Как узнать больше о ваших пользователях? Применение Data Mining в Рейтинге Mail.Ru
 Любой интернет-проект можно сделать лучше. Реализовать новые фичи, добавить серверов, переделать интерфейс или выпустить новую версию API. Вашим пользователям это понравится. Или нет? И вообще, что это за люди? Молодые или в возрасте? Обеспеченные или скорее наоборот? Из Москвы? Питера? Сан-Франциско, штат Калифорния? И почему, в конце концов, те сто теплых пледов, что вы закупили еще в мае, пылятся на складе, а футболки с октокотами расходятся, как горячие пирожки? Получить ответы поможет проект Рейтинг Mail.Ru. Эта статья о том, как мы применяем data mining, чтобы ответить на самые сложные вопросыКонечно, рассказать обо всем, что мы делаем, в одном посте невозможно, поэтому я проиллюстрирую наш подход примером решения конкретной задачи — определение категории дохода пользователя. Допустим, вы ведете блог про автомобили и показываете в нем рекламу предложений дорогих автосалонов. Узнав, что ваш блог читают в основном не очень обеспеченные пользователи, вы пересмотрите свою стратегию и будете показывать рекламу запчастей. Для Оки.
Любой интернет-проект можно сделать лучше. Реализовать новые фичи, добавить серверов, переделать интерфейс или выпустить новую версию API. Вашим пользователям это понравится. Или нет? И вообще, что это за люди? Молодые или в возрасте? Обеспеченные или скорее наоборот? Из Москвы? Питера? Сан-Франциско, штат Калифорния? И почему, в конце концов, те сто теплых пледов, что вы закупили еще в мае, пылятся на складе, а футболки с октокотами расходятся, как горячие пирожки? Получить ответы поможет проект Рейтинг Mail.Ru. Эта статья о том, как мы применяем data mining, чтобы ответить на самые сложные вопросыКонечно, рассказать обо всем, что мы делаем, в одном посте невозможно, поэтому я проиллюстрирую наш подход примером решения конкретной задачи — определение категории дохода пользователя. Допустим, вы ведете блог про автомобили и показываете в нем рекламу предложений дорогих автосалонов. Узнав, что ваш блог читают в основном не очень обеспеченные пользователи, вы пересмотрите свою стратегию и будете показывать рекламу запчастей. Для Оки.
Откуда Рейтинг берет свои данные? Если нужно узнать пол пользователя, используются регистрационные данные Почты Mail.Ru (пользователей, которые обманывают при регистрации, довольно мало) и профили из социальных сетей. Нужно узнать город — IP в помощь. Определить, высокий доход у данного пользователя или не очень, намного труднее.
Чтобы начать, нам понадобится обучающая выборка. Получить такую выборку вполне реально — можно использовать результаты соцопросов, панельных исследований или данные дружественных проектов. Обучающая выборка для задачи определения категории дохода составляется на основании данных о зарплатных пожеланиях пользователей сервиса HeadHunter. Нам известен ряд характеристик пользователей из выборки, в том числе пол, возраст, город проживания, категория дохода, область занятости. И идентификатор Рейтинга Mail.Ru. Последнее особенно важно, потому что моделировать поведение пользователей из выборки мы будем, используя данные Рейтинга. Учитывая это, мы можем сформулировать задачу, которую будем решать.
Задача: используя обучающую выборку, содержащую порядка миллиона пользователей с известной категорией индивидуального дохода, разработать модель, позволяющую по данным Рейтинга предсказать, к какой из пяти категорий относится новый неразмеченный пользователь: 1 — низкий доход, 2 — доход ниже среднего, 3 — средний доход, 4 — доход выше среднего, 5 — высокий доход.
Для того чтобы получать статистику по сайту, нужно добавить на страницы код счетчика Рейтинга. Данные о каждом посещении собираются счетчиком и отправляются на сервер, где сохраняются в виде лога. Каждому посещению (синоним: хиту) в логе соответствует одна строка. Например, на картинке ниже первая строка соответствует посещению сайта hi-tech.mail.ru пользователем A21CE около полудня 9 апреля, а вторая строка — посещению сайта horo.mail.ru.
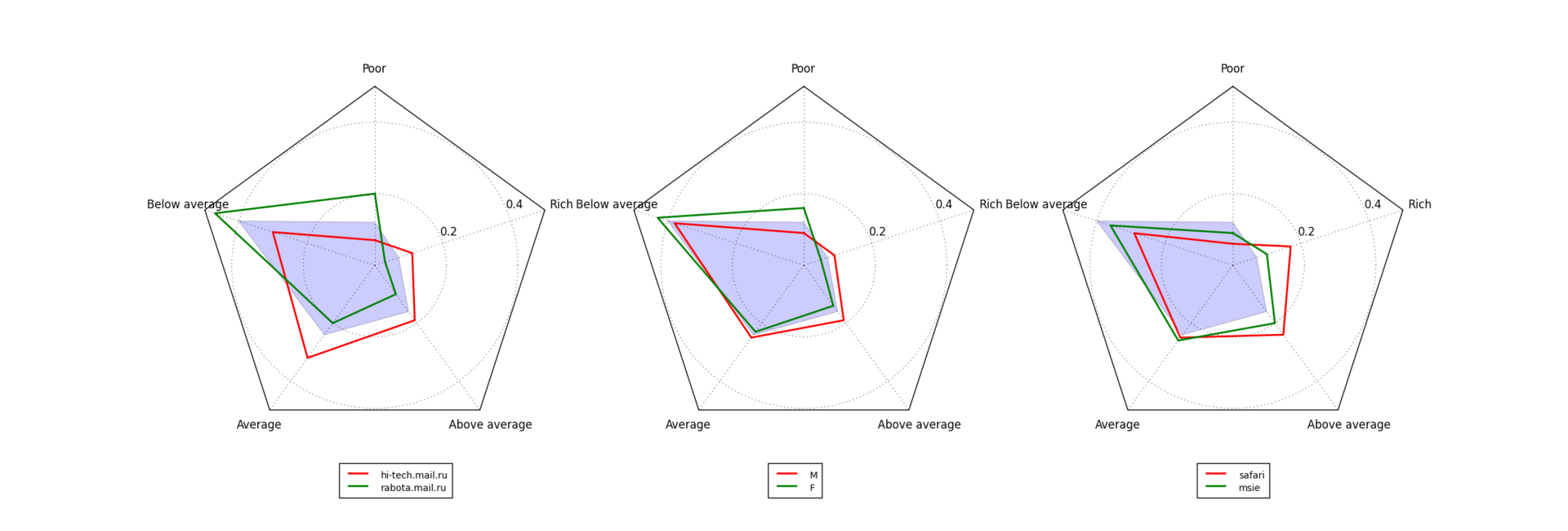
Оказывается, что имея достаточно таких данных о посещенных пользователем страницах, можно вполне успешно предсказать категорию дохода этого пользователя. Для иллюстрации идеи на картинке показаны радары распределений пользователей нескольких сайтов по категориям дохода.
 (кликабельно)
(кликабельно)
Априорное распределение отмечено синей областью — например, доля пользователей с доходом ниже среднего равна 0.39, а доля пользователей с высоким доходом равна 0.08. На левом графике видно, что для посетителей сайта hi-tech.mail.ru это соотношение другое: почти 12% пользователей этого сайта богатые, в то время как доля бедных меньше, чем в генеральной совокупности. Для сайта rabota.mail.ru ситуация обратная: среди людей, которые ищут работу, доля бедных больше, чем «обычно». Для многих других сайтов ситуация похожая — например, на сайты авиакомпаний больше ходят обеспеченные пользователи, а кредиты обычно ищут пользователи победнее. Следовательно, знание о том, какие сайты посещает пользователь, позволяет делать обоснованные предположения о категории дохода. В этом может помочь и другая имеющаяся в логах информация о пользователе, например, пол (средний график — у мужчин доход повыше) или используемый браузер (правый график — любители Safari внезапно побогаче людей, предпочитающих IE).
Подводим промежуточный итог. Вот такой получился план действий: анализируем сайты, посещенные пользователем, и другую доступную информацию, и делаем обоснованное предположение о категории дохода. Звучит просто. Но есть проблема: ручной анализ невозможен, потому что пользователей много. Десятки миллионов. А размер сжатого лога достигает 500МБ в минуту. Без data mining не обойтись.
Согласно процессу KDD (и любому из его аналогов: раз, два), решение задачи data mining начинается с feature engineering. Этот этап самый важный и одновременно самый трудоемкий. Мы выделяем признаки из полуструктурированного лога посещений страниц. На рисунке показаны дневные логи для трех реальных пользователей. На горизонтальной оси отложены минуты дня (0–1439), на вертикальной — секунды в соответствующей минуте (0–59). Каждая точка — посещение сайта. Для наглядности сайты показаны разными цветами. Пользователя с верхнего графика интересуют в основном знакомства (красные хиты соответствуют популярному сервису знакомств) и компьютерное железо (синие и зеленые хиты). Причем основная активность приходится на ночь (кто-то узнал себя?). Второй пользователь тоже не против познакомиться (зеленые хиты), но в рабочее время. Третий же тратит на это нерабочее время — вечер и предположительно обеденный перерыв.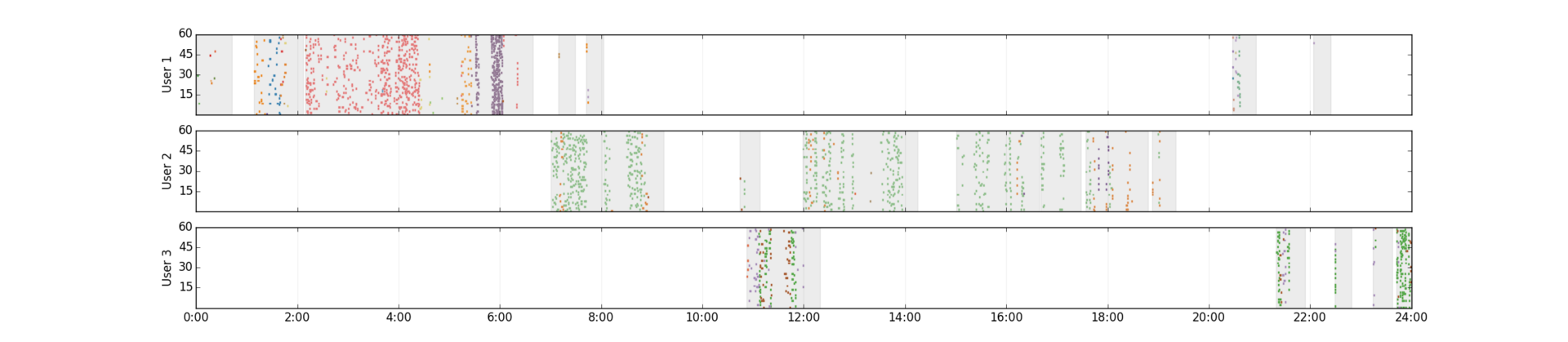 (кликабельно)
(кликабельно)
Хотя у представленных пользователей есть похожий интерес к знакомствам, паттерн поведения разный: различаются периоды активности, количество и частота хитов. Чтобы сгладить эту разницу, в web mining принято разбивать поток хитов пользователя на сессии — промежутки непрерывной активности в интернете. Существует множество подходов к выделению сессий, мы остановились на следующих простых правилах:
(1) два хита относятся к одной сессии, если интервал между ними не превышает 20 минут (2) сессия длится 20 минут после последнего хита
Сессии наших пользователей на графиках выделены серым. На основании полученных сессий мы преобразуем историю посещений пользователей в матрицу, которую можно будет подать на вход алгоритмам обучения машин. Каждая строка в этой матрице соответствует пользователю, каждый столбец — признаку. Хабр не резиновый, поэтому тут я остановлюсь на самом простом из используемых нами вариантов: каждый признак — это слово, извлеченное из URL посещенной страницы. Например, уже знакомый нам кусок лога:

преобразуется в такую матрицу:
hi-tech mail horo example A21CE 1 2 2 0 B0BB1 0 1 0 1 Значением признака для конкретного пользователя в данном случае является количество сессий пользователя, в которых встречался этот признак. В принципе, значение признака можно бинаризовать, используя порог, или применить один из многих вариантов взвешивания, например по idf. Эксперименты показывают, что любая из этих нормализаций приводит к улучшению качества модели. Мы остановились на бинаризации. Не все признаки одинаково полезны. Скажем, наличие ненулевого значения признака page ничего не говорит о доходе пользователя, потому что page — просто техническое слово, обозначающее нумерацию страниц. Напротив, пользователь с ненулевым значением признака jewellery, возможно, ищет ювелирные украшения, и это поможет классифицировать её в категорию «богатые». При анализе признаков мы используем следующие соображения:(1) признак должен давать статистически достоверные оценки. Для проверки используются например мультиномиальные тесты (2) признак должен быть информативным. Для проверки используются информационные критерии, такие как redundancy
На рисунке показаны признаки, лучше всего отражающие каждую из категорий. Например, большая доля богатых пользователей имеют ненулевой вес в колонке матрицы, соответствующей признаку IT-news. Видимо, быть айтишником довольно прибыльно. Категории бедных же больше подходят признаки, связанные с низкоквалифицированной работой («продавец-консультант», «без опыта»).
 (кликабельно)
(кликабельно)
Отобрав только информативные и статистически достоверные признаки, получаем матрицу меньшего размера, которая станет входными данными для алгоритмов обучения машин. Элементом этой матрицы x[i, j] является вес j-го признака у i-го пользователя. Ради справедливости замечу, что кроме обучающей выборки, отражающей посещенные пользователем страницы, мы строим еще несколько — например, по демографическим данным и по контенту страниц. Для каждой обучающей выборки строится отдельная модель, после чего все модели комбинируются.
Специфика нашей задачи классификации состоит в том, что матрицы данных обладают большой размерностью (миллионы строк и десятки тысяч столбцов) и при этом являются сильно разреженными. Поэтому используются реализации алгоритмов обучения, способные работать со sparse матрицами. Здесь мы не изобретаем велосипедов — используются ансамбли линейных моделей с cross-entropy функциями потерь: logistic regression и maxent. Такие модели хороши по ряду причин. Во-первых, кросс-энтропия натурально возникает при достаточно общих предположениях, в частности, когда распределение p (x | class) принадлежит экспоненциальному семейству распределений (подробности можно найти в Pattern Recognition and Machine Learning // C. Bishop и Machine Learning: A Probabilistic Perspective // K. Murphy). Во-вторых, алгоритм SGD позволяет эффективно обучить такую модель, в том числе и на разреженных данных. В-третьих, сериализация модели сводится к простому хранению вектора весов, следовательно, сохраненная модель занимает всего O (количество признаков) памяти. В-четвертых, применение модели требует только быстрого вычисления decision function. Для нашей обучающей матрицы строим ансамбль линейных моделей, используя bagging. Итоговое предсказание делается на основании голосования ансамбля.Для оценки качества классификации в наших задачах основной метрикой служит Affinity (более употребительное название — Lift). Эта метрика показывает, насколько наша модель лучше рандома. Для примера рассмотрим категорию богатых пользователей. Доля таких пользователей в общей популяции составляет 7%. Если наша модель при приемлемом охвате (Recall) дает точность (Precision), равную 21%, то Affinity считается как Affinity = 0.21 / 0.07 = 3.0. При этом recall настраивается так, чтобы выходное распределение пользователей по категориям примерно совпадало со входным. В таблице показаны метрики кросс-валидации построенной модели. Видно, что модель дает очень неплохой результат.
Class
Исходное распределение
Полученное распределение
Precision
Recall
Affinity
1
69720 (0.125)
18609 (0.033)
0.281
0.075
2.245
2
223358 (0.400)
274519 (0.492)
0.492
0.605
1.229
3
134024 (0.240)
93075 (0.167)
0.316
0.220
1.317
4
91448 (0.164)
118506 (0.212)
0.246
0.319
1.502
5
39353 (0.071)
53194 (0.095)
0.233
0.315
3.301
Посмотрим подробнее на результаты классификации. Понятно, что в нашем случае из-за упорядоченности категорий не все ошибки одинаково серьезны. Не страшно присвоить «богатому» пользователю категорию «выше среднего», совсем другое дело — обозвать его «бедным». На рисунке показана карта Affinity для сравнения предсказанной и реальной категории пользователей. Значение каждой ячейки вычисляется как: 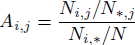 Иными словами, доля пользователей i категории среди тех, кого мы предсказали как j, разделенная на долю пользователей i категории в генеральной совокупности. На диагонали таким образом имеем Precision / TrueFraction = Affinity. Идеальный классификатор дает ненулевые значения элементов такой матрицы только на диагонали. Из рисунка видно, что в нашем случае соседние категории могут перемешиваться (3 «квадрата»: богатые — выше среднего, средние-выше среднего, бедные-ниже среднего), но при этом доля грубых ошибок довольно мала. Учитывая, что само деление на категории дохода довольно условное (попробуйте честно определить свою), размытие между соседними категориями вполне объяснимо. Еще заметим, что лучше всего определяются крайности — богатые и бедные, а хуже всего — категория средних. Это удачно, потому что именно крайности обычно интересуют бизнес (кто моя аудитория — эконом или премиум?).
Иными словами, доля пользователей i категории среди тех, кого мы предсказали как j, разделенная на долю пользователей i категории в генеральной совокупности. На диагонали таким образом имеем Precision / TrueFraction = Affinity. Идеальный классификатор дает ненулевые значения элементов такой матрицы только на диагонали. Из рисунка видно, что в нашем случае соседние категории могут перемешиваться (3 «квадрата»: богатые — выше среднего, средние-выше среднего, бедные-ниже среднего), но при этом доля грубых ошибок довольно мала. Учитывая, что само деление на категории дохода довольно условное (попробуйте честно определить свою), размытие между соседними категориями вполне объяснимо. Еще заметим, что лучше всего определяются крайности — богатые и бедные, а хуже всего — категория средних. Это удачно, потому что именно крайности обычно интересуют бизнес (кто моя аудитория — эконом или премиум?).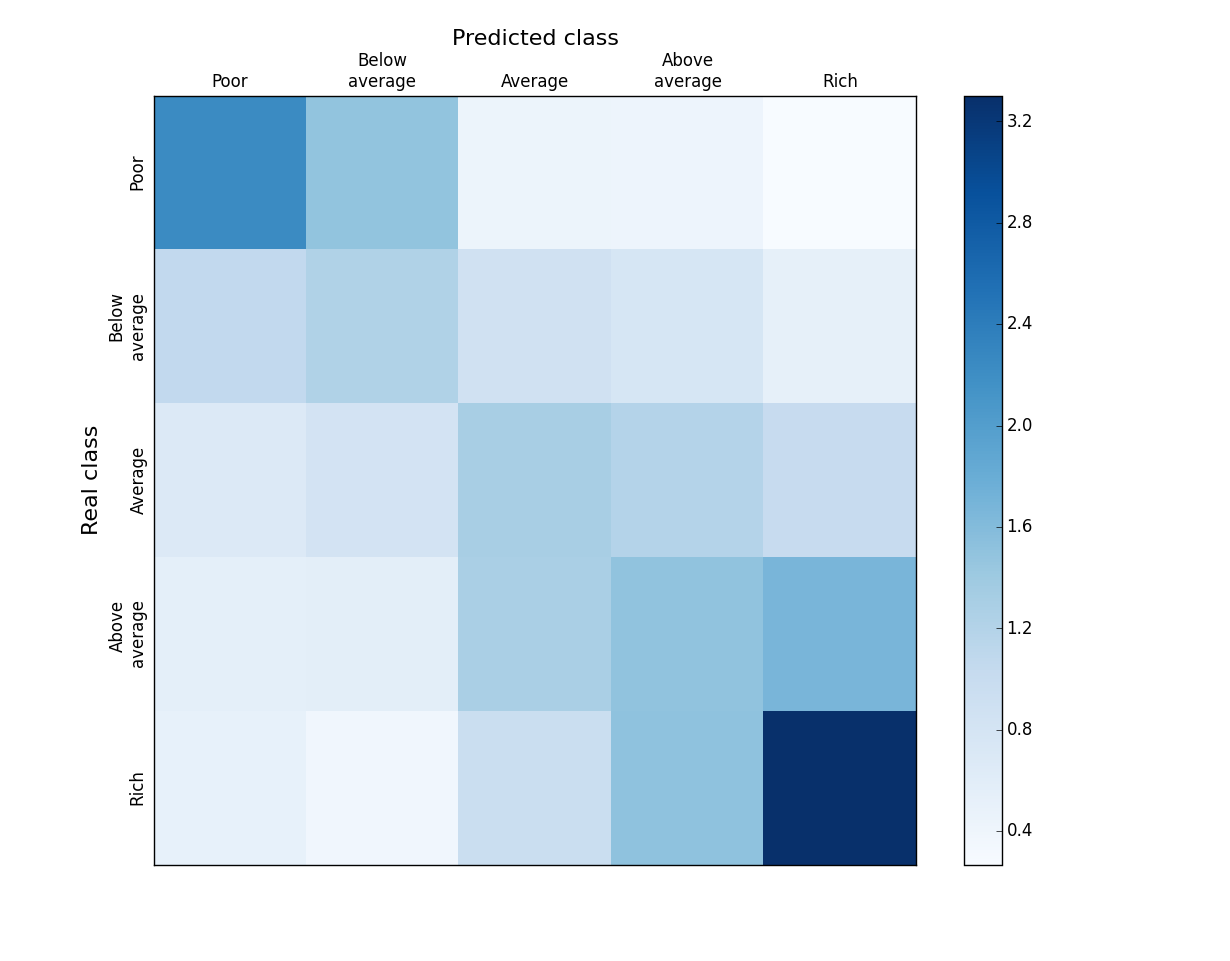
Последним этапом процесса является применение модели на неразмеченных пользователях. Таких пользователей у нас десятки миллионов, для каждого из них вычисляется вектор выбранных признаков и применяется обученная модель. Финальная проверка качества модели осуществляется на основании данных о пользователях, участвующих в панельном исследовании. Предсказанная категория дохода записывается в cookie Рейтинга. Счетчики читают эти куки и подсчитывает статистику по вашему сервису. Именно эту статистику вы видите в интерфейсе и можете использовать для принятия бизнес-решений. Задача замкнулась.
В статье на примере задачи определения категории дохода я описал подход, применяемый для решения задач классификации пользователей проекта Рейтинг Mail.Ru. Обзорный формат статьи не позволил мне углубиться в технические детали, например, в тонкости реализации тех или иных стадий процесса (в основном на Hadoop). Также для краткости пришлось опустить несколько важных подзадач — фильтрацию ботов и пользователей-однодневок, конструирование семантических признаков, составление ансамблей из моделей, построенных для разных обучающих выборок, подход к валидации построенных моделей, и еще много чего. Это уже немного другие истории, оставим их для будущих публикаций.
