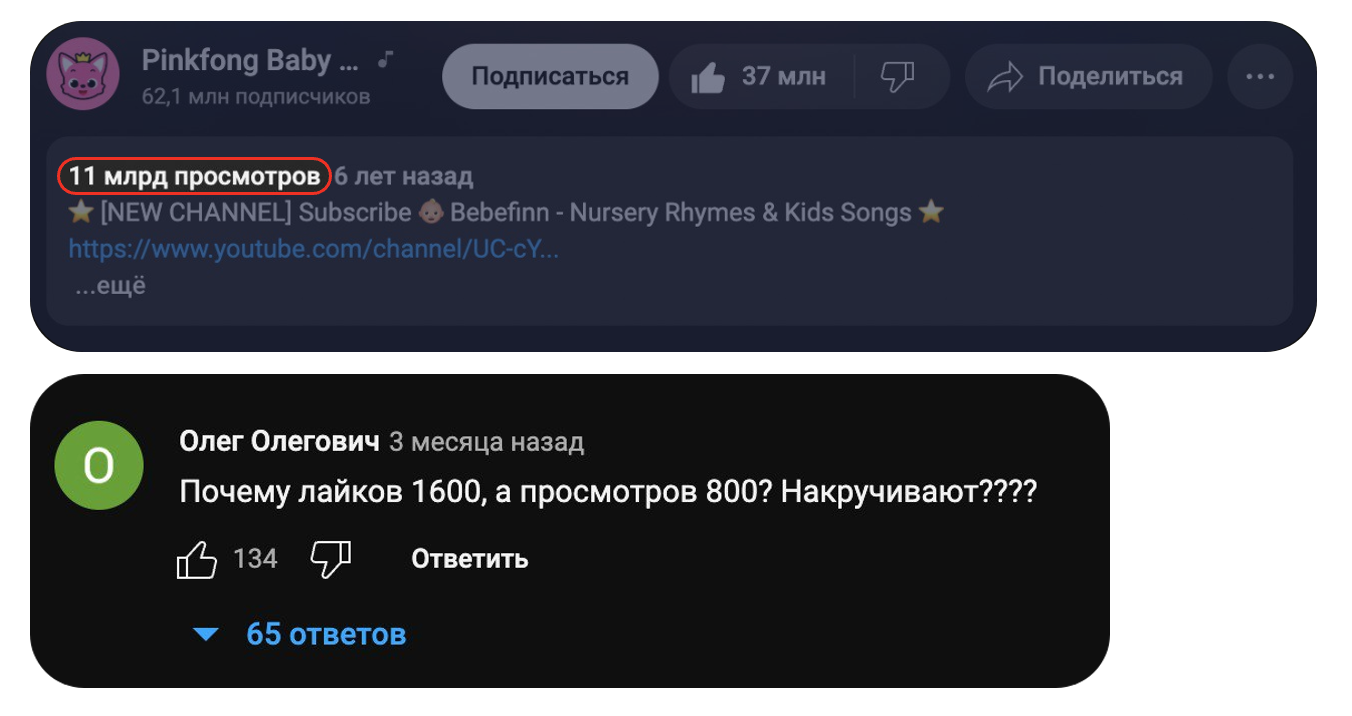
Непорядок. Почему так? Потому что мы кэшируем данные.
Чтобы не нагружать backend постоянными вычислениями количества лайков/дизлайков и просмотров, YouTube сохраняет промежуточное число, и раз в условные 15 минут обновляет его. В итоге нагрузка на backend минимальная (отдать сохранённую цифру без вычислений), а зрители рады, что страница быстро отрисовывается, за исключением душных ребят которые пишут комменты про накрутку.
Но пойдём дальше — современные высоконагруженные системы стараются использовать микросервисы и балансировать нагрузку между ними. Получается что копий backend«а может быть несколько (обычно не меньше 3) и балансировщик будет балансировать запросы в каждую копию. При использовании стандартного in memory кеша может возникнуть вот такое: когда мы обновляем видео, балансировщик отсылает нас на 1 копию, и мы видим, что на нём 2500 просмотров и 60 лайков.

Обновили второй раз, и нас отсылают на 2 копию микросервиса — видим 2 600 просмотров и 70 лайков.
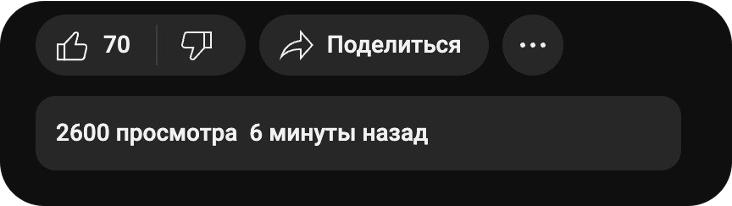
Обновили третий раз и на последнем инстансе микросервиса получаем опять же логичную картину — 2 700 просмотров и 80 лайков.

Но что произойдет, если мы обновим ещё раз? А произойдет следующее: мы увидим вторую ситуацию.
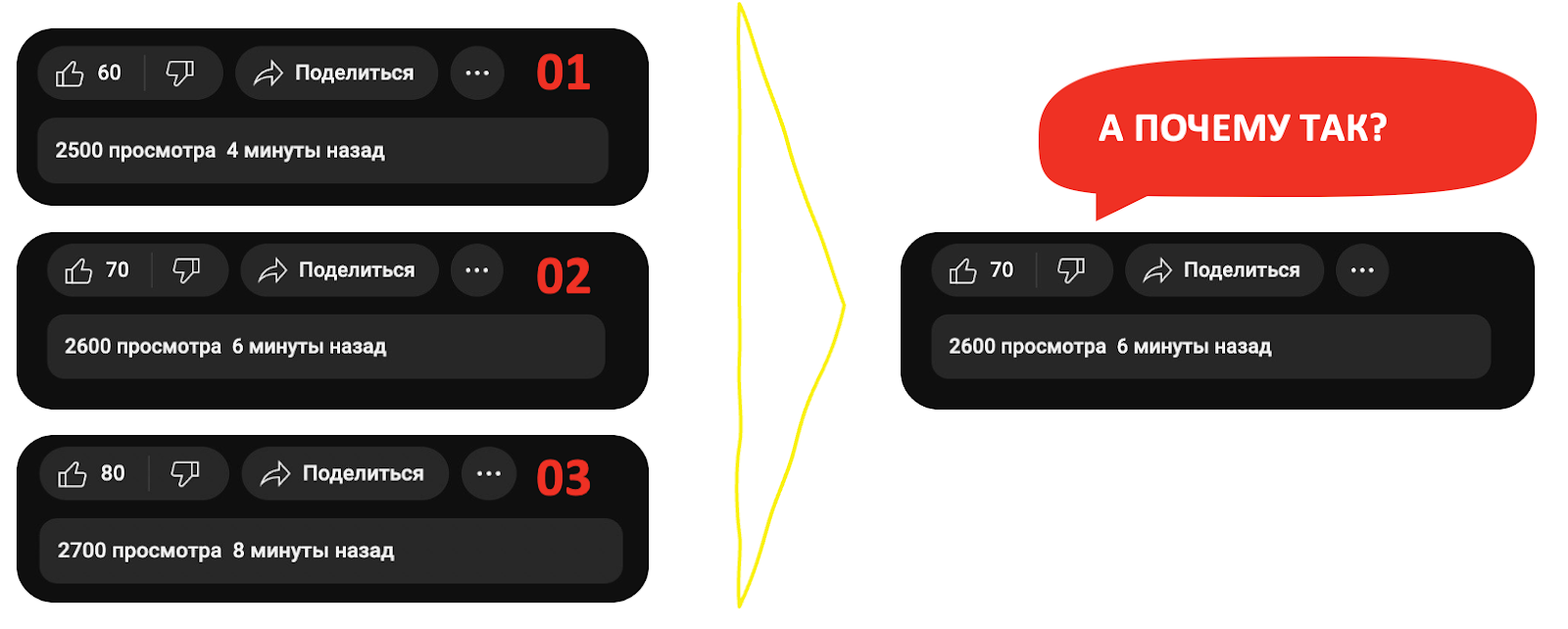
Или первую? Или третью? Ведь при обновлении страницы балансировщик может отослать нас как на первую, так на вторую или третью копию микросервиса. Мы можем увидеть абсолютно разный результат: 2500 просмотров, обновляем — уже 2700, обновляем — 2600.
Дело в том, что в современной отказоустойчивой системе держат не одну копию микросервиса, а несколько. И, соответственно, на каждом из микросервисов может быть несколько кэшей. Архитектурно это выглядит примерно так.

YouTube идёт в балансировщик, он балансирует запросы, и в каждом из микросервисов есть своя копия кэша, в которой хранятся определённые значения. Одно дело YouTube видео, 2500 или 2700 просмотров — какая разница? А если вы увидите на своём банковском счёте разное количество денег, то явно напряжётесь — 2500 или 2700 рублей разница есть.
Именно это ситуация называется неконсистентностью, и с ней мы справляемся тем, что вносим распределённые кэши. А что это такое? Вот это.
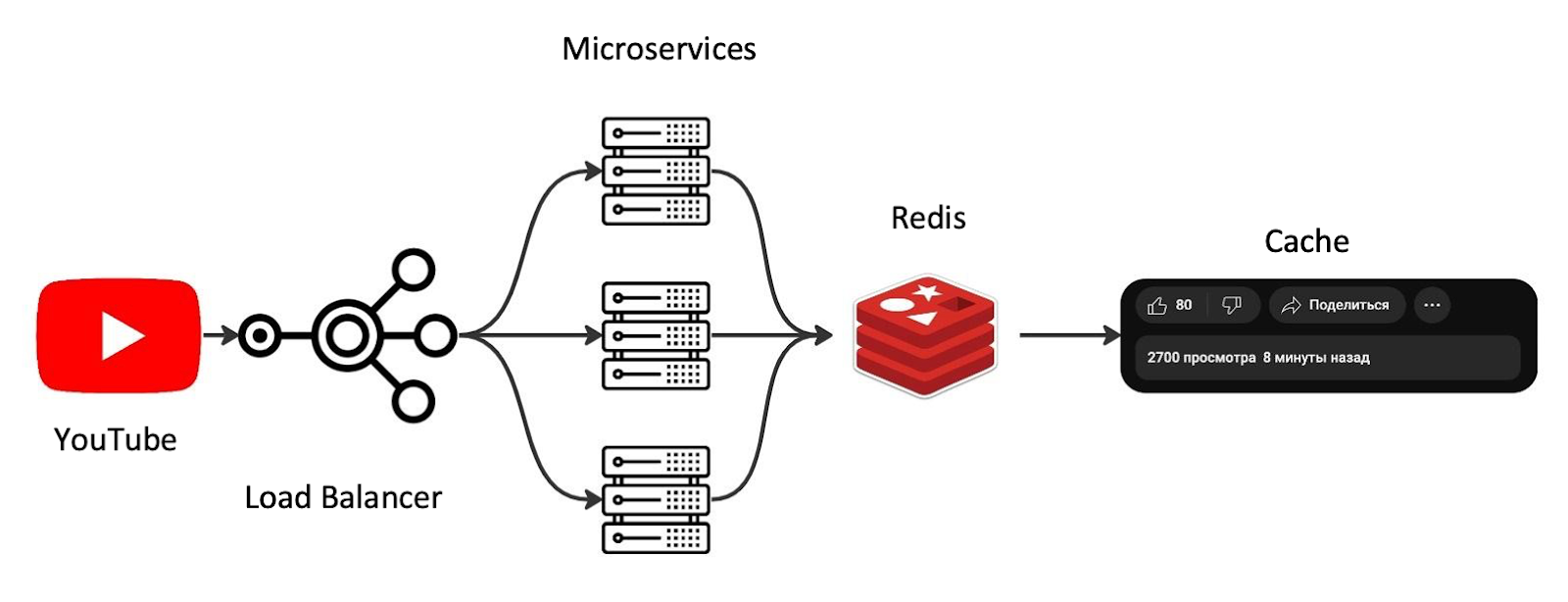
Вместо того, чтобы делать запрос в память микросервиса, мы просто идём в единую точку правды и спрашиваем у неё: «А сколько просмотров, лайков или других параметров?» На примере веб-странички это легко — просто накидываем Nginx, а если микросервисы общаются друг с другом, то тут уже возникает множество вопросов.
Ну, разобрались мы что такое кэши и зачем их распределяют. А зачем мы вообще брали и меняли одну технологию кэшей на другую? Давайте разберемся с первой технологией.
Hazelcast и деньги
Hazelcast — in memory Open Source база данных. Написана на Java, имеет поддержку не только Java-приложений, но и парочки самых популярных языков. Если верить коммитам, то в банке мы её используем с 2016 года.
Hazelcast — Open Source. А как измеряется «опенсорсность»? В количестве людей, которые её контрибьютят! Как можно увидеть, «опенсорсность» здесь есть и вроде даже неплохая.

На текущий момент существует версия Hazelcast v5.1.5 и вот какие фичи он выделяет на своем сайте:
Но у Hazelcast есть ещё и платная версия. И когда мы говорим о платности, то должны узнать ответ на вопрос — «А что из этого списка топовых фичей он поддерживает, что доступно в Open Source community version?» А поддержит он лишь одну фичу — On-Heap storage!
Это означает, что вот этого огромного списка фичей у вас не будет!

Нет ни записи данных на диск, ни фич безопасности, отсутствуют Rolling Upgrades и Cache Hot Restart, нет утилит для восстановления кластера и хранение данных вне хипа отсутствует. Да что говорить, если даже за подключение дополнительных нод нужна лицензия. Да, вы даже не сможете заперсистить данные на диск — придётся заплатить.

Hazelcast очень хочет ваших денег.

И тут у нас встал резонный вопрос, а сможем ли мы получить необходимые нам функции, какую-то безопасность, отказоустойчивость и Rolling Upgrades в других Open Source community версиях?
Есть ли на рынке альтернативы?
У нас был детальный и подробный ресерч на тему технологий. Мы начали сравнивать Ignite, Infinispan, Redis, Hazelcast по довольно большому количеству параметров (дублирую ссылку на таблицу из начала статьи).

Итак, с недавнего времени наш Мобайл стал полностью реактивным. О том, как мы переезжали на реактивные микросервисы, есть замечательная статья Татьяны Руфановой «Зачем нам Reactive и как его готовить».
В целом, нам важны:
реактивный драйвер;
аварийное восстановление;
элементарная безопасность, чтобы мы смогли запаролить наши базы данных;
Open Source;
и поддержка комьюнити.
И теперь мы плавно переходим к нашему главному герою Redis.
Почему Redis?
Это такая же Open Source база данных, которая используется во множестве кейсов: может быть и как кэш, и как база данных, и как решение для работы с геолокацией. Она имеет поддержку различных языков — даже Haskell есть.

Redis имеет ОЧЕНЬ СЕРЬЕЗНУЮ поддержку сообщества.
 Бонусом список ссылок, где Redis скромно хвастается, какие компании используют их продукт
Бонусом список ссылок, где Redis скромно хвастается, какие компании используют их продукт
А теперь давайте перейдем к фичам.
Redis выделяет такие фичи как поддержка откатов без потери данных, различных типов данных, паролей, логинов, TLS, транзакций, ещё и стримы есть и, как раз-таки, асинхронные взаимодействия.
А что есть в бесплатной версии Redis? Абсолютно те же фичи! Но есть один нюанс.
Типичный минус российского разработчика в текущих реалиях, но мы не пальцем деланы и умеем это обходить.
Так что идем дальше — сразу в статистические сравнения.
Если не смотреть всякие бенчмарки с сайта Hazelcast, где он сравнивается с Redis, которые, наверняка, очень объективные, то мы возьмём DB-Engines Ranking. Это топ, где они посчитали Hazelcast на 10 баллов, а Redis — на 182 балла, просто сравнив.

В этом исследовании Redis расположили на первом месте в key-value хранилищах и на шестом в общем зачёте.
Там очень много сравнений, вы можете посмотреть сами. Но я хотел бы отметить то, что Redis находится на шестом месте в общем зачёте, но при этом борется с такими мастодонтами как Oracle, MySQL, PostgreSQL и MongoDB.
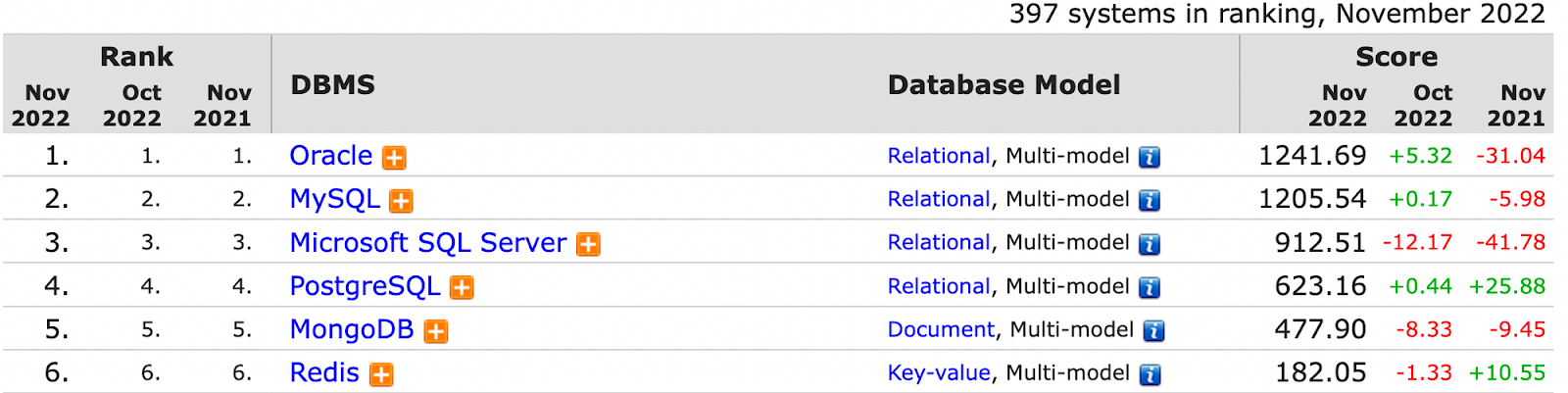
Колоссальная конкуренция, но Redis там находится на довольно высокой позиции.
Поэтому мы решили переехать с Hazelcast именно на Redis. Нам было важно то, чтобы это было безопасно и отказоустойчиво — мы же здесь за этим собрались? Забегая вперёд скажу, что нам нужно было просто «глупое» решение, которое записывает в кэш данные и забирает их в кэш. Среди всех решений, которые мы смотрели, подходящим для этого как раз-таки оказался Redis.
Ну, выбрали мы его и что дальше? А дальше разберемся как его приготовить.
Способы готовки отказоустойчивого Redis
Есть несколько способов приготовить Redis и мы разберем каждый.
Standalone Redis
Начнем с базового — стандартный Standalone Redis. Это обычный кластер из 3 отдельно стоящих редисов: 1 мастер, 2 реплики — то есть там требуется три серверные машинки. Быстро, дёшево, сердито.

Наше приложение интегрируется с ним, пишет данные в мастер и они реплицируются в реплики.
Но есть нюанс — отсутствие отказоустойчивости, которое можно побороть, используя Sentinel Redis.
Sentinel Redis
Что это такое? Мы берём и поверх нашего класса Standalone Redis ставим «смотрящих», которые следят за состоянием кластеров. Если отвалилась машинка с мастером, они проводят голосование, назначают нового мастера из реплик, и кэши продолжают дальше прекрасно работать.

Следующее решение — это Redis Cluster для тех, кто любит хранить всё в одном месте.
Redis Cluster
Это шардированный реплицированный кластер, который работает по принципу, похожему на предыдущий, но заставляет нас делать дополнительные операции. Например, клиент, который пишет в базу, обязан вычислить нужный мастер Redis, чтобы записать данные в правильную ячейку (чем то похоже на HashMap в Java), а прошлые решения по стандарту придерживаются принципа «Пишем в мастер — читаем из реплик».
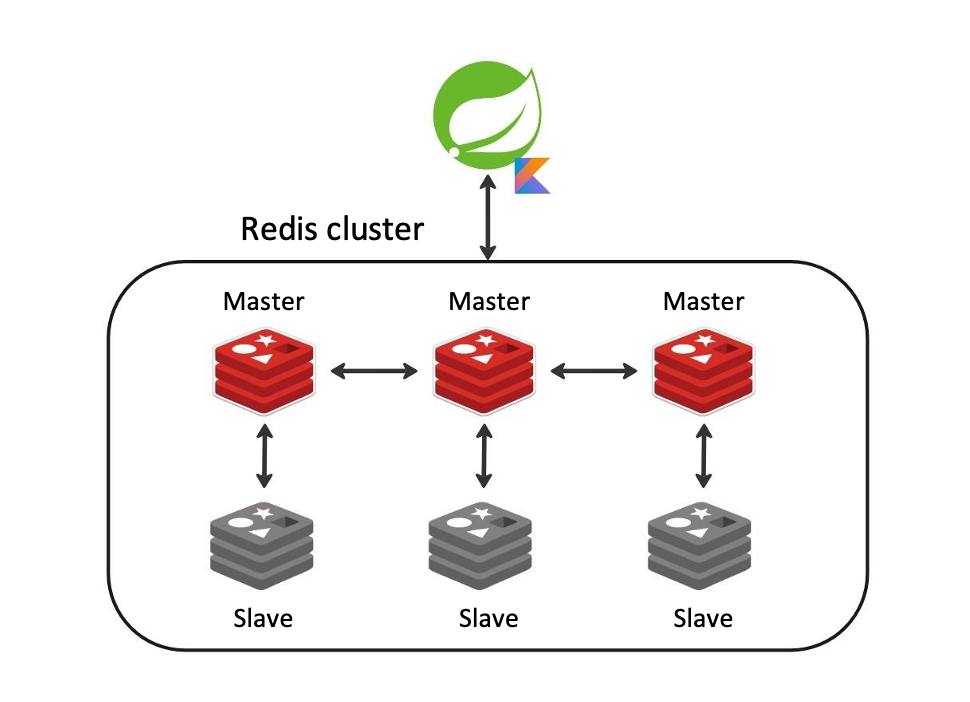
И да, вам действительно нужно 6 серверных машин, как на картинке, чтобы он работал правильно. На 3 сервера вы его не сможете развернуть, а не у каждой компании есть 6 серверных машин — это вообще-то много. Не берём в расчет то, что можно развернуть это на 3 машинах, раскидав мастера и реплики по разным хостам.
И кроме этого, вы не сможете проводить массовые операции, как например полную очистку базы данных — flushdb.
Managed Redis
Последнее решение, которое предоставляет Redis Labs. И это и есть то самое коммерческое решение, за которое просят денег.
Смысл в чём? Вы говорите, что я хочу Cluster Redis или Sentinel Redis, и за вас всё делают Redis Labs: разворачивают нужные вам кластера, а вам всего лишь нужно просто интегрироваться с ними и всё.
А как мы готовили отказоустойчивый Redis?
Взвесили все эти замечательные решения, и поняли, что нам нужен Sentinel Redis. Почему?
Потому что мы получаем отличную отказоустойчивость.
Нам нужно всего лишь 3 серверных машины, а не 6, что многовато.
Мы можем придерживаться действительно микросервесной архитектуры.
Мы можем использовать Database PerService.
У нас есть порядка 350 микросервисов и треть из них используют кэши. И это означает, что каждый из этой трети использует свой развёрнутый кластер Redis. Большое число, да?
В этом есть плюсы: мы обеспечиваем огромную отказоустойчивость, потому что если у нас что-либо из этого упадёт, то будет недоступна лишь маленькая часть приложения, а все остальные кэши будут работать. Мы не кладём всё в одно место.
Но есть и минус у этого решения — как минимум, сложно поддерживать.
Вы представляете, какое огромное количество Redis нужно администрировать, следить за ними, обновлять? Благо, у нас есть инструменты — это стандартные мониторинги Grafana, Redis, дашборды. Они рисуют красивые графики со всевозможными параметрами.
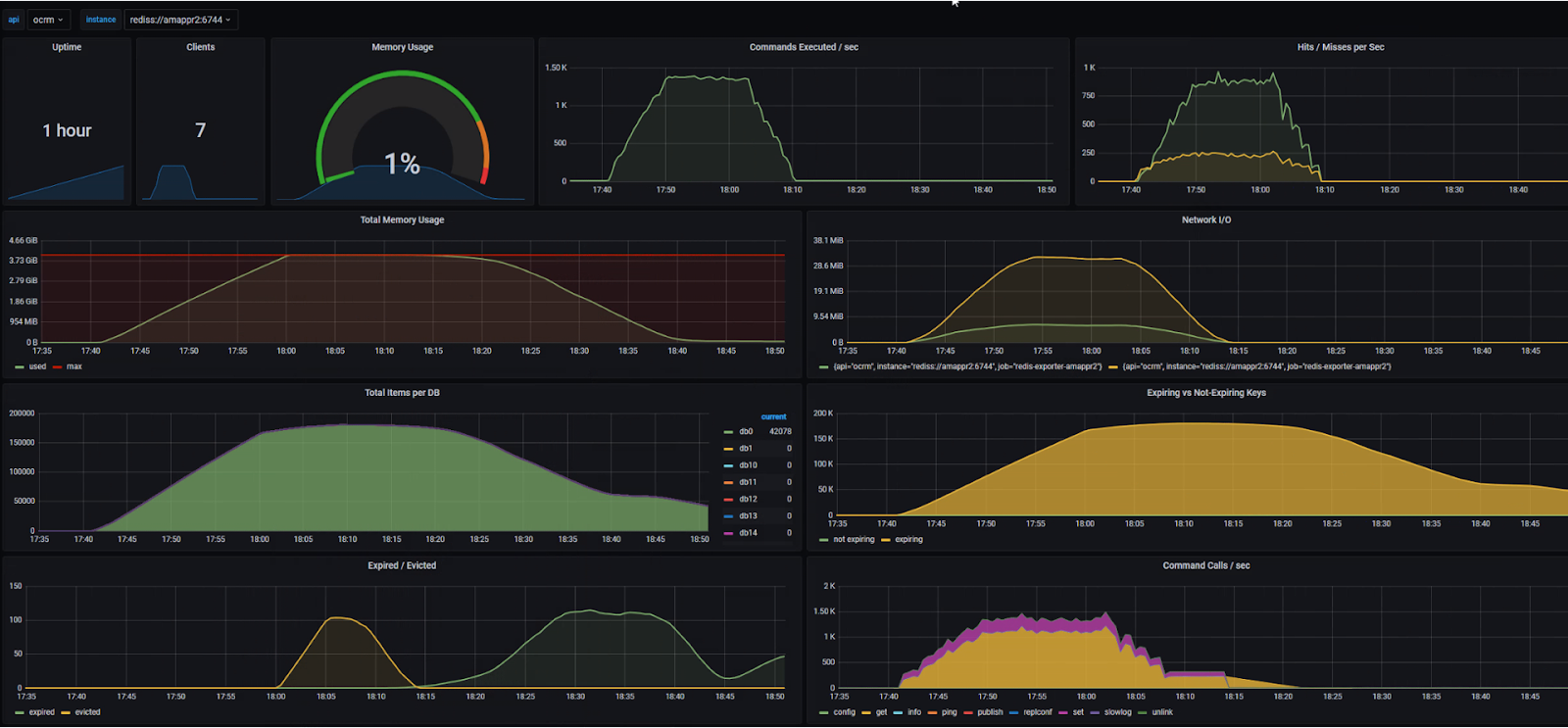
Кто заметил проблему — напишите в комментариях.
Как администрируем?
С админкой у нас всё было немного сложнее, что вылилось в несколько рабочих, и не очень, решений.
Redis Commander. Больше не работает, чем работает. Поставили, потестили, отказались.
Redis CLI. Если вы продвинутый пользователь Linux, то можете администрировать Redis через терминал.

Можете сделать абсолютно любые операции, которые хотите: и простые, и сложные, и просмотреть все данные.

На этом решении, кстати, построены все остальные админки.
Redis insight. Админка от Redis Labs. Поддерживает и визуализирует всё, что хочешь, но мне больше нравится то, что вы можете взять и посмотреть глазами, что конкретно кладётся в кэш — удобно для разработки. Однозначно, лайк!
Нюанс только один — что-то пошло не так и они выпустили v2 как клиентское приложение. Если у вас пять человек в команде — подходит нормально, но если у вас штат из 140 человек, то уже возникают вопросы. Настроить один раз в вебе гораздо удобнее, чем настраивать клиент каждому.
Redis Grafana app. Интересное, на мой взгляд, решение для администрирования. Встраивается в Grafana как приложение, может всё, что может Redis CLI, и очень легко автоматизировать вместе с мониторингами. Однозначно хороший выбор!
Поскольку мы придерживаемся концепции архитектура как код, у нас есть самописные Ansible-роли для раскатки админок, мониторингов, самого Redis, так что выкатка занимает обычно 3 строчки конфига и одну Ansible команду, довольно удобно. Ну и куда же без информации, а как это всё крутится — ответ в Docker-образах. Docker-образы используем Bitnami и с этим есть небольшая история, как мы контрибьютили в Open Source.
Мы всё прекрасно раскатали, поставили безопасные порты, но у нас не поднимаются контейнеры и диски. Почему? Потому что он пишет, что нам нужно указать не секьюрный порт.
Мы выяснили что в контейнере Sentinel был баг, а именно — нельзя было использовать только TLS-порт, нужно было всегда указывать фиктивный порт без TLS. Мы пошли допилили Docker-контейнер, и всё прекрасно заработало.
Вообще всем советую контрибьютить в Open Source. Это то, что позволяет разработчикам двигать индустрию вперёд.
И продолжая отвечать на свои же вопросы «А как мы готовили Redis?», отвечаю — мы взяли Redis Sentinel, приправили Ansible-скриптами, админками и мониторингами, запаролили и сделали взаимодействие зашифрованным.
Так как я всё же причислен к Java-коммьюнити, то рассказ был бы неполным если бы я не рассказал, а как же собственно микросервисы будут писать в Redis. Поэтому поговорим о таком замечательном фреймворке как Spring и его интеграции с Redis.
Как дела у Spring с Redis?
Есть Spring Starter, который уже интегрирует все вот эти вот функции кэша под собой. Но, как любая магия Spring, если мы собираемся делать что-либо нестандартное, мы сталкиваемся с нюансами.
Мы взяли аннотацию @Cacheable, навесили её над методом, и у нас всё прекрасно начало кэшироваться. Магия!

Но что, если мы хотим интегрировать это всё с Reactive или Coroutines (у нас для достижения ещё большей пропускной способности и отказоустойчивости почти все микросервисы на Реактиве)? Мы возьмём, повесим над ними эту аннотацию и что произойдет? А ничего хорошего — магия заканчивается.

Первое, что стоит учесть — это будет блокирующий вызов.
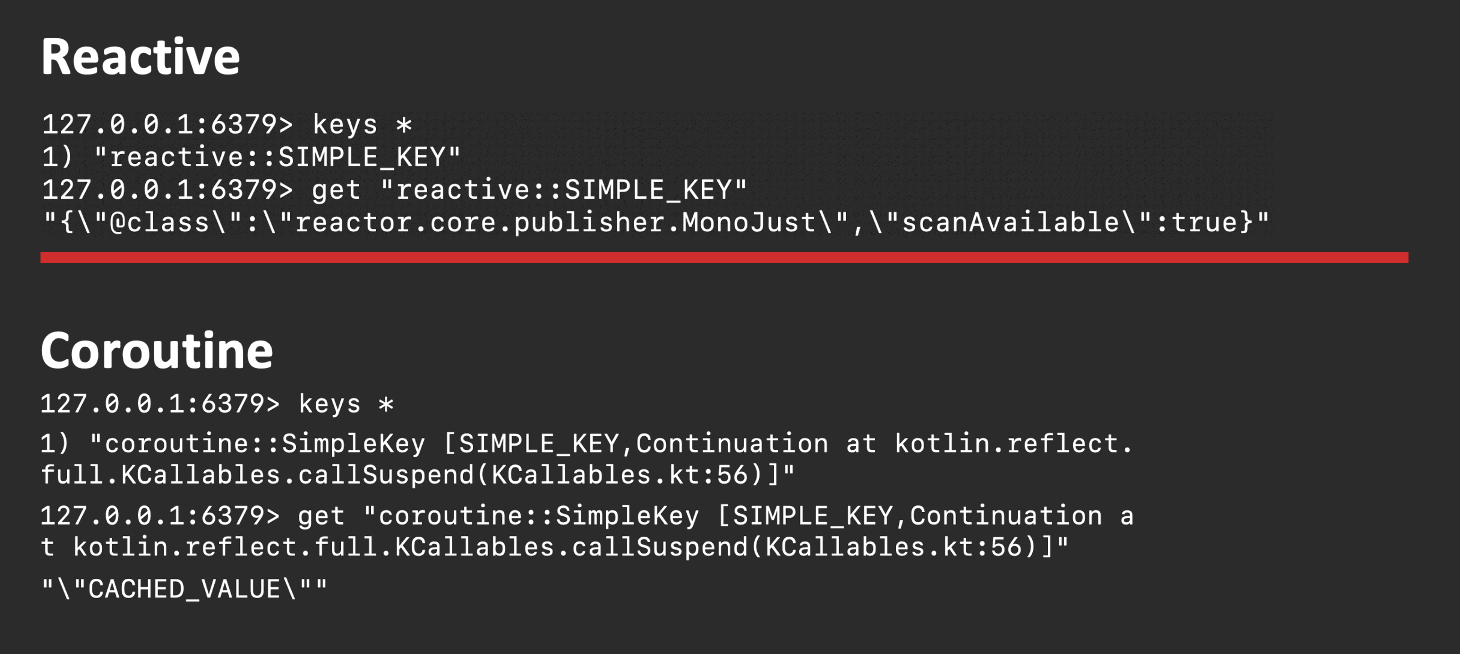
В случае с Реактивом это ещё и поломает вам второй вызов метода, потому что десериализовать полученную строку (выше красного) никак не получится. В случае с корутинами мы действительно сможем получить value.
Но посмотрите на ключ — он состоит из огромного текста и там даже есть стектрейс. Вот так Spring сериализует корутины.
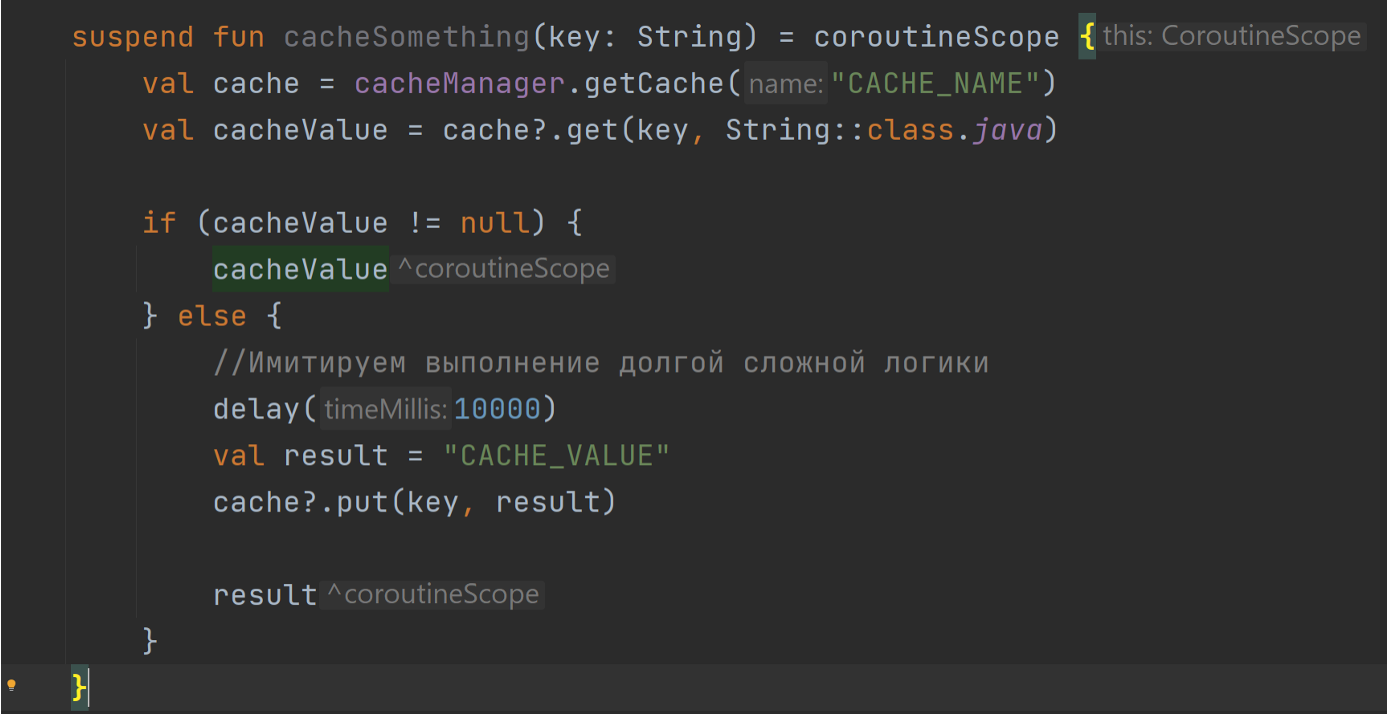
Что мы можем сделать, чтобы избавиться от этого? Мы можем написать код, получить его значение в кэше, проверить есть ли оно там, потом вернуть, если оно есть, а если нет, то вызвать бизнес-логику…
Но зачем оно нам надо, когда можно взять и написать свой Spring Starter, который будет работать так.
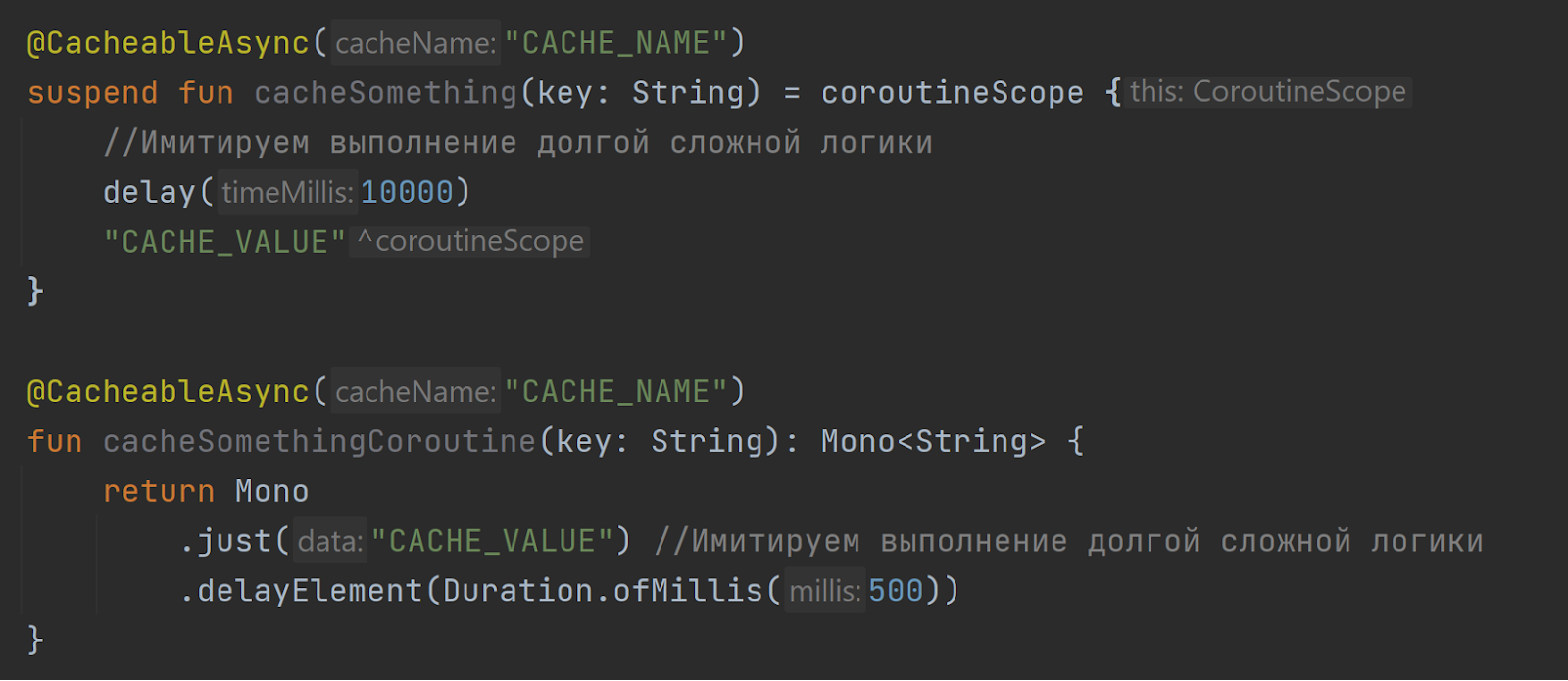
Он просто будет также вывешивать одну анотацию над методами Kotlin или Reactive, и всё будет прекрасно работать. Вот так мы побороли эту проблему со Spring и отсутствием реактивности.
И что нам это дало?
Для этого возьмём наш Hazelcast кластер. В пересчёте на облачные ресурсы (облако же это модная тема, да?) увидим, что на проде у нас было порядка 80 кластеров Hazelcast, из них каждый, как только раскатился, ел 520 Мб оперативной памяти.
Если мы возьмем голый кластер и попытаемся его развернуть, то нам нужно примерно 40 ГБ оперативной памяти.
А с Redis? А с ним мы уменьшили память до 3 ГБ.

И это дало нам следующее:
80 микросервисов уже у нас на проде;
в 200 раз снизилось потребление памяти на тестовой инфраструктуре;
на проде тоже снизилось, но не в 200 раз, а чуть поменьше;
на тестовой инфраструктуре затраты снизились вообще в 3 раза!
Что я в итоге хочу сказать? Не бойтесь экспериментировать и внедрять новые технологии! Это может быть очень даже выгодно.
Рекомендованные статьи:
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
