Как устроена Алиса. Лекция Яндекса
В этой лекции впервые рассматриваются технологические решения, на основе которых работает Алиса — голосовой помощник Яндекса. Руководитель группы разработки диалоговых систем Борис Янгель hr0nix рассказывает, как его команда учит Алису понимать желания пользователя, находить ответы на самые неожиданные вопросы и при этом вести себя прилично.
— Я расскажу, что внутри у Алисы. Алиса большая, в ней много компонент, поэтому я немного поверхностно пробегусь.
Алиса — голосовой помощник, запущенный Яндексом 10 октября 2017 года. Она есть в приложении Яндекса на iOS и Android, а также в мобильном браузере и в виде отдельного приложения под Windows. Там можно решать свои задачи, находить информацию в формате диалога, общаясь с ней текстом или голосом. И есть киллер-фича, которая сделала Алису довольно известной в рунете. Мы пользуемся не только заранее известными сценариями. Иногда, когда мы не знаем, что делать, мы используем всю мощь deep learning, чтобы сгенерировать ответ от имени Алисы. Это получается довольно забавно и позволило нам оседлать поезд хайпа.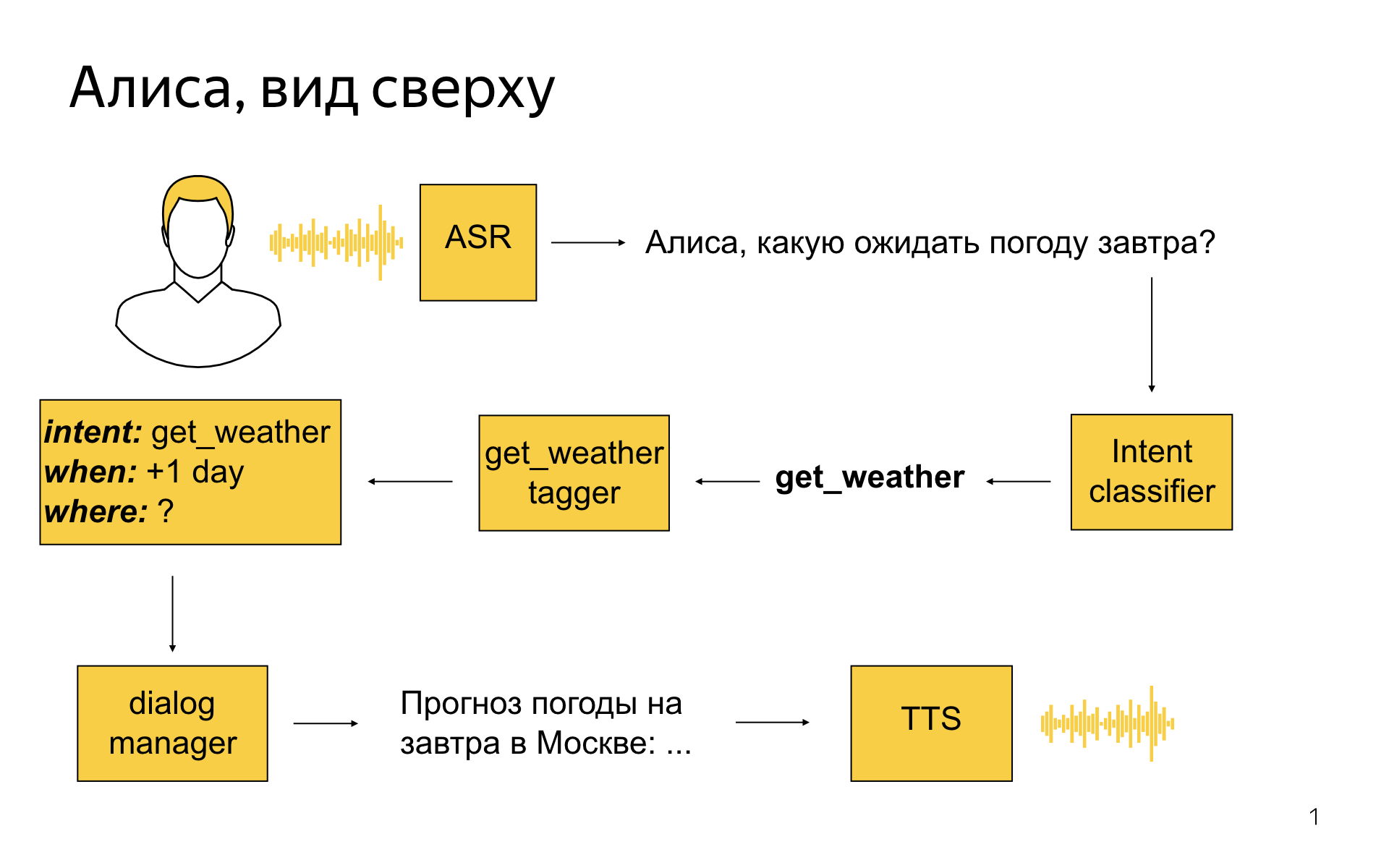
Как выглядит Алиса высокоуровнево?
Пользователь говорит: «Алиса, какую ожидать завтра погоду?»
Первым делом мы его речь стримим в сервер распознавания, он превращает ее в текст, и этот текст затем попадает в сервис, разработкой которого занимается моя команда, в такую сущность, как классификатор интентов. Это машиннообученная штука, задача которой — определить, чего же пользователь хотел сказать своей фразой. В этом примере классификатор интентов мог сказать: окей, наверное, пользователю нужна погода.
Затем для каждого интента есть специальная модель, которая называется семантический теггер. Задача модели — выделить полезные крупицы информации в том, что сказал пользователь. Теггер для погоды мог бы сказать, что завтра — это дата, на которую пользователю нужна погода. И все эти результаты разбора мы превращаем в некоторое структурированное представление, которое называется фреймом. В нем будет написано, что это интент погода, что погода нужна на +1 день от текущего дня, а где — неизвестно. Вся эта информация попадает в модуль dialog manager, который, помимо этого, знает текущий контекст диалога, знает, что происходило до этого момента. Ему на вход поступают результаты разбора реплики, и он должен принять решение, что с ними сделать. Например, он может сходить в API, узнать погоду на завтра в Москве, потому что геолокация пользователя — Москва, хоть он ее и не указал. И сказать — сгенерируйте текст, который описывает погоду, затем его отправить на модуль синтеза речи, который с пользователем поговорит прекрасным голосом Алисы.
Dialog Manager. Здесь нет никакого машинного обучения, никакого reinforcement learning, там только конфиги, скрипты и правила. Это работает предсказуемо, и понятно, как это поменять, если нужно. Если менеджер приходит и говорит, поменяйте, то мы можем это сделать в короткие сроки.
В основе концепции Dialog Manager лежит концепция, известная тем, кто занимается диалоговыми системами, как form-filling. Идея в том, что пользователь своими репликами как бы заполняет некую виртуальную форму, и когда он в ней заполнит все обязательные поля, его потребность можно удовлетворить. Движок event-driven: каждый раз, когда пользователь что-то делает, происходят какие-то события, на которые можно подписываться, писать их обработчики на Python и таким образом конструировать логику диалога.
Когда нужно в сценариях сгенерировать фразу — например, мы знаем, что пользователь говорит про погоду и нужно ответить про погоду, — у нас есть мощный язык шаблонов, который позволяет нам эти фразы писать. Вот так это выглядит.
Это надстройка над питонячьим шаблонизатором Jinja2, в которую добавили всякие лингвистические средства, например возможности склонять слова или согласовывать числительные и существительные, чтобы можно было легко когерентный текст писать, рандомизировать кусочки текста, чтобы увеличивать вариативность речи Алисы.
В классификаторе интентов мы успели попробовать множество разных моделей, начиная от логистической регрессии и заканчивая градиентным бустингом, рекуррентными сетями. В итоге остановились на классификаторе, который основан на ближайших соседях, потому что он обладает кучей хороших свойств, которых у других моделей нет.
Например, вам часто надо иметь дело с интентами, для которых у вас есть буквально несколько примеров. Просто учить обычные классификаторы мультиклассовые в таком режиме невозможно. Например, у вас оказывается, что во всех примерах, которых всего пять, была частица «а» или «как», которой не было в других примерах, и классификатор находит самое простое решение. Он решает, что если встречается слово «как», то это точно этот интент. Но это не то, чего вы хотите. Вы хотите семантической близости того, что сказал пользователь, к фразам, которые лежат в трейне для этого интента.
В итоге мы предобучаем метрику на большой датасете, которая говорит о том, насколько семантически близки две фразы, и потом уже пользуемся этой метрикой, ищем ближайших соседей в нашем трейнсете.
Еще хорошее качество этой модели, что ее можно быстро обновлять. У вас появились новые фразы, вы хотите посмотреть, как изменится поведение Алисы. Все, что нужно, это добавить их множество потенциальных примеров для классификатора ближайших соседей, вам не нужно переподбирать всю модель. Допустим, для нашей рекуррентной модели это занимало несколько часов. Не очень удобно ждать несколько часов, когда вы что-то меняете, чтобы увидеть результат.
Семантический теггер. Мы пробовали conditional random fields и рекуррентные сети. Сети, конечно, работают намного лучше, это ни для кого не секрет. У нас там нет уникальных архитектур, обычные двунаправленные LSTM с attention, плюс-минус state-of-the-art для задачи тегирования. Все так делают и мы так делаем.
Единственное, мы активно пользуемся N-best гипотез, мы не генерируем только самую вероятную гипотезу, потому что иногда нам нужна не самая вероятная. Например, мы перевзвешиваем зачастую гипотезы в зависимости от текущего состояния диалога в dialog manager.
Если мы знаем, что на предыдущем шаге мы задали вопрос про что-то, и есть гипотеза, где теггер что-то нашел и гипотеза, где не нашел, то наверное, при прочих равных первое более вероятно. Такие трюки нам позволяют немного улучшить качество.
А еще машиннообученный теггер иногда ошибается, и не совсем точно в самой правдоподобной гипотезе находят значение слотов. В этом случае мы ищем в N-best гипотезу, которая лучше согласуется с тем, что мы знаем о типах слотов, это позволяет тоже еще немного качество заработать.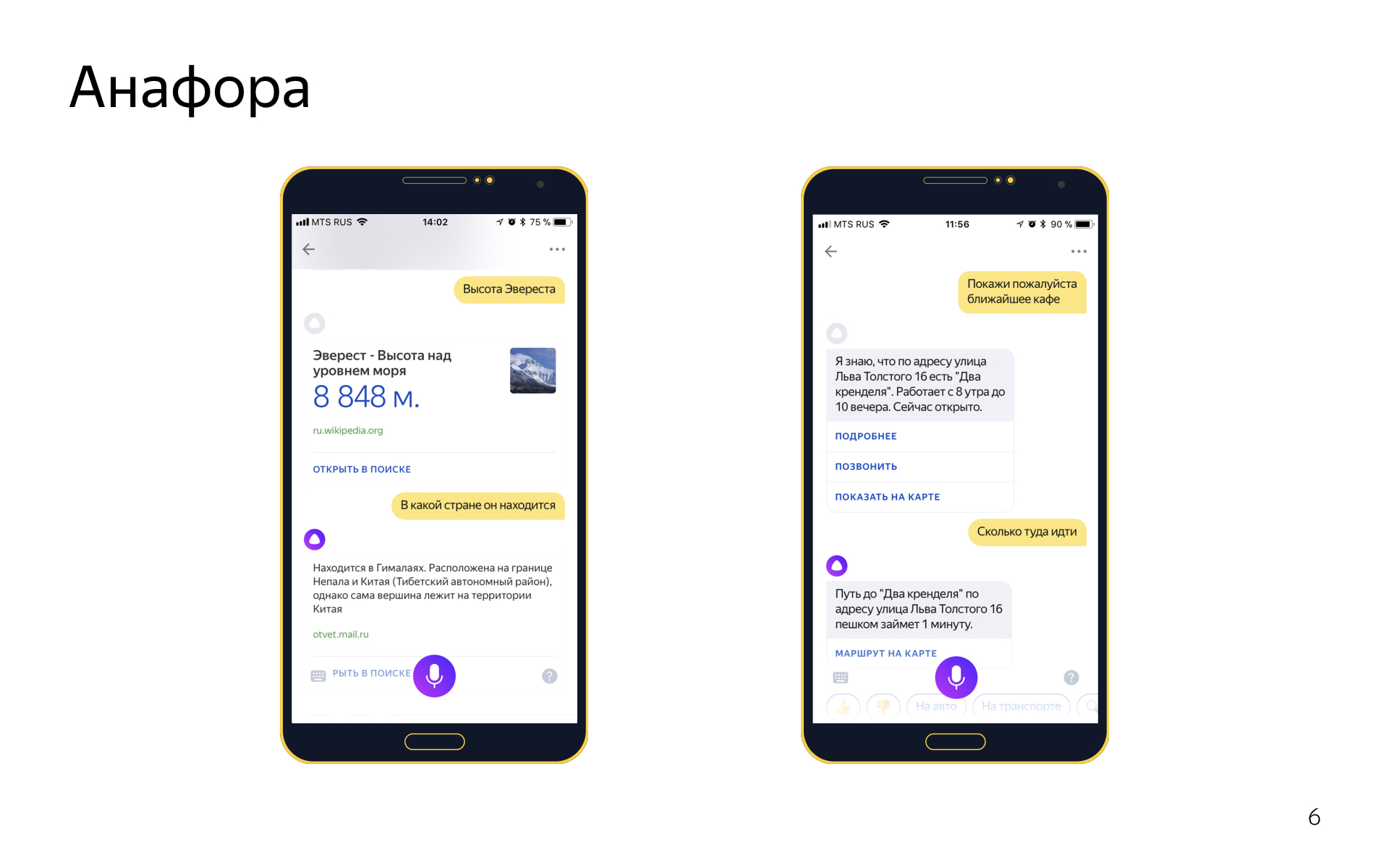
Еще в диалогах есть такое явление Анафора. Это когда вы с помощью местоимения ссылаетесь на какой-то объект, который был раньше в диалоге. Скажем, говорите «высота Эвереста», и потом «в какой стране он находится». Мы анафоры умеем разрешать. Для этого у нас две системы.
Одна general-purpose система, которая может работать на любых репликах. Она работает поверх синтаксического разбора всех пользовательских репликах. Если мы видим местоимение в его текущей реплике, мы ищем known phrases в том, что он сказал раньше, считаем для каждой из них скорость, смотрим, можно ли ее подставить вместо этого местоимения, и выбираем лучшую, если можем.
А еще у нас есть система разрешения анафор, основанная на form filling, она работает примерно так: если в предыдущем интенте в форме был геообъект, и в текущем есть слот для геообъекта, и он не заполнен, и еще мы в текущий интент попали по фразе с местоимением «туда», то наверное, можно предыдущий геообъект импортировать из формы и подставить сюда. Это простая эвристика, но производит неплохое впечатление и круто работает. В части интентов работает одна система, а в части обе. Мы смотрим, где работает, где не работает, гибко это настраиваем.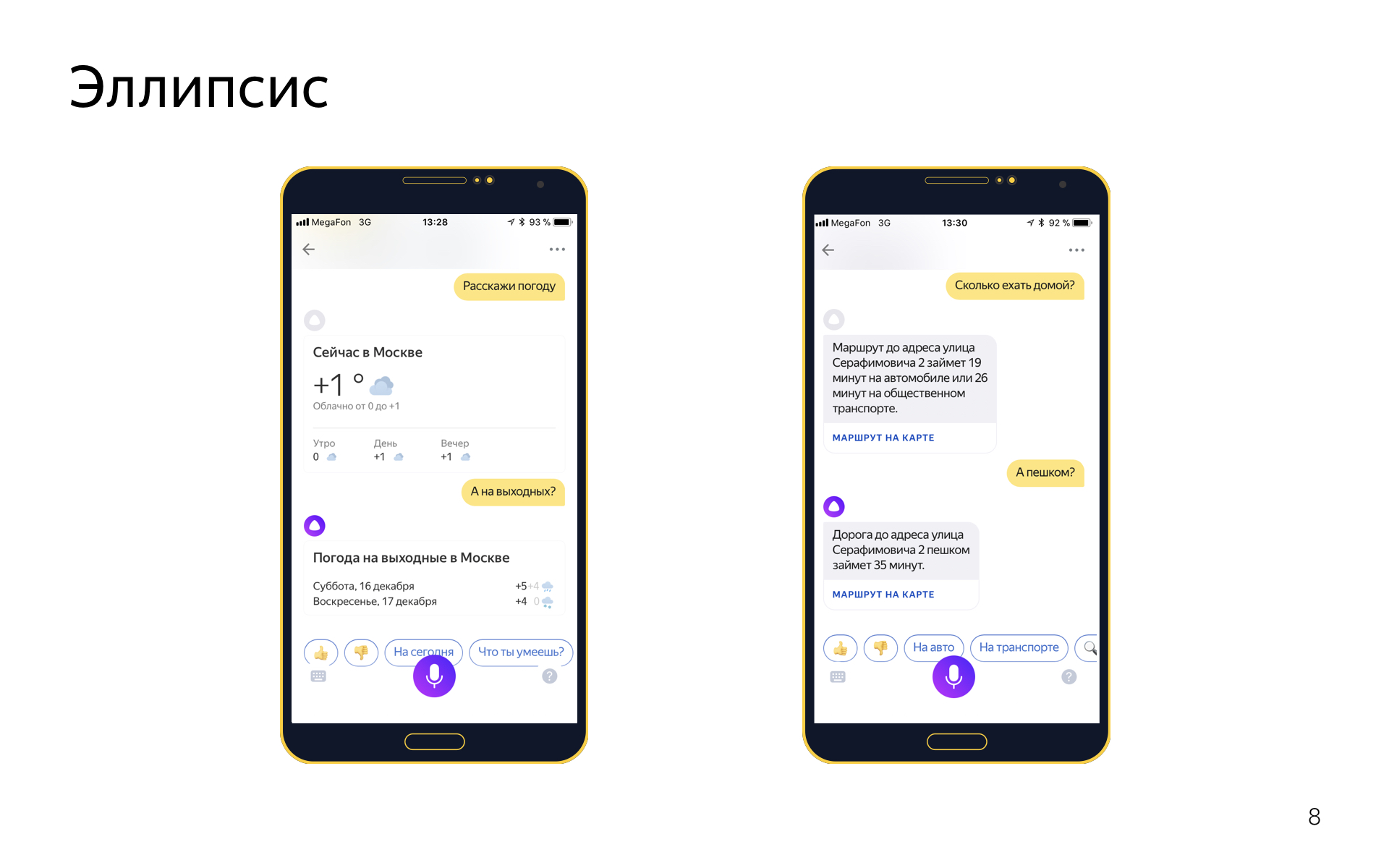
Есть эллипсис. Это когда в диалоге вы опускаете какие-то слова, потому что они подразумеваются из контекста. Например, вы можете сказать «расскажи погоду», а потом «а на выходных?», имея в виду «расскажи погоду на выходных», но вы хотите повторять эти слова, потому что это ни к чему.
С эллипсисами мы тоже умеем работать примерно следующим образом. Эллиптические фразы или фразы-уточнения — это отдельные интенты.
Если есть интент get_weather, для которого в трейне фразы типа «расскажи погоду», «какая сегодня погода», то у него будет парный интент get_weather_ellipsis, в котором всевозможные уточнения погоды: «а на завтра», «а на выходные», «а что там в Сочи» и так далее. И эти эллиптические интенты в классификаторе интентов на равных конкурируют со своими родителями. Если вы скажете «а в Москве?», классификатор интентов, например, скажет, что с вероятностью 0,5 это уточнение в интенте погода, и с вероятностью 0,5 уточнение в интенте поиска организаций, например. И затем диалоговый движок перевзвешивается scores, которые назначил классификатор интентов, который назначил их с учетом текущего диалога, потому что он, например, знает, что до этого шел разговор о погоде, и вряд ли это было уточнение про поиск организаций, скорее это про погоду.
Такой подход позволяет обучаться и определять эллипсисы без контекста. Вы можете просто откуда-то набрать примеров эллиптических фраз без того, что было раньше. Это довольно удобно, когда вы делаете новые интенты, которых нет в логах вашего сервиса. Можно или фантазировать, или чего-то придумывать, или пытаться на краудсорсинговой платформе собрать длинные диалоги. А можно легко насинтезировать для первой итерации таких эллиптических фраз, они будут как-то работать, и потом уже собирать логи.
Вот жемчужина нашей коллекции, мы называем ее болталкой. Это та самая нейросеть, которая в любой непонятной ситуации чего-то от имени Алисы отвечает и позволяет вести с ней зачастую странные и часто забавные диалоги.
Болталка — на самом деле fallback. В Алисе это работает так, что если классификатор интентов не может уверенно определить, чего хочет пользователь, то другой бинарный классификатор сперва пытается решить — может, это поисковый запрос и мы найдем что-то полезное в поиске и туда отправим? Если классификатор говорит, что нет, это не поисковый запрос, а просто болтовня, то срабатывает fallback на болталку. Болталка — система, которая получает текущий контекст диалога, и ее задача — сгенерировать максимально уместный ответ. Причем сценарные диалоги тоже могут являться частью контекста: если вы говорили про погоду, а потом сказали что-то непонятное, сработает болталка.
Это позволяет нам делать вот такие штуки. Вы спросили про погоду, а потом болталка ее как-то прокомментировала. Когда работает, выглядит очень круто.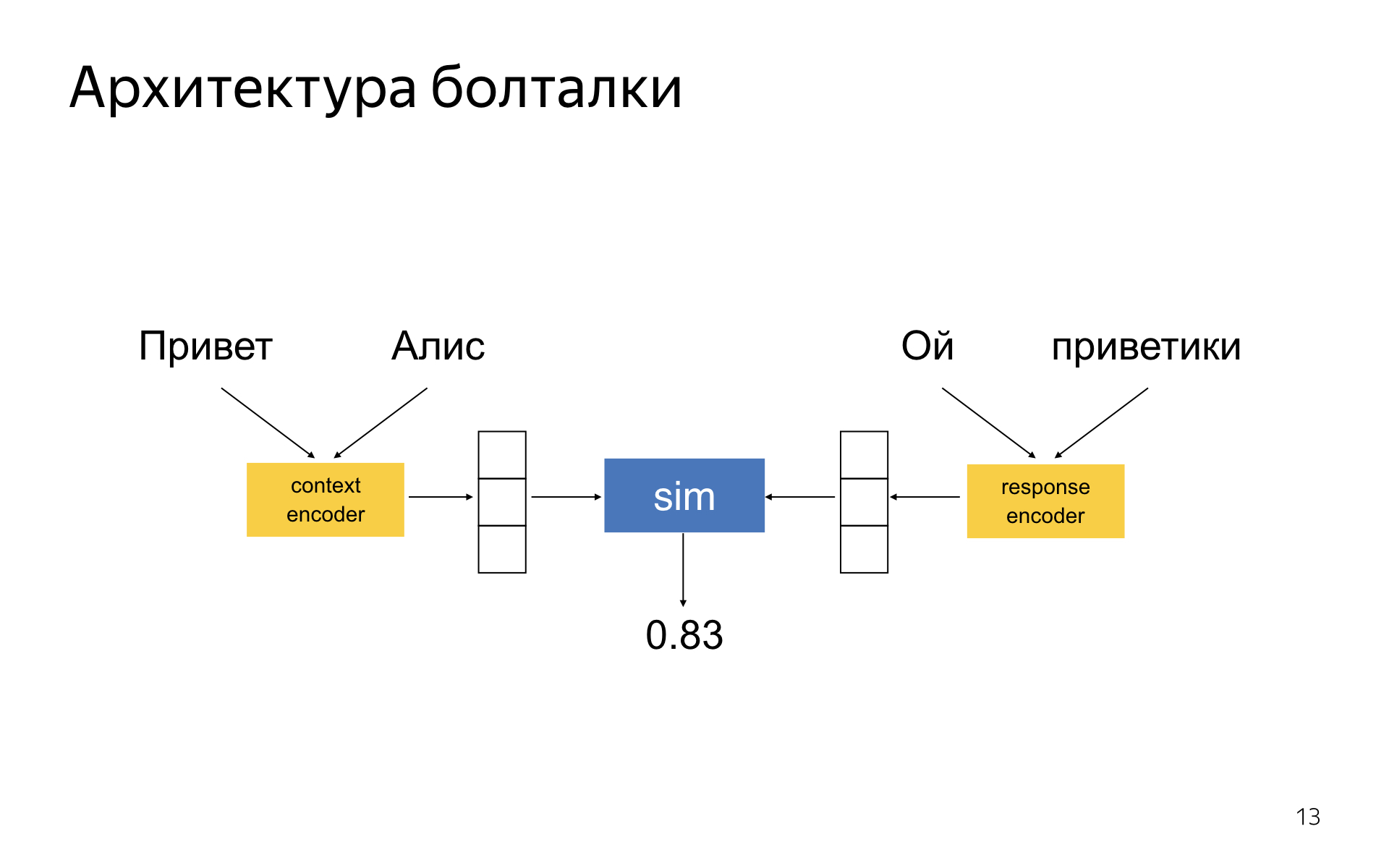
Болталка — DSSM-подобная нейронная сеть, где есть две башни энкодера. Один энкодер кодирует текущий контекст диалога, другой — ответ-кандидат. У вас получается два embedding-вектора для ответа и контекста, и сеть обучается так, чтобы косинусное расстояние между ними было тем больше, чем уместнее данный ответ в контексте и чем неуместнее. В литературе эта идея давно известна.
Почему у нас вроде неплохо все работает — кажется, что чуть лучше, чем в статьях?
Никакой серебряной пули нет. Нет техники, которая позволит внезапно сделать классно разговаривающую нейронную сеть. Нам удалось достичь неплохого качества, потому что мы в качестве понемножку выиграли везде. Мы долго подбирали архитектуры этих башен-энкодеров, чтобы они лучше всего работали. Очень важно правильно подобрать схему сэмплирования отрицательных примеров в обучении. Когда вы обучаетесь на диалоговых корпусах, у вас есть только положительные примеры, которые когда-то кем-то были сказаны в таком контексте. А отрицательных нет — их нужно как-то генерировать из этого корпуса. Там есть много разных техник, и одни работают лучше, чем другие.
Важно, как вы выбираете ответ из топа кандидатов. Можно выбирать наиболее вероятный ответ, предлагаемый моделью, но это не всегда лучшее, что можно сделать, потому что при обучении модель учитывала не все характеристики хорошего ответа, которые существуют с продуктовой точки зрения.
Ещё очень важно, какими дата-сетами вы пользуетесь, как их фильтруете.
Чтобы по крупицам собрать из этого всего качество, надо уметь измерять все, что вы делаете. И тут наша гордость состоит в том, что все аспекты качества системы мы умеем мерить на нашей краудсорсинговой платформе по кнопке. Когда у нас появляется новый алгоритм генерации результатов, мы в несколько кликов можем сгенерировать ответ новой модели на специальном тестовом корпусе. И — померить все аспекты качества полученной модели в Толоке. Основная метрика, которой мы пользуемся, — логическая уместность ответов в контексте. Не надо говорить чушь, которая никак с этим контекстом не связана.
Есть ряд дополнительных метрик, которые мы стараемся оптимизировать. Это когда Алиса к пользователю на «ты» обращается, говорит о себе в мужском роде и произносит всякие дерзости, гадости и глупости.
Высокоуровнево я рассказал все, что хотел. Спасибо.
