Как увидеть на снимке лес? Наш опыт сегментации снимков Sentinel-2

Перед капитальной застройкой большой территории необходимо её детально исследовать. В зависимости от вида участка серьёзно варьируется стоимость строительства, предварительной обработки местности и многих других сопутствующих работ.
Чтобы серьезно минимизировать издержки на строительство объектов, некоторые компании используют спутниковые снимки с размеченной территорией. Такой метод исследования участка в разы дешевле проведения экспедиций, с помощью которых и в настоящее время часто решают эту задачу.
Но как получить полностью размеченные по необходимым критериям спутниковые снимки?
Мы в компании «Цифровое проектирование» решаем различные задачи сегментации. На каждой подробно остановимся в наших следующих материалах. В этом же тексте расскажем про наш опыт нахождения леса на спутниковых снимках, как пытаемся построить ML модель по разметке леса и про то, что уже удалось добиться на данном этапе, а к чему мы еще только стремимся.
Какая перед нами стоит задача?
Нам необходимо разработать алгоритм автоматической разметки леса довольно больших по площади областей для последующего анализа территории.
Помимо того, что нам необходимо разметить, где находится лес, нужно ещё классифицировать его на хвойный и лиственный. В дальнейшем планируется проводить оценку биомассы, для чего также будут нужны снимки с размеченным лесом. Важное условие на текущем этапе — распознавание леса должно проводиться по открытым данным, которые можно найти в интернете.
Мы использовали многоспектральные снимки спутников дистанционного зондирования Земли Sentinel-2, которые созданы Европейским космическим агентством. Спутники были запущены в 2015 году и продолжают функционировать до сих пор.
Почему именно Sentinel-2? В этом решении мы руководствовались несколькими, важными для нас, факторами.
Новые снимки Sentinel появляются достаточно часто. Для одной и той же территории снимок может обновиться уже через 5 дней. К тому же, они распространяются свободно, что для нас, как вы уже поняли, было критически важно. Также есть интерфейс, с помощью которого можно скачать нужный снимок. Правда, не очень удобный, но главное — он есть. Можно найти и API под Python и CLI, который позволяет легко автоматизировать запросы даже к архивным данным Sentinel.
Большое преимущество Sentinel-2 — они видят 12 спектральных каналов. Спутники видят не только каналы видимого спектра (синий, зеленый и красный), но также фиксируют невидимые глазу спектральные диапазоны (например, NIR и SWIR), что в контексте распознавания леса может быть довольно критично.
Ещё одним преимуществом снимков Sentinel-2 является их высокое разрешение в рамках основных RGB каналов и ближнего инфракрасного диапазона — 10 метров на пиксель. По остальным каналам, правда, разрешение хуже — 20 или 60 метров на пиксель, но для нас они были уже не столь важны. Для сравнения — у некоторых других агентств снимки по каналам RGB + ближний инфракрасный идут с разрешением 30 метров на пиксель, что серьезно усложняет задачу построения точных контуров леса. Коммерческие продукты, такие как WorldView-3, могут предложить существенно лучшее разрешение (~30 см панхроматический канал, 1.24 м — RGB). Но, как уже упоминалось, такие продукты на текущем этапе проекта не используются.
Как решаются подобные задачи?
Классический подход заключается в расчёте множества различных индексов и сравнении их с некоторыми эмпирически подобранными пороговыми значениями.
В нашей работе мы использовали один из самых известных индексов для определения леса и прочей растительности — нормализованный разностный вегетационный индекс (NDVI — normalized difference vegetation index). Это числовой показатель качества и количества растительности на участке.
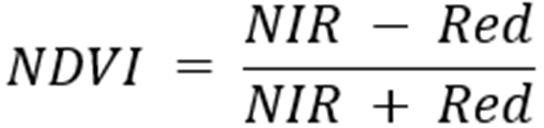
NIR — ближний инфракрасный, Red — красный канал
Почему нормализованный? В нем есть деление на сумму. Получившиеся вследствие деления значения NDVI находятся в интервале [-1, 1]. Значения NDVI от -1 до 0 это объекты неживой природы и инфраструктуры — снег, вода, песок, камни, дома, дороги и т. п. Значения для растений лежат в диапазоне от 0 до 1.
А почему вегетационный? Потому что значения индекса определяются тем, как растения отражают и поглощают световые волны разной длины. Если мы посмотрим на график отражения листа дерева в зависимости от длины волны, то в красной области спектра будет максимум поглощения солнечной энергии хлорофиллом, а в ближнем инфракрасном спектре, который уже не виден человеческим глазом, находится максимум отражения солнечного света клеточными структурами листа.
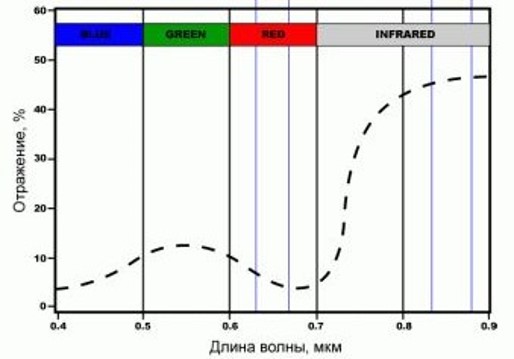
Поэтому, чем больше разница между NIR и Red, тем большее значение количества хлорофилла находится в соответствующем пикселе. Взаимосвязь этих каналов друг к другу позволяет четко отделять растительность от иных природных объектов.
Этот индекс настолько широко и так давно используется, что про него даже можно найти мемы.

Естественно, у такого классического способа имеется ряд недостатков:
- высокое значение может быть не только там где лес, но и где любая другая растительность;
- пороговые значения, которые используются, чтобы различать между собой разные типы растительности, варьируются от кадра к кадру в зависимости от особенностей местности и времени съёмки;
- использование вегетационных индексов наиболее эффективно при анализе в динамике, когда есть возможность сравнить снимки за разные даты, построить график и сделать выводы. Но для этого нужно много хороших снимков, что затрудняет задачу минимум в виду периодической облачности на доступных снимках;
- из-за большого количества эмпирически обоснованных методик, применимых лишь в достаточно ограниченных условиях, процесс плохо поддается автоматизации.
Однако для нас все недостатки перевесил один значительный плюс — относительно высокое разрешение и доступность снимков при использовании данных Sentinel-2.
Ищем данные
Для решения поставленной задачи мы использовали методы машинного обучения. Нам необходимо было создать две модели. Одна из них по снимку определяла бы, где находится лес, а другая сегментировала его на хвойный и лиственный.
Благодаря такому подходу нам не нужно самостоятельно подбирать сложные правила взаимодействия всех индексов — модель это сделает за нас, на основании данных. Данных, которые предстояло найти…
Мы занялись поисками территории, для которой уже известно — где лес, а где не лес. Первые данные, которые мы обнаружили, нас сильно воодушевили — это была полностью размеченная карта Словении.
Сразу же стал очевиден и первый камень преткновения. Словения не очень большая страна, особенно в сравнении с Россией или даже отдельными субъектами РФ. Однако, как оказалось позднее — это совсем не главная проблема.
По найденным данным была обучена модель, и мы получили очень высокие значения метрики intersection-over-union (метрика степени пересечения между двумя множествами). Грубо говоря — точность определения леса этой моделью на той части разметки, которая не участвовала в процессе обучения. И она составила 91%!
Не буду долго тянуть и скажу сразу — в дальнейшем значение этой метрики у нас только падало. Однако в процессе работы результаты становились осмысленней.
Важно отметить, что мы использовали несколько аугментаций (техника искусственного увеличения исходного набора данных) датасетов — горизонтальное / вертикальное отражение и случайный поворот на 90 градусов. С гаммой, яркостью и прочими классическими аугментациями на начальном этапе было принято решение не работать.
«Естественной» аугментацией также послужили снимки за разные даты для одной и той же территории, которые мы использовали в работе. Какие-то искажения это явно дало, но они максимально естественные (листва желтеет, появляется снег и т.п.).
В качестве модели мы взяли сверточную нейронную сеть, потому что она позволяет «из коробки» учитывать как взаимное пространственное расположение пикселей, так и расположение «в глубину» (все спектральные каналы). Основная архитектура модели — U-Net с кодировщиком ResNet-34.
Первые результаты давали большие надежды — в отдельных случаях только на основе разметки модель могла делать предсказания лучше, чем сама разметка. Хотя последняя проходила много стадий валидации, в том числе проводились и экспедиции.
По изображениям вы можете увидеть, что модель сразу же начала отбивать правильно те места, где леса нет.

Ground Truth маска

Предсказание модели
Но в применении к участку, которого, напомним, в тренировочной выборке не было, получился совершенно бессмысленный результат. Если ещё поиграться с чувствительностью модели либо нормализацией кадров, то появлялись некоторые пятна. В основном же модель показывала, что либо везде находится лес, либо леса нигде нет. Важно также подчеркнуть — дело не в несбалансированности целевых классов, мы проверили это, регулируя соответствующие веса целевой функции.
Основная проблема в том, что леса в Словении совсем не похожи на леса в России (а именно — Сибири). Там растут другие деревья, на других почвах и их характеристики в разных спектральных каналах не похожи на то, что можно наблюдать в Сибири.
Могли возникнуть предположения, что спутник снимал под другим углом и были искажения, из-за чего и появилась разница. Однако у Sentinel серьёзная процедура нормировки данных — и по уровню яркости, и по углам. Есть понятные умозрительные представления, почему критическим является именно состав леса и состав почвы. Достоверно известно, что спектральные свойства разных почв (разной влажности, разного состава) отличаются.
Никаких размеченных данных по Сибири нам найти не удалось, поэтому было решено добавить к имеющейся разметке Словении кусочки ручной разметки (т.е. выполненной своими силами) по регионам, которые похожи на Сибирь. К чему мы с новым вдохновением и приступили.
Размечаем вручную
Чтобы улучшить предсказания по Сибири и сохранить масштабируемость, для ручной разметки мы выбрали участки в Иркутской и Архангельской областях. Области были определены из соображений простоты ручной разметки и наибольшего сходства с интересующим нас регионом. Мы решили провести независимую разметку тремя людьми, что должно было помочь компенсировать систематические ошибки в работе каждого.

Разметка Иркутской области

Разметка Архангельской области
На этом этапе у нас возникло несколько дилемм, которые необходимо было решить.
Считать ли лесом отдельно стоящее дерево? Поскольку дальнейшим этапом работы модели будет оценка биомассы, функционально мы решили считать лесом более-менее плотно стоящие друг к другу деревья. Поэтому, при разметке отдельное дерево мы могли пропустить.
Как добиться того, чтобы все участники процесса трактовали снимок одинаково? Практически невозможно прийти к универсальному гайдлайну «что такое лес, а что такое не лес». Поэтому наша идея заключалась в диверсификации подходов. Попытки по-разному комбинировать наборы данных показали, что наши систематические ошибки могут хорошо друг друга компенсировать.
Чтобы исключить вариант обучения модели работать с конкретным кадром и конкретным регионом, мы не стали брать для ручной разметки именно тот регион, с которым в дальнейшем будем работать. В таком случае сохранялась возможность для последующей обобщаемости нашей модели.
Поскольку те небольшие участки, что мы разметили, нельзя сравнить по объему с имеющимся датасетом Словении, на этом этапе параллельно мы разрабатывали модели на основе Random Forest, которые можно использовать для классификации каждого отдельного пикселя без учета «оконных признаков». Даже при небольшой ручной разметке «набегает» приличное количество размеченных пикселей, которые складываются в солидный для обучения RF датасет.
И снова первые результаты были очень воодушевляющие! Модель, обученная только по Словении, давала бессмысленные результаты. Но модель, обученная по совокупности выборок, оказалась способна исправить некоторые ошибки ручной разметки! Общая информация о том, что такое лес из Словении и специфичный небольшой кусочек информации из Архангельской и Иркутской областей в сумме позволили получить такой результат. Для визуализации полученных результатов мы использовали бинарную маску и карту вероятностей.

Снимок
Разметка

Предсказание модели: бинарная маска

Предсказание модели: карта вероятностей
Казалось бы, все отлично — наша нейросеть уже видит лучше нас! Ученик превзошел учителя! Однако, на деле это не совсем так.
К сожалению, было много участков, где смысл результатов был весьма сомнителен. И на одном из примеров (кусок Иркутской области) можно продемонстрировать те трудности, с которыми мы столкнулись.

Предсказание модели

Ручная разметка
Явно выраженной разницы между ручной разметкой и предсказанием модели нет. Важно понимать, что на подложке здесь не снимок Sentinel с 10-метровым разрешением, а снимок из Яндекса, в который мы иногда подглядывали при разметке.
Мы снова принялись искать способы улучшения нашей модели.
Добавляем еще данных
В процессе последующих поисков были найдены новые данные с разметкой леса Европы (от Великобритании и Португалии до Финляндии и Турции). К тому же — на хвойный и лиственный. Показалось, что они в корне изменят всю дальнейшую работу.

Для работы мы выбрали достаточно обширные территории Финляндии и Норвегии, леса которых похожи на сибирские.
Однако, и попытка распознавания этих данных нейросетями или Random Forest как «лес/не лес», и попытка распознавания как «хвойный/лиственный», хоть и давали какие-то, порой осмысленные, результаты, но в итоге все они были отбракованы. Несмотря на весьма неплохое качество, подходящее разрешение и более высокие метрики моделей, данные снова оказались неприменимы для качественного решения поставленных задач в целевом регионе.
Из чего мы пришли к разочаровывающему для нас итогу — леса Европы не похожи на леса Сибири. Это объясняется и почвой, и прочими геоботаническими соображениями. После множественных просмотров мы заключили, что ни данные Словении, ни данные Финляндии и Норвегии не делают предсказания модели лучше. Модели, обученные только на нашей ручной разметке, давали гораздо более осмысленный результат.
Мы приняли решение отложить данные европейских стран и сделать дополнительную ручную разметку уже по Сибири. Для неё отбирались регионы таким образом, чтобы учесть самые типичные ошибки нашей модели. Была выдвинута гипотеза, что имеет смысл выделить наиболее очевидные участки хвойного и лиственного лесов для разметки. Потому что даже на снимке с разрешением 1 метр на пиксель далеко не всегда понятно, какой лес перед тобой — хвойный или лиственный.

Предсказания модели до использования точечной разметки

Предсказания модели после использования точечной разметки
Идея с точечной разметкой, которая указывает модели её типичные ошибки, в результате показала себя эффективной. Но очевидно также и то, что остаются зоны, на которых нет леса, но обе модели размечают его там.
Для того, чтобы решить эту проблему, мы использовали второй снимок. Как я и сказал в начале, вегетационные индексы наибольшую разницу между разными классами поверхности дают именно в динамике, и мы решили применить это способ.
Однако в свободном доступе есть только инструмент, который не позволяет загрузить сразу много кадров с приемлемым уровнем облачности за необходимые даты и требует большое время ожидания для выгрузки архивных данных, кроме того, сервис попросту иногда глючит. Разумеется, есть и продукт без подобных ограничений, но за определенный прайс, а мы, как вы помните, работаем только с открытыми данными.
Поэтому, мы не могли использовать длинный временной ряд снимков, однако, как выяснилось, всего одного дополнительного снимка за другой вегетационный период оказалось вполне достаточно. При одновременном использовании сразу двух снимков результаты действительно намного улучшились. На тех проблемных участках, которые раньше распознавались как лес, новая модель уже не делала подобных ошибок. Мы избавились от ложноположительных срабатываний довольно серьёзно.

После применения второго снимка результаты серьезно улучшились
На этом этапе мы стали использовать летние и осенние снимки, потому что наиболее заметная динамика в разных участках спектра происходит именно на этом переходе.
На ранних этапах у нас еще было предположение использовать зимние снимки для того, чтобы размечать лес на «хвойный/лиственный». Для этого предполагалось использовать не вегетационный, а снежный индекс и смотреть на снежное покрытие и соотносить его с маской леса.
После проверки ряда гипотез выделить надежный критерий, по которому было бы удобно размечать разные типы леса с использованием зимних снимков, не получилось. Во многом это связано с тем, что снег — явление не постоянное. Его может сдуть, он ложится не только на лес и не всегда лежит равномерно. Поэтому, от этой идеи мы решили пока что отказаться.

Снимок

Результаты предсказаний моделей
Еще один пример. На снимке желтым показаны результаты работы последней модели, фиолетовым — промежуточной, красным — то, что отбивалось как лес первой моделью. Как видите, тут тоже довольно серьёзные улучшения.
Промежуточные итоги
Наша работа ещё далека от завершения, но на данном этапе мы уже пришли к нескольким важным для нас выводам.
- Если хотите доверять разметке — сделайте её сами. В разметке всегда будут ошибки, и лучше знать их природу. Не всегда удаётся формально определить строгие критерии правил разметки (например, 5 рядом растущих деревьев — это лес?), однако это не страшно. Систематические ошибки создателей разметки, скорее всего, будут компенсировать друг друга, оставляя «в среднем» то, что согласуется со здравым смыслом большинства.
- Временные ряды (даже из двух снимков) в разы улучшают предсказания. Если у вас есть возможность использовать несколько снимков — не пренебрегайте ей.
- Не всегда лучшее значение формальной метрики совпадения двух множеств свидетельствует о лучшем результате на качественном уровне. Так, например, предсказание модели может быть очень «дырявым» и походить на пыль, однако иметь высокое значение IoU. Сейчас мы пытаемся придумать, чем можно заменить нашу метрику, чтобы оперировать более приближенными к бизнес-логике конкретными цифрами. Кроме того, различные варианты постобработки предсказаний модели (например, обычное сглаживание или более продвинутые методы, такие как Conditional Random Fields) могут увеличить качество результата.
Потенциал для последующего развития нашей модели обширный. К примеру, мы надеемся, что наш опыт позволит в будущем оценивать, как восстанавливаются леса после серьезных пожаров.
В настоящий момент мы работаем над внедрением в пайплайны данных цифровой модели рельефа (DEM) и ожидаем, что это даст нам большой прирост точности. Также мы улучшаем наши практики проведения экспериментов (логирование процесса обучения, документирование моделей, разработка библиотеки для удобной работы с различными форматами геоданных в контексте задач ML).
Обо всем, конечно же, расскажем в следующих материалах.
Задавайте вопросы и делитесь своим опытом в решении подобных задач — будет интересно продолжить обсуждение в комментариях.
