Как устроено A/B-тестирование в Авито
Всем привет. Меня зовут Данила, я работаю в команде, которая развивает аналитическую инфраструктуру в Авито. Центральное место в этой инфраструктуре занимает А/B-тестирование.
А/B эксперименты — ключевой инструмент принятия решений в Авито. В нашем цикле продуктовой разработки А/B-тест является обязательным этапом. Мы проверяем каждую гипотезу и выкатываем только позитивные изменения.
Мы собираем сотни метрик и умеем детализировать их до бизнес-разрезов: вертикали, регионы, авторизованные пользователи и т. д. Мы делаем это автоматизированно с помощью единой платформы для экспериментов. В статье я достаточно подробно расскажу, как платформа устроена и мы с вами погрузимся в некоторые интересные технические детали.

Основные функции платформы A/B мы формулируем следующим образом.
- Помогает быстро запускать эксперименты
- Контролирует нежелательные пересечения экспериментов
- Считает метрики, стат. тесты, визуализирует результаты
Другими словами, платформа помогает наиболее быстро принимать безошибочные решения.
Если оставить за скобками процесс разработки фич, которые отправляются в тестирование, то полный цикл эксперимента выглядит так:

- Заказчик (аналитик или продакт-менеджер) настраивает через админку параметры эксперимента.
- Сплит-сервис, согласно этим параметрам, раздает клиентскому устройству нужную группу A/B.
- Действия пользователей собираются в сырые логи, которые проходят через агрегацию и превращаются в метрики.
- Метрики «прогоняются» через статистические тесты.
- Результаты визуализируются на внутреннем портале на следующий день после запуска.
Весь транспорт данных в цикле занимает один день. Эксперименты длятся, как правило, неделю, но заказчик получает инкремент результатов каждый день.
Теперь давайте погрузимся в детали.
В админке для конфигурации экспериментов используется формат YAML.

Это удобное решение для небольшой команды: доработка возможностей конфига обходится без фронта. Использование текстовых конфигов упрощает работу и пользователю: нужно делать меньше кликов мышкой. Похожее решение используется A/B-фреймворке Airbnb).
Для деления трафика на группы используем распространенную технику хеширования с солью.
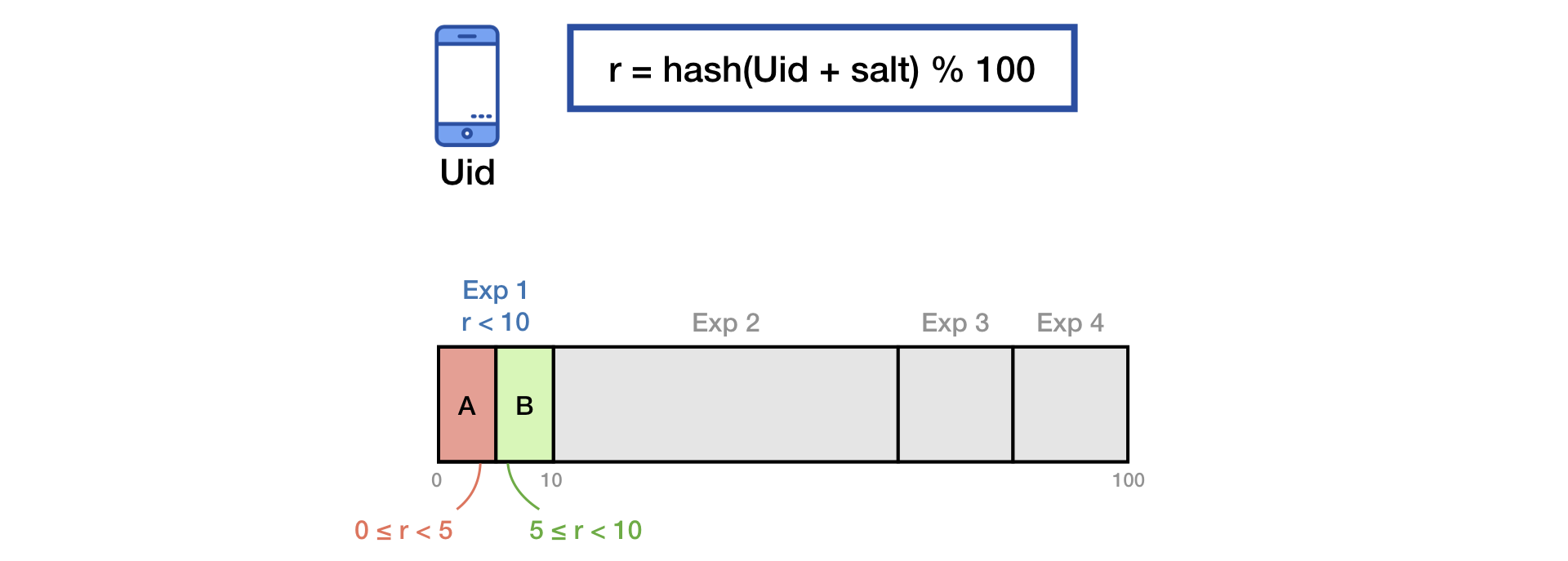
Для устранения эффекта «памяти» пользователей, при запуске нового эксперимента, мы делаем дополнительное перемешивание второй солью:
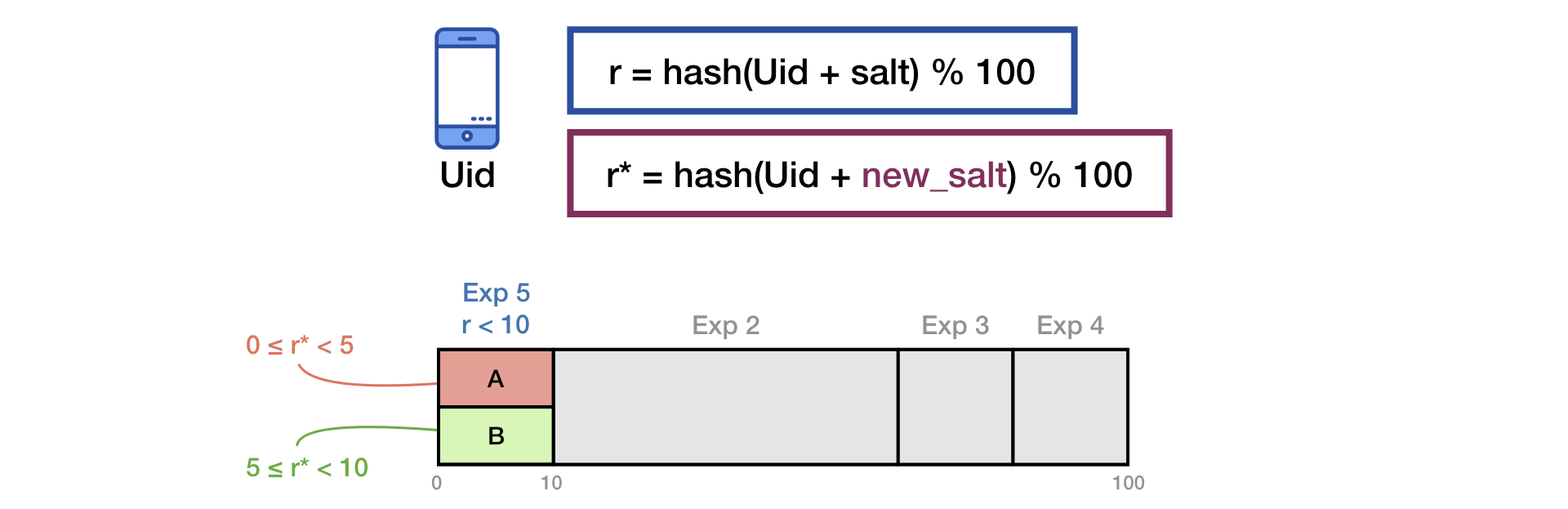
Этот же принцип описан в презентации Яндекса.
Чтобы не допускать потенциально опасных пересечений экспериментов, мы используем логику, схожую со «слоями» в Google.
Сырые логи мы раскладываем в Vertica и агрегируем в таблицы-препараты со структурой:

Observations (наблюдения) — это, как правило, простые каунтеры событий. Наблюдения используются как компоненты в формуле расчета метрик.
Формула расчета любой метрики — это дробь, в числителе и знаменателе которой стоит сумма наблюдений:
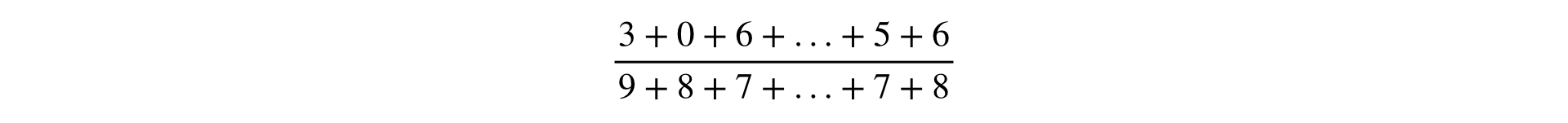
В одном из докладов Яндекса метрики подразделялись на два типа: по юзерам и Ratio. В этом есть бизнес-смысл, но в инфраструктуре удобнее все метрики считать единообразно в виде Ratio. Это обобщение валидно, потому что «поюзерная» метрика очевидно представима в виде дроби:
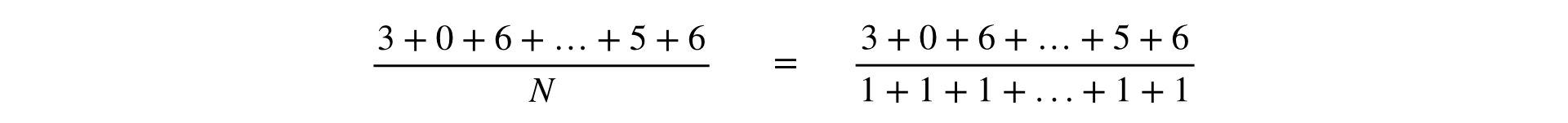
Наблюдения в числителе и знаменателе метрики мы суммируем двумя способами.
Простым:
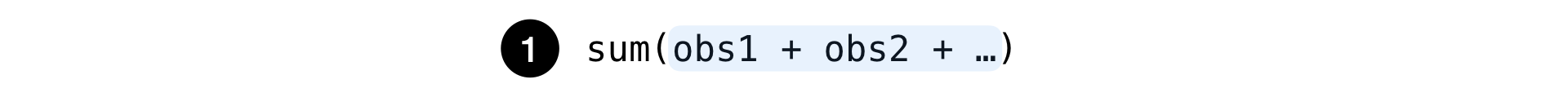
Это обычная сумма любого набора наблюдений: количество поисков, кликов по объявлениям и т. д.
И посложнее:

Уникальное количество ключей, в группировке по которым сумма наблюдений больше заданного порога.
Такие формулы легко задаются с помощью YAML-конфига:

Параметры groupby и threshold опциональны. Как раз они и определяют второй способ суммирования.
Описанные стандарты позволяют сконфигурировать почти любую онлайн-метрику, которую только можно придумать. При этом сохраняется простая логика, не накладывающая избыточную нагрузку на инфраструктуру.
Значимость отклонений по метрикам мы измеряем классическими методами: T-test, Mann-Whitney U-test. Главное необходимое условие для применения этих критериев — наблюдения в выборке не должны зависеть друг от друга. Почти во всех наших экспериментах мы считаем, что пользователи (Uid) удовлетворяют этому условию.

Теперь возникает вопрос: как провести T-test и MW-test для Ratio-метрик? Для T-test нужно уметь считать дисперсию выборки, а для MW выборка должна быть «поюзерной».
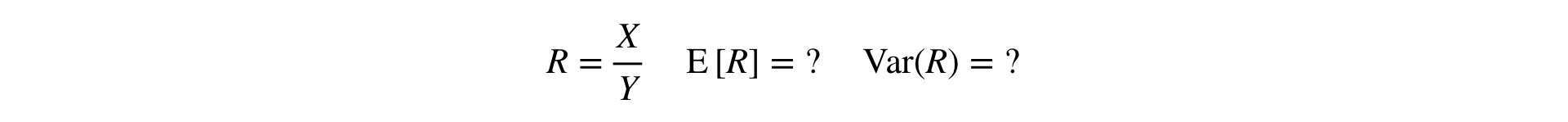
Ответ: нужно разложить Ratio в ряд Тейлора до первого порядка в точке ![$({E}\left[X\right], {E}\left[Y\right])$](https://habrastorage.org/getpro/habr/formulas/52a/019/7a7/52a0197a735d62cb00eba1b49da8fdd2.svg) :
:
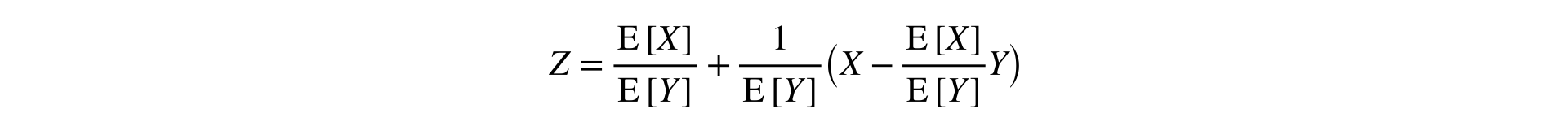
Данная формула преобразует две выборки (числитель и знаменатель) в одну, сохраняя среднее и дисперсию (асимптотически), что позволяет применять классические стат. тесты.
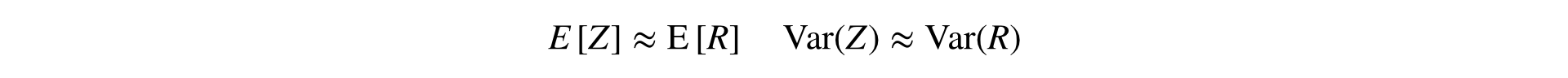
Похожую идею коллеги из Яндекса называют методом линеаризации Ratio (выступления раз и два).
Использование быстрых для CPU стат. критериев дает возможность проводить миллионы итераций (сравнений treatment vs. control) за считанные минуты на вполне обычном сервере с 56 ядрами. Но в случае больших объемов данных производительность упирается, в первую очередь, в хранение и время считывания с диска.
Расчет метрик по Uid ежедневно порождает выборки общим размером в сотни миллиардов значений (ввиду большого количества одновременных экспериментов, сотен метрик и кумулятивного накопления). Каждый день выгребать такие объемы с диска слишком проблематично (несмотря на большой кластер колоночной базы Vertica). Поэтому мы вынужденно сокращаем кардинальность данных. Но делаем это почти без потери информации о дисперсии с помощью техники, которую называем «Бакеты».
Идея проста: хешируем Uid’ы и по остатку от деления «разбрасываем» их на некоторое количество бакетов (обозначим их число за B):
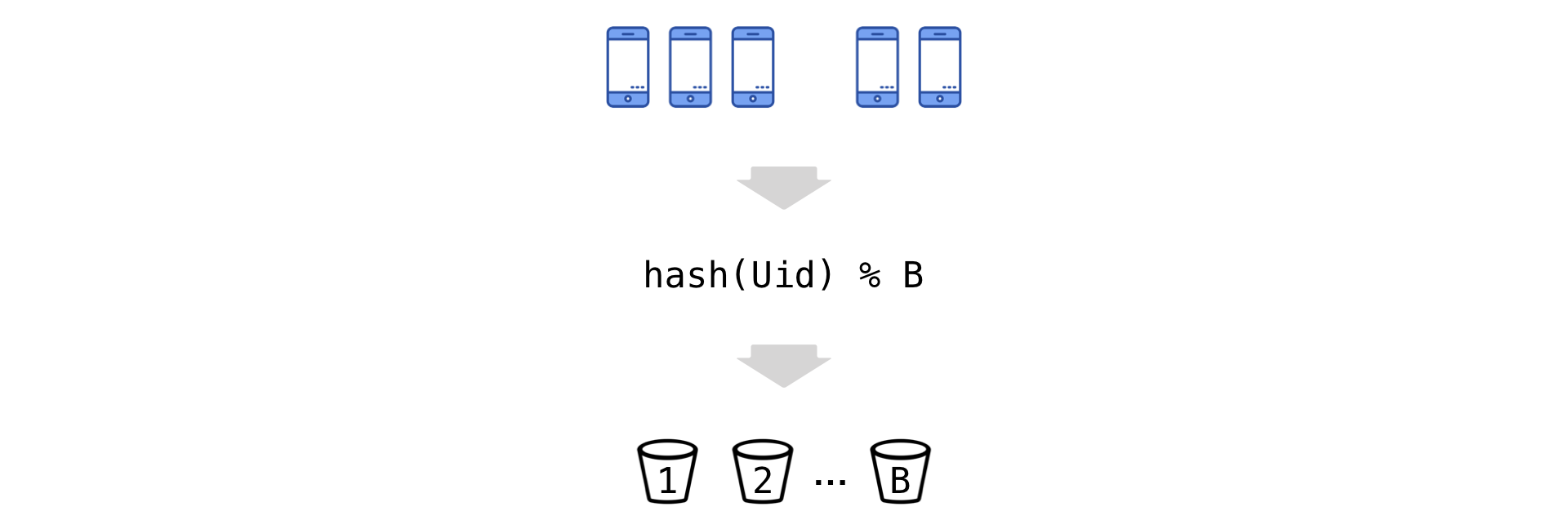
Теперь переходим к новой экспериментальной единице — бакет. Наблюдения в бакете суммируем (числитель и знаменатель независимо):

При таком преобразовании условие о независимости наблюдений выполняется, значение метрики не изменяется, и легко проверить, что и дисперсия метрики (среднего по выборке наблюдений) сохраняется:

Чем больше бакетов, тем меньше информации теряется, и тем меньше ошибка в равенстве. В Авито мы берем B = 200.
Плотность распределения метрики после бакетного преобразования всегда становится схожа с нормальным.
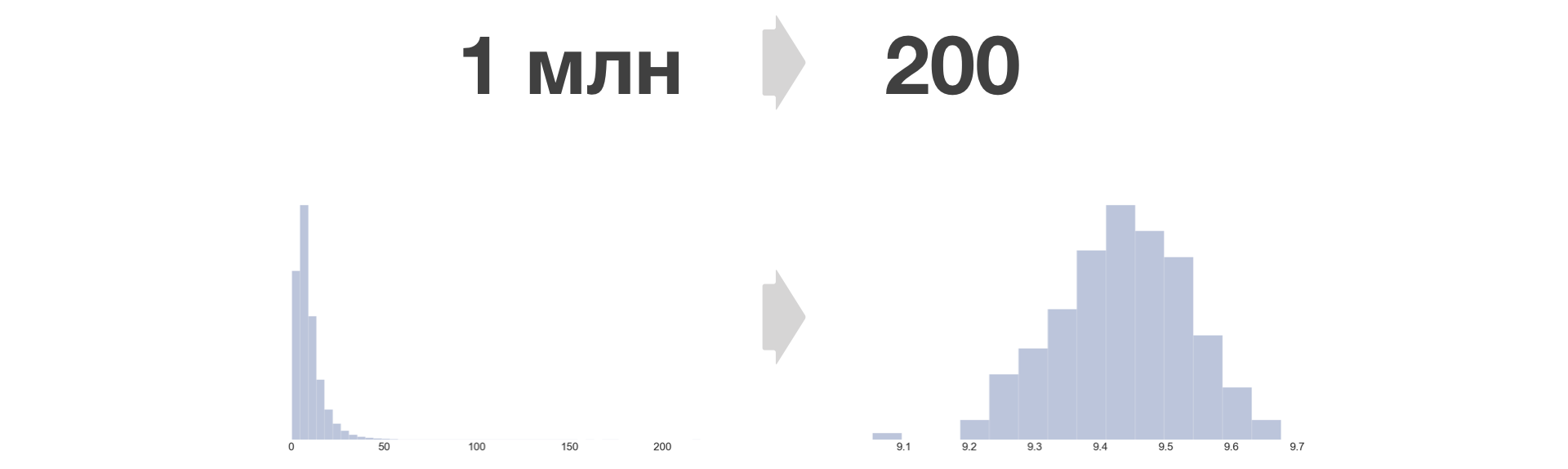
Сколь угодно большие выборки можно сокращать до фиксированного размера. Рост в количестве хранимых данных в таком случае лишь линейно зависит от количества экспериментов и метрик.
В качестве инструмента визуализации мы используем Tableau и веб-вью на Tableau Server. У каждого сотрудника Авито есть туда доступ. Следует отметить, что Tableau с задачей справляется хорошо. Реализовать аналогичное решение с помощью полноценной бэк/фронт разработки было бы куда более ресурсоемкой задачей.
Результаты каждого эксперимента — это простыня из нескольких тысяч чисел. Визуализация обязана быть такой, чтобы минимизировать неправильные выводы в случае реализации ошибок I и II рода, и при этом не «проморгать» изменения в важных метриках и срезах.
Во-первых, мы мониторим метрики «здоровья» экспериментов. Т. е. отвечаем на вопросы: «Поровну ли участников «налилось» в каждую из групп?», «Поровну ли авторизованных или новых пользователей?».
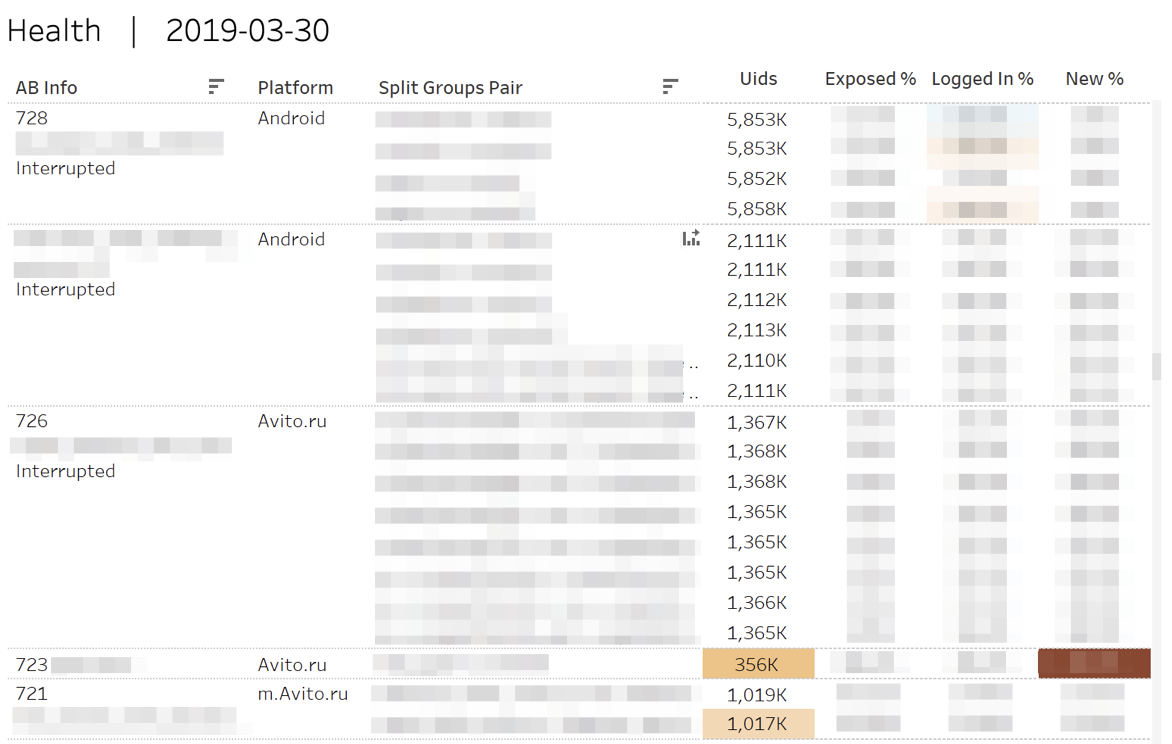
В случае статистически значимых отклонений соответствующие клеточки подсвечиваются. При наведении на любое число отображается кумулятивная динамика по дням.
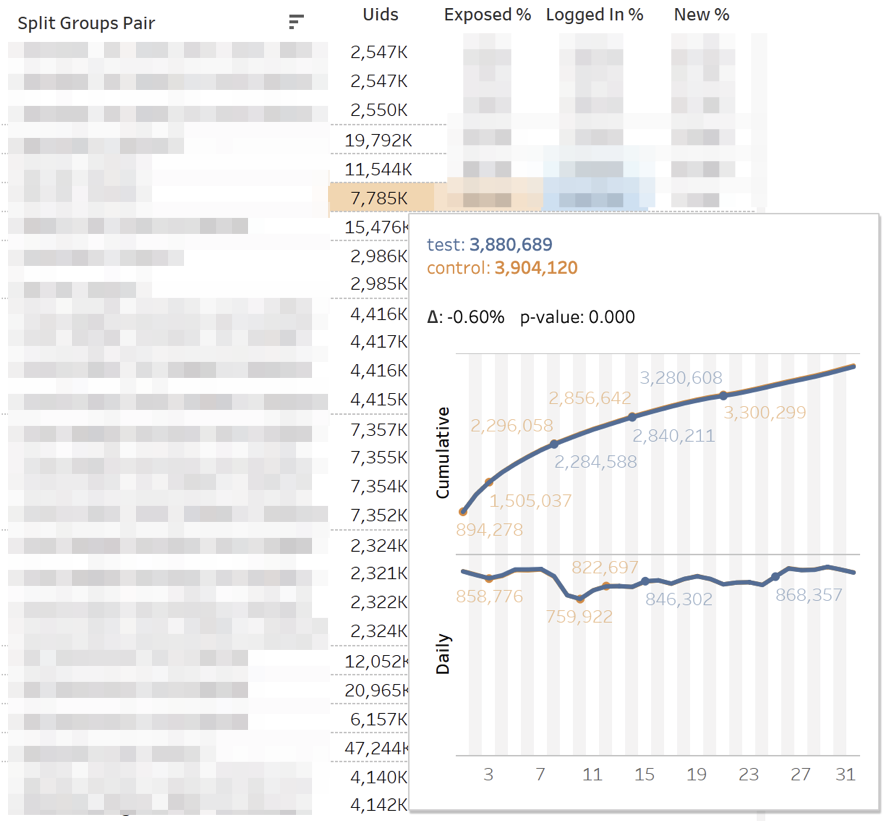
Главный дашборд с метриками выглядит так:
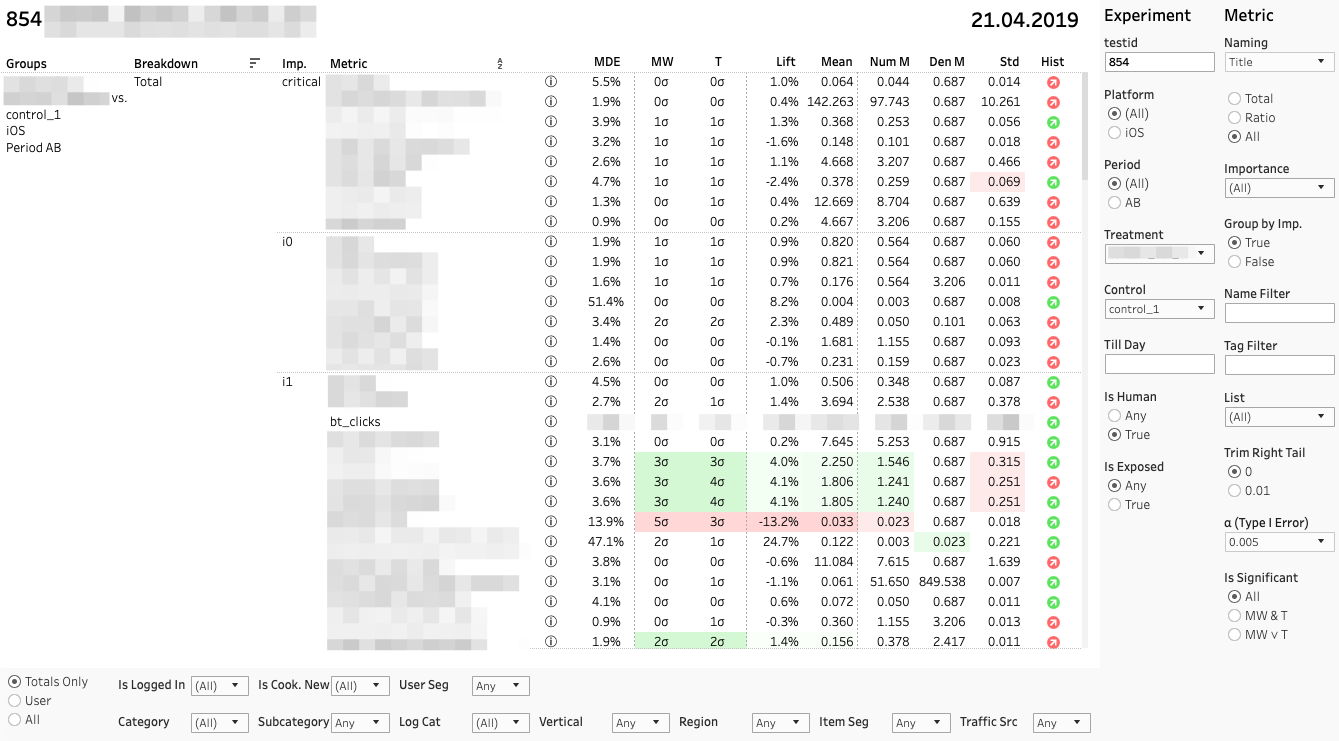
Каждая строка — сравнение групп по конкретной метрике в конкретном разрезе. Справа — панель с фильтрами по экспериментам и метрикам. Снизу — панель фильтров по разрезам.
Каждое сравнение по метрике состоит из нескольких показателей. Разберем их значения слева направо:
1. MDE. Minimum Detectable Effect

⍺ и β — заранее выбранные вероятности ошибки I и II рода. MDE очень важен, если изменение статистически не значимо. При принятии решения заказчик должен помнить, что отсутствие стат. значимости не равносильно отсутствию эффекта. Достаточно уверенно можно утверждать лишь то, что возможный эффект не больше, чем MDE.
2. MW | T. Результаты Mann-Whitney U- и T-test
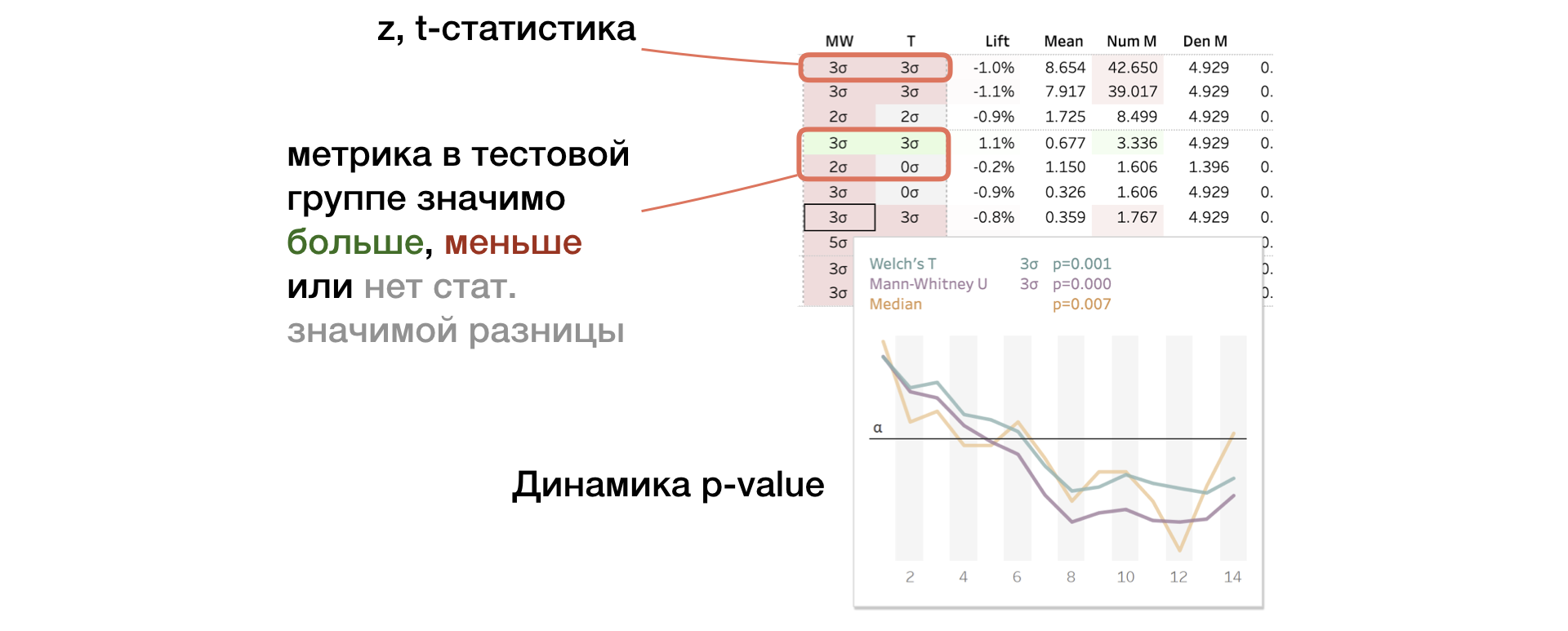
На панель выводим значение z- и t-статистики (для MW и T соответственно). В тултип — динамику p-value. Если изменение значимое, то клетка подсвечивается красным или зеленым цветом в зависимости от знака разницы между группами. В таком случае мы говорим, что метрика «прокрасилась».
3. Lift. Разница между группами в процентах
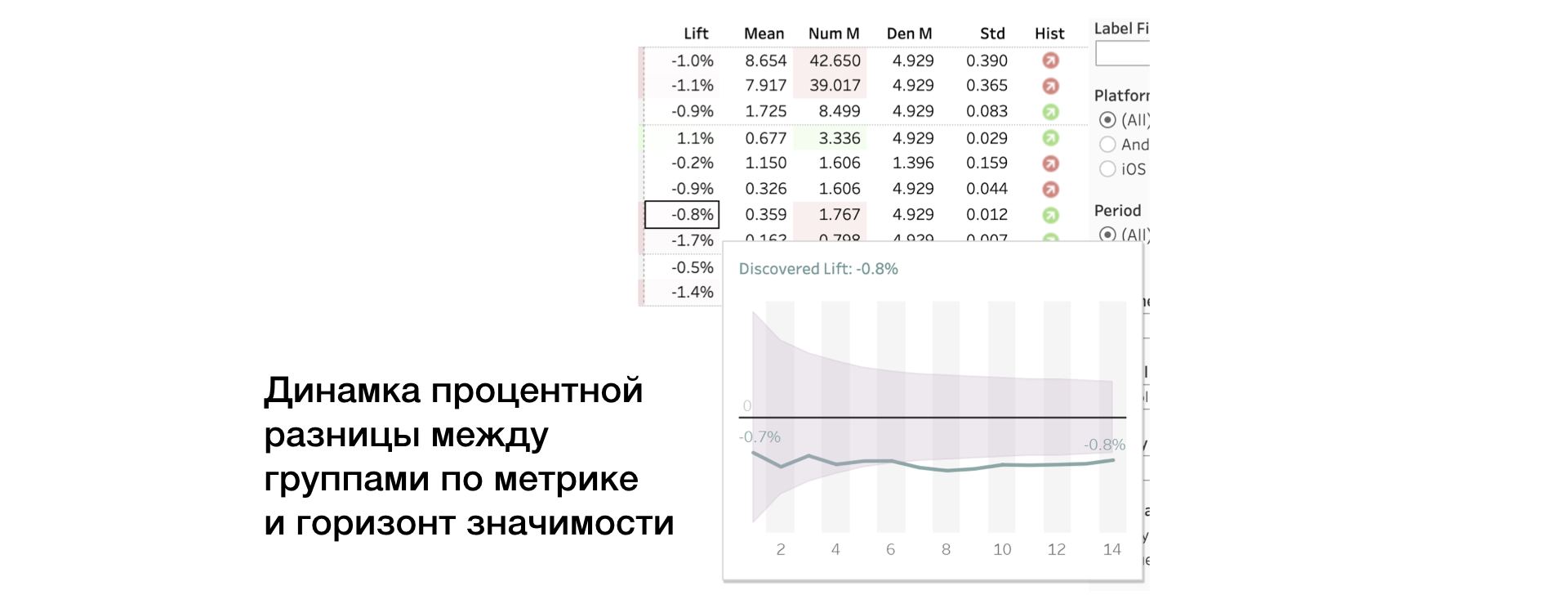
4. Mean | Num | Den. Значение метрики, а также числитель и знаменатель отдельно
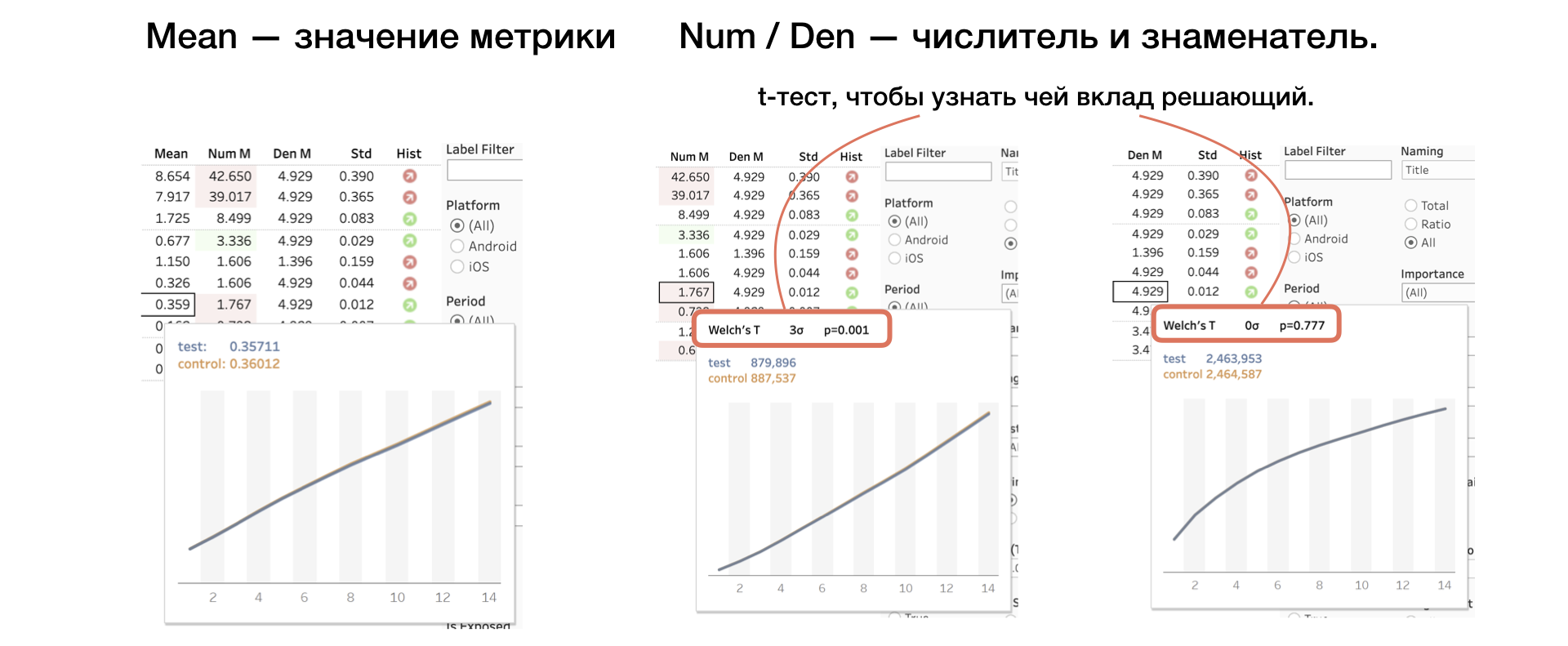
К числителю и знаменателю применяем еще один T-test, который помогает понять, чей вклад решающий.
5. Std. Выборочное стандартное отклонение
6. Hist. Тест Шапиро-Уилка на нормальность «бакетного» распределения.
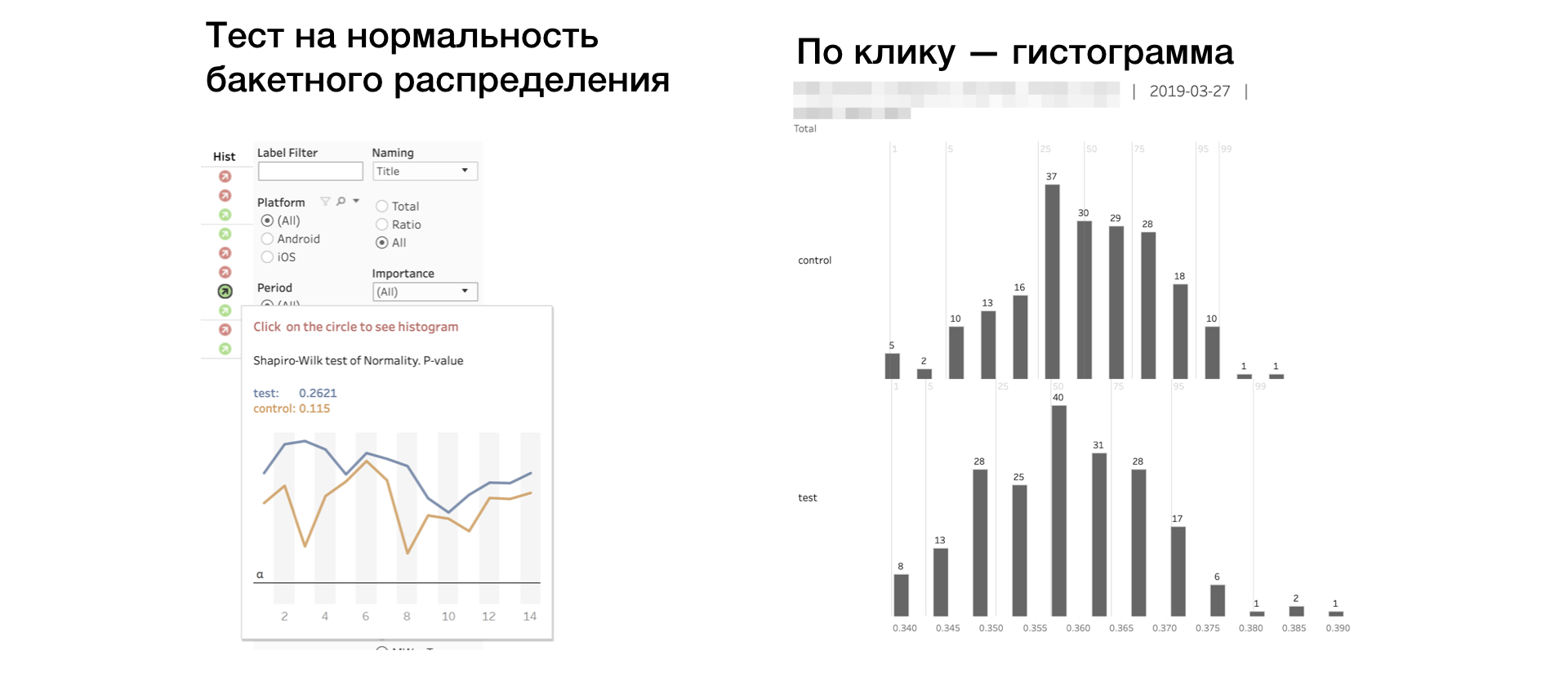
Если индикатор красный, то, возможно, в выборке есть выбросы или аномально длинный хвост. В таком случае принимать результат по этой метрике нужно осторожно, либо не принимать вовсе. Клик на индикатор открывает гистограммы метрики по группам. По гистограмме однозначно видны аномалии — так проще делать выводы.
Появление платформы A/B в Авито — переломная точка, когда наш продукт стал развиваться быстрее. Каждый день мы принимаем «зеленые» эксперименты, которые заряжают команду; и «красные», которые дают полезную пищу для размышлений.
Нам удалось построить эффективную систему A/B-тестинга и метрик. Часто сложные проблемы мы решали простыми методами. Благодаря этой простоте, инфраструктура имеет хороший запас прочности.
Уверен, те, кто собирается построить платформу A/B в своей компании, нашли в статье несколько интересных инсайтов. Я рад поделиться с вами нашим опытом.
Пишите вопросы и комментарии — постараемся на них ответить.
